本文目录
RDB(默认)
自动触发 🆚 手动触发
优点
缺点
何时会触发RDB快照
AOF
启用 AOF
配置路径
AOF 文件📃
AOF 的写回策略
AOF 的重写机制
优点
缺点
RDB & AOF 优先级
终极方案:RDB + AOF 混合方式
补充:纯缓存模式(无持久化需求+提升性能)
形容Redis的持久化其实就4个单词: write data to dist
持久化主要是为了加强数据安全
Redis支持两种不同的持久化机制,RDB 和 AOF
RDB(默认)
RDB(Redis Database)持久化机制是将Redis在内存中的数据快照(snapshot)保存到磁盘上。该机制可以在指定的时间间隔内将内存中的数据保存到磁盘上(📃dump.rdb二进制备份文件),以便在Redis重启后恢复数据。RDB机制能够快速进行备份和恢复操作,并且对于大规模数据的恢复速度比AOF方式更快,但可能会丢失最后一次快照之后的所有更改。
自动触发 🆚 手动触发
按照时间修改频次的自动触发
Redis 7.0(括号内为6.2以前的版本)RDB持久化机制的配置文件redis.conf里配置的选项如下:
save 900 1 (3600 1)
save 300 10 (300 100)
save 60 10000(60 10000)其中,每行配置项表示一个“保存条件”,分别为:
-
save { seconds} {changes}:在 {seconds} 秒内,如果发生了 {changes} 次修改,则进行持久化。
注意⚠️
-
物理恢复,服务一定要和备份分机隔离
-
如果
dump.rdb文件报错,可以使用redis-check-rdb /myredis/dumpfiles/dump6379.rdb命令进行修复(/myredis/dumpfiles/dump6379.rdb需要替换为自己的真实路径)
顺便介绍下配置文件redis.conf中RDB相关的其他配置
-
snapshotting模块中的配置项
-
dbfilename配置dump.rdb的文件名(建议可以加上端口号) -
dir配置dump.rdb的路径 -
stop-write-on-bgsave-error配置当快照写入失败时,Redis是否继续接受新的写请求-
默认yes,即不会,保证数据一致性
-
-
rdbcompression配置是否进行压缩存储-
