前言
项目开发中经常会使用消息队列来完成异步处理、应用解耦、流量控制等功能。虽然消息队列的出现解决了一些场景下的问题,但是同时也引出了一些问题,其中使用消息队列时如何保证消息的可靠性就是一个常见的问题。如果在项目中遇到需要保证消息一定被消费的场景时,如何保证消息不丢失,如何保证消息的可靠性?
最近在写项目时使用 RabbitMQ 消息队列中间件时也遇到了需要保证消息可靠性的场景,所以将如何保持消息可靠性的方案记录下来,下面将讲解一下如何保证 RabbitMQ 的消息可靠性。
如何保证 RabbitMQ 的消息可靠性
先放一张 RabbitMQ 是如何消息传递的图:
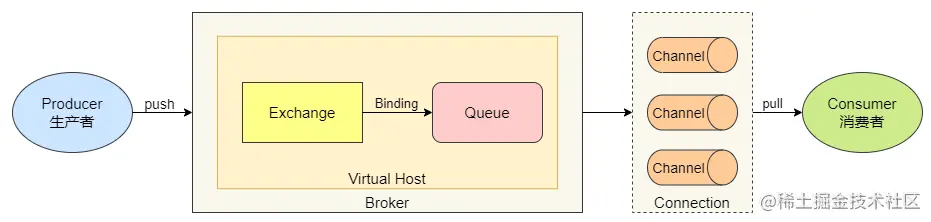
生产者Producer 将消息发送到指定的 交换机Exchange,交换机根据路由规则路由到绑定的 队列Queue 中,最后和消费者建立连接后,将消息推送给 消费者Consumer。
那么消息会在哪些环节丢失呢,列出可能出现消息丢失的场景有:
- 生产者将消息发送到 RabbitMQ Server 异常:可能因为网络问题造成 RabbitMQ 服务端无法收到消息,造成生产者发送消息丢失场景。
- RabbitMQ Server 中消息在交换机中无法路由到指定队列:可能由于代码层面或配置层面错误导致消息路由到指定队列失败,造成生产者发送消息丢失场景。
- RabbitMQ Server 中存储的消息丢失:可能因为 RabbitMQ Server 宕机导致消息未完全持久化或队列丢失导致消息丢失等持久化问题,造成 RabbitMQ Server 存储的消息丢失场景。
- 消费者消费消息异常:可能在消费者接收到消息后,还没来得及消费消息,消费者宕机或故障等问题,造成消费者无法消费消息导致消息丢失的场景。
以上就是 RabbitMQ 可能出现消息丢失的场景,接下来将依次讲解如何避免这些消息丢失的场景问题。
由于在项目开发中使用的是 RabbitMQ,所以使用 Spring Boot 集成的 AMQP 依赖即可使用 RabbitMQ。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
1. 保证生产者发送消息到 RabbitMQ Server
为了避免因为网络故障或闪断问题导致消息无法正常发送到 RabbitMQ Server 的情况,RabbitMQ 提供了两种方案让生产者可以感知到消息是否正确无误的发送到 RabbitMQ Server中,这两种方案分别是 事务机制 和 发送方确认机制。下面分别介绍一下这两种机制如何实现。
事务机制
先说配置和使用:
-
配置类中配置事务管理器
/** * 消息队列配置类 * * @author 单程车票 */ @Configuration public class RabbitMQConfig { /** * 配置事务管理器 */ @Bean public RabbitTransactionManager transactionManager(ConnectionFactory connectionFactory) { return new RabbitTransactionManager(connectionFactory); } } -
通过添加事务注解 + 开启事务实现事务机制
/** * 消息业务实现类 * * @author 单程车票 */ @Service public class RabbitMQServiceImpl { @Autowired private RabbitTemplate rabbitTemplate; @Transactional // 事务注解 public void sendMessage() { // 开启事务 rabbitTemplate.setChannelTransacted(true); // 发送消息 rabbitTemplate.convertAndSend(RabbitMQConfig.Direct_Exchange, routingKey, message); } }
通过上面的配置即可实现事务机制,执行流程为:在生产者发送消息之前,开启事务,而后发送消息,如果消息发送至 RabbitMQ Server 失败后,进行事务回滚,重新发送。如果 RabbitMQ Server 接收到消息,则提交事务。
可以发现事务机制其实是同步操作,存在阻塞生产者的情况直到 RabbitMQ Server 应答,这样其实会很大程度上降低发送消息的性能,所以一般不会使用事务机制来保证生产者的消息可靠性,而是使用发送方确认机制。
发送方确认机制
先说配置和使用:
-
配置文件
spring: rabbitmq: publisher-confirm-type: correlated # 开启发送方确认机制配置属性有三种分别为:
none:表示禁用发送方确认机制correlated:表示开启发送方确认机制simple:表示开启发送方确认机制,并支持waitForConfirms()和waitForConfirmsOrDie()的调用。
