前言
无论是在开发过程中还是在准备跑路的面试过程中,和Redis相关的话题,难免会涉及到四个特殊场景:缓存穿透、缓存雪崩、缓存击穿以及数据一致性。
虽然在作为服务缓存层的时候Redis确实能极大减少服务端的请求压力,但是如果在开发中不注意这些场景的话,在高并发场景下有可能会导致系统崩溃,数据错乱等情况。Now,笔者结合学习过程中的一些实际的业务场景来复现并解决这些问题。
缓存穿透
缓存穿透是指查询一个不存在的数据,在缓存层和持久层都查询不到,这样查不到的数据不会写入缓存,这样一个不存在的数据每次的请求都会去查询持久层,缓存也就失去了保护后端持久层的意义了。最严重的后果就是是后端存储负载加大,造成后端存储宕机。
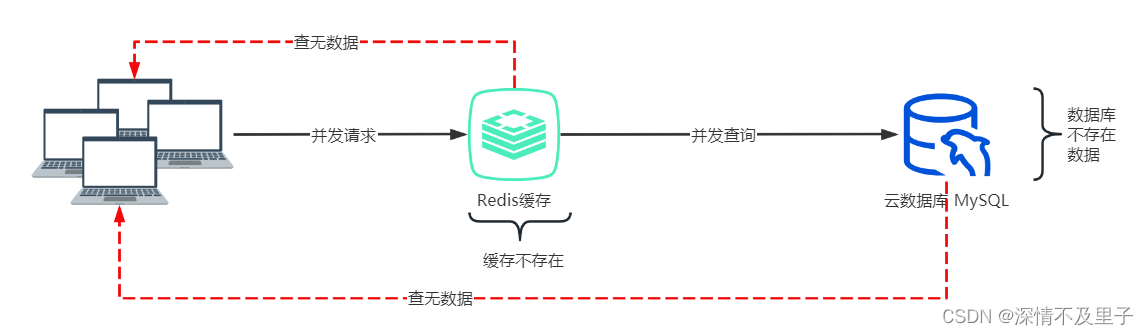
比如现在对一条测试数据进行缓存,一般的逻辑是先查询缓存中是否存在该数据,如果存在则直接返回,否则再查询数据库并将查询结果进行缓存。这里用注解的方式实现缓存。
@Cacheable(key = "#id")
public RedisTest findById(Integer id) {
RedisTest all = redisTestDao.findAllByIdRedisTest(id);
log.info("查询数据库---》{}",id);
return StringUtils.isEmpty(all)?null:all;一般情况而言,并没有什么不妥之处。但是如果出现一些恶意攻击的情况,出现大量请求去查询一个并不存在的数据,如果设置结果为null时不进缓存就会大量查询数据库,严重造成数据库宕机。如果进入缓存,就会使空数据与正常数据一样过期,一样造成内存浪费。
解决方案1:对空值设置更短的过期时长
@Cacheable(key = "#id")
public RedisTest findById(Integer id) {
RedisTest all = redisTestDao.findAllByIdRedisTest(id);
log.info("查询数据库---》{}",id);
if (StringUtils.isEmpty(all)){
redisTemplate.opsForValue().set(String.valueOf(id),"", Duration.ofMinutes(5));
return null;
}
return all;
}这样查询一次数据库后,后续全部存放空数据,并且空数据能更快清除,而不影响内存释放。
2023-04-25 17:21:40.836 INFO 21712 --- [nio-8090-exec-2] com.yy.Aspect.LogAspect : 访问时间:2023-04-25T17:21:40.836--访问接口:R com.yy.redisCache.controller.RedisCacheController.getById(Integer)
Creating a new SqlSession
SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@8ade77b] was not registered for synchronization because synchronization is not active
JDBC Connection [HikariProxyConnection@1951093559 wrapping com.mysql.cj.jdbc.ConnectionImpl@4c983b3a] will not be managed by Spring
==> Preparing: select * from redis_test where id =?
==> Parameters: 1(Integer)
<== Total: 0
Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@8ade77b]
2023-04-25 17:21:40.910 INFO 21712 --- [nio-8090-exec-2] c.y.r.service.impl.RedisTestServiceImpl : 查询数据库---》1
2023-04-25 17:21:52.178 INFO 21712 --- [nio-8090-exec-7] com.yy.Aspect.LogAspect : 访问时间:2023-04-25T17:21:52.178--访问接口:R com.yy.redisCache.controller.RedisCacheController.getById(Integer)
2023-04-25 17:21:52.180 INFO 21712 --- [nio-8090-exec-2] com.yy.Aspect.LogAspect : 访问时间:2023-04-25T17:21:52.180--访问接口:R com.yy.redisCache.controller.RedisCacheController.getById(Integer)
2023-04-25 17:21:52.180 INFO 21712 --- [nio-8090-exec-1] com.yy.Aspect.LogAspect : 访问时间:2023-04-25T17:21:52.180--访问接口:R com.yy.redisCache.controller.RedisCacheController.getById(Integer)
2023-04-25 17:21:52.180 INFO 21712 --- [nio-8090-exec-8] com.yy.Aspect.LogAspect : 访问时间:2023-04-25T17:21:52.180--访问接口:R com.yy.redisCache.controller.RedisCacheController.getById(Integer)
2023-04-25 17:21:52.180 INFO 21712 --- [nio-8090-exec-5] com.yy.Aspect.LogAspect : 访问时间:2023-04-25T17:21:52.180--访问接口:R com.yy.redisCache.controller.RedisCacheController.getById(Integer)
2023-04-25 17:21:52.180 INFO 21712 --- [nio-8090-exec-4] com.yy.Aspect.LogAspect : 访问时间:2023-04-25T17:21:52.180--访问接口:R com.yy.redisCache.controller.RedisCacheController.getById(Integer)
2023-04-25 17:21:52.180 INFO 21712 --- [io-8090-exec-10] com.yy.Aspect.LogAspect : 访问时间:2023-04-25T17:21:52.180--访问接口:R com.yy.redisCache.controller.RedisCacheController.getById(Integer)
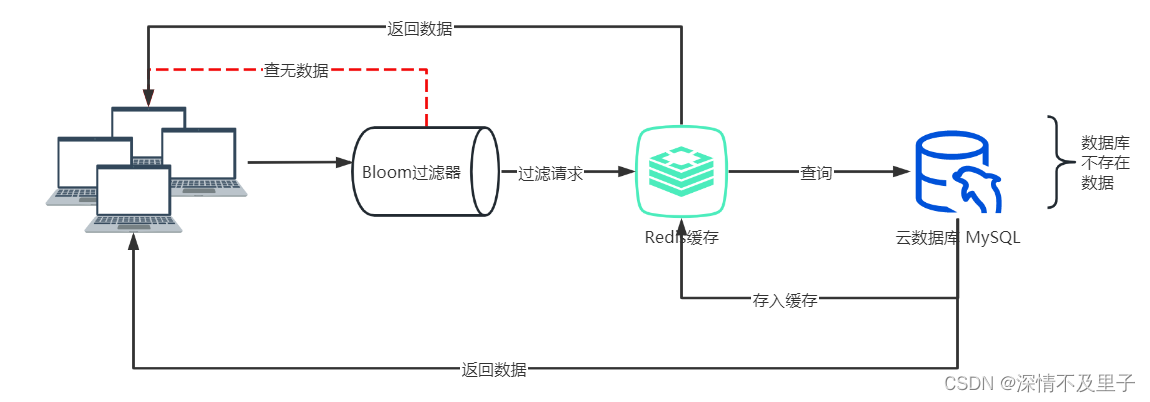
解决方案2:布隆过滤器
布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
Bloom Filter 原理
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
Bloom Filter跟单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。

