4. virio-net前端驱动分析
4.1 重要数据结构
4.1.1 send_queue结构

send_queue结构是对virtqueue的封装,是virtio-net的发送队列,即数据流向从前端驱动(Guest)到后端驱动(Host)
4.1.2 receive_queue结构

receive_queue结构也是对virtqueue的封装,是virtio-net的接收队列,即数据流向从后端驱动(Host)到前端驱动(Guest)
说明:multiqueue virtio-net
virtio-net前端驱动支持multiqueue机制,也就是允许有多对send_queue & receive_queue,在virtnet_probe过程中会检查宿主机的设置,获取收发队列的对数

这样在创建virtqueue时,会根据配置项分配内存
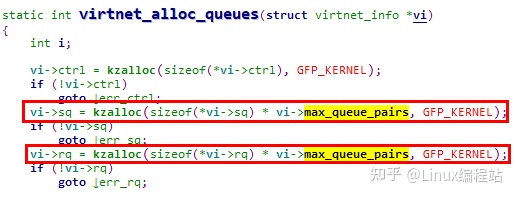
但是在一般情况下,均使用1条send_queue + 1条receive_queue,且没有控制队列
4.1.3 virtnet_netdev callback数组
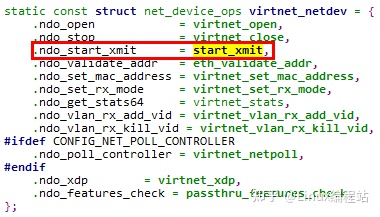
在Linux中,net_device结构描述了一个网络设备,其中的net_device_ops则包含了该网络设备的操作方法集
其中特别注意ndo_start_xmit callback函数,该函数为网卡发送报文时使用的函数
【文章福利】小编在群文件上传了一些个人觉得比较好得学习书籍、视频资料,有需要的可以进群【977878001】领取!!!额外赠送一份价值699的内核资料包(含视频教程、电子书、实战项目及代码)
内核资料直通车:Linux内核源码技术学习路线+视频教程代码资料
学习直通车:Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈
4.2 发送报文流程
4.2.1 到达start_xmit函数
内核协议栈
dev_hard_start_xmit //net\core\dev.c
xmit_one
netdev_start_xmit //include/linux/netdevice.h
__netdev_start_xmit
ops->ndo_start_xmit(skb, dev); 到virtio_net.c 中
||
\/
virtio_net.c中
static const struct net_device_ops virtnet_netdev = {
.ndo_start_xmit = start_xmit,
start_xmit
xmit_skb // 把skb放到vqueue中
virtqueue_add_outbuf
//把数据写到队列中
virtqueue_add //virtio_ring.c
virtqueue_add_split
virtqueue_kick //virtio_ring.c
||
\/
virtqueue_kick
virtqueue_notify
vq->notify(_vq) // agile_nic.c中notify函数,通知板卡驱动给队列中写数据了,然后板卡收到notify后,读取数据
① 虚拟机中的进程发送网络包时,仍然通过文件系统和socket调用网络协议栈到达网络设备层。只不过此时不是到达普通的网络设备,而是virtio-net前端驱动
② virtio-net前端驱动作为网卡设备驱动层,接收IP层传输下来的二层网络数据包
③ 发送网络包的流程最终将调用net_device_ops结构中的ndo_start_xmit回调函数,在virtio-net驱动中,就是start_xmit函数

