一,操作系统
1.1,Linux系统基础操作
1.2,linux进程与线程
1.2.1并发,并行
(1)并发:在一段时间内交替的执行多个任务:对于单核CPU处理多任务,操作系统轮流让让各个任务交替执行,只不过每个任务处理的时间可能比较短,看起来是同时在处理。(当任务的数量大于CPU核心数就可看做事并发执行的。)
(2)并行:在一段时间内真正的同时执行多个任务。对于多核CPU处理多任务,操作系统会给CPU的每个内核安排一个执行的任务,多核真正实现多个任务同时处理。
1.2.2进程
- 进程是资源分配的最小单位,他是操作系统进行资源分配和调度运行的基本单位,通俗讲,一个正在运行的程序就是一个进程,qq,微信等。
- 进程的创建使用
(1)导包
import multiprocessing
(2)创建进程类对象
proc1=multiprocessing.Process()

(3)启动进程
#(1)导包
import multiprocessing
import time
def coding():
for i in range(3):
print("正在写代码!")
time.sleep(1)
def music():
for i in range(3):
print("正在听音乐!")
time.sleep(1)
#(2)创建进程类对象,也叫子进程
proc1=multiprocessing.Process(target=coding)
proc2=multiprocessing.Process(target=music)
if __name__ == '__main__':
# (3)启动进程
proc1.start()
proc2.start()

- 函数传参
(1)在定义进程类对对象时,Process()的参数中可以使用args或者kwargs来确定函数需要输入的参数。args使用元组方式传参,kwargs使用字典方式。
#2函数有参数
import multiprocessing
import time
def coding(msg):
for i in range(3):
print(msg)
time.sleep(1)
def music(msg):
for i in range(3):
print(msg)
time.sleep(1)
proc1=multiprocessing.Process(target=coding,args=(2,))
#args=(2,)以元组形式进行传参,如果只有一个参数值需要添加逗号,
# 用以区分这不是一个括号,而是元组
proc2=multiprocessing.Process(target=music,kwargs={"msg":3})
if __name__ == '__main__':
# (3)启动进程
proc1.start()
proc2.start()

1.2.3获取进程编号
- 当程序中的进程数量越来越多时,就无法区分主进程和子进程,为了方便管理每个进程都有自己的编号,通过获取进程编号就可以区分不同的进程。
- 两个获取进程编号的方法:
getpid()#获取当前进程的编号,getppid()#获取当前父进程的编号,需要导入os模块,使用os.getpid()获取进程编号。
import os
def GetPid():
print("GetPid当前进程的编号:",os.getpid())
print("父进程进程的编号:",os.getppid())
if __name__ == '__main__':
# (3)启动进程
Proc3 = multiprocessing.Process(target=GetPid())
Proc3.start()
- 一旦运行程序,系统会自动创建一个主进程用来管理代码中各行程序,
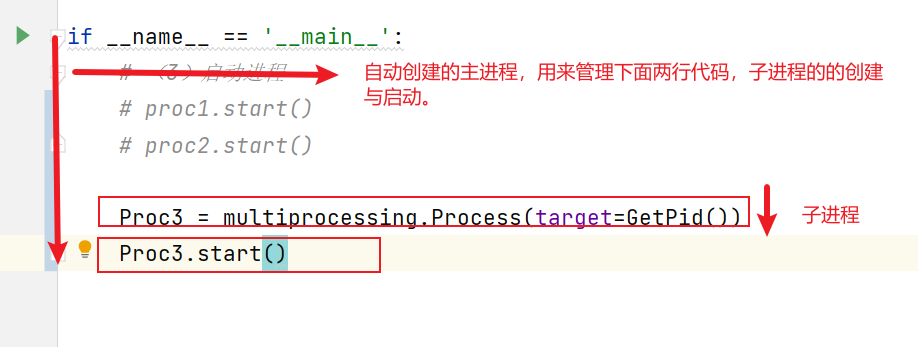
Proc3子进程有主进程创建,查看其父进程使用os.getppid()
验证主进程创建子进程,查看下面两个子进程的父进程编号是否相同:
import multiprocessing
import time
import os
def coding(msg):
print("coding父进程进程的编号:", os.getppid())
# for i in range(3):
# print(msg)
# time.sleep(1)
def music(msg):
print("music父进程进程的编号:", os.getppid())
# for i in range(3):
# print(msg)
# time.sleep(1)
if __name__ == '__main__':
# (3)启动进程
proc1 = multiprocessing.Process(target=coding, args=(2,))
# args=(2,)以元组形式进行传参,如果只有一个参数值需要添加逗号,
# 用以区分这不是一个括号,而是元组
proc2 = multiprocessing.Process(target=music, kwargs={"msg": 3})
# Proc3 = multiprocessing.Process(target=GetPid())
proc1.start()
proc2.start()
# Proc3.start()

