1.生成透视表
在使用Python处理数据时,我们希望能够快速地进行排列与计算数据,从而帮助我们更有效的分析数据,pivot_table函数可以实现Excel数据透视表的功能
基本语法格式
pd.pivot_table(data, values=None, index=None,
columns=None, aggfunc='mean',
fill_value=None, margins=False,
dropna=True, margins_name='All')参数说明
| 参数 | 描述 |
| data | 需要透视的DataFrame对象 |
| values | 需要聚合的字段(一个或多个) |
| index | 在数据透视表的索引上进行分组的列 |
| columns | 在数据透视表的列上进行分组的列 |
| aggfunc | 用于聚合的函数,默认是平均数mean |
| fill_value | 指定值来填充数据透视表的缺失值 |
| margins | 布尔值,默认值为False,对所有的行/列进行汇总 |
| dropna | 布尔值,默认值为True,当某一列全为NULL值时,dropna=True时删除该列,否则保留 |
| margins_name | 指定汇总行/列的名称 |
导入数据
import pandas as pd
df = pd.DataFrame({
'A':['a1', 'a1', 'a1', 'a2', 'a2', 'a2'],
'B':['b2', 'b2', 'b1', 'b1', 'b1', 'b1'],
'C':['c1', 'c1', 'c2', 'c2', 'c1', 'c1'],
'D':[1, 2, 3, 4, 5, 6]})
df

'''
A a1 a2
D 2 5
'''
pd.pivot_table(df,columns=['A'])
'''
D
A
a1 2
a2 5
'''
pd.pivot_table(df,index=['A'])pivot_table()默认的算法是取平均值,columns=['A']用于将原df中A列的去重值作为数据透视表的字段列,index=['A']用于将原df中A列的去重值作为数据透视表的索引
res1 = pd.pivot_table(df, index='A', columns='B', values='D')res1

我们以(a1,b1)进行计算来源分析
'''
A B C D
2 a1 b1 c2 3
'''
df.loc[(df.A=='a1') & (df.B=='b1')]
# 对D列求平均数
# 3.0
df.loc[(df.A=='a1') & (df.B=='b1')].D.mean()筛选A列值为'a1'且B列值为'b1'的数据行,并对该数据行的D列求平均数,最终得到的结果为3.0,res1其他位置上的计算推导类似
import numpy as np
res2 = pd.pivot_table(df, index=['A','B'], columns=['C'],
values='D', aggfunc=np.sum, fill_value=0,
margins=True)
'''
C c1 c2 All
A B
a1 b1 0 3 3
b2 3 0 3
a2 b1 11 4 15
All 14 7 21
'''
print(res2)res2

index=['A','B'] 指定多个索引,aggfunc=np.sum 指定聚合方法为求和,fill_value=0 指定聚合为空的值为0,margins=True 增加行列汇总
import numpy as np
res3 = pd.pivot_table(df, index=['A','B'], columns=['C'],
values='D', aggfunc=[np.mean,np.sum])
'''
mean sum
C c1 c2 c1 c2
A B
a1 b1 NaN 3.0 NaN 3.0
b2 1.5 NaN 3.0 NaN
a2 b1 5.5 4.0 11.0 4.0
'''
print(res3)res3

