系统性能压力测试
一、压力测试
压力测试是给软件不断加压,强制其在极限的情况下运行,观察它可以运行到何种程度,从而发现性能缺陷,是通过搭建与实际环境相似的测试环境,通过测试程序在同一时间内或某一段时间内,向系统发送预期数量的交易请求、测试系统在不同压力情况下的效率状况,以及系统可以承受的压力情况。然后做针对性的测试与分析,找到影响系统性能的瓶颈,评估系统在实际使用环境下的效率情况,评价系统性能以及判断是否需要对应用系统进行优化处理或结构调整。并对系统资源进行优化。
在压力测试中我们会涉及到相关的一些性能指标:
- 响应时间(Response Time:RT):从客服端发送请求开始到获取到服务器的响应结果的总的时间
- HPS(Hits Per Second):每秒点击的次数
- TPS(Transaction Per Second):系统每秒处理的交易数,也叫会话次数
- QPS(Query Per Second):系统每秒处理查询的次数
在互联网企业中,如果一个业务有且仅有一个请求连接,那么TPS=QPS=HPS的,而在一般情况下用TPS来衡量整个业务流程,用QPS来衡量接口查询的次数,用HPS来衡量服务器单击请求。
我们在测试的时候就会通过这些指标(HPS,TPS,QPS)的数据来衡量系统的系统,指标越高说明系统性能越好,在一般情况下,各个行业的指标范围有着比较大的差异,下面简单的列举了下,仅供参考
- 金融行业:1000TPS~50000TPS
- 保险行业:100TPS~100000TPS
- 制造业:10TPS~5000TPS
- 互联网大型网站:10000TPS~1000000TPS
- 互联网其他:1000TPS~50000TPS
当然我们还会涉及到一些其他的名词,如下:
| 名词 | 说明 |
|---|---|
| 最大响应时间 | 用户发出请求到系统做出响应的最大时间 |
| 最少响应时间 | 用户发出请求到系统做出响应的最少时间 |
| 90%响应时间 | 指所有用户的响应时间进行排序,第90%的响应时间 |
当我们从外部来看,性能测试主要要关注这三个性能指标
| 指标 | 说明 |
|---|---|
| 吞吐量 | 每秒钟系统能够处理的请求数,任务数 |
| 响应时间 | 服务处理一个请求或一个任务的耗时 |
| 错误率 | 一批请求中结果出错的请求所占的比例 |
二、JMeter
1.安装JMeter
官网地址:https://jmeter.apache.org/download_jmeter.cgi 下载后解压即可,然后进入到bin目录下双击 JMeter.bat文件即可启动

