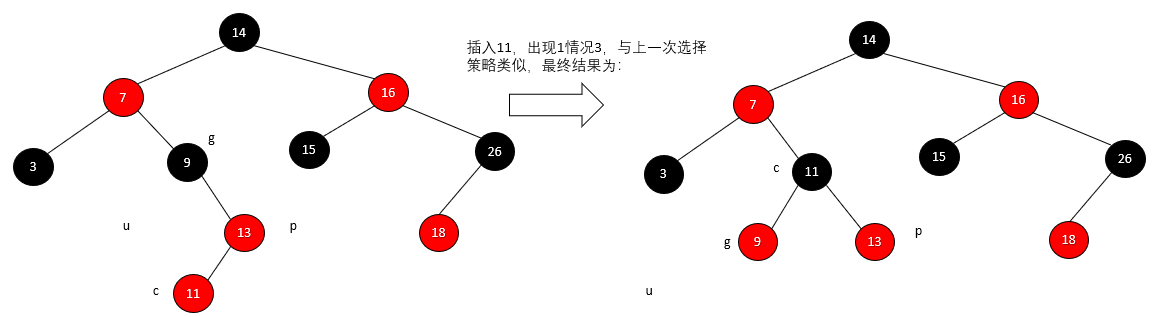
数据结构
类型
什么是类型 ?
内存中的二进制数据本身没有什么区别,就是一串0或1的组合。
内存中有一个字节内容是0x63,他究竟是深恶 字符串?字符?还是整数?
本来0x63表示数字 但是文字必须编码成为0和1的组合 才能记录在计算机系统中。在计算机世界里,一切都是数字,但是一定需要指定
类型才能正确的理解它的含义
如果0x63是整数,它就属于整数类型,它是整数类型的一个具体的实列 整数类型就是一个抽象的概念,他是对有一类有着共同特征的事务的抽象概念,
它就属于整数类型,它是整数类型的一个具体的实例。整数类型就是一个抽象的概念,它是对一类有着共同特征的事务的抽象概念。他展示出来就是99,因为多数情况下,程序按照人们习惯采用10进制输出
如果0x63时byte类型或者rune(字符int32)类型,在Go语言中,它是不同于整型的类型,但是展示出来同样时99.
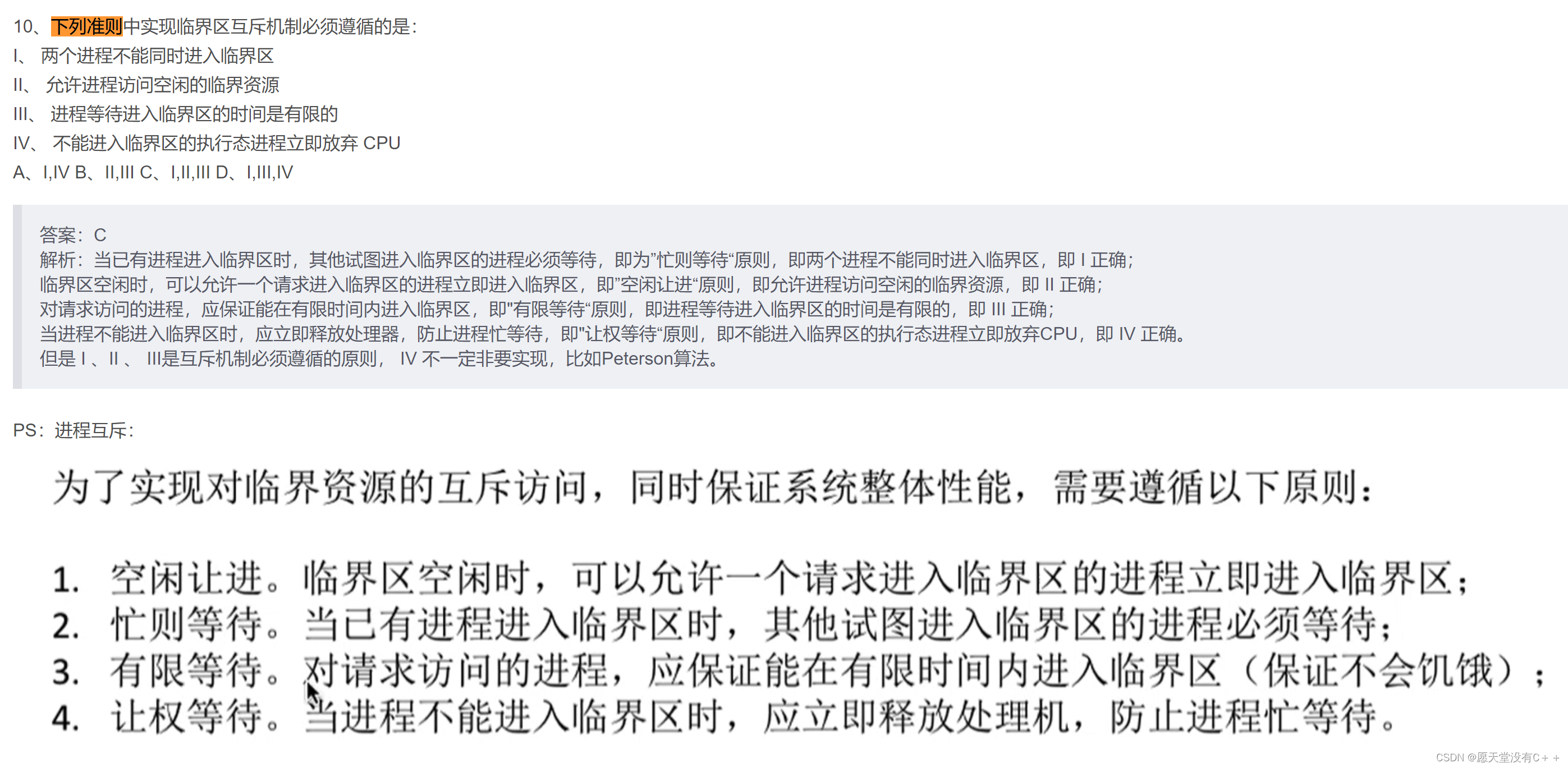
如果0x63时string类型,则展示出一个字符的字符串"c"。
func main(){
var a = 0x63
fmt.Printf("%T %[1]d %[1]c \n",a) //类型 数值 字符
var b byte = 0x63
fmt.Printf("%T %[1]d %[1]c\n",b) //uint8(字节) 99 c
var c rune = 0x63
fmt.Printf("%T %[1]d %[1]c\n",c)
// x:= '1' //单引号默认是字符类型
d := "\x63" //定义字符串
fmt.Printf("%T %[1]s\n",d)
fmt.Printf("%T %[1]s\n", string(a)) //将a 进行类型转换
}
//结果====>
/*
int 99 c
uint8 99 c
int32 99 c
string c
string c
*/
数值处理
math包的使用
取整
在fmt.Println(1/2, 3/2, 5/2) // "/" 整数除法,截取整数部分 "%"求模
fmt.Println(-1/2, -3/2, -5/2)
fmt.Println("~~~~~~~~~~~~~~~~~~~~~~~~~~~")
fmt.Println(math.Ceil(2.01), math.Ceil(2.5), math.Ceil(2.8)) //向上取整 2取3
fmt.Println(math.Ceil(-2.01), math.Ceil(-2.5), math.Ceil(-2.8))
fmt.Println("~~~~~~~~~~~~~~~~~~~~~~~~~~~")
fmt.Println(math.Floor(2.01), math.Floor(2.5), math.Floor(2.8)) //向下取整 -2. 取-2
