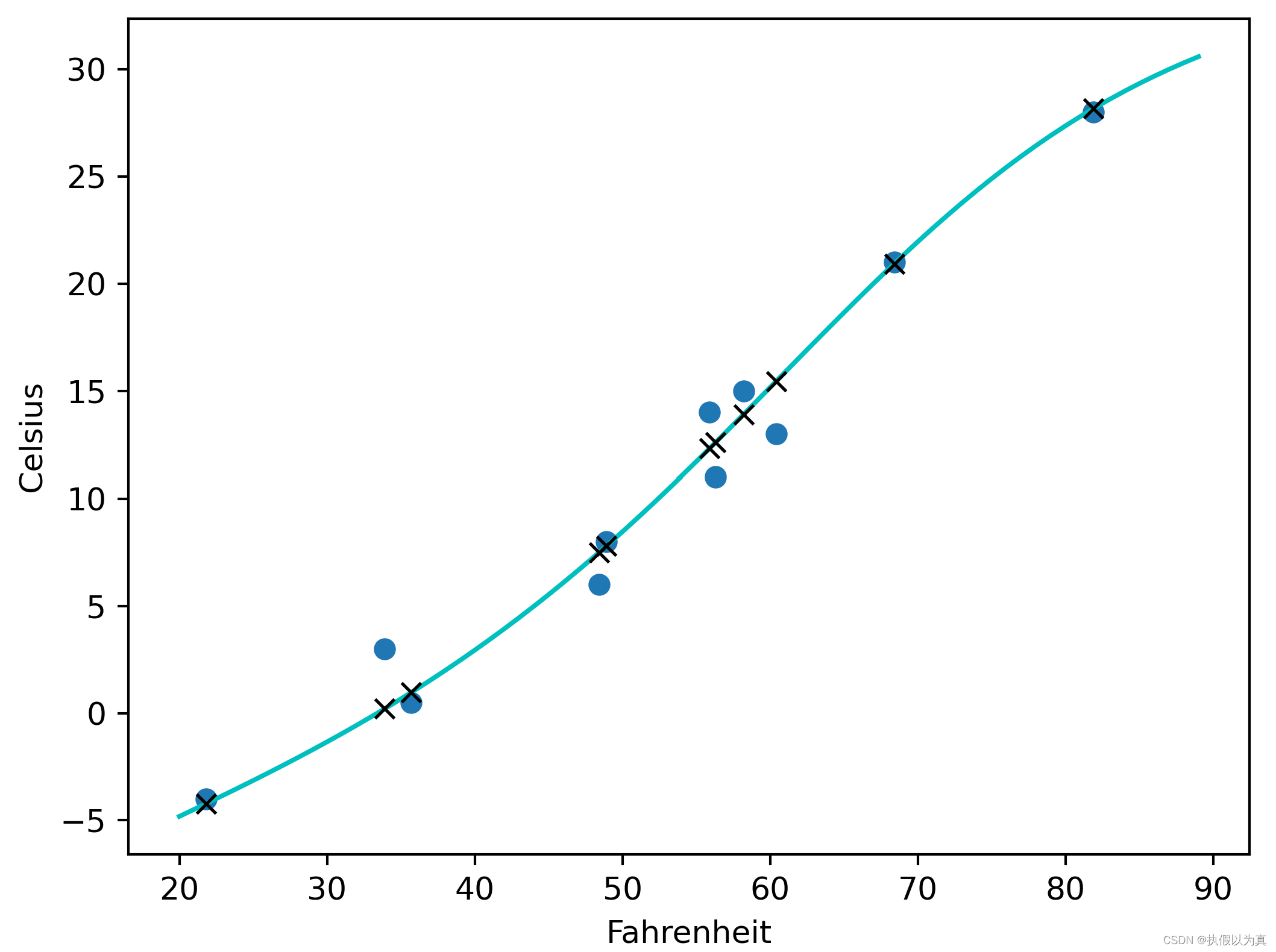
文章目录
- 前言
- 与其他功能交互
- 设备的开启和关闭
- 队列
- 通知内核帧已接收:NAPI和netif_rx
- NAPI简介
- NAPI所用之net_device字段
- net_rx_action和NAPI
- 新旧驱动程序接口
- 操作poll_list
- 设备驱动程序与内核间的旧接口:netif_rx的第一部分
- netif_rx的初始任务
- 管理队列以及下半部调度
- 拥塞管理
- netif_rx中的拥塞管理
- 平均队列长度及拥塞等级计算
- 处理NET_RX_SOFTIRQ:net_rx_action
- 积压的处理:process_backlog轮询虚拟函数
- 入口帧的处理
- 处理特殊功能
前言
前面一节我们知道了,处理L2层的帧的函数是由中断事件驱动的。下面我们将着手讨论帧的接收,此时,硬件会使用中断事件通知CPU,该帧已经可用了。
接收中断事件的CPU会执行do_IRQ函数。IRQ编号会引发正确的处理函数被启用后。此处理函数通常是设备驱动程序在设备设备驱动程序初始化期间所注册的函数,IRQ函数处理例程会在中断模式下执行,即后续的中断事件都会暂时被关闭。
中断处理函数会执行一些立即性的任务,然后把其他任务安排到下半部函数中以便在稍后执行。明确的将,中断处理函数会:
-
把帧拷贝到
sk_buff数据结构。 -
对一些
sk_buff参数做初始化,以便在稍后由上面的网络层使用(显然是skb->protovol,借此表示较高协议处理函数,这在后面将详细介绍)。 -
更新其他一些该设备私有的参数,本篇不会讨论,因为不会影响帧在网络协议栈内的路径。
为NET_RX_SOFIRQ软中断调度以准备执行,借此通知内核新帧的事。
由于设备发出中断事件的理由各不相同(新帧已接收、帧已成功传输等等),内核的代码会配合中断通知信息,使得设备驱动程序处理例程可以按类型处理中断事件。
与其他功能交互
研究本篇介绍的函数时,会时常看见一些代码片段和选用的内核功能交互。就其它功能而言,不会在其代码上花太多时间。本章所示的流程图多数都会显示出这些选用功能会在函数的何处进行处理。
以下是我们会看见的选用功能及其相关的内核符号:
-
802.1 d Ethernet Bridging(CONFIG_BRIDGE/CONFIG_BRIDGE_MODULE)- 桥接模式
-
Netpoll(CONFIG_NETPOLL)Netpoll是一个通用的框架,可通过轮询网络适配卡(NIC)而传送及接收帧,把中断事件的需求删除掉。任何内核功能都可使用Netpoll,以受益于该功能。著名的案例是Netconsole,可以通过UDP把内核信息(例如,用printk打印字符串)发送到远程主机。Netconsole及其子选项可以通过make xconfig菜单打开:Networking support-> Network console logging support选项。要使用Netpoll时,设备必须支持才行(有不少已经支持)。
-
Packet Action(CONFIG_NET_CLS_ACT)- 通过此功能,流量控制可以对入口流量进行分类,并且采取一些操作。可能的操作包括丢弃封包以及消化封包。要查看
make xconfig菜单中的这个选项以及其所有子选项,必须选取Networking support->Networking options -> Qos and/or fair queueing -> Packet classifier API选项。
- 通过此功能,流量控制可以对入口流量进行分类,并且采取一些操作。可能的操作包括丢弃封包以及消化封包。要查看
设备的开启和关闭
当net_device->status中的__LINK_STATE_START标识被设置时,设备就可被视为已开启。前面的博客已经说明了此标识的细节。当设备打开时(dev_open),这个标识通常就会被设置,而当设备关闭时(dev_close),就会被清除。虽然有一个标识是明确用于开启或关闭设备的传输(__LINK_STATE_XOFF),却没有标识用于开启和关闭接收。此能力是通过其他方式完成的,也就是关闭设备。__LINK_STATE_START标识的状态可由netif_running函数检查。
后面会显示的几个函数都是简单的包裹函数,可以检查标识,如__LINK_STATE_START的正确状态,以确保设备已装备好做其该做之事。
队列
讨论L2行为时,我们通常会提到帧接收和传输时所需的队列(入口队列和出口队列)。每个队列都有一个指针指向其相关联的设备,以及一个指针指向存储输入/输出缓冲区的skb_buff数据结构。只有少数专用的设备可以不需要队列就能工作,其中一例是回环设备。回环设备可以省掉队列,因为当你从回环设备传出一个封包时,该封包会立刻被传递出去(给本地系统),而无需排入队列的中间过程。再者,因为在回环设备上的传输不会失败,也没必要让封包重新排入队列以尝试另一次传输。
出口队列和设备直接想关联;流量控制(QoS层)会让每个设备都定义一个队列。后面我们会介绍,内核会记录等待传输帧的设备而非帧本身。我们也会知道,并非所有的设备都在用流量控制。对于入口队列而言,情况比较复杂,后续做分析。
通知内核帧已接收:NAPI和netif_rx
Linux2.5版本内核中(然后回头移植到2.4版本的新修正版中)引入了一套新的API以处理入口帧,由于找不到更好的名称,我们称之为NAPI(New API,新型API)。隐秘额很少有设备更新成使用NAPI,所以Linux驱动程序通知内核新帧的事有两种方式:
-
通过旧函数netif_rx- 这种方法是由那些遵循中断期间处理多帧所使用的技术的设备所使用。多数Linux设备驱动程序依然使用这种手法。
-
通过NAPI机制- 这种方法是由遵循中断期间处理多帧末尾介绍的改进的技术的设备所使用。这是Linux内核中的新事物,但是只有少数驱动程序用到。
drivers/net/tg3.c是第一个改用NAPI的驱动程序。
