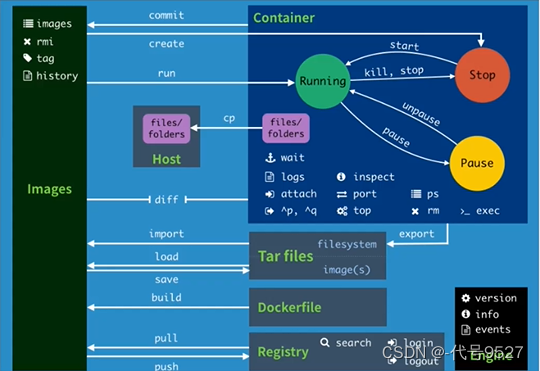
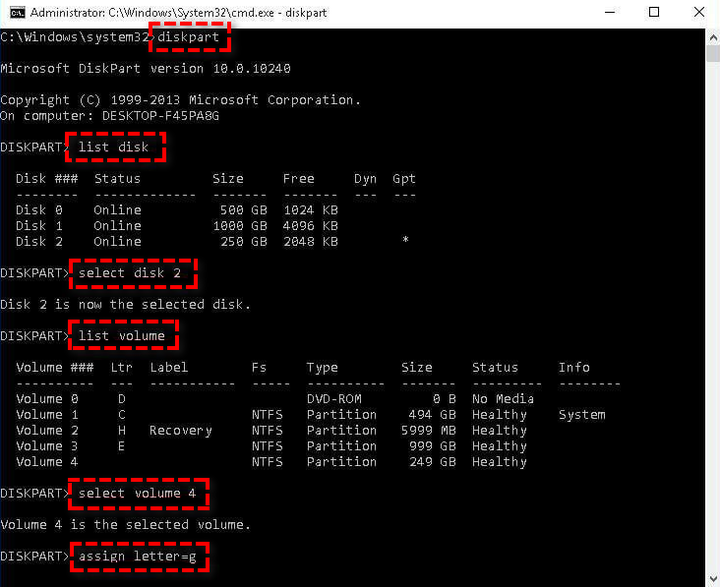
- 目标
- 效果图
- 操作说明
- 代码
目标
探究肺癌患者的CT图像的图像特征并构建一个诊断模型
效果图
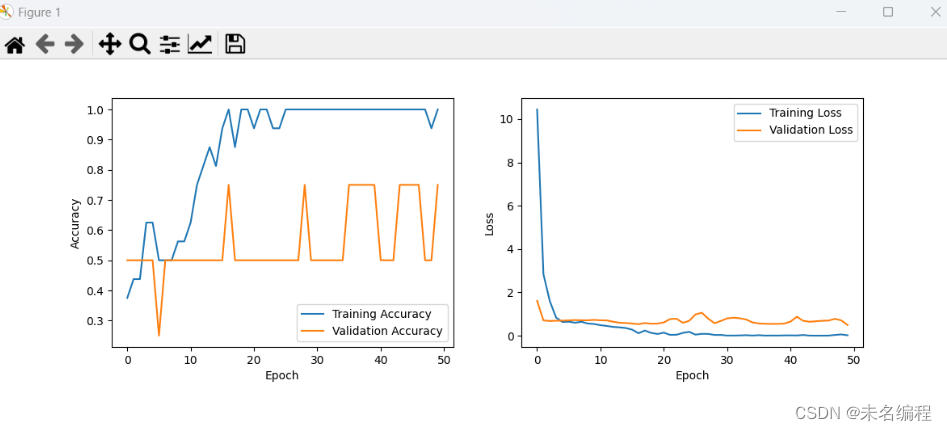
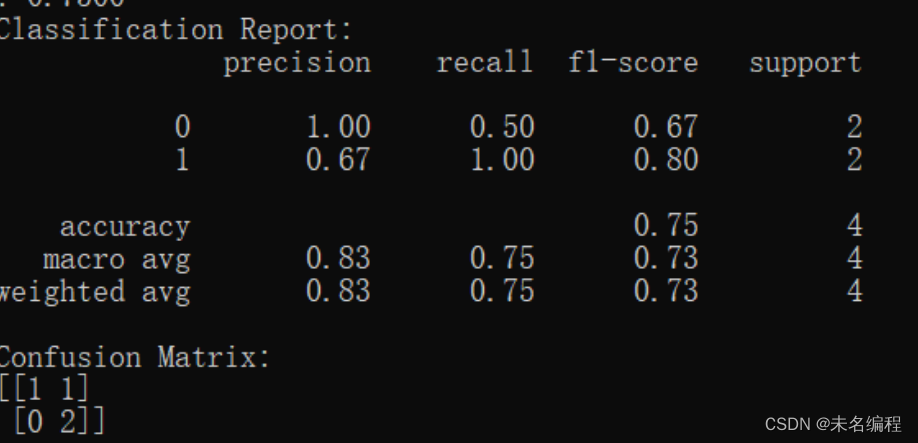
操作说明
代码中我以建立10张图为例,多少你自己定
准备工作:
1.准备肺癌或非肺癌每个各10张图,在本地创建一个名为“data”的文件夹,用于存放数据集。在“data”文件夹下创建两个子文件夹,分别命名为“cancer”和“non_cancer”,用于存放肺癌和非肺癌图像。将10张肺癌图像命名为“cancer_1.jpg”到“cancer_10.jpg”,并将它们放入“cancer”文件夹中。将10张非肺癌图像命名为“non_cancer_1.jpg”到“non_cancer_10.jpg”,并将它们放入“non_cancer”文件夹中。
- 在开始编写和执行代码之前,请确保已经安装完成以下库:
TensorFlow:用于构建和训练深度学习模型
Keras:用于快速构建和训练模型
scikit-learn:用于评估模型和数据预处理
numpy:用于数组和矩阵操作
OpenCV:用于处理和操作图像数据
matplotlib:用于可视化结果
安装命令
pip install tensorflow
pip install keras
pip install scikit-learn
pip install numpy
pip install opencv-python
pip install matplotlib
确保在本地创建了一个名为“data”的文件夹,并在其中创建了名为“cancer”和“non_cancer”的子文件夹。
将肺癌和非肺癌图像分别放入对应的子文件夹,并确保它们的命名正确
3.然后就可以复制上txt里面的代码进行执行了(记得改代码里面路径)

