学习hive之路就此开启啦,让我们共同努力
目录
Hive网站:
Hive的安装部署:
启动并使用Hive:
安装Mysql:
安装Mysql依赖包:
启动Mysql:
查看密码:
登录root:
密码错误报错:
元数据库配置:
(1)登录Mysql:
(2)创建元数据库:
(3)将MySQL的JDBC驱动拷贝到Hive的lib目录下:
(4)在$HIVE_HOME/conf目录下新建hive-site.xml文件
(5)初始化Hive元数据库(修改为采用MySQL存储元数据)
Hive服务部署:
hiveserver2服务:
2)hiveserver2部署
(2)Hive端配置
启动hive:
客户端:
图形化界面:
metastore服务:
metastore运行模式:
(1)嵌入式模式:
(2)独立服务模式
Hive网站:
学习hive之前这几个网站是必不可少的
1)Hive官网地址
官网地址
2)文档查看地址
查看文档地址
3)下载地址
下载地址
4)github地址
GitHub - apache/hive: Apache Hive
Hive的安装部署:
(1)先下载Hive(要与你的Hadoop版本不产生冲突)
(2)上传到你的虚拟机中
(3)解压到你的虚拟机中
(4)添加环境变量
(需要管理员权限)
vim /etc/profile.d/my_env.sh在脚本中添加环境配置:
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin(5)source一下
这里用到了source而我想不起来它的具体作用了,便去重新了解了一下
作用如下:
-
加载环境变量:通过使用
source命令加载一个脚本文件,可以将其中定义的环境变量导入到当前Shell会话中。这样,可以在当前会话中直接使用这些变量,而无需每次启动一个新的Shell会话。 -
执行脚本:
source命令可以用于在当前Shell中执行指定的脚本文件。这对于需要在当前Shell中运行脚本并将其中的命令结果直接应用到当前环境的情况非常有用。 -
重载配置文件:某些应用程序和服务在配置更改后需要重新加载配置文件才能生效。使用
source命令可以重新加载这些应用程序或服务的配置文件,使更改立即生效,而无需重新启动整个应用程序或服务。 -
导入函数和别名:通过使用
source命令加载一个包含函数和别名定义的脚本文件,可以将这些函数和别名导入到当前Shell会话中,从而可以在当前会话中直接调用这些函数和别名,而无需每次重新定义。
(6)初始化元数据库
在初始化时默认为 derby数据库
在那个目录下执行命令就在那个目录下建立数据库
bin/schematool -dbType derby -initSchema启动并使用Hive:
启动Hive:
在Hive目录下执行命令:
bin/hive简单使用Hive:
创建表:
create table stu(id int, name string)添加数据:
insert into stu values(1,"ss")第二次添加数据:
insert into stu values(1,"sshjkjkj")查询数据:
查询数据是很快的,对于简单查询是不需要调度yarn提交任务的
select * from stu;
以上操作我们可以查看HDFS客户端来看变化:
在HDFS中生成新的文件夹/user/hive/warehouse/stu
因此可知 hive中的表对于HDFS中的文件夹 向hive表中添加数据生成文件(添加一次生成一个)

上述为最小化模式,只可单机运行,不可多客户端运行(derby为单机数据库)
为了应对开发环境,我们通常把元数据库存储在Mysql中
安装Mysql:
先将Mysql上传到Linux上,再解压tar包
因为系统自带的mariadb与Mysql冲突,所以需要卸载mariadb
安装Mysql依赖包:
(1)安装common包:
sudo rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm(2)安装libs包:
rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm(3) 安装libs-compat包:
rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm(4) 安装client:
rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm(5)安装server:
rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm依次安装
启动Mysql:
systemctl start mysqld查看密码:
在我们第一一次启动Mysql是会在日志中记录我们的初始密码
cat /var/log/mysqld.log | grep password登录root:
根据上个命令查看到的密码进行登录让后进行修改密码(密码必须足够复杂不然因为MySQL密码策略会不让你修改)因此我们要修改密码策略
set global validate_password_policy=0;
set global validate_password_length=4;让后就可以设置简单的密码了
设置:
set password=password("123456");进入MySQL库 :
use mysql 查询user表:
select user, host from user; 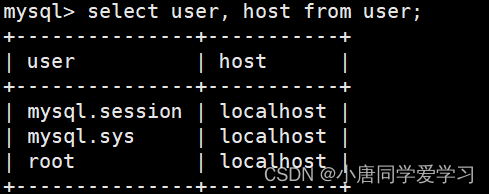
user 列:存储了MySQL数据库中的用户名称(用户名)。每个用户都有一个唯一的用户名,用于标识用户在数据库中的身份
host 列:指定了与用户关联的主机名(或IP地址)。它定义了允许该用户连接到MySQL数据库的来源。用户可以通过指定主机名或IP地址来限制或允许他们连接到数据库。
修改user表:
我们可以修改root用户所关联的主机为允许 root 用户从任何主机连接到MySQL数据库。
update user set host="%" where user="root";
密码错误报错:
如果第一次登录mysql就遇到提示密码错误可以看下边文章:
链接
元数据库配置:
元数据库原来时存在本机数据库derby中的,我们为了应和生产环境要在MySQL中创建元数据库
(1)登录Mysql:
mysql -uroot -p123456(2)创建元数据库:
create database metastore;(3)将MySQL的JDBC驱动拷贝到Hive的lib目录下:
因为Hive要与Mysql建立链接存储元数据,所以需要把JDBC驱动拷贝过去确保Hive能够正确地连接到MySQL数据库
(4)在$HIVE_HOME/conf目录下新建hive-site.xml文件
创建这个文件是一个重要的配置文件,用于指定Hive的配置参数
配置文件内容如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>(5)初始化Hive元数据库(修改为采用MySQL存储元数据)
执行hive的bin目录下的一个脚本
bin/schematool -dbType mysql -initSchema -verboseHive服务部署:
hiveserver2服务:
Hive的hiveserver2服务的作用是提供jdbc/odbc接口,为用户提供远程访问Hive数据的功能,例如用户期望在个人电脑中访问远程服务中的Hive数据,就需要用到Hiveserver2。
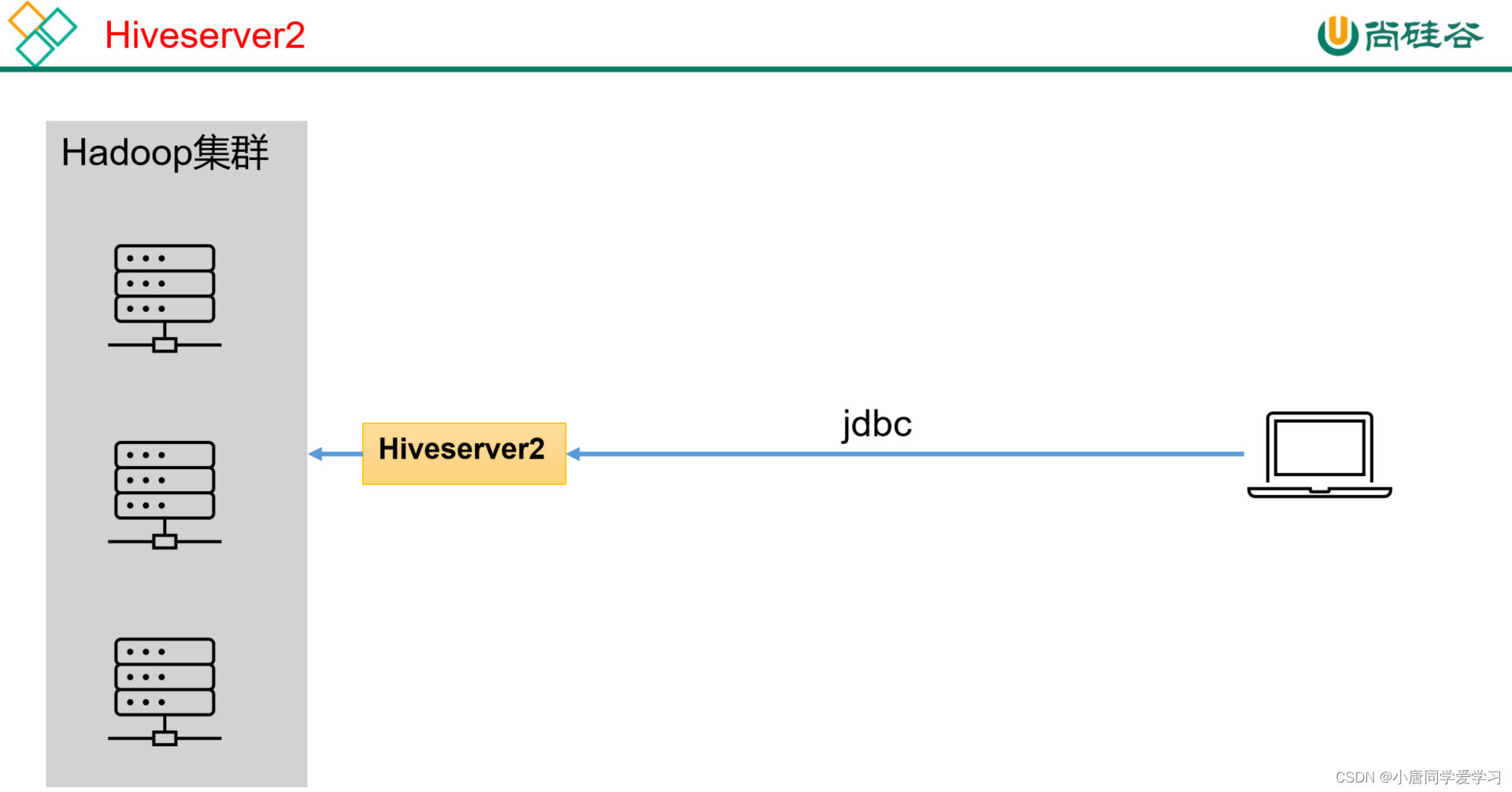
1)用户说明
在远程访问Hive数据时,客户端并未直接访问Hadoop集群,而是由Hivesever2代理访问。由于Hadoop集群中的数据具备访问权限控制,所以此时需考虑一个问题:那就是访问Hadoop集群的用户身份是谁?是Hiveserver2的启动用户?还是客户端的登录用户?
答案是都有可能,具体是谁,由Hiveserver2的hive.server2.enable.doAs参数决定,该参数的含义是是否启用Hiveserver2用户模拟的功能。若启用,则Hiveserver2会模拟成客户端的登录用户去访问Hadoop集群的数据,不启用,则Hivesever2会直接使用启动用户访问Hadoop集群数据。模拟用户的功能,默认是开启的。
具体逻辑如下:
未开启用户模拟功能:
开启用户模拟功能:
生产环境,推荐开启用户模拟功能,因为开启后才能保证各用户之间的权限隔离。
2)hiveserver2部署
(1)Hadoop端配置
hivesever2的模拟用户功能,依赖于Hadoop提供的proxy user(代理用户功能),只有Hadoop中的代理用户才能模拟其他用户的身份访问Hadoop集群。因此,需要将hiveserver2的启动用户设置为Hadoop的代理用户,配置方式如下:
修改配置文件core-site.xml,然后记得分发三台机器
cd $HADOOP_HOME/etc/hadoopvim core-site.xml添加配置如下:
<!--配置所有节点的atguigu用户都可作为代理用户-->
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
<!--配置atguigu用户能够代理的用户组为任意组-->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
