XML在以后更多的是用来作为配置文件的。
一. 配置文件
什么是配置文件
- 用来保存程序在运行时需要的一些参数。



- 当配置信息比较复杂的时候,我们就可以用XML。
 二. XML概述
二. XML概述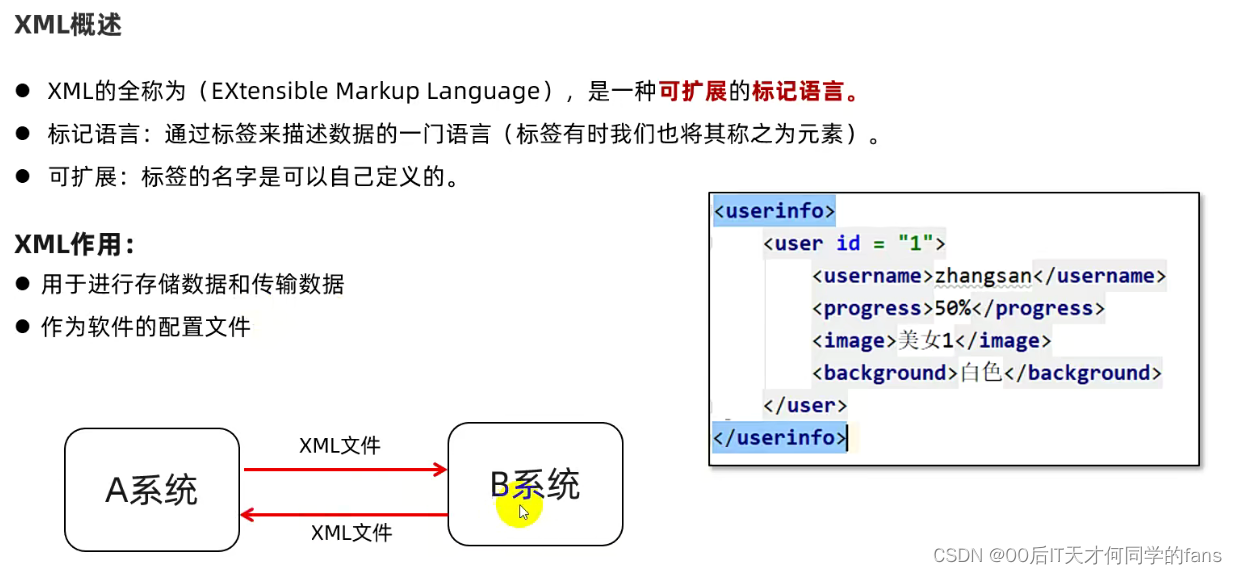



三. XML的创建、语法规则


- 根标签就是写在最外面的标签。


<?xml version="1.0" encoding="UTF-8" ?>
<student>
<!-- 下面表示第一个学生的信息-->
<studnet id = "1">
<name>1<2</name>
<age><![CDATA[<<<<<< >>>>>> &&&& '''' """"]]></age>
</studnet>
</student>

四. XML文档约束
- XML文件可以作为软件的配置文件,软件刚开始运行的时候第一步要去读取并解析XML文件里面的内容,所以XML文件的编写方式要按照软件规定的格式 / 要求来进行书写,否则软件无法解析!
- 软件所规定的要求 / 格式专业用语就叫文档约束。约束本身也是一个文件。

