目录
文章目录
- 目录
- OVS-DPDK
- OvS-DPDK v.s. SR-IOV
- 东西向流量
- 南北向流量 / 跨服务器东西流量
- OVS Hardware Offload
- OVS-DPDK Hardware Offload
- DPDK Hardware offload
- OvS-DPDK Hardware offload
- OvS-DPDK Hardware offload with vDPA
OVS-DPDK
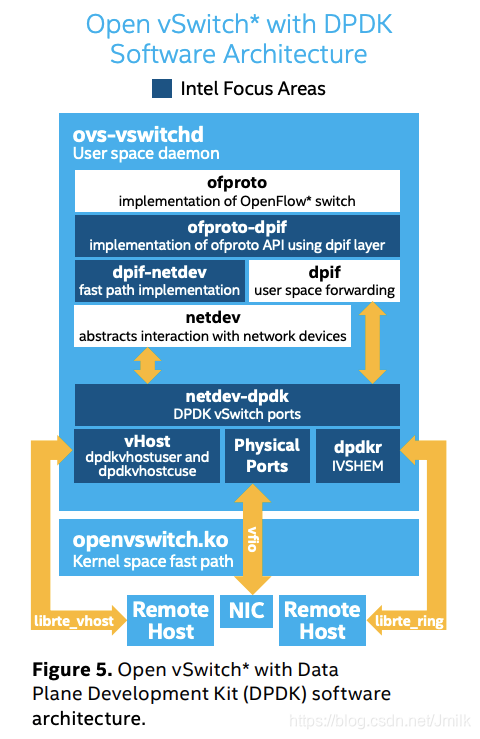
上图中的深色模块就是引入 DPDK 的相关模块。
-
ofproto-dpif:实现了 ofproto 模块 API,直接操作 dpif 层。
-
dpif-netdev:用户空间中 “快速路径” 的实现,它实现了 dpif 模块 API,可以直接操作 netdev 设备,能够实现数据包在用户空间的快速处理,减少和内核空间的切换开销。
-
netdev-dpdk:应用 DPDK 库实现了 netdev 模块 API,提供了多种类型的接口,如下:
- Physical ports(PMD):使用 vfio 或者 igb_uio 实现的端口。
- vHost(dpdkvhostuser and dpdkvhostcuse):使用 librte_vhost 库实现的端口,用户可以基于这两种端口类型创建 vhost-user 和 vhost-cuse 端口来完成用户空间的数据转发,并且能够实现和 VM 的快速通信,只要提供 virtio 后端驱动 vhost 即可,virtio/vhost 被证实是用于 VM 通信的一套快速、安全、标准的接口。