1.2.4进程之间不共享全局变量
- 进程间是不共享全局变量的:实际上创建一个子进程就是把主进程的资源进行拷贝产生一个新的进程,这里主进程与子进程是相互独立的。而线程之间是共享全局变量的。
- 定义一个列表,然后定义两个进程一个用来写入数据,一个用来读取数据 ,看两个进程能否同时操作这一个列表中的数据。
#验证进程间不共享全局变量
import multiprocessing
mylist=list()
#写入数据
def write_data():
for i in range(3):
mylist.append(i)
print(f"add:{i}")
print(mylist)
#打印数据
def read_data():
print(mylist)
if __name__ == '__main__':
#创建写,读进程
wirte_process=multiprocessing.Process(target=write_data)
read_process=multiprocessing.Process(target=read_data)
wirte_process.start()
read_process.start()

1.2.5主进程与子进程结束顺序
- 主进程会等待所有子进程结束后才会结束:

- 但是在代码中显示的结果不同:
import multiprocessing
import time
#创建工作函数
def work():
for i in range(10):
print("working!....")
time.sleep(0.2)
if __name__ == '__main__':
#创建子进程
work_process=multiprocessing.Process(target=work)
work_process.start()
#延迟一秒使效果更明显
time.sleep(1)
print("主进程已结束")

由输出结果图可看到:子进程还没有结束主进程已经显示结束
3. 改进:设置守护主进程,主进程退出后子进程直接销毁,不再执行子进程的代码
import multiprocessing
import time
#创建工作函数
def work():
for i in range(10):
print("working!....")
time.sleep(0.2)
if __name__ == '__main__':
#创建子进程
work_process=multiprocessing.Process(target=work)
#设置守护主进程,主进程退出后子进程直接销毁,不再执行子进程的代码
work_process.daemon=True
work_process.start()
#延迟一秒使效果更明显
time.sleep(1)
print("主进程已结束")
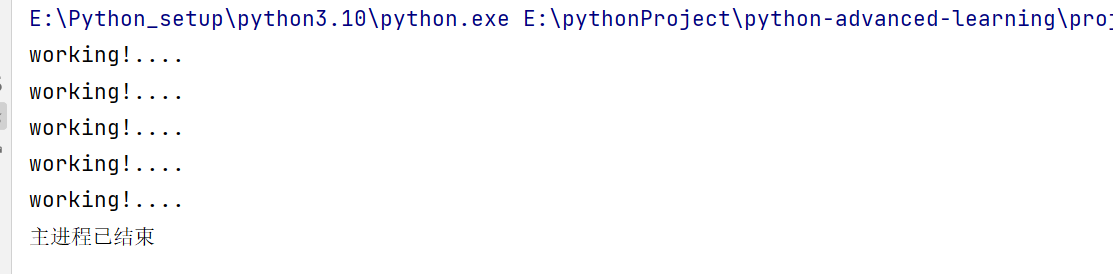
4. 第二种方法:直接手动销毁子进程 work_process.terminate()

