导语
对于多个同一类型的数据进行存放和处理时,相信很多人想到的第一个方法就是使用数组,但是数组的使用有非常多的局限性,比如长度不够啦,增删操作需要移动多个元素啦。
对于此种问题,采用集合才是最好的解决办法,由于java语言对数据结构进行了封装,我们只需要在java已有的集合框架中选择对我们问题最合适的类,就可以完成创建和操作数据结构的任务,在应用的过程中,我们并不需要考虑数据结构和算法的实现细节,而所抽象出来的数据结构和操作统称为java集合框架。
集合框架的引入所带来的优势:
1:集合框架强调了软件的复用。集合框架通过提供有用的数据结构和算法,能够使程序员将重心放在程序更为重要的部分。
2:简化编程,提高效率,集合框架通过提供有用的数据结构(动态数组,链接表,树等)和算法的高性能,高质量的实现使程序的运行速度和质量得到显著提高。
3:集合框架允许不同类型的数据以相同的方式和高度互操作方式工作。
4:集合框架允许扩展或修改。
java集合的构成部分:
java集合的主要由三个部分构成:接口,实现方式,算法。
接口作为一种特定类型的集合提供行为,不同接口描述一组不同的数据类型。
集合框架中的主要接口有Collection,List,Set,Map,每个接口都有若干个实现类。
集合框架图:

单列存储即为:用于存储一系列符合某种规则的元素,元素是孤立存在的
双列存储:元素是成对存在的,每个元素由键与值两部分组成,通过键可以找到所对应的值。
注意:Map中的集合不能包含重复的键,值可以重复;每个键只能对应一个值
Collection接口:
Collection接口是最基本的集合接口,该接口不会被直接扩展,List和Set接口都对Collection进行了扩展,提供了更加具体的实现,Collection接口提供了对集合的最通用定义,主要用于传送对象集合,并对它们进行基本的操作[添加,删除,以及迭代],Collection能够得到集合中元素的个数,不管为空还是包含有特定的对象。

List接口与实现类:
List是Collection接口的子接口,它是一种包含有序元素的线性表,其中的元素在List集合的存放是顺序存放的,不仅允许一个元素重复存放,而且还允许存放null元素。
既然都是接口,如果我们想要使用其中的方法,那么就需要通过它的实现类去调用,List接口常用的实现类有ArrayList和LinkedList,对于这两种实现类,它们不仅能够实现List接口中的方法,也可以实现Collection中的方法,因为Collection是Set和List的"父亲".
List作为Collection的“儿子”,不仅继承了Collection定义的方法之外,还新增了一些方法,主要扩充方法,如下所示:

ArrayList集合:
ArrayList集合具有以下特点:
1:ArrayList实现了List接口。
2:ArrayList允许任何对象类型的数据作为它的元素。
3:ArrayList允许null作为它的元素。
**4:ArrayList不是线程安全的,不适合用于多线程环境中。**
ArrayList有3个重载的构造方法:
ArrayList():构造一个空的ArrayList对象,同时为其分配一个默认大小的容量。
ArrayList(Collection c):构造一个和参数c中具有相同元素的ArrayList对象。
ArrayList(int initialCapacity):构造一个空的ArrayList对象,同时为其分配大小为initialCapacity的容量。
ArrayList常用的方法如下:
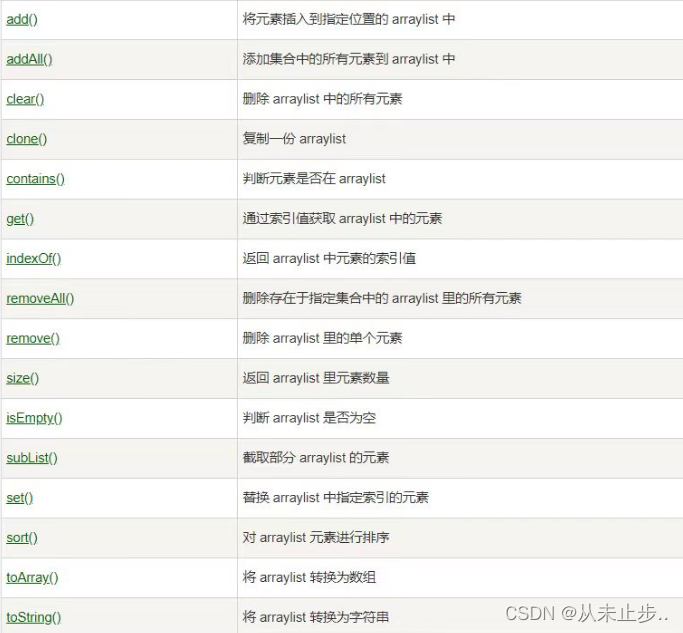
ArrayList集合方法的简单使用:
import java.util.*;
public class List_example {
public static void main(String[]args) {
List numbers=new ArrayList<>();
numbers.add("王俊凯");
numbers.add("王源");
numbers.add("易烊千玺");
System.out.println(((ArrayList<?>) numbers).clone());//复制列表
System.out.println(numbers.contains("张三"));//判断该对象是否在列表中
System.out.println(numbers.get(1));//获得列表索引为1的元素
numbers.clear();//删除所有元素
System.out.println(numbers.size());//计算列表的长度
}
}
输出:
[王俊凯, 王源, 易烊千玺]
false
王源
0
LinkedList集合:
LinkedList集合的特点:ArrayList的所具备的特点,它都具备,除此之外,它还具备自身特有的两个个特点:
1:LinkedList中添加了针对初始化元素和结束元素的get和set操作。
2:LinkedList通常可以当做队列,双端队列和堆栈等数据结构使用
LinkedList具有如下两个构造方法:
LinkedList():构造一个空的LinkedList对象
LinkedList(Collection c):构造一个包含与c相同的元素的LinkedList对象
LinkedList新增的方法:
public void addFirst(E e) 将指定元素插入到此列表的开头
public void addLast(E e) 将指定元素添加到此列表的结尾
public E getFirst() 返回次列表的第一个元素
