目录
遗传算法相关参数问题
种群规模、迭代次数、交叉率、变异率对算法的影响
A*算法中open表和close表的作用
为什么A*算法中open表是增长的
启发式函数h(n)取值的影响
A*算法可以找到最优解的条件
模式识别系统的组成
有监督学习和无监督学习的区别
模型评估三大原则
查准率和查全率
KNN中K值选取的影响
回归问题和分类问题的区别
线性回归问题机器学习的步骤
模型训练时batch和epoch的含义
sigmoid函数和ReLU函数的区别
神经元模型
BP学习算法的正向传播和反向传播
BP算法的流程
CNN中卷积层和池化层的作用
CNN中的关键技术
CNN优于全连接神经网络的地方
GAN的工作流程
遗传算法相关参数问题
编码方式
- 二进制编码:把问题的解表示为由0和1组成的位串,每一位对应一个基因。二进制编码简单易用,但可能存在汉明悬崖问题,即相邻整数的二进制代码之间有很大的汉明距离,导致交叉和变异难以跨越。
- 格雷编码:把问题的解表示为由0和1组成的位串,但每两个相邻的数用格雷码表示,其对应的码位只有一个不相同,从而可以提高算法的局部搜索能力。格雷编码可以避免汉明悬崖问题,但需要额外的编码和解码过程。
- 实数编码:把问题的解表示为实数或浮点数,可以直接对应问题的参数空间,不需要编码和解码过程。实数编码适合处理连续优化问题,但需要设计特定的交叉和变异算子。
- 排列编码:把问题的解表示为一种排列或序列,每个位置对应一个基因。排列编码适合处理组合优化问题,如旅行商问题,但也需要设计特定的交叉和变异算子。
选择方法
- 轮盘赌选择法:这是一种最简单也最常用的选择法,它根据个体的适应度值与总适应度值的比例来分配选择概率,即适应度值越高的个体被选中的概率越大。具体步骤如下:
-
- 将种群中个体的适应度值叠加,得到总适应度值
- 每个个体的适应度值除以总适应度值得到个体被选择的概率
- 计算个体的累积概率以构造一个轮盘
- 产生一个[0,1]之间的随机数,根据轮盘确定被选中的个体
- 锦标赛选择法:这是一种通过多轮比较来确定被选中个体的方法,它可以有效地控制选择压力和保持多样性。具体步骤如下:
-
- 随机从种群中抽取k个个体,其中k是一个预设的参数,通常为2或3
- 比较这k个个体的适应度值,选择最高者作为赢者
- 将赢者复制到新种群中,重复以上步骤直到新种群满员
交叉策略
- 单点交叉:在两个个体的染色体上随机选择一个交叉点,然后交换该点后面的部分基因。
- 两点交叉:在两个个体的染色体上随机选择两个交叉点,然后交换这两个点之间的部分基因。
变异策略
- 位反转变异:在一个个体的染色体上随机选择一个或多个基因位,然后将其取反,即0变为1,1变为0。
- 交换变异:在一个个体的染色体上随机选择两个基因位,然后交换它们的值。
- 插入变异:在一个个体的染色体上随机选择一个基因位,然后将其插入到另一个随机位置上,原来位置后面的基因位依次向前移动一位。
- 逆转变异:在一个个体的染色体上随机选择一个子串,然后将其逆序排列。
- 均匀变异:在一个个体的染色体上逐位比较基因,以一定概率改变不同的基因。
种群规模、迭代次数、交叉率、变异率对算法的影响
- 种群规模:种群规模是每代个体的固定总数,即初始解的个数。种群规模过小会导致搜索空间不足,陷入局部最优解;种群规模过大会导致计算量增加,收敛速度变慢。一般来说,种群规模应该根据问题的复杂度和搜索空间的大小来确定,一般取10到100之间的值。