4.2.2 start_xmit函数主要流程
与virtio框架相关的只有2个步骤,
① 调用xmit_skb函数将网络包写入virtqueue

② 触发后端驱动中断

virtqueue_kick函数在上文已有说明,此处说明一下xmit_skb函数的实现
4.2.3 xmit_skb函数

xmit_skb函数将sk_buff映射到scatterlist中,之后调用virtqueue_add_outbuf函数将数据请求加入send_queue的avail ring
说明:这里传递给data的值为skb,也就是要发送的skb的地址。注意,skb的地址值是一个GVA(Guest Virtual Address),因此只在虚拟机中使用
4.3 接收报文流程
数据接收流程:
napi_gro_receive(&rq->napi, skb);
netif_receive_skb
__netif_receive_skb // 传输skb给网络层
/\
||
驱动 virtio_net.c 中poll方法 napi_poll(n, &repoll); 即virtio_net.c 中 virtnet_poll()
virtnet_poll
virtnet_receive
receive_buf // 接收到的数据转换成skb
//根据接收类型XDP_PASS、XDP_TX等对 virtqueue 中的数据进行不同的处理
skb = receive_mergeable(dev, vi, rq, buf, ctx, len, xdp_xmit,stats); or
skb = receive_big(dev, vi, rq, buf, len, stats); or
skb = receive_small(dev, vi, rq, buf, ctx, len, xdp_xmit, stats);
napi_gro_receive(&rq->napi, skb); // 把skb上传到上层协议栈
schedule_delayed_work //通过你延迟队列接收数据
refill_work
try_fill_recv(vi, rq, GFP_KERNEL);
如果检测到本次中断 receive 数据完成,则重新开启中断
local_bh_enable //enable 软中断 等待下一次中断接收数据
/\
||
中断下半步
执行软中断回调函数 net_rx_action(), 调用 virtio_net.c 中 virtnet_poll()
/\
||
检查poll队列上是否有设备在等待轮询
napi_schedule ->__napi_schedule -> list_add_tail(&napi->poll_list, &sd->poll_list); //把 NAPI 加入到本地cpu的 softnet_data 的 poll_list链表头
__raise_softirq_irqoff(NET_RX_SOFTIRQ); // 调度收包软中断
/\
||
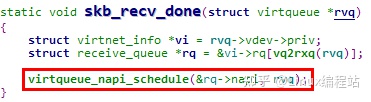
skb_recv_done //virtio_net.c 中 virtnet_find_vqs() 中,数据接收完成回调函数
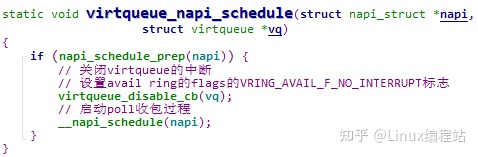
virtqueue_napi_schedule
调用 napi_schedule
/\
||
每个vq 对应一个数据接收函数 vring_interrupt()
vring_interrupt() //virtio_ring.c
vq->vq.callback(&vq->vq); 即virtio_net.c 中 skb_recv_done
/\
||
中断上半步
pcie网卡发送数据给host时,会触发pci msix硬中断,然后host driver agile_nic.c 中执行回调函数vring_interrupt4.3.1 NAPI接收网络包流程概述
① 传统的网络收包流程完全靠中断驱动,当网络包到达十分频繁时,就会频繁触发中断,进而影响系统的整体性能
② NAPI方式的核心就是当有数据包到达时,集中处理网络包,之后再去处理其他事情
③ NAPI的处理流程是,当一些网络包到达触发中断时,内核处理完这些网络包之后,主动轮询poll网卡,主动去接收到来的网络包。如果一直有,就一直处理,等处理告一段落再返回
当再有下一批网络包到达时,再中断,再轮询poll。这样就会大大减少中断的数量,提升网络处理的效率
说明:注册NAPI收包poll函数
在virtio-net前端驱动中,在probe过程中,会调用netif_napi_add函数注册收包poll函数

可见此处注册的函数为virtnet_poll
4.3.2 virtio中断处理函数 skb_recv_done
如上文所述,virtqueue的中断处理函数最终会调用到创建virtqueue时注册的callback回调函数,该函数为 skb_recv_done,这也就是virtio-net前端驱动的收包中断顶半部操作
4.3.3 virtnet_poll函数分析

说明:virtnet_poll_cleantx函数分析
在接收数据报文之前,先调用了virtnet_poll_cleantx函数处理了send_queue
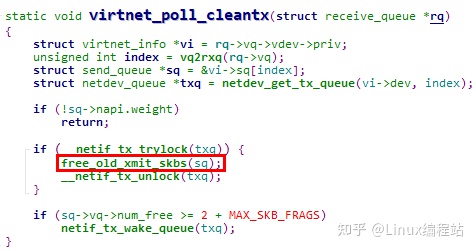
其中的核心为free_old_xmit_skbs函数,分析如下,