这里一般使用
correlated开启发送方确认机制即可,至于simple的waitForConfirms()方法调用是指串行确认方法,即生产者发送消息后,调用该方法等待 RabbitMQ Server 确认,如果返回 false 或超时未返回则进行消息重传。由于串行性能较差,这里一般都是用异步 confirm 模式。 -
通过调用
setConfirmCallback()实现异步 confirm 模式感知消息发送结果/** * 消息业务实现类 * * @author 单程车票 */ @Service public class RabbitMQServiceImpl { @Autowired private RabbitTemplate rabbitTemplate; @Override public void sendMessage() { // 发送消息 rabbitTemplate.convertAndSend(RabbitMQConfig.Direct_Exchange, routingKey, message); // 设置消息确认回调方法 rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() { /** * MQ确认回调方法 * @param correlationData 消息的唯一标识 * @param ack 消息是否成功收到 * @param cause 失败原因 */ @Override public void confirm(CorrelationData correlationData, boolean ack, String cause) { // 记录日志 log.info("ConfirmCallback...correlationData["+correlationData+"]==>ack:["+ack+"]==>cause:["+cause+"]"); if (!ack) { // 出错处理 ... } } }); } }
生产者发送消息后通过调用 setConfirmCallback() 可以将信道设置为 confirm 模式,所有消息会被指派一个消息唯一标识,当消息被发送到 RabbitMQ Server 后,Server 确认消息后生产者会回调设置的方法,从而实现生产者可以感知到消息是否正确无误的投递,从而实现发送方确认机制。并且该模式是异步的,发送消息的吞吐量会得到很大提升。
上面就是发送放确认机制的配置和使用,使用这种机制可以保证生产者的消息可靠性投递,并且性能较好。
2. 保证消息能从交换机路由到指定队列
在确保生产者能将消息投递到交换机的前提下,RabbitMQ 同样提供了消息投递失败的策略配置来确保消息的可靠性,接下来通过配置来介绍一下消息投递失败的策略。
先说配置:
spring:
rabbitmq:
publisher-confirm-type: correlated # 开启发送方确认机制
publisher-returns: true # 开启消息返回
template:
mandatory: true # 消息投递失败返回客户端
mandatory 分为 true 失败后返回客户端 和 false 失败后自动删除两种策略。显然设置为 false 无法保证消息的可靠性。
到这里的配置是可以保证生产者发送消息的可靠性投递。
通过调用 setReturnCallback() 方法设置路由失败后的回调方法:
/**
* 消息业务实现类
*
* @author 单程车票
*/
@Service
public class RabbitMQServiceImpl {
@Autowired
private RabbitTemplate rabbitTemplate;
@Override
public void sendMessage() {
// 发送消息
rabbitTemplate.convertAndSend(RabbitMQConfig.Direct_Exchange, routingKey, message);
// 设置消息确认回调方法
rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() {
/**
* MQ确认回调方法
* @param correlationData 消息的唯一标识
* @param ack 消息是否成功收到
* @param cause 失败原因
*/
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
// 记录日志
log.info("ConfirmCallback...correlationData["+correlationData+"]==>ack:["+ack+"]==>cause:["+cause+"]");
if (!ack) {
// 出错处理
...
}
}
});
// 设置路由失败回调方法
rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() {
/**
* MQ没有将消息投递给指定的队列回调方法
* @param message 投递失败的消息详细信息
* @param replyCode 回复的状态码
* @param replyText 回复的文本内容
* @param exchange 消息发给哪个交换机
* @param routingKey 消息用哪个路邮键
*/
@Override
public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {
// 记录日志
log.info("Fail Message["+message+"]==>replyCode["+replyCode+"]" +"==>replyText["+replyText+"]==>exchange["+exchange+"]==>routingKey["+routingKey+"]");
// 出错处理
...
}
});
}
}
通过调用 setReturnCallback() 方法即可实现当交换机路由到指定队列失败后回调方法,拿到被退回的消息信息,进行相应的处理如记录日志或重传等等。
3. 保证消息在 RabbitMQ Server 中的持久化
对于消息的持久化,只需要在发送消息时将消息持久化,并且在创建交换机和队列时也保证持久化即可。
配置如下:
/**
* 消息队列
*/
@Bean
public Queue queue() {
// 四个参数:name(队列名)、durable(持久化)、 exclusive(独占)、autoDelete(自动删除)
return new Queue(MESSAGE_QUEUE, true);
}
/**
* 直接交换机
*/
@Bean
public DirectExchange exchange() {
// 四个参数:name(交换机名)、durable(持久化)、autoDelete(自动删除)、arguments(额外参数)
return new DirectExchange(Direct_Exchange, true, false);
}
在创建交换机和队列时通过构造方法将持久化的参数都设置为 true 即可实现交换机和队列的持久化。
@Override
public void sendMessage() {
// 构造消息(将消息持久化)
Message message = MessageBuilder.withBody("单程车票".getBytes(StandardCharsets.UTF_8)).setDeliveryMode(MessageDeliveryMode.PERSISTENT).build();
// 向MQ发送消息(消息内容都为消息表记录的id)
rabbitTemplate.convertAndSend(RabbitMQConfig.Direct_Exchange, routingKey, message);
}
在发送消息前通过调用 MessageBuilder 的 setDeliveryMode(MessageDeliveryMode.PERSISTENT) 在构造消息时设置消息持久化(MessageDeliveryMode.PERSISTENT)即可实现对消息的持久化。
通过确保消息、交换机、队列的持久化操作可以保证消息的在 RabbitMQ Server 中不丢失,从而保证可靠性,其实除了持久化之外还需要保证 RabbitMQ 的高可用性,否则 MQ 都宕机或磁盘受损都无法确保消息的可靠性,关于高可用性这里就不作过多说明,有兴趣的可以去了解一下。
4. 保证消费者消费的消息不丢失
在保证发送方和 RabbitMQ Server 的消息可靠性的前提下,只需要保证消费者在消费消息时异常消息不丢失即可保证消息的可靠性。
RabbitMQ 提供了 消费者应答机制 来使 RabbitMQ 能够感知到消费者是否消费成功消息,默认情况下,消费者应答机制是自动应答的,也就是RabbitMQ 将消息推送给消费者,便会从队列删除该消息,如果消费者在消费过程失败时,消息就存在丢失的情况。所以需要将消费者应答机制设置为手动应答,只有消费者确认消费成功后才会删除消息,从而避免消息的丢失。
下面来看看如何配置消费者手动应答:
spring:
rabbitmq:
publisher-confirm-type: correlated # 开启发送方确认机制
publisher-returns: true # 开启消息返回
template:
mandatory: true # 消息投递失败返回客户端
listener:
simple:
acknowledge-mode: manual # 开启手动确认消费机制
通过 listener.simple.acknowledge-mode = manual 即可将消费者应答机制设置为手动应答。
之后只需要在消费消息时,通过调用 channel.basicAck() 与 channel.basicNack() 来根据业务的执行成功选择是手动确认消费还是手动丢弃消息。
/**
* 监听消费队列的消息
*/
@RabbitListener(queues = RabbitMQConfig.MESSAGE_QUEUE)
public void onMessage(Message message, Channel channel) {
// 获取消息索引
long index = message.getMessageProperties().getDeliveryTag();
// 解析消息
byte[] body = message.getBody();
...
try {
// 业务处理
...
