我们知道学习一个技术,最好的方式就是从全局观出发,然后针对不同的点进行拆分,一个个破解。既可以将学到的和已有的知识联系起来,又可以有一定的深度和目的性。
Redis基础架构
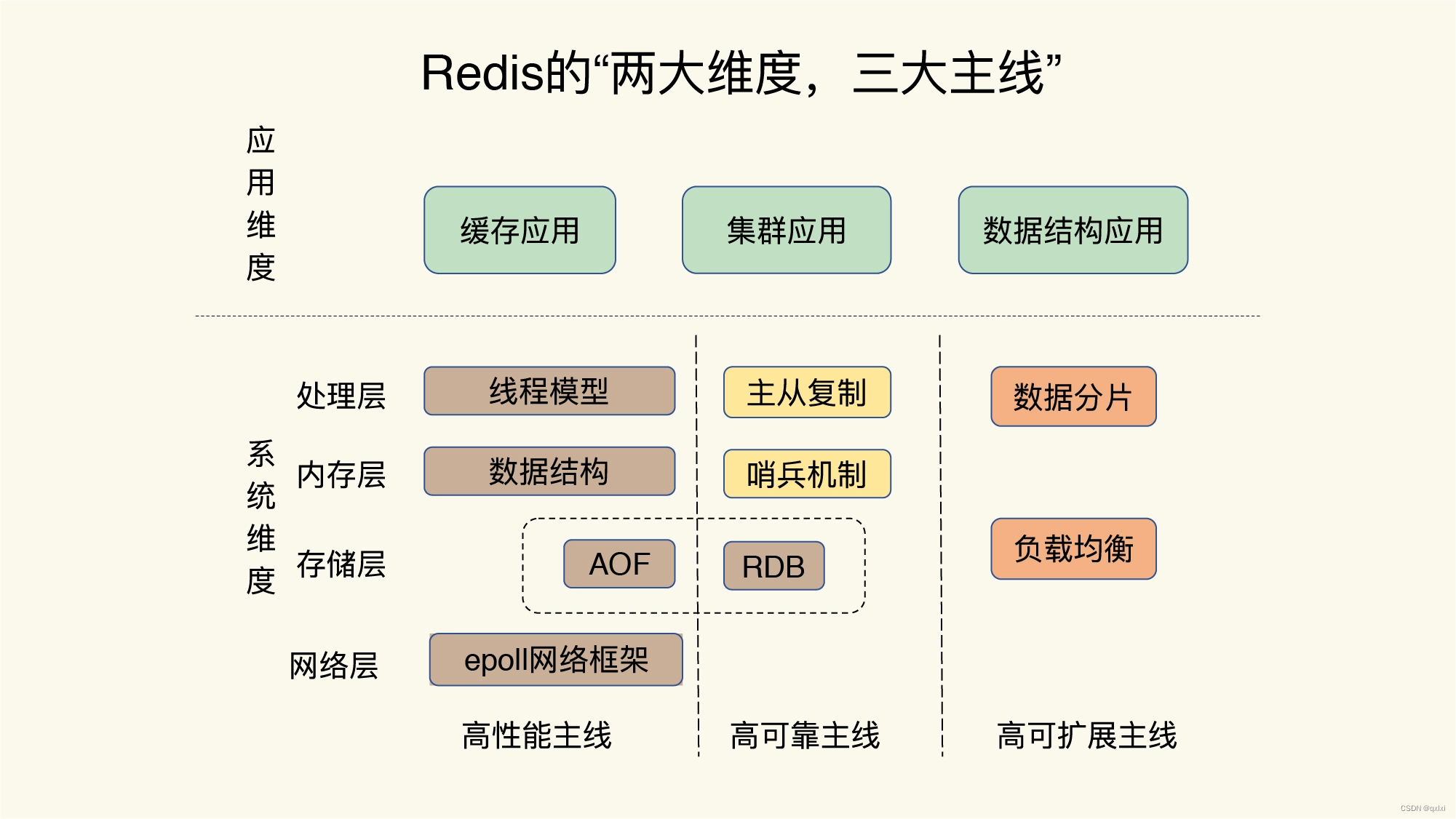
对于一个中间件来说,一个是使用层面(应用层面),另一个就是核心原理(系统纬度)。
对于Redis来说应用纬度包括
- 缓存应用:相应的使用场景,引出的问题等
- 集群应用:为实现高可用,高性能,必然使用集群模式
- 数据结构应用:不同的数据结构可以解决不同的问题。比如hash可以快速查找
对于系统纬度来说:
- 高性能主线:
- 线程模型:(单线程、多线程、Reactor模式等)