public E getLast() 返回次列表的最后一个元素
public E removeFirst() 移除并返回此列表的第一个元素
public E removeLast() 移除并返回此列表的最后一个元素
public E pop() 从次列表所表示的堆栈处弹处一个元素
public void push(E e) 将元素推入此列表所表示的堆栈
LinkedList作为栈和队列的简单使用:
import java.util.*;
public class Warehouse1 {
public static void main(String[]args) {
LinkedList<Integer> statck=new LinkedList<>();
LinkedList<Integer> sqlist=new LinkedList<>();
for(int i=0;i<=5;i++){//将LinkedList看作栈
statck.addFirst(i);
}
System.out.println("集合中的元素为:"+statck);
for(int i=0;i<=5;i++){//将LinkedList看作队列
sqlist.addLast(i);
}
System.out.println("集合中的元素为:"+sqlist);
}
}
输出:
集合中的元素为:[5, 4, 3, 2, 1, 0]
集合中的元素为:[0, 1, 2, 3, 4, 5]
ArrayList和LinkedList都是List接口的实现类,两者之间的区别主要有以下几点:
1:ArrayList是以数组方式实现的List集合,LinkedList是以链表方式实现的List集合。
在ArrayList的中间插入或者删除一个元素意味着这个列表中剩余的元素都会被移动,而在LinkedList的中间插入或者删除一个元素的开销是固定的,二者的关系和我们在数据结构中所学的“顺序表”和“链表”很相似。
2:ArrayList支持高效地按索引访问元素,LinkedList不支持高效地按索引访问元素。
3:ArrayList的空间浪费主要体现在列表的结尾预留了一定的容量空间,而LinkedList的空间浪费则体现在它的每个元素都需要消耗相当的空间。
4:如果操作经常是在一列数据的而不是在前面或中间,并且需要随机地访问其中的元素时,使用ArrayList会得到比较好的性能,当操作经常是在一列数据的前面或中间添加或删除数据,并且按照顺序访问其中的元素时,使用LinkedList会得到比较好的性能。
Vector集合:
1:Vector实现了List接口
2:Vector的大小可以在元素进行添加和删除时,根据需要自动进行扩充和缩减
3:Vector是线程安全的,可使用在多线程环境中
Vector有以下四个构造方法:
Vector();创建一个元素个数为0的Vector对象,并为其分配默认大小的初始容量。
Vector(int size);创建一个元素个数为0的Vector对象,并为其分配默认大小的初始容量。
Vector(int initialcapacity,int capacityIncrement);创建一个元素个数为0的Vector对象,为其分配大小为initialcapacity的初始容量,并指定当Vector中的元素个数达到初始容量时,Vector会自动增加capacityIncrement的容量
Vector(Collection c);创建一个包含了集合c中元素的Vector对象
Vector新增的方法:
addElement(Object obj) 把指定的元素加到向量尾部,向量容量比以前大1
insertElementAt(Object obj, int index) 把指定对象作为此向量中的元素插入到指定的index处,此后的内容向后移动1 个单位
setElementAt(Object obj, int index) 把指定对象加到所定索引处,把原来的值改为当前的值
removeElement(Object obj) 从向量中移除变量的第一个(索引最小的)匹配项
removeAllElements() 把向量中所有元素移走,向量大小为0
toArray();返回一个数组,包含次此向量中以恰当顺序存放的所有元素
举例:
import java.util.*;
public class Warehouse1 {
public static void main(String[]args) {
Vector<String> vector=new Vector<>();
vector.addElement("王俊凯");
vector.addElement("王源");
vector.addElement("易烊千玺");
vector.insertElementAt("杨迪",2);
System.out.println("当前集合中元素有:"+vector);
vector.setElementAt("蔡徐坤",2);
vector.removeElement("王俊凯");
System.out.println("当前集合中元素有:"+vector);
}
}
输出:
当前集合中元素有:[王俊凯, 王源, 杨迪, 易烊千玺]
当前集合中元素有:[王源, 蔡徐坤, 易烊千玺]
stack:
stack继承Vector类,其本质是“先进后出”的数据结构----栈,我们早就在数据结构中学习过栈的特点是:先进入栈的元素后出栈,后入栈的元素先出栈。
stack类提供了一些新增的方法:
boolean empty(); 判断栈是否为空
