数据库
- 数据库表的设计
- ER 关系图
- 三大范式
- 聚合函数与分组查询
- 聚合函数 (count、sum、avg、max、min)
- 分组查询 group by fields....having....(条件)
- 多表联查
- 内连接
- 外连接(左连接,右连接)
- 自连接
- 子查询
- 合并查询 UNION
数据库表的设计
ER 关系图
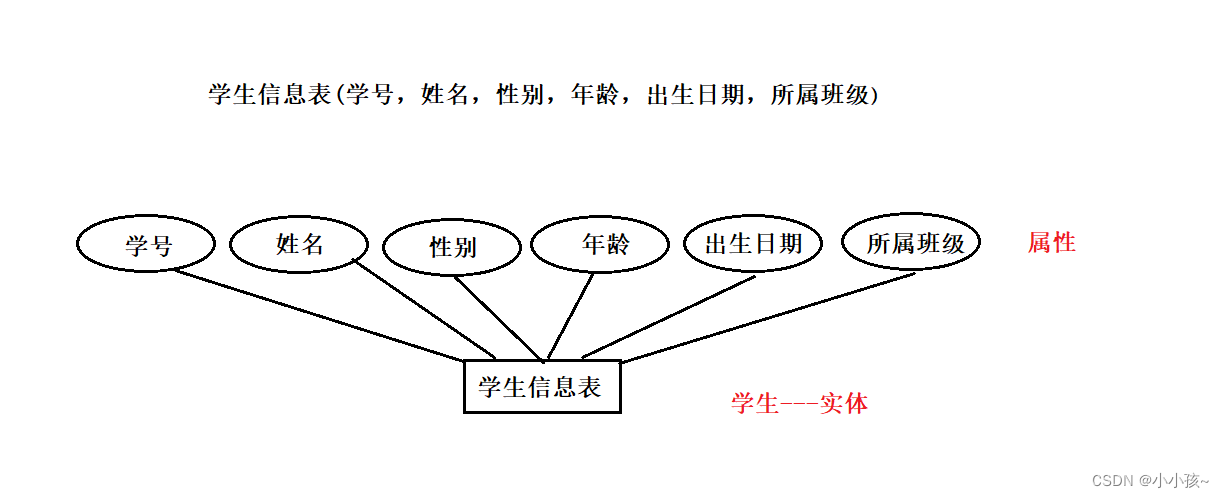
ER 图:以图形的方式描述表与表之间的关系
矩形:实体
圆形:实体属性
菱形:实体间关系
例如:
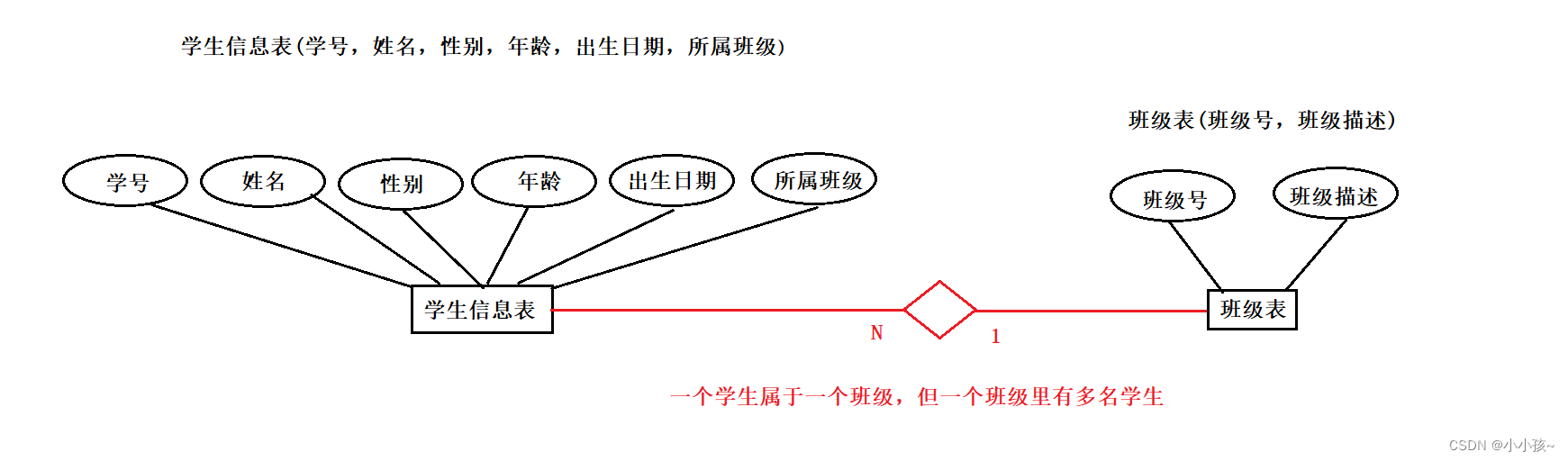
给定学生信息表的个字段信息,画出其 ER 图
学生信息表(学号,姓名,性别,年龄,出生日期,所属班级)
班级表(班级号,班级描述)

