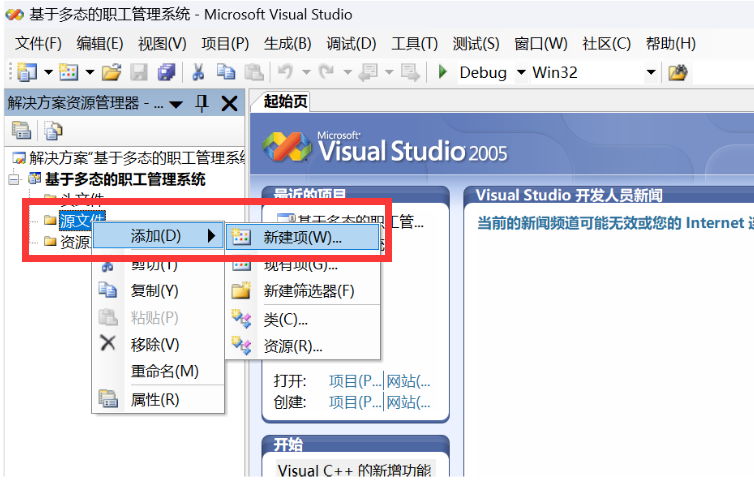
文章地址:《RepVGG: Making VGG-style ConvNets Great Again》
代码地址:https://github.com/megvii-model/RepVGG
文章发表于CVPR2021,文章提出一种将训练态和推断态网络结构解耦的方法。文章认为目前复杂的网络结构能够获取更高的精度,但是存在很明显的缺点:
-
多分支结构可能会降低推断速度以及更占用显存。例如resnet的残差结构在多个分支的地方需要复制一份tensor用于分支之间的计算,如下图所示

-
depthwise conv或者shufflenet中的channel shuffle操作对实际落地的支持可能不太好等
对应的只有简单的由 3 × 3 3\times 3 3×3卷积和relu激活组成的网络,有如下几点优势:
-
许多多分支的网络虽然在FLOPs上小于VGG,但是推断时并没有更快(例如VGG-16的FLOPs是EfficientNet-B3的8.4倍,但在1080Ti上运行,VGG-16还要快1.6倍)
-
多分支网络更耗显存,因为每个分支都需要有一份tensor用于计算直到分支通过加(addition)或者串联(concatenation)的方式合并
-
多分支网络更不灵活,例如resnet必须由resnet block组成,而resnet block中最后一个卷积必须与输入保持一致,否则shortcut结构就不能工作了。更不灵活的是,在对网络进行通道剪枝时,多分支的网络剪枝起来很麻烦而且不合理(因为block内,通道数会互相影响)
为了取长补短,文字提出一种重参(re-parameterization)的方式,将训练态的网结构与推断态的网络结构解耦。即训练时利用多分支的网络结构,推断只有普通的 3 × 3 3\times 3 3×3和relu激活组成的网络。
一、重参的原理
重参的原理就是通过代数的方式将多分支合并为一个分支。
更具体的,我们可以将
1
×
1
1\times 1
1×1的卷积看成是
3
×
3
3\times 3
3×3大小卷积的特例,identity和BN分支可以看成是
1
×
1
1\times 1
1×1卷积的特例。这句话可以用下图表示:

上图A是将重参前的结构演变为 3 × 3 3\times 3 3×3卷积的流程图,流程分为如下几步:
-
将 3 × 3 3\times 3 3×3的卷积和bn层合并成 3 × 3 3\times 3 3×3卷积
-
将 1 × 1 1\times 1 1×1的卷积转换为 3 × 3 3\times 3 3×3的卷积,然后与bn合并成 3 × 3 3\times 3 3×3的卷积
-
将BN转换为 3 × 3 3\times 3 3×3的卷积
-
将转换后的三个 3 × 3 3\times 3 3×3的并联的卷积合并为最终的 3 × 3 3\times 3 3×3的卷积
这里在合并前就是训练态的结构,合并后就是推断态的网络结构。
上图B是具体的参数转换流程,为了方便理解这里加以说明一下。上图假设当前网络块的输入 C 1 C_1 C1和输出通道 C 2 C_2 C2都为2。图中对于一个卷积来说,水平方向为输入的通道数,竖直方向为输出通道数。
-
对于 1 × 1 1\times 1 1×1的卷积来说,将其转换为 3 × 3 3\times 3 3×3的卷积,就是将 1 × 1 1\times 1 1×1的卷积核进行周围补0,补成 3 × 3 3\times 3 3×3的大小即可
-
对于BN层或者shortcut结构来说,将其转换为 3 × 3 3\times 3 3×3的卷积,就是对应通道数除当前输出通道的中心为对应的值,其它值都为0。例如identity结构,当前中心值为1,其它值都为0,这样与输入相乘后,仍然为输入的值。
具体用公式表示如下(对公式不感兴趣的可以不看,上图已经很清晰了,这里是想说明代数方式如何将网络进行化简合并的):
先定义一些符号, 3 × 3 3\times 3 3×3大小输入通道为 C 1 C_1 C1输出通道为 C 2 C_2 C2的卷积参数表示为 W ( 3 ) ∈ R C 2 × C 1 × 3 × 3 W^{(3)}\in R^{C_2 \times C_1 \times 3\times 3} W(3)∈RC2×C1×3×3,对应输入输出通道数的 1 × 1 1\times 1 1×1卷积参数表示为 W ( 1 ) ∈ R C 2 × C 1 W^{(1)}\in R^{C_2 \times C_1} W(1)∈RC2×C1。跟在 3 × 3 3\times 3 3×3大小卷积后的BN层参数为 μ ( 3 ) , θ ( 3 ) , γ ( 3 ) , β ( 3 ) \mu^{(3)}, \theta^{(3)}, \gamma^{(3)}, \beta^{(3)} μ(3),θ(3),γ(3),β(3),跟在 1 × 1 1\times 1 1×1大小卷积后的BN层参数为 μ ( 1 ) , θ ( 1 ) , γ ( 1 ) , β ( 1 ) \mu^{(1)}, \theta^{(1)}, \gamma^{(1)}, \beta^{(1)} μ(1),θ(1),γ(1),β(1),identity分支中的BN层参数为 μ ( 0 ) , θ ( 0 ) , γ ( 0 ) , β ( 0 ) \mu^{(0)}, \theta^{(0)}, \gamma^{(0)}, \beta^{(0)} μ(0),θ(0),γ(0),β(0)。这里假设 C 1 = C 2 , H 1 = H 2 , W 1 = W 2 C_1=C_2, H_1=H_2, W_1=W_2 C1=C2,H1=H2,W1=W2,符号 ∗ * ∗表示卷积。那么对于输入 M ( 1 ) ∈ R N × C 1 × H 1 × W 1 M^{(1)}\in R^{N \times C_{1} \times H_{1} \times W_1} M(1)∈RN×C1×H1×W1和输出 M ( 2 ) ∈ R N × C 2 × H 2 × W 2 M^{(2)}\in R^{N\times C_2 \times H_2 \times W_2} M(2)∈RN×C2×H2×W2存在如下关系:
M ( 2 ) = b n ( M ( 1 ) ∗ W ( 3 ) , μ ( 3 ) , θ ( 3 ) , γ ( 3 ) , β ( 3 ) ) + b n ( M ( 1 ) ∗ W ( 1 ) , μ ( 1 ) , θ ( 1 ) , γ ( 1 ) , β ( 1 ) ) + b n ( M ( 1 ) , μ ( 0 ) , θ ( 0 ) , γ ( 0 ) , β ( 0 ) ) M^{(2)}=bn(M^{(1)} * W^{(3)}, \mu^{(3)}, \theta^{(3)}, \gamma^{(3)}, \beta^{(3)}) \\ +bn(M^{(1)} * W^{(1)}, \mu^{(1)}, \theta^{(1)}, \gamma^{(1)}, \beta^{(1)}) \\ + bn(M^{(1)}, \mu^{(0)}, \theta^{(0)}, \gamma^{(0)}, \beta^{(0)}) M(2)=bn(M(1)∗W(3),μ(3),θ(3),γ(3),β(3))+bn(M(1)∗W(1),μ(1),θ(1),γ(1),β(1))+bn(M(1),μ(0),θ(0),γ(0),β(0))
其中推断态的BN可以写成下式:
b
n
(
M
,
μ
,
θ
,
γ
,
β
)
:
,
i
,
:
,
:
=
(
M
:
,
i
,
:
,
:
−
μ
i
)
θ
i
γ
i
+
β
i
bn(M, \mu, \theta, \gamma, \beta)_{:, i, :, :}=(M_{:, i, :, :}-\mu_i)\frac{\theta_i}{\gamma_i}+\beta_i
bn(M,μ,θ,γ,β):,i,:,:=(M:,i,:,:−μi)γiθi+βi
上式中体现了bn的操作索引是在C维度进行的,详细可参考GN-Group Normalization
上式可以化简为:
b n ( M ∗ W , μ , θ , γ , β ) ∗ : , i , : , : = ( M ∗ W ′ ) ∗ : , i , : , : + b ‘ i bn(M* W, \mu, \theta, \gamma, \beta)*{:, i, :, :}=(M* W')*{:, i, :, :}+b‘_{i} bn(M∗W,μ,θ,γ,β)∗:,i,:,:=(M∗W′)∗:,i,:,:+b‘i
其中 W ′ ∗ i , : , : , : = θ i γ i W ∗ i , : , : , : W'*{i, :, :, :}=\frac{\theta_i}{\gamma_i}W*{i, :, :, :} W′∗i,:,:,:=γiθiW∗i,:,:,:, b i ′ = − μ i γ i θ i + β i b'_i=-\frac{\mu_i \gamma_i}{\theta_i}+\beta_i bi′=−θiμiγi+βi
到这里重参的原理基本就介绍完了,具体实验请查看原文。


![阶段二38_面向对象高级_网络编程[UDP单播组播广播代码实现]](https://img-blog.csdnimg.cn/3ad5a6179b9a40fca28227ddb8eb5362.png#pic_center)