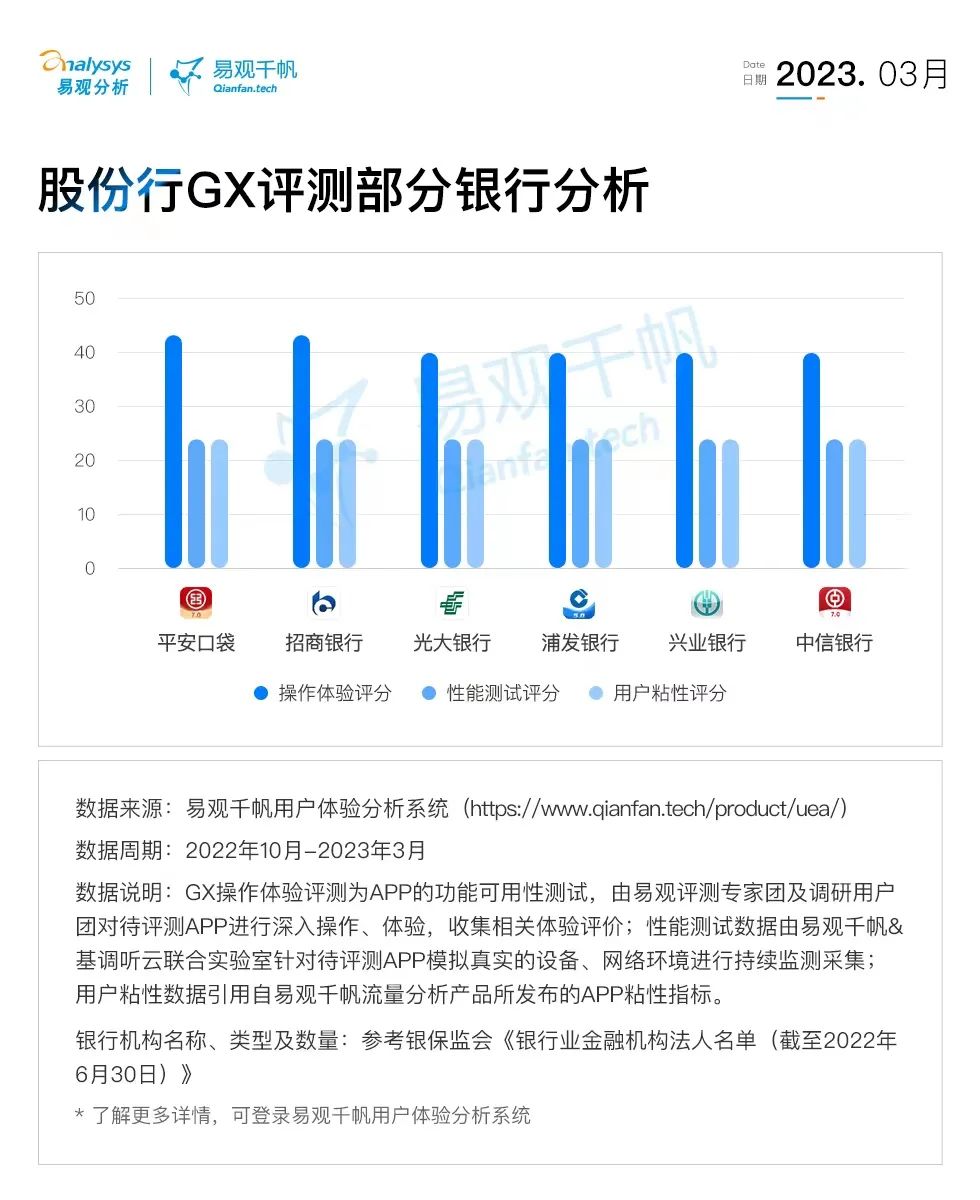
卷积神经网络
传统意义上的多层神经网络只有输入层、隐藏层和输出层。其中隐藏层的层数根据需要而定,没有明确的理论推导来说明到底多少层合适。
卷积神经网络CNN,在原来多层神经网络的基础上,加入了更加有效的特征学习部分,具体操作就是在原来的全连接层前面加入了卷积层和池化层。卷积神经网络的出现,使得神经网络层数得以加深,“深度”学习由此而来。
卷积神经网络的结构
神经网络的基本组成包括输入层、隐藏层和输出层,而卷积神经网络的特点在于隐藏层分为卷积层和池化层(pooling layer,又叫下采样层)以及激活层。
- 卷积层:通过在原始图像上平移来提取特征
- 激活层:增加非线性分割能力
- 池化层:减少学习的参数,降低网络的复杂度(最大池化和平均池化)
为了能够达到分类效果,还会有一个全连接层(Full Connection)也就是最后的输出层,进行损失计算并输出分类结果。