该工具支持中文

中文后的页面

2.JMeter基本操作
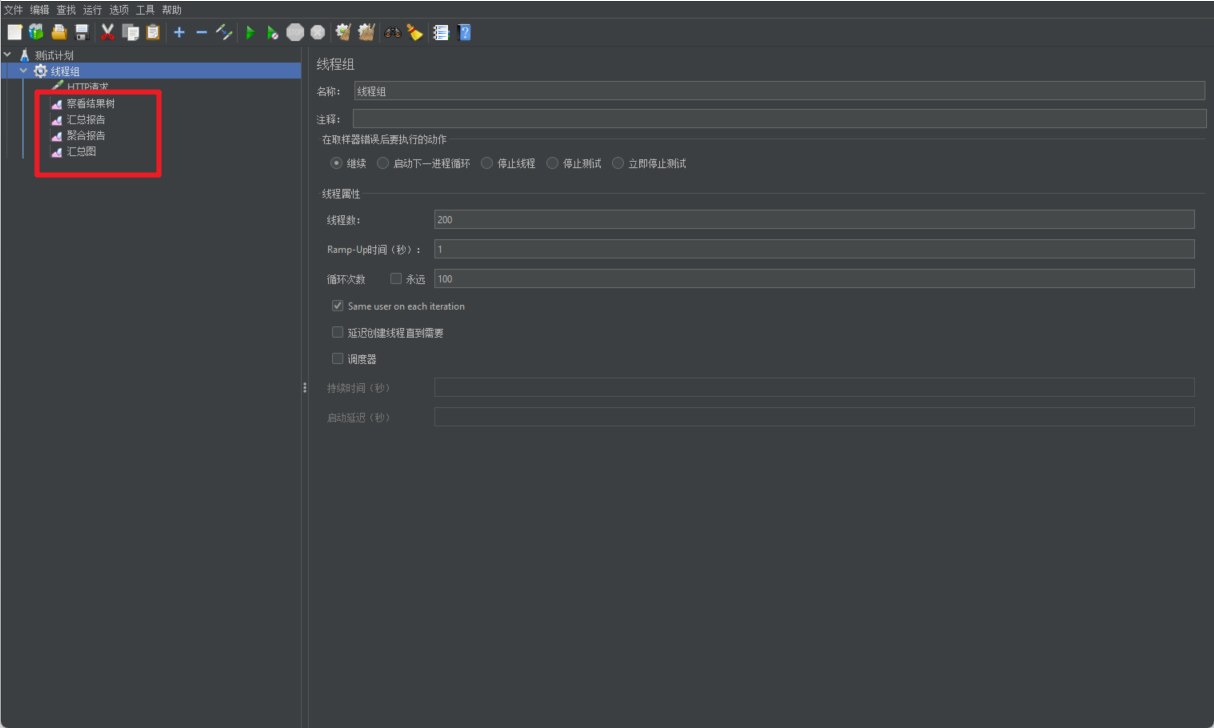
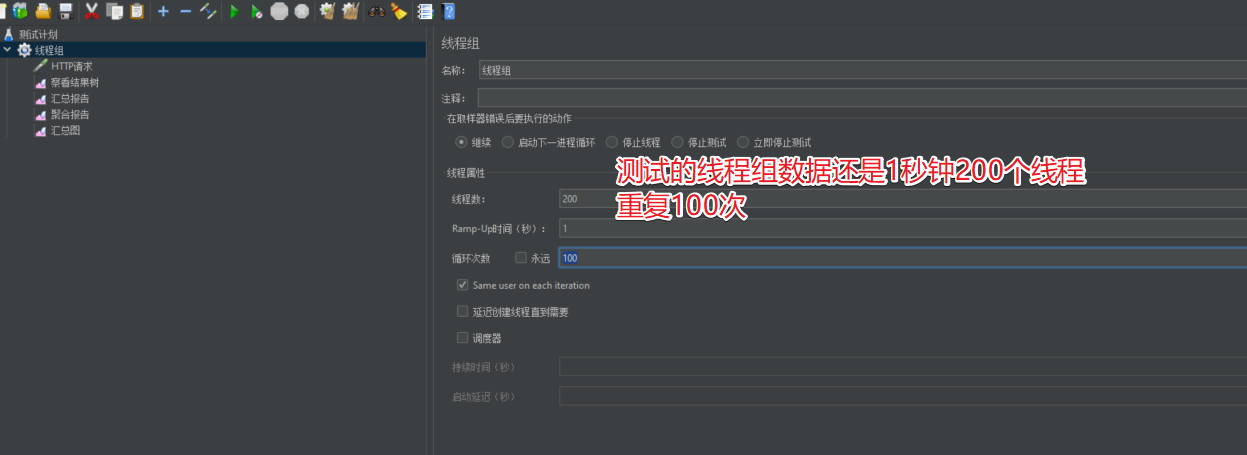
2.1 添加线程组
线程组的作用就是定义任务的相关属性,比如每秒执行多少线程,重复多少次该操作

