目录
前言:功能描述
第一步:flume拉取日志数据,并将源数据保存至Kafka
flume配置文件:
users:
user_friends_raw:
events:
train:
第二步:Kafka源数据处理
方式一:KafkaStream
EventAttendStream
UserFriendsStream
方式二:sparkStreaming
EventAttendeesRaw -> EventAttendees
UserFriendRaw -> UserFriend
第三步:Kafka topic数据发送到HBase
EventAttendee -> HBase
Events -> HBase
Train -> HBase
UserFriends -> HBase
Users -> HBase
前言:功能描述
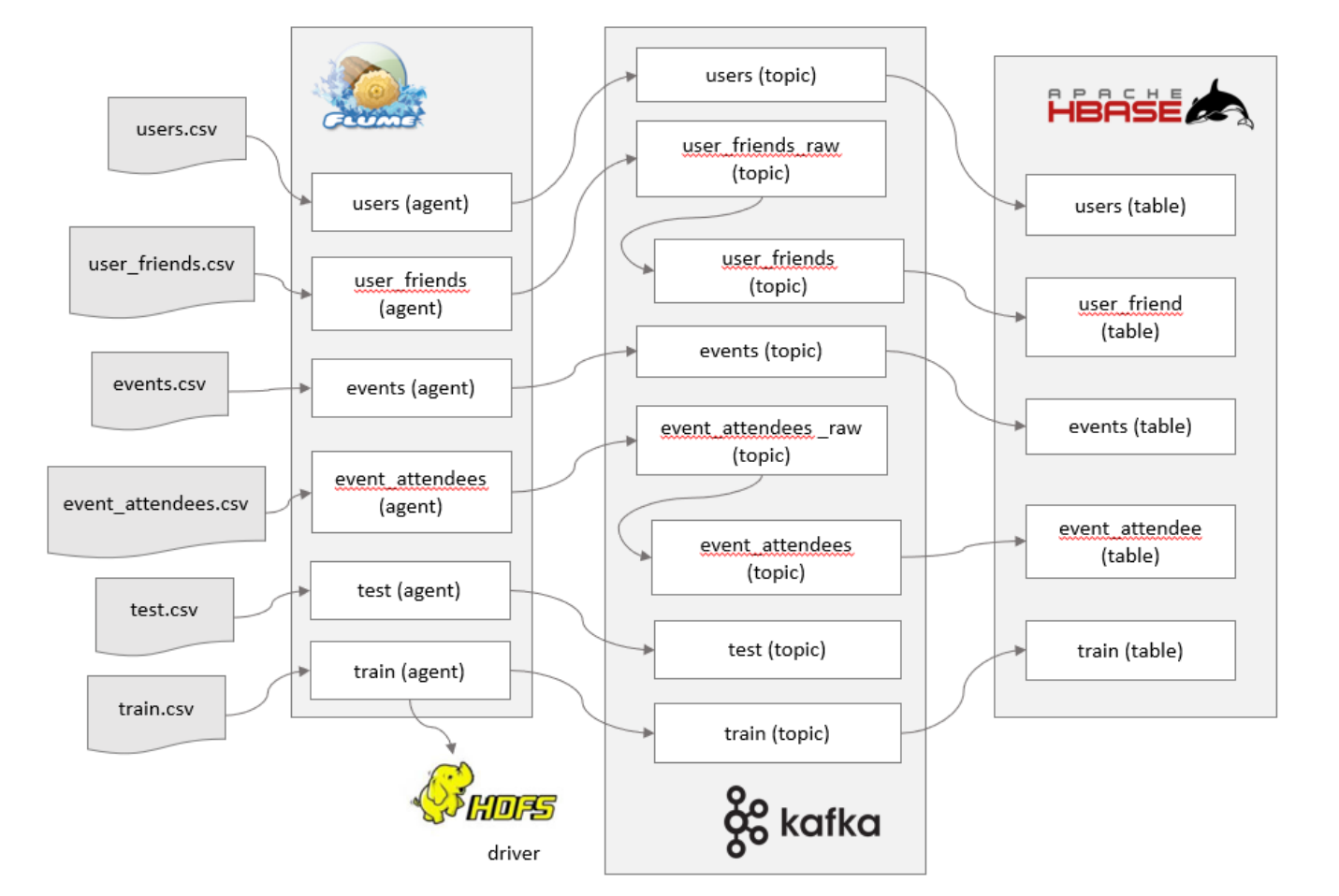
源数据为日志数据,通过flume采集后发送到Kafka,对源数据进行处理后保存至hbase。
第一步:flume拉取日志数据,并将源数据保存至Kafka
flume配置文件:
users:
users.sources=usersSource
users.channels=usersChannel
users.sinks=userSink
users.sources.usersSource.type=spooldir
users.sources.usersSource.spoolDir=/opt/flumelogfile/users
users.sources.usersSource.deserializer=LINE
users.sources.usersSource.deserializer.maxLineLength=320000
users.sources.usersSource.includePattern=user_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
users.sources.usersSource.interceptors=head_filter
users.sources.usersSource.interceptors.head_filter.type=regex_filter
users.sources.usersSource.interceptors.head_filter.regex=^user_id*
users.sources.usersSource.interceptors.head_filter.excludeEvents=true
users.channels.usersChannel.type=file
users.channels.usersChannel.checkpointDir=/opt/flumelogfile/checkpoint/users
users.channels.usersChannel.dataDirs=/opt/flumelogfile/data/users
users.sinks.userSink.type=org.apache.flume.sink.kafka.KafkaSink
users.sinks.userSink.batchSize=640
users.sinks.userSink.brokerList=192.168.136.20:9092
users.sinks.userSink.topic=users
users.sources.usersSource.channels=usersChannel
users.sinks.userSink.channel=usersChanneluser_friends_raw:
userfriends.sources=userfriendsSource
userfriends.channels=userfriendsChannel
userfriends.sinks=userfriendsSink
userfriends.sources.userfriendsSource.type=spooldir
userfriends.sources.userfriendsSource.spoolDir=/opt/flumelogfile/uf
userfriends.sources.userfriendsSource.deserializer=LINE
userfriends.sources.userfriendsSource.deserializer.maxLineLength=320000
userfriends.sources.userfriendsSource.includePattern=uf_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
userfriends.sources.userfriendsSource.interceptors=head_filter
userfriends.sources.userfriendsSource.interceptors.head_filter.type=regex_filter
userfriends.sources.userfriendsSource.interceptors.head_filter.regex=^user*
userfriends.sources.userfriendsSource.interceptors.head_filter.excludeEvents=true
userfriends.channels.userfriendsChannel.type=file
userfriends.channels.userfriendsChannel.checkpointDir=/opt/flumelogfile/checkpoint/uf
userfriends.channels.userfriendsChannel.dataDirs=/opt/flumelogfile/data/uf
userfriends.sinks.userfriendsSink.type=org.apache.flume.sink.kafka.KafkaSink
userfriends.sinks.userfriendsSink.batchSize=640
userfriends.sinks.userfriendsSink.brokerList=192.168.136.20:9092
userfriends.sinks.userfriendsSink.topic=user_friends_raw
userfriends.sources.userfriendsSource.channels=userfriendsChannel
userfriends.sinks.userfriendsSink.channel=userfriendsChannel
events:
events.sources=eventsSource
events.channels=eventsChannel
events.sinks=eventsSink
events.sources.eventsSource.type=spooldir
events.sources.eventsSource.spoolDir=/opt/flumelogfile/events
events.sources.eventsSource.deserializer=LINE
events.sources.eventsSource.deserializer.maxLineLength=320000
events.sources.eventsSource.includePattern=events_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
events.sources.eventsSource.interceptors=head_filter
events.sources.eventsSource.interceptors.head_filter.type=regex_filter
events.sources.eventsSource.interceptors.head_filter.regex=^event_id*
events.sources.eventsSource.interceptors.head_filter.excludeEvents=true
events.channels.eventsChannel.type=file
events.channels.eventsChannel.checkpointDir=/opt/flumelogfile/checkpoint/events
events.channels.eventsChannel.dataDirs=/opt/flumelogfile/data/events