卷积层(Convolutional Layer)
卷积神经网络中每层卷积层由若干卷积单元(卷积核)组成,每个卷积单元的参数都是通过反向传播算法最佳化得到的。
卷积运算的目的是特征提取,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。
卷积核(Filter也可以叫过滤器)的四大要素
- 卷积核大小
- 卷积核步长
- 卷积核个数
- 卷积核零填充大小
通道数为1时一般叫 卷积核,通道数大于1时一般叫 滤波器 。
卷积核的计算
卷积核我们可以理解为一个观察的人,带着若干权重和一个偏置去观察,进行特征加权运算。

注:卷积核的常用大小为1*1、3*3、5*5。
我们需要平移去观察图片,需要的参数就是步长。
假设移动的步长为一个像素,那么最终这个人观察的结果以下图为例:

如果移动步长为2,那么结果如下:

如果在某一层结构中,不止是一个人在观察,而是多个人(卷积核)一起去观察,那么就会得到多张观察结果。
- 不同的卷积核带的权重和偏置都不一样,即随机初始化的参数
除此之外,输出结果的大小除了由大小和步长决定,还有零填充。因为Fliter观察窗口的大小和移动步长有时会导致超过图片像素宽度。
零填充就是在图片像素外围填充值为0的像素,填充几圈根据实际而定。

卷积核的计算代码示例:
import torch
import torch.nn.functional as F
# Input表示输入的图像颜色值
Input = torch.tensor([[23, 12, 220, 43, 2],
[45, 57, 25, 122, 91],
[189, 15, 149, 222, 76],
[12, 35, 57, 29, 20],
[4, 34, 65, 8, 18]])
# kernel表示卷积核
kernel = torch.tensor([[2.1, 0.7, 1.0],
[1.3, 1.2, 3.0],
[2.8, 0.3, 0.9]])
# 要转换成conv卷积接受的参数的维度形式,batch_size可以看作是一次训练有几张图片,这里一个矩阵故为1,而这里是灰度图片故channel也为1
Input = torch.reshape(Input, (1, 1, 5, 5)).float() # 默认是long要转成float,变成batch_size=1,channel=1,高H=5,宽W=5
kernel = torch.reshape(kernel, (1, 1, 3, 3)).float()
output = F.conv2d(Input, kernel, stride=1) # conv2d表示二维卷积(图像就是二维矩阵),stride=1表示步长为1
print(output)
output2 = F.conv2d(Input, kernel, stride=2) # 表示步长为2(默认是为1)
print(output2)
output3 = F.conv2d(Input, kernel, stride=1, padding=1) # 表示步长为1且零填充了一圈(padding默认为0)
print(output3)
神经网络代码示例:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 下载CIFAR10数据集中的测试集(因为训练集太大了),转化为tensor格式存在同路径的pytorch_data文件下
dataset = torchvision.datasets.CIFAR10("pytorch_data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64) # 设置一组图片的数量为64
class Mynn(nn.Module):
def __init__(self): # 构造函数
super(Mynn, self).__init__() # 调用父类构造函数进行初始化
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x): # 前向传播
x = self.conv1(x)
return x
mynn = Mynn()
writer = SummaryWriter("logs") # 将训练的中间过程的结果可视化(存在文件logs)
step = 0
for data in dataloader:
imgs, targets = data
output = mynn(imgs)
# print(imgs.shape)
# print(output.shape)
# torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# torch.Size([64, 6, 30, 30]) -> [xxx, 3, 30, 30]
output = torch.reshape(output, (-1, 3, 30, 30)) # batch_size根据后面channel、H、W的值推出,故这里的-1是占位符
writer.add_images("output", output, step)
step = step + 1
writer.close()
在该目录终端输入tensorboard --logdir=logs(这里文件名是logs所以写=logs),然后打开http://localhost:6006/ 即可查看可视化。
这里torchboard为了加速,默认会只显示部分组(step)的图片结果,可以通过改写为tensorboard --logdir=logs --samples_per_plugin=images=1000以显示所有的图片,1000表示的是显示的图片数,写大点比较好。

