第九周作业
目录
- MT2125 一样的虫子
- MT2126 AB数对
- MT2127 权值计算
- MT2128 黑客小码哥
- MT2129 来给单词分类
MT2125 一样的虫子
难度:黄金 时间限制:1秒 占用内存:128M
题目描述
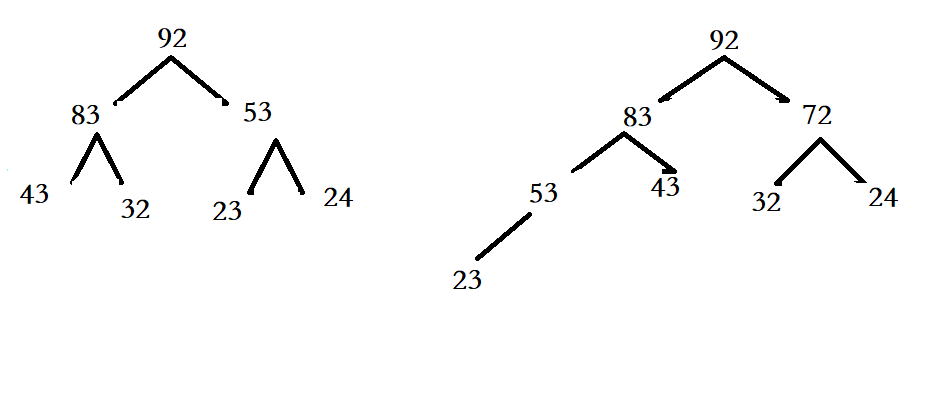
有 N 只虫子,每只虫子有6条腿,每条腿都有长度且长得很奇怪,如下图所示。
第 i i i 只虫子六条腿的长度从某条腿开始依次记为 a 1 , a 2 , … , a 6 a_1,a_2,…,a_6 a1,a2,…,a6 。但是,不同人选择的起始腿不同,记录方向也可能不同(顺时针或逆时针),这就导致记录的序列可能也有所不同。但是,他们所得的六元组序列都代表形状相同的虫子。例如, a 1 , a 2 , … , a 6 a_1,a_2,…,a_6 a1,a2,…,a6 和 a 2 , a 3 , … , a 6 , a 1 a_2,a_3,…,a_6,a_1 a2,a3,…,a6,a1 就是形状相同的虫子; a 1 , a 2 , … , a 6 a_1,a_2,…,a_6 a1,a2,…,a6 和 a 6 , a 5 , … , a 2 , a 1 a_6,a_5,…,a_2,a_1 a6,a5,…,a2,a1 也是形状相同的虫子。我们称两只虫子相同,当且仅当它们各自从某一条腿开始顺时针或逆时针记录长度,能得到两个相同的六元组。
小码哥请你计算这 N 只虫子中是否存在两只相同的虫子。
格式
输入格式:输入的第一行将包含一个整数 n n n ,即要检查的虫子的数量;
接下来是 n n n 行,每行描述一个虫子。每只虫子将由包含六个数 a 1 , a 2 , … , a 6 a_1,a_2,…,a_6 a1,a2,…,a6 的行来描述,即虫子腿的长度。
输出格式:如果所有的虫子都是不同的,你的程序应该打印消息:No;
如果有两只虫子相同,你的程序应该打印消息:found.。样例 1
输入:2
1 2 3 4 5 6
4 3 2 1 6 5输出:found.