4.1 XML文档约束方式一-DTD约束[了解]




4.2 XML文档约束方式二-schema约束[了解]
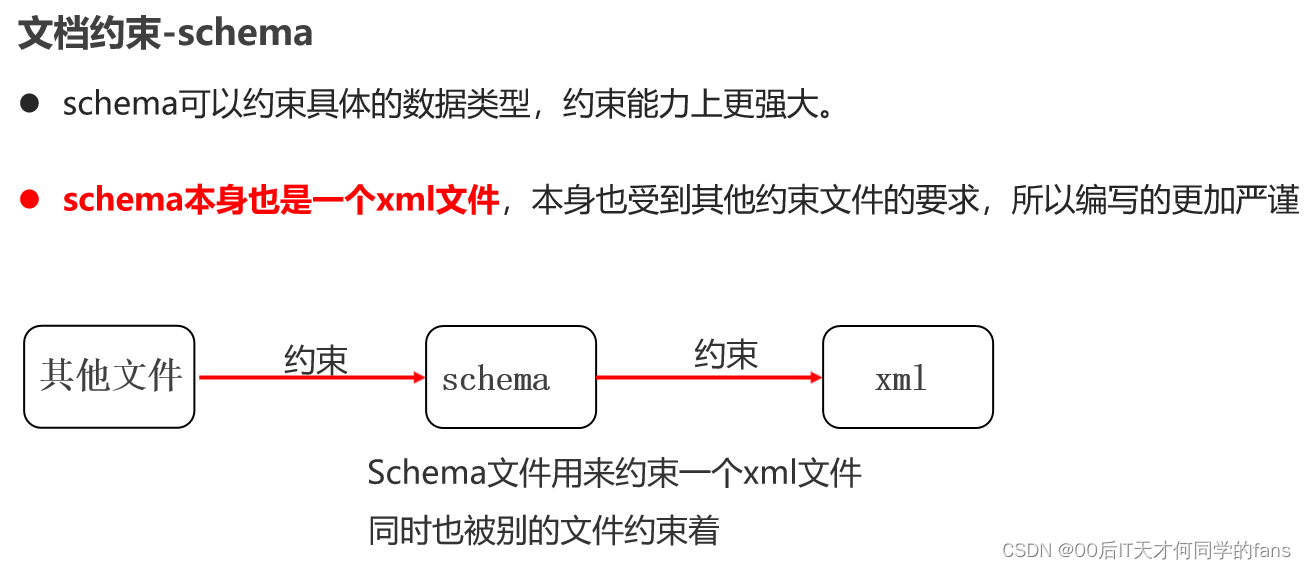


- 什么是复杂的标签?就是标签里面还可以有标签。
- sequence表示这个里面所有的标签必须按照顺序来书写。
简单的引入方式:
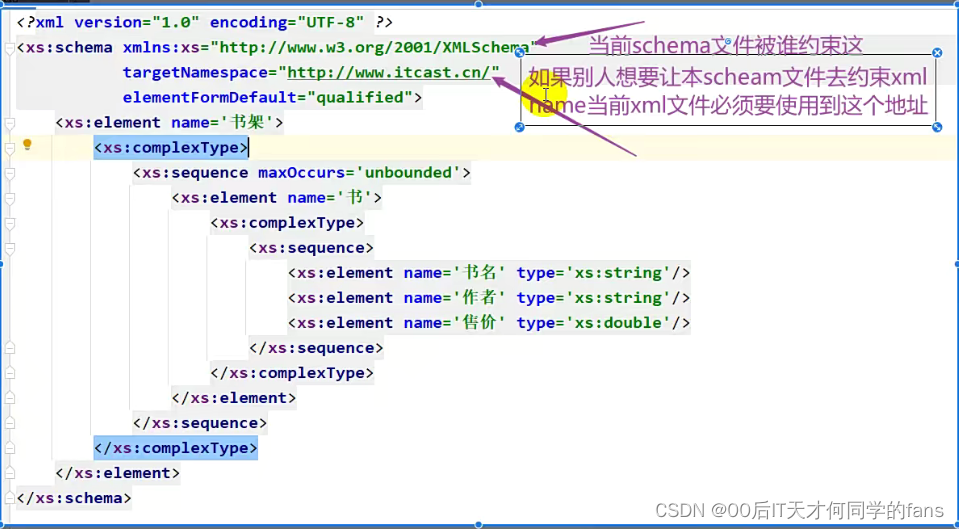
复杂的引入方式:


五. XML解析技术

5.1 XML解析技术概述
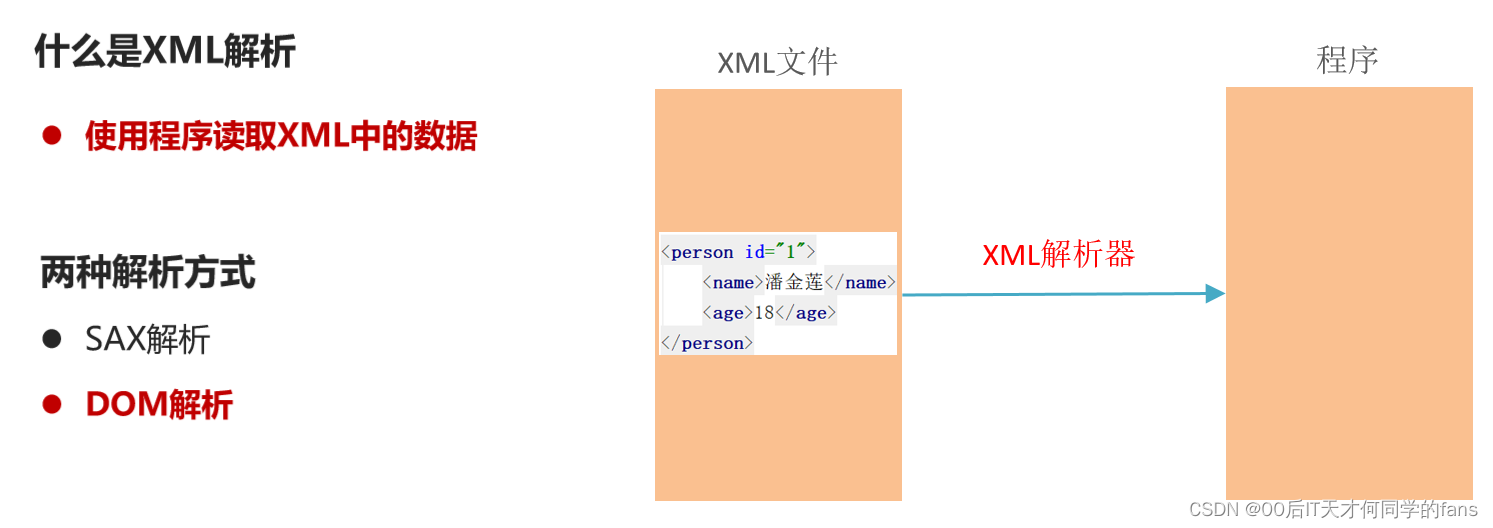
在我们的XML文件当中,不管是删除还是添加,都要通过它的父节点,也就是父元素去操作。

- DOM的缺点在我们现在的硬件当中可以是忽略不计的,因为现在我们的内存都非常地大。

- 在我们整个XML文件当中,所有的内容都可以认为是节点。
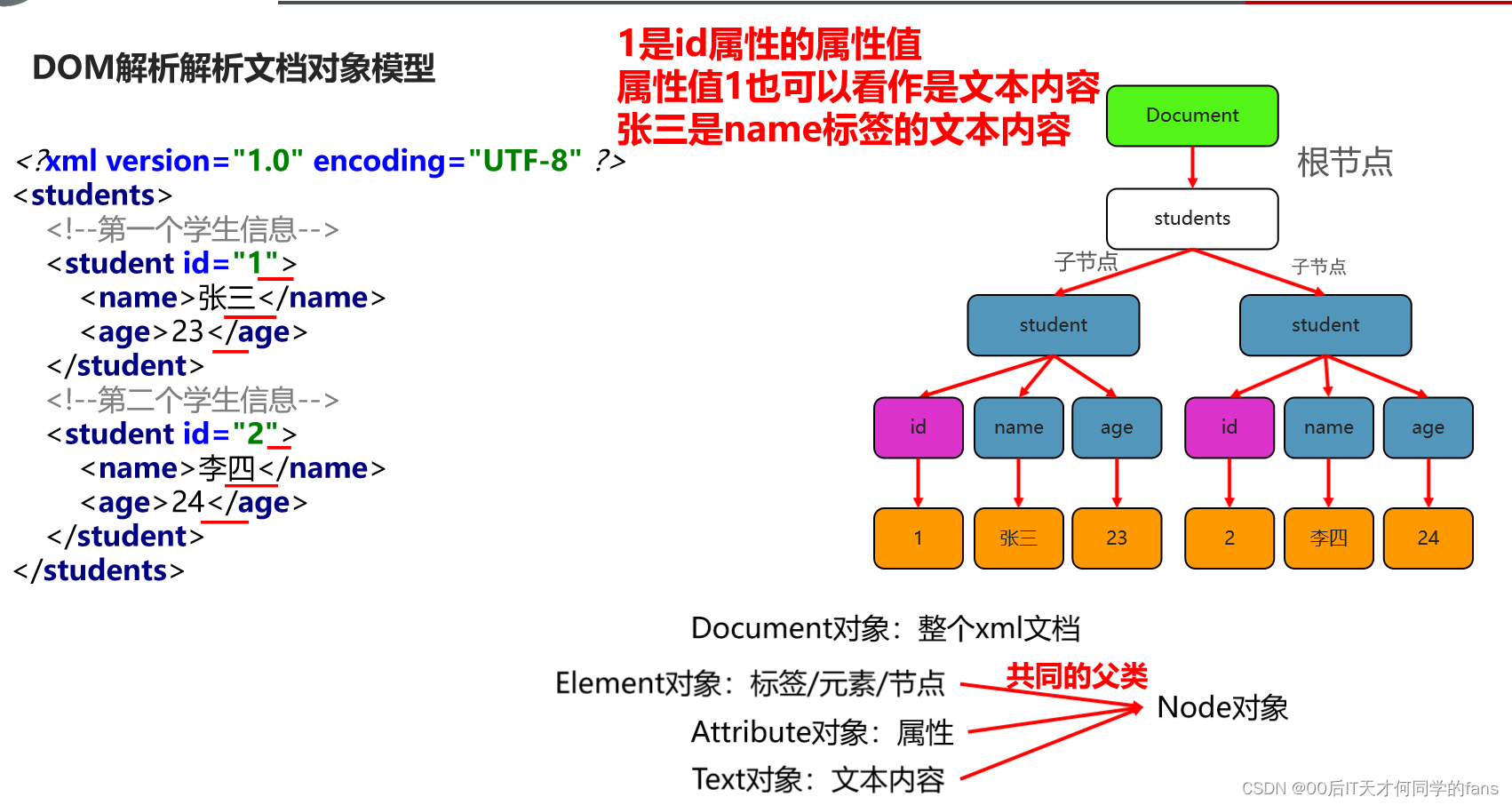

5.2 Dom4J解析XML文件


5.3 Dom4J解析XML文件中的各种节点
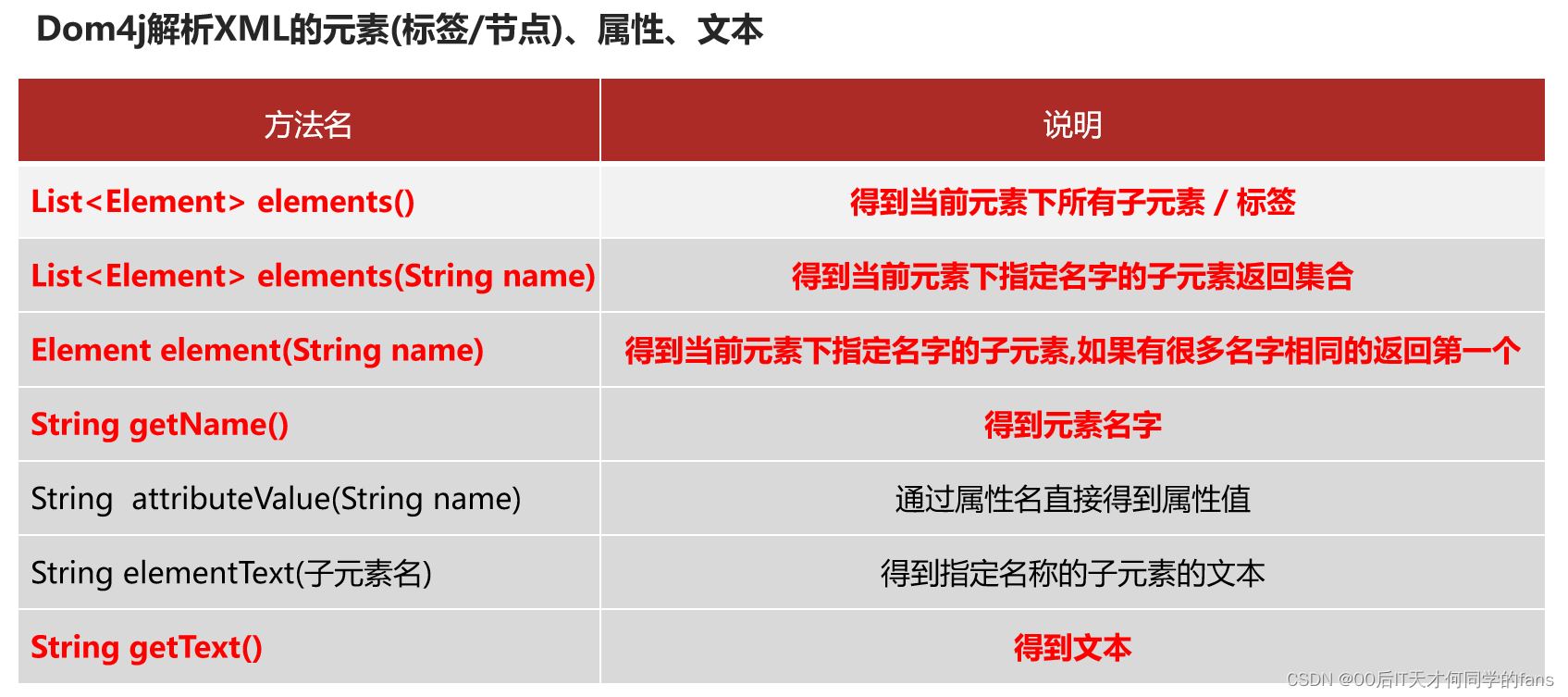
Dom4J获取文档对象并解析XML:
<?xml version="1.0" encoding="UTF-8" ?>
<persons>
<person id = "1">
<name>zhangsan</name>
<age>23</age>
</person>
<person id = "2">
<name>lisi</name>
<age>24</age>
</person>
<person id = "3">
<name>wangwu</name>
<age>25</age>
</person>
<a></a>
</persons>package com.dom4j;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
public class Dom4jDemo {
public static List<Person> list = new ArrayList<>();
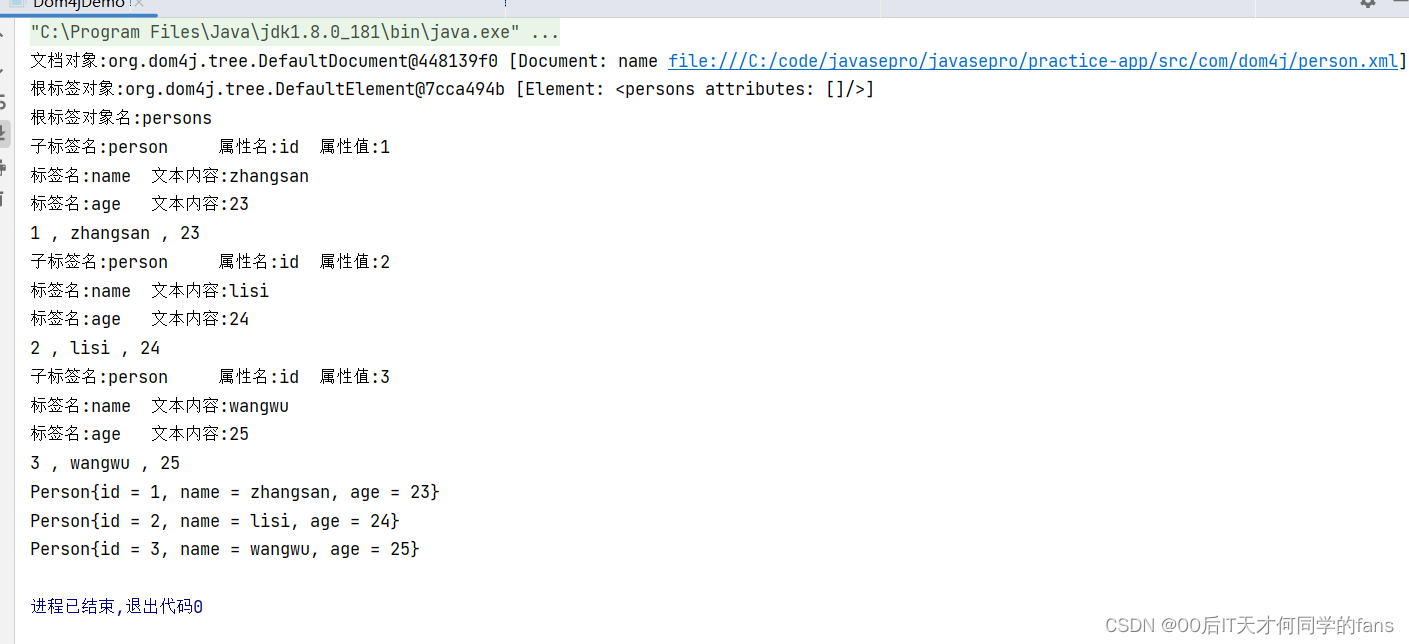
public static void main(String[] args) throws DocumentException {
// 1.创建解析器对象
SAXReader saxReader = new SAXReader();
// 2.利用解析器去读取xml文件,并返回文档对象
File file = new File("practice-app\\src\\com\\dom4j\\person.xml");