- dpdkr:使用 librte_ring 实现,用户可以基于这种端口类型创建 dpdk-ring 端口来完成用户空间的数据转发,它能够实现和 VM 之间快速的零拷贝通信(使用 IVSHMEM 或者其他进程间通信方式)。
OvS-DPDK 通过将 VirtIO 的 Backend 实现在 Userspace,实现了 VM 与 OVS-DPDK 共享 Userspace 内存,这样 VM 在收发报文时,只需要 OvS-DPDK 将从网卡收到的报文数据写入 VM 的内存,或从 VM 内存将要发送的报文拷贝到网卡 DMA 的内存,由于减少了内存拷贝次数和 CPU 调度干扰,提升了转发通道的整体效率和吞吐量。
OvS-DPDK 相对转发能力有所提高,但也存在新的问题。
- 首先,目前大多数服务器都是 NUMA 结构,在跨 NUMA 转发时性能要比同 NUMA 转发弱。而物理网卡只能插在一个 PCIe 插槽上,这个插槽只会与一个 NUMA 存在亲和性,所以 OvS-DPDK 上跨 NUMA 转发的流量不可避免。
- 第二,在 VM 与 OvS-DPDK 共享内存时,初始化的队列数量通常是与 VM 的 CPU 个数相同,才能保证 VM 上每一个 CPU 都可以通过共享内存收发数包,这样导致不同规格的 VM 在 OvS-DPDK 上收发队列所接入的 CPU 是非对称的,在转发过程中需要跨 CPU 转发数据。最后,OvS-DPDK 在转发数据时,不同 VM 的流量由于 CPU 瓶颈导致拥塞,会随机丢包,无法保障租户带宽隔离。