备注
其中: 0 ≤ n ≤ 100000 , 0 ≤ a 1 , a 2 , … , a 6 ≤ 100000 0≤n≤100000,0≤a_1,a_2,…,a_6≤100000 0≤n≤100000,0≤a1,a2,…,a6≤100000。
相关知识点:哈希表,集合

题解
本题的实质是对输入数据进行判断:是否出现重复数据。这让我们很直观地意识到,可利用集合这一数据结构。基于这种思路,我们只需要在每次输入数据时,提前判断集合中是否已存在该输入数据:如果是,则直接输出“found.”并结束程序;否则就往集合中插入该数据,并继续接受下一条输入,直到所有数据都顺利插入集合,输出“No”。
但这道题的难点在于:对于某些实际上重复的数据而言,在输入时并不一定完全相同。比如对于下图所示的虫子,可能系统输入的六元组序列为{4, 1, 4, 2, 5, 4}。但是,系统也可能选择从长度为1的腿开始(按顺时针方向)记录,则输入的六元组为 {1, 4, 2, 5, 4, 4};如果按逆时针方向记录,则输入的六元组为 {1, 4, 4, 5, 2, 4}。虽然这三个六元组完全不同(这将导致在往集合中插入这些数据时都能顺利插入),但它们本质上表达的却是同一只虫子(即为一组重复数据),因此我们需要设计相关算法来处理这种情况。

首先要明确一件事:虫子的记录方向仅有两个,顺时针和逆时针。因此在固定某条腿作为起始元素时,同一只虫子最多有两条不同的六元组序列。如此,就能将一只虫子具有的若干种记录方案(6×2=12)降低至2条(或1条)。那要采取怎样的方法实现“固定腿”呢?一种最简单的办法就是选择输入六元组序列中的最值(最大或最小)。比如上面例子中的{1, 4, 2, 5, 4, 4}和{1, 4, 4, 5, 2, 4}就选择了序列中的最小值作为固定起始元素。采用这样的方法记录虫子时,就能得到某个虫子独一无二的两条六元组序列。根据这样的转换方法,再结合前面的思路将输入数据依次插入集合(并判重)就能对本题进行求解。

这里我们再深入思考一个问题,既然可以固定起始腿,那能不能固定记录方向呢?答案是可以,但需要对方向的定义做进一步设置。由于输入的六元组序列方向未知,所以我们并不知道当前序列是按“顺时针”还是“逆时针”方向记录而得。实际上,“顺时针”或“逆时针”对于代码而言根本就是不可见的。所以,若要固定方向,就必须人为地设置一种序列读取规则作为对方向的定义。故此,有以下算法:
- 获取输入序列 ary;
- 寻找序列中最小(大)值的索引,设为 minArg;
- 判断 minArg 前一位元素与后一位元素的大小关系:如果 ary[minArg-1] < ary[minArg+1] 则定义从 minArg 往前扫描得到的序列为当前虫子的唯一六元组序列(称为前向序列);如果 ary[minArg-1] > ary[minArg+1] 则定义从 minArg 往后扫描得到的序列为当前虫子的唯一六元组序列(称为后向序列);如果 ary[minArg-1] = ary[minArg+1] 则两个方向的序列都执行添加。
任意输入在执行此算法后,总能将该六元组序列进行规范化,进而得到关于其对应虫子的唯一(二)标识。接下来就能采用一开始提到的基于集合的算法来完成对重复数据的查找。例如,对于输入的某六元组序列 ary = {3,4,5,4,1,2},程序的执行流程如下:
- 找到最小值索引 4;
- ary[3]=4 > ary[5]=2,因此需要从第 4 个索引开始构建后向序列,即:{1,2,3,4,5,4}。
即认为这只虫子存在唯一标识{1,2,3,4,5,4}。
下面给出基于以上思路得到的完整代码(已 AC):
/*
MT2125 一样的虫子
*/
#include<bits/stdc++.h>
using namespace std;
// 设置腿的个数
const int LEG = 6;
int ary[LEG];
// 定义集合
set<string> s;
bool insertInsect(int ary[]){
// 获取数组中最小值的索引
int minArg = 0;
for(int i=1;i<LEG;i++)
if(ary[i] < ary[minArg])
minArg = i;
// 若最小值前的数据小于最小值后的数据,则构建前向序列并执行添加
string str = "";
if(ary[minArg==0?LEG-1:minArg-1] < ary[minArg==LEG-1?0:minArg+1]){
// 构建前向扫描序列
for(int i=0; i<LEG; i++)
str += to_string(ary[(minArg+LEG-i)%LEG])+",";
// 向集合中添加前向扫描序列
if(s.find(str) == s.end()) s.insert(str);
else return false;
}
// 若最小值前的数据大于最小值后的数据,则构建后向序列并执行添加