- 这种方法是由遵循中断期间处理多帧末尾介绍的改进的技术的设备所使用。这是Linux内核中的新事物,但是只有少数驱动程序用到。
当用make xconfig这类工具配置内核时,有些设备驱动程序可让你在这两种接口间做选择。
下列代码片段来自于vortex_rx,依然使用旧函数netif_rx,因此,可以想象到,多数尚未改用NAPI的网络设备驱动程序,其所做之事都很类似:
skb = dev_alloc_skb(pkt_len + 5);
... ... ...
if(skb != NULL){
skb->dev = dev;
skb_reserve(skb, 2); /*把IP对齐在16字节边界上*/
... ... ...
/*把DATA拷贝到sk_buff结构*/
... ... ...
skb->protocol = eth_type_trans(skb, dev);
netif_rx(skb);
dev->last_rx = jiffiies;
... ... ...
}
首先,以dev_alloc_skb分配sk_buff数据结构,然后帧会被拷贝进去。注意,拷贝前,程序会保留两个字节使IP报头对其16字节边界。每个网络设备驱动程序都被关联上给定的接口类型;例如,Vortex设备驱动程序driver/net/3c59x.c就关联到一个特定的Ethernet卡系列。因此,驱动程序知道链接层报头的长度,也知道该如何予以解读。假设报头长16*k+n,则驱动程序可以调用skb_reserve,用16-n作为偏移量,就可以使对齐16字节边界。Ethernet报头是14个字节,所以k=0,n=14,而程序所需的偏移量为2(参见include/linux/sk_buff.h中NET_IP_ALIGN的定义以及相关的批注)。
此外应注意,此时驱动程序并没有区分不同的L3协议。驱动程序把L3报头对齐到16自己边界上,而不管其类型。L3协议可能是IP,因为IP使用最广泛,但是此时还无法确保,也有可能是Netware的IPX或其他东西。无论所用的L3协议为何,对其都有用处。
关于eth_type_trans将在后面博客描述,可用于提取协议表示符skb->protocol
取决于驱动程序设计的复杂度,其程序区段后面有其他的管理工作,但不是我们讨论的主要部分。此函数的最重要的部分是把帧接收的通知信息传给内核。
NAPI简介
虽然有些NIC设备驱动程序尚未改用NAPI,但是新型基础架构已经整合至内核,而且连netif_rx和内核其余部分之间的接口也罢NAPI考虑进来了。我们先谈NAPI而非介绍旧的方法(纯netif_rx),在说明旧驱动程序如何保有其旧接口(netif_rx),同时又共享一些新型基础架构机制。
NAPI混合了中断事件和轮询,在高流量负载下其性能会比旧方法要好,因为可以大幅减少CPU的负载。内核开发人员又把这个基础架构反回来移植到2.4版内核。
在旧模型中,设备驱动程序会为其所接收的每个帧都产生一个中断事件。在高流量负载下,花在处理中断事件的时间会造成资源相当程度的浪费。
NAPI背后的主要想法很简单:混合使用中断事件和轮询,而不使用纯粹的中断事件驱动模型。如果接收到新帧时,内核还没完成处理前几个帧的工作,驱动程序就没必要产生其他中断事件:让内核一直处理设备输入队列中的数据会比较简单一点(该设备的中断功能关闭),然后当该队列为空时再重新开启中断功能。如此一来,驱动程序就能获得中断事件和轮询的优点:
-
异步事件——如帧的接收是由中断事件指出,如此一来,如果设备的入口队列是空的,内核就不用一直去检查了。 -
如果内核知道设备的入口队列中有数据存在,就没必要浪费时间去处理中断事件通知信息。用简单的轮询就够了。
从内核处理的观点看,以下是NAPI方法的一些有点:
-
减少了CPU的负载(因为中断事件变少了)- 假设工作量(也就是每秒帧数)相同,则使用NAPI时CPU的负载比较低。这在高工作量时特别明显。在低工作量时使用NAPI,根据内核开发人员在内核邮件论坛所公布的测试报告,实际上的CPU用量会高一点。
-
设备的处理更为公平- 稍后就会知道,一些设备的入口队列中若有数据,就会以相当公平的循环方式予以访问。这样就能确保当其他设备的负载都很高时,低流量的设备所体验到的延时依然处于可接受的范围之内。
NAPI所用之net_device字段
查看NAPI的实现和用法之前,我们必须说明一些net_device数据结构的字段。
为了处理驱动程序使用NAPI接口的设备,有四个新字段添加到此结构中,以供NET_RX_SOFTURQ软IRQ使用。其他设备不会用到这些字段,但是它们可共享嵌入在softnet_data结构中作为backlog_dev字段的net_device结构的字段。
-
poll- 这个虚拟函数可用于把缓冲区从设备的输入队列中退出。此队列是使用NAPI设备的私有队列,而
softnet_data->input_pkt_queue供其他设备使用。
- 这个虚拟函数可用于把缓冲区从设备的输入队列中退出。此队列是使用NAPI设备的私有队列,而
-
poll_list- 这是设备列表,其中的设备就是在入口队列中有新帧等待被处理的设备。这些设备就是所谓的处于轮询状态。此列表的头为
softnet_data->poll_list。此列表中的设备都处于中断功能关闭状态,而内核当前正在予以轮询。
- 这是设备列表,其中的设备就是在入口队列中有新帧等待被处理的设备。这些设备就是所谓的处于轮询状态。此列表的头为
-
quota -
weight-
quota(配额)是一个整数,代表的是poll虚拟函数一次可以从队列退出的缓冲区的最大数目。其值的增加以weight为单位,用于在不同设备间施加某种公平性。配额愈低,表示潜在的延时愈低,因此让其他设备饿死的风险就愈低。另一方面,低配额会在增加设备间的切换量,因此整体的耗费会增加。 -
对配有非NAPI驱动程序的设备而言,
weight的默认值为64(存储在/net/core/dev.c顶端的weight_p变量)。weight_p之值可通过/proc修改。 -
对配有NAPI驱动程序的设备而言,默认值是由驱动程序所选。最常见的值是64,但是也有用16和32的。其值可通过