fmt.Println(math.Floor(-2.01), math.Floor(-2.5), math.Floor(-2.8))
fmt.Println("~~~~~~~~~~~~~~~~~~~~~~~~~~~")
fmt.Println(math.Round(2.01), math.Round(2.5), math.Round(2.8)) //四舍五入
fmt.Println(math.Round(-2.01), math.Round(-2.5), math.Round(-2.8))
fmt.Println(math.Round(0.5), math.Round(1.5), math.Round(2.5),
math.Round(3.5))
运行结果
0 1 2
0 -1 -2
~~~~~~~~~~~~~~~~~~~~~~~~~~~
3 3 3
-2 -2 -2
~~~~~~~~~~~~~~~~~~~~~~~~~~~
2 2 2
-3 -3 -3
~~~~~~~~~~~~~~~~~~~~~~~~~~~
2 3 3
-2 -3 -3
1 2 3 4
其他数值处理
fmt.Println(math.Abs(-2.7)) // 绝对值
fmt.Println(math.E, math.Pi) // 常数
fmt.Println(math.MaxInt16, math.MinInt16) // 常量,极值
fmt.Println(math.Log10(100), math.Log2(8)) // 对数
fmt.Println(math.Max(1, 2), math.Min(-2, 3)) // 最大值、最小值
fmt.Println(math.Pow(2, 3), math.Pow10(3)) // 幂
fmt.Println(math.Mod(5, 2), 5%2) // 取模
fmt.Println(math.Sqrt(2), math.Sqrt(3), math.Pow(2, 0.5)) // 开方
标准输入
Scan: 空白字符分割,回车提交。换行符当作空白字符
package main
import (
"fmt"
)
func main() {
var n int
var err error
var word1, word2 string
fmt.Print("Plz input two words: ")
n, err = fmt.Scan(&word1, &word2) // 控制台输入时,单词之间空白字符分割
if err != nil {
panic(err)
}
fmt.Println(n)
fmt.Printf("%T %s, %T %s\n", word1, word1, word2, word2)
fmt.Println("~~~~~~~~~~~~~~~~~~~~~~~~~~~")
var i1, i2 int
fmt.Println("Plz input two ints: ")
n, err = fmt.Scan(&i1, &i2)
if err != nil {
panic(err)