默认yes,会采用LZF算法进行压缩
-
-
rdbchecksum配置是否进行数据校验-
默认yes,会使用CRC64算法来进行数据校验,这样会增加约10%的性能消耗,希望提升性能可以关闭此功能
-
-
rdb-del-sync-files配置是否允许在没有持久性的情况下删除复制中使用的RDB文件-
默认no
-
-
-
如何禁用快照
-
取消配置文件
redis.conf中的# save ""的注释(永久) -
也可以通过
redis-cli config set save ""动态停止RDB保存(重启后失效)
-
立刻执行的手动触发
-
save同步,主程序会阻塞,不再对外提供缓存功能,直到完成文件备份(线上不会使用) -
bgsave异步,不阻塞,备份由后台异步完成,会fork一个子进程由子进程复制持久化过程-
fork为当前进程制作一个副本 -
lastsave查看最后一次成功执行快照的时间 -
COW写时复制技术Copy On Write
-
优点
-
RDB在保存RDB文件时父进程唯一要做的就是fork出一个子进程,接下来的操作都交由子进程来做,父进程无需进行其他任何IO操作,所以RDB持久化方式可以最大化redis的性能
-
格式紧凑,并且RDB文件在内存中加载速度要比AOF快很多
-
可以按照业务定时备份,适合大规模的数据恢复,以及对数据完整性和一致性要求不高的场景
缺点
-
数据丢失风险大
-
在一定间隔时间做一次备份,所以如果redis意外down掉的话就会丢失从当前时间到最近的一次快照期间的数据
-
-
数据量太大时会影响服务性能
-
RDB是内存数据的全量同步,如果数据量太大,I/O操作会严重影响数据库性能
-
RDB依赖于主进程的fork,fork的时候内存中的数据被克隆了一份,数据集较大会导致占用内存较高,导致服务请求瞬间延迟
-
何时会触发RDB快照
-
符合配置文件中的快照配置
-
执行save/bgsave命令
-
执行flushall/flushdb命令(会清空)
-
执行shutdown并且没有开启AOF持久化
-
主从复制时,主节点会自动触发
AOF