Bloom Filter的缺点
bloom filter之所以能做到在时间和空间上的效率比较高,是因为牺牲了判断的准确率、删除的便利性。
-
存在误判,可能要查到的元素并没有在容器中,但是hash之后得到的k个位置上值都是1。如果bloom filter中存储的是黑名单,那么可以通过建立一个白名单来存储可能会误判的元素。
-
删除困难。一个放入容器的元素映射到bit数组的k个位置上是1,删除的时候不能简单的直接置为0,可能会影响其他元素的判断。
Bloom Filter的实现
在使用布隆过滤器时有两个核心参数,分别是预估的数据量size以及期望的误判率fpp,这两个参数我们可以根据自己的业务场景和数据量进行自主设置。在实现布隆过滤器时,有两个核心问题,分别是hash函数的选取个数n以及确定bit数组的大小len。
1,根据预估数据量size和误判率fpp,可以计算出bit数组的大小len。

2.根据预估数据量size和bit数组的长度大小len,可以计算出所需要的hash函数个数n。

项目中这里用Hutool工具包中布隆过滤器来实现,通过指定BitMap就能创建一个BitMapBloomFilter来使用。
Step1:创建BitMapBloomFilter的Bean
创建一个配置类,指定BitMap大小、创建过滤器对象并注入Spring容器。
@Configuration
public class RedisConfig {
@Bean
public BitMapBloomFilter bitMapBloomFilter(){
//指定布隆过滤器BitMap的大小
return new BitMapBloomFilter(10);
}Step2:初始化布隆过滤器中的数据
将需要查询的数据放入布隆过滤器,这样进行查询时会先通过过滤器过滤不存在的查询条件,然后再查缓存或数据库。
package com.yy.redisCache.util;
import cn.hutool.bloomfilter.BitMapBloomFilter;
import cn.hutool.core.collection.CollUtil;
import com.yy.redisCache.pojo.RedisTest;
import com.yy.redisCache.service.impl.RedisTestServiceImpl;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
import java.util.List;
/**
* @author young
* Date 2023/4/26 10:30
* Description: 初始化布隆过滤器,将查询的id对应的key存入过滤器
*/
@Component
public class BloomFilterInitData {
@Resource
private RedisTestServiceImpl redisTestService;
@Resource
private BitMapBloomFilter bitMapBloomFilter;
@PostConstruct
public void initMethod() {
List<RedisTest> testList = redisTestService.lambdaQuery().select(RedisTest::getId).list();
if (CollUtil.isNotEmpty(testList)) {
testList.stream().map(data -> {
return "test::" + data.getId();
}).forEach(bitMapBloomFilter::add);
}
}
}Step3:修改业务类中的查询逻辑
@Service
@Slf4j
@CacheConfig(cacheNames = "test")//缓存名,和管理器中配置的一致
public class RedisTestServiceImpl extends ServiceImpl<RedisTestDao, RedisTest> implements RedisTestService {
@Resource
private RedisTestDao redisTestDao;
@Autowired
private RedisTemplate<String,String> redisTemplate;
@Resource
private BitMapBloomFilter bitMapBloomFilter;
@Override
public RedisTest bloomData(Integer id) {
String key = "test::" + id;
boolean has = bitMapBloomFilter.contains(key);
if (!has){
log.info("数据不存在,过滤----" );
return null;
}
String s = redisTemplate.opsForValue().get(key);
RedisTest redisTest = null;
if (CharSequenceUtil.isNotEmpty(s)){
log.info("查询缓存----");
redisTest = JSONUtil.toBean(s,RedisTest.class);
}else {
log.info("查询数据库----" );
redisTest = lambdaQuery().eq(RedisTest::getId,id).one();
if (ObjectUtil.isNotEmpty(redisTest)){
redisTemplate.opsForValue().set("test::" + id,JSONUtil.toJsonStr(redisTest),2L, TimeUnit.MINUTES);
}
}
return redisTest;
}
}这样面对大量不存在的数据执行查询访问时,先通过布隆过滤器过滤一些没有结果的数据,防止直接查询数据库或进入缓存,然后将有结果的数据查询数据库后放入缓存,一定程度上减少了缓存内存压力,又防止多次直接操作数据库层。
Step4:测试
创建控制层接口,进行接口测试。
@GetMapping("get/bloom")
public R<RedisTest> bloom(@RequestParam Integer id){
RedisTest test = service.bloomData(id);
if (ObjectUtil.isNotEmpty(test)){
return R.ok(test);
} return R.fail(null);
}通过测试工具ApiPost进行自动化,模拟20条请求,id范围为1~5(随机),其中1~3的id无数据。
测试成功后查看日志可发现,在并行请求时,一次请求时间执行内其他的请求也会查询数据库,但是有数据的部分放入缓存后,后期就之查缓存就行了,而不存在结果的数据已经被布隆过滤器完全过滤了。
2023-04-26 15:12:42.269 INFO 19080 --- [io-8090-exec-22] com.yy.Aspect.LogAspect : 访问时间:2023-04-26T15:12:42.269--访问接口:R com.yy.redisCache.controller.RedisCacheController.bloom(Integer)
2023-04-26 15:12:42.269 INFO 19080 --- [io-8090-exec-22] c.y.r.controller.RedisCacheController : 进入测试的id---》2