E peek(); 返回但不移除栈顶部的元素
E pop(); 返回并移除栈顶部的元素
E push(E item); 对元素执行压栈操作
int search(Object o);返回对象在栈中的位置,以1为基数
举例:
import java.util.*;
public class Warehouse1 {
public static void main(String[]args) {
Stack stack=new Stack();
System.out.println(stack.empty());
stack.add("张三");
stack.add("李四");
stack.add("王五");
System.out.println(stack.search("张三"));
System.out.println("栈中元素有:"+stack);
}
}
输出:
true
3
栈中元素有:[张三, 李四, 王五]
Set接口与实现类:
Set接口是Collection的子接口,存放到Set接口的集合中的元素是没有顺序的,且不允许有重复的元素,也不能有null元素,其元素添加后采用自己内部的一个排列机制存放,即集合中元素的存放顺序可能与添加时的顺序不一致。
如果两个Set对象含有完全相同的元素,无论这些元素在集合中的位置如何,这两个对象都被认为是相等的,它常见的实现类是HashSet和TreeSet
set接口中常用的方法:
由于Set接口没有引入新的方法或者常量,可以说Set就是一个Collection,只是行为不同,但是它规定Set集合的实例中不能包含相同的元素。
HashSet集合:
HashSet集合有如下特点:
1:HashSet实现了Set接口
2:任何对象类型的数据作为它的元素
3:HashSet是为优化查询速度而设计的Set
4:存放到HashSet集合中的元素需要重写equals()方法和HashCode()方法
HashSet有以下常用的构造方法:
HashSet():构造一个空的HashSet
HashSet(Collection c):构造一个和给定的Collection中具有相同元素的HashSet对象
HashSet(int capacity):构造一个给定初始容量capacity的HashSet对象
HashSet(int capacity,float fillRatio):构造一个给定初始容量capacity和填充比fillRatio的HashSet对象
package Hashset;
public class student {
private int age ;
private String name;
public student(String name,int age) {
this.age=age;
this.name=name;
}
public String toString() {
return "student [age=" + age + ", name=" + name + "]";
}
public void setage(int age) {
this.age=age;
}
public int getage() {
return age;
}
public void stename(String name) {
this.name=name;
}
public String getname() {
return name;
}
@Override
public int hashCode() {
return super.hashCode();
}
@Override
public boolean equals(Object obj) {
return super.equals(obj);
}
}
重写tostring/hashcode/equlas方法:
举例:
package Hashset;
import Hashset.student;
import java.util.HashSet;
import java.util.Iterator;
public class text {
public static void main(String[] args) {
HashSet<student> set=new HashSet<student>();
set.add(new student("yueshuai",22));
set.add(new student("yueshuai",22));
set.add(new student("xiaoma",22));
set.add(new student("xiaozhou",23));
set.add(new student("yueshuai",22));
set.add(new student("yueshuai",22));
Iterator<student> k=set.iterator();//迭代器
while(k.hasNext()) {
student f=k.next();
System.out.println(f);
}
}
}
package Hashset;
import java.util.HashSet;
import java.util.Iterator;
public class Hashdemo {
public static void main(String[] args) {
//创建HashSet对象
HashSet<String> hs = new HashSet<String>();
//给集合中添加自定义对象
hs.add("zhangsan");