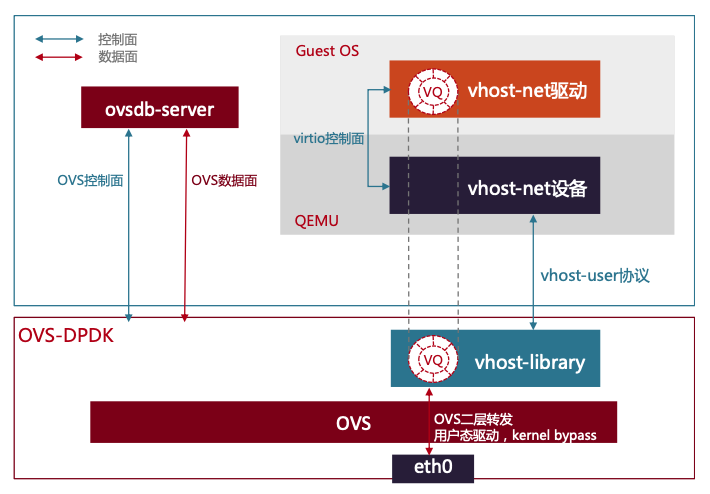
OvS-DPDK v.s. SR-IOV
东西向流量
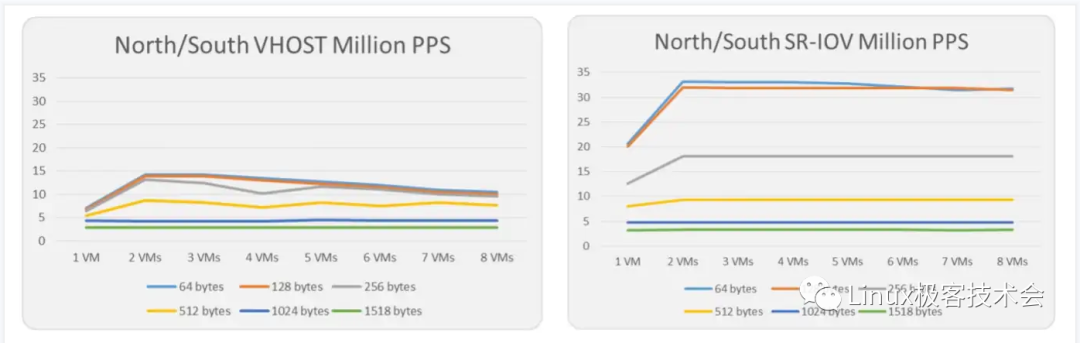
东西向流量,DPDK 性能优于 SR-IOV。
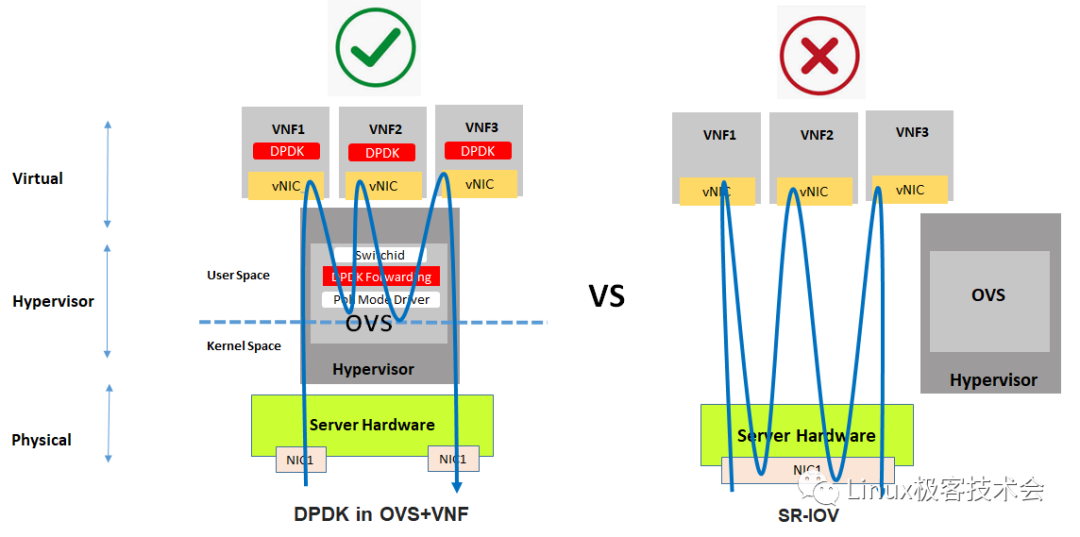
SR-IOV 成为了一个瓶颈,流量路径会变长,网卡资源会被占用。Intel 官方给出东西向流量场景下 DPDK 与 SR-IOV 的性能测试数据。
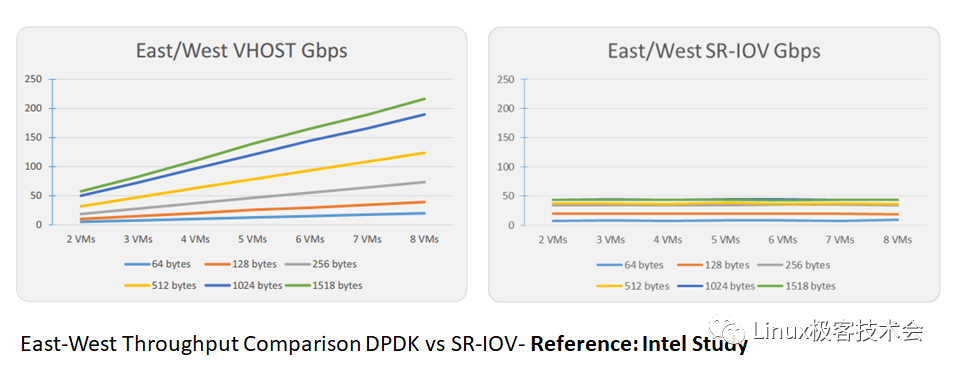
南北向流量 / 跨服务器东西流量
南北流量,也包括跨服务器东西流量场景中,SR-IOV 性能要优于 DPDK。
OVS Hardware Offload
2018 年,Open vSwitch 发布了基于 TC Flower 的 Hardware offload 功能,支持将 Datapath 卸载到 SmartNIC 上。
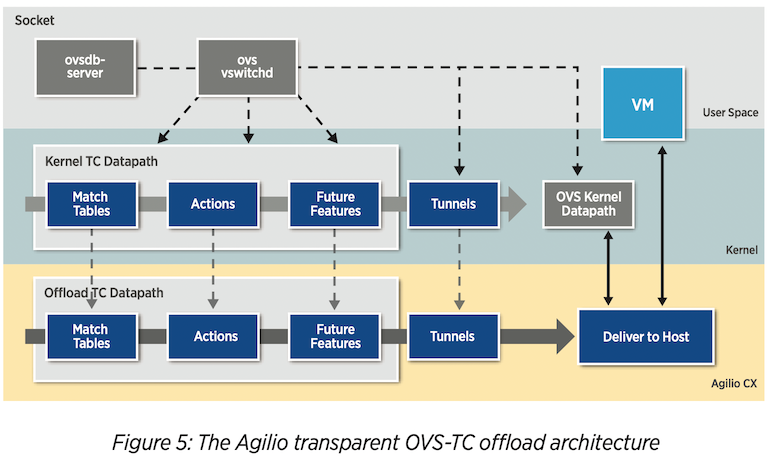
OvS Hardware offload 架构如下,存在 3 个 Datapath。
- OvS Kernel Datapath:内核级的 Fast datapath。
- OvS Kernel TC Datapath:作为 SmartNIC TC Datapath 在内核中的挂载点。
- SmartNIC TC Datapath:硬件级的 Fast datapath。