events.sinks.eventsSink.type=org.apache.flume.sink.kafka.KafkaSink
events.sinks.eventsSink.batchSize=640
events.sinks.eventsSink.brokerList=192.168.136.20:9092
events.sinks.eventsSink.topic=events
events.sources.eventsSource.channels=eventsChannel
events.sinks.eventsSink.channel=eventsChannel
event_attendees_raw:
ea.sources=eaSource
ea.channels=eaChannel
ea.sinks=eaSink
ea.sources.eaSource.type=spooldir
ea.sources.eaSource.spoolDir=/opt/flumelogfile/ea
ea.sources.eaSource.deserializer=LINE
ea.sources.eaSource.deserializer.maxLineLength=320000
ea.sources.eaSource.includePattern=ea_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
ea.sources.eaSource.interceptors=head_filter
ea.sources.eaSource.interceptors.head_filter.type=regex_filter
ea.sources.eaSource.interceptors.head_filter.regex=^event*
ea.sources.eaSource.interceptors.head_filter.excludeEvents=true
ea.channels.eaChannel.type=file
ea.channels.eaChannel.checkpointDir=/opt/flumelogfile/checkpoint/ea
ea.channels.eaChannel.dataDirs=/opt/flumelogfile/data/ea
ea.sinks.eaSink.type=org.apache.flume.sink.kafka.KafkaSink
ea.sinks.eaSink.batchSize=640
ea.sinks.eaSink.brokerList=192.168.136.20:9092
ea.sinks.eaSink.topic=event_attendees_raw
ea.sources.eaSource.channels=eaChannel
ea.sinks.eaSink.channel=eaChannel
train:
train.sources=trainSource
train.channels=trainChannel
train.sinks=trainink
train.sources.trainSource.type=spooldir
train.sources.trainSource.spoolDir=/opt/flumelogfile/train
train.sources.trainSource.deserializer=LINE
train.sources.trainSource.deserializer.maxLineLength=320000
train.sources.trainSource.includePattern=train_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
train.sources.trainSource.interceptor=head_filter
train.sources.trainSource.interceptor.head_filter.type=regex_filter
train.sources.trainSource.interceptor.head_filter.regex=^user*
train.sources.trainSource.interceptor.head_filter.excludeEvents=true
train.channels.trainChannel.type=file
train.channels.trainChannel.checkpointDir=/opt/flumelogfile/checkpoint/train
train.channels.trainChannel.dataDirs=/opt/flumelogfile/data/train
train.sinks.trainink.type=org.apache.flume.sink.kafka.KafkaSink
train.sinks.trainink.batchSize=640
train.sinks.trainink.brokerList=192.168.136.20:9092
train.sinks.trainink.topic=train
train.sources.trainSource.channels=trainChannel
train.sinks.trainink.channel=trainChannel
第二步:Kafka源数据处理
user_friends和event_attendees需要对元数据进行处理,在这里我们有两种方式。一种是KafkaStream将数据消费后发送到新的topic。
方式一:KafkaStream
第一步:初始化配置
Properties properties = new Properties(); // 组id properties.put(StreamsConfig.APPLICATION_ID_CONFIG, "userfriend"); // 设备id properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.136.20:9092"); // key反序列化 properties.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); // value反序列化 properties.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());第二步:创建流构造器
StreamsBuilder builder = new StreamsBuilder();第三步:从topic中取数据,放入到新的topic中
builder.stream("event_attendees_raw").to("event_attendees"); 上面一行相当于下面两行 KStream<Object, Object> mystreamin = builder.stream("event_attendees_raw"); mystreamin.to("event_attendees");第四步:通过建造者模式,创建kafkaStreams
Topology topo = builder.build(); KafkaStreams kafkaStreams = new KafkaStreams(topo, properties);第五步:启动程序
kafkaStreams.start();
EventAttendStream
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.*;
import java.util.ArrayList;
import java.util.Properties;
public class EventAttendStream {
public static void main(String[] args) {
// 1. 初始化配置
Properties properties = new Properties();
properties.put(StreamsConfig.APPLICATION_ID_CONFIG, "userfriend");
properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.136.20:9092");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
properties.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
properties.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// 2. 创建流构造器
StreamsBuilder builder = new StreamsBuilder();
// 3. 将topic event_attendees_raw的数据取出,处理后发送到topic event_attendees
builder.stream("event_attendees_raw")
.flatMap((key,value)->{
ArrayList<KeyValue<String, String>> list = new ArrayList<>();
String[] fields = value.toString().split(",");
String event = fields[0];
if(event.trim().length()>0){
if (fields.length>=2){ //判断yes的位置是否有值
String[] yes = fields[1].split("\\s+");
for (String y : yes) {
System.out.println(event+" "+y+" yes");
KeyValue<String, String> kv = new KeyValue<>(null, event + "," + y+" yes");
list.add(kv);
}
}
if (fields.length>=3){ //判断maybe的位置是否有值
String[] maybe = fields[2].split("\\s+");
for (String my : maybe) {
System.out.println(event+" "+my+" maybe");
KeyValue<String, String> kv = new KeyValue<>(null, event + "," + my+" maybe");
list.add(kv);
}
}
if (fields.length>=4){ //判断invited的位置是否有值
String[] invited = fields[3].split("\\s+");
for (String in : invited) {
System.out.println(event+" "+in+" invited");
KeyValue<String, String> kv = new KeyValue<>(null, event + "," + in+" invited");
list.add(kv);
}
}
if (fields.length>=5){ //判断no的位置是否有值
String[] no = fields[4].split("\\s+");
for (String n : no) {
System.out.println(event+" "+n+" no");
KeyValue<String, String> kv = new KeyValue<>(null, event + "," + n+" no");
list.add(kv);
}
}
}
return list;
})
.to("event_attendees");
// 4. kafkaStream需要传递两个参数,Topology topology, Properties props
// props配置通过new Properties()实现
// Topology则通过builder.build()创建
Topology topo = builder.build();
KafkaStreams streams = new KafkaStreams(topo, properties);
// 5. 启动程序
streams.start();
}
}
UserFriendsStream
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.*;
import java.util.ArrayList;
import java.util.Properties;
public class UserFriendsStream {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(StreamsConfig.APPLICATION_ID_CONFIG,"userfriend");
properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.136.20:9092");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
properties.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
properties.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
// 主要业务逻辑处理 start
builder.stream("user_friends_raw")
.flatMap((key,value)->{
ArrayList<KeyValue<String,String>> list = new ArrayList<>();
String[] fields = value.toString().split(",");
if(fields.length==2){
String userid = fields[0];
String[] friends = fields[1].split("\\s+");
for (String friendid :
friends) {
System.out.println(userid + " " + friendid);
KeyValue kv = new KeyValue<String, String>(null, userid + "," + friendid);
list.add(kv);
}
}
return list;
})
.to("user_friends");
// 主要业务逻辑处理 end
Topology topo = builder.build();
KafkaStreams streams = new KafkaStreams(topo, properties);
streams.start();
}
}方式二:sparkStreaming
第一步:配置sparkStream
val conf = new SparkConf().setAppName("user_friends_raw").setMaster("local[*]") val streamingContext = new StreamingContext(conf,Seconds(5))第二步:kafka配置
val kafkaParams = Map( (ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.136.20:9092"), (ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"), (ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"), (ConsumerConfig.GROUP_ID_CONFIG -> "ea01"), )第三步:KafkaStream创建流
val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream( streamingContext, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe(Set("user_friends_raw"), kafkaParams) )第四步:对RDD进行处理
kafkaStream.foreachRDD( rdd=>{ rdd.foreachPartition(x=>x处理) } )第五步:创建Kafka producer并发送
val props = new util.HashMap[String,Object]() props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.136.20:9092") props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer") props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer") val producer = new KafkaProducer[String,String](props) val record = new ProducerRecord[String,String]("user_friends2",userid+","+friend) producer.send(record)第六步:启动采集器