打开后即可看到经卷积conv处理后的结果:(可以看到图片是8*8=64一组的)

输出大小的计算公式

注:D为通道数,比如D1, 如果图片是彩色的,即RGB类型,这时候通道数固定为3,如果是灰色的,通道数为1。
多通道图片的观察
如果是一张彩色图片,那么就有三种表为R,G,B,原本每个人需要带一个3*3或者其他大小的卷积核,现在需要带3张3*3的权重和一个偏置,总共就27个权重。最终每个人还是得出一张结果。
通道 channel
通道数可以理解为深度或者层数
比如 彩色图像的由三层图像叠加产生
下图滤波器(3 * 3 * 3)的层数也为3 (宽 * 高 * 通道数)

滤波器的个数 = 特征图的个数(特征图数即输出的图像数也即输出的通道数out_channel)
经过卷积后生成的图叫做特征图 (提取原图片的特征),一个滤波器可以产生一张特征图。
激活函数
随着神经网络的发展,大家发现原有的sigmoid等激活函数并不能达到好的效果,所以采取新的激活函数。
Relu


Relu优点
- 有效解决梯度消失的问题。
- 计算速度非常快,SGD(批梯度下降)的求解速度远快于sigmoid和tanh。
sigmoid缺点
- 计算量较大,且在反向传播时容易出现梯度消失的情况。
激活函数示例代码:
import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("pytorch_data", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Mynn(nn.Module):
def __init__(self):
super(Mynn, self).__init__()
# self.relu1 = ReLU()
self.sigmoid1 = Sigmoid() # 因为这个数据集的数都是非负的relu没用,所以就用sigmoid示例了
def forward(self, input):
output = self.sigmoid1(input)
return output
mynn = Mynn()
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, global_step=step)
output = mynn(imgs)
writer.add_images("output", output, step)
step += 1
writer.close()
池化层(Polling)

注:比如右边粉色的四个小格(即四个像素点)有像素1、1、5、6,那么取最大值为6。
最大池化示例代码:
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./pytorch_data", train=False, download=True,
transform=torchvision.transforms.ToTensor()) # ./也表示同级目录
dataloader = DataLoader(dataset, batch_size=64)
class Mynn(nn.Module):
def __init__(self):
super(Mynn, self).__init__()
# 默认的步长就是卷积核大小,比如这里的默认步长就是3,ceil_mode表示移动窗口超出图片外的时侯是否对图片内窗口包含的矩阵取最大值,默认为false
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, input):
output = self.maxpool1(input)
return output
mynn = Mynn()
writer = SummaryWriter("./logs")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = mynn(imgs)
writer.add_images("output", output, step)
step = step + 1
writer.close()
可以看到经过池化后,图片变模糊了,类似的比如把视频从1080p到720p减小占用空间大小。