Document document = saxReader.read(file);
// 拿到了document表示我已经拿到了xml文件的整体
// 3.打印文档对象
System.out.println("文档对象:" + document);
// 4.自己解析的时候一定要一层一层的去解析
// 5.获取根元素 / 根标签对象
Element rootElement = document.getRootElement();
System.out.println("根标签对象:" + rootElement);
String rootElementName = rootElement.getName();
System.out.println("根标签对象名:" + rootElementName); // 根标签对象名:persons
// 6.获取当前根标签下所有的子标签
/*List<Element> elements = rootElement.elements();
for (Element element : elements) {
System.out.println(element.getName());
}*/
// 7.获取当前根标签下指定名字的子标签返回集合
List<Element> elements = rootElement.elements("person");
for (Element element : elements) {
// 7.继续获取子标签里面的内容
// 获取指定属性的对象
Attribute id = element.attribute("id");
// 获取该属性的属性名
String idName = id.getName();
// 获取该属性的文本内容 / 属性值
String idValue = id.getText();
System.out.println("子标签名:" + element.getName() + " 属性名:" + idName + " 属性值:" + idValue);
// name标签
Element name = element.element("name");
// 获取name标签的文本内容
String nameValue = name.getText();
System.out.println("标签名:" + name.getName() + " 文本内容:" + nameValue);
// age标签
Element age = element.element("age");
// 获取age标签的文本内容
String ageValue = age.getText();
System.out.println("标签名:" + age.getName() + " 文本内容:" + ageValue);
System.out.println(idValue + " , " + nameValue + " , " + ageValue);
// 创建Person对象
Person p = new Person(idValue, nameValue, Integer.valueOf(ageValue));
// 把Person对象添加到集合当中去
list.add(p);
}
// 打印输出list集合
// System.out.println(list);
// 使用Stream流的方式进行打印
list.stream().forEach(s -> System.out.println(s));
}
}
package com.dom4j;
public class Person {
private String id;
private String name;
private int age;
public Person() {
}
public Person(String id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
/**
* 获取
* @return id
*/
public String getId() {
return id;
}
/**
* 设置
* @param id
*/
public void setId(String id) {
this.id = id;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person{id = " + id + ", name = " + name + ", age = " + age + "}";
}
}