streamingContext.start() streamingContext.awaitTermination()
EventAttendeesRaw -> EventAttendees
import java.util
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
object SparkStreamEventAttendeesrawToEventAttends {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("user_friends_raw").setMaster("local[*]")
val streamingContext = new StreamingContext(conf,Seconds(5))
streamingContext.checkpoint("checkpoint")
val kafkaParams = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.136.20:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG -> "ea01"),
(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG->"earliest")
)
val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(Set("event_attendees_raw"), kafkaParams)
)
kafkaStream.foreachRDD(rdd=>{
rdd.foreachPartition(x=>{
val props = new util.HashMap[String,Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.136.20:9092")
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String,String](props)
x.foreach(y=> { // event,yes,maybe,invited,no
val fields = y.value().split(",")
if(fields.length>=0) {
val events = fields(0)
if (fields.length >= 2) {
val yess = fields(1).split("\\s+")
for (yes <- yess) {
val record = new ProducerRecord[String, String]("event_attendees2", events + "," + yes)
producer.send(record)
}
}
if (fields.length >= 3) {
val maybes = fields(2).split("\\s+")
for (maybe <- maybes) {
val record = new ProducerRecord[String, String]("event_attendees2", events + "," + maybe)
producer.send(record)
}
}
if (fields.length >= 4) {
val inviteds = fields(3).split("\\s+")
for (invited <- inviteds) {
val record = new ProducerRecord[String, String]("event_attendees2", events + "," + invited)
producer.send(record)
}
}
if (fields.length >= 5) {
val nos = fields(4).split("\\s+")
for (no <- nos) {
val record = new ProducerRecord[String, String]("event_attendees2", events + "," + no)
producer.send(record)
}
}
}
})
})
}
)
// 启动采集器
streamingContext.start()
streamingContext.awaitTermination()
}
}UserFriendRaw -> UserFriend
import java.util
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamUserFriendrawToUserFriend {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("user_friends_raw").setMaster("local[*]")
val streamingContext = new StreamingContext(conf,Seconds(5))
streamingContext.checkpoint("checkpoint")
val kafkaParams = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.136.20:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG -> "uf"),
(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG->"earliest")
)
val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(Set("user_friends_raw"), kafkaParams)
)
kafkaStream.foreachRDD(
rdd=>{
rdd.foreachPartition(x=>{
val props = new util.HashMap[String,Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.136.20:9092")
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String,String](props)
x.foreach(y=>{
val splits = y.value().split(",")
if(splits.length==2){
val userid = splits(0)
val friends = splits(1).split("\\s+")
for(friend<-friends){
val record = new ProducerRecord[String,String]("user_friends2",userid+","+friend)
producer.send(record)
}
}
})
})
}
)
streamingContext.start()
streamingContext.awaitTermination()
}
}
第三步:Kafka topic数据发送到HBase
第一步:初始化配置
Properties properties = new Properties(); properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.136.20:9092"); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class); properties.put(ConsumerConfig.GROUP_ID_CONFIG, "event_attendee");第二步:配置Kafka消费者,消费数据
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties); consumer.subscribe(Collections.singleton("event_attendees"));第三步:配置hbase信息,连接hbase数据库