}
fmt.Println(n)
fmt.Printf("%T %[1]d, %T %[2]d", i1, i2)
}
如果少一个数据,Scan就会堵塞;如果输入数据多了,等下回Scan读取。例如,一次性输入a b 1 2 看看效果
我们发现 当一次性输入 a b 1 2 的时候 第二个Scan会被自动赋值为 1 2 ,无需再手动输入
Scanf: 读取输入,按照格式匹配解析。如果解析失败,立即报错,那么就会影响后面的Scanf。
package main
import (
"fmt"
)
func main() {
var n int
var err error
var name string
var age int
fmt.Print("Plz input your name and age: ")
n, err = fmt.Scanf("%s %d\n", &name, &age) // 这里要有\n以匹配回车
if err != nil {
panic(err)
}
fmt.Println(n, name, age)
var weight, height int
fmt.Print("weight and height: ")
_, err = fmt.Scanf("%d %d", &weight, &height) //fmt.Scanf("%d,%d", &weight, &height)尽量不要使用这种
if err != nil {
panic(err)
}
fmt.Printf("%T %[1]d, %T %[2]d", weight, height)
}
线性数据结构
线性表:
- 线性表(简称表),是一种抽象的数学概念,是一组元素的系列的抽象,它由有穷个元素组成(0个或任意个)
- 顺序表:使用一大块连续的内存顺序存储表中的元素,这样实现的表称为顺序表,或称连续表
- 在顺序表中,元素的关系使用顺序表的存储顺序自然地表示
- 链接表:在存储空间中将分散存储的元素链接起来,这种称为链接表,简称链表
数组等类型,如同地铁站拍好的队伍,有序,可以插队,离队,可以进行索引
链表,就如同一串带线的珠子,随意摆放在桌子上 ,可以插队,离队,可以进行索引。
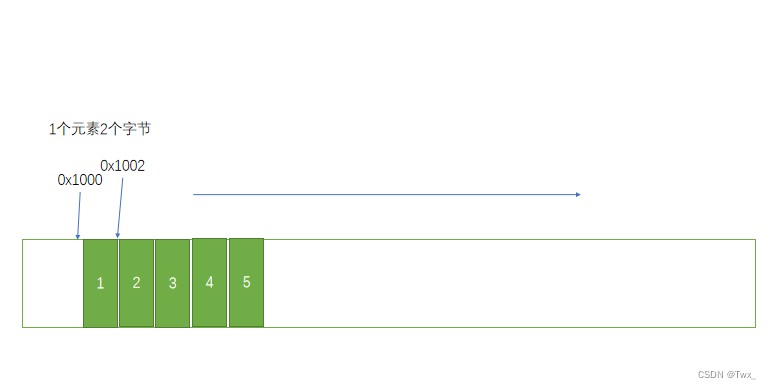
顺序表数据结构
可以看到 顺序表中的每一个元素的地址是依照顺序所排列的
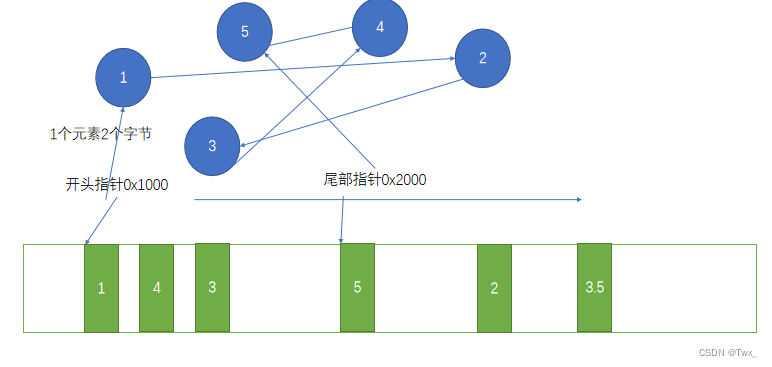
链接表数据结构
链接表中的元素 并不是有顺序的排列 他的各个元素 分布在不同的内存地址上,在双向链表中 index(n) 和index(n+1)相互记录了双方的地址,比如index1<->index2,index2<->index3,在单向链表中 前一个元素只记录第二个元素的地址
我们对比一下 线性数据结构中 顺序表和线性表的增删改查
顺序表:
- 知道某个元素的地址或者首地址,可以通过偏移量进行查找某个元素
增加元素:
- 尾部:直接在偏移量的内存位置放置 代价小
