前言
- 神经架构搜索(NAS):自动化设计高性能深度神经网络架构的技术
- 神经架构搜索任务主要有三个关键组成部分,即:
- 模型搜索空间,定义了一个要探索的模型的集合
- 一个合适的策略作为探索这个模型空间的方法
- 一个模型评估器,用于为搜索空间中每个模型评估性能
- 本文将演示如何在DARTS中提出的著名模型空间中进行搜索。
- 最后,我们在 CIFAR-10 数据集上得到了一个性能强大的模型,其准确率高达 97.28%。
- 需要用到
NNI库,请提前安装好pip install nni。依赖库版本限制:pip install torchmetrics==0.10、pip install pytorch-lightning==1.9.4
使用预搜索的 DARTS 模型
- 首先使用
torchvision加载 CIFAR-10 数据集。 - 需要注意的是,如果你要使用多试验策略(
multi-trial strategies),用nni.trace()包装CIFAR10和使用nni.retiarii.evalator.pytorch(而不是torch.utils.data)的DataLoader是必须的。
import nni
import torch
from torchvision import transforms
from torchvision.datasets import CIFAR10
from nni.retiarii.evaluator.pytorch import DataLoader
CIFAR_MEAN = [0.49139968, 0.48215827, 0.44653124]
CIFAR_STD = [0.24703233, 0.24348505, 0.26158768]
transform_valid = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(CIFAR_MEAN, CIFAR_STD),
])
valid_data = nni.trace(CIFAR10)(root='./data', train=False, download=True, transform=transform_valid)
valid_loader = DataLoader(valid_data, batch_size=256, num_workers=6)
- 我们从DARTS搜索空间中选择一个,它在我们的目标数据集 CIFAR-10 上进行了原生训练,以省去繁琐的微调步骤
from nni.retiarii.hub.pytorch import DARTS as DartsSpace
darts_v2_model = DartsSpace.load_searched_model('darts-v2', pretrained=True, download=True)
def evaluate_model(model, cuda=False):
device = torch.device('cuda' if cuda else 'cpu')
model.to(device)
model.eval()
with torch.no_grad():
correct = total = 0
for inputs, targets in valid_loader:
inputs, targets = inputs.to(device), targets.to(device)
logits = model(inputs)
_, predict = torch.max(logits, 1)
correct += (predict == targets).sum().cpu().item()
total += targets.size(0)
print('Accuracy:', correct / total)
return correct / total
evaluate_model(darts_v2_model, cuda=True) # Set this to false if there's no GPU.
- 评估模型
from nni.retiarii.hub.pytorch import DARTS as DartsSpace
# 加载预训练模型
darts_v2_model = DartsSpace.load_searched_model('darts-v2', pretrained=True, download=True)
# 评估模型
def evaluate_model(model, cuda=False):
# 将模型迁移到GPU上
device = torch.device('cuda' if cuda else 'cpu')
model.to(device)
# 将模型置为评估状态
model.eval()
# 不计算梯度
with torch.no_grad():
correct = total = 0
for inputs, targets in valid_loader:
# 将数据迁移到GPU上
inputs, targets = inputs.to(device), targets.to(device)
# 模型输出结果
logits = model(inputs)
_, predict = torch.max(logits, 1)
# 统计正确与错误数量
correct += (predict == targets).sum().cpu().item()
total += targets.size(0)
# 打印准确率
print('Accuracy:', correct / total)
return correct / total
evaluate_model(darts_v2_model, cuda=True) # Set this to false if there's no GPU.