- 数据结构
- 持久化
- 网络框架
- 高可靠主线:
- 主从复制
- 哨兵机制
- 高可拓展主线:
- 数据分片
- 负载均衡
存哪些数据
对于键值数据库来说,基本结构就是Key-Values。但是为了支持更多业务场景,Redis提供了比较多的数据结构类型,具体就是String、List、Hash、Set、ZSet、GEO、HyperLogLog、BitMap、bitfield、Stream。
为什么要支持多样的数据结构呢
不同的数据结构,在空间和性能效率上是不同的,可以满足的业务场景也是不同,所以说需要根据具体的业务来结合使用相应的数据结构,充分发挥出对应数据结构的优点。
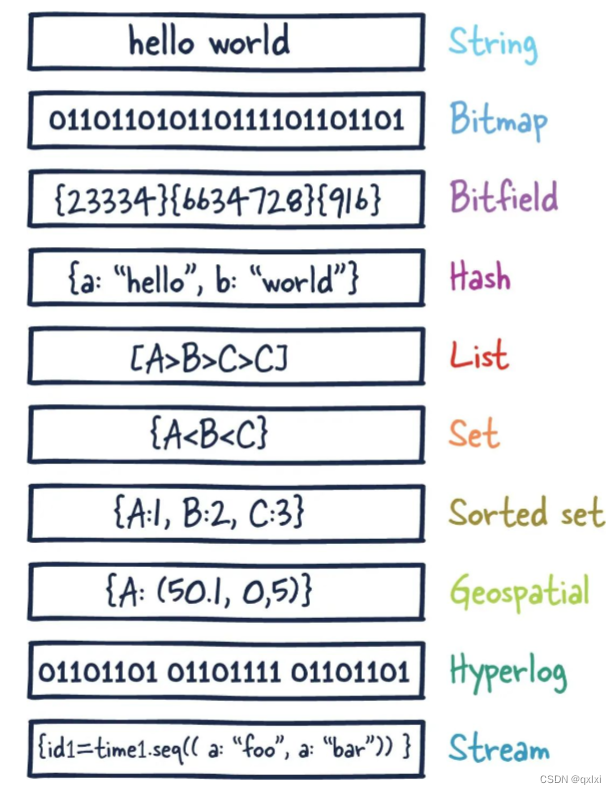