- 中间:相当于插队,此后所有的数据向后移
- 头部:从头开始所有元素依次向后挪动
修改元素:
- 使用索引找到元素,最快,找到修改即可
删除元素:
- 尾部: 如果是尾部 不需要挪动
- 中间或开头: 删除元素后 其元素需要要前挪动
链接表:
- 单向链接表来看,从头开始 效率相对低于顺序表
- 知道其中一个元素或者开始地址,不能直接通过偏移量找到某个元素,需要从头遍历一遍
增加元素:
- 尾部:尾巴指针增加元素,改改地址,效率高
- 中间:遍历查找,找到插入点 断开小手 分别连接
- 头部:改改地址 效率高
修改元素:
- 使用索引查找元素,修改其内容,效率较高
删除元素:
- 定位元素,索引最快
- 删除元素,断开小手重新拉 很快
数组
· 长度不可变
· 内容可变
· 可索引
· 值类型
· 顺序表
定义
// 注意下面2种区别
var a0 [3]int // 零值初始化3个元素的数组 [0,0,0] 未赋值 默认0值
var a1 = [3]int{} // 零值初始化3个元素的数组 [0,0,0]
// [3]int是类型,[3]int{} 是字面量值
var a2 [3]int = [3]int{1, 3, 5} // 声明且初始化,不推荐,啰嗦
var a3 = [3]int{1, 3, 5} // 声明且初始化,推荐
count := 3
a4 := [count] int{1,3,5} // 错误的长度类型,必须是常量,换成const
fmt.Println(a2, a3)
const count = 3
a4 := [count]int{1, 3, 5} // 正确
fmt.Println(a2, a3, a4)
a5 := [...]int {10, 30, 50} // ...让编译器确定当前数组大小
a6 := [5]int{100, 200} // 顺序初始化前面的,其余用零值填充
a7 := [5]int{1: 300, 3: 400} // 指定索引位置初始化,其余用零值填充
// 二维数组
a8 := [2][3]int{{100}} // 两行三列 [[100 0 0] [0 0 0]]
// [[10 0 0] [11 12 0] [13 14 15] [16 0 0]]
// 多维数组,只有第一维才能用...推测
// 第一维有4个,第二维有3个。可以看做4行3列的表
a9 := [...][3]int{{10}, {11, 12}, {13, 14, 15}, {16}}
长度和容量
· cap即capacity,容量,表示给数组分配的内存空间可以容纳多少个元素
· len即length,长度,指的是容器中目前有几个元素
由于数组创建时就必须确定的元素个数,且不能改变长度,所以不需要预留多余的内存空间,因此cap和len对数组来说一样。
索引
Go语言不支持负索引。通过[index]来获取该位置上的值。索引范围就是[0, 长度-1]。
修改
func main(){
//编译器定义数组长度
var a1 = [...]int{1,2,3}