输出:
Accuracy: 0.9737
使用 DARTS 模型空间
DARTS中提供的模型空间起源于NASNet,其中完整的模型是通过重复堆叠单个计算单元(称为cell)来构建的。网络中有两种类型的单元。第一种称为普通单元(normal cell),第二种称为缩减单元(reduction cell)。普通单元和缩减单元之间的主要区别在于缩减单元将对输入特征图进行下采样,并降低其分辨率。普通单元和缩减单元交替堆叠,如下图所示。
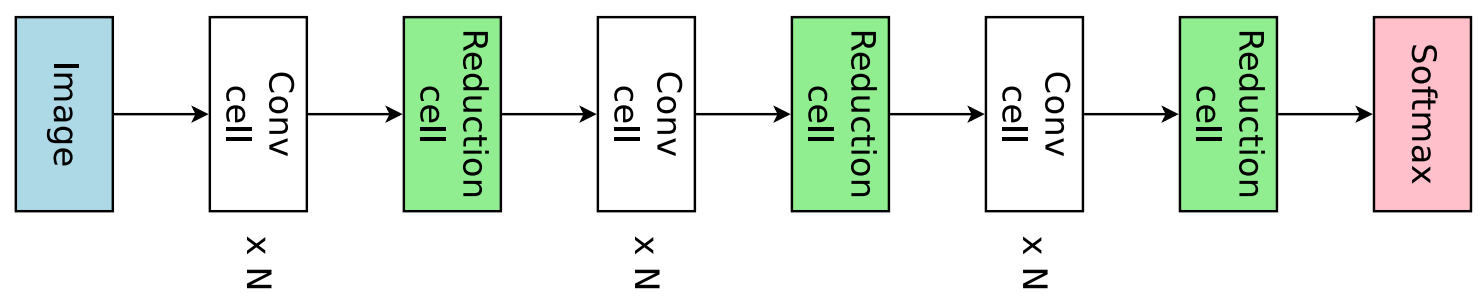
- 一个单元格将前两个单元格的输出作为输入,并包含一组节点。每个节点采用同一单元内的两个先前节点(或两个单元输入),并对每个输入应用运算符(例如,卷积或最大池化),并将运算符的输出相加作为节点的输出。单元格的输出是从未用作另一个节点输入的所有节点的串联。
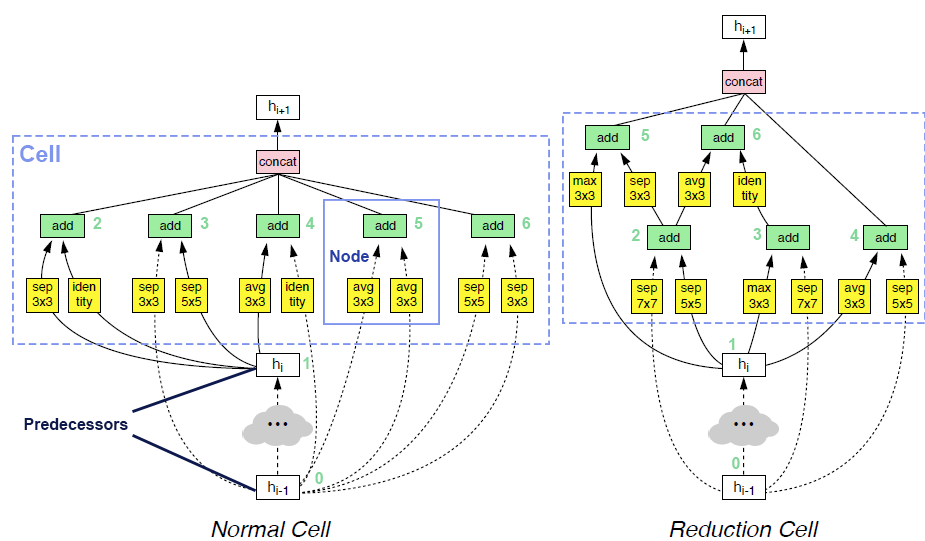
DARTS论文中提出的搜索空间对NASNet中的原始空间进行了两次修改。候选模块已经缩小到7个:- Max pooling 3x3
- Average pooling 3x3
- Skip connect (Identity)
- Separable convolution 3x3
- Separable convolution 5x5
- Dilated convolution 3x3
- Dilated convolution 5x5
- 其次, cell 的输出是cell 内所有节点的串联。
- 由于搜索空间是基于单元格的,一旦固定了普通单元格和缩减单元格,我们就可以无限次地堆叠它们。为了节省搜索成本,通常的做法是在搜索阶段减少过滤器(即通道)的数量和堆叠单元的数量,并在训练最终搜索到的架构时将它们增加回来。
- 在下面的示例中,我们初始化一个DARTS 模型空间,其中包含 16 个初始过滤器和 8 个堆叠单元。该网络专用于具有 32x32 输入分辨率的 CIFAR-10 数据集。
模型架构搜索
- 定义搜索空间,
width表示通道数,num_cells表示单元堆叠数。 - 为了快速检验代码正确性,
fast_dev_run为True时将只运行几个batch。
fast_dev_run = True
model_space = DartsSpace(width=16,num_cells=8,dataset='cifar')
- 要开始探索模型空间,首先需要有一个评估者来提供“好模型”的标准。当我们在 CIFAR-10 数据集上搜索时,可以轻松地将
Classification用作起点。 - 请注意,对于典型的NAS设置,模型搜索应该在验证集上进行,最终搜索模型的评估应该在测试集上进行。然而,由于 CIFAR-10 数据集没有测试数据集(只有 50k train + 10k valid),我们必须将原始训练集拆分为训练集和验证集。推荐的DARTS策略划分训练/验证比例为1:1。
import numpy as np
from nni.retiarii.evaluator.pytorch import Classification
from torch.utils.data import SubsetRandomSampler
# 图片预处理器
transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(CIFAR_MEAN, CIFAR_STD),
])
# 下载训练数据
train_data = nni.trace(CIFAR10)(root='./data', train=True, download=True, transform=transform)
# train_data数量
num_samples = len(train_data)
# 对图片进行随机排列
indices = np.random.permutation(num_samples)
# 分离点
split = num_samples // 2
# 训练数据加载器
# SubsetRandomSampler():无放回地按照给定的索引列表采样样本元素
search_train_loader = DataLoader(
train_data, batch_size=64, num_workers=6,
sampler=SubsetRandomSampler(indices[:split]),
)
# 验证集数据加载器
search_valid_loader = DataLoader(
train_data, batch_size=64, num_workers=6,
sampler=SubsetRandomSampler(indices[split:]),
)
# 评估模型
evaluator = Classification(learning_rate=1e-3,
weight_decay=1e-4,
train_dataloaders=search_train_loader,
val_dataloaders=search_valid_loader,
max_epochs=10,
gpus=1,
fast_dev_run=fast_dev_run,)
模型搜索策略
- 我们将使用
DARTS(可微分架构搜索)作为探索模型空间的搜索策略。DARTS策略属于one-shot策略的范畴。one-shot策略和multi-trial策略之间的根本区别在于,one-shot策略将搜索与模型训练结合到一次运行中。与多试验策略相比,one-shot NAS不需要迭代产生新的试验(即模型),从而节省了模型训练的过多成本。
from nni.retiarii.strategy import DARTS as DartsStrategy
strategy = DartsStrategy()
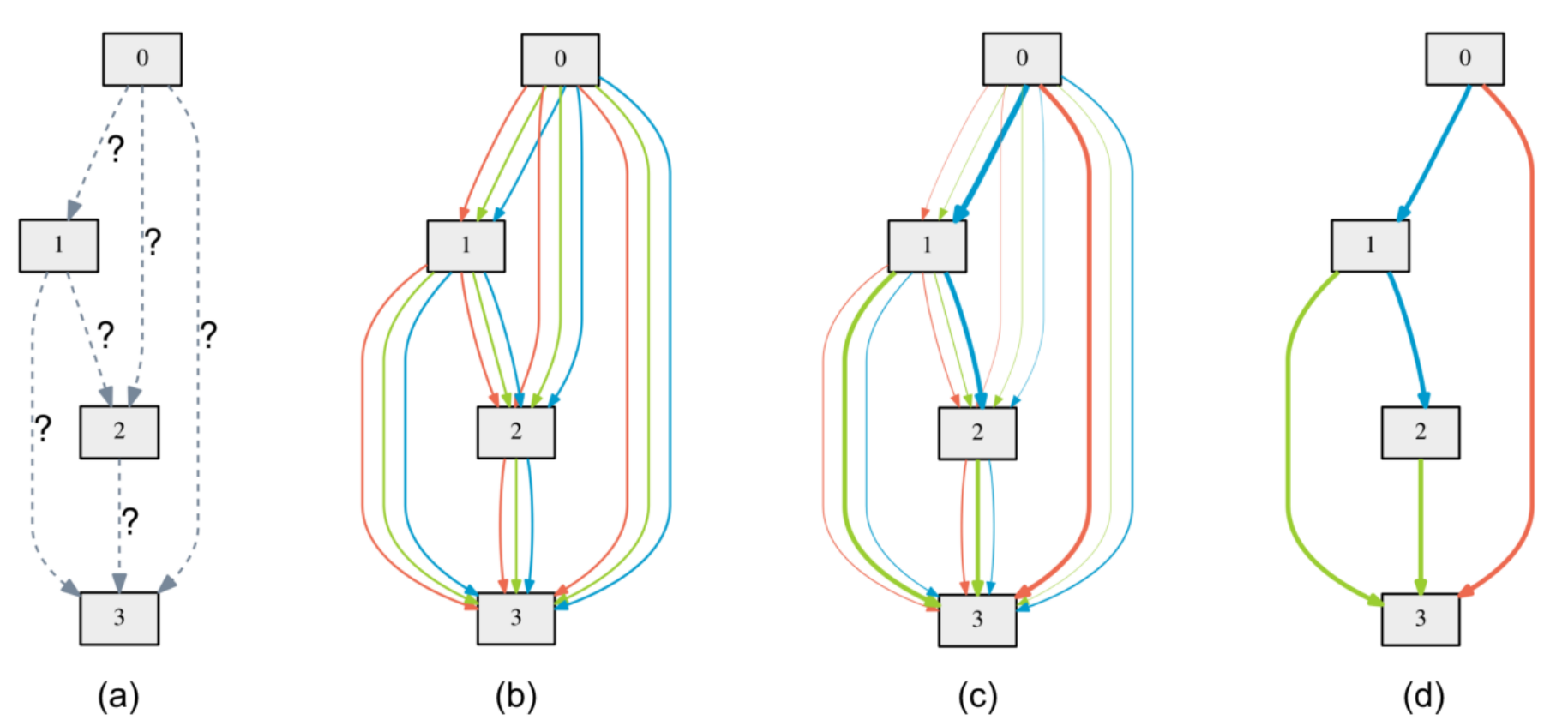
- DARTS 策略原理:单元格转换为密集连接的图形,并将运算符放在边上(参见下图)。由于算子尚未确定,每条边都是多个算子的加权混合(图中为多种颜色)。DARTS 然后学习在网络训练期间为每条边分配最佳“颜色”。它最终为每条边选择一种“颜色”,并丢弃多余的边。边缘上的权重称为架构权重。
开始实验
from nni.retiarii.experiment.pytorch import RetiariiExperiment, RetiariiExeConfig
config = RetiariiExeConfig(execution_engine='oneshot')
experiment = RetiariiExperiment(model_space, evaluator=evaluator, strategy=strategy)
experiment.run(config)
- 然后,我们可以得到最佳模型
export_top_models。模型是一个dict(称为architecture dict),描述了所选普通单元格和缩减单元格。