/sysfs调整。
-
使用NAPI的设备会对这四个字段以及其他net_device字段根据前面讲述的初始化模型做初始化。关于虚拟的backlog_dev设备,其初始化工作由net_dev_init完成。
net_rx_action和NAPI

如上图所示是每次内核轮询进来的网络流量时所发生的事。在此图中可以看到poll_list列表,其内的设备处于轮询状态,也可以看到poll虚拟函数以及软中断函数net_rx_action之间的关系。下面几节会详细说明此图各个方面的细节,但是转入源码之前,了解这部分如何交互是很重要的。
我们已经知道net_rx_action是NET_RX_SOFTIRQ标识相关联的函数。为了简洁起见,我们假设在一段低活动量期间之后有些设备开始接收帧,而这些行为触发了net_rx_action的执行,至于是如何做到的,就目前而言并不重要。
net_rx_action会浏览列表中处于轮询状态的设备,然后为每个设备都调用相关联的poll虚拟函数,以处理入口队列中的帧。前面说过,该列表中的设备会按照循环方式被查阅,而且每次其poll方法启用时,能处理的帧数目都有最大值存在。如果在其时间片内无法使队列清空,就得等到下一个时间片继续下去。也就是说,net_rx_action会持续为入口队列中有数据的设备调用其设备驱动程序所提供的poll方法,直到入口队列为空。到那时就不用再轮询了,而设备驱动程序就可以重新开启该设备的中断事件通知功能。值得强调的是,中断功能关闭只针对那些在poll_list中的设备,也就是只用于那些使用NAPI而且不共享backlog_dev的设备。
net_rx_action会限制其执行时间,当其用完限制的执行时间或处理过一定数量的帧后,就会自行重新调度以准备执行,这样是为了限制net_rx_action能与其他内核任务彼此公平运行。同时,每个设备也会限制其poll方法每次启用时所能处理的帧的数目,才能与其他设备之间彼此公平运行。当设备无法清空其入口队列时,就得等到下一次调用其poll方法的时候。
新旧驱动程序接口
现在,net_device结构和NAPI相关的字段意义,以及NAPI背后高层思想应该都已经清楚了,我们可以向源码走近一点了。
下图显示出了了解NAPI的驱动程序与其他驱动程序之间的差异性,驱动程序如何通知内核接收到新的帧。
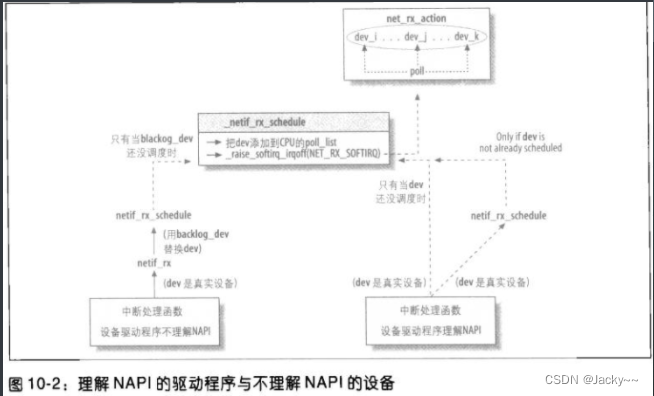
从设备驱动程序的角度看,NAPI与非NAPI之间只有两点差异。首先,NAPI驱动程序必须提供一个poll方法,。其次,为帧调度所调度的函数有别:非NAPI调用netif_rx,而NAPI驱动程序调用定义在include/linux/netdevice.h中的__netif_rx_schedule的包裹函数,检查以确保该设备正在运行,而且该软IRQ还没调度,然后才调用__netif_rx_schedule。这些检查以netif_rx_schedule_prep进行的。有些驱动程序会调用netif_rx_schedule,而其他的驱动程序则明确调用netif_rx_schedule_prep,而必要时再调用__netif_rx_schedule。
如上图所示,这两种驱动程序都会把输入设备排入轮询表(poll_list),为NET_RX_SOFTIRQ软中断调度以准备执行,最后再由net_rx_action予以处理。即使这两种驱动程序最后都会调用__netif_rx_schedule(非NAPI驱动程序会在netif_rx中做这件事),NAPI设备给予的性能会好很多。
上图中一项重要细节是,在两种情况下传给__netif_rx_schedule的net_device结构。非NAPI设备使用的是内建至CPU的softnet_data结构的net_device结构,而非NAPI设备使用的涉及他们自己的net_device结构。
操作poll_list
前节已知,调用netif_rx_schedule或__netif_rx_schedule时,就可以把任何设备(包括虚拟的backlog_dev)添加到poll_list列表。
逆向操作——从列表中移除设备——是由netif_rx_complete或__netif_rx_complete所做的(第二个是假设本地CPU的中断功能已关闭)。后面会详细分析。
设备可通过netif_poll_disable和netif_poll_enable暂时关闭和重新开启轮询。这并不表示设备驱动程序已决定返回到中断模式。例如,当设备必须被设备驱动程序复位,以应用某种硬件配置变更时,对设备的轮询可能就得关闭。
前面说过,netif_rx_schedule会为poll_list中的设备(也就是__LINK_STATE_RX_SCHED标识被设置)过滤请求。因此,如果驱动程序设置该标识,但是没有设备添加到poll_list,基本就是为该设备关闭轮询;该设备绝不会被添加到poll_list。这是netif_poll_disable的工作方式;如果__LINK_STATE_RX_SCHED没设置,就会予以设置,然后返回;否则,就等待该标识被清楚,然后再予以设置
static inline void netif_poll_disable(struct net_device *dev)
{
while(test_and_set_bit(__LINK_STATE_RX_SCHED, &dev->state)){
/*一点都不急*/
current->state = TASK_INTERRUPTIBLE;
schedule_timeout(1);
}
}
设备驱动程序与内核间的旧接口:netif_rx的第一部分
当新的输入帧正等待处理时,设备驱动程序通常是调用定义在net/core/dev.c中的netif_rx函数,此函数的工作是为短暂执行的软IRQ(把帧退出队列然后予以处理)调度。下图所示是其所做之事以及其事件的流程。此图实际上比代码还长,但是有助于了解netif_rx流程中的脉络。
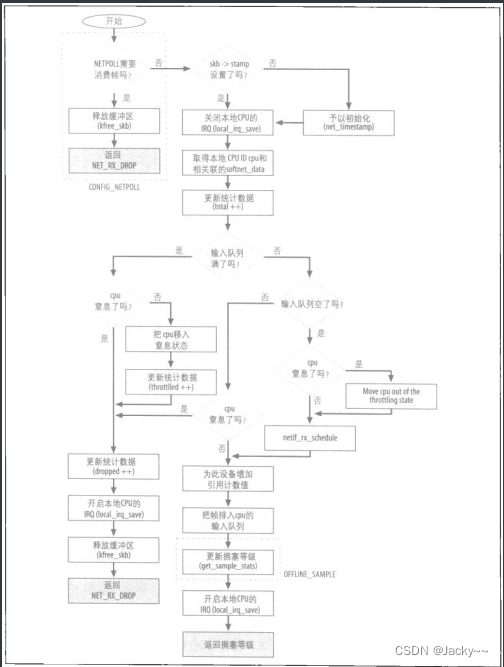
