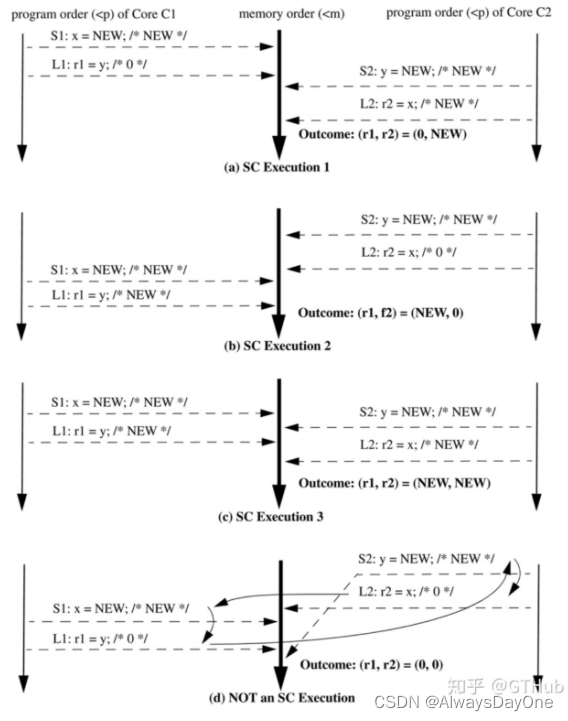
人们总是高估了未来一到两年的变化,低估了未来十年的变革。
---比尔盖茨
近来OpenAI的GPT技术可以说在全球都带来了巨大的影响,也让大家看到了什么叫大力出奇迹。chatGPT和GPT4的能力给了大家很大的震撼,其流畅自如、逻辑清晰、出众的能力,给使用过的人都留下了深刻的印象,同时也让无数人对这项技术产生了担忧和畏惧,其中就包含即将踏入互联网行业的我。
起初在chatGPT刚出来的那段时间,我是抱着了解但未尝试的态度的,知道这项技术很先进,但是不知道其对未来的影响,或许是因为没有亲身去使用导致了对其能力的低估吧。后来其越来越火,GPT4相继问世,我使用之后的感受,我切身感受到了这一技术的变革性。

**gpt是个什么样的技术呢?**生成式预训练的模型,主要用在自然语言生成上,能够处理各种语种的输入和输出,如中文,英文等各种主流语言,不知道是否支持世界上所有有文字资料的语种。
目前gpt的技术主要应用在对话中,即人与计算机进行对话 — chatGPT,能够记忆多轮对话的内容,并结合上下文给出相应的答案,且生成的文本逻辑上,语法上都有很好的准确性。对话的内容不限,从生活常识,到百科,到文学,到各行各业的知识,学术界的,工业界的,都能给出不错的答案。目前关于垂直领域的知识,主要是关于计算机的,不知道其他工科的怎么样。但也并不是毫无缺点,生成的文本可能会有一些事实性错误,编造一些不存在的东西,不能确保准确性,有些泛泛而谈。
综合以上,可以对chatGPT做一个总结:一个拥有强大文本生成能力的模型,能够处理各种问题,理解语言中较复杂的语义,但也存在一些缺点。