- 迭代次数:迭代次数是指遗传算法进行多少代的进化。迭代次数过少会导致搜索不充分,无法找到较好的解;迭代次数过多会导致计算时间增加,收敛速度变慢。一般来说,迭代次数应该根据问题的难度和收敛情况来确定,一般取50到500之间的值。
- 交叉率:交叉率是指每代中进行交叉操作的个体比例。交叉操作是遗传算法中最重要的操作,它可以产生新的个体,增加种群的多样性,从而提高搜索能力。交叉率过低会导致搜索能力不足,陷入局部最优解;交叉率过高会导致搜索能力过强,破坏优秀个体,降低收敛速度。一般来说,交叉率应该根据问题的特点和搜索空间的大小来确定,一般取0.6到0.9之间的值。
- 变异率:变异率是指每代中进行变异操作的基因比例。变异操作是遗传算法中辅助交叉操作的操作,它可以引入新的基因,增加种群的多样性,从而跳出局部最优解。变异率过低会导致搜索能力不足,陷入局部最优解;变异率过高会导致搜索能力过强,破坏优秀个体,降低收敛速度。一般来说,变异率应该根据问题的特点和搜索空间的大小来确定,一般取0.01到0.1之间的值。
A*算法中open表和close表的作用
A*算法是一种启发式搜索算法,它可以在图中找到从起点到终点的最短路径。A*算法使用了两个列表,分别是open表和close表
open表是一个优先队列,它存储了所有已经被评估过启发函数值但还没有被扩展成后继节点的节点。启发函数值是一个估计值,表示从当前节点到目标节点的代价。A*算法每次从open表中选择一个启发函数值最小的节点,称为当前节点,然后将其从open表中移除,并将其加入到close表中。