1.2.6线程
- python的多线程可以通过threading模块中的Tread类实现,每创建一个Thread对象就创建了一个线程。
import threading
thread_obj1=threading.Thread()
"""
-group:暂无用处,未来功能的预留参数
-target:执行的目标任务名,,一般是方法名
-args:以元组的方式给执行任务传参
-kwargs:以字典方式给执行任务传参
-name:线程名,一般不用设置
"""
thread_obj.start()
- 单线程实例:
import time
def sing():
while True:
print("我在唱歌!")
time.sleep(1)
def dance():
while True:
print("我在跳舞!")
time.sleep()
if __name__ == '__main__':
sing()
dance()

由于是单线程,导致一次只能执行一个程序,跳舞的程序无法执行。
3. 多线程实现
import threading
import time
def sing():
while True:
print("我在唱歌!")
time.sleep(1)
def dance():
while True:
print("我在跳舞!")
time.sleep(1)
#定义两个线程
thread_obj1 = threading.Thread(target=sing)
thread_obj2 = threading.Thread(target=dance)
if __name__ == '__main__':
thread_obj1.start()
thread_obj2.start()

4. 实例三,实现传参->args(元组),kwargs(字典 )
import threading
import time
def sing(msg):
while True:
print(msg)
time.sleep(1)
def dance(msg):
while True:
print(msg)
time.sleep(1)
#定义两个线程
thread_obj1 = threading.Thread(target=sing,args=("唱歌中",))#以元组传参
thread_obj2 = threading.Thread(target=dance,kwargs={"msg":"跳舞中"})#以字典传参
if __name__ == '__main__':
thread_obj1.start()
thread_obj2.start()
注意:对于传入的元组参数,如果元组只有一个值,要加逗号,否则只是普通的数值,如threading.Thread(target=sing,args=("唱歌中",))

1.2.7主线程与子线程的执行顺序
(1)按理说主线程执行完毕后子线程也会停止执行,但实际并非如此:
import threading
import time
def work():
for i in range(10):
print(f"子线程执行第{i}次。")
time.sleep(1)
if __name__ == '__main__':
work_thre1=threading.Thread(target=work)
work_thre1.start()#启动子进程
time.sleep(1)
print("主进程执行完毕!")
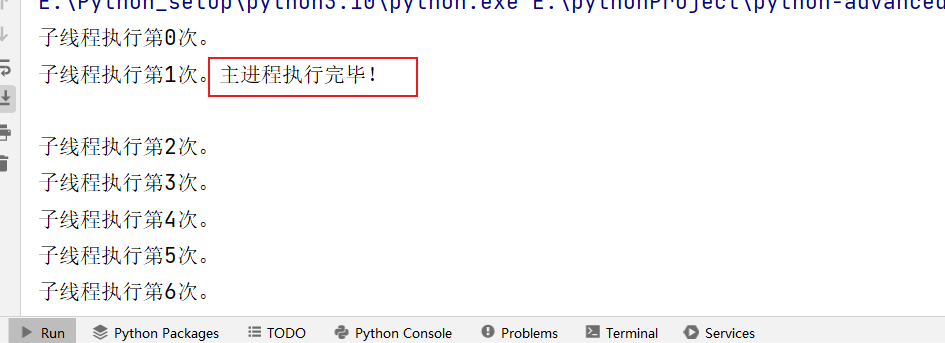
(2)通过设置守护 主进程:
work_thre1.daemon=True

