基频F0建模方法
语音合成领域需要对基频进行建模,具体到文语转换TTS、语音转换VC、情感语音转换EVC领域等。
语音合成F0
包括文语转换,情感语音转换
TTEF:text-to-emotional-features synthesis
EVC:emotional voice conversion
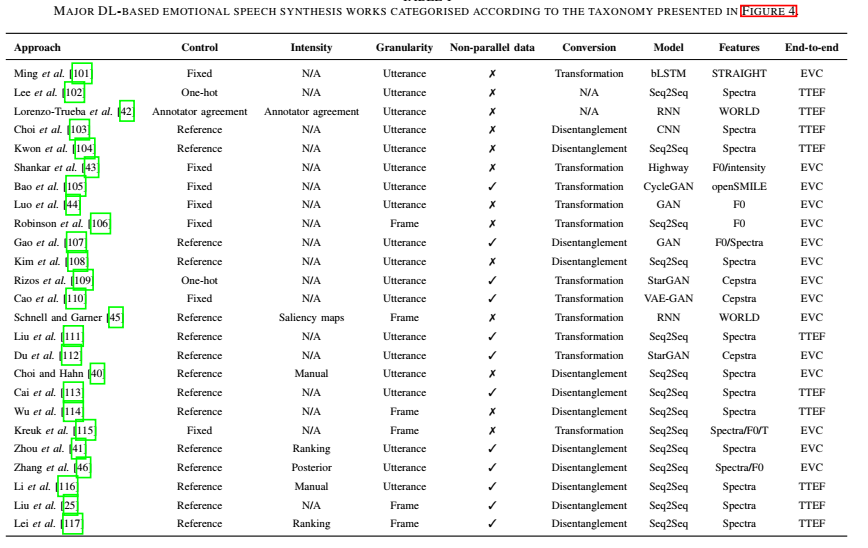
如何表示情感来实现这种控制?我们分为基于引用的 reference-based方法和无引用reference-free的方法(如one-hot)。第一种是使用情感语音样本来调节ESS系统所需产生的情感。第二种提供了情感的非听觉表征,表征的选择是分化的一个子类。
2022《An Overview of Affective Speech Synthesis and Conversion in the Deep Learning Era》
语音转换F0
韵律(音高、音长、频谱平衡、能量)对说话者身份也很重要,但大多数VC文献都侧重于频谱特征映射研究(Helander and Nurminen, 2007);Morley等人,2012)。