close表是一个集合,它存储了所有已经被访问过的节点。这样可以避免重复访问同一个节点,提高搜索效率。A*算法每次扩展当前节点的所有后继节点,计算它们的启发函数值,并检查它们是否已经在open表或close表中存在。如果不存在,就将它们加入到open表中;如果存在,就比较它们的启发函数值,如果新的值更小,就更新它们的值,并修改它们的父节点为当前节点。¹²
这个过程一直重复,直到找到目标节点或者open表为空为止。如果找到目标节点,就沿着父节点指针回溯得到最短路径;如果open表为空,就说明没有可行的路径。¹²
open表和close表的作用是帮助A*算法按照启发函数值的顺序搜索图中的节点,并记录已经访问过的节点,从而找到最短路径。
为什么A*算法中open表是增长的
Open表是增长的,因为每次扩展一个节点时,都会把它的相邻可达节点加入到Open表中(除非它们已经在Closed表中或者是障碍物)。这样,Open表中的节点数量会随着搜索过程而增加,直到找到终点或者没有可扩展的节点为止。
启发式函数h(n)取值的影响
h(n) 比重大:降低搜索工作量,但可能导致找不到最优解;
h(n) 比重小:一般导致工作量加大,极限情况下变为盲目搜索,但可能可以找到最优解。
A*算法可以找到最优解的条件
启发函数必须是一致的(admissible):启发函数不能高估从当前节点到目标节点的距离。也就是说,该函数估计的距离不能大于实际距离。如果启发函数是一致的,则 A* 搜索算法保证能够找到最短路径。
