79单词搜索

思路:

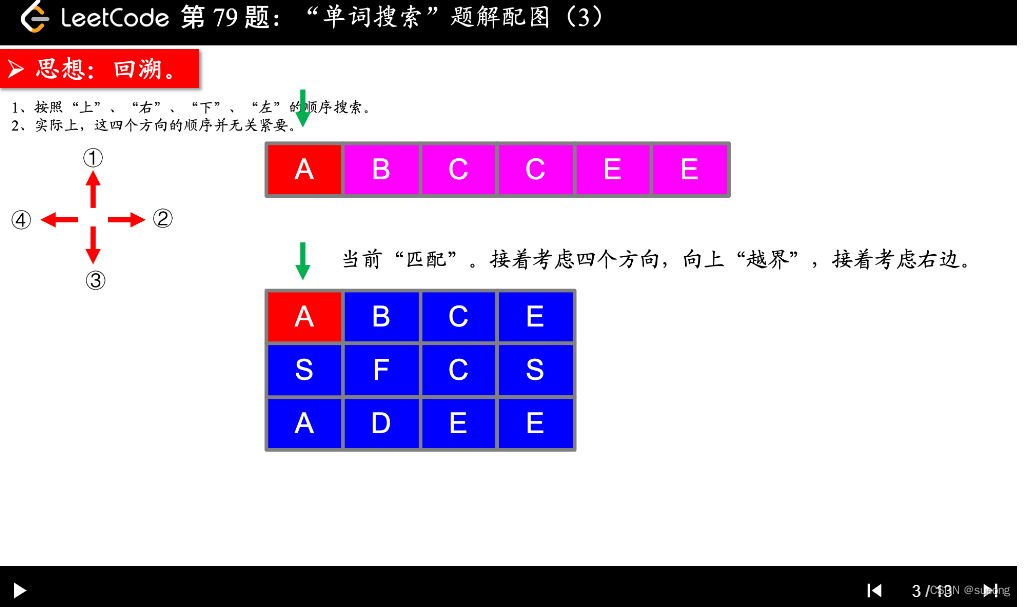
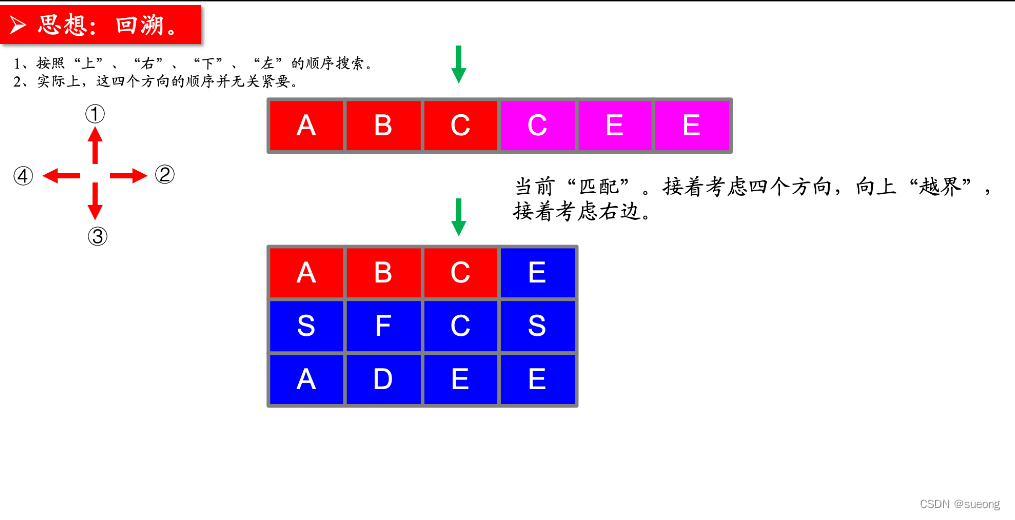



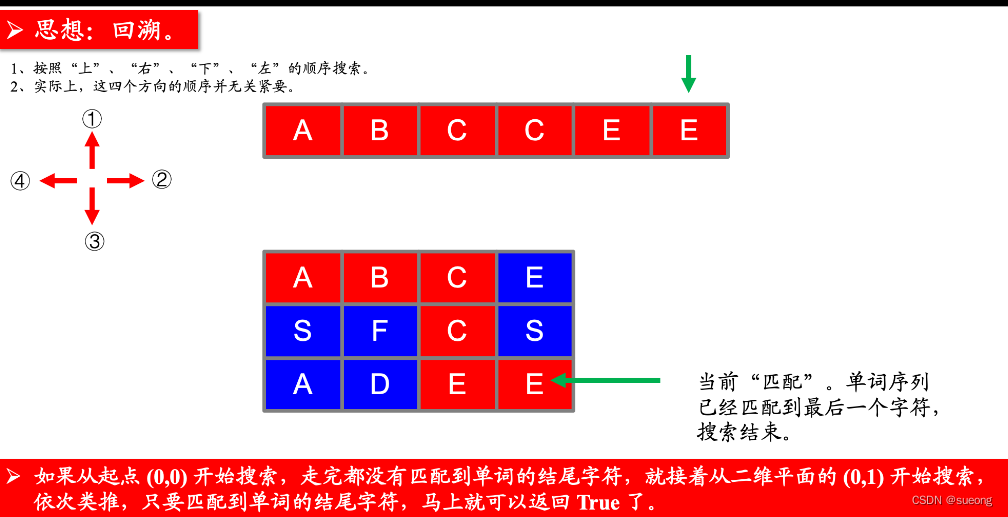
注意:
我自己在写
for i in range(m):
for j in range(n):
# 对每一个格子都从头开始搜索
if self.__search_word(board, word, 0, i, j, marked, m, n):
return True
这一段的时候,就写成了:
这一段代码是错误的,不要模仿
for i in range(m):
for j in range(n):
# 对每一个格子都从头开始搜索
return self.__search_word(board, word, 0, i, j, marked, m, n)
这样其实就变成只从坐标 (0,0) 开始搜索,搜索不到返回 False,但题目的意思是:只要你的搜索返回 True 才返回,如果全部的格子都搜索完了以后,都返回 False ,才返回 False。
class Solution:
directs = [(0,1),(0,-1),(1,0),(-1,0)]
def exist(self, board: List[List[str]], word: str) -> bool:
m = len(board)
if m == 0:
return False
n = len(board[0])
visited = [[0] * n for _ in range(m)]
for i in range (0,m):
for j in range (0,n):
if self.dfs(i, j, 0, board, word, visited):
return True
return False
def dfs(self, x, y, begin, board, word, visited):
# 递归出口,如果遍历的index在word的最后,判断盘上是否和单词最后一个是否一样
if begin == len(word) - 1:
return board[x][y] == word[begin]
if board[x][y] == word[begin]:
# 访问过标记
visited[x][y] = 1
for dire in self.directs:
new_x = x + dire[0]
new_y = y + dire[1]
# 遍历四个方向,且保证不越界且没访问过,接着遍历单词的下一个位置
if 0 <= new_x < len(board) and 0<= new_y < len(board[0]) and visited[new_x][new_y]==0:
if self.dfs(new_x, new_y, begin+1, board, word, visited):
return True
# 回溯
visited[x][y] = 0
return False
class Solution:
directs = [(0,1),(0,-1),(1,0),(-1,0)]
def exist(self, board: List[List[str]], word: str) -> bool:
m = len(board)
if m == 0:
return False
n = len(board[0])
visited = [[0] * n for _ in range(m)]
def dfs(x, y, begin):
# 递归出口,如果遍历的index在word的最后,判断盘上是否和单词最后一个是否一样
if begin == len(word) - 1:
return board[x][y] == word[begin]
if board[x][y] == word[begin]:
# 访问过标记
visited[x][y] = 1
for dire in self.directs:
new_x = x + dire[0]
new_y = y + dire[1]
# 遍历四个方向,且保证不越界且没访问过,接着遍历单词的下一个位置
if 0 <= new_x < len(board) and 0<= new_y < len(board[0]) and visited[new_x][new_y]==0:
if dfs(new_x, new_y, begin+1):
return True
# 回溯
visited[x][y] = 0
return False
for i in range (0,m):
for j in range (0,n):
if dfs(i, j, 0):
return True
return False
208 前缀树

包含三个单词 “sea”,“sells”,“she” 的 Trie 会长啥样呢?

简化后:
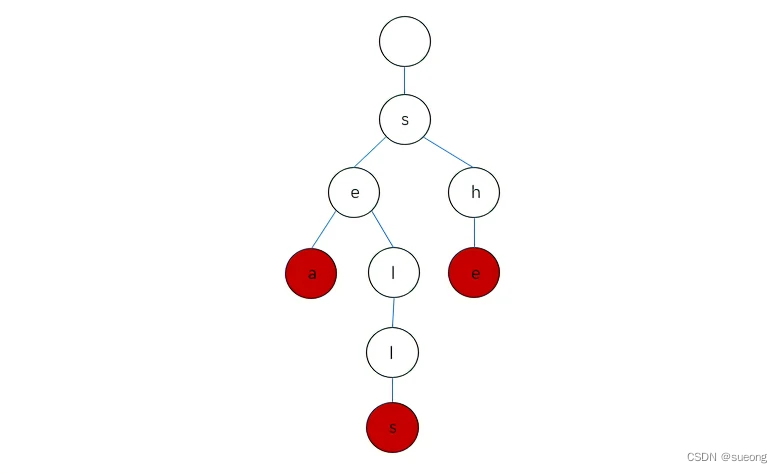
定义类 Trie
class Trie {
private:
bool isEnd;
Trie* next[26];
public:
//方法将在下文实现...
};
插入
描述:向 Trie 中插入一个单词 word
实现:这个操作和构建链表很像。首先从根结点的子结点开始与 word 第一个字符进行匹配,一直匹配到前缀链上没有对应的字符,这时开始不断开辟新的结点,直到插入完 word 的最后一个字符,同时还要将最后一个结点isEnd = true;,表示它是一个单词的末尾。
void insert(string word) {
Trie* node = this;
for (char c : word) {
if (node->next[c-'a'] == NULL) {
node->next[c-'a'] = new Trie();
}
node = node->next[c-'a'];
}
node->isEnd = true;
}
查找
描述:查找 Trie 中是否存在单词 word
实现:从根结点的子结点开始,一直向下匹配即可,如果出现结点值为空就返回 false,如果匹配到了最后一个字符,那我们只需判断 node->isEnd即可。
bool search(string word) {
Trie* node = this;
for (char c : word) {
node = node->next[c - 'a'];
if (node == NULL) {
return false;
}
}
return node->isEnd;
}
前缀匹配
描述:判断 Trie 中是或有以 prefix 为前缀的单词
实现:和 search 操作类似,只是不需要判断最后一个字符结点的isEnd,因为既然能匹配到最后一个字符,那后面一定有单词是以它为前缀的。
bool startsWith(string prefix) {
Trie* node = this;
for (char c : prefix) {
node = node->next[c-'a'];
if (node == NULL) {
return false;
}
}
return true;
}
链接:https://leetcode.cn/problems/implement-trie-prefix-tree/solution/trie-tree-de-shi-xian-gua-he-chu-xue-zhe-by-huwt/
class Trie:
# 根节点不存字母
# next 存了26个字母
def __init__(self):
self.next = [None] * 26
self.isEnd = False
def insert(self, word: str) -> None:
node = self
# 先查找有没有这个字母,没有就新建一个节点,新建后就有该字母的节点,就将树遍历下去
for ch in word:
# 如果ch在树中不存在,就新建一个单词的
if node.next[ord(ch) - ord('a')] == None:
node.next[ord(ch) - ord('a')] = Trie()
node = node.next[ord(ch) - ord('a')]
node.isEnd = True
def search(self, word: str) -> bool:
node = self
for ch in word:
if node.next[ord(ch) - ord('a')] == None:
return False
node = node.next[ord(ch) - ord('a')]
# 遍历到最后 判断是不是单词的结束
return node.isEnd
def startsWith(self, prefix: str) -> bool:
node = self
for ch in prefix:
if node.next[ord(ch) - ord('a')] == None:
return False
node = node.next[ord(ch) - ord('a')]
# 遍历到最后 不需要判断是不是单词的结束 说明存在prefix
return True
# Your Trie object will be instantiated and called as such:
# obj = Trie()
# obj.insert(word)
# param_2 = obj.search(word)
# param_3 = obj.startsWith(prefix)
211. 添加与搜索单词 - 数据结构设计

思路:和208构建字典树类似
只是查询的时候需要对通配符.特殊处理,

class WordDictionary:
def __init__(self):
self.next = [None] * 26
self.isEnd = False
def addWord(self, word: str) -> None:
node = self
for ch in word:
if node.next[ord(ch) - ord("a")] == None:
node.next[ord(ch) - ord("a")] = WordDictionary()
node = node.next[ord(ch) - ord("a")]
node.isEnd = True
def search(self, word: str) -> bool:
root = self
def dfs(index,node):
if index == len(word):
return node.isEnd
ch = word[index]
# 如果ch不是. 看是否存在该字符的节点 如果存在该字符节点 且往后搜索后面的字符 dfs(word下一个字符,树上的下一个节点)
if ch != '.':
child = node.next[ord(ch) - ord("a")]
if child != None and dfs(index+1,child):
return True
# ch 是. ,遍历整个next数组,26个元素,对每个元素都进行dfs
else:
for child in node.next:
if child != None and dfs(index+1,child):
return True
return False
return dfs(0,root)
# Your WordDictionary object will be instantiated and called as such:
# obj = WordDictionary()
# obj.addWord(word)
# param_2 = obj.search(word)
212单词搜索 II

思路:
对棋盘上的每个位置进行dfs,对输入的单词集合构建成字典树,对于棋盘上的任意位置(i,j)只有在字典树存在从字符a到字符b的边的时候,我们才能在棋盘上找到a-b的路径,
注意:
回溯过程,每次只需要判断新增单元格的字母是否是上一个单元格对应前缀树结点的子结点即可。

from collections import defaultdict
class TrieNode:
def __init__(self):
self.children = defaultdict(TrieNode)
#这里要把原来的指针换成map映射 因为要存具体字母的值 如果key不存在也会自动创建再插入不会报错
self.word = ""# 这里把原来的isEnd换成单词串,如果是结尾存的是单词本身
def insert(self, word):
node = self
for ch in word:
node = node.children[ch]
node.word = word
class Solution:
def findWords(self, board: List[List[str]], words: List[str]) -> List[str]:
# 给每个单词建立字典树
trie = TrieNode()
for word in words:
trie.insert(word)
print(trie.children)
print( "b" in trie.children['o'].children)
# defaultdict(<class '__main__.TrieNode'>, {'o': <__main__.TrieNode object at 0x7f518eeae7d0>, 'p': <__main__.TrieNode object at 0x7f518eef51b0>, 'e': <__main__.TrieNode object at 0x7f518eef52d0>, 'r': <__main__.TrieNode object at 0x7f518eef53f0>})
# False
m,n = len(board),len(board[0])
directions = [(0,1),(0,-1),(1,0),(-1,0)]
def dfs(x, y, node):
# 加上也没错 但是运行时间会变长,因为多判断了一次 进入dfs永远不会经过这个 因为最后回溯都会复原 进入的xy也在范维内
# if not( 0<= x < m and 0 <= y < n) or board[x][y]=="#":
# return
# 如果当前位置字符不在字典树当前节点的孩子中,直接返回
ch = board[x][y]
if ch not in node.children:
return
# 获取当前字符对应的子节点
child = node.children[ch]
# 说明是单词结尾,加入结果集
if child.word!="":
res.add(child.word)
# 如果不是单词结尾,标记已访问,探索该点的四个方向,说明应该有孩子节点
if child.children: #!!关键语句 可以使运行时间减半
board[x][y] = '#'
for dire in directions:
new_x = x + dire[0]
new_y = y + dire[1]
# 边界符合且未访问过 dfs(board的新位置,字典树的下一个节点即孩子节)
if 0<= new_x < m and 0 <= new_y < n and board[new_x][new_y]!="#":
dfs(new_x, new_y, child)
# 回溯
board[x][y] = ch
#存储搜索到的单词
res = set()
# 对棋盘上的每个位置都dfs
for i in range(m):
for j in range(n):
dfs(i,j,trie)
return list(res)