aggfunc=[np.mean,np.sum] 指定聚合方法为求平均值以及求和,即我们可以使用aggfunc参数添加多个计算方法
如果DataFrame有多个数据列,我们也可以为每一个列指定不同的计算方法
导入数据
import pandas as pd
import numpy as np
df1 = pd.DataFrame({
'A':['a1', 'a1', 'a1', 'a2', 'a2', 'a2'],
'B':['b2', 'b2', 'b1', 'b1', 'b1', 'b1'],
'C':['c1', 'c1', 'c2', 'c2', 'c1', 'c1'],
'D':[1, 2, 3, 4, 5, 6],
'E':[7, 8, 9, 10, 11, 12]})
# D列求平均值,E列求和
res4 = pd.pivot_table(df1, index=['A','B'], columns=['C'],
aggfunc={'D':np.mean, 'E':np.sum})
'''
D E
C c1 c2 c1 c2
A B
a1 b1 NaN 3.0 NaN 9.0
b2 1.5 NaN 15.0 NaN
a2 b1 5.5 4.0 23.0 10.0
'''
print(res4)df1
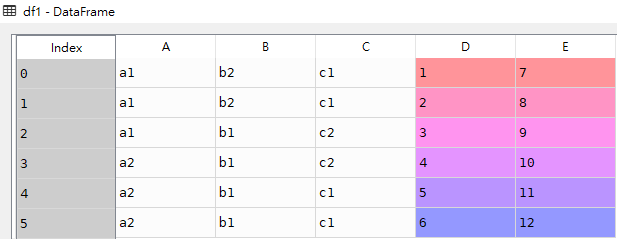
res4

最终形成的res4数据,D列求平均,E列求和
2.生成交叉表
交叉表(cross tabulation)是用于统计分组频率的特殊透视表
交叉表就是将两列或多列中不重复的元素组成一个新的DataFrame,新数据的行和列交叉部分的值为其组合在原数据中的数量
基本语法格式
pd.crosstab(index, columns, values=None,
rownames=None, colnames=None, aggfunc=None,
margins=False, margins_name='All',
dropna=True, normalize=False)参数说明
| 参数 | 描述 |
| index | 传入列,如df['A'],作为新数据的索引,新数据的索引为传入列的去重值 |
| columns | 传入列,如df['A'],作为新数据的列,新数据的列为传入列的去重值 |
| values | 传入列,根据此列的数值进行计算,计算方法取aggfunc参数指定的方法 |
| rownames | 为新数据index起名,一个序列,默认值为None,必须与传递的行数、组数匹配 |
| colnames | 为新数据columns起名,一个序列,默认值为None,必须与传递的列数、组数匹配 |
| aggfunc | 函数,values列计算使用的计算方法 |
| margins | 布尔值,默认值为False,对所有的行/列进行汇总 |
| margins_name | 指定汇总行/列的名称 |
| dropna | 布尔值,默认值为True,当某一列全为NULL值时,dropna=True时删除该列,否则保留 |
| normalize | { 'all', 'index', 'columns' } 或 { True, False },默认值为False,通过将对应值除以所有值的总和进行归一化 |
导入数据
import pandas as pd
# 原数据
df = pd.DataFrame({
'A':['a1','a1','a2','a2','a1'],
'B':['b2','b1','b2','b2','b1'],
'C':[1,2,3,4,5]})df
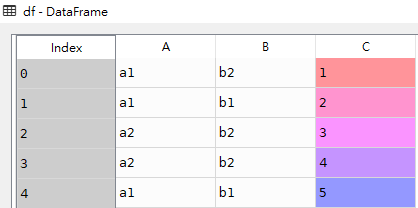
res1 = pd.crosstab(index=df['A'], columns=df['B'])
res1

A和B两列进行交叉,A列去重有a1和a2两个值,B列去重有b1和b2两个值。交叉后组成了新的数据,索引分别是a1和a2,列分别为b1和b2,它们交叉位上对应的值为此组合的数量,如(a1,b1)组合有2个,所以它们的交叉位上的值为2; (a1,b2)组合有1个,所以它们的交叉位上的值为1; 没有(a2,b1)组合,所以它们的交叉位上的值为0; (a2,b2)组合有2个,所以它们的交叉位上的值为2
import numpy as np
# 用aggfunc指定聚合方法对values指定的列进行计算
res2 = pd.crosstab(index=df['A'], columns=df['B'],
values=df['C'], aggfunc=np.sum)
res2