exported_arch = experiment.export_top_models()[0]
exported_arch
输出:
{'normal/op_2_0': 'skip_connect',
'normal/input_2_0': 0,
'normal/op_2_1': 'dil_conv_3x3',
'normal/input_2_1': 1,
'normal/op_3_0': 'sep_conv_3x3',
'normal/input_3_0': 2,
'normal/op_3_1': 'avg_pool_3x3',
'normal/input_3_1': 0,
'normal/op_4_0': 'dil_conv_5x5',
'normal/input_4_0': 0,
'normal/op_4_1': 'dil_conv_5x5',
'normal/input_4_1': 1,
'normal/op_5_0': 'sep_conv_3x3',
'normal/input_5_0': 2,
'normal/op_5_1': 'dil_conv_5x5',
'normal/input_5_1': 0,
'reduce/op_2_0': 'dil_conv_3x3',
'reduce/input_2_0': 1,
'reduce/op_2_1': 'max_pool_3x3',
'reduce/input_2_1': 0,
'reduce/op_3_0': 'sep_conv_3x3',
'reduce/input_3_0': 0,
'reduce/op_3_1': 'sep_conv_3x3',
'reduce/input_3_1': 1,
'reduce/op_4_0': 'dil_conv_3x3',
'reduce/input_4_0': 0,
'reduce/op_4_1': 'dil_conv_5x5',
'reduce/input_4_1': 3,
'reduce/op_5_0': 'sep_conv_5x5',
'reduce/input_5_0': 4,
'reduce/op_5_1': 'sep_conv_3x3',
'reduce/input_5_1': 0}
- 可以将模型框架可视化
import io
import graphviz
import matplotlib.pyplot as plt
from PIL import Image
def plot_single_cell(arch_dict, cell_name):
g = graphviz.Digraph(
node_attr=dict(style='filled', shape='rect', align='center'),
format='png'
)
g.body.extend(['rankdir=LR'])
g.node('c_{k-2}', fillcolor='darkseagreen2')
g.node('c_{k-1}', fillcolor='darkseagreen2')
assert len(arch_dict) % 2 == 0
for i in range(2, 6):
g.node(str(i), fillcolor='lightblue')
for i in range(2, 6):
for j in range(2):
op = arch_dict[f'{cell_name}/op_{i}_{j}']
from_ = arch_dict[f'{cell_name}/input_{i}_{j}']
if from_ == 0:
u = 'c_{k-2}'
elif from_ == 1:
u = 'c_{k-1}'
else:
u = str(from_)
v = str(i)
g.edge(u, v, label=op, fillcolor='gray')
g.node('c_{k}', fillcolor='palegoldenrod')
for i in range(2, 6):
g.edge(str(i), 'c_{k}', fillcolor='gray')
g.attr(label=f'{cell_name.capitalize()} cell')
image = Image.open(io.BytesIO(g.pipe()))
return image
def plot_double_cells(arch_dict):
image1 = plot_single_cell(arch_dict, 'normal')
image2 = plot_single_cell(arch_dict, 'reduce')
height_ratio = max(image1.size[1] / image1.size[0], image2.size[1] / image2.size[0])
_, axs = plt.subplots(1, 2, figsize=(20, 10 * height_ratio))
axs[0].imshow(image1)
axs[1].imshow(image2)
axs[0].axis('off')
axs[1].axis('off')
plt.show()
plot_double_cells(exported_arch)

重新训练搜索到的模型
-
我们在上一步得到的只是一个单元(cell)结构。为了得到一个最终可用的带有训练好权重的模型,我们需要基于这个结构构建一个真实的模型,然后对其进行充分的训练。
-
要基于从实验导出的体系结构字典构建固定模型,我们可以使用
nni.retiarii.fixed_arch()。在with-context下,我们会根据创建一个固定的模型exported_arch,而不是创建一个空间。
from nni.retiarii import fixed_arch
with fixed_arch(exported_arch):
final_model = DartsSpace(width=16, num_cells=8, dataset='cifar')
- 打印
final_model框架:
DARTS(
(stem): Sequential(
(0): Conv2d(3, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(stages): ModuleList(
(0): Sequential(
(0): Cell(
(preprocessor): CellPreprocessor(
(pre0): ReLUConvBN(
(0): ReLU()
(1): Conv2d(48, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(pre1): ReLUConvBN(
(0): ReLU()
(1): Conv2d(48, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(ops): ModuleList(
(0): ModuleList(