a1[0] += 100 //[100,2,3]
}
遍历
索引遍历
func main(){
//编译器定义数组长度
var a1 = [...]int{1,2,3}
a1[0] += 100 //[100,2,3]
for i :=0;i<len(a1);i++{
fmt.Println(i,a1[i])
}
}
for-range 遍历
func main(){
//编译器定义数组长度
var a1 = [...]int{1,2,3}
a1[0] += 100 //[100,2,3]
//i 索引 v 元素值
for i,v := range a1{
fmt.Println(i,v)
}
}
内存模型
func main(){
var a [3]int
for i:=0;i<len(a);i++{
fmt.Println(i,a[i],&a[i])
}
fmt.Printf("%p %p, %v\n", &a, &a[0], a)
a[0] = 1000
fmt.Printf("%p %p, %v\n", &a, &a[0], a)
}
===========================================================================
0 0 0xc0000ae078
1 0 0xc0000ae080
2 0 0xc0000ae088
0xc0000ae078 0xc0000ae078, [0 0 0] //数组地址 首元素地址 数组元素
0xc0000ae078 0xc0000ae078, [1000 0 0]
上面的每个元素间隔8字节 正好是64位,符合int定义
· 数组必须在编译时就确定大小,之后不能改变大小
· 数组首地址就是数组地址
· 所有元素一个接一个顺序存在内存中
· 元素的值可以改变 但元素的地址不变
如果元素字符串类型呢?
func main() {
var a = [3]string{"abc","xyzafsdfdsgdgdf","asd"}
for i := 0; i < len(a); i++ {
fmt.Println(i,a[i],&a[i])
}
fmt.Printf("%p %p, %v\n",&a,&a[0],a)
}
=======================================================================
0 abc 0xc000112480
1 xyzafsdfdsgdgdf 0xc000112490
2 asd 0xc0001124a0
0xc000112480 0xc000112480, [abc xyzafsdfdsgdgdf asd]
· 数组首地址是第一个元素的地址
· 所有元素顺序存储在内存中
· 元素的值可以改变,但是元素地址不变
我们可以发现 字符串数组每个元素的地址偏移量相差16个字节,这是为什么? 为什么第二个元素占了这么多位置,
还是和第三个元素相差16个字节?