Configuration conf = HBaseConfiguration.create(); conf.set(HConstants.HBASE_DIR,"hdfs://192.168.136.20:9000/hbase"); conf.set(HConstants.ZOOKEEPER_QUORUM,"192.168.136.20"); conf.set(HConstants.CLIENT_PORT_STR,"2181"); Connection connection = ConnectionFactory.createConnection(conf); Table eventAttendTable = connection.getTable(TableName.valueOf("events_db:event_attendee"));第四步:consumer消费数据
ConsumerRecords<String, String> poll = consumer.poll(Duration.ofMillis(100));第五步:数据拉取出来之后插入到hbase中
ArrayList<Put> datas = new ArrayList<>(); for (ConsumerRecord<String, String> record : poll) { // 将Kafka中的数据按照","分隔, String[] split = record.value().split(","); // rowkey Put put = new Put(Bytes.toBytes(split[0])); // 列族 put.addColumn("eu".getBytes(), "user".getBytes(), split[0].getBytes()); // put作为一条数据,插入到datas中 datas.add(put); }
EventAttendee -> HBase
package nj.zb.kb21.kafka.kafkatohb;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HConstants;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.io.IOException;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Properties;
public class EventAttendeToHB {
static int num = 0; // 计数器
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.136.20:9092");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); // 手动提交
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000"); // 自动提交时,提交时间
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "event_attendee");
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 配置Kafka信息。消费消息
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singleton("event_attendees"));
// 配置hbase信息,连接hbase数据库
Configuration conf = HBaseConfiguration.create();
conf.set(HConstants.HBASE_DIR,"hdfs://192.168.136.20:9000/hbase");
conf.set(HConstants.ZOOKEEPER_QUORUM,"192.168.136.20");
conf.set(HConstants.CLIENT_PORT_STR,"2181");
Connection connection = null;
try {
connection = ConnectionFactory.createConnection(conf);
Table eventAttendTable = connection.getTable(TableName.valueOf("events_db:event_attendee"));
while (true) {
ConsumerRecords<String, String> poll = consumer.poll(Duration.ofMillis(100));
ArrayList<Put> datas = new ArrayList<>();
for (ConsumerRecord<String, String> record : poll) {
System.out.println(record.value()); // userid,friendid
String[] eventattend = record.value().split(",");
Put put = new Put(Bytes.toBytes(eventattend[0]+eventattend[1].split("\\s")[0]+eventattend[1].split("\\s")[1])); // rowkey
put.addColumn("euat".getBytes(), "eventid".getBytes(), Bytes.toBytes(eventattend[0]));
put.addColumn("euat".getBytes(), "friendid".getBytes(), Bytes.toBytes(eventattend[1].split("\\s")[0]));
put.addColumn("euat".getBytes(), "state".getBytes(), Bytes.toBytes(eventattend[1].split("\\s")[1]));
datas.add(put);
}
num = num + datas.size();
System.out.println("----------num:" + num);
if (datas.size() != 0)
eventAttendTable.put(datas);
Thread.sleep(10);
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Events -> HBase
package nj.zb.kb21.kafka.kafkatohb;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HConstants;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.io.IOException;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Properties;
public class EventsToHB {
static int num = 0; // 计数器
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.136.20:9092");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); // 手动提交
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000"); // 自动提交时,提交时间
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "events");
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 配置Kafka信息。消费消息
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singleton("events"));
// 配置hbase信息,连接hbase数据库
Configuration conf = HBaseConfiguration.create();
conf.set(HConstants.HBASE_DIR,"hdfs://192.168.136.20:9000/hbase");
conf.set(HConstants.ZOOKEEPER_QUORUM,"192.168.136.20");
conf.set(HConstants.CLIENT_PORT_STR,"2181");
Connection connection = null;
try {