图形结构必须不包括环路(acyclic):A* 算法只适用于图形结构不包括环路的问题。因为对于含有环路的图形结构,启发函数可能会导致算法在环路中无限循环下去。
模式识别系统的组成
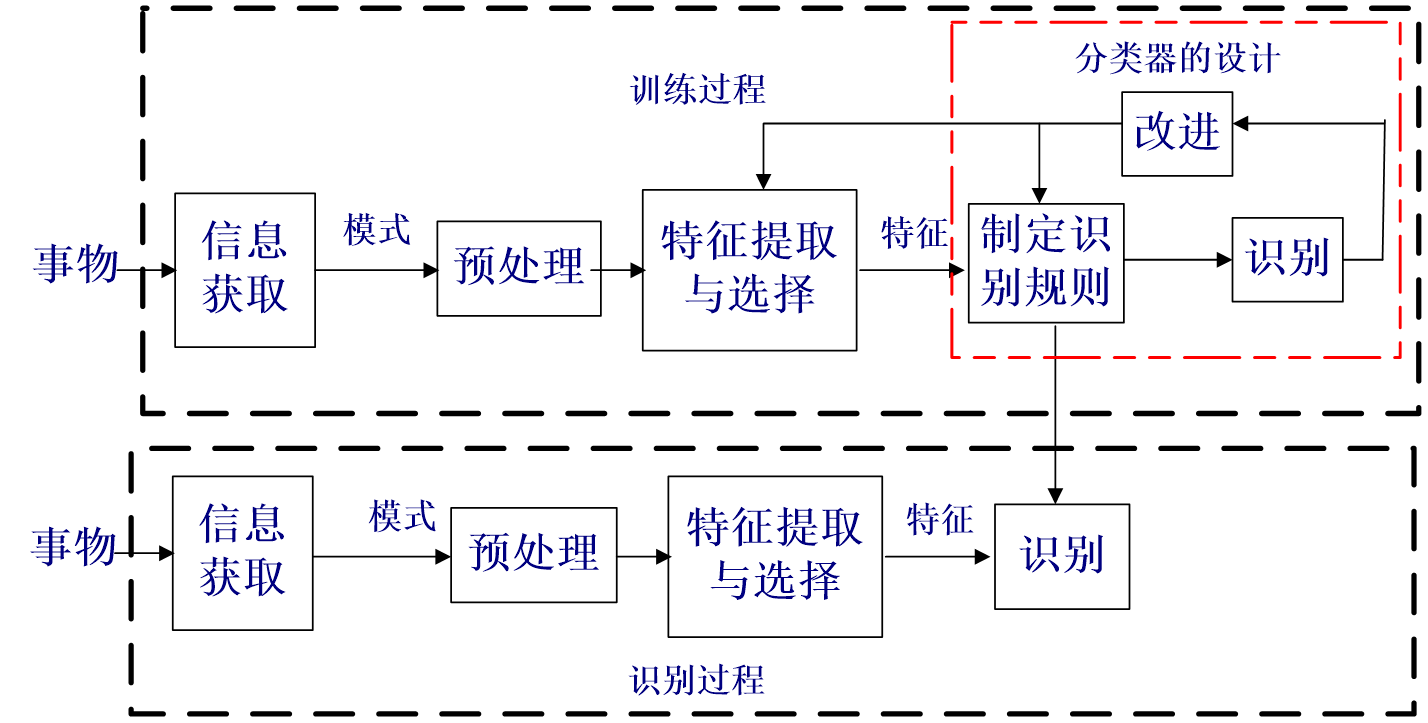
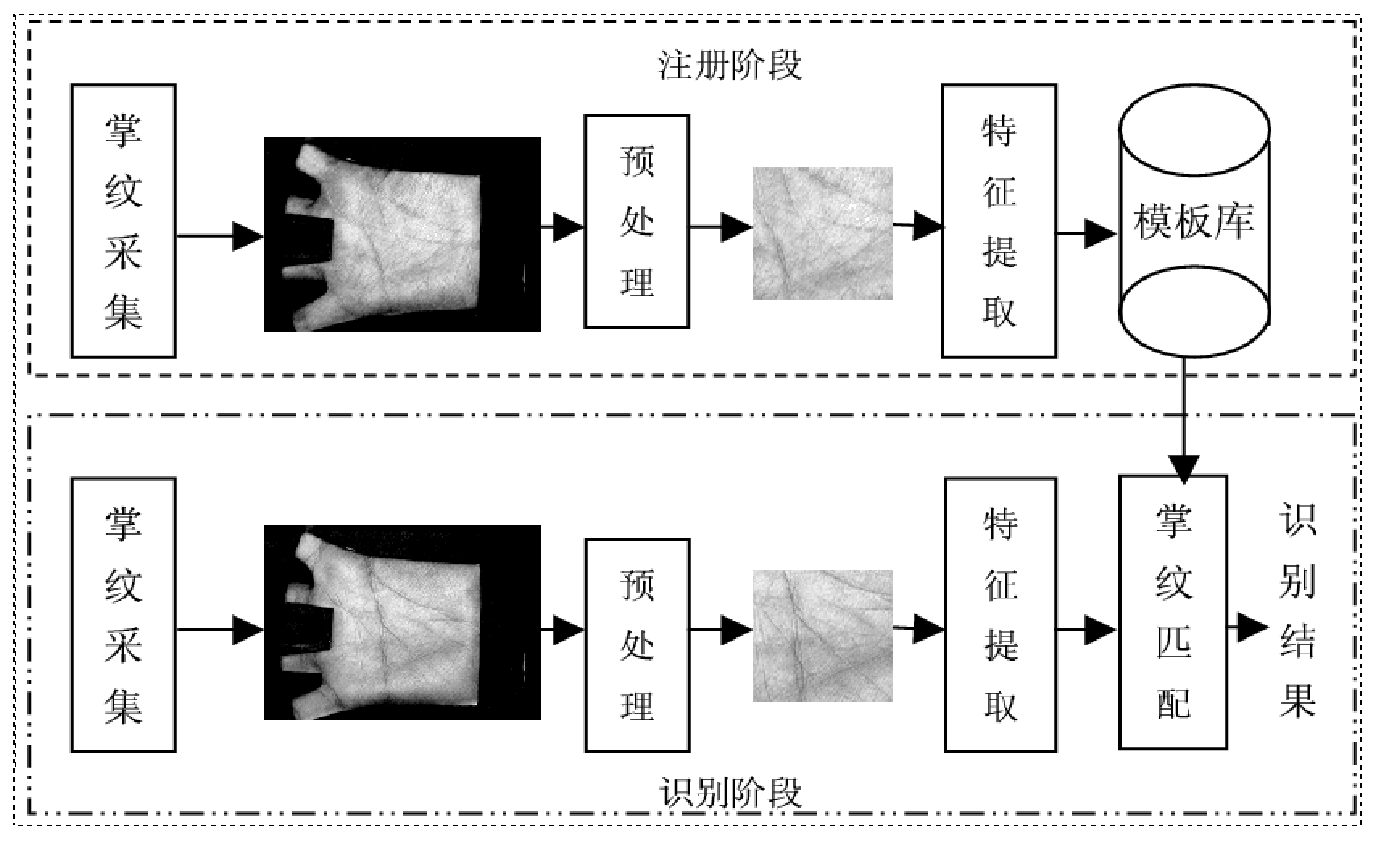
举例:掌纹识别
有监督学习和无监督学习的区别
有监督学习和无监督学习是机器学习中的两个重要概念。
有监督学习需要有标签数据作为训练数据,而无监督学习则不需要。
有监督学习的目标是通过已知的标签数据来预测未知数据的标签,而无监督学习的目标是发现数据中的模式和结构
模型评估三大原则
奥卡姆剃刀:在性能得到满足的情况下,模型越简单越好
数据集划分时的样本采样原则:训练集、测试集和验证集的分布应尽量一致
测试集使用原则:训练阶段不要以任何理由偷看测试集;对测试集的反复评估也是一种隐蔽地偷看行为
查准率和查全率
- 查准率是指预测为正例的样本中,真正为正例的比例。它反映了预测结果的准确性,即避免将反例误判为正例。提高查准率的方法是增加预测为正例的门槛,只有当样本的正例概率很高时才将其判为正例,这样可以减少假正例(false positive)的数量,但同时也会增加假反例(false negative)的数量,即将正例误判为反例。
- 查全率是指真正为正例的样本中,预测为正例的比例。它反映了预测结果的完整性,即尽可能地覆盖所有的正例。提高查全率的方法是降低预测为正例的门槛,只要样本有一定的正例概率就将其判为正例,这样可以减少假反例(false negative)的数量,但同时也会增加假正例(false positive)的数量,即将反例误判为正例。