原因 :
字符串实际上是引用类型,Go字符串默认内存中存储16字节,它的元素卸载了堆上
值类型
func main() {
var a1 = [2]int{1,2}
fmt.Printf("a1 %p %p\n",&a1,&a1[0])
a2 := a1
fmt.Printf("a2 %p %p\n",&a2,&a2[0])
//调用函数 将a1做为实参传入
showAddr(a1)
}
====================================================================================
a1 0xc0000140a0 0xc0000140a0
a2 0xc0000140d0 0xc0000140d0
a3 0xc0000140e0 0xc0000140e0
可以看出a1,a2,a3的地址都不一样,a2:=a1的地址也不一样,这说明,Go语言在这些地方进行了
值拷贝,都生成了一份副本。
切片
· 长度可变
· 内容可变
· 引用类型
· 底层基于数组
func main() {
//定义切片
var s1 []int
var s2 = []int{}
var s3 = []int{1,2,3} //定义字面量 长度为3 容量为3
var s4 = make([]int,3,5) //使用make定义切片 make([]type,len,cap) 数据类型是切片引用类型,长度为3 容量位5
//s4 的结果是 [0,0,0]
}
内存模型
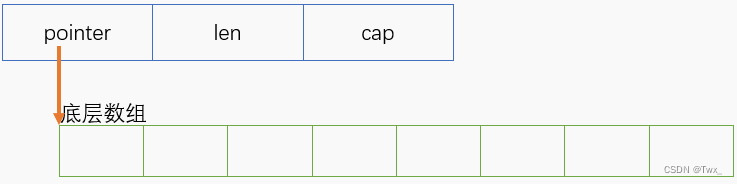
切片本质是对底层数组一个连续片段的引用,此片段可以是整个底层数组,也可以是起始和终止索引标识的一些项的子集。
//以下是go切片的结构体 他的属性成员是 底层数组的指针,长度,容量
// https://github.com/golang/go/blob/master/src/runtime/slice.go
type slice struct {
array unsafe.Pointer
len int
cap int
}
func main() {
//定义切片
var s1 []int = []int{1,2,3}
fmt.Printf("切片地址: %p 底层数组地址: %p",&s1,&s1[0])
}
---------------------------------------------------------------------
切片地址: 0xc00009e060 底层数组地址: 0xc0000ae078
引用类型
func showAddr(s []int) ([]int,error){
fmt.Printf("s %p,%p,%d,%d,%v\n",&s,&s[0],len(s),cap(s))
//修改一个元素
if len(s) <= 0 {
return nil, errors.New("切片不应为空值")
}else {
s[0] = 100
return s ,nil
}
}
func main() {
s1 := []int{10,20,30}
fmt.Printf("s1 %p, %p, %d, %d, %v\n", &s1, &s1[0], len(s1), cap(s1), s1)
s2 := s1
fmt.Printf("s2 %p, %p, %d, %d, %v\n", &s2, &s2[0], len(s2), cap(s2), s2)
fmt.Println("~~~~~~~~~~~~~~~~~~~~~~~~~~~")
s3,_:= showAddr(s1)
fmt.Printf("s1 %p, %p, %d, %d, %v\n", &s1, &s1[0], len(s1), cap(s1), s1)
fmt.Printf("s2 %p, %p, %d, %d, %v\n", &s2, &s2[0], len(s2), cap(s2), s2)
fmt.Printf("s3 %p, %p, %d, %d, %v\n", &s3, &s3[0], len(s3), cap(s3), s3)
}
--------------------------------------------------------------------------------------
s1 0xc000004078, 0xc00000c198, 3, 3, [10 20 30]
s2 0xc0000040a8, 0xc00000c198, 3, 3, [10 20 30]
~~~~~~~~~~~~~~~~~~~~~~~~~~~
s 0xc0000040f0,0xc00000c198,3,3,%!v(MISSING)
s1 0xc000004078, 0xc00000c198, 3, 3, [100 20 30]
s2 0xc0000040a8, 0xc00000c198, 3, 3, [100 20 30]
s3 0xc0000040d8, 0xc00000c198, 3, 3, [100 20 30]
可以发现 ,我们定义的这些切片 他们的header值都不一样,但是底层数组用的是同一个。
那如果在上面showAddr函数中对切片增加一个元素会怎么样呢?