其次,表与表之间存在一对一、一对多、多对一 的对应关系
上述 ER 图,一个学生只能属于一个班级,而一个班级里边可以有多个学生,因此学生信息表与班级表之间是属于多对一的关系
一般在多对多关系中,需要创建一个第三方表来找到两个独立实体之间的关系建立起联系
三大范式
第一范式 1NF:表中每个字段都应该具备原子性(即不可再分割特性)
特性:属性不可分割,即每个属性都是不可分割的原子项。(实体的属性即表中的列)
第二范式 2NF:主要针对组合主键的表
表中的每个字段都应该与主键完全关联
特性:在1NF的基础上,非码属性必须完全依赖于候选码(在1NF基础上消除非主属性对主码的部分函数依赖)
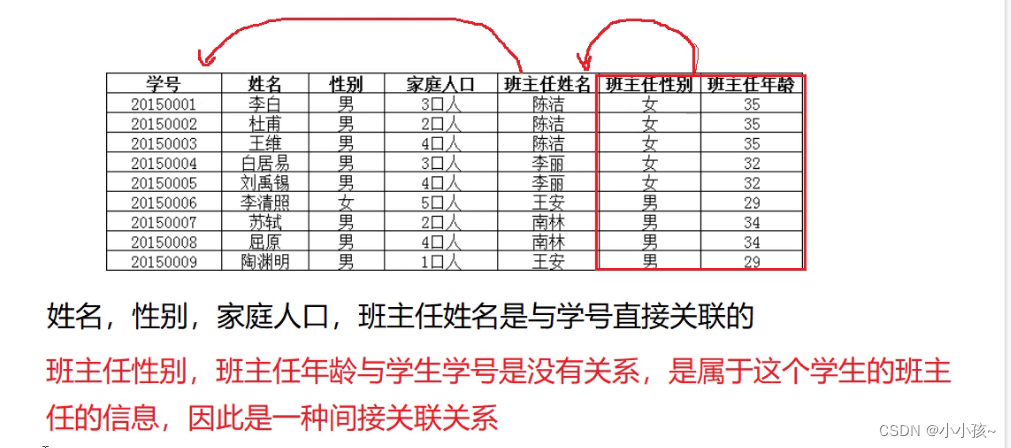
例如,在学生信息表中,给定一个主键信息–学生学号 sn,则可以确定唯一的学生信息(学生姓名,学生性别,学生年龄,出生日期…),也就是除学号 sn 以外的其他属性都完全依赖于学生学号 sn
第三范式 3NF:表中每个字段,都应该与主键直接关联而不应该简介关联
特性:在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
聚合函数与分组查询
聚合函数 (count、sum、avg、max、min)
聚合函数:数据库提供给用户的用于进行数据统计的函数
实例中使用的表结构信息:

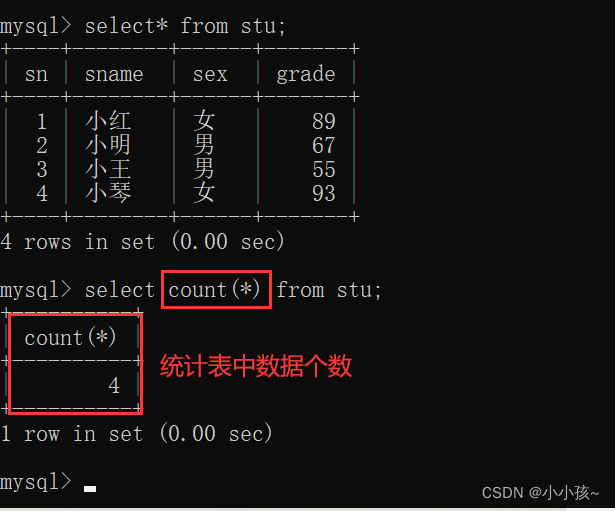
1、count 统计个数
count(*):统计查询的结果个数
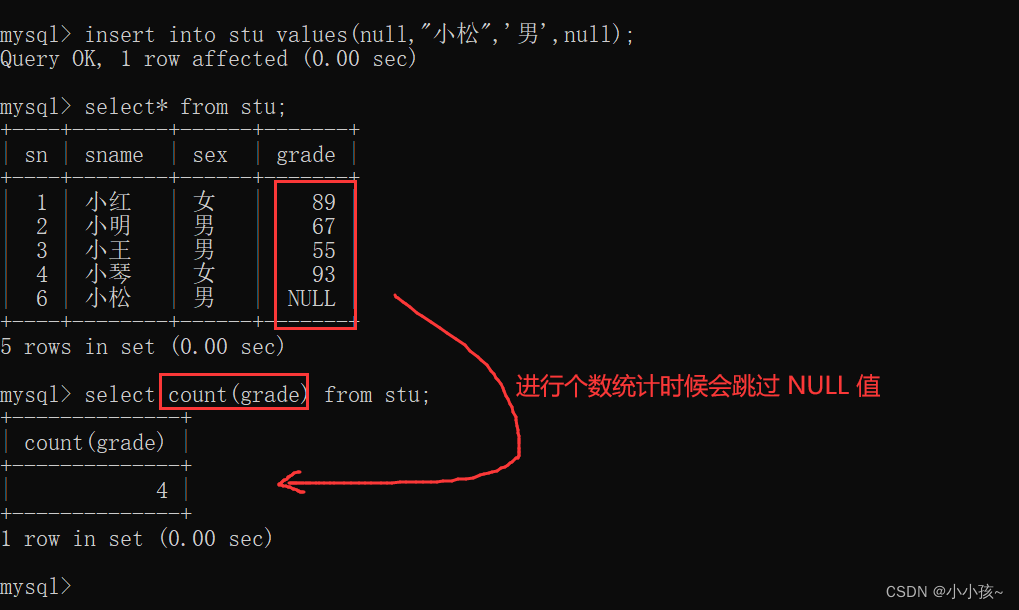
count(列名):会忽略空值
当要查找的列中含有空值时:
2、sum 统计总和
sum(列名):对某属性值进行求和