else if(ary[minArg==0?LEG-1:minArg-1] > ary[minArg==LEG-1?0:minArg+1]){
// 构建后向扫描序列
for(int i=0; i<LEG; i++)
str += to_string(ary[(minArg+i)%LEG])+",";
// 向集合中添加后向扫描序列
if(s.find(str) == s.end()) s.insert(str);
else return false;
}
// 若数组最小值前后的值相等,就都执行添加
else{
string str_ = "";
// 构建前向扫描序列
for(int i=0; i<LEG; i++)
str += to_string(ary[(minArg+LEG-i)%LEG])+",";
// 构建后向扫描序列
for(int i=0; i<LEG; i++)
str_ += to_string(ary[(minArg+i)%LEG])+",";
// 向集合中添加前向扫描序列
if(s.find(str) == s.end()) s.insert(str);
else return false;
// 如果前、后向扫描序列不等,则继续添加后向扫描序列(以排除所有腿长度一致的情况)
if(str != str_)
if(s.find(str_) == s.end()) s.insert(str_);
else return false;
}
// 认为当前插入的序列是唯一
return true;
}
int main( )
{
int n; cin>>n;
for(int i=0;i<n;i++){
for(int j=0;j<LEG;j++) cin>>ary[j];
if(!insertInsect(ary)){
cout<<"found."<<endl;
return 0;
}
}
cout<<"No"<<endl;
return 0;
}
MT2126 AB数对
难度:黄金 时间限制:1秒 占用内存:128M
题目描述
给出一串数以及一个数字 C,要求计算出所有 A-B=C 的数对个数。
格式
输入格式:输入共两行,第一行两个整数 n , C ( 1 ≤ n ≤ 200000 , 1 ≤ C ≤ 30 ) n ,C (1≤n≤200000,1≤C≤30) n,C(1≤n≤200000,1≤C≤30);
第二行 n 个整数作为要求处理的那串数。
输出格式:一行表示该串数中包含的满足 A-B=C 的数对的个数。样例1
输入:4 1
1 1 2 3输出:3
相关知识点:
哈希表
题解
本题旨在寻找差值为 C 的所有数对(即A-B=C中的A和B)。最简单直接的方式就是暴力枚举,对每个数都将其与输入序列中的其他数进行做差,如果差值为 C 就记符合题意的数对个数ans++,这样求解的时间复杂度为 O(n^2 )。但是题目给出的数串长度最多达到了20 0000,因此暴力法肯定是拿不到满分的。所以必须想想其他的求解方法。
对于任意数A,如果有A-B=C成立,则对A而言,其目标数即为A-C=B。因此在输入数据时,对每个A我们都可以立即得到与其匹配的B。那么接下来只要知道B在输入数据中出现了几次就能马上得到当前数A的数对次数。基于这样的思路,可以利用字典这一数据结构来构建每个数的出现次数,然后再扫描一次原始输入的数串,并从字典里获取A-C的出现次数以累加即能得到最终满足A-B=C的所有数对个数。
下面给出基于以上思路写出的完整代码(已 AC):
/*
MT2126 AB数对
map使用技巧:
当map中的value为基本数据类型时,value值默认为0(或‘\0’)
*/
#include<bits/stdc++.h>
using namespace std;
// 相关数据结构的定义
const int MAX = 200005;
int ary[MAX];
map<int, int> m;
int main( )
{
// 录入数据
int n, C;cin>>n>>C;
for(int i=0;i<n;i++){
cin>>ary[i];
m[ary[i]]++;
// 这里将每个数与 C 的差值进行原地求解
ary[i] -= C;
}
// 统计每个数作为被减数时,其对应减数出现过多少次(这两个数即构成了一组数对)
long ans = 0;
for(int i=0;i<n;i++) ans += m[ary[i]];
// 输出数对个数
cout<<ans<<endl;
return 0;
}
MT2127 权值计算
难度:黄金 时间限制:1秒 占用内存:128M
题目描述
对于一个长度为 n n n 的数组 a a a,我们定义它的权值 w a w_a wa。若 a a a 中存在数 x x x 满足 x x x 在整个数组中出现的次数大于等于 x x x 本身,这样的 x x x 中最大的一个就是 a a a 的权值 w a w_a wa ;若不存在这样的 x x x ,则该数组的权值为 0。现在小码哥给你一个数组,请你计算它的权值。