因此,查准率和查全率是一种权衡关系,提高一个往往会降低另一个,反之亦然。不同的任务或场景可能对查准率和查全率有不同的偏好或要求,例如,在垃圾邮件过滤中,我们更倾向于提高查准率,避免将正常邮件误判为垃圾邮件;而在疾病诊断中,我们更倾向于提高查全率,避免将患病者误判为健康者。
KNN中K值选取的影响

回归问题和分类问题的区别
回归问题和分类问题的区别在于输出变量的类型。 定量输出称为回归,或者说是连续变量预测; 定性输出称为分类,或者说是离散变量预测。
分类问题通常适用于预测一个类别(或类别的概率)而不是连续的数值。
回归问题通常是用来预测一个值,如预测房价、未来的天气情况等等。
线性回归问题机器学习的步骤
1定义一个带有未知参数的函数(模型)
2定义损失函数
3基于优化方法得到最优参数
模型训练时batch和epoch的含义
在深度学习中,batch是指每次训练模型时,同时输入多个样本进行训练的一种方式。batch size是指每个batch中包含的样本数。batch size越大,训练速度越快,但内存消耗也越大;batch size越小,训练速度越慢,但内存消耗也越小。
epoch是指将所有训练数据都过一遍的训练过程。在每个epoch中,模型会对所有训练数据进行一次前向传播和反向传播,并更新模型参数。epoch数是指将所有训练数据都过一遍所需要的次数。
sigmoid函数和ReLU函数的区别