hs.add("lisi");
hs.add("wangwu");
hs.add("zhangsan");
//取出集合中的每个元素
Iterator<String> it = hs.iterator();
while(it.hasNext()){
String s = it.next();
System.out.println(s);
}
}
}
输出:
student [age=22, name=xiaoma]
student [age=23, name=xiaozhou]
student [age=22, name=yueshuai]
student [age=22, name=yueshuai]
student [age=22, name=yueshuai]
student [age=22, name=yueshuai]
通过输出结果,我们发现,重复的数据都被放入了集合中,这显然与集合元素不重复的特点相违背,那么出现这种现象的原因即为:在上述代码中,向collection接口的实现类的对象中添加数据obj时,我们采用的是系统默认的object类的equals()方法,而该方法在进行比较时,实际上是使用“==”进行比较,比较的内容为对象引用的地址,而不是内容,所以才会导致多个相同值的对象被加入集合中。
因此,在使用自定义类时,我们必须对equals进行重写!
将equals重写如下所示:
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
student other = (student) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
重写equals的同时,也必须要重写hashcode,不清楚原因的,请移步之前的文章object类,有详细解说
将hashcode重写如下所示:
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
具体计算方法移步可参考这篇文章!
当我们想通过tostring去输出表示对象值的字符串时,直接继承object的tostring方法:
@Override
public String toString() {
return super.toString();
}
输出:
Hashset.student@d2bafb1e
Hashset.student@fd6ab7d
Hashset.student@f986602a
结果并非是我们所期待的那样,它并没有返回表示对象的字符串,而返回的是类名@散列码,如果想要输出我们所希望的表示对象值的字符串,那么就需要重写tostring方法!
重写tostring方法如下所示:
@Override
public String toString() {
return "student{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
输出:
student{age=22, name='xiaoma'}
student{age=23, name='xiaozhou'}
student{age=22, name='yueshuai'}
Hashset集合在设计时,为了避免多次调用equals()方法所带来的效率降低问题,当添加元素时,首先调用该元素的hashcode()方法得到一个地址值,如果该地址值没有被占用,就将该元素插入,如果地址值已经被占用了,再调用equals()方法与占用该位置的元素比较,如果为true,这两个元素被认为是重复的,重复的元素就不会被添加,如果为false,元素才会被添加到Hashset中。
LinkedHashSet集合:
1: LinkedHashSet实现了Set接口
2: LinkedHashSet从HashSet继承而来
3: LinkedHashSet的存储结构是一个双向链表,可以保证元素的顺序,它不同于HashSet的是它的遍历顺序和插入顺序是一致的
LinkedHashSet有以下四种常用的构造方法:
LinkedHashSet(); //构造一个空的 LinkedHashSet
LinkedHashSet(Collection c);//构造一个和给定的Collection中具有相同元素的 LinkedHashSet对象
LinkedHashSet(int capacity);//构造一个给定初始容量capacity的 LinkedHashSet对象
LinkedHashSet(int capacity,float fillRatio);//构造一个给定初始容量capacity和填充比fillRatio的LinkedHashSet对象
LinkedHashSet的简单使用:
package Hashset;
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Set;
public class demo1{
public static void main(String[]args){
Set<Integer> linkedSet=new LinkedHashSet<>();
linkedSet.add(9);
linkedSet.add(4);
linkedSet.add(18);
Iterator<Integer> k=linkedSet.iterator();//迭代器
while(k.hasNext()) {
Integer f=k.next();
System.out.println(f);
}
}
}
输出:
输出顺序与我们输入的顺序相同!
