- 索引使用
1.1. 全局索引(Global Indexing)
名词解释:
全局索引,适用于读多写少的业务场景。使用Global indexing在写数据的时候开销很大,因为所有对数据表的更新操作(DELETE, UPSERT VALUES and UPSERT SELECT),都会引起索引表的更新,而索引表是分布在不同的数据节点上的,跨节点的数据传输带来了较大的性能消耗。在读数据的时候Phoenix会选择索引表来降低查询消耗的时间。在默认情况下如果想查询的字段不是索引字段的话索引表不会被使用,也就是说不会带来查询速度的提升。
1.2. 使用前提(开发、测试、生产环境已准备完毕)
做好hbase安装与phoenix连接的相关配置
1.3. 使用示例
1.3.1. 创建phoenix的schema
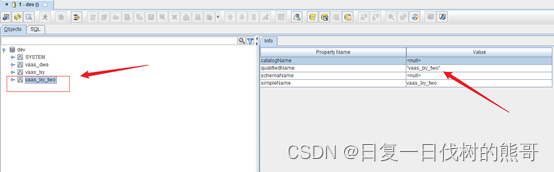
示例的schema是vaas_lxy_two
create schema if not exists “vaas_lxy_two”;
1.3.2. 创建phoenix的表
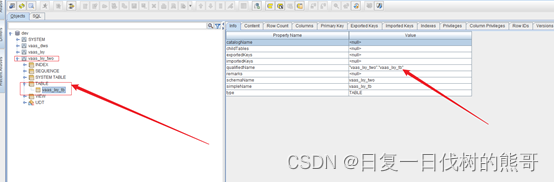
表名:vaas_lxy_tb
列簇:C1
主键:id
压缩算法:Snappy (可选)
create table if not exists “vaas_lxy_two”.“vaas_lxy_tb”(“id” varchar not null primary key,“C1”.“name” varchar,“C1”.“sex” varchar)COMPRESSION=‘Snappy’;

注意:列族只能在非主键列中进行指定。
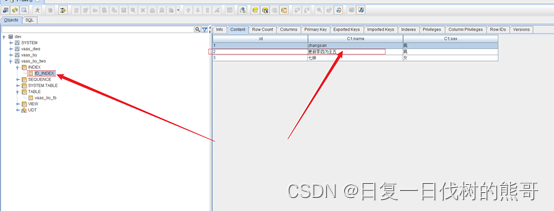
1.3.3. 创建phoenix的全局索引
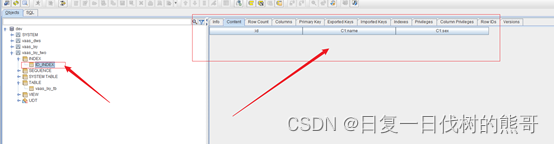
索引名称:id_index
索引字段:id
包含字段:C1.name;C1.sex
列簇:C1

create index id_index on “vaas_lxy_two”.“vaas_lxy_tb”(“id”) include (“C1”.“name”,“C1”.“sex”);
注意:查询涉及到的条件字段和查询字段必须都要在索引字段或者include字段范围内!!!
1.3.4. phoenix插入数据
upsert into “vaas_lxy_two”.“vaas_lxy_tb”(“id”,“C1”.“name”,“C1”.“sex”) values(‘1’,‘zhangsan’,‘男’);
upsert into “vaas_lxy_two”.“vaas_lxy_tb”(“id”,“C1”.“name”,“C1”.“sex”) values(‘2’,‘李四’,‘男’);
upsert into “vaas_lxy_two”.“vaas_lxy_tb”(“id”,“C1”.“name”,“C1”.“sex”) values(‘3’,‘七妹’,‘女’);
数据表数据:
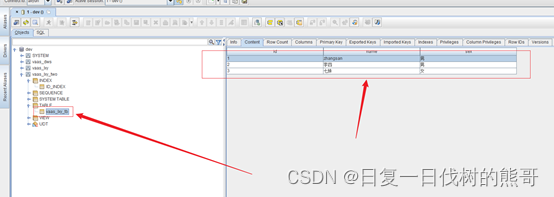
索引表数据:
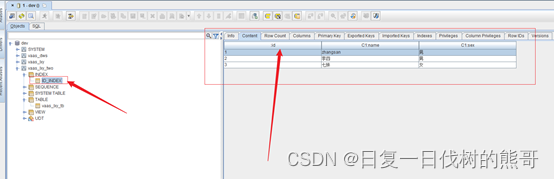
1.3.5. Phoenix更新数据
upsert into “vaas_lxy_two”.“vaas_lxy_tb”(“id”,“C1”.“name”,“C1”.“sex”) values(‘2’,‘更新李四为王五’,‘男’);
数据表数据:
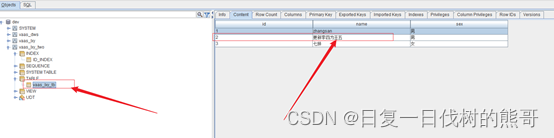
索引表数据: