一、概述
invokeBeanFactoryPostProcessors的执行顺序大致如下,先执行子类BeanDefinitionRegistryPostProcessor再执行父类BeanFactoryPostProcessor。而对于同一个类的执行顺序是先执行外部的集合再到子集,之后再到父集。更小维度执行的顺序按照order注解进行执行。
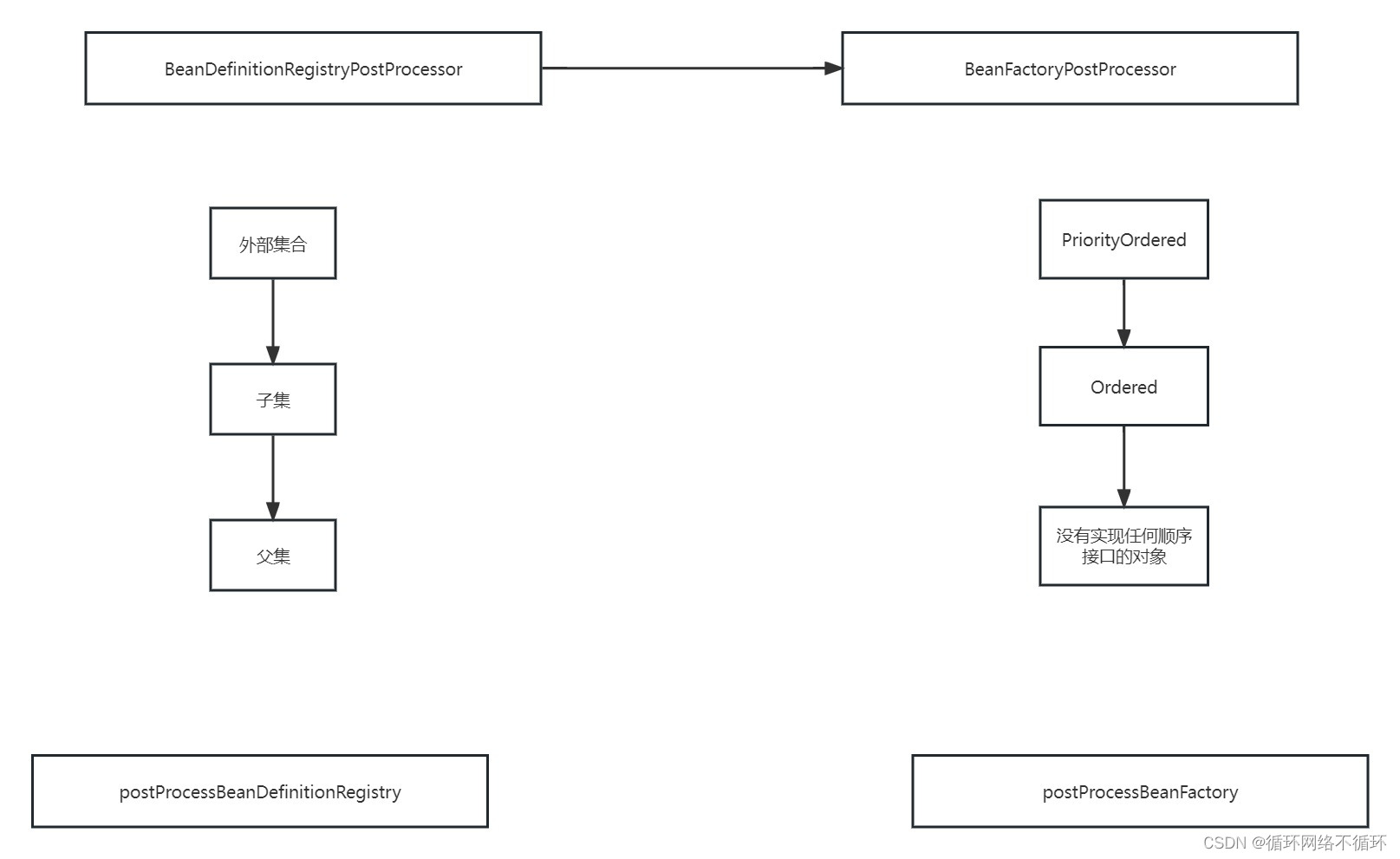
二、重要方法
(一)invokeBeanFactoryPostProcessors
1、代码解读
public static void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {
// 无论是什么情况,优先执行BeanDefinitionRegistryPostProcessors
// 将已经执行过的BFPP存储在processedBeans中,防止重复执行
Set<String> processedBeans = new HashSet<>();
if (beanFactory instanceof BeanDefinitionRegistry) {
// 判断beanfactory是否是BeanDefinitionRegistry类型,此处是DefaultListableBeanFactory,实现了BeanDefinitionRegistry接口,所以为true
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
// 此处希望大家做一个区分,两个接口是不同的,BeanDefinitionRegistryPostProcessor是BeanFactoryPostProcessor的子集
// BeanFactoryPostProcessor主要针对的操作对象是BeanFactory,而BeanDefinitionRegistryPostProcessor主要针对的操作对象是BeanDefinition
// 存放BeanFactoryPostProcessor的集合
List<BeanFactoryPostProcessor> regularPostProcessors = new ArrayList<>();
// 存放BeanDefinitionRegistryPostProcessor的集合
List<BeanDefinitionRegistryPostProcessor> registryProcessors = new ArrayList<>();
// 首先处理入参中的beanFactoryPostProcessors,遍历所有的beanFactoryPostProcessors,将BeanDefinitionRegistryPostProcessor
// 和BeanFactoryPostProcessor区分开
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
// 如果是BeanDefinitionRegistryPostProcessor
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
BeanDefinitionRegistryPostProcessor registryProcessor =
(BeanDefinitionRegistryPostProcessor) postProcessor;
// 直接执行BeanDefinitionRegistryPostProcessor接口中的 postProcessBeanDefinitionRegistry方法
registryProcessor.postProcessBeanDefinitionRegistry(registry);
// 添加到registryProcessors,用于后续执行postProcessBeanFactory方法
registryProcessors.add(registryProcessor);
}
else {
// 否则,只是普通的BeanFactoryPostProcessor,添加到regularPostProcessors,用于后续执行postProcessBeanFactory方法
regularPostProcessors.add(postProcessor);
}
}
// 用于保存本次要执行的BeanDefinitionRegistryPostProcessor
List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>();
// 调用所有实现PriorityOrdered接口的BeanDefinitionRegistryPostProcessor实现类
// 找到所有实现BeanDefinitionRegistryPostProcessor接口bean的beanName
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
// 遍历处理所有符合规则的postProcessorNames
for (String ppName : postProcessorNames) {
// 检测是否实现了PriorityOrdered接口
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
// 获取名字对应的bean实例,添加到currentRegistryProcessors中
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
// 将要被执行的BFPP名称添加到processedBeans,避免后续重复执行
processedBeans.add(ppName);
}
}
// 按照优先级进行排序操作
sortPostProcessors(currentRegistryProcessors, beanFactory);
// 添加到registryProcessors中,用于最后执行postProcessBeanFactory方法
registryProcessors.addAll(currentRegistryProcessors);
// 遍历currentRegistryProcessors,执行postProcessBeanDefinitionRegistry方法
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry, beanFactory.getApplicationStartup());
// 执行完毕之后,清空currentRegistryProcessors
currentRegistryProcessors.clear();
// 调用所有实现Ordered接口的BeanDefinitionRegistryPostProcessor实现类
// 找到所有实现BeanDefinitionRegistryPostProcessor接口bean的beanName,
// 此处需要重复查找的原因在于上面的执行过程中可能会新增其他的BeanDefinitionRegistryPostProcessor
postProcessorNames =
// 检测是否实现了Ordered接口,并且还未执行过
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {
// 获取名字对应的bean实例,添加到currentRegistryProcessors中
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
// 将要被执行的BFPP名称添加到processedBeans,避免后续重复执行
processedBeans.add(ppName);
}
}
// 按照优先级进行排序操作
sortPostProcessors(currentRegistryProcessors, beanFactory);
// 添加到registryProcessors中,用于最后执行postProcessBeanFactory方法
registryProcessors.addAll(currentRegistryProcessors);
// 遍历currentRegistryProcessors,执行postProcessBeanDefinitionRegistry方法
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry, beanFactory.getApplicationStartup());
// 执行完毕之后,清空currentRegistryProcessors
currentRegistryProcessors.clear();
// 最后,调用所有剩下的BeanDefinitionRegistryPostProcessors
boolean reiterate = true;
while (reiterate) {
reiterate = false;
// 找出所有实现BeanDefinitionRegistryPostProcessor接口的类
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
// 遍历执行
for (String ppName : postProcessorNames) {
// 跳过已经执行过的BeanDefinitionRegistryPostProcessor
if (!processedBeans.contains(ppName)) {
// 获取名字对应的bean实例,添加到currentRegistryProcessors中
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
// 将要被执行的BFPP名称添加到processedBeans,避免后续重复执行
processedBeans.add(ppName);
reiterate = true;
}
}
// 按照优先级进行排序操作
sortPostProcessors(currentRegistryProcessors, beanFactory);
// 添加到registryProcessors中,用于最后执行postProcessBeanFactory方法
registryProcessors.addAll(currentRegistryProcessors);
// 遍历currentRegistryProcessors,执行postProcessBeanDefinitionRegistry方法
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry, beanFactory.getApplicationStartup());
// 执行完毕之后,清空currentRegistryProcessors
currentRegistryProcessors.clear();
}
// 调用所有BeanDefinitionRegistryPostProcessor的postProcessBeanFactory方法
invokeBeanFactoryPostProcessors(registryProcessors, beanFactory);
// 最后,调用入参beanFactoryPostProcessors中的普通BeanFactoryPostProcessor的postProcessBeanFactory方法
invokeBeanFactoryPostProcessors(regularPostProcessors, beanFactory);
}
else {
// 如果beanFactory不归属于BeanDefinitionRegistry类型,那么直接执行postProcessBeanFactory方法
invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory);
}
// 到这里为止,入参beanFactoryPostProcessors和容器中的所有BeanDefinitionRegistryPostProcessor已经全部处理完毕,下面开始处理容器中
// 所有的BeanFactoryPostProcessor
// 可能会包含一些实现类,只实现了BeanFactoryPostProcessor,并没有实现BeanDefinitionRegistryPostProcessor接口
// 找到所有实现BeanFactoryPostProcessor接口的类
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);
// 用于存放实现了PriorityOrdered接口的BeanFactoryPostProcessor
List<BeanFactoryPostProcessor> priorityOrderedPostProcessors = new ArrayList<>();
// 用于存放实现了Ordered接口的BeanFactoryPostProcessor的beanName
List<String> orderedPostProcessorNames = new ArrayList<>();
// 用于存放普通BeanFactoryPostProcessor的beanName
List<String> nonOrderedPostProcessorNames = new ArrayList<>();
// 遍历postProcessorNames,将BeanFactoryPostProcessor按实现PriorityOrdered、实现Ordered接口、普通三种区分开
for (String ppName : postProcessorNames) {
// 跳过已经执行过的BeanFactoryPostProcessor
if (processedBeans.contains(ppName)) {
// skip - already processed in first phase above
}
// 添加实现了PriorityOrdered接口的BeanFactoryPostProcessor到priorityOrderedPostProcessors
else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class));
}
// 添加实现了Ordered接口的BeanFactoryPostProcessor的beanName到orderedPostProcessorNames
else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
orderedPostProcessorNames.add(ppName);
}
else {
// 添加剩下的普通BeanFactoryPostProcessor的beanName到nonOrderedPostProcessorNames
nonOrderedPostProcessorNames.add(ppName);
}
}
// 对实现了PriorityOrdered接口的BeanFactoryPostProcessor进行排序
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
// 遍历实现了PriorityOrdered接口的BeanFactoryPostProcessor,执行postProcessBeanFactory方法
invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors, beanFactory);
// 创建存放实现了Ordered接口的BeanFactoryPostProcessor集合
List<BeanFactoryPostProcessor> orderedPostProcessors = new ArrayList<>(orderedPostProcessorNames.size());
// 遍历存放实现了Ordered接口的BeanFactoryPostProcessor名字的集合
for (String postProcessorName : orderedPostProcessorNames) {
// 将实现了Ordered接口的BeanFactoryPostProcessor添加到集合中
orderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
// 对实现了Ordered接口的BeanFactoryPostProcessor进行排序操作
sortPostProcessors(orderedPostProcessors, beanFactory);
// 遍历实现了Ordered接口的BeanFactoryPostProcessor,执行postProcessBeanFactory方法
invokeBeanFactoryPostProcessors(orderedPostProcessors, beanFactory);
// 最后,创建存放普通的BeanFactoryPostProcessor的集合
List<BeanFactoryPostProcessor> nonOrderedPostProcessors = new ArrayList<>(nonOrderedPostProcessorNames.size());
// 遍历存放实现了普通BeanFactoryPostProcessor名字的集合
for (String postProcessorName : nonOrderedPostProcessorNames) {
nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
// 遍历普通的BeanFactoryPostProcessor,执行postProcessBeanFactory方法
invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory);
// 清除元数据缓存(mergeBeanDefinitions、allBeanNamesByType、singletonBeanNameByType)
// 因为后置处理器可能已经修改了原始元数据,例如,替换值中的占位符
beanFactory.clearMetadataCache();
}
2、疑惑点
在BeanDefinitionRegistryPostProcessor的时候我们写了大量的重复代码并执行了几次。这是为什么呢?因为在执行postProcessBeanDefinitionRegistry方法时我们有可能会在放入BeanDefinitionRegistryPostProcessor所以下面要再执行一下,以免遗漏。

下面我就演示一下执行postProcessBeanDefinitionRegistry方法时放入BeanDefinitionRegistryPostProcessor的代码。
代码:
public class MyBeanDefinitionRegistryPostProcessor implements BeanDefinitionRegistryPostProcessor, PriorityOrdered {
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException {
System.out.println("执行postProcessBeanDefinitionRegistry---MyBeanDefinitionRegistryPostProcessor");
BeanDefinitionBuilder builder = BeanDefinitionBuilder.rootBeanDefinition(MySelfBeanDefinitionRegistryPostProcessor.class);
builder.addPropertyValue("name","zhangsan");
registry.registerBeanDefinition("msb",builder.getBeanDefinition());
}
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
System.out.println("执行postProcessBeanFactory---MyBeanDefinitionRegistryPostProcessor");
BeanDefinition msb = beanFactory.getBeanDefinition("msb");
msb.getPropertyValues().getPropertyValue("name").setConvertedValue("lisi");
System.out.println("===============");
}
@Override
public int getOrder() {
return 0;
}
}配置:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:msb="http://www.mashibing.com/schema/user"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.mashibing.com/schema/user http://www.mashibing.com/schema/user.xsd">
</context:property-placeholder>-->
<bean class="com.mashibing.selfbdrpp.MyBeanDefinitionRegistryPostProcessor"></bean>
</beans>执行结果:
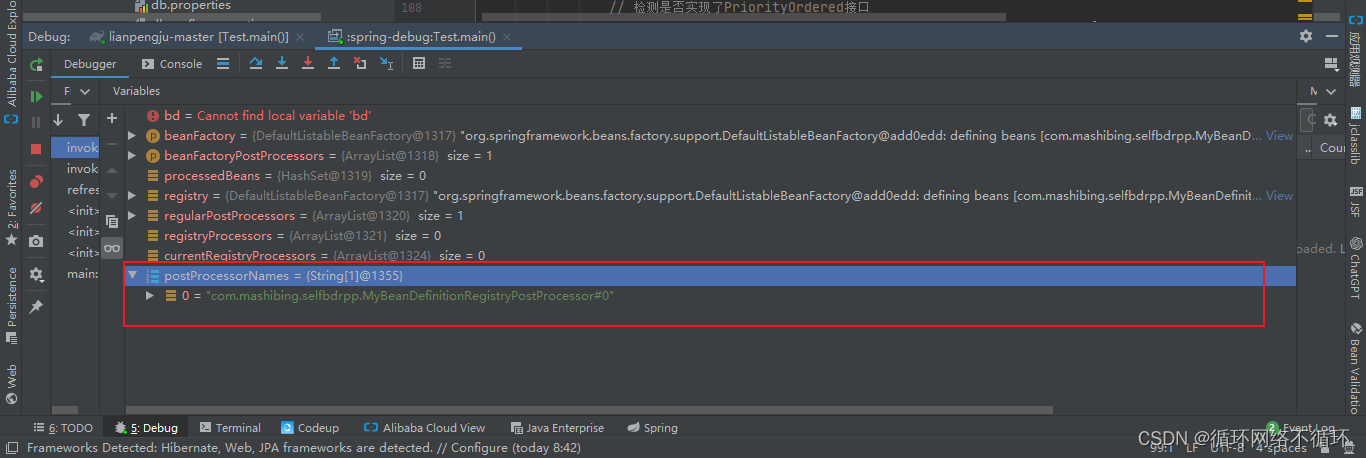
可以看到在第二次执行beanFactory.getBeanNamesForType这个方法时,确实队列中多出了两个元素,也证明了我们的猜想。

(二)自动装配
自动装配分为两个阶段,一个阶段是将启动类装入Spring容器中,另一个阶段就是对Spring容器中的注解信息进行解析。
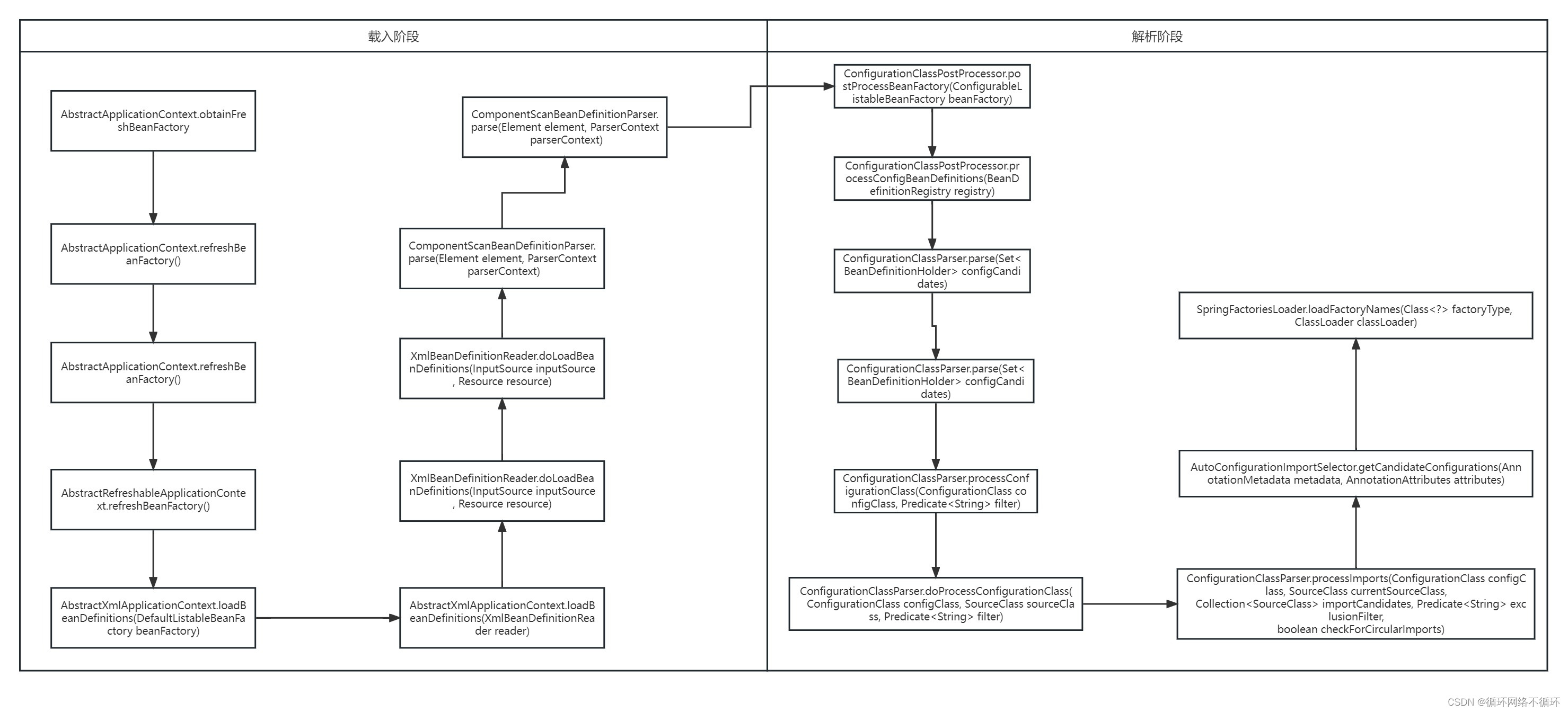
1、启动类装入
在obtainFreshBeanFactory这个方法执行时,Spring就会根据注解进行扫描,对该类进行解析。
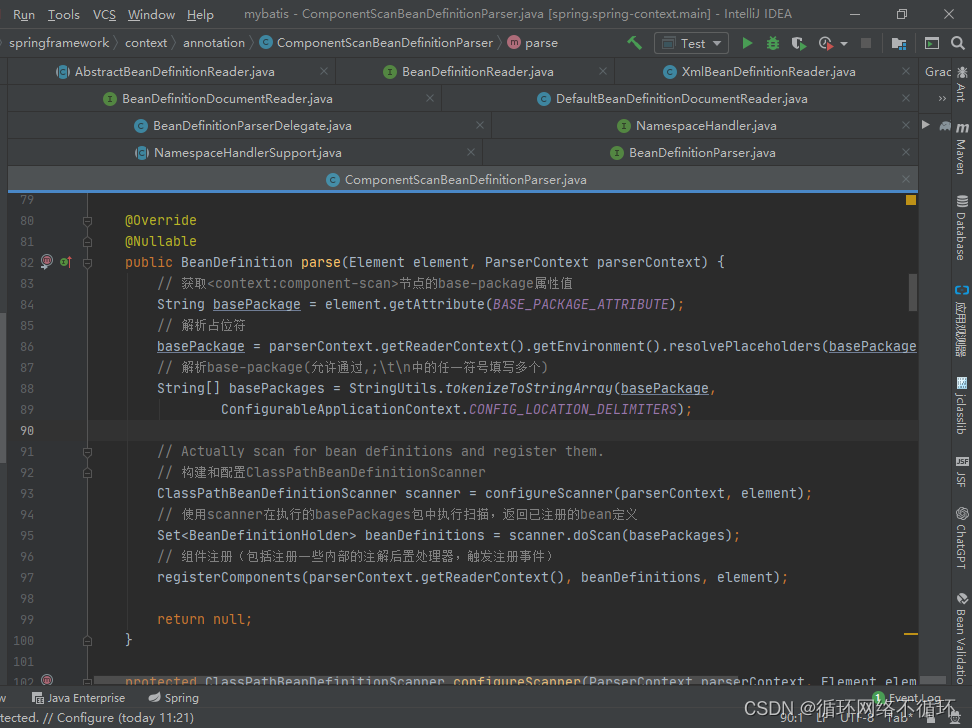
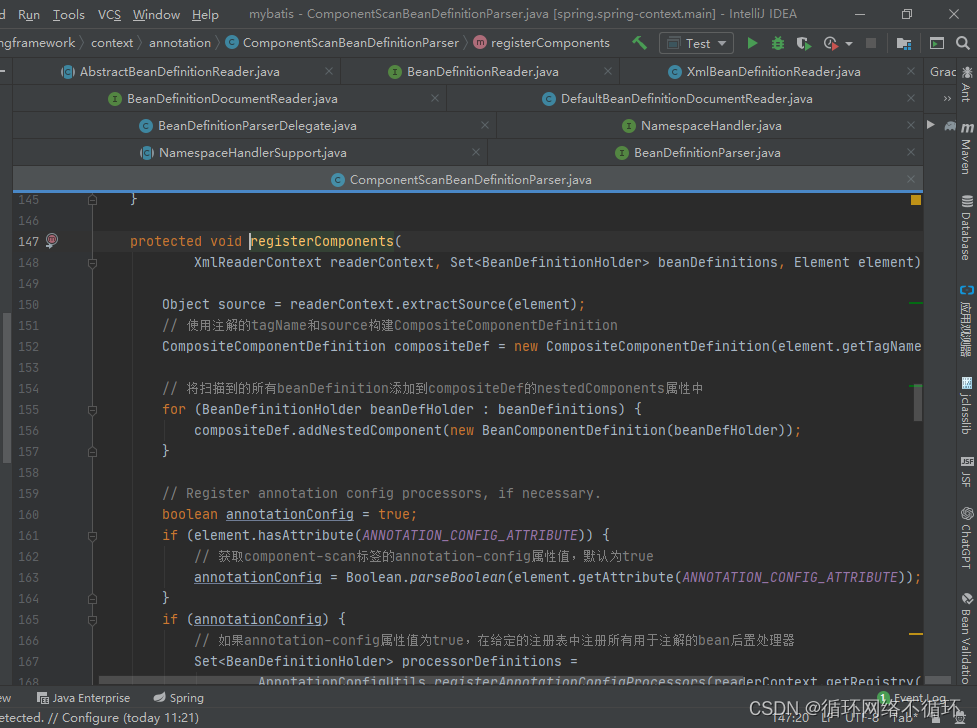
2、注解解析
上面的方法仅仅是将启动类装入容器中,但是并未对容器上的注解进行解析,接下来我们看看他解析的过程。里面处理的主要逻辑如下。
processConfigBeanDefinitions:
这一步的作用是调用ConfigurationClassParser的解析方法进行解析。
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
// 创建存放BeanDefinitionHolder的对象集合
List<BeanDefinitionHolder> configCandidates = new ArrayList<>();
// 当前registry就是DefaultListableBeanFactory,获取所有已经注册的BeanDefinition的beanName
String[] candidateNames = registry.getBeanDefinitionNames();
// 遍历所有要处理的beanDefinition的名称,筛选对应的beanDefinition(被注解修饰的)
for (String beanName : candidateNames) {
// 获取指定名称的BeanDefinition对象
BeanDefinition beanDef = registry.getBeanDefinition(beanName);
// 如果beanDefinition中的configurationClass属性不等于空,那么意味着已经处理过,输出日志信息
if (beanDef.getAttribute(ConfigurationClassUtils.CONFIGURATION_CLASS_ATTRIBUTE) != null) {
if (logger.isDebugEnabled()) {
logger.debug("Bean definition has already been processed as a configuration class: " + beanDef);
}
}
// 判断当前BeanDefinition是否是一个配置类,并为BeanDefinition设置属性为lite或者full,此处设置属性值是为了后续进行调用
// 如果Configuration配置proxyBeanMethods代理为true则为full
// 如果加了@Bean、@Component、@ComponentScan、@Import、@ImportResource注解,则设置为lite
// 如果配置类上被@Order注解标注,则设置BeanDefinition的order属性值
else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {
// 添加到对应的集合对象中
configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));
}
}
// Return immediately if no @Configuration classes were found
// 如果没有发现任何配置类,则直接返回
if (configCandidates.isEmpty()) {
return;
}
// Sort by previously determined @Order value, if applicable
// 如果适用,则按照先前确定的@Order的值排序
configCandidates.sort((bd1, bd2) -> {
int i1 = ConfigurationClassUtils.getOrder(bd1.getBeanDefinition());
int i2 = ConfigurationClassUtils.getOrder(bd2.getBeanDefinition());
return Integer.compare(i1, i2);
});
// Detect any custom bean name generation strategy supplied through the enclosing application context
// 判断当前类型是否是SingletonBeanRegistry类型
SingletonBeanRegistry sbr = null;
if (registry instanceof SingletonBeanRegistry) {
// 类型的强制转换
sbr = (SingletonBeanRegistry) registry;
// 判断是否有自定义的beanName生成器
if (!this.localBeanNameGeneratorSet) {
// 获取自定义的beanName生成器
BeanNameGenerator generator = (BeanNameGenerator) sbr.getSingleton(
AnnotationConfigUtils.CONFIGURATION_BEAN_NAME_GENERATOR);
// 如果有自定义的命名生成策略
if (generator != null) {
//设置组件扫描的beanName生成策略
this.componentScanBeanNameGenerator = generator;
// 设置import bean name生成策略
this.importBeanNameGenerator = generator;
}
}
}
// 如果环境对象等于空,那么就重新创建新的环境对象
if (this.environment == null) {
this.environment = new StandardEnvironment();
}
// Parse each @Configuration class
// 实例化ConfigurationClassParser类,并初始化相关的参数,完成配置类的解析工作
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry);
// 创建两个集合对象,
// 存放相关的BeanDefinitionHolder对象
Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates);
// 存放扫描包下的所有bean
Set<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size());
do {
// 解析带有@Controller、@Import、@ImportResource、@ComponentScan、@ComponentScans、@Bean的BeanDefinition
parser.parse(candidates);
// 将解析完的Configuration配置类进行校验,1、配置类不能是final,2、@Bean修饰的方法必须可以重写以支持CGLIB
parser.validate();
// 获取所有的bean,包括扫描的bean对象,@Import导入的bean对象
Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());
// 清除掉已经解析处理过的配置类
configClasses.removeAll(alreadyParsed);
// Read the model and create bean definitions based on its content
// 判断读取器是否为空,如果为空的话,就创建完全填充好的ConfigurationClass实例的读取器
if (this.reader == null) {
this.reader = new ConfigurationClassBeanDefinitionReader(
registry, this.sourceExtractor, this.resourceLoader, this.environment,
this.importBeanNameGenerator, parser.getImportRegistry());
}
// 核心方法,将完全填充好的ConfigurationClass实例转化为BeanDefinition注册入IOC容器
this.reader.loadBeanDefinitions(configClasses);
// 添加到已经处理的集合中
alreadyParsed.addAll(configClasses);
candidates.clear();
// 这里判断registry.getBeanDefinitionCount() > candidateNames.length的目的是为了知道reader.loadBeanDefinitions(configClasses)这一步有没有向BeanDefinitionMap中添加新的BeanDefinition
// 实际上就是看配置类(例如AppConfig类会向BeanDefinitionMap中添加bean)
// 如果有,registry.getBeanDefinitionCount()就会大于candidateNames.length
// 这样就需要再次遍历新加入的BeanDefinition,并判断这些bean是否已经被解析过了,如果未解析,需要重新进行解析
// 这里的AppConfig类向容器中添加的bean,实际上在parser.parse()这一步已经全部被解析了
if (registry.getBeanDefinitionCount() > candidateNames.length) {
String[] newCandidateNames = registry.getBeanDefinitionNames();
Set<String> oldCandidateNames = new HashSet<>(Arrays.asList(candidateNames));
Set<String> alreadyParsedClasses = new HashSet<>();
for (ConfigurationClass configurationClass : alreadyParsed) {
alreadyParsedClasses.add(configurationClass.getMetadata().getClassName());
}
// 如果有未解析的类,则将其添加到candidates中,这样candidates不为空,就会进入到下一次的while的循环中
for (String candidateName : newCandidateNames) {
if (!oldCandidateNames.contains(candidateName)) {
BeanDefinition bd = registry.getBeanDefinition(candidateName);
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bd, this.metadataReaderFactory) &&
!alreadyParsedClasses.contains(bd.getBeanClassName())) {
candidates.add(new BeanDefinitionHolder(bd, candidateName));
}
}
}
candidateNames = newCandidateNames;
}
}
while (!candidates.isEmpty());
// Register the ImportRegistry as a bean in order to support ImportAware @Configuration classes
if (sbr != null && !sbr.containsSingleton(IMPORT_REGISTRY_BEAN_NAME)) {
sbr.registerSingleton(IMPORT_REGISTRY_BEAN_NAME, parser.getImportRegistry());
}
if (this.metadataReaderFactory instanceof CachingMetadataReaderFactory) {
// Clear cache in externally provided MetadataReaderFactory; this is a no-op
// for a shared cache since it'll be cleared by the ApplicationContext.
((CachingMetadataReaderFactory) this.metadataReaderFactory).clearCache();
}
}
processImports:
processImports的主要作用的拿到Import标签并拿到selector选择器。
private void processImports(ConfigurationClass configClass, SourceClass currentSourceClass,
Collection<SourceClass> importCandidates, Predicate<String> exclusionFilter,
boolean checkForCircularImports) {
// 如果使用@Import注解修饰的类集合为空,那么直接返回
if (importCandidates.isEmpty()) {
return;
}
// 通过一个栈结构解决循环引入
if (checkForCircularImports && isChainedImportOnStack(configClass)) {
this.problemReporter.error(new CircularImportProblem(configClass, this.importStack));
}
else {
// 添加到栈中,用于处理循环引入的问题
this.importStack.push(configClass);
try {
// 遍历每一个@Import注解的类
for (SourceClass candidate : importCandidates) {
// 检验配置类Import引入的类是否是ImportSelector子类
if (candidate.isAssignable(ImportSelector.class)) {
// Candidate class is an ImportSelector -> delegate to it to determine imports
// 候选类是一个导入选择器->委托来确定是否进行导入
Class<?> candidateClass = candidate.loadClass();
// 通过反射生成一个ImportSelect对象
ImportSelector selector = ParserStrategyUtils.instantiateClass(candidateClass, ImportSelector.class,
this.environment, this.resourceLoader, this.registry);
// 获取选择器的额外过滤器
Predicate<String> selectorFilter = selector.getExclusionFilter();
if (selectorFilter != null) {
exclusionFilter = exclusionFilter.or(selectorFilter);
}
// 判断引用选择器是否是DeferredImportSelector接口的实例
// 如果是则应用选择器将会在所有的配置类都加载完毕后加载
if (selector instanceof DeferredImportSelector) {
// 将选择器添加到deferredImportSelectorHandler实例中,预留到所有的配置类加载完成后统一处理自动化配置类
this.deferredImportSelectorHandler.handle(configClass, (DeferredImportSelector) selector);
}
else {
// 获取引入的类,然后使用递归方式将这些类中同样添加了@Import注解引用的类
String[] importClassNames = selector.selectImports(currentSourceClass.getMetadata());
Collection<SourceClass> importSourceClasses = asSourceClasses(importClassNames, exclusionFilter);
// 递归处理,被Import进来的类也有可能@Import注解
processImports(configClass, currentSourceClass, importSourceClasses, exclusionFilter, false);
}
}
// 如果是实现了ImportBeanDefinitionRegistrar接口的bd
else if (candidate.isAssignable(ImportBeanDefinitionRegistrar.class)) {
// Candidate class is an ImportBeanDefinitionRegistrar ->
// delegate to it to register additional bean definitions
// 候选类是ImportBeanDefinitionRegistrar -> 委托给当前注册器注册其他bean
Class<?> candidateClass = candidate.loadClass();
ImportBeanDefinitionRegistrar registrar =
ParserStrategyUtils.instantiateClass(candidateClass, ImportBeanDefinitionRegistrar.class,
this.environment, this.resourceLoader, this.registry);
/**
* 放到当前configClass的importBeanDefinitionRegistrars中
* 在ConfigurationClassPostProcessor处理configClass时会随之一起处理
*/
configClass.addImportBeanDefinitionRegistrar(registrar, currentSourceClass.getMetadata());
}
else {
// Candidate class not an ImportSelector or ImportBeanDefinitionRegistrar ->
// process it as an @Configuration class
// 候选类既不是ImportSelector也不是ImportBeanDefinitionRegistrar-->将其作为@Configuration配置类处理
this.importStack.registerImport(
currentSourceClass.getMetadata(), candidate.getMetadata().getClassName());
/**
* 如果Import的类型是普通类,则将其当作带有@Configuration的类一样处理
* 将candidate构造为ConfigurationClass,标注为importedBy,意味着它是通过被@Import进来的
* 后面处理会用到这个判断将这个普通类注册进DefaultListableBeanFactory
*/
processConfigurationClass(candidate.asConfigClass(configClass), exclusionFilter);
}
}
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to process import candidates for configuration class [" +
configClass.getMetadata().getClassName() + "]", ex);
}
finally {
this.importStack.pop();
}
}
}getAutoConfigurationEntry:
该方法会到META-INF/spring.factories找到自动配置类并进行解析。
protected AutoConfigurationEntry getAutoConfigurationEntry(AnnotationMetadata annotationMetadata) {
if (!isEnabled(annotationMetadata)) {
return EMPTY_ENTRY;
}
AnnotationAttributes attributes = getAttributes(annotationMetadata);
List<String> configurations = getCandidateConfigurations(annotationMetadata, attributes);
configurations = removeDuplicates(configurations);
Set<String> exclusions = getExclusions(annotationMetadata, attributes);
checkExcludedClasses(configurations, exclusions);
configurations.removeAll(exclusions);
configurations = getConfigurationClassFilter().filter(configurations);
fireAutoConfigurationImportEvents(configurations, exclusions);
return new AutoConfigurationEntry(configurations, exclusions);
}SpringFactoriesLoader.loadFactoryNames:
public static List<String> loadFactoryNames(Class<?> factoryType, @Nullable ClassLoader classLoader) {
String factoryTypeName = factoryType.getName();
return loadSpringFactories(classLoader).getOrDefault(factoryTypeName, Collections.emptyList());
}