2023-04-26 15:12:42.269 INFO 19080 --- [io-8090-exec-22] c.y.r.service.impl.RedisTestServiceImpl : 数据不存在,过滤----
2023-04-26 15:12:42.298 INFO 19080 --- [nio-8090-exec-4] com.yy.Aspect.LogAspect : 访问时间:2023-04-26T15:12:42.298--访问接口:R com.yy.redisCache.controller.RedisCacheController.bloom(Integer)
2023-04-26 15:12:42.300 INFO 19080 --- [nio-8090-exec-4] c.y.r.controller.RedisCacheController : 进入测试的id---》3
2023-04-26 15:12:42.300 INFO 19080 --- [nio-8090-exec-4] c.y.r.service.impl.RedisTestServiceImpl : 数据不存在,过滤----
2023-04-26 15:12:42.316 INFO 19080 --- [io-8090-exec-26] com.yy.Aspect.LogAspect : 访问时间:2023-04-26T15:12:42.316--访问接口:R com.yy.redisCache.controller.RedisCacheController.bloom(Integer)
2023-04-26 15:12:42.318 INFO 19080 --- [io-8090-exec-26] c.y.r.controller.RedisCacheController : 进入测试的id---》3
2023-04-26 15:12:42.318 INFO 19080 --- [io-8090-exec-26] c.y.r.service.impl.RedisTestServiceImpl : 数据不存在,过滤----
2023-04-26 15:12:42.335 INFO 19080 --- [io-8090-exec-21] com.yy.Aspect.LogAspect : 访问时间:2023-04-26T15:12:42.335--访问接口:R com.yy.redisCache.controller.RedisCacheController.bloom(Integer)
2023-04-26 15:12:42.336 INFO 19080 --- [io-8090-exec-21] c.y.r.controller.RedisCacheController : 进入测试的id---》4
2023-04-26 15:12:42.359 INFO 19080 --- [io-8090-exec-21] c.y.r.service.impl.RedisTestServiceImpl : 查询数据库----
2023-04-26 15:12:42.408 INFO 19080 --- [io-8090-exec-23] com.yy.Aspect.LogAspect : 访问时间:2023-04-26T15:12:42.408--访问接口:R com.yy.redisCache.controller.RedisCacheController.bloom(Integer)
2023-04-26 15:12:42.408 INFO 19080 --- [io-8090-exec-23] c.y.r.controller.RedisCacheController : 进入测试的id---》4
2023-04-26 15:12:42.431 INFO 19080 --- [io-8090-exec-23] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-26 15:12:42.449 INFO 19080 --- [nio-8090-exec-9] com.yy.Aspect.LogAspect : 访问时间:2023-04-26T15:12:42.449--访问接口:R com.yy.redisCache.controller.RedisCacheController.bloom(Integer)
2023-04-26 15:12:42.449 INFO 19080 --- [nio-8090-exec-9] c.y.r.controller.RedisCacheController : 进入测试的id---》4
2023-04-26 15:12:42.472 INFO 19080 --- [nio-8090-exec-9] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-26 15:12:42.489 INFO 19080 --- [io-8090-exec-25] com.yy.Aspect.LogAspect : 访问时间:2023-04-26T15:12:42.488--访问接口:R com.yy.redisCache.controller.RedisCacheController.bloom(Integer)
2023-04-26 15:12:42.489 INFO 19080 --- [io-8090-exec-25] c.y.r.controller.RedisCacheController : 进入测试的id---》4
2023-04-26 15:12:42.511 INFO 19080 --- [io-8090-exec-25] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-26 15:12:42.530 INFO 19080 --- [io-8090-exec-14] com.yy.Aspect.LogAspect : 访问时间:2023-04-26T15:12:42.530--访问接口:R com.yy.redisCache.controller.RedisCacheController.bloom(Integer)
2023-04-26 15:12:42.531 INFO 19080 --- [io-8090-exec-14] c.y.r.controller.RedisCacheController : 进入测试的id---》3
2023-04-26 15:12:42.531 INFO 19080 --- [io-8090-exec-14] c.y.r.service.impl.RedisTestServiceImpl : 数据不存在,过滤----
2023-04-26 15:12:42.549 INFO 19080 --- [nio-8090-exec-8] com.yy.Aspect.LogAspect : 访问时间:2023-04-26T15:12:42.549--访问接口:R com.yy.redisCache.controller.RedisCacheController.bloom(Integer)
2023-04-26 15:12:42.549 INFO 19080 --- [nio-8090-exec-8] c.y.r.controller.RedisCacheController : 进入测试的id---》3
2023-04-26 15:12:42.549 INFO 19080 --- [nio-8090-exec-8] c.y.r.service.impl.RedisTestServiceImpl : 数据不存在,过滤----