2.2 取样器
在定义了线程组后,我们得继续定义每个线程的操作行为,也就是创建对应的取样器,在取样器中我们定义要访问的服务的协议及地址信息。

然后我们需要在取样器中定义服务的信息

2.3 监视器
在取样器中我们定义了要访问的服务信息,然后我们就要考虑请求后我们需要获取任务的相关的指标信息。这时就用到了监视器。

对应的结果数据有 查看结果树 汇总报告 聚合报告 ,查看结果对应的图形 汇总图 …
2.4 测试百度
写好了取样器后,启动测试。

启动后我们就可以查询测试的结果数据




2.5 测试商城首页
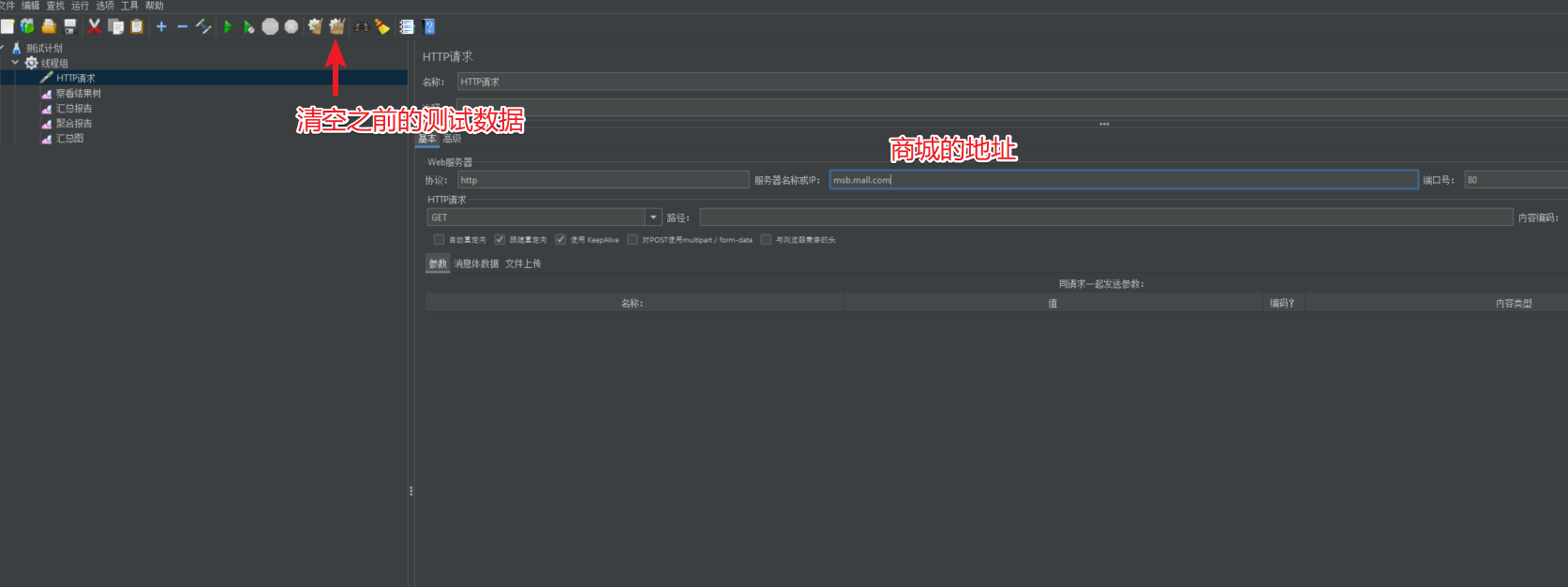
启动后查看对应的结果




2.6 JMeter Address 占用的问题

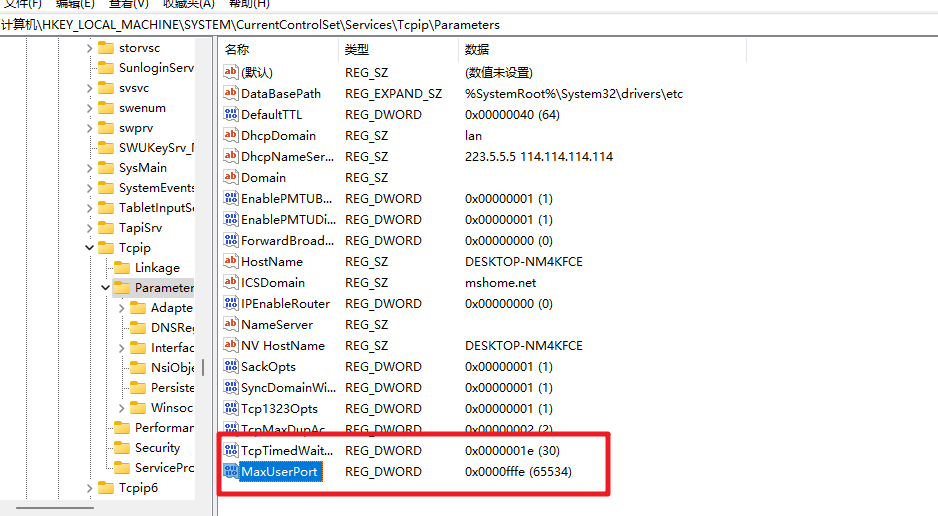
搜索之后发现需要在regedit中添加注册表项MaxUserPort,TcpTimedWaitDelay重启一下就可以解决了。
解决方法:
打开注册表:ctrl+r 输入regedit
进入注册表,路径为:\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters
新建DWORD值,(十进制)设置为30秒。名称:TcpTimedWaitDe,值:30
新建DWORD值,(十进制)最大连接数65534。名称:MaxUserPort,值:65534
修改完成后重启生效
三、性能优化
1.考虑影响服务性能的因素
数据库、应用程序,中间件(Tomcat,Nginx),网络和操作系统等
我们还得考虑当前的服务属于
- CPU密集型:计算比较影响性能—>添加CPU,加机器
- IO密集型:网络IO,磁盘IO,数据库读写IO,Redis读写IO --》缓存,加固态硬盘,添加网卡
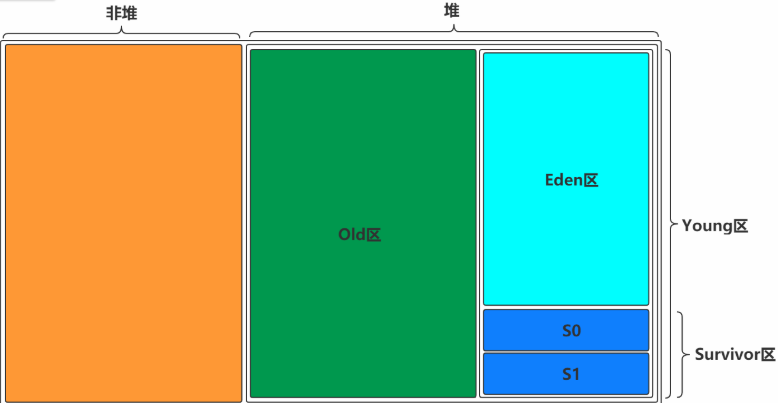
2.JVM回顾
JVM的内存结构