我们学习下 如何对切片进行追加元素操作
append:在切片的尾部追加元素,长度加1。
增加元素后,有可能超过当前容量,导致切片扩容。
func main() {
//追加操作
s1 := make([]int,3,5)
fmt.Printf("s1 %p, %p, l=%-2d, c=%-2d, %v\n", &s1, &s1[0], len(s1), cap(s1), s1) //[0,0,0]
s2 := append(s1,1,2)
fmt.Printf("s1 %p, %p, l=%-2d, c=%-2d, %v\n", &s1, &s1[0], len(s1), cap(s1), s1) //[0,0,0]
fmt.Printf("s2 %p, %p, l=%-2d, c=%-2d, %v\n", &s2, &s2[0], len(s2), cap(s2), s2) //[0,0,0,1,2]
s3 := append(s1,-1)
fmt.Printf("s1 %p, %p, l=%-2d, c=%-2d, %v\n", &s1, &s1[0], len(s1), cap(s1), s1) //[0,0,0]
fmt.Printf("s2 %p, %p, l=%-2d, c=%-2d, %v\n", &s2, &s2[0], len(s2), cap(s2), s2) //[0,0,0,-1,2]
fmt.Printf("s3 %p, %p, l=%-2d, c=%-2d, %v\n", &s3, &s3[0], len(s3), cap(s3), s3) //[0,0,0,-1]
s4 := append(s3,3,4,5)
fmt.Printf("s1 %p, %p, l=%-2d, c=%-2d, %v\n", &s1, &s1[0], len(s1), cap(s1), s1) //[0,0,0]
fmt.Printf("s2 %p, %p, l=%-2d, c=%-2d, %v\n", &s2, &s2[0], len(s2), cap(s2), s2) //[0,0,0,-1,2]
fmt.Printf("s3 %p, %p, l=%-2d, c=%-2d, %v\n", &s3, &s3[0], len(s3), cap(s3), s3) //[0,0,0,-1]
fmt.Printf("s4 %p, %p, l=%-2d, c=%-2d, %v\n", &s4, &s4[0], len(s4), cap(s4), s4)//[0,0,0,-1,3,4,5]
}
---------------------------------------------------------------------------------------------------------------
s1 0xc000004078, 0xc00000a450, l=3 , c=5 , [0 0 0]
s1 0xc000004078, 0xc00000a450, l=3 , c=5 , [0 0 0]
s2 0xc0000040a8, 0xc00000a450, l=5 , c=5 , [0 0 0 1 2]
s1 0xc000004078, 0xc00000a450, l=3 , c=5 , [0 0 0]
s2 0xc0000040a8, 0xc00000a450, l=5 , c=5 , [0 0 0 -1 2]
s3 0xc0000040f0, 0xc00000a450, l=4 , c=5 , [0 0 0 -1]
s1 0xc000004078, 0xc00000a450, l=3 , c=5 , [0 0 0]
s2 0xc0000040a8, 0xc00000a450, l=5 , c=5 , [0 0 0 -1 2]
s3 0xc0000040f0, 0xc00000a450, l=4 , c=5 , [0 0 0 -1]
s4 0xc000004150, 0xc00000e230, l=7 , c=10, [0 0 0 -1 3 4 5] //长度超过了底层数组的容量,底层数组变更了
· append一定返回一个新的切片
· append可以增加若干元素
- 如果增加元素时,当前长度+新增个数 <= cap则不扩容
原切片使用元来的底层数组,返回的新切片也使用这个底层数组
返回的新切片有新的长度
原切片长度不变 - 如果增加元素时,当前长度+新增个数 >cap 则进行扩容
生成新的底层数组,新生成的切片使用该新数组,将旧数组中的数据拷贝到新数组中,并且追加元素
原切片底层数组、长度、容量不变
扩容策略
(新版本1.18+)阈值变成了256,当扩容后的cap<256时,扩容翻倍,容量变成之前的2倍;当
cap>=256时, newcap += (newcap + 3*threshold) / 4 计算后就是 newcap = newcap +
newcap/4 + 192 ,即1.25倍后再加192。
扩容是创建新的内部数组,把原内存数据拷贝到新内存空间,然后在新内存空间上执行元素追加操作。
切片频繁扩容成本非常高,所以尽量早估算出使用的大小,一次性给够,建议使用make。
增加一个元素会导致扩容,会怎么样呢?请先在脑中思考
package main
import (
"fmt"
)
func showAddr(s []int) []int {