// 业务执行成功则手动确认
channel.basicAck(index, false);
}catch (Exception e) {
// 记录日志
log.info("出现异常:{}", e.getMessage());
try {
// 手动丢弃信息
channel.basicNack(index, false, false);
} catch (IOException ex) {
log.info("丢弃消息异常");
}
}
}
这里说明一下 basicAck() 与 basicNack() 的参数说明:
void basicAck(long deliveryTag, boolean multiple)方法(会抛异常):- deliveryTag:该消息的index
- multiple:是否批量处理(true 表示将一次性ack所有小于deliveryTag的消息)
void basicNack(long deliveryTag, boolean multiple, boolean requeue)方法(会抛异常):- deliveryTag:该消息的index
- multiple:是否批量处理(true 表示将一次性ack所有小于deliveryTag的消息)
- requeue:被拒绝的是否重新入队列(true 表示添加在队列的末端;false 表示丢弃)
通过设置手动确认消费者应答机制即可保证消费者在消费信息时的消息可靠性。
Spring Boot 提供的消息重试机制
除了消费者应答机制外,Spring Boot也提供了一种重试机制,只需要通过配置即可实现消息重试从而确保消息的可靠性,这里简单介绍一下:
spring:
rabbitmq:
listener:
simple:
acknowledge-mode: auto # 开启自动确认消费机制
retry:
enabled: true # 开启消费者失败重试
initial-interval: 5000ms # 初始失败等待时长为5秒
multiplier: 1 # 失败的等待时长倍数(下次等待时长 = multiplier * 上次等待时间)
max-attempts: 3 # 最大重试次数
stateless: true # true无状态;false有状态(如果业务中包含事务,这里改为false)
通过配置在消费者的方法上如果执行失败或执行异常只需要抛出异常(一定要出现异常才会触发重试,注意:不要捕获异常) 即可实现消息重试,这样也可以保证消息的可靠性。
总要有总结
上面就是我在项目中关于如何保证 RabbitMQ 的消息可靠性的配置和实现方案了。下面想聊聊我在实际使用消息队列实现消息可靠性时遇到的问题。
消费者消费消息需要保证幂等性
由于实现了消息可靠性导致消息重发或消息重试造成消费者可能会存在消息被重复消费的情况,这种情况就需要保证消息不被重复消费,也就是消息保证幂等性。
实现幂等性的方法有很多:借助数据库的乐观锁或悲观锁、借助 redis 的分布式锁、借助 redis 实现 token 机制等等都可以很好的保证消息的幂等性。
使用消息队列很难做到 100% 的消息可靠性
我在项目实际开发中使用 RabbitMQ 实现消息可靠性,实践后的感受是消息队列很难能做到 100% 的消息可靠性,上面的实现方案中 RabbitMQ 提供的机制做到的是尽可能地减小消息丢失的几率。
大多数情况下消息丢失都是因为代码出现错误,那么这样无论进行多少次重发都是无法解决问题的,这样只会增加 CPU 的开销,所以我认为更好的解决办法是通过记录日志的方式等待后续回溯时更好的发现问题并解决问题。对于一些不是很需要保证百分百可靠性的场景,都可以通过记录日志的方式来保证消息可靠性即可。
我在项目中采用的是消息落库的方式,先将消息落库,而后生产者将消息发送给 MQ,使用数据库记录消息的消费情况,对于重试多次仍然无法消费成功的消息,后续通过定时任务调度的方式对这些无法消费成功的消息进行补偿。我认为这样可以尽可能地保证消息的可靠性。但是同样这样也带来了问题就是消息落库需要数据库磁盘IO的开销,增大数据库压力同时降低了性能。
总之,在实现消息的可靠性时,应该根据项目的需求来考虑如何处理。对于消息要求可靠性低的只需要在出错时记录日志方便后续回溯解决出错问题即可,对于消息可靠性要求高的则可以采用消息落库 + 定时任务的方式尽可能保证百分百的可靠性。