sigmoid函数和ReLU函数的主要区别在于它们的形状和性质。sigmoid函数在输入值较大或较小时,输出值接近于0或1,而在输入值接近于0时,输出值接近于0.5。这意味着sigmoid函数在输入值较大或较小时,梯度会变得很小,从而导致梯度消失问题。ReLU函数则不存在这个问题,因为它在输入值为负时,梯度为0,在输入值为正时,梯度为1。这使得ReLU函数更容易训练,并且可以加速收敛速度。
另外,ReLU函数还具有稀疏性和非线性特性。稀疏性是指ReLU函数可以使一部分神经元的输出为0,从而使得神经网络更加稀疏;非线性特性是指ReLU函数可以引入非线性因素,从而使得神经网络更加灵活。这些特性使得ReLU函数在深度学习中被广泛使用,并且已经被证明比sigmoid函数更有效。
神经元模型
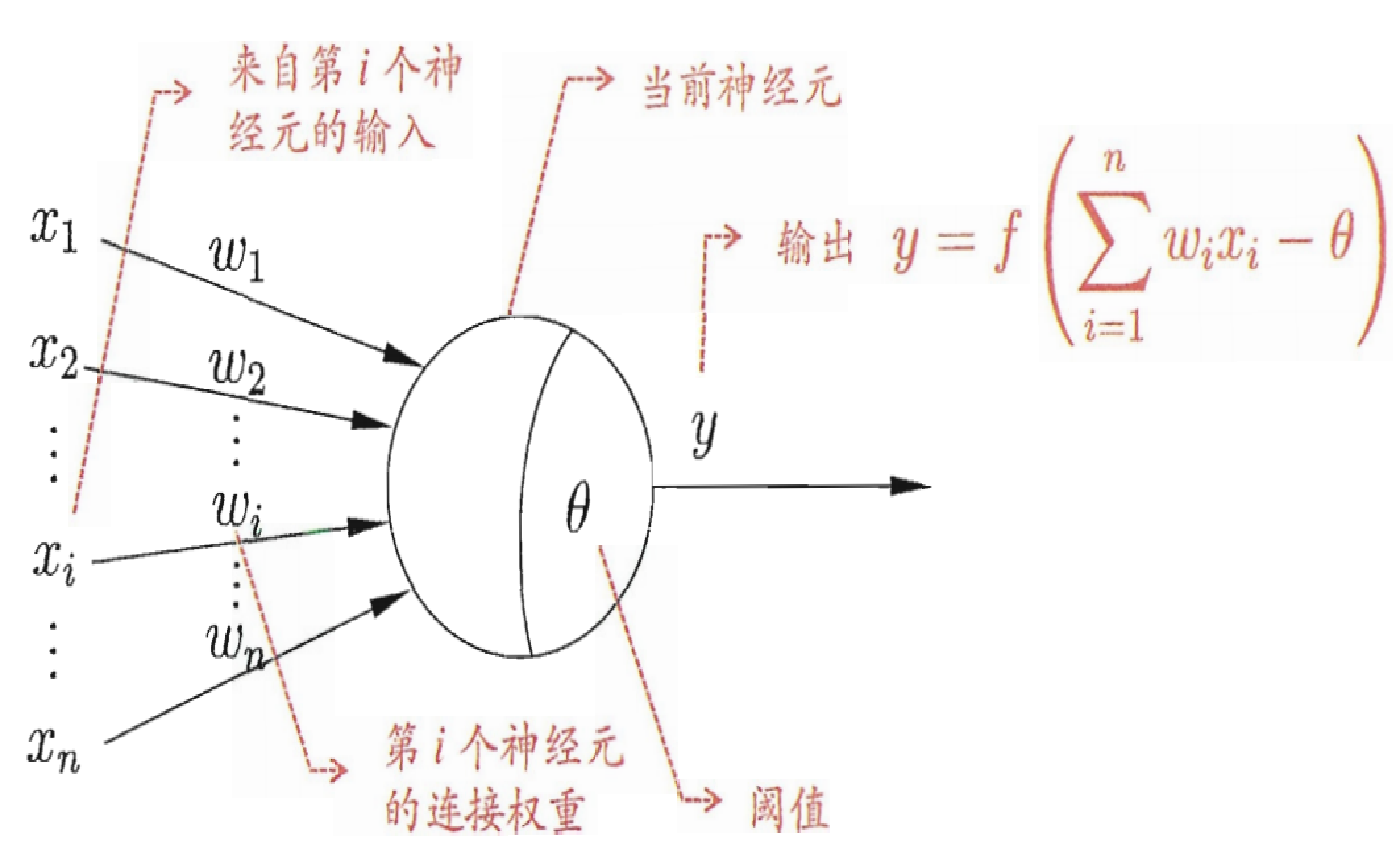
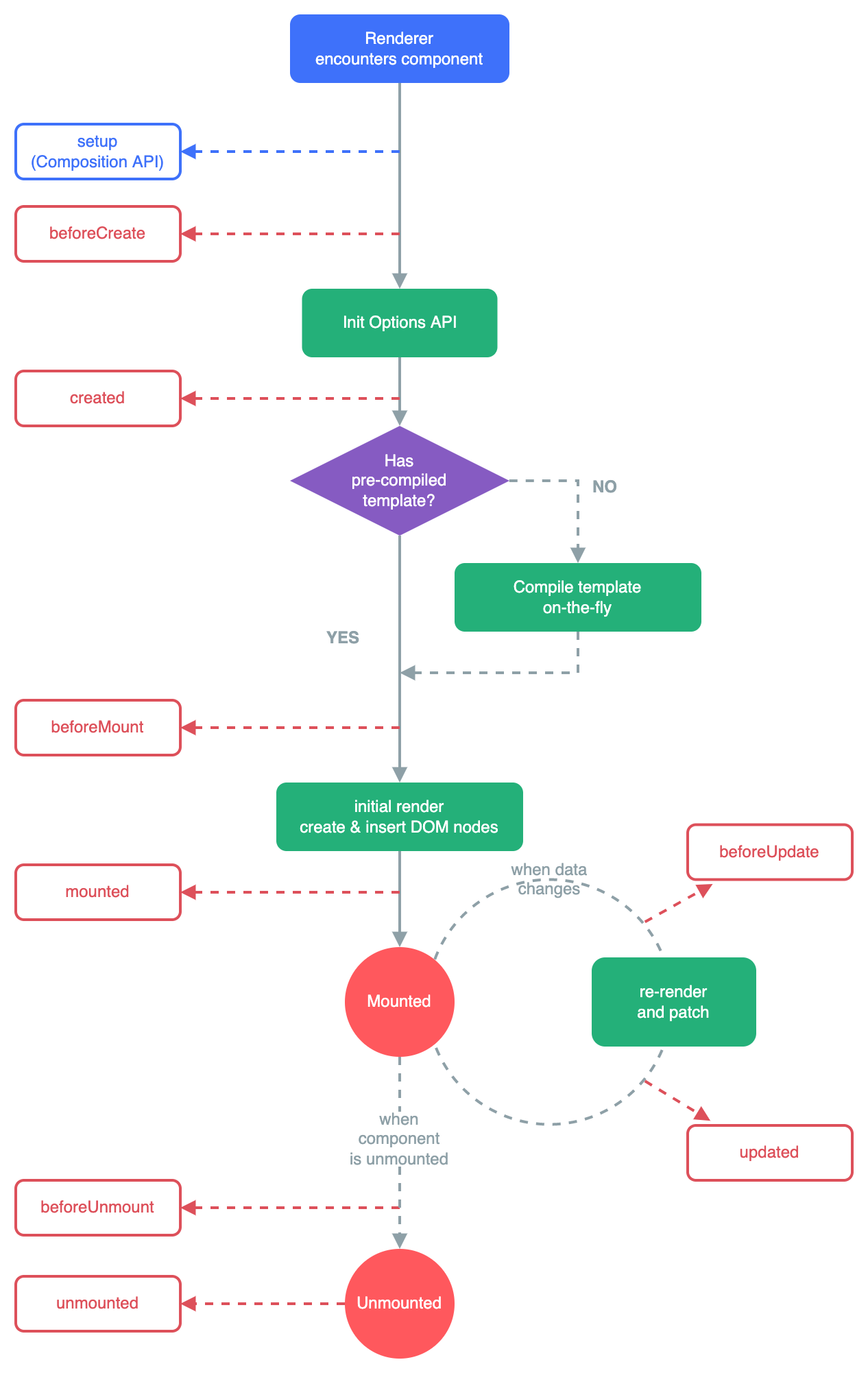
BP学习算法的正向传播和反向传播
正向传播:输入信息由输入层传至隐层,最终在输出层输出。
反向传播:修改各层神经元的权值,使误差信号最小
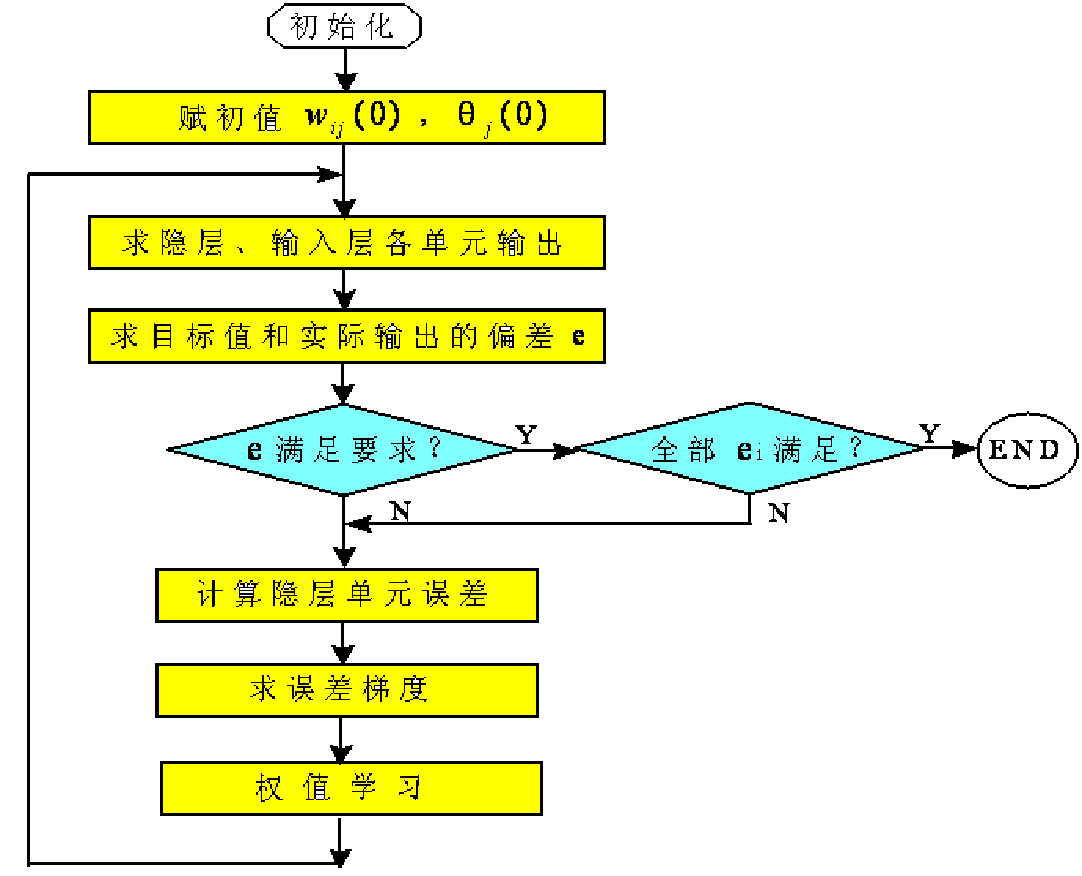
BP算法的流程
CNN中卷积层和池化层的作用
在卷积神经网络(CNN)中,卷积层和池化层都是用于提取图像特征的。卷积层通过使用卷积核来提取图像的局部特征,而池化层则通过对卷积层输出的特征图进行下采样来减少特征图的大小。池化层可以帮助减少过拟合,提高模型的泛化能力
CNN中的关键技术
局部链接
权值共享:所有卷积模板都相同
多卷积核
CNN优于全连接神经网络的地方
卷积层相比于全连接层有以下优势:
- 参数共享:卷积层的参数共享可以大大减少需要学习的参数数量,提高模型的泛化能力。相对于全连接层,卷积层需要学习的参数数量更少,因此更容易训练,而且更不容易过拟合。