如下图:主进程结束时子进程虽然只执行一次,也不会继续执行。

1.2.8线程间共享全局变量
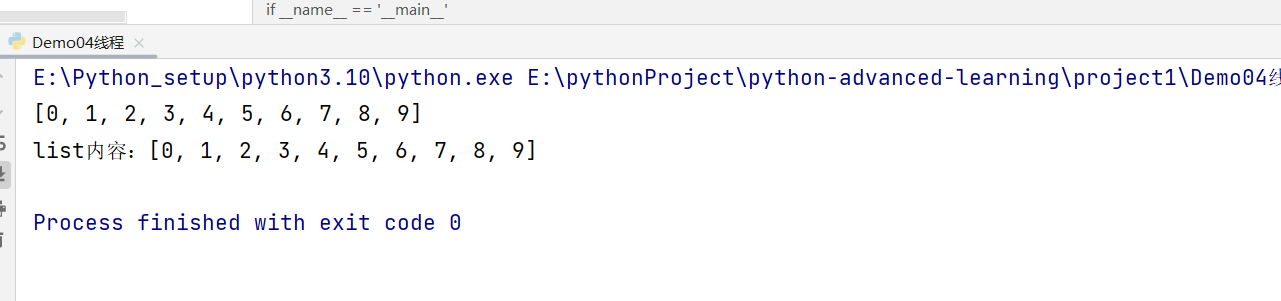
#04,线程间共享全局变量
import threading
import time
my_list=[]#全局变量
def write_data():
for i in range(10):
my_list.append(i)
print(my_list)
def read_data():
print(f"list内容:{my_list}")
if __name__ == '__main__':
write_Thread=threading.Thread(target=write_data)
read_Thread=threading.Thread(target=read_data)
write_Thread.start()
#设置时间间隔,确保充分时间执行 写入线程
time.sleep(3)
read_Thread.start()
1.2.9多线程资源抢占
(1)以下列task1(),task2()两个函数为例,分别将对全局变量num加一重复一千万次循环(数据大一些,太小的话执行太快,达不到验证的效果)。
import threading
import time
num = 0
def task1(nums):
global num
for i in range(nums):
num += 1
print("task1---num=%d" % num)
def task2(nums):
global num
for i in range(nums):
num += 1
print("task2---num=%d" % num)
if __name__ == '__main__':
nums = 10000000
t1 = threading.Thread(target=task1, args=(nums,))
t2 = threading.Thread(target=task2, args=(nums,))
t1.start()
t2.start()
# 因为主线程不会等子线程执行完就会执行,所以这里延迟五秒,确保最后执行。
time.sleep(5)
print("main----num=%d" % num)

如图,输出结果比较混乱,既没有一千万,最终结果也不是二千万。因为多线程运行时出现了资源竞争,即可以理解为,每个函数运行的时间都不确定,且互相影响,
如从初始值0开始,假设t1的线程先执行,执行到+1后,此时的num=1还未存储,然后即被叫停,t2开始执行,去获取num,获取到的num等于初始值0,然后其执行了+1并存储,存储后num=1,然后t2停止t1继续,再次存储num=1。即加了两次1,但是num还是只等于1。
因为t1和t2谁来运行的分配是完全随机的,所以最后加了两千万次1后值是小于2000万的。
1.2.10互斥锁
- 某个线程要更改共享数据时,先将其锁定,此时资源的状态为"锁定",其他线程不能改变,只到该线程释放资源,将资源的状态变成"非锁定",其他的线程才能再次锁定该资源。
- 互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
#创建锁
mutex = threading.Lock()
#给线程上锁
mutex.acquire() # 上锁
xxxx锁定的内容xxxxx
mutex.release() # 解锁
整体代码:
import threading
import time
num = 0
def task1(nums):
global num
mutex.acquire()
for i in range(nums):
num += 1
mutex.release()
print("task1---num=%d" % num)
def task2(nums):
global num
mutex.acquire()
for i in range(nums):
num += 1
mutex.release()
print("task2---num=%d" % num)
if __name__ == '__main__':
nums = 10000000
mutex = threading.Lock()
t1 = threading.Thread(target=task1, args=(nums,))
t2 = threading.Thread(target=task2, args=(nums,))
t1.start()
t2.start()
# 因为主线程不会等子线程执行完就会执行,所以这里延迟五秒,确保最后执行。
time.sleep(5)
print("main----num=%d" % num)