netif_rx通常是在中断环境下被驱动程序所调用,但是,也有例外,特别是当此函数是被同环设备调用时。因此,netif_rx在其启动时会关闭本地CPU的中断事件,然而当其完成工作时会再予以重新开启。
查看代码时应该记住一点:不同的CPU可以同时执行netif_rx。这不是问题,因为每个CPU都配有一个私有的softnet_data结构以维护状态信息。此外,CPU的softnet_data结构还包括一个私有的输入队列。
此函数的原型如下:
int netif_rx(struct sk_buff *skb)
其唯一的输入参数就是该设备接收的缓冲区,而其输出值就是指出拥塞等级之值。
netif_rx主要的任务如下,可参考上图
-
对
sk_buff数据结构的一些字段做初始化(如接收帧的时间)。 -
把已接收的帧存储到CPU的私有输入队列,然后触发相关联的软IRQ
NET_RX_SOFTIRQ以通知内核时。只有当某些条件满足时,这个步骤才会发生,而最重要的一点就是队列中是否有空间。 -
更新有关拥塞等级的统计数据。
下图所示是一个系统范例,其中有一些CPU和设备。每个CPU都有自己的softnet_data实例,而该实例内有私有的输入队列,netif_rx会在此存储入口帧,此外,当缓冲区已不再需要时,就会被送往completion_queue。此图显示出一个范例,CPU1从eth0接收到一个RxComplete中断事件。相关联的驱动程序会把入口帧存储至CPU1的队列。CPUm从ethn接收到一个DMADone中断事件,指出已传输的缓冲区已不在需要,因此可以移往completion_queue队列。
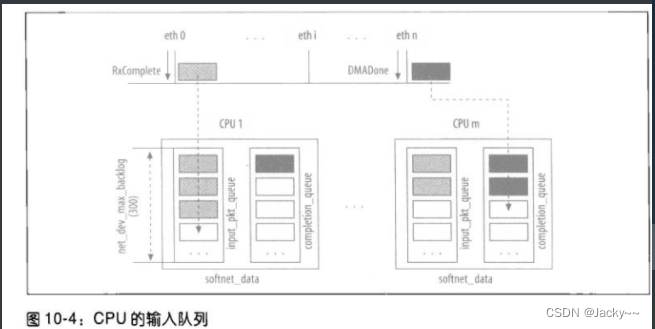
netif_rx的初始任务
netif_rx会先把函数启用的时间保存(也是代表帧接收的时间)到缓冲区结构的stamp字段。
保存事件戳需要CPU代价,因此,只有当至少有一位用户对该字段有兴趣时,net_timestamp才会初始化skb->stamp。若对该字段有兴趣,可以调用net_enable_timestamp予以声明。
不要把这里对时间戳的指定和设备驱动程序调用netif_rx前后所做的执行混淆了。
设备驱动程序把其最近帧的接收时间存储在net_device结构中,而netif_rx存储的时间是缓冲区内接收帧的时间。因此,设备有个时间戳,而帧本身也有个时间戳。再者,要注意这两个时间戳使用不同精度。设备驱动程序存储的最近帧的时间戳是以jiffies表示,在内核2.6版本中依赖于体系结构而定,其精度可以是10ms或1ms(例如,2.6版本以前,i386用的值是10ms,但是从2.6起,其值为1ms)。然而,netif_rx取得其时间戳的方式是调用get_fast_time,而返回一个更高精度的值。
本地CPU的ID通过调用smp_processor_id()获取,并存储在局部变量this_cpu之中:
this_cpu = smp_processor_id();
我们必须使用本地CPU ID,才能在各个CPU向量中取出与该CPU相关联的数据结构,如下列netif_rx中的代码所示:
queue = &__get_cpu_var(softnet_data);
上列代码会把指向softnet_data结构的指针存储在queue。softnet_data结构与本地CPU相关联,为调用netif_rx的设备驱动程序所触发的中断事件提供服务。
现在,netif_rx会更新CPU所接收的帧总数:包括接受的以及丢弃的(例如,因为队列中以没有空间):
netdev_rx_stat[this_cpu].tottal++
每个设备驱动程序也会持有统计数据,将其存储在dev->priv所指的私有数据结构中。这些统计数据——包括已接收的帧数目、已丢弃的帧数目——都是按各个设备分别存储的,但是,由netif_rx更新的统计数据则是按各个CPU分别存储的。
管理队列以及下半部调度
输入队列是由softnet_data->input_pkt_queue管理。每个输入队列都有最大长度,由全局变量netdev_max_backlog指定,其值为300。也就是说,每个CPU的输入队列中最多只能有300个帧等待处理,而无论系统中的设备数目有多少。
尝试告诉我们,netdev_max_backlog的值应该依赖于设备数目以及设备的速度。然而,在SMP系统这一点很难追踪,因为中断事件都是动态分布在CPU之间,那个设备会与那个CPU对话很难看出来。因此,netdev_max_backlog值的选择是通过试验和出错得到的。可以想见,将来其值会以动态方式设置,以反映出接口的类型和数目。其值已经可由系统管理员做配置调整。
在以前的内核中,当时各个CPU数据结构softnet_data还不存在,所有设备会共享一个输入队列,名为backlog,而其大小都是300个帧。使用softnet_data的主要收获不是n个CPU使队列有n*300个帧空间,而是CPU之间不再需要上锁,因为每个CPU都有自己的队列。下列代码能控制在什么条件下netif_rx会将其新帧插入到一个队列,以及在什么条件下会为该队列调度以准备执行:
if(queue->input_pkt_queue.qlen <= netdev_max_backlog){
if(queue->input_pkt_queue.qlen){
if(queue->throttle)
goto drop;
enqueue:
dev_hold(skb->dev);
__skb_queue_tail(&queue->input_queue, skb);
#ifndef OFFLINE_SMPLF
get_sample_stats(this_cpu);
#endif
local_irq_restore(flags);
return queue->cng_level;
}
if(queue->throttle)
queue->throttle = 0;
netif_rx_schedule(&queue->backlog_dev);
goto enqueue;
}
... ... ...