(0): Identity()
(1): DilConv(
(0): ReLU()
(1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), groups=16, bias=False)
(2): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ModuleList(
(0): SepConv(
(0): ReLU()
(1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=16, bias=False)
(2): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=16, bias=False)
(6): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): AvgPool2d(kernel_size=3, stride=1, padding=1)
)
(2): ModuleList(
(0-1): 2 x DilConv(
(0): ReLU()
(1): Conv2d(16, 16, kernel_size=(5, 5), stride=(1, 1), padding=(4, 4), dilation=(2, 2), groups=16, bias=False)
(2): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): ModuleList(
(0): SepConv(
(0): ReLU()
(1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=16, bias=False)
(2): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=16, bias=False)
(6): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): DilConv(
(0): ReLU()
(1): Conv2d(16, 16, kernel_size=(5, 5), stride=(1, 1), padding=(4, 4), dilation=(2, 2), groups=16, bias=False)
(2): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(inputs): ModuleList(
(0-3): 4 x ModuleList(
(0-1): 2 x ChosenInputs()
)
)
(postprocessor): CellPostprocessor()
)
(1): Cell(
(preprocessor): CellPreprocessor(
(pre0): ReLUConvBN(
(0): ReLU()
(1): Conv2d(48, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(pre1): ReLUConvBN(
(0): ReLU()
(1): Conv2d(64, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(ops): ModuleList(
(0): ModuleList(
(0): Identity()
(1): DilConv(
(0): ReLU()
(1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), groups=16, bias=False)
(2): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ModuleList(
(0): SepConv(
(0): ReLU()
(1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=16, bias=False)
(2): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=16, bias=False)
(6): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): AvgPool2d(kernel_size=3, stride=1, padding=1)
)
(2): ModuleList(
(0-1): 2 x DilConv(
(0): ReLU()
(1): Conv2d(16, 16, kernel_size=(5, 5), stride=(1, 1), padding=(4, 4), dilation=(2, 2), groups=16, bias=False)
(2): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): ModuleList(
(0): SepConv(
(0): ReLU()
(1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=16, bias=False)
(2): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=16, bias=False)
(6): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): DilConv(
(0): ReLU()
(1): Conv2d(16, 16, kernel_size=(5, 5), stride=(1, 1), padding=(4, 4), dilation=(2, 2), groups=16, bias=False)
(2): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(inputs): ModuleList(
(0-3): 4 x ModuleList(
(0-1): 2 x ChosenInputs()
)
)
(postprocessor): CellPostprocessor()
)
)
(1): Sequential(
(0): Cell(
(preprocessor): CellPreprocessor(
(pre0): ReLUConvBN(
(0): ReLU()
(1): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(pre1): ReLUConvBN(
(0): ReLU()
(1): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(ops): ModuleList(
(0): ModuleList(
(0): DilConv(
(0): ReLU()
(1): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(2, 2), dilation=(2, 2), groups=32, bias=False)
(2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
(1): ModuleList(
(0-1): 2 x SepConv(
(0): ReLU()
(1): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=32, bias=False)
(2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(6): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): ModuleList(
(0): DilConv(
(0): ReLU()
(1): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(2, 2), dilation=(2, 2), groups=32, bias=False)
(2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): DilConv(
(0): ReLU()
(1): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(4, 4), dilation=(2, 2), groups=32, bias=False)
(2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): ModuleList(
(0): SepConv(
(0): ReLU()
(1): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=32, bias=False)
(2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=32, bias=False)
(6): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): SepConv(
(0): ReLU()
(1): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=32, bias=False)
(2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(6): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(inputs): ModuleList(
(0-3): 4 x ModuleList(
(0-1): 2 x ChosenInputs()
)
)
(postprocessor): CellPostprocessor()
)
(1): Cell(
(preprocessor): CellPreprocessor(
(pre0): FactorizedReduce(
(relu): ReLU()
(conv_1): Conv2d(64, 16, kernel_size=(1, 1), stride=(2, 2), bias=False)
(conv_2): Conv2d(64, 16, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pad): ConstantPad2d(padding=(0, 1, 0, 1), value=0)
)
(pre1): ReLUConvBN(
(0): ReLU()
(1): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(ops): ModuleList(
(0): ModuleList(
(0): Identity()
(1): DilConv(
(0): ReLU()
(1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), groups=32, bias=False)
(2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ModuleList(
(0): SepConv(
(0): ReLU()
(1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(6): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): AvgPool2d(kernel_size=3, stride=1, padding=1)
)
(2): ModuleList(
(0-1): 2 x DilConv(
(0): ReLU()
(1): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(4, 4), dilation=(2, 2), groups=32, bias=False)
(2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): ModuleList(
(0): SepConv(
(0): ReLU()
(1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(6): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): DilConv(
(0): ReLU()
(1): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(4, 4), dilation=(2, 2), groups=32, bias=False)
(2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(inputs): ModuleList(
(0-3): 4 x ModuleList(
(0-1): 2 x ChosenInputs()
)
)
(postprocessor): CellPostprocessor()
)
(2): Cell(
(preprocessor): CellPreprocessor(
(pre0): ReLUConvBN(
(0): ReLU()
(1): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(pre1): ReLUConvBN(
(0): ReLU()
(1): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(ops): ModuleList(