5.4 Dom4J解析XML文件-案例实战
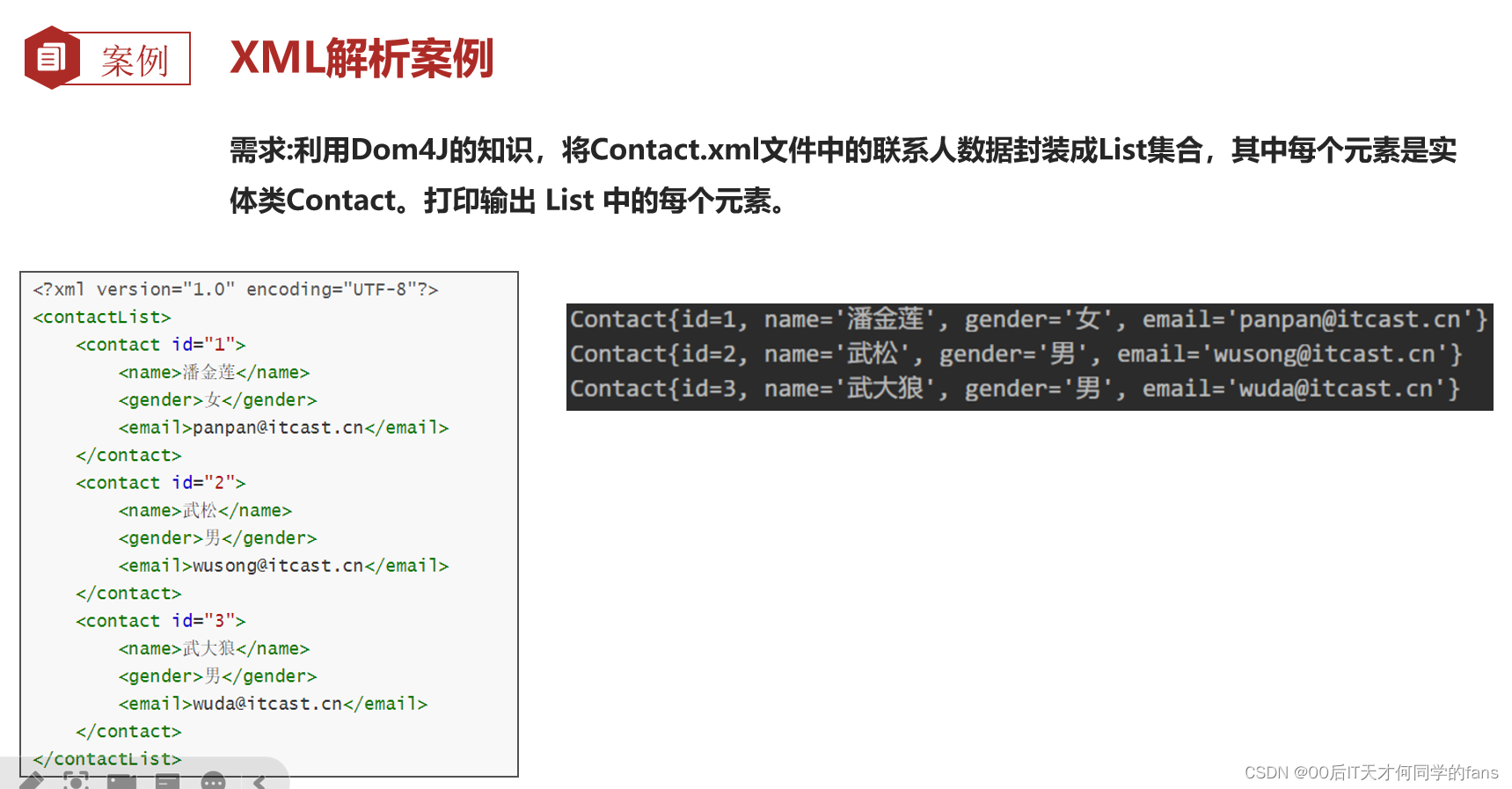 解析XML文件并登录:
解析XML文件并登录:
<?xml version="1.0" encoding="UTF-8" ?>
<users>
<user id = "1">
<username>zhangsan</username>
<password>123</password>
<!--身份证号码-->
<personid>12794372194721124135281</personid>
<phoneid>12746821789412</phoneid>
<!--权限,是否为管理员-->
<admin>true</admin>
</user>
<user id = "2">
<username>lisi</username>
<password>123</password>
<personid>127371293472194147410183</personid>
<phoneid>12269846128941</phoneid>
<admin>false</admin>
</user>
</users>package com.dom4j;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
/**
Document表示整个文档对象
Element表示标签 / 元素 / 节点
Attribute表示属性
Text表示文本
Element、Attribute、Text共同的父类:Node(节点)
每一个标签、属性、文本都可以看作是一个节点
*/
public class Dom4jDemo2 {
// 创建List集合存储从XML文件当中解析出来的用户对象信息
public static List<User> list = new ArrayList<>();
public static void main(String[] args) throws DocumentException {
// 1.创建一个解析器对象
SAXReader saxReader = new SAXReader();
// 2.利用解析器去获取xml文件,获得一个文档对象
File file = new File("practice-app\\src\\com\\dom4j\\user.xml");
Document document = saxReader.read(file);
// 思想:从外面开始一层一层的扒开(脱衣服)
// 3.获取根标签
Element rootElement = document.getRootElement();
System.out.println("根标签名:" + rootElement.getName()); // 根标签名:users
// 4.进入根标签,获取里面的user标签
List<Element> elements = rootElement.elements("user");
System.out.println("user标签个数:" + elements.size()); // user标签个数:2
// 5.遍历集合得到每一个usre标签
for (Element element : elements) {
// 6.获取user标签的属性id
Attribute id = element.attribute("id");
// 获取该属性id的属性名
String idName = id.getName();
// 获取该属性id的属性值 / 文本内容
String idValue = id.getText();
// 获取用户名标签
Element username = element.element("username");
// 获取该标签的文本内容
String usernameValue = username.getText();
// 获取密码标签
Element password = element.element("password");
// 获取密码标签的文本内容
String passwordValue = password.getText();
// 获取personid标签
Element personid = element.element("personid");
// 获取该标签的文本内容
String personidValue = personid.getText();
// 获取phoneid
Element phoneid = element.element("phoneid");
// 获取该标签的文本内容
String phoneidValue = phoneid.getText();
// 获取权限admin,是否为管理员
Element admin = element.element("admin");
// 获取该标签的文本内容
String adminValue = admin.getText();
// 创建User对象
User u = new User(usernameValue, passwordValue,
personidValue, phoneidValue, Boolean.valueOf(adminValue));
// 把User对象添加到集合中去
list.add(u);
}
// 利用Stream流打印输出list集合
list.stream().forEach(s -> System.out.println(s));
// 登录操作
Scanner sc = new Scanner(System.in);
System.out.println("请输入用户名:");
String username = sc.nextLine();
System.out.println("请输入密码:");
String password = sc.nextLine();
// 1.判断用户名是否存在,如果不存在提示用户名未注册
int index = getIndex(list, username);
if(index == -1){
System.out.println("该用户名未注册");
}else{
// 表示存在
User user = list.get(index);
if(user.getPassword().equals(password)){
System.out.println("登录成功!");
}else{
System.out.println("密码错误,登录失败!");
}
}
}
/**
* 查询username在List集合当中的索引
* @param list:存储User对象的集合
* @param username:传进来的用户名
* @return:如果存在返回索引,如果不存在返回-1
*/
public static int getIndex(List<User> list, String username){
for (int i = 0; i < list.size(); i++) {
User user = list.get(i);
if(user.getUsername().equals(username)){
return i;
}
}
return -1;
}
}