drop:
__get_cpu_var(netdev_rx_stat).dropped++;
local_irq_restore(flags);
kfree_skb(skb);
return NET_RX_DROP;
}
第一个if语句确认是否还有空间。如果队里已满,则语句返回false,而CPU就会被放入窒息状态(throttle state),也就是说输入流量已超载,因此后续的帧都会被丢弃。创立窒息的代码这里没有显示出来,但是,下一节讨论拥塞管理时就会出现。
然而,即使队列有空间也不足以确保该帧会被接受。CPU可能已处于“窒息”状态(由第三个if语句确认),就此而言,该帧还是会被丢弃。
当队列成空时,窒息状态就可解除。这就是第二个if语句所做的测试。当队列上有数据而且CPU处于窒息状态,该帧就会被丢弃。但是,当队列为空,而CPU处于窒息状态时(也就是所示代码的下半部的if语句所做的测试),窒息状态就会被解除。调用dev_hold(skb->dev)会为该设备增加引用计数值,使得该设备无法被移除,直到此缓冲区已完全被处理为止。相应的递减是由dev_put完成,会在net_rx_action内发生。
如果所有测试都满足,则该缓冲区就会用__skb_queue_tail(&queue->input_pkt_queue, skb)排入输入队列,而该CPU的IRQ状态就会被恢复,然后此函数返回。
把帧排入队列是相当快的,因为不涉及任何内存拷贝,只是指针操作而已。input_pkt_queue是指针列表。__skb_queue_tail把指向新缓冲区的指针添加到其列表中,而没有拷贝该缓冲区。
NET_RX_SOFTIRQ软中断可通过netif_rx_schedule调度以准备执行。注意,只有当新缓冲区添加到空队列时,netif_rx_schedule才会被调用。其原因在于如果队列不为空,则NET_RX_SOFTIRQ已经被调度了,因此,没有必要再调度一次。
拥塞管理
拥塞管理是输入帧处理任务中的重要部分。超负荷的CPU会变得不稳定,对系统造成很大的延时。前面已说明高负载所产生的中断事件为何会使得系统瘫痪,因此需要拥塞管理机制以确保系统的稳定性,使得在高网络负载下不会受到拖累。在高流量下负载下降低CPU负载的常见方式包括:
-
尽可能减少中断事件的数目
- 实现方法是把驱动程序编写为在一次中断事件中处理许多帧,或者使用NAPI。
-
在入口径中尽早丢弃帧
- 如果程序知道有一个帧会被那些较高层丢弃掉,就可以迅速丢弃帧,以节省CPU时间。例如,如果设备驱动程序知道入口队列已经满了,就可以立刻丢弃帧,而不用转发给内核使其再予以丢弃。
本节要谈的就是第二点。
类似的最优化也会应用在输出路径上:如果设备驱动程序没有资源可接受新的帧以传输(也就是内存不足),再让内核把新帧压入驱动程序以传输,那就是浪费CPU时间了。
就接收和传输这两种情况而言,内核都提供了一组函数,可设置、消除以及获取接收和传输队列的状态,因此,就能使设备驱动程序(在接收上)以及内核核心程序(在传输上)执行刚才所提到的优化工作。
拥塞等级的良好就是已接收的帧数目以及正等待处理的帧数目。当设备驱动程序使用NAPI时,就是由驱动程序实现任何拥塞控制机制。这是因为入口帧会被放入NIC的内存内,或者放在驱动程序所控管的接收环内,因此内核无法追踪流量拥塞情况。相反,当设备驱动程序没使用NAPI时,帧会被添加到各个CPU队列(softnet_data->input_pkt_queue),而内核就会追踪队列的拥塞等级。本节我们讨论后者的情况:
队列理论是很复杂的主题,本书不讨论这种数学细节,只要简单的要点就能令我满意:在对列中当前帧的数目并不一定代表真实的拥塞等级。平均队列长度是队列状态较好的导向。记录平均值可以使系统避免错误地把突发的流量归类为拥塞。在Linux网络协议栈中,平均队列长度是由softnet_data结构的两个字段报告:cng_level和avg_blog。
avg_blog是平均值,随时都可能比input_pkt_queue的长度更大或更小。avg_blog代表历史,而input_pkt_queue代表当前情况。因此,这两个变量用于两种不同的目的:
-
在默认情况下,每次一个帧排入
input_pkt_queue时,avg_blog就会更新,而相关联的拥塞等级也会计算出来,存储至cng_level。netif_rx的返回值就是cng_level,使得调用netif_rx的设备驱动程序可以得到有关队列状态的反馈信息,然后根此改变其行为。 -
input_pkt_queue中帧的数目不能超过最大值。到达最大值时,后续的帧就会被丢弃,因为CPU显然已经不能承受了。
我们回到拥塞等级的计算和使用。avg_blog和cng_level会在由netif_rx调用的get_sample_stats中得到更新。
此时,很少有设备驱动程序来使用来自于netif_rx的反馈信息。这列反馈信息的最常见用法,就是用于更新设备驱动程序的本地统计数据。有关反馈信息的有趣应用可参考drivers/net/tulip/de2104x.c:当netif_rx返回NET_RX_DROP时,局部变量drop会置为1,使得主要循环开始丢弃接收帧内的帧,而不予以处理。
只要入口队列input_pkt_queue没满,设备驱动程序就得使用来自于netif_rx的反馈信息以处理拥塞情况。当情况变得更糟而输入队列填满时,内核就得干预,使用softnet_data->throttle标识以CPU关闭帧的接收(记住,每个CPU都有一个softnet_data结构)。
netif_rx中的拥塞管理
让我们回到netif_rx,看一些前一节省略掉的代码。下面摘录的两段代码包括了先前显示过的代码以及显示出CPU何时会进入窒息状态的新代码
if(queue->input_pkt_queue.qlen <= netdev_max_backlog){
if(queue->input_pkt_queue.qlen){
if(queue->throttle)
goto drop;
... ... ...
return queue->cng_level
}
... ... ...