AOF(Append Only File)持久化机制是指将Redis服务器接收到的每一条写命令(例如 SET、LPUSH等)都写入到一个追加的日志文件中,以此记录所有对数据集的修改。当Redis服务器重新启动时,它会从日志文件中读取所有写命令,并重新执行它们,以此将数据集恢复到重启前的状态。该机制的优点是在故障恢复时数据丢失较少,但相对于RDB方式,AOF方式的恢复速度可能会比较慢。
启用 AOF
如果要启用Redis AOF持久化机制需要在配置文件redis.conf中开启(默认no,开启改为yes)
appendonly yes配置路径
指定AOF日志文件的名称为
appendfilename "appendonly.aof"指定AOF日志文件的路径(注意这个路径是拼在上面介绍RDB时介绍的dir后面的)
appenddirname "appendonlydir"按照上述配置 dir / appendonlydir / appendfilename,如果dir配置的是/myredis,那么AOF日志文件的完整路径为 /myredis/appendonlydir/appendonly.aof
如果你不知道自己的配置文件在哪里,可以通过命令行或者其他工具🔧进行查询,示例如下:
sudo find / -name '*redis.conf*'tips:在vim的编辑模式下,可以使用:set nu显示行号,使用/+搜索内容快速定位查询内容
AOF 文件📃
Redis 7.0 有个新特性 Multi-part AOF ,即把原本单个的AOF文件拆成了多个AOF文件,在MP-AOF中,有三种类型的AOF:
-
BASE:基础文(只有一个)
-
appendonly.aof.1.base.rdb
-
-
INCR:增量文件(有多个)
-
appendonly.aof.1.incr.aof -
appendonly.aof.2.incr.aof
-
-
mainfest:清单文件
-
appendonly.aof.mainfest
-
AOF 的写回策略
配置文件redis.conf中的appendfsync是配置AOF的写回策略的,即指定何时将日志数据写入磁盘,可选值为 no、always 和 everysec,默认如下:
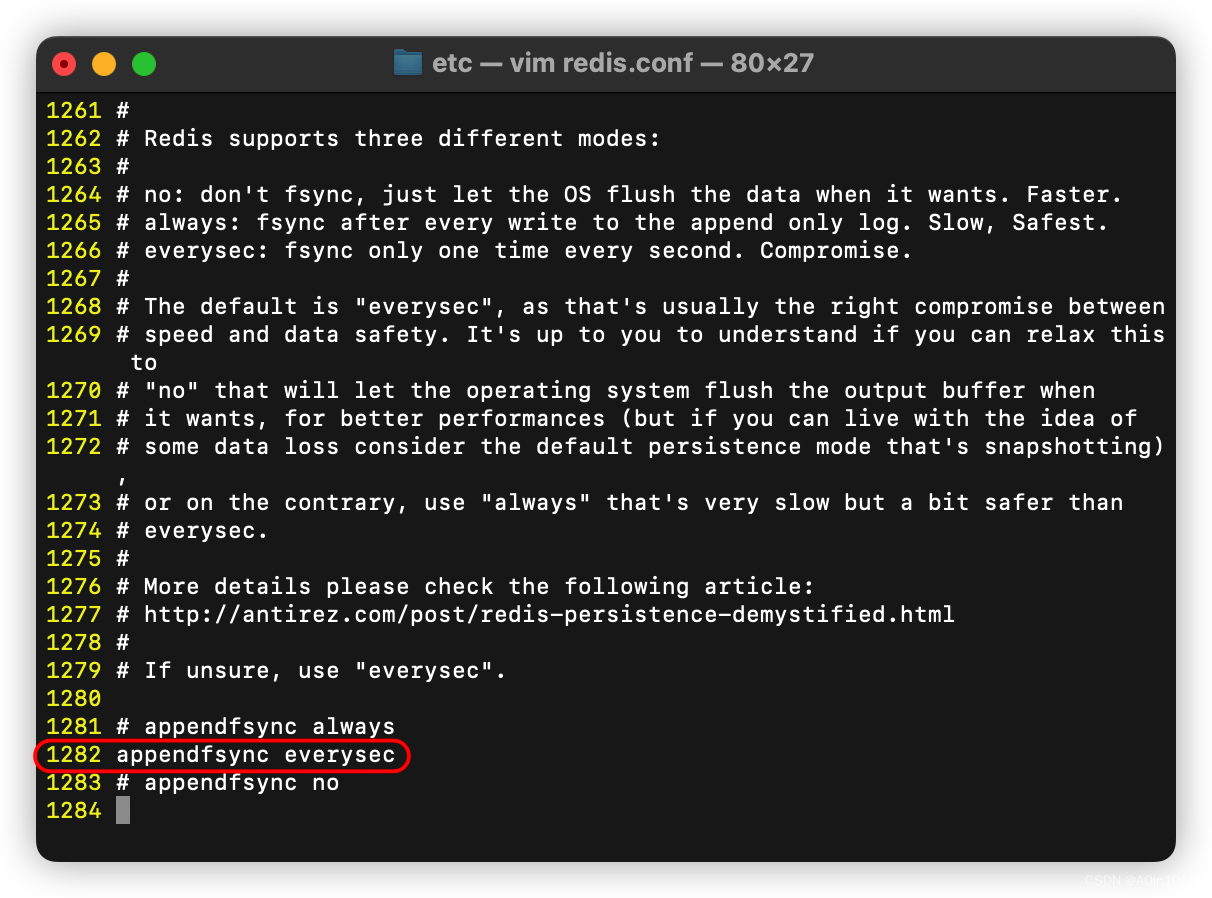
appendfsync everysec-
always 同步写会,每个写命令执行完立刻同步地将日志写回磁盘
-
everysec (默认项)每秒写回, 每个写命令执行完只会先写到AOF文件的内存缓冲区中,每隔1秒地将日志写回磁盘(是性能和数据安全性的折中方案)