六. XML检索技术:Xpath
Xpath技术可以快速的获取XML文件当中的某一个值




<?xml version="1.0" encoding="UTF-8" ?>
<persons>
<person id = "1">
<name>zhangsan</name>
<age>23</age>
</person>
<person id = "2">
<name>lisi</name>
<age>24</age>
</person>
<person id = "3">
<name>wangwu</name>
<age>25</age>
</person>
</persons> 1.绝对路径检索
package com.xpath;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.File;
/**
利用Xpath技术检索XML文件
*/
public class XpathDemo {
public static void main(String[] args) throws DocumentException {
// 1.需要创建解析器对象
SAXReader saxReader = new SAXReader();
// 2.利用解析器对象去读取本地的xml文件,获得一个文档对象
File file = new File("practice-app\\src\\com\\xpath\\person.xml");
Document document = saxReader.read(file);
// 3.获取到一个文档对象,然后就可以利用xpath方式来进行快速检索
// 两个方法:
// 1.检索单个 document.selectSingleNode("路径表达式")
// 2.检索多个 document.selectNodes("路径表达式")
// 1.绝对路径检索:从根节点开始逐层的查找
// 不能写成 \ 符号,\符号在Java当中我们叫做转义字符
/*List<Node> list = document.selectNodes("/persons/person/name");
System.out.println(list.size()); // 3
for (Node node : list) {
System.out.println("标签名:" + node.getName() + " 文本内容:" + node.getText());
}*/
// 检索单个
Element element = (Element) document.selectSingleNode("/persons/person/name");
System.out.println("标签名:" + element.getName() + " 文本内容:" + element.getText());
}
}
2. 相对路径检索

package com.xpath;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.List;
/**
利用Xpath技术检索XML文件
*/
public class XpathDemo2 {
public static void main(String[] args) throws DocumentException {
// 1.需要创建解析器对象
SAXReader saxReader = new SAXReader();
// 2.利用解析器对象去读取本地的xml文件,获得一个文档对象
Document document = saxReader.read(new File("practice-app\\src\\com\\xpath\\person.xml"));
// 3.获取到一个文档对象,然后就可以利用xpath方式来进行快速检索
// 两个方法:
// 1.检索单个 document.selectSingleNode("路径表达式")
// 2.检索多个 document.selectNodes("路径表达式")
// 利用相对路径进行检索
// 相对路径它是有一个参照物,参照物:自己本身
Element rootElement = document.getRootElement();
// 相对于自己去往下查找
// 检索单个
// Element element = (Element) rootElement.selectSingleNode("./person/age");
// 检索所有
List<Node> list = rootElement.selectNodes("./person/age");
for (Node node : list) {
System.out.println(node.getText());
}
// System.out.println("标签名:" + element.getName() + " 文本内容:" + element.getText());
}
}