现在发展到的gpt4,不仅可以处理文本,还具有了多模态的能力,能够理解图像,生成图像。或许以后能够输入输出更加的自由,可以是文本,语音,图像,视频等,输出亦然。
**关于未来的大模型。**可以沿着发展趋势展开一下想象,在未来的某天:大模型技术取得了更大的进步,其理解人类世界的能力愈发强大,不仅能够以显而易见的方式接收信息,如视、听,或许还能触摸,再加上对现实的理解,AI能做到的事或许和人类没有很大差距,甚至能够在某些方面(很多方面)超越人类。在工作中,你大部分时间在与AI系统打交道,你的上下游是AI系统,你接受AI的任务,解决一些AI暂时不能解决的问题后交给下游的AI来完成;生活中,可能有一个能力超强、且很懂你的AI助手、管家、甚至伴侣,管家能够接管你生活中的绝大部分安排,为你指定各种计划,替你规划、决策,为你的孩子辅导功课;商店里、饭店里,与你交流的可能是服务员。
要实现这样的未来,我们还有多远的,什么样的了路要走呢?
作为一名即将进入互联网行业的学生来说,AI的发展确实让我对自己的职业发展着实担忧了一把。未来AI技术的强大,一些方面的工作会很快被AI技术取代,目前已知的发展空间会被压缩,进而影响自己的工作待遇、职业发展方向。毕竟,未来的变动需要我们花费时间、精力去学习、去适应,还参杂很多不确定性。如果这真的是一场革命,那么肯定会有现在所不知的机会和机遇出现。干好当下的事很重要,但我现在能为未来做什么呢?接下来分析一下发模型对未来的行业的影响。
数据隐私一定是一个首要考虑的因素,因此很多商业化场景中会以安全,隐私为重要的考虑,可能会导致很多公司构建自己的大模型,不一定要达到最优的水平,但能在自己的垂直场景中达到一定的壁垒。各个公司如何构建自己的大模型呢?没有这个能力怎么办?虽然现在很多巨头都在往这个方向发展,但是真正做的好,能商业化的并没有那么多,市场还是一片蓝海。可以想到,这么多的巨头尚不能做的很好,其他的行业、公司有怎么做呢?当然,以后会有更多的公司能够做好,但是还是存在一个分水岭,岭以上的公司有能力做好自己的大模型,以下的公司不会自研或者说会另辟蹊径。有能力的公司可以把自己的大模型以服务的形式向外提供,并以此开展自己的产品。
在大模型掀起的这场革命(如果有)中,未来的软件会是什么样子的呢?现在的软件开发过程,通常需要人来沟通和理解需求,开发完成后进行迭代修改,并进行维护。如果AI能快速、准确地实现需求,或者小的需求块,那我们可能主要负责对需求的划分、细化、整理使其标准化(AI能理解的形式),具体的开发将由AI自动完成,最后再加以测试和人工检查和测试。这个时候可能很多低级(简单,容易被流程化)的开发会被取缔,程序员的工作重点更多放在整体流程的把控和分解上。那个时候,或许我们能开发出更大规模的软件,以更快的速度,类似于流浪地球2中MOSS自动生成操作系统。这个时候的程序员还需要具备手撕代码的能力吗?整体架构、流程的把控和理解或许是更为重要的能力,对技术的广度有更高的要求。
当然,并不是所有地方都会上大模型,但是很可能大家都会使用它。一种方式是对大模型的小型化,或者使小模型同样拥有足够的能力,一种是API的形式,把大模型作为一项服务,在有一种可能是二者的结合,在共有大模型的基础上产品有自己的私有模型。大模型的小型化,这也是业界和学界一直在做的事情,模型的量化、压缩、剪枝、蒸馏等,以及在各种硬件平台上适配。API的形式就不赘述了。我觉得目前还未出现,但是将来很有可能出现的就是第三种情况:共用大模型+私有模型。同样是处于对数据安全性考虑,也是维护自身产品壁垒。依赖大模型构建的产品,数据是其灵魂,也是其壁垒所在,也包括安全问题。如何在这样的约束下用好大模型?个人的一个想法:对大模型的拆解、分析,大模型的扩展能力,大模型与小模型(私有模型很有可能就是小模型)的融合,最好能够做到大模型是一个大软件,小模型则是一个插件,能够很好的借助大模型的能力。
最令我期待的是具身智能 — 我们接触的是具有实体的AI。当前AI技术在很多领域都有了很大的发展,CV、NLP、语音等,但更多的是以工具的形式出现在我们的生活中。但这些技术很多终究是没能达到流程与人类进行交互的能力,但现在我们看到希望了,GPT正在逐步实现(已经?)这一点。以上技术的融合是很有可能出现一个能够数字人的,能够具身,就看未来硬件和机器人技术的发展了。
希望未来不需要担心以上问题。

再放几张《Bicentennial Man》的剧照,希望我以后也能有机器管家(当然不是安德鲁那样的🤣)。




关于gpt的几篇参考论文:
- Improving Language Understanding by Generative Pre-Training(GPT1);
- Language Models are Unsupervised Multitask Learners(GPT2);
- Language Models are Few-Shot Learners(GPT3);
- Training language models to follow instructions with human feedback(InstructGPT);
- GPT-4 Technical Report;