(0): ModuleList(
(0): Identity()
(1): DilConv(
(0): ReLU()
(1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), groups=32, bias=False)
(2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ModuleList(
(0): SepConv(
(0): ReLU()
(1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(6): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): AvgPool2d(kernel_size=3, stride=1, padding=1)
)
(2): ModuleList(
(0-1): 2 x DilConv(
(0): ReLU()
(1): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(4, 4), dilation=(2, 2), groups=32, bias=False)
(2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): ModuleList(
(0): SepConv(
(0): ReLU()
(1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(6): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): DilConv(
(0): ReLU()
(1): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(4, 4), dilation=(2, 2), groups=32, bias=False)
(2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(inputs): ModuleList(
(0-3): 4 x ModuleList(
(0-1): 2 x ChosenInputs()
)
)
(postprocessor): CellPostprocessor()
)
)
(2): Sequential(
(0): Cell(
(preprocessor): CellPreprocessor(
(pre0): ReLUConvBN(
(0): ReLU()
(1): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(pre1): ReLUConvBN(
(0): ReLU()
(1): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(ops): ModuleList(
(0): ModuleList(
(0): DilConv(
(0): ReLU()
(1): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(2, 2), dilation=(2, 2), groups=64, bias=False)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
(1): ModuleList(
(0-1): 2 x SepConv(
(0): ReLU()
(1): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=64, bias=False)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(6): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): ModuleList(
(0): DilConv(
(0): ReLU()
(1): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(2, 2), dilation=(2, 2), groups=64, bias=False)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): DilConv(
(0): ReLU()
(1): Conv2d(64, 64, kernel_size=(5, 5), stride=(1, 1), padding=(4, 4), dilation=(2, 2), groups=64, bias=False)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): ModuleList(
(0): SepConv(
(0): ReLU()
(1): Conv2d(64, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=64, bias=False)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(64, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=64, bias=False)
(6): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): SepConv(
(0): ReLU()
(1): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=64, bias=False)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(6): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(inputs): ModuleList(
(0-3): 4 x ModuleList(
(0-1): 2 x ChosenInputs()
)
)
(postprocessor): CellPostprocessor()
)
(1): Cell(
(preprocessor): CellPreprocessor(
(pre0): FactorizedReduce(
(relu): ReLU()
(conv_1): Conv2d(128, 32, kernel_size=(1, 1), stride=(2, 2), bias=False)
(conv_2): Conv2d(128, 32, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pad): ConstantPad2d(padding=(0, 1, 0, 1), value=0)