9
4
18
TreeSet集合:
TreeSet集合有如下特点:
1:TreeSet实现了Set接口
2:TreeSet对加入其中的元素按照某种规则进行升序排列,排序规则由元素本身决定。
3:TreeSet允许添加空元素
4:TreeSet不是线程安全的,不能用在多线程环境中
5:所有添加到TreeSet的元素必须是可比较的
TreeSet有以下四种常见的构造方法:
1:TreeSet():构造一个空的TreeSet
2:TreeSet(Collection c):构造一个和给定的Collection中具有相同元素的TreeSet对象,同时为其中的元素按照升序排列
3:TreeSet(Compatartor c):构造一个空的TreeSet并为其规定排列规则
4:TreeSet(SortedSet c):构造一个和给定的SortedSet具有相同元素,相同排序规则的TreeSet对象
TreeSet新增方法的简单使用:
代码如下:
package Hashset;
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Set;
import java.util.TreeSet;
public class demo1{
public static void main(String[]args){
TreeSet<Integer> treeSet=new TreeSet<>();
treeSet.add(10);
treeSet.add(67);
treeSet.add(199);
System.out.print("当前集合中的第一个元素为:");
System.out.println(treeSet.first());
System.out.print("当前元素中的最后一个元素为:");
System.out.println(treeSet.last());
System.out.print("返回当前集合中小于等于指定元素的最大元素:");
System.out.println(treeSet.floor(78));
System.out.println("集合中的元素有:");
Iterator<Integer> k=treeSet.iterator();//迭代器
while(k.hasNext()) {
Integer f=k.next();
System.out.println(f);
}
}
}
输出:
当前集合中的第一个元素为:10
当前元素中的最后一个元素为:199
返回当前集合中小于等于指定元素的最大元素:67
集合中的元素有:
10
67
199
注意:在向TreeSet中添加的字符串元素是按照字符串的大小升序排放的,而并非按照我们输入的顺序进行存放
举例:
package Hashset;
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Set;
import java.util.TreeSet;
public class demo1{
public static void main(String[]args){
TreeSet<String> treeSet=new TreeSet<>();
treeSet.add("java");
treeSet.add("python");
treeSet.add("C语言");
System.out.print("当前集合中的第一个元素为:");
System.out.println(treeSet.first());
System.out.print("当前元素中的最后一个元素为:");
System.out.println(treeSet.last());
System.out.println("集合中的元素有:");
Iterator<String> k=treeSet.iterator();//迭代器
while(k.hasNext()) {
String f=k.next();
System.out.println(f);
}
}
}
输出:
当前集合中的第一个元素为:C语言
当前元素中的最后一个元素为:python
集合中的元素有:
C语言
java
python
总结:
前文中我们曾了解Set集合中的元素无序是指HashSet集合中的元素无序,但Linked-HashSet可以实现元素按添加顺序存放,而TreeSet可以实现元素的排序
![[附源码]计算机毕业设计springboot基于Web的绿色环保网站](https://img-blog.csdnimg.cn/e9dff6394d3f44e2a5bdbe541b45791d.png)

![[附源码]计算机毕业设计JAVA小型医院药品及门诊管理](https://img-blog.csdnimg.cn/d58f2445c9774006b40ec72620c662ef.png)





![[Linux]------初识多线程](https://img-blog.csdnimg.cn/584a1f72d29b43119cfe6b8662d298ed.png)