- 空间局部性:卷积层能够捕获输入数据中的空间局部性信息。在图像识别任务中,相邻像素之间的关系非常重要,卷积层能够利用这种关系来提取图像特征,而全连接层则无法捕获这种信息。
- 计算复杂度:由于参数共享和空间局部性,卷积层的计算复杂度比全连接层低。在处理大规模数据时,卷积层更加高效。
- 模型泛化能力:卷积层能够学习到输入数据的局部特征,因此具有更好的模型泛化能力。相对于全连接层,卷积层更容易处理输入数据中的噪声和变形。
- 可解释性:卷积层的输出可以看做是输入数据的特征图,因此更容易解释模型的预测结果。相对于全连接层,卷积层更容易理解和可解释。
综上所述,卷积层相比于全连接层具有更好的模型泛化能力、更高的计算效率和更好的可解释性,适用于处理图像、音频等二维或三维数据。
GAN的工作流程
生成对抗网络(GAN)是一种深度学习模型,由两个神经网络组成:生成器和判别器。生成器的作用是生成与训练数据相似的新数据,而判别器的作用是区分真实数据和生成器生成的数据。GAN 的训练过程是交替训练这两个网络,直到生成器生成的数据能够以假乱真,并与判别器的能力达到一定均衡。GAN 的工作流程如下:
- 初始化生成器和判别器的参数。
- 从训练集中抽取 n 个样本,以及从噪声分布中采样得到 n 个噪声样本。
- 固定生成器,训练判别器,使其尽可能区分真假。
- 固定判别器,训练生成器,使其尽可能欺骗判别器。
- 多次更新迭代后,最终辨别器无法区分图片到底是来自真实的训练样本集合,还是来自生成器 G 生成的样本即可,此时辨别的概率为0.5,完成训练。