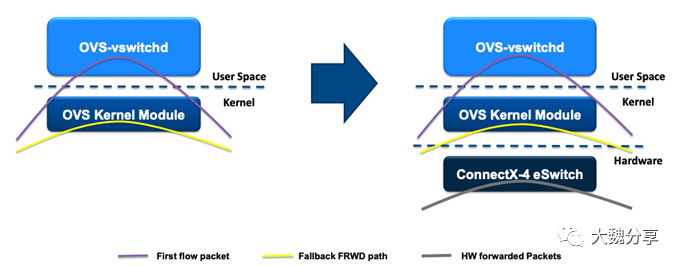
以 Mellanox 为例,在 Mellanox Physical Network Interface 中存在一个 Virtual Switch 成为 eSwitch。如果 Mellanox 开启了 Hardware Offload Flag NETIF_F_HW_TC,那么 OvS 在初始化时就会通过 TC Flower 向 eSwitch 下发一条 Default Rule,包含了 Match Entry 和 Action。而 Default Rule 的 Match Entry 就是所有匹配不上 other rules 的所有数据流,Action 就是将数据报文发送至 OvS Kernel Datapath。
如果该报文是 First Package 的话,那么 OvS Kernel Datapath 还会再发送至 ovs-vswitchd 进行转发以及 On-demand 的 OpenFlow Rule install to Datapath。在 Install OpenFlow Rule to Datapath 时,ovs-vswitch 还会根据 Hardware Offload Flag 来判断是安装到 OvS Kernel Datapath,还是安装到 SmartNIC TC Datapath。如果是后者的话,那么 ovs-vswitchd 会调用 TC Flower 接口将 Rule 下发到 SmartNIC。