-
no 操作系统控制的写回,每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区中,有操作系统决定何时将缓冲区8内容写回磁盘
表示写期间是否同步,默认no
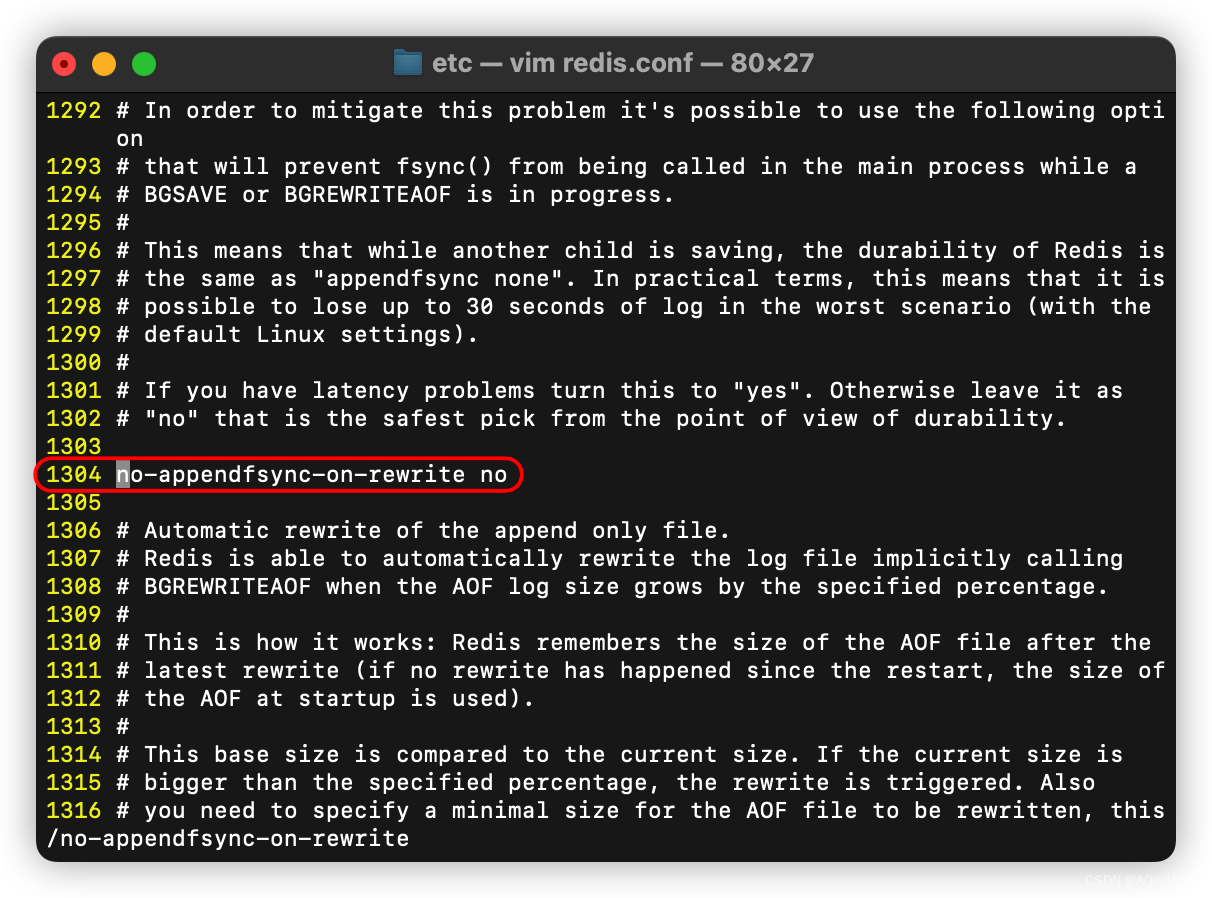
no-appendfsync-on-rewrite noAOF 的重写机制
由于AOF持久化是Redis不断将写命令记录到AOF文件中,随着Redis的不断运行,AOF的文件会越来越大,文件越大,占用服务内存越大以及AOF恢复的时间需要越长,重写机制就是解决这个问题的
重写机制主要有两种实现方式:
-
自动执行
auto-aof-rewrite-percentage 100 # 当前aof文件的大小比上次重写时增加了100% auto-aof-rewrite-min-size 64mb # 重写时aof文件的大小需要大于64mb-
在配置文件
redis.conf中进行配置,当AOF文件的大小超过所设定的峰值时,Redis就会自动启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集 -
注意:需要同时满足上面两条才会触发
-
auto-aof-rewrite-percentage表示当前aof文件的大小比上次重写时增加的百分比 -
auto-aof-rewrite-min-size表示重写时满足的aof文件的大小
-
-
-
手动执行
-
使用命令
bgrewriteaof
-
总的来说,AOF重写机制并不是对原文件进行重新整理🔄,而是直接读取服务器现有键值对,然后用一条命令去代替之前记录这个键值对的多条命令,生成一个新的文件然后去替换原来的AOF文件。可以降低文件的占用空间,同时更小的AOF也可以更快的被Redis加载
优点
-
使用AOF更加持久
-
可以定制fsync策略,最多丢失1秒数据
-
-
AOF是个仅附加日志,不会出现寻道问题,也不会出现在断电时出现损坏的问题,即使出于某种原因(磁盘已满等)日志以写一半的命令结尾,也可以使用
redis-check-aof工具进行修复 -
当AOF变得太大时,Redis能够在后台自动重写AOF
-