fmt.Printf("s %p, %p, %d, %d, %v\n", &s, &s[0], len(s), cap(s), s)
// 修改一个元素
if len(s) > 0 {
s[0] = 123
}
return s
}
func main() {
s1 := []int{10, 20, 33}
fmt.Printf("s1 %p, %p, %d, %d, %v\n", &s1, &s1[0], len(s1), cap(s1), s1)
s2 := s1
fmt.Printf("s2 %p, %p, %d, %d, %v\n", &s2, &s2[0], len(s2), cap(s2), s2)
fmt.Println("~~~~~~~~~~~~~~~~~~~~~~~~~~~")
s3 := showAddr(s1)
fmt.Printf("s1 %p, %p, %d, %d, %v\n", &s1, &s1[0], len(s1), cap(s1), s1)
fmt.Printf("s2 %p, %p, %d, %d, %v\n", &s2, &s2[0], len(s2), cap(s2), s2)
fmt.Printf("s3 %p, %p, %d, %d, %v\n", &s3, &s3[0], len(s3), cap(s3), s3)
}
运行结果
s1 0xc000008078, 0xc0000101b0, 3, 3, [10 20 33]
s2 0xc0000080a8, 0xc0000101b0, 3, 3, [10 20 33]
~~~~~~~~~~~~~~~~~~~~~~~~~~~
s 0xc0000080f0, 0xc0000101b0, 3, 3, [10 20 33]
s1 0xc000008078, 0xc0000101b0, 3, 3, [123 20 33]
s2 0xc0000080a8, 0xc0000101b0, 3, 3, [123 20 33]
s3 0xc0000080d8, 0xc0000101b0, 3, 3, [123 20 33]
这说明,底层数组是同一份,修改切片中的某个已有元素,那么所有切片都能看到。
那如果在上面showAddr函数中对切片增加一个元素会怎么样呢?
增加一个元素会导致扩容,会怎么样呢?
package main
import (
"fmt"
)
func showAddr(s []int) []int {
fmt.Printf("s %p, %p, %d, %d, %v\n", &s, &s[0], len(s), cap(s), s)
// // 修改一个元素
// if len(s) > 0 {
// s[0] = 123
// }
s = append(s, 100, 200) // 覆盖s,请问s1会怎么样
fmt.Printf("s %p, %p, %d, %d, %v\n", &s, &s[0], len(s), cap(s), s)
return s
}
func main() {
s1 := []int{10, 20, 30}
fmt.Printf("s1 %p, %p, %d, %d, %v\n", &s1, &s1[0], len(s1), cap(s1), s1)
s2 := s1
fmt.Printf("s2 %p, %p, %d, %d, %v\n", &s2, &s2[0], len(s2), cap(s2), s2)
fmt.Println("~~~~~~~~~~~~~~~~~~~~~~~~~~~")
s3 := showAddr(s1)
fmt.Printf("s1 %p, %p, %d, %d, %v\n", &s1, &s1[0], len(s1), cap(s1), s1)
fmt.Printf("s2 %p, %p, %d, %d, %v\n", &s2, &s2[0], len(s2), cap(s2), s2)
fmt.Printf("s3 %p, %p, %d, %d, %v\n", &s3, &s3[0], len(s3), cap(s3), s3)
}
运行结果
s1 0xc000008078, 0xc0000101b0, 3, 3, [10 20 30]
s2 0xc0000080a8, 0xc0000101b0, 3, 3, [10 20 30]
~~~~~~~~~~~~~~~~~~~~~~~~~~~
s 0xc0000080f0, 0xc0000101b0, 3, 3, [10 20 30]
s 0xc0000080f0, 0xc00000e390, 5, 6, [10 20 30 100 200]
s1 0xc000008078, 0xc0000101b0, 3, 3, [10 20 30]
s2 0xc0000080a8, 0xc0000101b0, 3, 3, [10 20 30]
s3 0xc0000080d8, 0xc00000e390, 5, 6, [10 20 30 100 200]
可以看到showAddr传入s1,但是返回的s3已经和s1不共用同一个底层数组了,分道扬镳了。
其实这里还是值拷贝,不过拷贝的是切片的标头值(Header)。标头值内指针也被复制,刚复制完大家
指向同一个底层数组罢了。但是仅仅知道这些不够,因为一旦操作切片时扩容了,或另一个切片增加元
素,那么就不能简单归结为“切片是引用类型,拷贝了地址”这样简单的话来解释了。要具体问题,具体
分析。