}
if(!queue->throttle){
queue->throttle =1;
__get_cpu_var(netdev_rx_stat).throttled++;
}
当队列为空时,softnet_data->throttle会被清楚。正确的讲,当第一个帧排入空队列时,softnet_data->throttle就会被处netif_rx清楚。此事也会发生在process_backlog中。
平均队列长度及拥塞等级计算
avg_blog和cng_level的值总是会在get_sample_stats中更新。而get_sample_stats可以用两种不同的方式启用:
-
每次接收一个新帧时(
netif_rx)。这是默认方式。 -
通过周期性的定时器。要使用这种技术,必须定义
OFFLINE_SAMPLE符号。这也就是为什么在netif_rx中get_sample_stats的执行依赖于OFFLINE_SAMPLE符号的定义。默认是关闭的。
在中等和高流量负载下,以第一种方法执行get_sample_stats比第二种方法更常见。
就这两种情况而言,用于计算avg_blog的公式都应该又简单又快速,因为公式时常会被调用。所使用的公式会把新近的历史和当前情况都考虑进来了:
new_value_for_avg_blog = (old_value_of_avg_blog + current_value_of_queue_len) /2
当前和过去的权重该怎么分配,不是简单的问题。上述公式可以很快就对拥塞等级有所调整,因此过去(旧值)只有50%的权重,而当前则占有另外50%。
get_sample_stats也会更新cng_level,其值源于avg_blog。如果RAND_LTE符号有定义、此函数会多执行一个操作,以随机决定把cng_level升高一级。这种随机调整需要更多时间去计算,但奇怪的是,这样可以使内核在一种特定场合下执行得更好。
在只有一个接口的系统中,如果没有拥塞问题,随机丢弃帧是在没意义,只会让吞吐量变低而已。但是,假设我们有多个接口共享一个输入队列,而且有一个设备的流量负载比其他设备都高很多。因此贪心的设备会比其他设备更快的速度填入共享的入口队列,因此,其他设备通常会发现入口队列没有空间,所以它们的帧就会被丢弃。贪婪的设备也会看到他的一些帧被丢弃,但是,与其负载相比并不成比例。当拥有多接口的系统遇到拥塞问题时,就应该按设备负载的比例丢弃输入帧。用在这种情景下时,RAND_LTE就能增添一些公平性:随机丢弃额外的帧,最后就应该能得到按负载比例丢弃帧的结果。
处理NET_RX_SOFTIRQ:net_rx_action
net_rx_action是用于处理进来的帧的下一个函数其执行的触发是当驱动程序通知内核有关输入帧存在的时候。下图所示是此函数的控制流程:
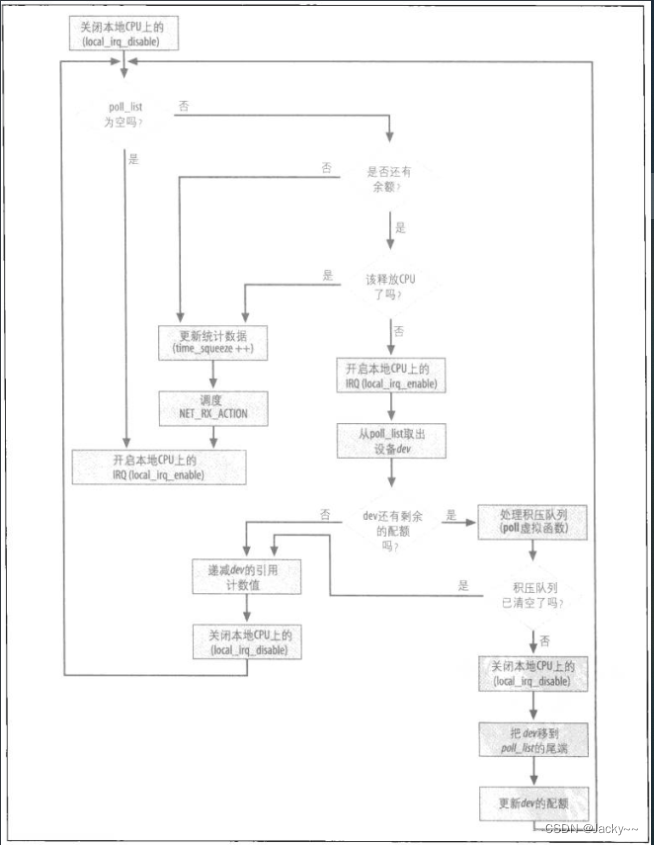
帧可以在两个地方等待net_rx_action予以处理:
-
一个共享的CPU专用队列
- 非NAPI设备的中断处理例程,调用
netif_rx能把帧放入softnet_data->input_pkt_queue,中断处理函数在此运行。
- 非NAPI设备的中断处理例程,调用
-
设备内存
- NAPI驱动程序所用的poll方法会直接从设备(或设备驱动程序的接收环)中取出帧。
“新旧驱动程序接口”一节说明了这两种情况下内核会如何接到要执行net_rx_action的通知。
net_rx_action的工作相当简单:浏览poll_list设备列表,而这些设备的入口队列中都有数据,然后为每个设备启用相关联的poll虚拟函数,直到下列条件之一满足。
-
列表中没设备了
-
net_rx_action已执行太久了,因此应该释放CPU,以免成为CPU贪婪的占用者。 -
从队列中退出及处理的帧数目以及抵达指定的上限值,即budget。budget的初始化是在该函数的开头设成
netdev_max_backlog,其定义在net/core/dev.c中,其值为300.