这里也很好地体现了vring_desc_state结构中data成员的使用,
① 前端驱动发送报文时,将含有报文的skb写入data成员,数据请求加入avail ring
② 后端驱动处理完数据请求后,将chain descriptor从avail ring加入used ring
③ 前端驱动在处理后端驱动已使用的chain descriptor时,从data成员中取出skb地址,并释放sk_buffer
4.3.4 virtnet_receive函数分析前奏
首先思考一个问题,receive_queue中的avail ring是何时填充的 ?
receive_queue的数据流向是从后端驱动到前端驱动,但是前端驱动需要先将数据请求加入avail ring,这样后端驱动在要发送网络包时,才能从avail ring中取出可用的chain descriptor
而且这里还带来另外一个问题,前端驱动是不知道后端驱动所要发送的报文大小的,那么该如何组织descriptor ring呢 ?
结合上文,这里解题的线索就是virtqueue_add_inbuf & virtqueue_add_inbuf_ctx函数在virtio-net前端驱动中的调用
这样我们就很容易地找到关键的函数,try_fill_recv !

可见try_fill_recv函数会将所有可用的描述符均加入receive_queue的avail ring,供后端驱动使用
我们分析add_recvbuf_small函数,另外两种情况需要后端驱动配置支持

这里需要注意调用virtqueue_add_inbuf_ctx的2个参数,因为后续的接收报文流程会使用
data:实参为buf,即分配的内存页面的GVA
ctx:实参为ctx,值为xdp_headroom
说明:try_fill_recv函数的调用时机
① 打开网卡时
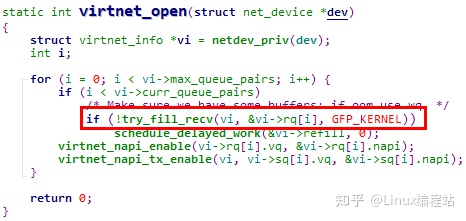
其中调度vi->refill工作,也会导致try_fill_recv函数被调用
② 网卡restore时

③ 接收报文时,也就是接下来要分析的函数

4.3.5 virtnet_receive函数分析

① 调用virtqueue_get_buf函数
将receive_queue中used ring的chain descriptor归还descriptor table,返回的buf就是上文分析的分配的内存的GVA,该地址在虚拟机中可以使用
② 调用receive_buf函数接收报文数据

至此,virtio-net前端驱动接收报文的工作就结束后,后续就是虚拟机Linux内核网络协议栈的工作了
5. Linux virtio-net中对内存的使用
5.1 scatterlist 实现分析
5.1.1 scatterlist 产生背景
scatterlist用于汇总分散的物理内存(以页为单位),并以数组的形式组织起来,典型的应用场景如下图所示,


在一个系统中,CPU、DMA和Device通过不同的方式使用内存,
① CPU通过MMU以虚拟地址(VA)访问内存
② DMA直接以物理地址(PA)访问内存
③ Device通过自己的IOMMU以设备地址(DA)访问内存
如果访问的内存虚拟地址连续但是物理地址不连续,CPU的访问没有问题,但是当需要将内存地址交给DMA进行传输时,只能以不连续的物理内存块的方式传递
而scatterlist就是用户汇总这些不连续的物理内存块的方式
5.1.2 scatterlist结构
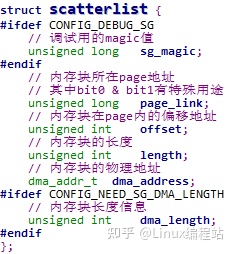
scatterlist以page为单位,描述了一个物理地址连续的内存块
说明1:如果要组织的连续物理内存超过一页怎么办 ?
要组织的连续物理内存超过一页是常态,所以单个scatterlist结构是没啥实际用途的。在实际使用中,Linux内核默认将scatterlist组织为数组使用
在virtio-net前端驱动中,收发队列中均包含了scatterlist数组

需要注意的是,这里scatterlist数组的大小与sk_buff中分片的个数是匹配的,这里增加的2个scatterlist分别用于存放sk_buff的线性数据部分和virtio-net的头部信息,可以参考下图理解

说明2:page_link中bit1的作用
page_link中的bit1是数组有效成员终止位,因为一次传输不一定使用scatterlist数组的所有成员,因此需要对最后一个有效的成员进行标记
下图中,一个scatterlist数组有6个成员,但是本次传输只使用其中3个