2023-04-26 15:12:42.566 INFO 19080 --- [io-8090-exec-24] com.yy.Aspect.LogAspect : 访问时间:2023-04-26T15:12:42.566--访问接口:R com.yy.redisCache.controller.RedisCacheController.bloom(Integer)
2023-04-26 15:12:42.566 INFO 19080 --- [io-8090-exec-24] c.y.r.controller.RedisCacheController : 进入测试的id---》5
2023-04-26 15:12:42.589 INFO 19080 --- [io-8090-exec-24] c.y.r.service.impl.RedisTestServiceImpl : 查询数据库----缓存击穿
当某个key成为一个热点(商品秒杀时)时,这样处于一个集中式高并发的情况下,如果key突然失效一瞬间,请求就会马上击穿缓存层,直接请求数据库,这样后端负载会很快过载甚至崩溃。这样就形成了缓存击穿。

针对缓存击穿问题,有两种解决方案,一种是对热点数据不设置过期时间,另一种是采用互斥锁的方式。
解决方案一:热点数据不设置过期时间
热点数据不设置过期时间,当后台更新热点数据数需要同步更新缓存中的数据,这种解决方式适用于不严格要求缓存一致性的场景。实现方式就使不设置ttl即可,不具体演示。
解决方案二:使用互斥锁
如果是单机部署的环境下可以使用synchronized或lock来处理,保证同时只能有一个线程来查询数据库,其他线程可以等待数据缓存成功后在被唤醒,从而直接查询缓存即可。如果是分布式部署,可以采用分布式锁来实现互斥。
package com.yy.redisCache.util;
import cn.hutool.core.text.CharSequenceUtil;
import cn.hutool.core.util.StrUtil;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeUnit;
/**
* @author young
* Date 2023/4/26 15:36
* Description: redis互斥锁实现
*/
@Component
public class RedisLock {
@Autowired
private RedisTemplate<String ,String> redisTemplate;
/**
* 互斥锁
* @param k 对应redis中的key
* @param v 存放的锁标识
* @param expire 过期时间
* @return
*/
public boolean setLock(String k,String v,long expire){
Boolean absent = redisTemplate.opsForValue().setIfAbsent(k, v, expire, TimeUnit.MINUTES);
if (Boolean.TRUE.equals(absent)){
return true;
}
//如果线程没有获取锁,则在此处循环获取
return setLock(k,v,expire);
}
/**
* 释放锁
* @param k 对应redis中的jey
* @param v 锁标识
*/
public void unlock(String k,String v){
String s = redisTemplate.opsForValue().get(k);
if (CharSequenceUtil.equals(s,v)){
//避免锁被其他线程误删
redisTemplate.delete(k);
}
}
}重新改进业务层代码,在进行数据库查询之前加锁,当数据读取完成后再释放锁。
@Override
public RedisTest lockData(Integer id) {
String key = "test::" + id;
boolean has = bitMapBloomFilter.contains(key);
if (!has){
log.info("数据不存在,过滤----" );
return null;
}
String s = redisTemplate.opsForValue().get(key);
RedisTest redisTest = null;
if (CharSequenceUtil.isNotEmpty(s)){
log.info("查询缓存----");
redisTest = JSONUtil.toBean(s,RedisTest.class);
}else {
//创建锁对应的id标识
String uid = IdUtil.simpleUUID();
String lockKey = key+"::lock";
boolean b = redisLock.setLock(lockKey, uid, 1);
if (b){
try{
//加锁如果成功先查缓存
s = redisTemplate.opsForValue().get(key);
if (CharSequenceUtil.isNotEmpty(s)){
log.info("查询缓存----");
redisTest = JSONUtil.toBean(s,RedisTest.class);
}else {
log.info("查询数据库----" );
redisTest = lambdaQuery().eq(RedisTest::getId,id).one();
if (ObjectUtil.isNotEmpty(redisTest)){
//设置一秒的缓存测试并发效果
redisTemplate.opsForValue().set("test::" + id,JSONUtil.toJsonStr(redisTest),1L, TimeUnit.SECONDS);
}
}
}finally {
//释放锁
redisLock.unlock(lockKey,uid);
}
}
}
return redisTest;
}测试并发条件下的的效果,这里用20个请求模拟并发,实际每秒完成12个请求,也就是说在只设置了1秒缓存的情况下,某个时间段必然会查询数据库,但是在执行这一次数据库操作的时间内其他请求并不会多次查询数据库,而是等缓存重新建立后再查询建立缓存后的数据。
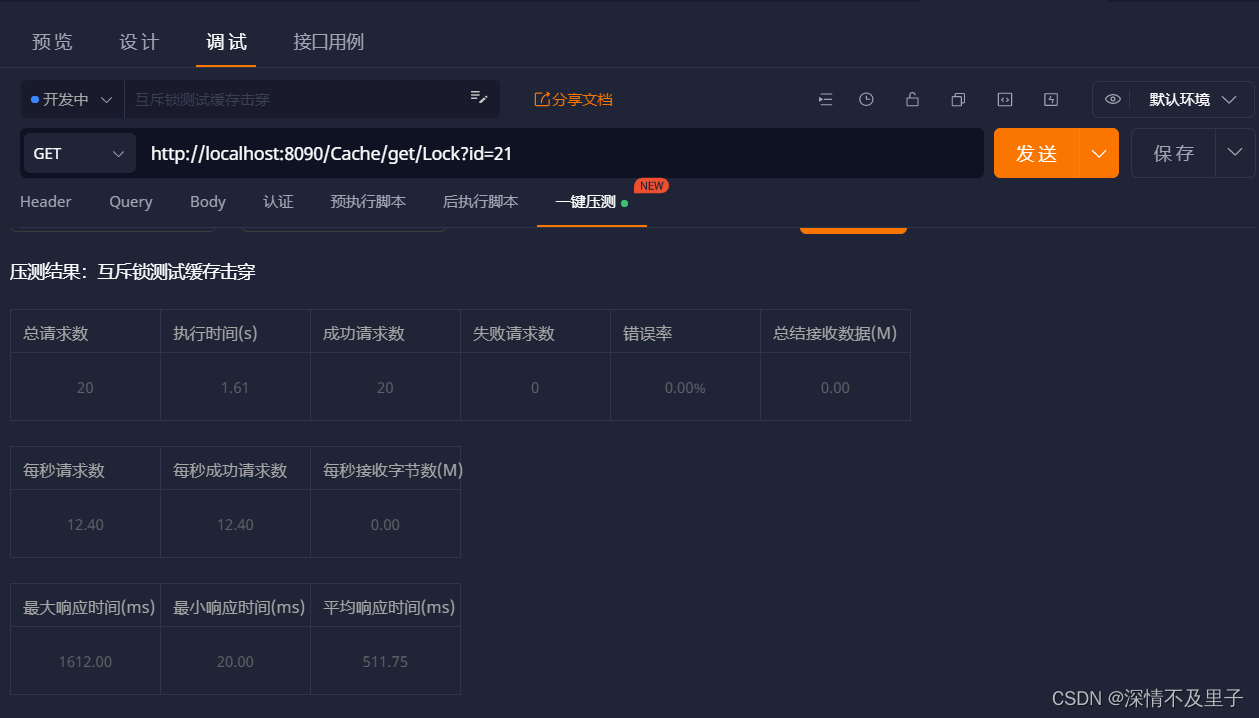
查看日志,可以看到预期效果实现了,在缓存失效的情况下,仅执行了一次数据库操作,后面请求全部走缓存。
2023-04-28 08:53:04.850 INFO 7264 --- [nio-8090-exec-6] c.y.r.service.impl.RedisTestServiceImpl : 查询数据库----
Creating a new SqlSession
SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@33e03af6] was not registered for synchronization because synchronization is not active
JDBC Connection [HikariProxyConnection@704636388 wrapping com.mysql.cj.jdbc.ConnectionImpl@57df93c1] will not be managed by Spring
==> Preparing: SELECT id,redis_name,redis_pwd,address FROM redis_test WHERE (id = ?)