加锁过后,某线程占用公共资源(全局变量)时,其他进程处于等待状态。

1.2.11死锁
(1)死锁:是指多个线程同时被阻塞,其中一个或者全部线程都在等待某个资源,由于资源争夺而造成的一中僵局。若无外力推进,他们都将无法推进。由于无限期的阻塞,程序没有办法进行正常终止。例如两个线程都在等待对方的资源,而自己不肯放弃当前的资源,就会形成死锁状态。
(2)案例:支队take1,和task2进行加锁不进行解锁。task1对应的进行会持续霸占资源:
import threading
import time
num = 0
def task1(nums):
global num
print("task1.......")
mutex.acquire()
for i in range(nums):
num += 1
print("task1---num=%d" % num)
def task2(nums):
global num
print("task2.......")
mutex.acquire()
for i in range(nums):
num += 1
print("task2---num=%d" % num)
if __name__ == '__main__':
nums = 10000000
mutex = threading.Lock()
t1 = threading.Thread(target=task1, args=(nums,))
t2 = threading.Thread(target=task2, args=(nums,))
t1.start()
t2.start()
# 因为主线程不会等子线程执行完就会执行,所以这里延迟五秒,确保最后执行。
time.sleep(5)
print("main----num=%d" % num)

1.3Socket
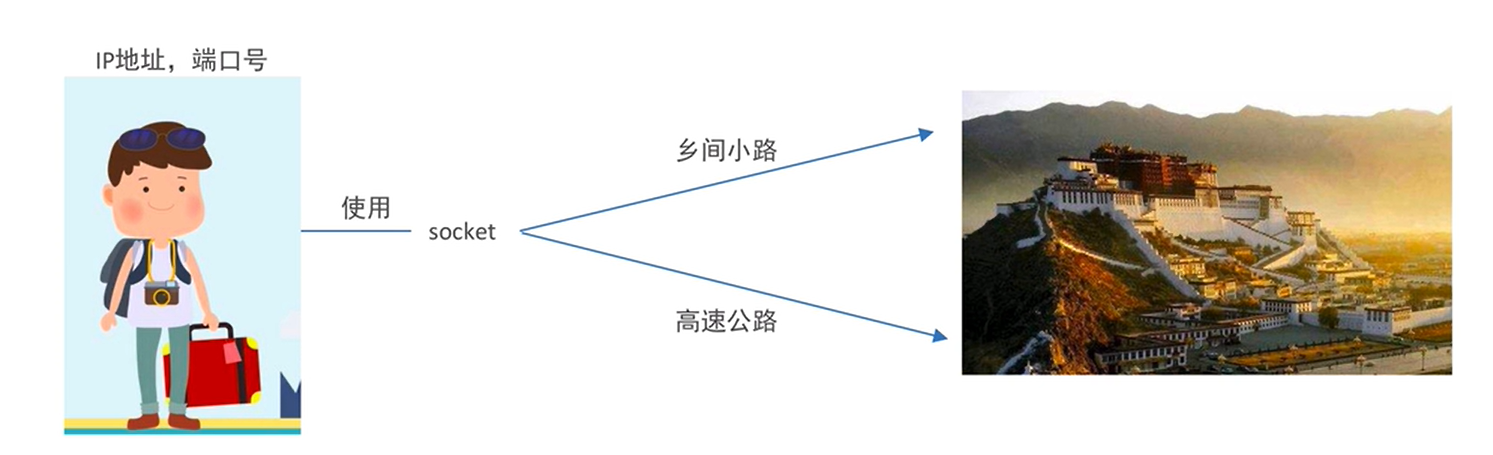
只拥有IP地址和端口号还无法实现网络之间的通信,还需要借助socket(套接字)来完成通讯,打电话只知道对方号码还不行,还需要一个可以接通的工具。
1.3.1Socket简介
- Socket是一种网络通信协议,它是为了解决不同计算机之间的通信而设计的。在计算机网络中,Socket是一种特殊的文件描述符,它允许应用程序通过网络进行通信。Socket提供了一种标准的接口,使得应用程序能够通过网络协议(如TCP或UDP)进行通信。
- Socket通常作为一种低级别的网络编程接口,它可以在不同的操作系统和编程语言中使用。它提供了一种面向流和面向消息的数据传输方式,并且可以在客户端和服务器端之间建立连接。使用Socket可以实现各种网络应用程序,如Web服务器、邮件服务器、FTP服务器等。