全连接层(Full Connection)
前面的卷积和池化相当于特征工程,最后的全连接层在整个神经网络中起到“分类器”的作用。
模型的参数调优
优化器示例代码:
import torch
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("pytorch_data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Mynn(nn.Module):
def __init__(self):
super(Mynn, self).__init__()
self.model1 = Sequential( # 将一系列网络层放在Sequential序列里,代码更简洁
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(), # 将数据展平成一行
Linear(1024, 64), # 线性层
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
mynn = Mynn()
optim = torch.optim.SGD(mynn.parameters(), lr=0.01) # SGD为随机梯度下降,lr为学习率
for epoch in range(20): # 表示20次训练
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = mynn(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad() # 将优化器梯度清零
result_loss.backward() # 反向传播,通过损失去调参数的权重以达到更小的损失
optim.step() # 将优化器的参数调优
running_loss = running_loss + result_loss
print(running_loss) # 每轮训练后的总损失
现有网络模型的使用及修改
vgg16分类模型的代码示例:
import torchvision
from torch import nn
from torchvision.models import VGG16_Weights
vgg16_false = torchvision.models.vgg16(weights=None) # vgg16是分类模型,weights是权重参数
vgg16_true = torchvision.models.vgg16(weights=VGG16_Weights.DEFAULT) # 表示是已经经过预训练的模型(DEFAULT表示使用默认的权重参数),表现的会比较好点
print(vgg16_true)
train_data = torchvision.datasets.CIFAR10('pytorch_data', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10)) # 表示在classifier里添加一个线性层
print(vgg16_true)
print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096, 10) # 表示将classifier里编号6这个层修改成nn.Linear(4096, 10)
print(vgg16_false)
注:比如写nn.Linear(1000, 10)类似这样模型的参数时可以将光标放到圆括号里,然后按Ctrl+p可以查看参数提示。
网络模型的保存与加载
保存:
import torch
import torchvision
from torch import nn
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式1,模型结构+模型参数
torch.save(vgg16, "vgg16_method1.pth") # vgg16_method1.pth为保存的文件名,后缀一般为pth
# 保存方式2,模型参数(官方推荐)
torch.save(vgg16.state_dict(), "vgg16_method2.pth") # state_dict()表示的就是将状态(参数)用字典的形式保存起来加载:
import torch
import torchvision
# 方式1:保存方式1,加载模型
model = torch.load("vgg16_method1.pth")
# print(model)
# 方式2:加载模型
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
# model = torch.load("vgg16_method2.pth")
# print(vgg16)
注:如果是加载自己写的保存下来的模型,记得要import写该模型网络结构的.py文件,比如该.py文件叫model.py则from model import *。
采用GPU训练模型
方法一:在网络模型、数据和损失函数后加上.cuda()即可。
mynn = Mynn()
mynn=mynn.cuda()
imgs, targets = data
imgs=imgs.cuda()
targets=targets.cuda()
loss = nn.CrossEntropyLoss()
loss=loss.cuda()方法二:
# 定义训练的设备
device = torch.device("cuda")
mynn = Mynn()
mynn = Mynn.to(device)
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)模型的应用
model.py
import torch
from torch import nn
# 搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
if __name__ == '__main__':
tudui = Tudui()
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)train.py
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch import nn
from torch.utils.data import DataLoader
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
tudui = Tudui()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs_train")
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i + 1))
# 训练步骤开始
tudui.train()
for data in train_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum() # argmax(1)表示获取横向的最大值,0则竖向
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()test.py
import torch
import torchvision
from PIL import Image
from torch import nn
image_path = "../imgs/airplane.png" # 这里是看能否预测出这个飞机的图片是不是属于飞机这个类别
image = Image.open(image_path)
print(image)
image = image.convert('RGB') # 有时候的图片可能是四个通道的,多了透明层,为了保险保留RGB的三个层(通道)即可
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
model = torch.load("tudui_29_gpu.pth", map_location=torch.device('cpu')) # gpu训练出的模型在cpu运行要加map_location
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))