3. 全文检索

package com.xpath;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.List;
/**
利用Xpath技术检索XML文件
*/
public class XpathDemo3 {
public static void main(String[] args) throws DocumentException {
// 1.需要创建解析器对象
SAXReader saxReader = new SAXReader();
// 2.利用解析器对象去读取本地的xml文件,获得一个文档对象
Document document = saxReader.read(new File("practice-app\\src\\com\\xpath\\person.xml"));
// 3.获取到一个文档对象,然后就可以利用xpath方式来进行快速检索
// 两个方法:
// 1.检索单个 document.selectSingleNode("路径表达式")
// 2.检索多个 document.selectNodes("路径表达式")
// 总结:
// 路径里面如果只有一个/表示单级的路径
// 路径里面如果有//表示,单级的可以,多级的也可以
// 全文检索
// 1.//contact 找contact元素,无论元素在哪里
/* List<Node> list = document.selectNodes("//name");
System.out.println(list.size()); // 4
for (Node node : list) {
System.out.println(node.getText());
}*/
// 2.//contact/name 找contact,无论在哪一级,但name一定是contact的子节点
// List<Node> list = document.selectNodes("//person/name");
// for (Node node : list) {
// System.out.println(node.getName());
// }
// 3.//contact//name contact无论在哪一种,name只要是contact的子孙元素都可以找到
List<Node> list = document.selectNodes("//person//name");
System.out.println(list.size());
}
}
4. 属性检索

package com.xpath;
import org.dom4j.*;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.List;
/**
利用Xpath技术检索XML文件
*/
public class XpathDemo4 {
public static void main(String[] args) throws DocumentException {
// 1.需要创建解析器对象
SAXReader saxReader = new SAXReader();
// 2.利用解析器对象去读取本地的xml文件,获得一个文档对象
Document document = saxReader.read(new File("practice-app\\src\\com\\xpath\\person.xml"));
// 3.获取到一个文档对象,然后就可以利用xpath方式来进行快速检索
// 两个方法:
// 1.检索单个 document.selectSingleNode("路径表达式")
// 2.检索多个 document.selectNodes("路径表达式")
// 属性查找
// 查找属性和带属性查找
// 1.//@属性名:查属性
// List<Node> list = document.selectNodes("//@id");
// System.out.println(list.size()); // 3
// for (Node node : list) {
// System.out.println(node.getText());
// }
// 2.//元素[@属性名]:查的是带有指定属性的标签
/*List<Node> list = document.selectNodes("//person[@name]");
System.out.println(list.size()); // 0
for (Node node : list) {
System.out.println(node.getText());
}*/
List<Node> list1 = document.selectNodes("//person[@id]");
System.out.println(list1.size());
for (Node node : list1) {
// 将父类node节点向下转型为子类Element标签
Element element = (Element) node;
// 获取该标签的标签名
System.out.println(element.getName());
// 获取该标签的id属性
Attribute id = element.attribute("id");
// 获取该标签的属性名以及属性值
System.out.println("标签名:" + element.getName() + " 属性名:" + id.getName() + " 属性值:" + id.getText());
}
System.out.println("===========================================================");
// 3.//元素[@属性名=‘值’]:查的是带有指定属性和属性值的标签
List<Node> list2 = document.selectNodes("//person[@id='1']");
for (Node node : list2) {
// 将父类node节点向下转型为子类Element标签
Element element = (Element) node;
// 获取该标签的标签名
String elementName = element.getName();
// 获取该标签的属性
Attribute id = element.attribute("id");
// 获取该标签的属性名以及属性值
String idName = id.getName();
String idValue = id.getText();
System.out.println("标签名:" + elementName + " 属性名:" + idName + " 属性值:" + idValue);
}
}
}

Xpath的小结:
- Xpath底层依赖于dom4j。在刚开始导包的时候一定要把dom4j的jar包一起导入。
- 有两个检索的方法:
- selectNodes("路径"):查询所有
- selectSingleNode("路径"):查询单个的,如果结果有多个,默认返回第一个。
3. 四种检索方式:
/ :单级路径
// :多级路径
@ 属性
绝对路径:一定是从根节点开始
相对路径:从现在的自己节点开始的。
用根节点调用selectNodes,那么此时就是相对于根节点而言。
用name节点调用selectNodes,那么此时就是相对于name标签而言。
全文检索:只要xml文件中存在就可以找到
//name 在整个xml文件中找name这个标签
扩展用法:
//person/name:先找person,再找person的子标签name。
//person//name:先找person,再找person的子标签name,但是此时 name可以是孙标签。
带属性的查询:
查属性: //@属性名 在全文中找指定的属性
查带有指定属性的标签: //标签名[@属性名]
查带有指定属性值的标签://标签名[@属性名= ' 值 ' ]
细节:如果说在双引号里面我们还要去引用其他的东西,那么这个时候我们就可以用单引号来引 用。