- 在Socket编程中,一个Socket通常由一个IP地址和一个端口号组成。IP地址用于标识网络中的主机,而端口号则用于标识特定的应用程序。当应用程序向网络发送数据时,它会将数据发送到特定的IP地址和端口号,而当应用程序接收数据时,它会监听特定的端口号,并等待来自网络的数据包。
总之:程序之间的网络数据传输可以通过socket完成,socket就是程序间网络数据通信的工具。
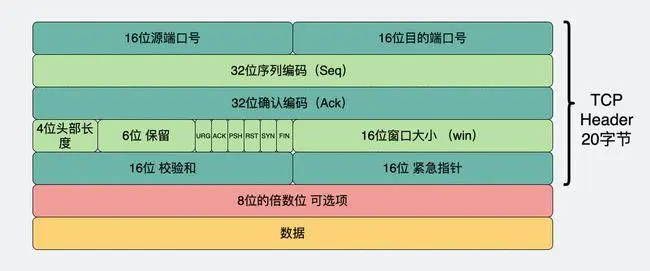
1.3.2TCP介绍
- 在确定想要传输数据的对象IP地址后,还需要选择网络传输协议,保证程序间按照指定的传输规则进行数据通信。
- TCP是传输控制协议:他是一种面向连接的,可靠的,基于字节流的传输层通讯协议。TCP协议通过三次握手建立连接,保证数据传输的可靠性和顺序性,并通过拥塞控制机制来保证网络的健康稳定。它将数据分割成适当的大小,通过IP协议进行传输,并在接收端重新组装数据。
1.3.2.1 TCP面向连接特性
(1)面向连接:TCP是一种面向连接的协议,这意味着在数据传输之前,发送方和接收方必须先建立一个连接。(打电话之前确保对面有接电话的条件,且对方可以随时接听)这个连接是一个虚拟的通道,用于在发送方和接收方之间传输数据。在连接建立之后,发送方和接收方可以通过这个连接传输数据,直到连接被关闭。
(2)建立的连接:建立连接的过程通常是通过三次握手实现的。在三次握手过程中,发送方首先向接收方发送一个 SYN 报文,表示请求建立连接;接收方收到 SYN 报文后,回复一个 SYN+ACK 报文,表示接收到请求并同意建立连接;最后,发送方再回复一个 ACK 报文,表示连接建立成功。这个过程中,双方都要确认对方的身份和可用性,以确保连接的正确性和稳定性。
(3)关闭连接:当数据传输完成或者连接出现问题时,发送方和接收方都可以关闭连接。关闭连接的过程也需要经过三次握手,这样可以确保双方都能正确地关闭连接。
1.3.2.2 TCP可靠性特性
(1)序列号和确认号机制:TCP将数据分割成若干个数据段,并为每个数据段分配一个序列号。接收方在接收到数据段后,会向发送方回复一个确认号,表示已收到该数据段。如果发送方在规定时间内未收到确认,就会重传该数据段。
(2)滑动窗口机制:TCP使用滑动窗口机制来控制发送方和接收方之间的数据传输速度。发送方会将数据发送到接收方,但是接收方并不会立即回复确认,而是在接收到一定数量的数据后才回复确认。这样可以避免发送方发送过多的数据,导致网络拥塞。
(3)重传机制:如果发送方在规定时间内未收到确认,就会重传该数据段。接收方在接收到重传的数据段后,会丢弃之前接收到的重复数据,并向发送方回复确认。
(4)拥塞控制机制:TCP使用拥塞控制机制来避免网络拥塞。发送方会根据网络状况来调整发送速度,以避免发送过多的数据导致网络拥塞。如果网络拥塞,发送方会减少发送速度,以避免进一步加剧网络拥塞。