下一节就会知道,net_rx_action会调用驱动程序的poll虚拟函数,而且多少会依赖这个函数以遵循这些限制条件。
队列的尺寸受限于netdev_max_backlog的值。此值即为net_rx_action的budget.然而,因为net_rx_action执行时中断功能是开启的,当net_rx_action在运行时,新帧可以添加到设备的输入队列。因此,可用帧数目很快就会大于budget,因此net_rx_action必须采取行动,以确保这类情况下不会执行太久。
现在,我们来看net_rx_action的内部细节:
static void net_rx_action(struct softirq_action *h)
{
struct softnet_data *queue = &__ghet_cpu_var(softnet_data);
unsigned long start_time = jiffies;
int budget = netdev_max_backlog;
local_irq_disable();
}
如果当前设备还没用到整个配额,就有机会以poll虚拟函数从其队列中将缓冲区退出:
while(!list_empty(&queue->poll_list)){
struct net_device *dev;
if(budget <= 0 || jiffies - start_time > 1)
goto softnet_break;
local_irq_enable();
dev = list_entry(queue->poll_list.next, struct net_device, poll_list);
}
如果因为设备配额不够打,无法把入口队列中所有缓冲区都退出,使得dev->poll返回(此时,传回值为非零),则该设备会被移到poll_list的尾端:
if(dev->quota <= 0 || dev->poll(dev, &budget)){
local_irq_disable();
liist_del(&dev->poll_list);
list_add_tail(&dev->poll_list, &queue->poll_list);
if(dev->quota < 0)
dev-<quota += dev->weight;
else
dev->quota += dev->weight;
}else{
}
当代替poll设法清空入口队列时,net_rx_action不会从poll_list中把该设备删除:poll应该调用netif_rx_complete(如果本地CPU的IRQ被关闭,也可以调用__netif_rx_complete负责此件事。)这一点会在下一节介绍process_backlog函数时说明。
此外,注意到budget是以引用方式传给poll虚拟函数,这是因为该函数会返回一个新的budget,以反映以处理的帧。next_rx_action中的主要循环每一轮都会插件budget,以确保没有超过整体限制的值。换言之,budget使net_rx_action和poll函数批次合作,使其不超出其限度:
dev_put(dev);
local_irq_disable();
}
}
out:
local_irq_enable();
return ;
当next_rx_action被迫返回时,而入口队列中仍然留有换冲区时,就会执行最后一段代码。在这种情况下,NET_RX_SOFTIRQ软IRQ会再度被调度准备执行,稍后将启用net_rx_action,负责剩余缓冲区:
softnet_break:
__get_cpu_var(netdev_rx_stat).time_squeeze++;
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
goto out;
}
注意,只有在操作设备列表poll_list做轮询时(也就是访问其softnet_data结构实体时),net_rx_action才会用local_irq_disable关闭中断功能。netpoll_poll_lock和netpoll_poll_unlock(NETPOLL功能所用)已被省略。如果你可以看内核源码,可以参见net/core/dev.c中的net_rx_action查看其细节。
积压的处理:process_backlog轮询虚拟函数
net_device数据结构的poll虚拟函数会由net_rx_action执行,以处理设备的积压队列,对那些不使用NAPI的设备而言,其初始化值默认在net_dev_init中设置为process_backlog。
内核2.6.12版本时,只有少数设备驱动程序使用NAPI,而且以其自己的一个函数的指针作为dev->poll初始化值:在drivers/net/tg3.c中的Broadcom Tigon3 Ethernet驱动程序是第一个采用NAPI的,因此是考察的绝佳范例。本节我们要分析在net/core/dev.c的默认处理函数process_backlog,其实现方式非常类似使用NAPI的设备驱动程序的poll方法(例如,可以拿process_backlog和tg3_poll比较)。
然而,因为process_backlog能管理一大群共享同一个入口队列的设备,有一个重要的差异必须要考虑。当process_backlog运行时,硬件中断是开启的,所以此函数可以被先占。因此,访问softnet_data结构时总是用local_irq_disable关闭本地CPU的 中断功能,使访问受到保护,特别是调用__skb_dequeue的时候。此锁对使用NAPI的设备驱动程序而言并不需要:当其poll方法被启用时,会为该设备关闭硬件中断功能。此外,每个设备都有其自己的队列。
来看process_backlog的主要部分,如下如所示
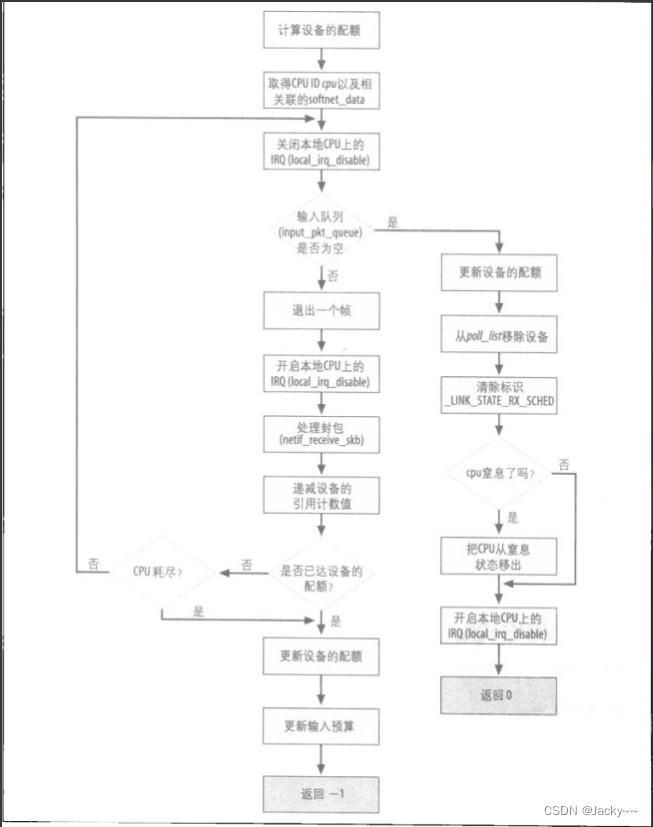
此函数一开始先做一些初始化工作
static int process_backlg(struct net_device *backlog_dev, int *budget)
{
int work = 0;
int quota = min(backlog_dev->quota, *budget);
struct softnet_data *queue = &__get_cpu_var(softnet_data);
unsigned long start_time = jiffies;
}
然后进入主循环,试图把输入队列中的所有缓冲区都退出,而且只有当下列条件之一满足时才会打断:
-
队列成空
-
设备的配额已用尽
-
此函数已执行太久了
后面两个条件类似于限制net_rx_action的条件。因为process_backlog是在net_rx_action中的循环调用的,也只有当process_backlog配合时,net_rx_action才能遵守其限制条件。因此,net_rx_action会把其所剩下的budget传给process_backlog,而process_backlog会将其配额设成该输入参数(budget)与自己的配额两者间的最小值。
budget是由net_rx_action在其启动时将其设置成300.dev->quota的默认值是64(多数设备都用此默认值)。我们考察一种情况,加上,有多个设备的队列都满了。前四个设备在此函数运行时都会接收到比起内部配额64大得多的budget,因此,其队列都可成空。下一个设备在传送其队列部分内容后可能就得停止了。也就是,process_backlog退出的缓冲区数目依赖于设备配置(dev->quota)以及其设备的流量负载。这样就能确保设备间更具公平性。
for(;;){
struct sk_buff *skb;
struct net_device *dev;
local_irq_disable();