3、avg 求平均值
avg(列名):对某属性值进行求平均
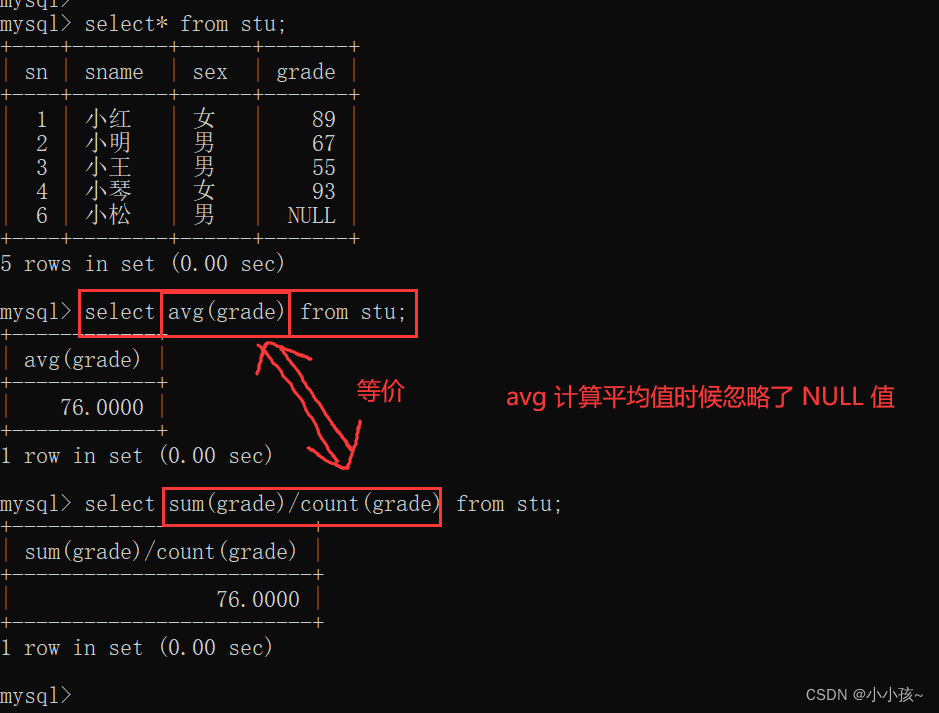
4、max 对指定字段求最大值
5、min 对指定字段求最小值

分组查询 group by fields…having…(条件)
分组查询本质上是为了进行数据统计
以表中指定字段对数据库表中数据进行分组,然后进行数据统计
例如在学生表中求男女生的平均成绩:
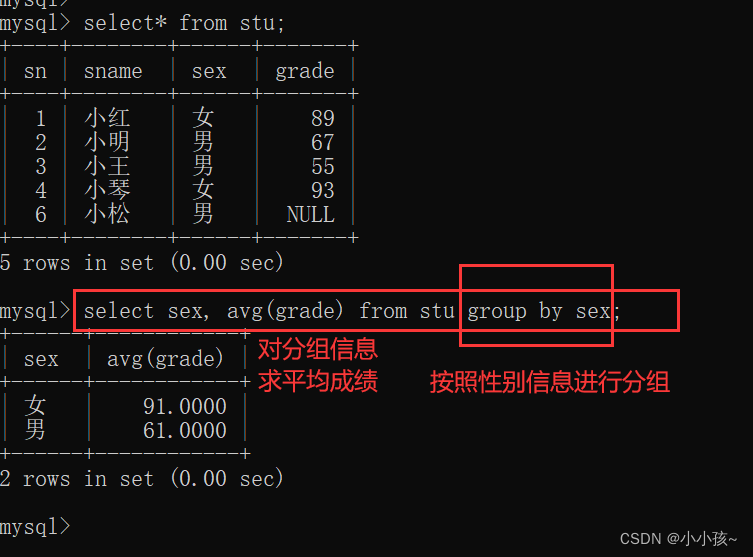
注意:分组查询中需要进行条件过滤时,不能使用 where,而要使用 having
例如在学生信息表中筛选出平均成绩大于80的性别信息:

多表联查
将多张表中的数据进行合并查询---------> 笛卡尔积
给定两张表结果:

内连接
在两张表中数据进行连接时候,找到了符合连接条件的数据则进行连接,找不到符合连接条件的数据则丢弃

内连接:
select* from table1 inner join table2 on condition
内连接结果:

外连接(左连接,右连接)
(1)左连接
左连接:以左表作为基表,在右表中查找符合连接条件的数据,找到了则连接,找不到连接 NULL
左连接:
select* from table1 left join table2 on condition
左连接结果:

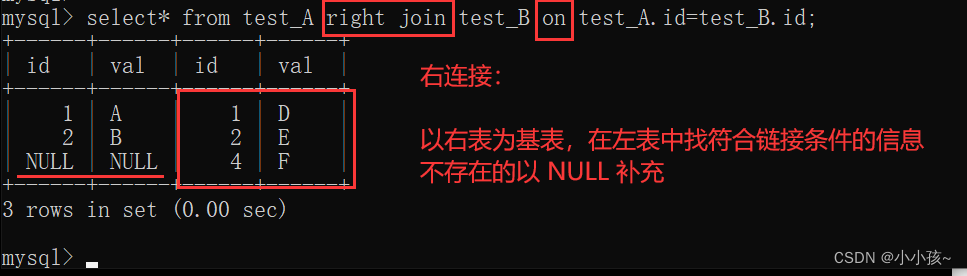
(2)右连接
以右表为基表,在左表中查找符合连接条件的数据,找到了则连接,找不到连接 NULL
右连接:
select* from table1 right join table2 on condition
右连接结果:
自连接
一张表自己连接自己进行查找
在前边查找中,我们都是对于同一条记录中的两个不同字段进行比较查找,但是当我们需要对同一条记录中同一个字段中的信息进行比较----------> 需要将这个字段的两个值并列(连接)起来进行比较,这就需要进行自连接
as :取别名
子查询
一个 sql 语句的查询过滤条件是基于另一条查询语句的结果进行的
//示例:
select * from 表名
where 条件 = (
//当子查询结果只有一条结果时候使用 = ,若存在多条结果则使用 IN
select* from 表名
where 条件 )
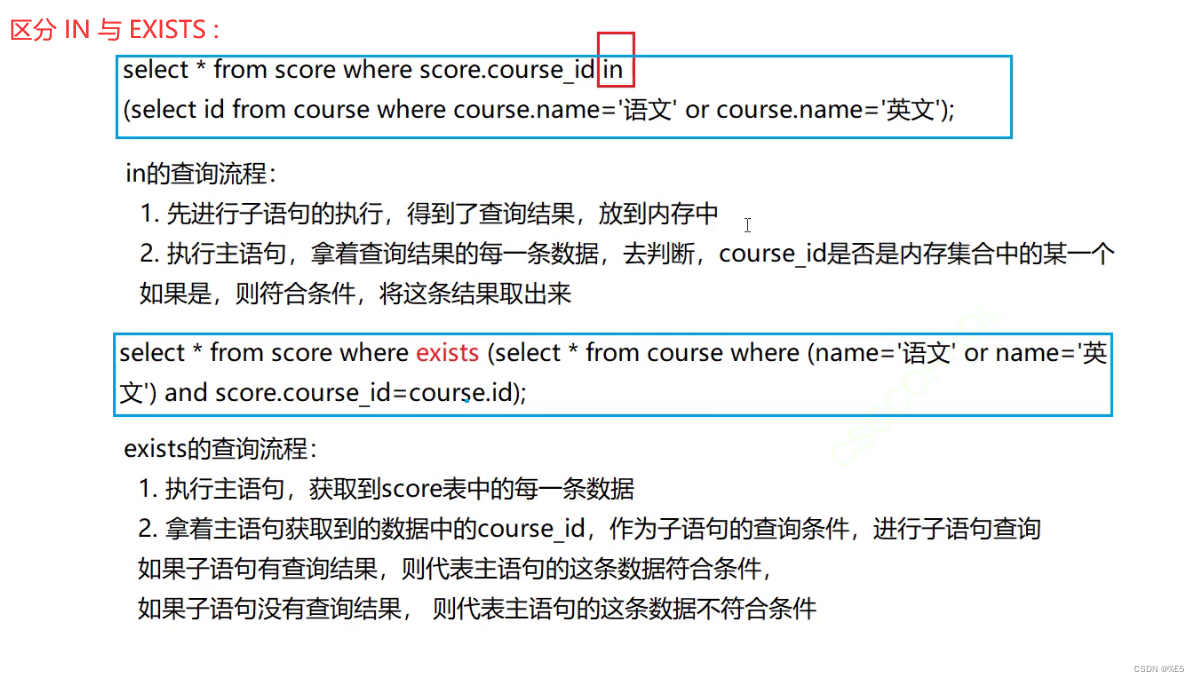
IN 与 EXISTS:
合并查询 UNION
将两条语句的查询结果合并起来进行返回,只有当两条语句的查询结果字段保持一致才能进行合并,UNION会自动去重 (UNION ALL 显示所有合并的结果)