此后,后续的数据流都可以直接在 SmartNIC 上进行转发,直到这条 Rule 老化(Aging)为止。
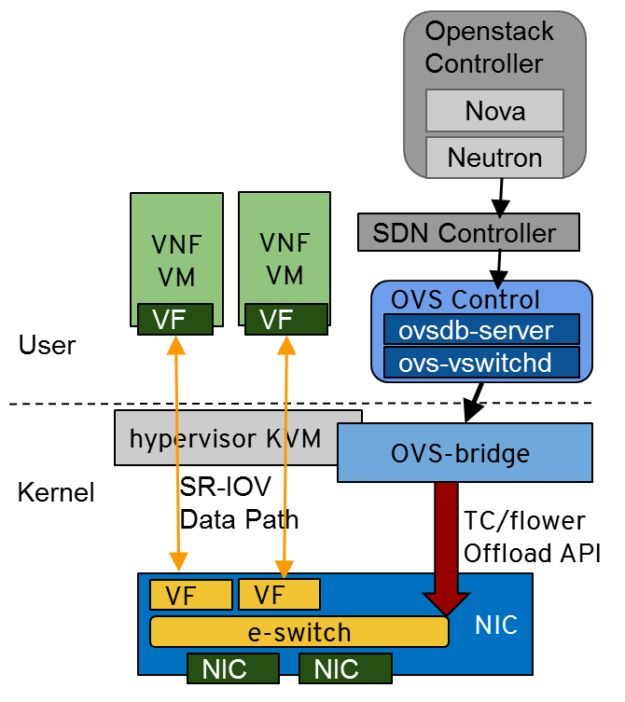
- OvS Hardware offload to NVIDIA ConnectX SmartNIC
OVS-DPDK Hardware Offload
DPDK Hardware offload
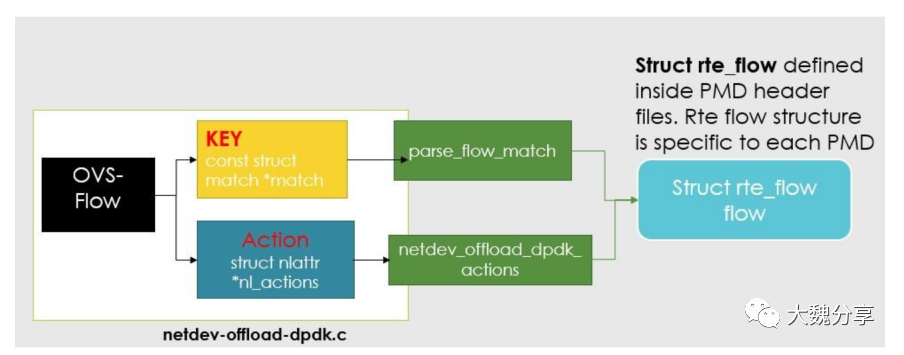
DPDK Hardware offload 功能基于 DPDK 的 rte_flow Lib 来实现。
rte_flow Lib 是 DPDK 提供的通用流编程接口,是 DPDK 对 Flow Representation 的实现,rte_flow API & structure 用于将 pkt forwarding rule 编程到(Program)NIC-hardware。例如将 OvS-DPDK Rule 卸载到 SmartNIC 上。
一条 RTE_FLOW 由以下 3 个部分组成:
- Attributes:是流本身的属性,包括:port、ingress/egress、group、priority、transfer(将流卸载到硬件)。
- Match:流的匹配模式。
- Action:匹配成功以后执行的动作。
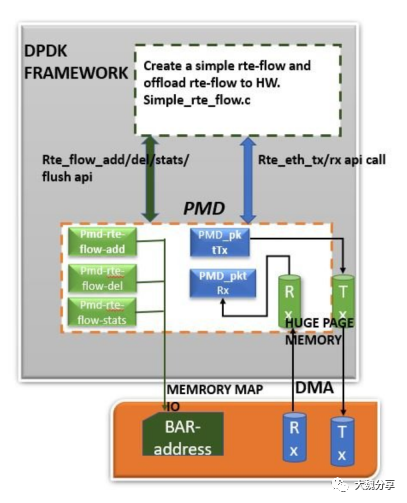