数据操作
上面列举了Redis的数据模型,但是对于数据的操作,无外乎就是以下三类。
- 添加/更新类
- 删除数据
- 获取数据
虽然Redis的客户端提供了基础的对数据的操作,但是比如对于一些判断数据是否存在exits、ttl等也需要提供。而数据存储的位置一般内存优先于磁盘,针对于可以容忍数据丢失的场景的业务来说。但是存储在磁盘中,可以持久化存储,但是访问速度就比较慢了,所以需要平衡二者。
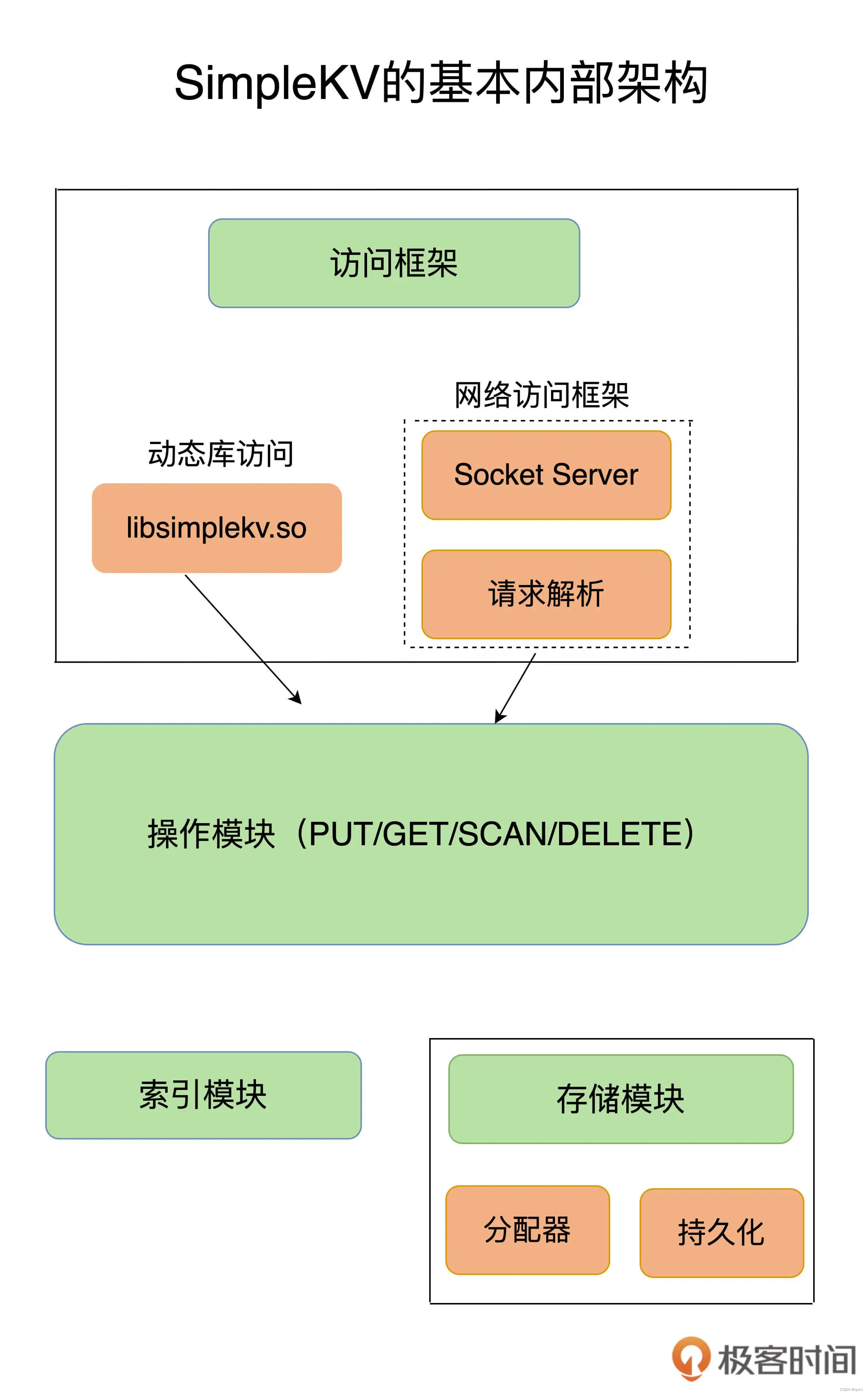
一个键值数据库的基本架构就是这样
- 访问框架
- 操作模块
- 索引模块
- 存储模块
访问模式