==> Parameters: 21(Integer)
<== Columns: id, redis_name, redis_pwd, address
<== Row: 21, redis测试数据21号, 577948, 本地测试数据67
<== Total: 1
Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@33e03af6]
2023-04-28 08:53:05.077 INFO 7264 --- [nio-8090-exec-6] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-28 08:53:05.096 INFO 7264 --- [nio-8090-exec-8] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-28 08:53:05.116 INFO 7264 --- [nio-8090-exec-6] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-28 08:53:05.159 INFO 7264 --- [nio-8090-exec-6] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-28 08:53:05.201 INFO 7264 --- [nio-8090-exec-6] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-28 08:53:05.223 INFO 7264 --- [nio-8090-exec-8] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-28 08:53:05.242 INFO 7264 --- [nio-8090-exec-6] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-28 08:53:05.263 INFO 7264 --- [nio-8090-exec-3] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-28 08:53:05.264 INFO 7264 --- [nio-8090-exec-8] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-28 08:53:05.284 INFO 7264 --- [nio-8090-exec-6] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-28 08:53:05.307 INFO 7264 --- [nio-8090-exec-8] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-28 08:53:05.326 INFO 7264 --- [nio-8090-exec-6] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-28 08:53:05.415 INFO 7264 --- [nio-8090-exec-1] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-28 08:53:05.546 INFO 7264 --- [nio-8090-exec-5] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-28 08:53:05.674 INFO 7264 --- [nio-8090-exec-9] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-28 08:53:05.810 INFO 7264 --- [io-8090-exec-10] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-28 08:53:05.964 INFO 7264 --- [nio-8090-exec-7] c.y.r.service.impl.RedisTestServiceImpl : 查询数据库----
Creating a new SqlSession
SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@5ffc6cea] was not registered for synchronization because synchronization is not active
JDBC Connection [HikariProxyConnection@522751494 wrapping com.mysql.cj.jdbc.ConnectionImpl@57df93c1] will not be managed by Spring
==> Preparing: SELECT id,redis_name,redis_pwd,address FROM redis_test WHERE (id = ?)
==> Parameters: 21(Integer)
<== Columns: id, redis_name, redis_pwd, address
<== Row: 21, redis测试数据21号, 577948, 本地测试数据67
<== Total: 1
Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@5ffc6cea]
2023-04-28 08:53:06.158 INFO 7264 --- [nio-8090-exec-4] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----
2023-04-28 08:53:06.286 INFO 7264 --- [nio-8090-exec-2] c.y.r.service.impl.RedisTestServiceImpl : 查询缓存----这种方式仅限于单机模式条件下,如果系统采用分布式则需要使用分布式锁来实现互斥了,这里不多做说明。
缓存雪崩
缓存雪崩是指对热点数据设置了相同的过期时间,在同一时间这些热点数据key大批量发生过期,请求全部转发到数据库,从而导致数据库压力骤增,甚至宕机。与缓存击穿不同的是,缓存击穿是单个热点数据过期,而缓存雪崩是大批量热点数据过期。
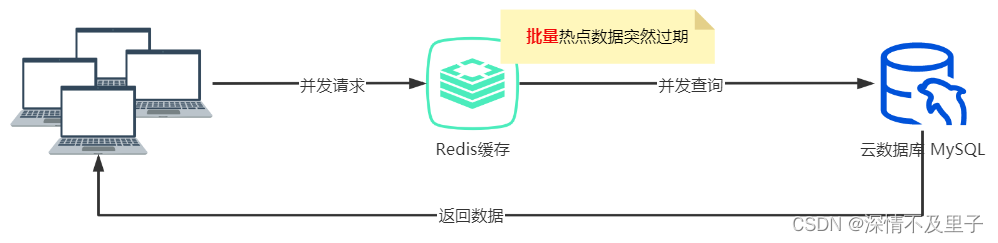
解决方案一:设置随机的过期时间
将key的过期时间后面加上一个随机数,这个随机数值的范围可以根据自己的业务情况自行设定,这样可以让key均匀的失效,避免大批量的同时失效。
if (ObjectUtil.isNotNull(redisTest)) {
//生成一个1~5的随机数
int randomInt = RandomUtil.randomInt(1, 5);
//过期时间+随机数形成随机时间
redisTemplate.opsForValue().set(redisKey, JSONUtil.toJsonStr(redisTest), 2L+randomInt, TimeUnit.SECONDS);
}解决方案二:不设置过期时间
不设置过期时间时,需要注意的是,在更新数据库数据时,同时也需要更新缓存数据,否则数据会出现不一致的情况。这种方式比较适用于不严格要求缓存一致性的场景。
解决方案三:搭建高可用集群
缓存服务故障时,也会触发缓存雪崩,为了避免因服务故障而发生的雪崩,推荐使用高可用的服务集群,这样即使发生故障,也可以进行故障转移。
数据一致性
通常情况下,使用缓存的直接目的是为了提高系统的查询效率,减轻数据库的压力。一般情况下使用缓存是下面这几步骤:
-
查询缓存,数据是否存在
-
如果数据存在,直接返回
-
如果数据不存在,再查询数据库
-
如果数据库中数据存在,那么将该数据存入缓存并返回。如果不存在,返回空。
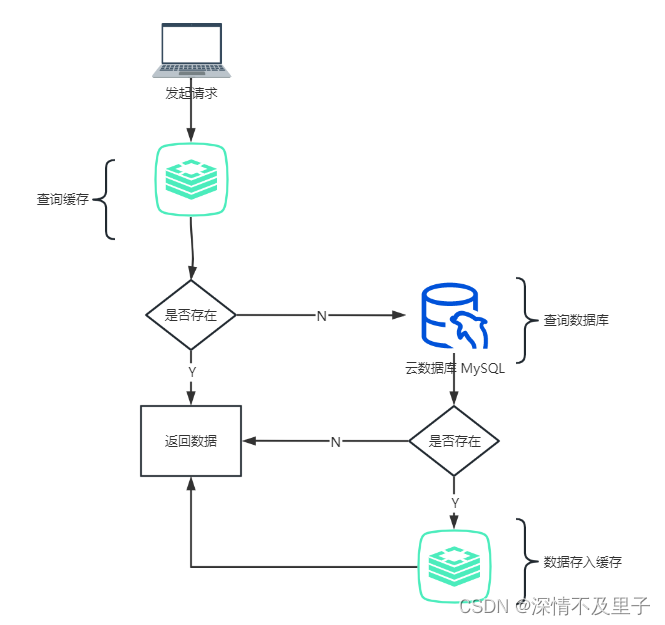
一般情况下这个流程并没有太大问题,但是会有一个细节问题:当一条数据存入缓存后,立刻又被修改了,那么这个时候缓存该如何更新呢。不更新肯定不行,这样导致了缓存中的数据与数据库中的数据不一致。一般情况下对于缓存更新有下面这几种情况:
-
先更新缓存,再更新数据库
-
先更新数据库,再更新缓存
-
先删除缓存,再更新数据库
-
先更新数据库,再删除缓存
先更新缓存,再更新数据库
先更新缓存,再更新数据库这种情况下,如果业务执行正常,不出现网络等问题,这么操作不会有啥问题,两边都可以更新成功。但是,如果缓存更新成功了,但是当更新数据库时或者在更新数据库之前出现了异常,导致数据库无法更新。这种情况下,缓存中的数据变成了一条实际不存在的假数据。
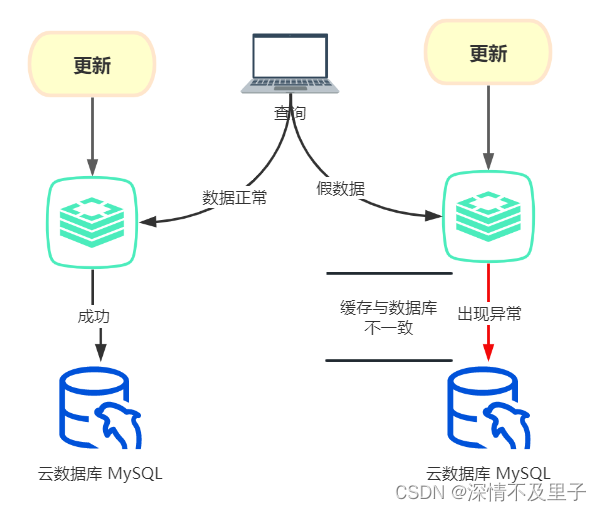