This dpdk-way of flow- representation is called rte-flow. An open-flow rule when converted into dpdk-defined flow-format, then this flow-data-structure is called rte-flow. Once a rte-flow is formed it can be passed to any PMD to be processed and Programmed into the hardware.
OvS-DPDK Hardware offload
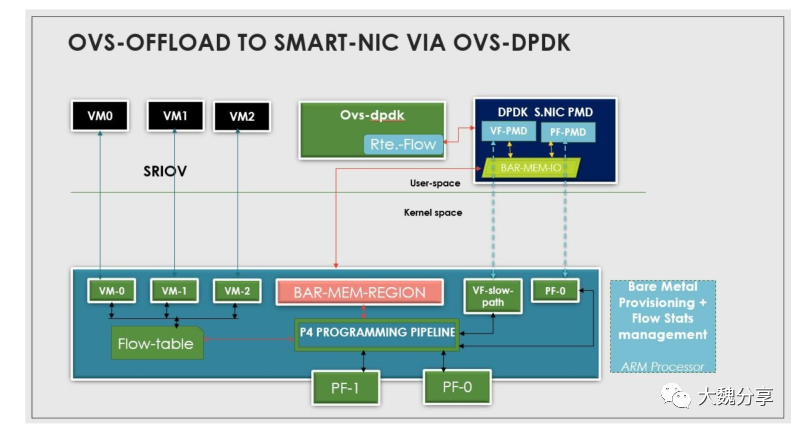
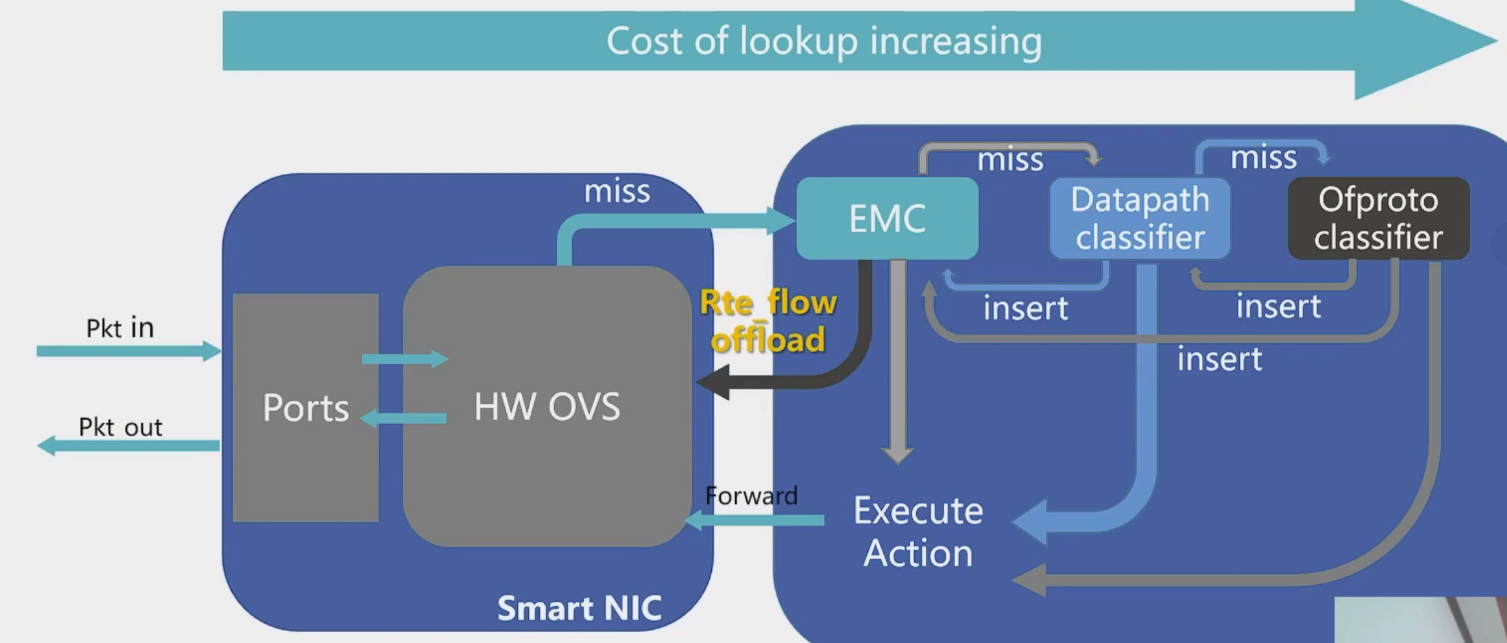
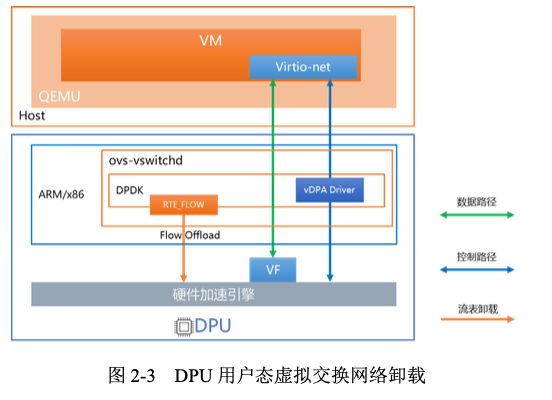
OvS-DPDK Hardware offload with vDPA
vSwitch 的 Control Plane 部署在 DPU 的 CPU 核上,Data Plane 卸载到 DPU 上的硬件加速引擎处理。CP 和 DP 之间通过 DPDK 标准 rte_flow 方式进行交互,实现 vSwitch Full offload。
vSwitch 的 DP 卸载后,还可以把 VirtIO Networking Backend 一同卸载。通过 Hardware vDPA 框架实现的 virtio-net 后端传递给虚拟机或裸金属内部的标准 virtio-net 前端,数据的传递无需 CPU 的干预,实现更高的网络转发性能。