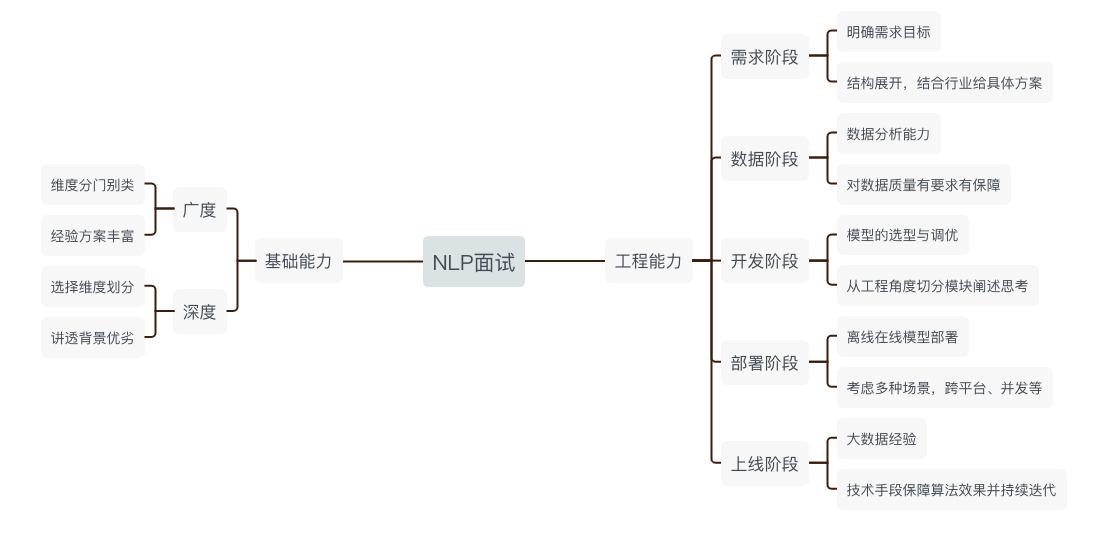
学一门新技术,还是要问那个问题,为什么我们需要这个技术,这个技术能解决什么痛点。
一、为何需要线程池
那么为什么我们需要线程池技术呢?多线程编程用的好好的,干嘛还要引入线程池这个东西呢?引入一个新的技术肯定不是为了装酷,肯定是为了解决某个问题的,而服务端一般都是效率问题。
我们可以看到多线程提高了CPU的使用率和程序的工作效率,但是如果有大量的线程,就会影响性能,因为要大量的创建与销毁,因为CPU需要在它们之间切换。线程池可以想象成一个池子,它的作用就是让每一个线程结束后,并不会销毁,而是放回到线程池中成为空闲状态,等待下一个对象来使用。

二、C++中的线程池
但是让人遗憾的是,C++并没有在语言级别上支持线程池技术,总感觉C++委员会对多线程的支持像是犹抱琵琶半遮面的羞羞女一样,无法完全的放开。
虽然无法从语言级别上支持,但是我们可以利用条件变量和互斥锁自己实现一个线程池。这里就不得不啰嗦几句,条件变量和互斥锁就像两把利剑,几乎可以实现多线程技术中的大部分问题,不管是生产消费者模型,还是线程池,亦或是信号量,所以我们必须好好掌握好这两个工具。
#ifndef _THREADPOOL_H
#define _THREADPOOL_H
#include <vector>
#include <queue>
#include <thread>
#include <iostream>
#include <condition_variable>
using namespace std;
const int MAX_THREADS = 1000; //最大线程数目
template <typename T>
class threadPool
{
public:
threadPool(int number = 1);
~threadPool();
bool append(T *task);
//工作线程需要运行的函数,不断的从任务队列中取出并执行
static void *worker(void *arg);
void run();
private:
//工作线程
vector<thread> workThread;
//任务队列
queue<T *> taskQueue;
mutex mt;
condition_variable condition;
bool stop;
};
template <typename T>
threadPool<T>::threadPool(int number) : stop(false)
{
if (number <= 0 || number > MAX_THREADS)
throw exception();
for (int i = 0; i < number; i++)
{
cout << "create thread:" << i << endl;
workThread.emplace_back(worker, this);
}
}
template <typename T>
inline threadPool<T>::~threadPool()
{
{
unique_lock<mutex> unique(mt);
stop = true;
}
condition.notify_all();
for (auto &wt : workThread)
wt.join();
}
template <typename T>
bool threadPool<T>::append(T *task)
{
//往任务队列添加任务的时候,要加锁,因为这是线程池,肯定有很多线程
unique_lock<mutex> unique(mt);
taskQueue.push(task);
unique.unlock();
//任务添加完之后,通知阻塞线程过来消费任务,有点像生产消费者模型
condition.notify_one();
return true;
}
template <typename T>
void *threadPool<T>::worker(void *arg)
{
threadPool *pool = (threadPool *)arg;
pool->run();
return pool;
}
template <typename T>
void threadPool<T>::run()
{
while (!stop)
{
unique_lock<mutex> unique(this->mt);
//如果任务队列为空,就停下来等待唤醒,等待另一个线程发来的唤醒请求
while (this->taskQueue.empty())
this->condition.wait(unique);
T *task = this->taskQueue.front();
this->taskQueue.pop();
if (task)
task->process();
}
}
#endif
三、线程池代码解析
- 对于线程池ThreadPool,必须要有构造和析构函数,构造函数中,创建N个线程(这个自己指定),插入到工作线程当中,工作线程可以是vector结构。工作线程中的线程具体要做什么呢?进入线程的时候必要用unique_lock进程加锁处理,不能让其他线程以及主线程影响到要处理的这个线程。判断任务队列是否为空,如果为空,则利用条件变量中的wait函数来阻塞该线程,等待任务队列不为空之后唤醒它。然后取出任务队列中的任务,执行任务中的具体操作。
- 接着将任务放入任务队列taskQueue,这里的任务是外部根据自己的业务自己定义的,可以是对象,可以是函数,结构体等等,而任务队列这里定义为queue结构,一定要记得将任务放入任务队列的时候,要在之前加锁,放入之后再解锁,这里的加锁解锁可以用unique_lock结构,当然也可以用mutex结构,而放入任务队列之后就可以用条件变量的notify_one函数通知阻塞的线程来取任务处理了。
- 看过我之前写的《生产消费者模型之条件变量》的朋友对以上代码有点熟悉,没错,线程池的实现就有点像是生产消费者模型,append()就像是生产者,不断的将任务放入队列,run()函数就像消费者,不断的从任务队列中取出任务来处理,生产消费的两头分别用notify_one()和wait()来唤醒和阻塞。更加详细的介绍可以去看我的上一篇文章。
- 最后写一个main文件来调用线程池的相关接口,main文件里定义一个任务对象,然后是main函数。
#include "threadPool.h"
#include <string>
using namespace std;
class Task
{
private:
int total = 0;
public:
void process();
};
//任务具体实现什么功能,由这个函数实现
void Task::process()
{
//这里就输出一个字符串
cout << "task successful! " << endl;
this_thread::sleep_for(chrono::seconds(1));
}
template class std::queue<Task>;
int main(void)
{
threadPool<Task> pool(1);
std::string str;
while (1)
{
Task *task = new Task();
pool.append(task);
delete task;
}
}以上就是线程池的实现部分,充分利用条件变量和互斥锁来实现,模型可以参考生产消费者模型。以上代码部分来自网络,根据自己的需求更改一些。