注意事情:
4. 图像大小:在load_images()函数中,已将图像调整为150x150大小。您可以根据实际情况更改此尺寸,但请注意,较大的图像可能会增加计算成本和训练时间。
例如,将图像大小调整为224x224:。

5.灰度图像:如果您的图像是灰度图像,可以将图像从单通道灰度转换为3通道灰度,以适应模型。在load_images()函数中添加如下代码

代码
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dropout, Flatten, Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import to_categorical
# 加载图像并调整大小
def load_images(data_dir, img_size): #从指定目录加载图像文件,并将它们转换成统一大小
images = []
labels = []
for folder in os.listdir(data_dir): #遍历指定路径下的文件夹,其中 os.listdir(data_dir) 返回指定目录中所有文件和文件夹的名称列表
for file in os.listdir(os.path.join(data_dir, folder)):
img_path = os.path.join(data_dir, folder, file)
img = cv2.imread(img_path)
img = cv2.resize(img, img_size)
images.append(img)
labels.append(folder)
return np.array(images), np.array(labels)
# 构建模型
def create_model(input_shape, num_classes): #创建神经网络模型。函数接受输入数据的形状 input_shape 和分类数量 num_classes 作为参数
model = Sequential() #将各个神经网络层按照顺序逐层叠加起来,构成一个“线性”模型
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=input_shape)) #添加了一个卷积层 Conv2D 到模型中 (3,3是滤波器大小)
#接受输入张量(特征图),尺寸为 input_shape;
#将每个滤波器应用于输入张量;
#对每个输出结果应用 ReLU 非线性激活;
#输出包括32张空间特征图通道
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(optimizer=Adam(), loss='categorical_crossentropy', metrics=['accuracy'])
#optimizer=Adam() 指定使用 Adam 优化算法;
#loss='categorical_crossentropy' 表示采用交叉熵作为损失函数,适合多分类问题;
#metrics=['accuracy'] 说明度量模型性能时以准确率作为衡量标准
return model
# 主程序
def main():
data_dir = r'F:\code_test\data'
img_size = (150, 150)#这是图片的大小根据自己图片修改
num_classes = 2
batch_size = 4
epochs = 50
# 加载图像数据
images, labels = load_images(data_dir, img_size)
# 数据预处理
images = images.astype('float32') / 255.0
labels = (labels == 'cancer').astype(int)
labels = to_categorical(labels, num_classes)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(images, labels, test_size=0.2, random_state=42)
# 数据增强
datagen = ImageDataGenerator(horizontal_flip=True, vertical_flip=True)
datagen.fit(X_train)
# 创建模型
model = create_model((img_size[0], img_size[1], 3), num_classes)
# 训练模型
history = model.fit(datagen.flow(X_train, y_train, batch_size=batch_size),
validation_data=(X_test, y_test),
steps_per_epoch=len(X_train) // batch_size,
epochs=epochs)
# 评估模型
y_pred = model.predict(X_test)
y_pred_classes = np.argmax(y_pred, axis=1)
y_test_classes = np.argmax(y_test, axis=1)
print("Classification Report:")
print(classification_report(y_test_classes, y_pred_classes))
print("Confusion Matrix:")
print(confusion_matrix(y_test_classes, y_pred_classes))
# 绘制训练过程的准确率和损失曲线
def plot_training_history(history):
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
plot_training_history(history)
if __name__ == '__main__':
main()
相关图片获取:
github链接
CSDN资源文件也有