前言
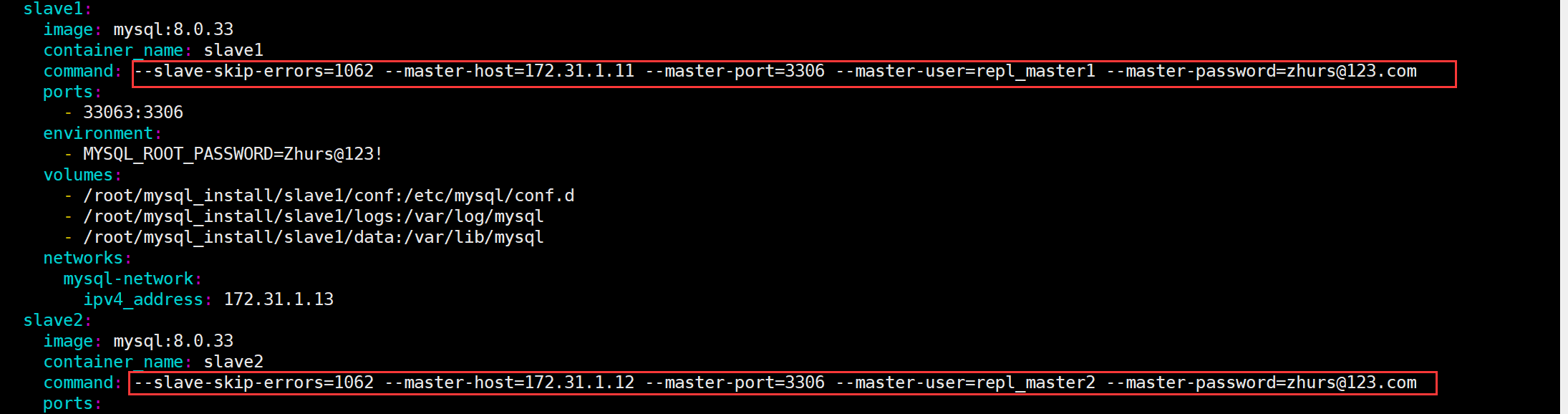
旁边的实习生一脸困惑:我把一个dataset的数据往某个文件夹或hive表中写的时候可以用partitionBy对数据进行分区,可是repartition顾名思义也好像与分区有关,这两个究竟有啥区别?我该如何使用?
API解释
- repartition
repartition是dataframe的一个方法,用来增加或减少内存中的分区;当需要将dataframe写入磁盘的时候,它会将所有part files文件写入指定的一个目录中。 - partitionBy
partitionBy是DataFrameWriter类的一个方法,用于将DataFrame写入磁盘中的分区目录里,分区列中每个唯一值对应一个分区子目录。

详细案例讲解
测试数据:
country
China
China
China
America
America
England
England
Japan
Japan
Japan
Korea
Korea
- repartition 案例详解
- repartition(numPartitions : scala.Int) 直接传入分区数量
package sparkdemo;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class RepPar {
public static void main(String[] args) {
Logger.getLogger("org").setLevel(Level.ERROR);
SparkSession spark = SparkSession
.builder()
.appName("appName")
.master("local[5]")
.enableHiveSupport()
.getOrCreate();
Dataset<Row> ds = spark.read().option("header", "true").csv("./data/country.csv");
Dataset<Row> repartition = ds.repartition(3);
System.out.println(repartition.rdd().getNumPartitions());
repartition.write().option("header","true").mode("overwrite").csv("./data/country1");
spark.stop();
}
}
案例中使用reparation将数据进行重分区,分区数量设置为3,这意味会把原始文件分为三个分区文件。当将该dataframe写入指定的./data/country1目录时,就会发现该目录下会生成三个分区文件:

而且分区文件中的内容是随机的:

注意:当要减少分区的时候,推荐使用coalesce算子,因为可以避免shuffle。
- repartition(numPartitions : scala.Int, partitionExprs : Column*) 传入分区数量以及指定要分区的列
该方法会把每个国家的数据放入相同的分区文件中。注意:不保证每个分区文件中仅包含一个国家。
package sparkdemo;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.spark.sql.Column;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class RepPar {
public static void main(String[] args) {
Logger.getLogger("org").setLevel(Level.ERROR);
SparkSession spark = SparkSession
.builder()
.appName("appName")
.master("local[5]")
.enableHiveSupport()
.getOrCreate();
Dataset<Row> ds = spark.read().option("header", "true").csv("./data/country.csv");
Dataset<Row> rCol = ds.repartition(3, new Column("country"));
rCol.write().option("header", "true").mode("overwrite").csv("./data/country2");
spark.stop();
}
}
该操作会对country这一列的数据对3进行取模,最终形成3个分区文件(partition = hash(country) % 3)。这保证了相同的country所有数据都最终都存在同一个分区中。


注意:可能会存在某个分区文件中数据多,某些少的情况。
- partitionBy详细案例
测试数据为了尽可能的简单明了,因此只用了一列country列,但是使用partitionBy的时候是不能对所有列进行操作(这里的由于仅有一列,也就不能对该列进行partitionBy操作),因此增加了一列code。
code,country
1,China
1,China
1,China
2,America
2,America
3,England
3,England
4,Japan
4,Japan
4,Japan
5,Korea
5,Korea
代码:
package sparkdemo;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.spark.sql.Column;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class RepPar {
public static void main(String[] args) {
Logger.getLogger("org").setLevel(Level.ERROR);
SparkSession spark = SparkSession
.builder()
.appName("appName")
.master("local[5]")
.enableHiveSupport()
.getOrCreate();
Dataset<Row> ds = spark.read().option("header", "true").csv("./data/country.csv");
ds.write().option("header", "true").partitionBy("country")
.mode("overwrite").csv("./data/country3");
spark.stop();
}
}
我们共有五个国家,对country进行partitionBy将创建五个子目录,子目录的名称是分区列=值。在磁盘上形成分区目录可以加速对分区进行筛选的效率。

注意:写入磁盘文件中并不包含分区列,因此可以节省一些存储空间。
- repartition和partitionBy结合使用
使用repartition可以在内存中创建指定数量的分区,再用partitionBy将指定的分区列,将数据写入repartition设定数据量的分区文件中。这样的好处是,可以减少小文件的数量。
package sparkdemo;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class RepPar {
public static void main(String[] args) {
Logger.getLogger("org").setLevel(Level.ERROR);
SparkSession spark = SparkSession
.builder()
.appName("appName")
.master("local[5]")
.enableHiveSupport()
.getOrCreate();
Dataset<Row> ds = spark.read().option("header", "true").csv("./data/country.csv");
ds.repartition(2).write().option("header", "true").partitionBy("country")
.mode("overwrite").csv("./data/country4");
spark.stop();
}
}
通过上面的操作,我们的数据集中有5个唯一的country,我们为每个country要求2个内存分区(通过repartition算子),因此可以看到每个country会只生成两个分区文件,总共最多(如果某个country只有1条数据那么只会生成1个小文件)创建5*2=10个磁盘小文件。

注意:如果设计不正确,这可能会造成数据倾斜。比如某个国家数据很多,某个很少,即某个分区文件中数据量巨大,某些分区文件中可能只有几条数据,这可能会造成严重的数据倾斜。
后记
根据上面的详细案例,相信很容易理解repartition和partitionBy的使用场景了。repartition是在内存中划分好分区文件的数量,partitionBy是在磁盘上根据分区列唯一值生成对应的分区子目录。