skb = __skb_dequeue(&queue->input_pkt_queue);
if(!skb)
goto job_done;
local_irq_enable();
dev = skb->dev;
netof_receive_skb(skb);
dev_put(dev);
work++;
if(work >= quota || jiffies - start_time >1)
break;
}
netif_receive_skb是处理帧的函数。下一节会予以说明。所有poll虚拟函数都会用到这个函数,包括NAPI和非NAPI
设备配额的更新取决于成功退出的缓冲区数目。如前所述,输入参数budget也会更新,因为net_rx_action必须借此追踪还能继续做多少工作:
backlog_dev->quota -= work;
*budget -= work;
return -1;
稍早所示的主循环在输入队列成空时,会跳转到标号job_done。如果此函数到达此处,窒息状态就可清楚(如果被设置),而且设备也可从poll_list删除。__LINK_STATE_RX_SCHED标识也会清除,因为设备在输入队列中已无数据,因此不需要再次调度做积压的处理。
job_done:
backlog_dev->quota -= work;
*budget -= work;
list_del(&backlog_dev->poll_list);
smp_mb_ _before_clear_bit();
netif_poll_enable(backlog_dev);
if(queue->throttle)
queue->throttle = 0;
local_irq_enable();
return 0;
}
实际上,process_backlog和NAPI驱动程序的poll方法之间有另一个的差异,我们以drivers/net/tg3.c作为范例:
if(done){
spin_lock_irqsave(&tp->lock, flag);
__netif_rx_complete(netdev);
tg3_restart_ints(tp);
spin_unlock_irqrestore(&tp->lock, flags);
}
这里的done是process_backlog中job_done的对称物,其意义相同,都是指队列成空。此时,在NAPI驱动程序中,__netif_rx_complete(定义在相同文件)函数会从poll_list中把设备删除,此任务是process_backlog直接所做的事。最后,NAPI驱动程序会为该设备重新开启中断功能。
入口帧的处理
如前所述,netif_receive_skb是辅助函数,poll虚拟函数用其处理入口帧,如下图所示
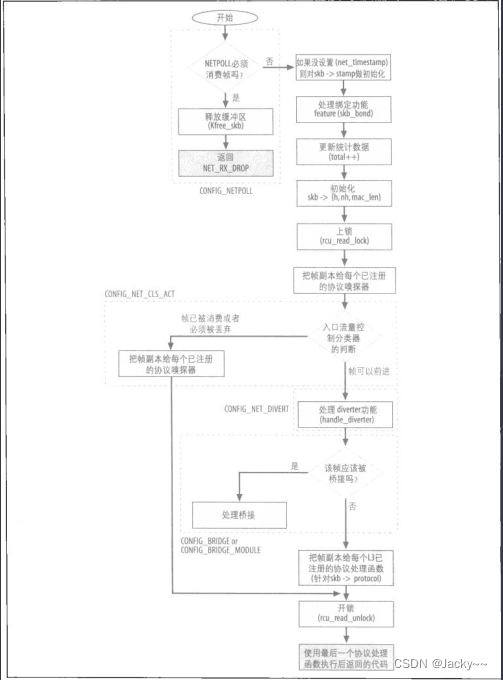
L2和L3都允许多种协议。每个设备驱动程序都会与一个特定的硬件类型相关联(例如Ethernet),所以,解读L2报头并获取信息,使其知道正在用的L3协议为何就很简单了。当net_rx_action启用时,L3协议标识符已由设备驱动程序从L2报头中提取而且存入skb->protocol中。
netif_receive_skb的三个主要任务是:
-
把帧的副本传给每个协议分流器,如果正在运行的话。
-
把帧的副本传给
skb->protocol所关联的L3协议处理函数。 -
负责此层必须处理的一些功能,例如桥接。
如果没有协议处理例程和skb->protocol关联,而且netif_receive_skb中的处理功能(如桥接)都没有消化该帧,该帧就会被丢弃,因为内核不知道该如何处理。
把输入帧传递给那些协议处理函数前,netif_receive_skb必须处理一些会改变帧命令的功能。
Bonding(绑定)可让一群接口组合起来,视为单一接口。如果帧来自的接口属于这类群组,则sk_buff数据结构中所引用的接收接口必须改成该群组中具有主设备角色的那个设备,netif_receive_skb才可以把封包传递给L3处理例程。这就是skb_bond的目的
skb_bond(skb);
帧传递给嗅探器(sniffer)以及协议处理例程的细节,后面会讨论。
一旦所有协议嗅探器都接收到封包副本,而且在真实协议处理函数取得副本前,Diverter、入口的流量控制以及桥接功能都必须予以处理。
如果桥接代码或入口的流量控制代码都没有消化该帧,则该帧会传给L3协议处理函数(通常每种协议只有一个处理函数,但是也可以注册多个)。在旧版本内核中,这就是唯一需要做的处理工作。但是,随着内核网络协议栈的增强,更多的功能添加进来(在这一层及其他层),封包经过网络协议栈的路径就变得越来越复杂。
此时,接收部分已完成,下一步就是L3协议处理函数决定要对封包如何处理:
-
传给接收工作站中正在执行的接收者(应用程序)。
-
丢弃(例如,健康检查失败)。
-
转发
最后一项选择对路由器而言是很常见的,但是对单接口工作站就不常见。
内核可从L3的目的地址确定该封包是否是传给本地系统。这个过程后面讨论。此时就视其为理所当然。如果封包要给本地系统,封包就会传递到上层去(及TCP、UDP、ICMP等等),如果不是给本地系统,就会传给ip_forward。
以上就结束了帧接收过程的冗长讨论。
处理特殊功能
netif_receive_skb会检查是否有任何Netpoll客户想消化该帧。
流量控制一直都用于实现出口路径上的QoS。然而,就新近版本的内核而言,也可以入口流量上配置过滤器并有所有动作。根据这样的配置,ing_filter可以决定输入缓冲区是要被丢弃,还是要在某处做进一步处理(也就是消化该帧)。
diverter允许内核改变原本发往其他主机帧的L2的母的地址,使得帧可以改造发往本地主机。这种功能有很多可能的用法,如网站Frame Diverter download | SourceForge.net所做的讨论。内核可以配置diverter所用的测定准则,以决定是否让帧改道。diverter所用的常见准则如下:
-
所有IP包(不管L3协议)
-
所有TCP包
-
特定端口的TCP包
-
所有UDP包
-
特定端口的UDP包。
调用handle_diverter可决定是否改变目的地的MAC地址。除了改变目的地的MAC地址外,skb->pkt_type也必须改成PACKET_HOST。
但是,另一个L2功能也会影响帧的命运:Bridging(桥接)。L2的桥接与L3的路由是配对功能,对此后面我们会进行讨论。每个net_device数据结构都有一个指向类型为net_dridge_port数据结构的指针,而此结构是用于存储表示桥接端口所需的额外信息。当接口没有开启桥接功能时,其值为NULL。当一个端口配置成桥接端口时,内核只会看L2报头。在此情况下,内核唯一用到的L3信息就是防火墙与防火墙有关的信息。
因为net_rx_action代表的是设备驱动程序和L3协议处理例程的边界,此函数中必须处理Bridging功能,并没有错。当内核支持桥接时,handle_bridge会初始化为一个函数,而由此函数检查该帧是否要交给桥接代码。当帧要交给桥接代码。而且桥接代码会予以消化时,handle_bridge就返回1。其他情况下,handle_bridge返回0,而且netif_receive_skb会继续处理帧skb。
if(handle_bridge(skb, &pt_prev, &ret));
goto out;



![[c++基础]-vector类](https://img-blog.csdnimg.cn/ee33b92d840b4e0e89829a2904e463a9.png)

![[ElasticSearch]-初识Elastic Stack](https://img-blog.csdnimg.cn/317c60c5ca88419194c71d45bdcc373a.png)