上述是对A列和B列进行交叉,按C列的值进行求和聚合
我们以(a1,b1)交叉位进行计算来源分析,在原来的df中,(a1,b1)组合有2个,对应C列值相加的和为7,故(a1,b1)交叉位值为7,其余交叉位计算类似
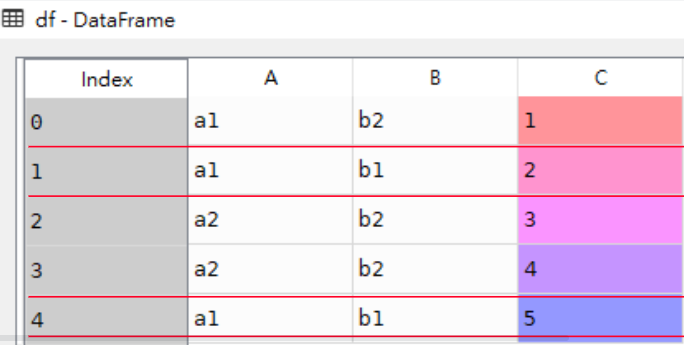
import numpy as np
# 交叉表,增加汇总
res3 = pd.crosstab(index=df['A'], columns=df['B'],
values=df['C'], aggfunc=np.sum,
margins=True, margins_name='Total')res3

margins=True可以增加行和列的汇总,按照行列方向对数据进行求和
margins_name='Total'可以定义这个汇总行和汇总列的名称
'''
B b1 b2
A
a1 2 1
a2 0 2
'''
pd.crosstab(index=df['A'], columns=df['B'])
res4 = pd.crosstab(index=df['A'], columns=df['B'], normalize=True)我们也可以使用rownames和colnames分别为index和columns起名
import pandas as pd
import numpy as np
# 原数据
df = pd.DataFrame({
'A':['a1','a1','a2','a2','a1'],
'B':['b2','b1','b2','b2','b1'],
'C':[1,2,3,4,5]})
# 未使用参数rownames和colnames起别名
pd.crosstab(index=df['A'], columns=df['B'],
values=df['C'], aggfunc=np.sum,
margins=True, margins_name='Total')
# 使用参数rownames和colnames起别名
pd.crosstab(index=df['A'], columns=df['B'],
values=df['C'], aggfunc=np.sum,
rownames=['Acol'],colnames=['Bcol'],
margins=True, margins_name='Total')输出以下结果
# 未使用参数rownames和colnames起别名
B b1 b2 Total
A
a1 7.0 1.0 8
a2 NaN 7.0 7
Total 7.0 8.0 15# 使用参数rownames和colnames起别名
Bcol b1 b2 Total
Acol
a1 7.0 1.0 8
a2 NaN 7.0 7
Total 7.0 8.0 15
res4

由上述结果可以清晰看到每个交叉位上的数据在全体中的地位
我们以(a1,b1)交叉位进行计算来源分析,在a1和b1交叉位上,值为2 / (2 + 1 + 0 + 2) = 2 / 5 = 0.4,故(a1,b1)交叉位值为0.4,其余交叉位计算类似
我们也可以对列进行归一化
'''
B b1 b2
A
a1 2 1
a2 0 2
'''
pd.crosstab(index=df['A'], columns=df['B'])
# 交叉表,按列归一化
res5 = pd.crosstab(index=df['A'], columns=df['B'], normalize='columns')res5
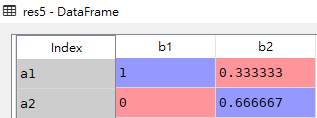
我们以(a1,b2)交叉位进行计算来源分析,在a1和b2交叉位上,值为1 / (1 + 2) = 1 / 3 = 0.333333,故(a1,b2)交叉位值为0.333333,其余交叉位计算类似
normalize参数可以帮助我们实现数据归一化,算法为对应值除以所有值的总和,让数据处于0~1的范围,方便我们观察此位置上的数据在全体中的地位





![Linux系统编程——多线程[上]:线程概念和线程控制](https://img-blog.csdnimg.cn/img_convert/12c8a65657e7f830bbd3592c846c9fbc.png)