模拟一个更新数据库时出现异常的业务情况:
/**
* 模拟更新数据库出现异常
* @param redisTest
* @return
*/
public boolean updateButException(RedisTest redisTest){
String key = "test::"+redisTest.getId();
redisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(redisTest),5L,TimeUnit.MINUTES);
//模拟异常
int exc =10/0;
return updateById(redisTest);
}构建测试接口:
public Boolean updateOne(@RequestBody RedisTest redisTest){
return service.updateButException(redisTest);
}测试更新情况并查询数据:

此时数据库更新出现异常,但是缓存已经更新成功了,再次执行查询操作后检查获取数据和实际数据库数据情况:

数据不一致的情况就出现了,显然获取的是个假数据。
先更新数据库,再更新缓存
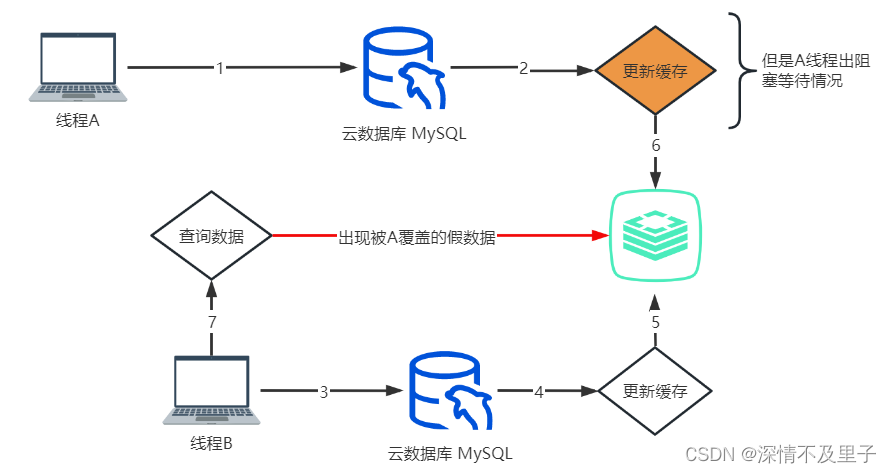
先更新数据库,再更新缓存和先更新缓存,再更新数据库的情况基本一致,如果失败,会导致数据库中是最新的数据,缓存中是旧数据。还有一种极端情况,在高并发情况下容易出现数据覆盖的现象:A线程更新完数据库后,在要执行更新缓存的操作时,线程被阻塞了,这个时候线程B更新了数据库并成功更新了缓存,当B执行完成后线程A继续向下执行,那么最终线程B的数据会被覆盖。此时B查询数据时仍然会出现数据一致性问题,B会在缓存中获得被A覆盖的假数据。
先删除缓存,再更新数据库
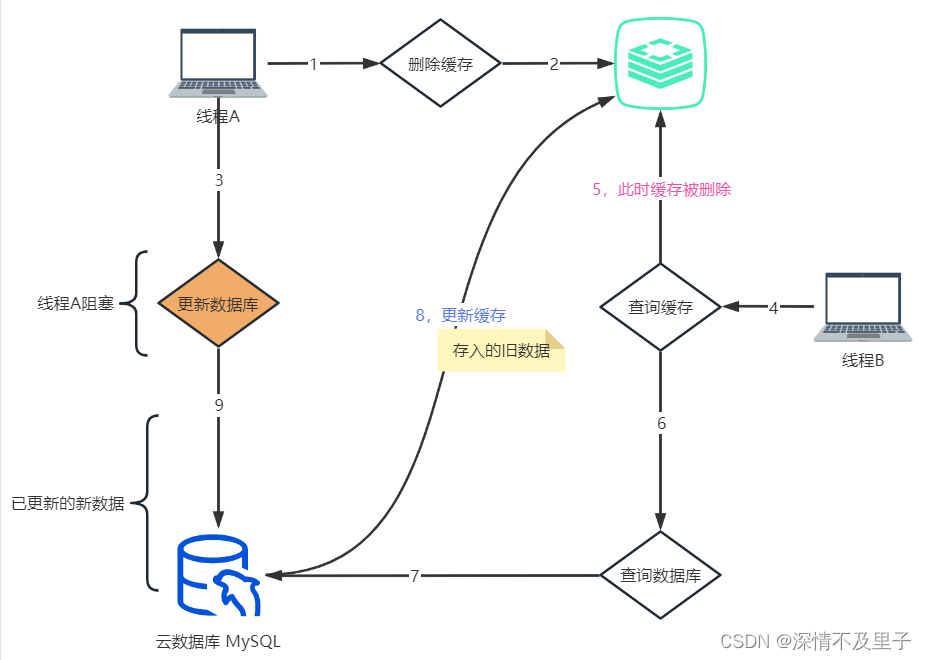
先删除缓存,再更新数据库这种情况,如果并发量不大用起来不会有啥问题。但是在并发场景下会有这样的问题:线程A在删除缓存后,在写入数据库前发生了阻塞。这时线程B查询了这条数据,发现缓存中不存在,继而向数据库发起查询请求,并将查询结果缓存到了redis。当线程B执行完成后,线程A继续向下执行更新了数据库,那么这时缓存中的数据为旧数据,与数据库中的值不一致。
先更新数据库,再删除缓存
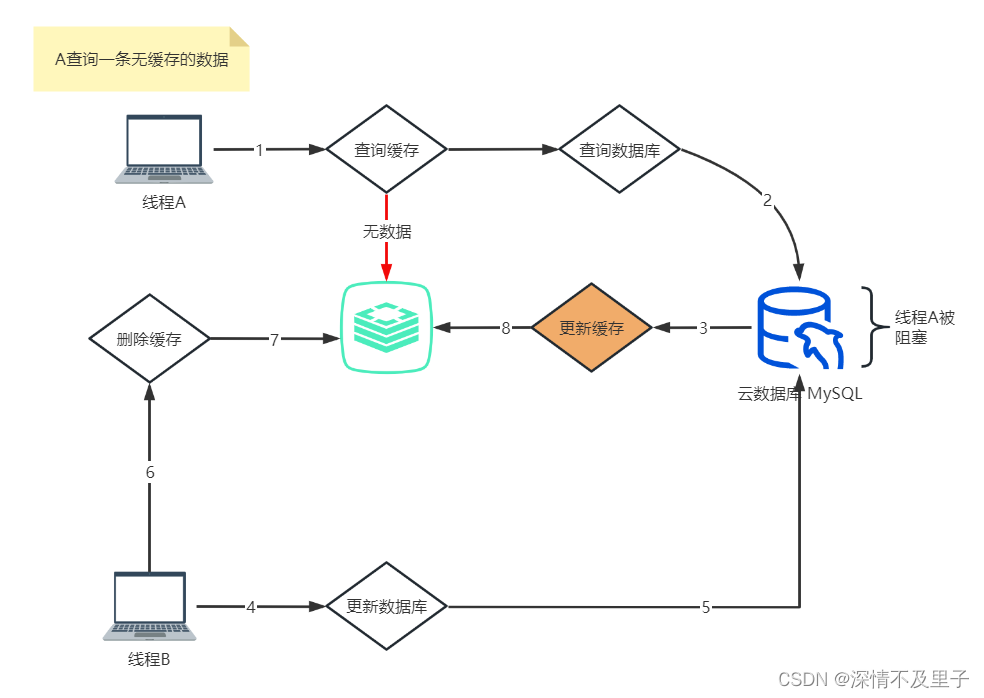
先更新数据库,再删除缓存也并不是绝对安全的,在高并发场景下,如果线程A查询一条在缓存中不存在的数据(这条数据有可能过期被删除了),查询数据库后在要将查询结果缓存到redis时发生了阻塞。这个时候线程B发起了更新请求,先更新了数据库,再次删除了缓存。当线程B执行成功后,线程A继续向下执行,将查询结果缓存到了redis中,那么此时缓存中的数据为A的数据,而数据库中却是B的数据,那么当A或B重新查询数据时,B会从缓存获得A更新的数据,而得不到数据库真实的数据,因此出现了数据不一致的情况。
解决数据不一致方案-延时双删
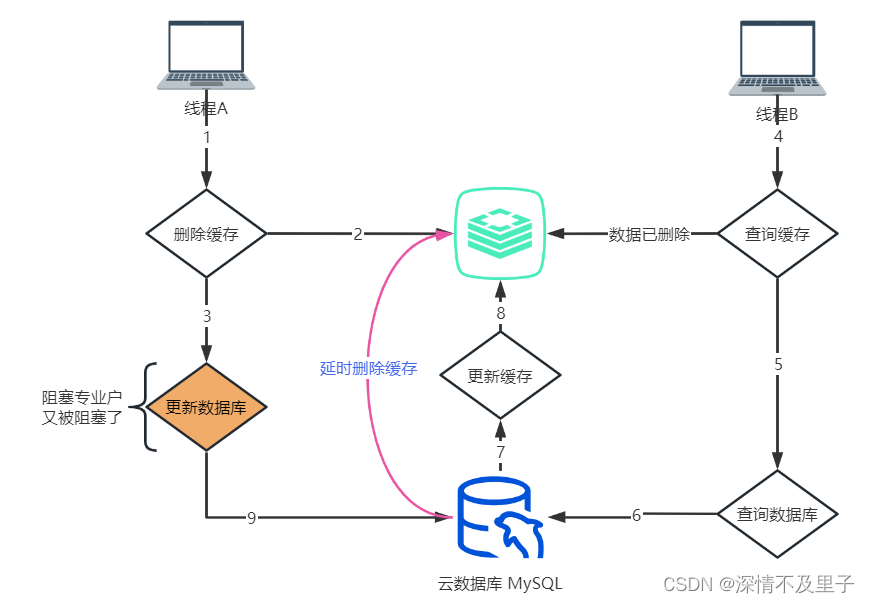
延时双删,即在写数据库之前删除一次,写完数据库后,再删除一次,在第二次删除时,并不是立即删除,而是等待一定时间在做删除。这种策略是分布式系统中数据库存储和缓存数据保持一致性的常用策略。
当Redis中出现缓存数据一致性问题时,延时双删是一种常用的解决方案,而RabbitMQ可以通过消息的延迟特性来实现延时效果。下面我们来介绍一下如何实现:
首先我们需要创建一个RabbitMQ的交换机、队列和绑定关系,可以使用RabbitTemplate实现,如下所示:
@Configuration
public class RabbitConfig {
private static final String EXCHANGE_NAME = "cacheExchange";
private static final String DELAY_QUEUE_NAME = "cacheDelayQueue";
private static final String ROUTING_KEY = "cacheKey";
// 声明交换机
@Bean
public DirectExchange exchange() {
return new DirectExchange(EXCHANGE_NAME);
}
// 声明延迟消息队列
@Bean
public Queue delayQueue() {