对于建模持续时间,一个全局的说话速率调整是不够的,因为已经观察到音素持续时间在源和目标说话者之间有一些任意的差异(Arslan和Talkin, 1998)。文献有决策树建模持续时间(Pozo, 2008)和嵌入持续时间的hmm(Wu et al., 2006)。
2017《An overview of voice conversion systems》
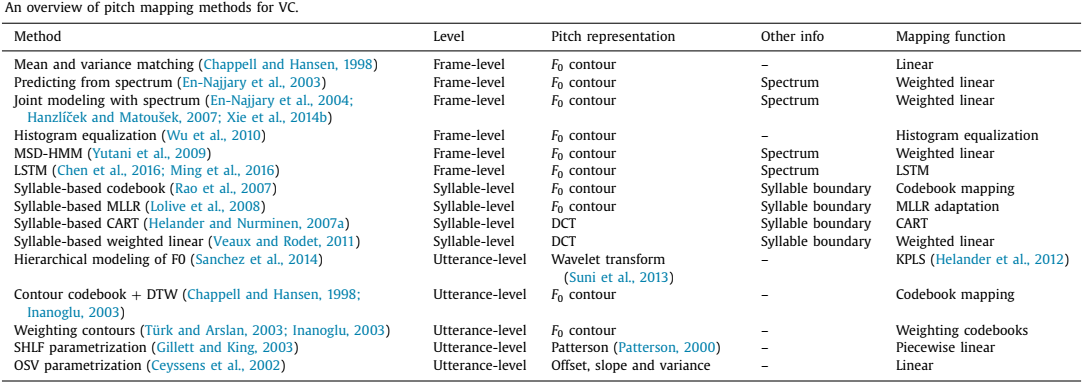
情感语音转换F0
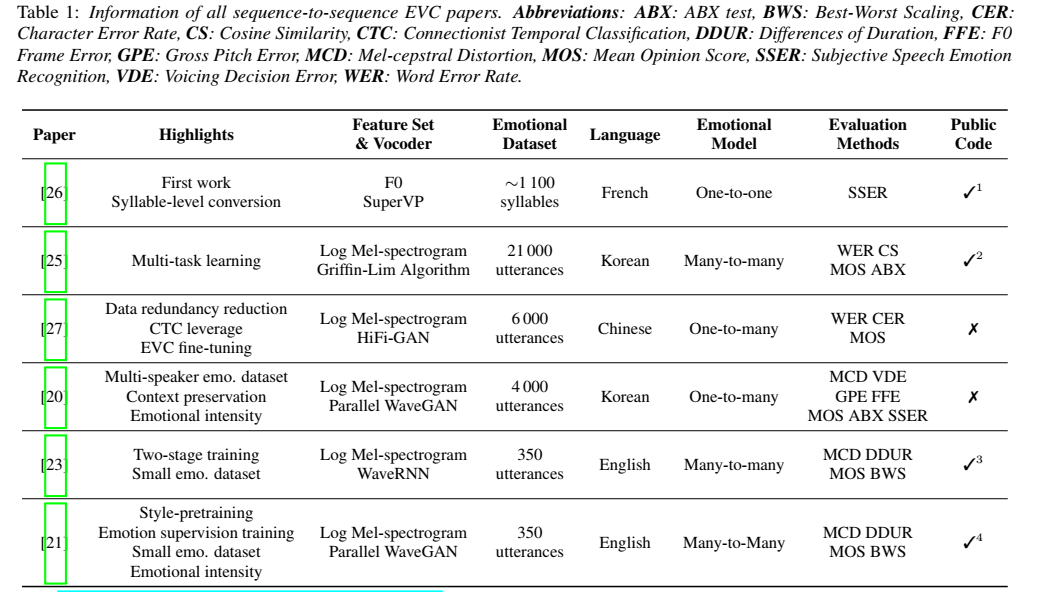
总结情感语音转换中的基频建模方法。对F0变量建模的方法包括风格化方法和多层次建模。
连续小波变换(CWT)作为一种多层次的建模方法,被广泛用于分层韵律特征的建模,如F0和能量轮廓。利用CWT分析,可以将信号分解成不同的频率分量,用不同的时间尺度表示。CWT已被证明对语音韵律建模是有效的,并已成功应用于各种情绪语音转换中。
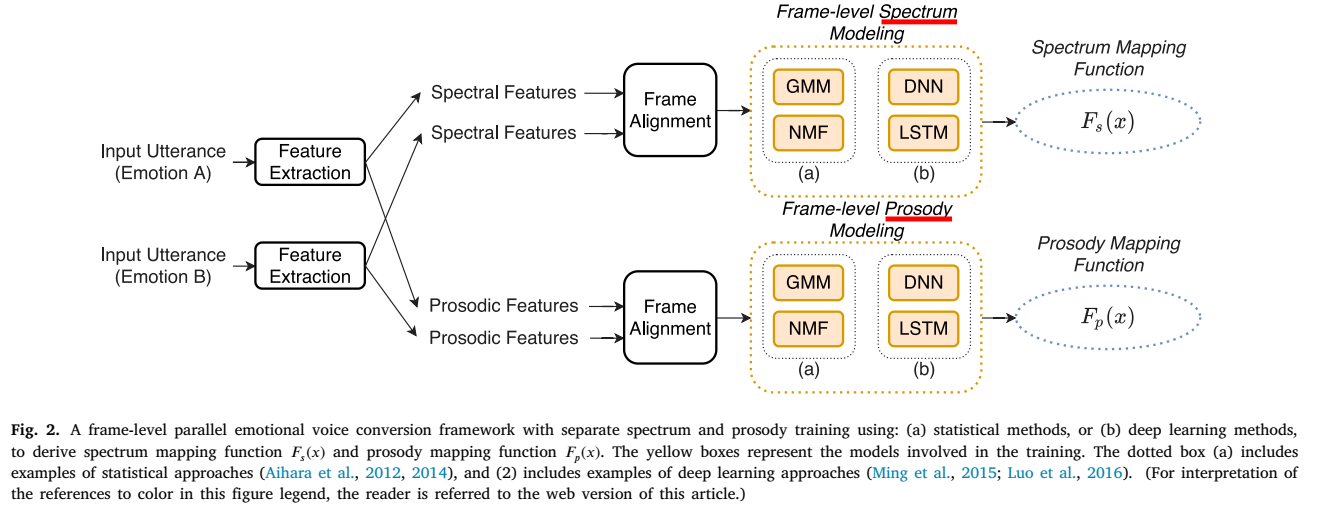
序列到序列建模:
2022《An Overview & Analysis of Sequence-to-Sequence Emotional Voice Conversion》