JVM中对象的存储和GC

3.jconsole和jvisualvm
jconsole和jvisualvm是JDK自带监控工具。可以帮助我们更好的查看服务的相关监控信息,jvisualvm功能会更加的强大些。
3.1 jconsole


找到对应的进程

3.2 jvisualvm
因为是jdk6.0后自带的,我们同样的可以在cmd或者搜索框中找到

打开的主页面

找到对应的进程,双击进入

查看对应的监视信息

添加插件。如果插件不可用,那么需要更新

https://visualvm.github.io/pluginscenters.html 需要结合你的jdk的版本来选择对应的插件的版本

安装好之后重启jvisualvm即可
%
4. 中间件的性能
以下是一个完整的请求链路

然后我们来测试下相关的组件的性能
| 压力测试内容 | 压力测试的线程数 | 吞吐量/s | 90%响应时间 | 99%响应时间 |
|---|---|---|---|---|
| Nginx | 50 | 7,385 | 10 | 70 |
| Gateway | 50 | 23,170 | 3 | 14 |
| 单独测试服务 | 50 | 23,160 | 3 | 7 |
| Gateway+服务 | 50 | 8,461 | 12 | 46 |
| Nginx+Gateway | 50 | |||
| Nginx+Gateway+服务 | 50 | 2,816 | 27 | 42 |
| 一级菜单 | 50 | 1,321 | 48 | 74 |
| 三级分类压测 | 50 | 12 | 4000 | 4000 |
| 首页全量数据 | 50 | 2 |

中间件越多,性能损失就越大,大多数的损失都是在数据的交互
简单的优化:
中间件:单个的效率都很高,串联的中间件越多,影响越大,但是在业务面前其实就比较微弱
业务:
- DB(MySQL,优化)
- 模板页面渲染
| 压力测试内容 | 压力测试的线程数 | 吞吐量/s | 90%响应时间 | 99%响应时间 |
|---|---|---|---|---|
| Nginx | 50 | 7,385 | 10 | 70 |
| Gateway | 50 | 23,170 | 3 | 14 |
| 单独测试服务 | 50 | 23,160 | 3 | 7 |
| Gateway+服务 | 50 | 8,461 | 12 | 46 |
| Nginx+Gateway | 50 | |||
| Nginx+Gateway+服务 | 50 | 2,816 | 27 | 42 |
| 一级菜单 | 50 | 1,321 | 48 | 74 |
| 三级分类压测 | 50 | 12 | 4000 | 4000 |
| 首页全量数据(DB-Themleaf) | 50 | 2 | ||
| 一级菜单(DB-索引) | 50 | 1900 | 40 | 70 |
| 三级分类压测(索引) | 50 | 34 | 1599 | 1700 |
| 首页全量数据(DB-Themleaf-放开缓存) | 50 | 30 | 。。。 | 。。。 |
5.Nginx实现动静分离
通过上面的压力测试我们可以发现如果后端服务及处理动态请求又处理静态请求那么他的吞吐量是非常有限的,这时我们可以把静态资源存储在Nginx中。

5.1 静态资源存储
把服务中的静态资源上传到Nginx服务中,把静态资源文件打成一个zip包,然后拖拽到Linux中,然后我们通过
unzip index.zip
来解压缩