这个重写个是完全安全的,因为当Redis继续附加到旧文件时,会使用创建当前数据集所需要的最少操作集生成一个全新的文件,一旦第二个文件准备就绪,Redis就会切换两者并开始附加到新的那一个
-
-
AOF以利于理解和解析的格式依次包含所有的操作日志。即使对数据库进行了清空操作,只要在此期间没有执行日志重写,就可以通过停止服务器、删除最新的清空操作,重新启动Redis来恢复数据集
总的来说就是:更好的保护数据不丢失、性能高、可做紧急恢复
缺点
-
AOF通常比相同数据集的等效RDB文件更大,并且恢复速度慢于RDB
-
AOF运行效率要慢于RDB(RDB是内核级别的命令),一般来讲如果fsync(同步策略)设置为每秒,性能较高,不设置则和RDB一样
-
但RDB能够提供关于延迟的更多保证
-
RDB & AOF 优先级
由配置文件(下图)可以看出,RDB和AOF是可以共存的,并且当两者都被开启时,Redis会优先加载AOF文件
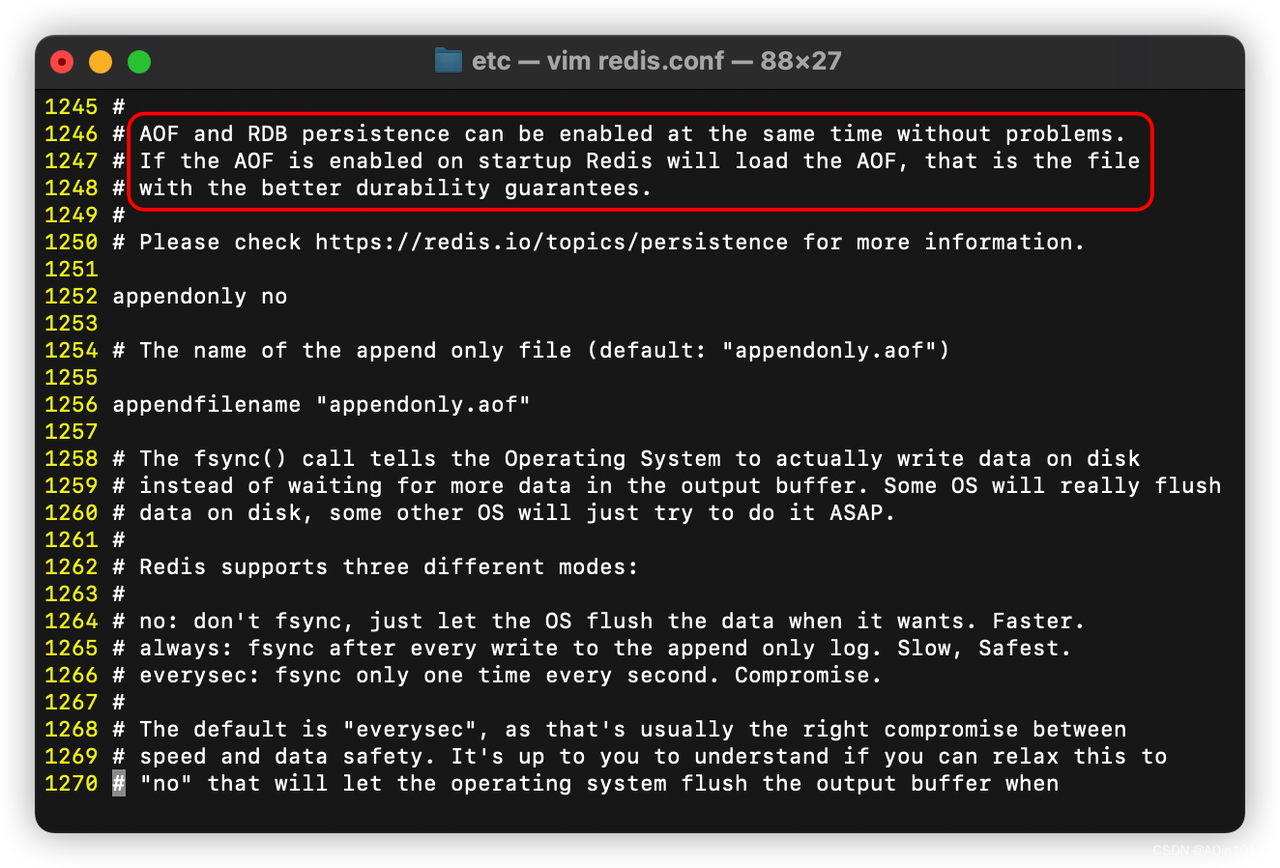
同时开启时的加载流程
同时开启RDB和AOF持久化时
-
重启时判断是否存在AOF文件,
-
存在,加载AOF文件 -> 3
-
不存在 -> 2
-
-
判断RDB文件是否存在
-
存在,加载RDB文件 -> 3
-
不存在 -> 3
-
-
完成启动(成功/失败)
终极方案:RDB + AOF 混合方式
结合RDB和AOF各自的优点:快速加载+避免丢失过多的数据
设置方式:
-
开启
appendonlyappendonly yes -
开启
aof-use-rdb-preambleaof-use-rdb-preamble yes
RDB做全量持久化,AOF做增量持久化,即先使用RDB进行快照存储,然后用AOF持久化所有写操作,当重写策略满足或者手动触发重写的时候,会将RDB中没有,只被AOF持久化的写操作(即最新的数据)存储为新的RDB记录📝,简单理解就是,混合模式下生成的AOF文件包含两部分:一部分是RDB文件的内容,另一部分是在重写时,由AOF储存的写操作生成的RDB纪录
补充:纯缓存模式(无持久化需求+提升性能)
同时关闭RDB和AOF
-
关闭RDB:
save "" -
关闭AOF:
appendonly no
值得注意的是,上述方式都只是关闭了自动触发的机制,我们仍然可以通过手动的方式生成RDB/AOF文件