<!--配置atguigu用户能够代理的用户为任意用户-->
<property>
<name>hadoop.proxyuser.atguigu.users</name>
<value>*</value>
</property>(2)Hive端配置
在hive-site.xml文件中添加如下配置信息
vim hive-site.xml<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>启动hive:
在hive下bin目录下有一个hiveserver2脚本进行启动
bin/hiveserver2但是这样启动的hiveserver2是处于阻塞状态的
对命令进行修改:
nohup bin/hiveserver2 &作用是在后台启动HiveServer2进程,并且使用nohup命令使其脱离终端控制,使其在用户退出终端时仍然可以运行
客户端:
在启动客户端之前要先确认hiveserver2启动
(1)使用命令行客户端beeline进行远程访问
(它存在bin目录下)

![]()
上述命令是获取jdbc连接 输入连接的主机与端口号
![]()
上述命令是登录hadoop102的用户名
第二行是输入密码(由于我们还没有启用hiveserver2的用户认定功能,所以我们可以不填密码)
图形化界面:
这里图形化页面是使用的DataGrip工具
经过我们创建hive连接与下载缺少的jdbc驱动现在正常使用
metastore服务:
Hive的metastore服务的作用是为Hive CLI或者Hiveserver2提供元数据访问接口。(只是提供接口,不存储元数据)
metastore运行模式:
(1)嵌入式模式:
嵌入式模式是在每个客户端中都嵌入了一个metastore服务,都可以自行进行访问元数据库
模式图:
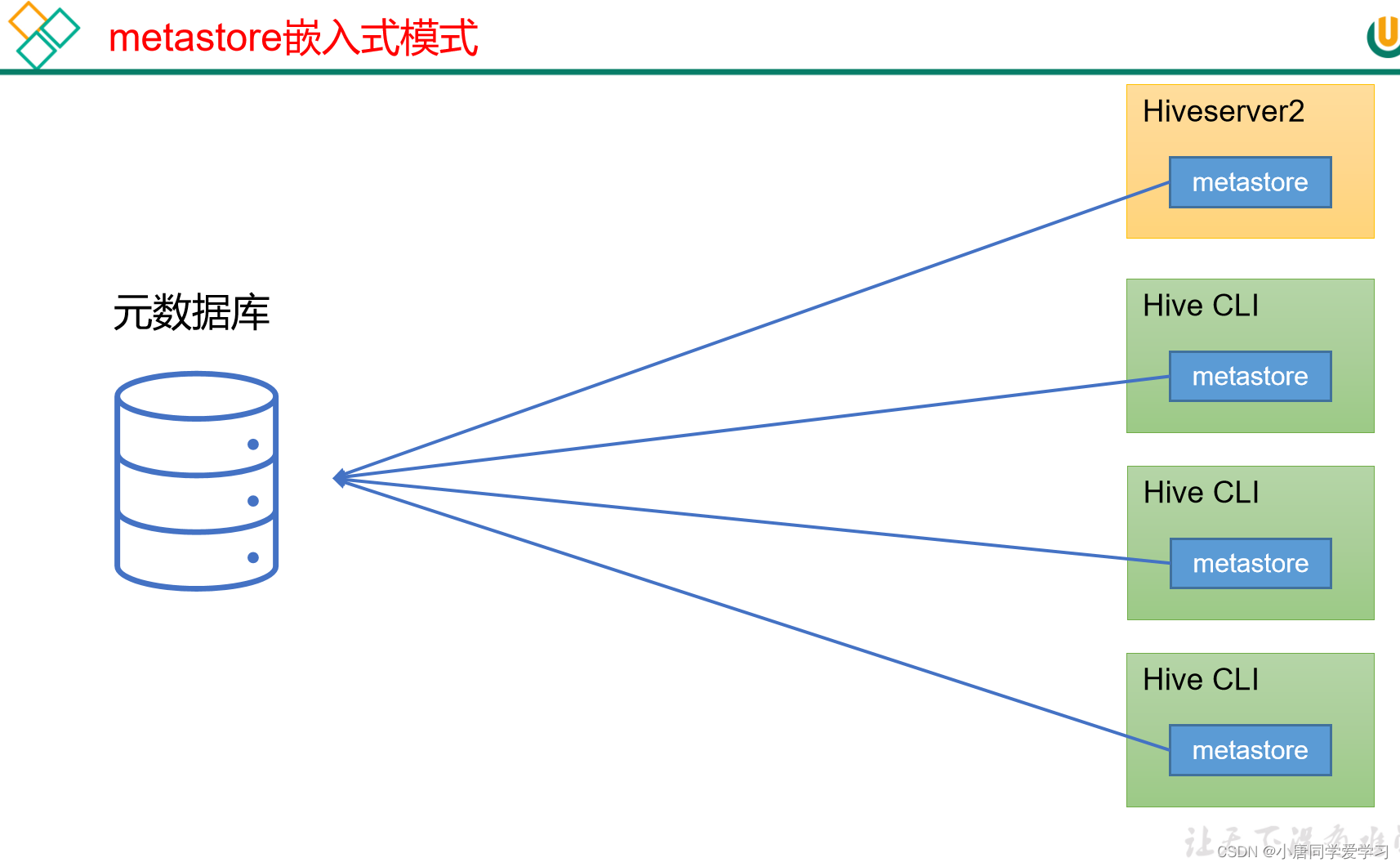
在生产环境中并不推荐,原因如下:
嵌入式模式下,每个Hive CLI都需要直接连接元数据库,当Hive CLI较多时,数据库压力会比较大。
每个客户端都需要用户元数据库的读写权限,元数据库的安全得不到很好的保证。
嵌入式模式部署:
需要在每个客户端中的hive-site.xml文件中添加与jdbc连接相关配置文件
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>(2)独立服务模式:
独立服务模式是每个客户端都共用一个服务,通过服务进行访问元数据库
模式图如下:

独立服务模式的部署:
在metastor所在的服务器上的hive-site.xml中添加jdbc连接元数据库相关的配置:
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>在其他的服务器上要在hive-site.xml中添加metastors的地址:
<!-- 指定metastore服务的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>注:
如果两种模式下的配置文件都包含,会按照独立服务模式进行