Linux内核代码中通过如下接口设置 & 检查该标志位
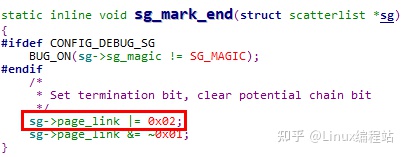

说明3:page_link中bit0的作用
page_link中的bit0是sacatterlist数组链接标志,用于实现将2个scatterlist数组链接起来。如果bit0置1,则该page_link指向的不是一个page结构,而是指向另一个scatterlist数组

Linux内核代码中通过如下接口设置 & 检查该标志位


可见如果需要链接2个scatterlist数组,前一个数组的最后一个成员不能指向有效page
看到这里,就更容易理解之前分析的virtqueue_add函数
5.1.3 scatterlist常用API
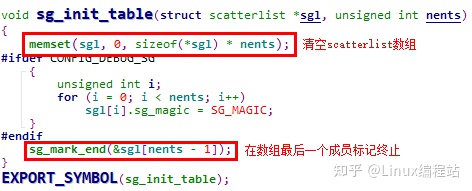
5.1.3.1 sg_init_table
5.1.3.2 sg_assign_page
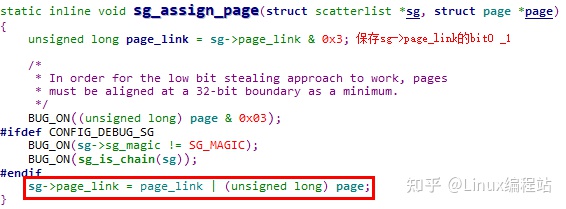
sg_assign_page函数将一个page与一个scatterlist关联起来
5.1.3.3 sg_set_page

sg_set_page在关联page的基础上,设置了内存块的偏移量与长度
5.1.3.4 sg_set_buf
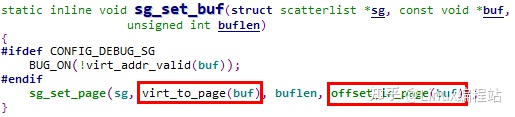
sg_set_buf函数是最常用的关联内存块与scatterlist的API,此处传入的buf参数为内存块起始的虚拟地址
5.1.3.5 sg_init_one

sg_init_one用于初始化一个scatterlist结构,并与一个内存块关联(该内存块必须在1个page内)
5.1.3.6 sg_page
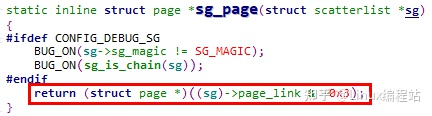
sg_page返回与scatterlist关联的物理页面地址
5.1.3.7 sg_next
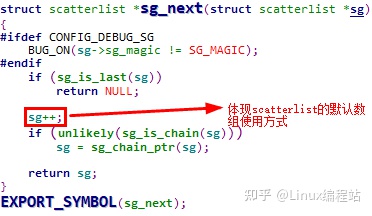
sg_next用于取出scatterlist数组中的下一个成员,如果达到终止成员,则返回NULL
5.2 virtio-net发送数据中的内存操作
5.2.1 将sk_buff关联到scatterlist数组

这里的核心是skb_to_sgvec函数,该函数用于将sk_buff中存储报文用的各个page关联到scatterlist数组,下面分析该函数

在__skb_to_sgvec函数中,将sk_buff的逐个分片都关联到scatterlist数组中

5.2.2 将scatterlist数组映射到vring描述符

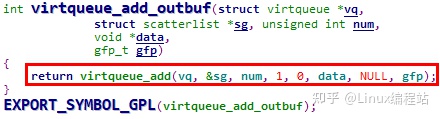
这里其实就回到了我们之前分析的virtqueue_add函数
5.3 virtio-net接收数据中的内存操作
备忘录:
topic 2:seL4中如何对接virtio-net
topic 3:virtio-net的上下游模块
topic 4:宿主机如何注册pci device,可以先分析qemu的实现思路
topic 5:SKB buffer的使用(这个属于网络相关知识点的补强)





![[附源码]计算机毕业设计JAVA小说网站的设计与实现1](https://img-blog.csdnimg.cn/d5b0a6b2160e46d88ccb73874113b208.png)