然后替换掉模板文件中的资源访问路径

5.2 Nginx配置
然后我们在Nginx的配置文件中指定static开头的请求的处理方式

保存后重启Nginx服务,然后就可以访问了

6.三级分类优化
我们在获取三级分类的数据的时候,会频繁的操作数据库,我们可以对这段代码来优化

在此处我们可以一次查询出所有的分类数据,然后每次从这个一份数据中获取对应的信息,达到减少数据库操作的次数的目的,从而提升服务的性能。
/**
* 跟进父编号获取对应的子菜单信息
* @param list
* @param parentCid
* @return
*/
private List<CategoryEntity> queryByParenCid(List<CategoryEntity> list,Long parentCid){
List<CategoryEntity> collect = list.stream().filter(item -> {
return item.getParentCid().equals(parentCid);
}).collect(Collectors.toList());
return collect;
}
/**
* 查询出所有的二级和三级分类的数据
* 并封装为Map<String, Catalog2VO>对象
* @return
*/
@Override
public Map<String, List<Catalog2VO>> getCatelog2JSON() {
// 获取所有的分类数据
List<CategoryEntity> list = baseMapper.selectList(new QueryWrapper<CategoryEntity>());
// 获取所有的一级分类的数据
List<CategoryEntity> leve1Category = this.queryByParenCid(list,0l);
// 把一级分类的数据转换为Map容器 key就是一级分类的编号, value就是一级分类对应的二级分类的数据
Map<String, List<Catalog2VO>> map = leve1Category.stream().collect(Collectors.toMap(
key -> key.getCatId().toString()
, value -> {
// 根据一级分类的编号,查询出对应的二级分类的数据
List<CategoryEntity> l2Catalogs = this.queryByParenCid(list,value.getCatId());
List<Catalog2VO> Catalog2VOs =null;
if(l2Catalogs != null){
Catalog2VOs = l2Catalogs.stream().map(l2 -> {
// 需要把查询出来的二级分类的数据填充到对应的Catelog2VO中
Catalog2VO catalog2VO = new Catalog2VO(l2.getParentCid().toString(), null, l2.getCatId().toString(), l2.getName());
// 根据二级分类的数据找到对应的三级分类的信息
List<CategoryEntity> l3Catelogs = this.queryByParenCid(list,l2.getCatId());
if(l3Catelogs != null){
// 获取到的二级分类对应的三级分类的数据
List<Catalog2VO.Catalog3VO> catalog3VOS = l3Catelogs.stream().map(l3 -> {
Catalog2VO.Catalog3VO catalog3VO = new Catalog2VO.Catalog3VO(l3.getParentCid().toString(), l3.getCatId().toString(), l3.getName());
return catalog3VO;
}).collect(Collectors.toList());
// 三级分类关联二级分类
catalog2VO.setCatalog3List(catalog3VOS);
}
return catalog2VO;
}).collect(Collectors.toList());
}
return Catalog2VOs;
}
));
return map;
}
优化后的压测表现
| 压力测试内容 | 压力测试的线程数 | 吞吐量/s | 90%响应时间 | 99%响应时间 |
|---|---|---|---|---|
| Nginx | 50 | 7,385 | 10 | 70 |
| Gateway | 50 | 23,170 | 3 | 14 |
| 单独测试服务 | 50 | 23,160 | 3 | 7 |
| Gateway+服务 | 50 | 8,461 | 12 | 46 |
| Nginx+Gateway | 50 | |||
| Nginx+Gateway+服务 | 50 | 2,816 | 27 | 42 |
| 一级菜单 | 50 | 1,321 | 48 | 74 |
| 三级分类压测 | 50 | 12 | 4000 | 4000 |
| 三级分类压测(业务优化后) | 50 | 448 | 113 | 227 |
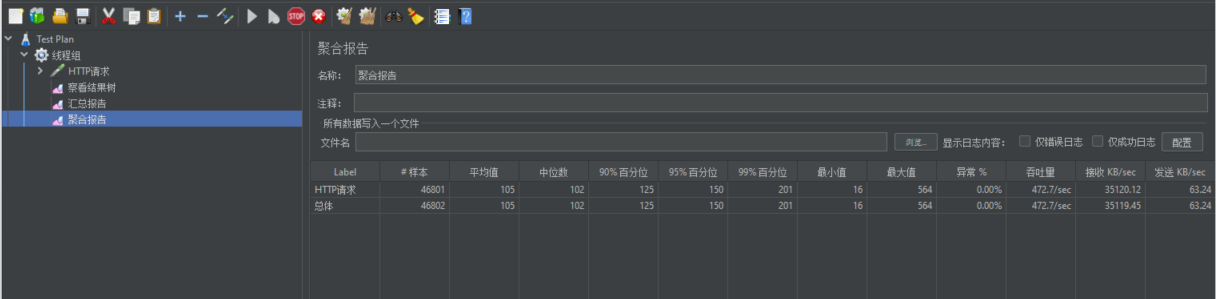
可以看到系统性能的提升还是非常明显的。