connection = ConnectionFactory.createConnection(conf);
Table userFriendTable = connection.getTable(TableName.valueOf("events_db:events"));
while (true){
ConsumerRecords<String,String> poll = consumer.poll(Duration.ofMillis(100));
ArrayList<Put> datas = new ArrayList<>();
for (ConsumerRecord<String, String> record : poll){
System.out.println(record.value()); // userid,friendid
String[] event = record.value().split(",");
Put put = new Put(Bytes.toBytes(event[0])); // row_key
put.addColumn("creator".getBytes(),"userid".getBytes(),event[1].getBytes());
put.addColumn("schedule".getBytes(),"starttime".getBytes(),event[2].getBytes());
put.addColumn("location".getBytes(),"city".getBytes(),event[3].getBytes());
put.addColumn("location".getBytes(),"state".getBytes(),event[4].getBytes());
put.addColumn("location".getBytes(),"zip".getBytes(),event[5].getBytes());
put.addColumn("location".getBytes(),"country".getBytes(),event[6].getBytes());
put.addColumn("location".getBytes(),"lat".getBytes(),event[7].getBytes());
put.addColumn("location".getBytes(),"lng".getBytes(),event[8].getBytes());
put.addColumn("remark".getBytes(),"commonwords".getBytes(),event[9].getBytes());
datas.add(put);
}
num = num + datas.size();
System.out.println("----------num:"+num);
if (datas.size()!=0)
userFriendTable.put(datas);
Thread.sleep(10);
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Train -> HBase
package nj.zb.kb21.kafka.kafkatohb;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HConstants;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.io.IOException;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Properties;
public class TrainToHB {
static int num = 0; // 计数器
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.136.20:9092");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); // 手动提交
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000"); // 自动提交时,提交时间
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "train");
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 配置Kafka信息。消费消息
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singleton("train"));
// 配置hbase信息,连接hbase数据库
Configuration conf = HBaseConfiguration.create();
conf.set(HConstants.HBASE_DIR,"hdfs://192.168.136.20:9000/hbase");
conf.set(HConstants.ZOOKEEPER_QUORUM,"192.168.136.20");
conf.set(HConstants.CLIENT_PORT_STR,"2181");
Connection connection = null;
try {
connection = ConnectionFactory.createConnection(conf);
Table usersTable = connection.getTable(TableName.valueOf("events_db:train"));
while (true) {
ConsumerRecords<String, String> poll = consumer.poll(Duration.ofMillis(100));
ArrayList<Put> datas = new ArrayList<>();
for (ConsumerRecord<String, String> record : poll) {
System.out.println(record.value()); // userid,friendid
String[] split = record.value().split(",");
Put put = new Put(Bytes.toBytes(split[0])); // rowkey
put.addColumn("eu".getBytes(), "user".getBytes(), split[0].getBytes());
put.addColumn("eu".getBytes(), "event".getBytes(), split[1].getBytes());
put.addColumn("eu".getBytes(), "invited".getBytes(), split[2].getBytes());
put.addColumn("eu".getBytes(), "timestamp".getBytes(), split[3].getBytes());
put.addColumn("eu".getBytes(), "interested".getBytes(), split[4].getBytes());
put.addColumn("eu".getBytes(), "not_interested".getBytes(), split[5].getBytes());
datas.add(put);
}
num = num + datas.size();
System.out.println("----------num:" + num);
if (datas.size() != 0)
usersTable.put(datas);
Thread.sleep(10);
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
UserFriends -> HBase
package nj.zb.kb21.kafka.kafkatohb;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HConstants;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.protocol.types.Field;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.io.IOException;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Properties;