)
(pre1): ReLUConvBN(
(0): ReLU()
(1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(ops): ModuleList(
(0): ModuleList(
(0): Identity()
(1): DilConv(
(0): ReLU()
(1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), groups=64, bias=False)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ModuleList(
(0): SepConv(
(0): ReLU()
(1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(6): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): AvgPool2d(kernel_size=3, stride=1, padding=1)
)
(2): ModuleList(
(0-1): 2 x DilConv(
(0): ReLU()
(1): Conv2d(64, 64, kernel_size=(5, 5), stride=(1, 1), padding=(4, 4), dilation=(2, 2), groups=64, bias=False)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): ModuleList(
(0): SepConv(
(0): ReLU()
(1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(6): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): DilConv(
(0): ReLU()
(1): Conv2d(64, 64, kernel_size=(5, 5), stride=(1, 1), padding=(4, 4), dilation=(2, 2), groups=64, bias=False)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(inputs): ModuleList(
(0-3): 4 x ModuleList(
(0-1): 2 x ChosenInputs()
)
)
(postprocessor): CellPostprocessor()
)
(2): Cell(
(preprocessor): CellPreprocessor(
(pre0): ReLUConvBN(
(0): ReLU()
(1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(pre1): ReLUConvBN(
(0): ReLU()
(1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(ops): ModuleList(
(0): ModuleList(
(0): Identity()
(1): DilConv(
(0): ReLU()
(1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), groups=64, bias=False)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ModuleList(
(0): SepConv(
(0): ReLU()
(1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(6): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): AvgPool2d(kernel_size=3, stride=1, padding=1)
)
(2): ModuleList(
(0-1): 2 x DilConv(
(0): ReLU()
(1): Conv2d(64, 64, kernel_size=(5, 5), stride=(1, 1), padding=(4, 4), dilation=(2, 2), groups=64, bias=False)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): ModuleList(
(0): SepConv(
(0): ReLU()
(1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(6): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): DilConv(
(0): ReLU()
(1): Conv2d(64, 64, kernel_size=(5, 5), stride=(1, 1), padding=(4, 4), dilation=(2, 2), groups=64, bias=False)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(inputs): ModuleList(
(0-3): 4 x ModuleList(
(0-1): 2 x ChosenInputs()
)
)
(postprocessor): CellPostprocessor()
)
)
)
(global_pooling): AdaptiveAvgPool2d(output_size=(1, 1))
(classifier): Linear(in_features=256, out_features=10, bias=True)
)
- 然后我们在完整的 CIFAR-10 训练数据集上训练模型,并在原始 CIFAR-10 验证数据集上对其进行评估。
train_loader = DataLoader(train_data, batch_size=96, num_workers=6) # Use the original training data
- 我们必须在这里创建一个新的评估器,因为使用了不同的数据拆分。
ax_epochs = 100
evaluator = Classification(
learning_rate=1e-3,
weight_decay=1e-4,
train_dataloaders=train_loader,
val_dataloaders=valid_loader,
max_epochs=max_epochs,
gpus=1,
export_onnx=False,
fast_dev_run=fast_dev_run
)
evaluator.fit(final_model)