Map<String, Object> args = new HashMap<>();
args.put("x-dead-letter-exchange", EXCHANGE_NAME);
args.put("x-dead-letter-routing-key", ROUTING_KEY);
return new Queue(DELAY_QUEUE_NAME, true, false, false, args);
}
// 绑定延迟消息队列到交换机
@Bean
public Binding binding() {
return BindingBuilder.bind(delayQueue())
.to(exchange())
.with(ROUTING_KEY);
}
// 声明RabbitTemplate
@Bean
public RabbitTemplate rabbitTemplate(final ConnectionFactory connectionFactory) {
final RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory);
rabbitTemplate.setExchange(EXCHANGE_NAME);
rabbitTemplate.setRoutingKey(ROUTING_KEY);
return rabbitTemplate;
}
}在这里我们声明了一个名为cacheExchange的DirectExchange交换机和一个名为cacheDelayQueue的延迟队列。我们还绑定了延迟队列到交换机,并声明了一个RabbitTemplate,用于发送消息。
当我们需要清除缓存时,可以发送一个延迟消息到队列中。消息的时间间隔可以根据实际需求设置,这里以10秒为例:
@Autowired
private RabbitTemplate rabbitTemplate;
public void clearCache(String key) {
// 删除Redis缓存中的数据
redisTemplate.delete(key);
// 发送延迟消息到队列中
rabbitTemplate.convertAndSend(key, new Object(), message -> {
message.getMessageProperties().setExpiration("10000");
return message;
});
}在这里,我们先使用RedisTemplate删除缓存中的数据,然后使用RabbitTemplate发送延迟消息,将键值作为消息的key,这样我们就可以在消息处理程序中根据key来删除数据。在消息发送时,我们设置了消息的过期时间为10秒,这意味着消息将在10秒后到期并被发送到绑定的交换机。
最后,我们需要编写一个消息处理程序来处理延迟消息并进行双重删除操作。在这个示例中,我们简单地使用RedisTemplate删除缓存数据:
@Component
public class CacheMessageReceiver {
@Autowired
private RedisTemplate redisTemplate;
@RabbitListener(queues = "cacheDelayQueue")
public void onMessage(Message message) {
String key = new String(message.getBody());
// 双重删除
redisTemplate.delete(key);
}
}在这个处理程序中,我们使用@RabbitListener将cacheDelayQueue队列作为监听目标,当队列中有消息到达时,我们提取出消息的key,并使用RedisTemplate进行双删除操作,以确保缓存数据一致性得到解决。
总之,在Redis缓存中出现缓存数据一致性问题时,RabbitMQ的延迟消息机制可以帮助我们实现延时双删的效果,保证数据的一致性,并且也可以很方便地集成到我们的项目中。但它不是强一致。其实不管哪种方案,都避免不了Redis存在脏数据的问题,只能减轻这个问题,要想彻底解决,得要用到同步锁和对应的业务逻辑层面解决。
总结
在日常的使用中缓存确实能帮助数据库节省很多访问压力,但是在实际使用中确实有很多需要我们格外注意的地方,如果处理不好就容易造成数据不一致的情况,严重甚至导致服务宕机。因此如果在读多写少并且对数据一致性要求不严的情况使用基本是没啥大问题的。但是如果在高并发的场景下,还有很多坑是需要留心注意。