public class UserFriendsToHB {
static int num = 0; // 计数器
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.136.20:9092");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); // 手动提交
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000"); // 自动提交时,提交时间
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "userfriend_group");
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 配置Kafka信息。消费消息
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singleton("user_friends"));
// 配置hbase信息,连接hbase数据库
Configuration conf = HBaseConfiguration.create();
conf.set(HConstants.HBASE_DIR,"hdfs://192.168.136.20:9000/hbase");
conf.set(HConstants.ZOOKEEPER_QUORUM,"192.168.136.20");
conf.set(HConstants.CLIENT_PORT_STR,"2181");
Connection connection = null;
try {
connection = ConnectionFactory.createConnection(conf);
Table userFriendTable = connection.getTable(TableName.valueOf("events_db:user_friend"));
while (true){
ConsumerRecords<String,String> poll = consumer.poll(Duration.ofMillis(100));
ArrayList<Put> datas = new ArrayList<>();
for (ConsumerRecord<String, String> record : poll){
System.out.println(record.value()); // userid,friendid
String[] split = record.value().split(",");
Put put = new Put(Bytes.toBytes((split[0]+split[1]).hashCode())); // rowkey
put.addColumn("uf".getBytes(),"userid".getBytes(),split[0].getBytes());
put.addColumn("uf".getBytes(),"friendid".getBytes(),split[1].getBytes());
datas.add(put);
}
num = num + datas.size();
System.out.println("----------num:"+num);
if (datas.size()!=0)
userFriendTable.put(datas);
Thread.sleep(10);
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Users -> HBase
package nj.zb.kb21.kafka.kafkatohb;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HConstants;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.io.IOException;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Properties;
public class UsersToHB {
static int num = 0; // 计数器
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.136.20:9092");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); // 手动提交
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000"); // 自动提交时,提交时间
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "users");
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 配置Kafka信息。消费消息
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singleton("users"));
// 配置hbase信息,连接hbase数据库
Configuration conf = HBaseConfiguration.create();
conf.set(HConstants.HBASE_DIR,"hdfs://192.168.136.20:9000/hbase");
conf.set(HConstants.ZOOKEEPER_QUORUM,"192.168.136.20");
conf.set(HConstants.CLIENT_PORT_STR,"2181");
Connection connection = null;
try {
connection = ConnectionFactory.createConnection(conf);
Table usersTable = connection.getTable(TableName.valueOf("events_db:users"));
while (true) {
ConsumerRecords<String, String> poll = consumer.poll(Duration.ofMillis(100));
ArrayList<Put> datas = new ArrayList<>();
for (ConsumerRecord<String, String> record : poll) {
System.out.println(record.value()); // userid,friendid
String[] user = record.value().split(",");
Put put = new Put(Bytes.toBytes(user[0])); // rowkey
put.addColumn("profile".getBytes(), "birthyear".getBytes(), user[2].getBytes());
put.addColumn("profile".getBytes(), "gender".getBytes(), user[3].getBytes());
put.addColumn("region".getBytes(), "locale".getBytes(), user[1].getBytes());
if (user.length > 5)
put.addColumn("region".getBytes(), "location".getBytes(), user[5].getBytes());
if (user.length > 6)
put.addColumn("region".getBytes(), "timezone".getBytes(), user[6].getBytes());
if (user.length > 4)
put.addColumn("registration".getBytes(), "joinAt".getBytes(), user[4].getBytes());
datas.add(put);
}
num = num + datas.size();
System.out.println("----------num:" + num);
if (datas.size() != 0)
usersTable.put(datas);
Thread.sleep(10);
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}