格式
输入格式:第一行输入一个正整数 n ( n ∈ [ 1 , 1 × 1 0 5 ] ) n(n∈[1,1×10^5 ]) n(n∈[1,1×105]);
第二行输入 n 个由空格隔开的整数,表示数组中的数,它们均在 [ 0 , 1 × 1 0 5 ] [0,1×10^5 ] [0,1×105] 内。
输出格式:输出该数组的权值。样例 1
输入:6
0 1 5 5 2 2
输出:2
相关知识点:
哈希表
题解
本题更像是一道模拟类型的题目,不过用到了 map 作为统计每个数字出现次数的数据结构。这里需要注意一些编码上的技巧:由于题目需要统计的是“数组中出现次数大于等于数字本身(相同时取最大)的数”,因此我们在遍历已构建好的 map 时需要按 key 排序,然后再根据 key 进行从大到小的扫描,这样一来,当找到第一个满足“出现次数大于等于数字本身”的数时,该数即为所求。幸运的是,STL 很人性化,当 map 的 key 为基本数据类型时,其构建过程已经默认按 key 值进行升序排列。
下面直接给出求解本题的完整代码(已 AC):
/*
MT2127 权值计算
map使用技巧:
当map中的key为基本数据类型时,其默认按key值升序排列
*/
#include<bits/stdc++.h>
using namespace std;
// 定义数组最大长度
const int MAX = 100005;
// 变量申明
int ary[MAX];
map<int, int> m;
// 寻找数组中某元素出现次数大于其本身的最大元素
int getWeight(int ary[], int n){
// 遍历所有字符串,统计每个数字的出现次数
for(int i=0; i<n; i++)
m[ary[i]]++;
// 遍历 map 寻找最大的出现次数大于其本身的元素(因此这里用的是反向迭代器)
for(auto iter = m.rbegin(); iter!=m.rend(); iter++)
if(iter->second >= iter->first)
return iter->first;
return 0;
}
int main()
{
// 录入数据
int n; cin>>n;
for(int i=0;i<n;i++) cin>>ary[i];
// 输出权值
cout<<getWeight(ary, n)<<endl;
return 0;
}
MT2128 黑客小码哥
难度:黄金 时间限制:1秒 占用内存:128M
题目描述
小码哥是一名黑客,他最近刚彩票中奖,由于还没兑换,小码哥十分担心彩票被盗(小码哥过分谨慎了),他想为自己的保险箱设新的密码,顺便想让你帮忙测试一种加密算法。
该加密算法主要有以下两种编码方式:
- 对于已知字符串中的某种字符,全部变成另一种字符。如里面出现的A全部换成B;
- 对于当前字符串,打乱字符顺序。
现给你一个加密后的字符串和加密前的字符串,判断加密前的字符串是否能由上述加密算法得到加密后的字符串。字符串中字符均为大写字母。
格式
输入格式:输入数据有多组,每组两行;
第一行为加密后的字符串;
第二行为加密前的字符串。
输出格式:输出YES或NO。样例 1
输入:JWPUDJSTVP
VICTORIOUS
MAMA
ROME
HAHA
HEHE
AAA
AAA
NEERCISTHEBEST
SECRETMESSAGES输出:YES
NO
YES
YES
NO备注
所有字符串长度不超过100。
相关知识点:
哈希表
题解
这道题的描述非常混乱,不看视频几乎很难理解他想要你做什么。下面对其进行一个大致的解读:
现在有一种字符加密算法,其只有两种规则:
- 字符替换(如所有 “A” 替换为 “B”)
- 字符顺序变换(如从“AABCDD”变成“BCAADD”或“AADDBC”)
至于其具体的替换、顺序规则是怎样的,我们并不得知。
然后接下来题目输入若干组询问,每次询问给出两行字符串,问这两行字符串是否有可能是经过此加密算法处理前后的两字符串。特别注意:是对“是否有可能”做出回应。这很容易理解,因为具体的规定我们都不清楚,而是仅知道它大致的规则,所以这里我们判断的是“哪一对字符串绝不可能是加密前后的两串”。
思路:分析上述规则会发现,该加密算法实际上只会改变某个字符串中的字符和顺序,因此,若要对比两个字符串是否为经过此加密算法处理前后的两个字符串,实际上就只需要判断“两个字符串内,由不同字符的出现次数构成的数字序列是否一致”。如,str1=“AABSBA” ,其各字符出现次数情况为 A:3, B:2, S:1,故得到序列 [3,2,1]; str2=“ZYTTYT” ,其各字符出现次数情况为 Z:1, Y:2, T:3,故得到序列 [1,2,3]。因此认为:这两字符串有可能是此加密算法处理前后的两个字符串。因为有可能该加密算法就是存在字符替换规则“A→T、B→Y、S→Z”,字符顺序变换规则“AABSBA→SBAABA”,从而使得上述字符串 str1 和 str2 成为该加密算法加密前后的两串字符。反之,当由两个字符串中不同字符出现次数构成的数字序列不一致时,这就绝不可能是该加密算法加密前后的两个字符串。
所以这道题本质也是“统计不同字符出现次数”的题,因而又要用到map。
下面给出基于上述思路得到的完整代码(已 AC):
/*
MT2128 黑客小码哥
*/
#include<bits/stdc++.h>
using namespace std;
const int LETERCNT = 26;
// 判断两个字符串是否有可能是经过指定加密算法处理前后的两串
bool isSamePossiblely(string str1, string str2){
// 长度不同就一定不是
int strlen = str1.length();
if(strlen != str2.length()) return false;
// 否则进一步判断各字符的出现次数是否一致
int ary1[LETERCNT]={0}, ary2[LETERCNT]={0};
// 先统计各字符串中不同字符的出现次数(即认为存在字符变换操作)
for(int i=0; i<strlen; i++){
ary1[str1[i]-'A']++;
ary2[str2[i]-'A']++;
}
// 消除字符间的顺序差异(即认为存在字符顺序变换操作)
sort(ary1, ary1+LETERCNT);
sort(ary2, ary2+LETERCNT);
// 判断是否可能是变换前后的两字符串
for(int i=0;i<LETERCNT;i++)
if(ary1[i] != ary2[i])
return false;
return true;
}
int main()
{
string str1, str2;
while(cin>>str1>>str2) {
if(isSamePossiblely(str1, str2)) cout<<"YES"<<endl;
else cout<<"NO"<<endl;
}
return 0;
}
MT2129 来给单词分类
难度:钻石 时间限制:1秒 占用内存:128M
题目描述
现有如下单词分类原则:两个单词可以分为一类当且仅当组成这两个单词的各个字母的数量均相等。
现有 n n n 个单词均由大写字母组成,每个单词长度小于等于100。求单词被分为几类。格式
输入格式:第一行输入单词个数 n n n;
接下来 n n n 行每行一个单词。
输出格式:一个整数表示类数。样例1
输入:3
AABAC
CBAAA
AAABB输出:2
备注
对于 70% 的数据满足 n ≤ 100 n≤100 n≤100;
对于 100% 的数据满足 n ≤ 10000 n≤10000 n≤10000。
相关知识点:
哈希表,集合
题解
这道题 “MT2125 一样的虫子” 有点类似,本质都是判断重复元素,因此也需要用到集合。但是这道题的不同点在于:
- 将“判断元素是否重复”变为“统计总类别数”;
- 输入数据为字符串而非数组。
对于第 1 点,只需要输出最终的集合规格即可;对于第 2 点,只需要对字符串进行排序即可(这就消除了字符串内各字符的顺序差异),反而更简单。因此,求解本题的思路也更简单:接受输入、对各字符串排序、全部插入集合(这一步会过滤同一类单词)、输出集合规格。
此处值得一提的是字符串排序函数(即 sort() 函数),当sort()中的传递参数为 string 类型时,其必须传入待排序 string 的头和尾位置,此时其传入参数应该为 sort(str.begin(), str.end()),第三个参数决定了对该字符串的排序规则(默认缺省时将按字符升序排列),如果想要进行降序排列,则第三个参数为 greater<type>()(此处可写 greater<int>())。
下面给出基于以上思路得到的完整代码(已 AC):
/*
MT2129 来给单词分类
统计异质字符串的类别数
*/
#include<bits/stdc++.h>
using namespace std;
// 定义字符串最大长度
const int MAX = 10005;
// 变量申明
string strs[MAX];
set<string> s;
// 统计异质字符串中的类别数
int getClassNum(string strs[], int n){
// 遍历所有字符串
for(int i=0; i<n; i++){
// 将每个字符串单独排序
sort(strs[i].begin(), strs[i].end());
// 插入集合
s.insert(strs[i]);
}
return s.size();
}
int main()
{
// 录入数据
int n; cin>>n;
for(int i=0;i<n;i++) cin>>strs[i];
// 输出类别数
cout<<getClassNum(strs, n)<<endl;
return 0;
}