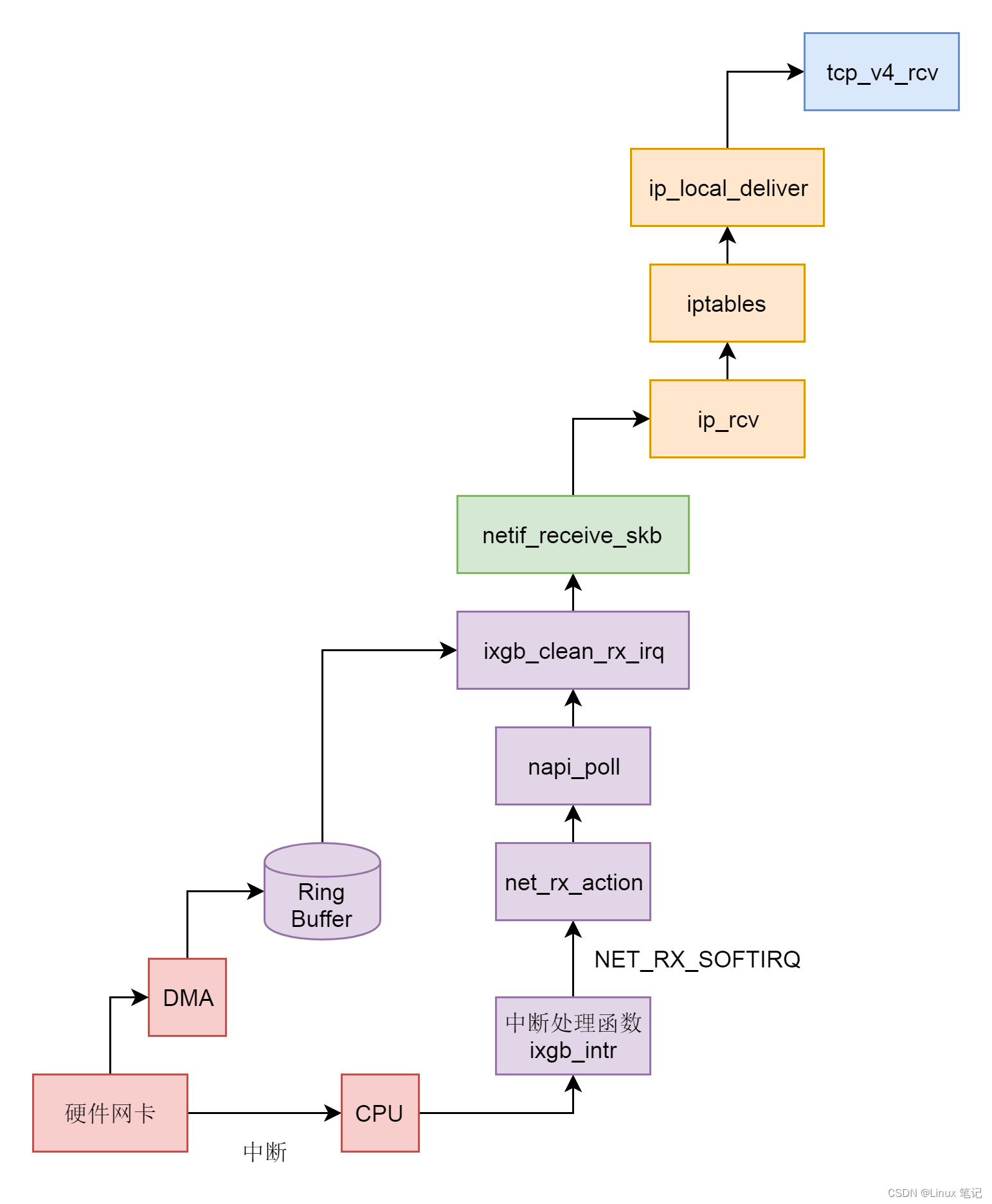
访问模式说白了就是如何连接到Redis服务端,一般来说一是可以通过函数连接库,二是通过网络框架,而Redis采用了后者。但是网络框架上需要解决的问题,比如数据的连接请求,数据数据,数据存储。如果是单线程,那么可能出现某一个流程的阻塞,导致整体性能下降。而如果是多线程,那么可能出现多个线程之间对于共享资源的竞争,而这个数据安全问题就需要考虑。而这就是IO模型设计。
定位键值对位置
当连接请求后,通过网络框架将请求到服务端后,这个时候如何进行查找相对应的key的位置,一般来说大多采用B+树、Hash等。而对于内存操作的Redis来说 使用Hash可以很好的和内存随机操作相匹配。