文章目录
- 写在最前面
- step1:相关说明
- step2:Prerequisites
- 安装要求
- tensorflow-gpu
- 1. 安装和测试
- 2. 错误提示
- ① numpy版本
- ② tensorflow版本
- ③TensorRT
- step3:Installation
- 1. Update your -arch
- 2. Install the Python COCO API
- 3. setup VOC
- 4. Download pre-trained model
- step4:Demo and Test
- 1. Demo for testing
- ① pycharm直接运行(CPU)
- ② 命令行运行(GPU)
- ③ pycharm直接运行(GPU)
- ④ 命令行运行(CPU)
- 2. Test with pre-trained Resnet101 models
- ① time: command not found
- ② load(×××, Loader=)
- step5:Train your own model
- 1. 下载权重
- 2. 设计自己的数据集
- 3. 修改代码
- ① classes
- ② bbox
- 3. config
- 4. 训练和测试
写在最前面
像我一样不熟悉代码不熟悉tensorflow的同学拿到源码的第一件事一定是环境配置和代码复现!不要嫌麻烦,一定要下载数据集、下载训练好的模型,如果能成功检测再去改自己的!我就是因为没提前测试走了很多弯路。一定要先测试!否则有很大的可能会推翻重来。
step1:相关说明
本文基于tensorflow版本的Faster R-CNN源码,使用GPU训练。全过程均使用Pycharm远程连接服务器进行(因为可以看到远程主机的文件结构,所以不是全程都在终端)。
| 我的环境 | |
|---|---|
| GPU | RTX 3090(24GB) * 1 |
| PyTorch | 1.10.0 |
| Python | 3.8(ubuntu20.04) |
| Cuda | 11.3 |
| conda默认环境 | root/miniconda3/ |
源码地址:
https://github.com/endernewton/tf-faster-rcnn.git
step2:Prerequisites
安装要求
因为很多教程提到使用conda出现的错误更少,所以相关配置操作默认使用conda。
要求安装:
- tensorflow-gpu
- opencv-python(使用pip安装)
- cython
- easydict
- pillow
- matplotlib
- scipy
- PyYAML
Cython是一种通过python语法编写C扩展的编程语言
easydict允许以属性的方式访问dict类型,且可以递归地访问,使用起来比较方便。
切换到终端,先使用conda list命令查看现有的库,我这里pillow、matplotlib、scipy均已存在。使用conda install XXX命令安装对应的包。
tensorflow-gpu
1. 安装和测试
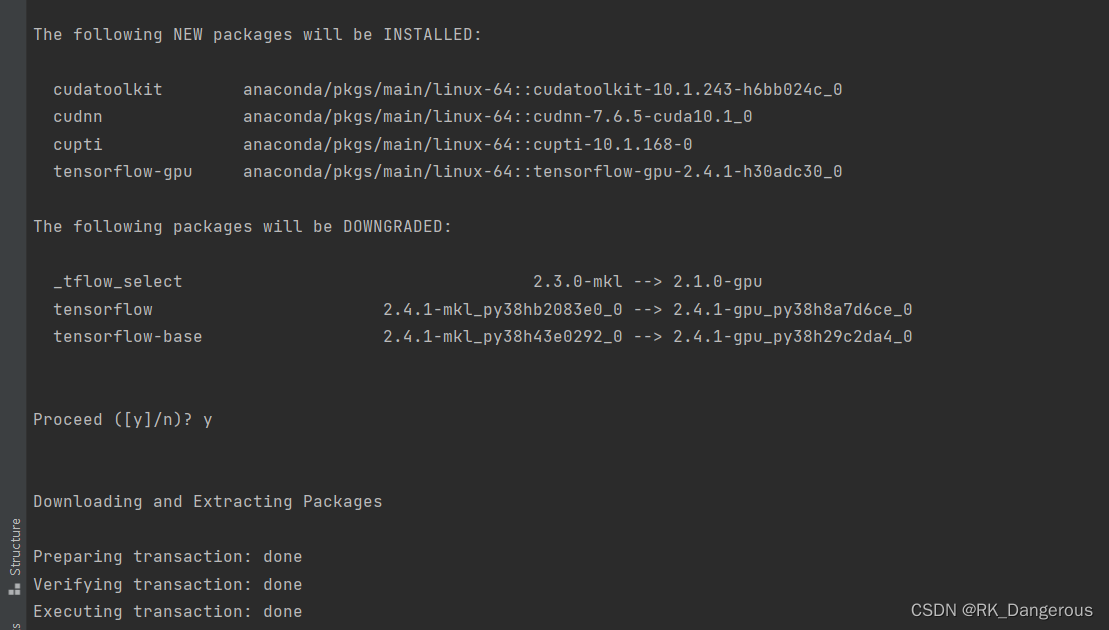
以tensorflow-gpu为例,输入命令conda install tensorflow-gpu进行安装。(据我所知tensorflow-gpu和tensorflow是不一样的,如果想成功用GPU训练,必须要安装tensorflow-gpu)
因为我乱七八糟安装了好几次,所以这个界面有点乱,安装成功大概就是这样:
一定要先检查环境,看看tensorflow能不能正常使用。新建一个python文件,输入以下内容:
import torch
flag = torch.cuda.is_available()
print(torch.__version__,flag)
ngpu= 1
# Decide which device we want to run on
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
print(device)
print(torch.cuda.get_device_name(0))
print(torch.rand(3,3).cuda())
import tensorflow as tf
print(tf.__version__, tf.test.is_gpu_available())
2. 错误提示
① numpy版本
运行上述代码后出现报错,提示我的numpy有问题。
FutureWarning: In the future `np.object` will be defined as the corresponding NumPy scalar.
折腾了好久,应该是numpy的版本有问题。
由于这里是numpy的版本太高,但我安装低版本在后面代码运行的过程中还是会报新的错误,太高也不行太低也不行。经过多次尝试我目前安装的是1.22.0。
② tensorflow版本
我自带的tensorflow初始版本较低,较低版本的tensorflow在安装其他库的时候会有限制,我在安装numpy时遇到的提示如下:
tensorflow 2.4.1 requires absl-py~=0.10, but you have absl-py 1.3.0 which is incompatible.
tensorflow 2.4.1 requires flatbuffers~=1.12.0, but you have flatbuffers 2.0 which is incompatible.
tensorflow 2.4.1 requires gast==0.3.3, but you have gast 0.4.0 which is incompatible.
tensorflow 2.4.1 requires grpcio~=1.32.0, but you have grpcio 1.42.0 which is incompatible.
tensorflow 2.4.1 requires six~=1.15.0, but you have six 1.16.0 which is incompatible.
tensorflow 2.4.1 requires tensorflow-estimator<2.5.0,>=2.4.0, but you have tensorflow-estimator 2.6.0 which is incompatible.
tensorflow 2.4.1 requires termcolor~=1.1.0, but you have termcolor 2.1.0 which is incompatible.
tensorflow 2.4.1 requires typing-extensions~=3.7.4, but you have typing-extensions 4.0.0 which is incompatible.
tensorflow 2.4.1 requires wrapt~=1.12.1, but you have wrapt 1.13.3 which is incompatible.
(先别着急,往后看)可以根据提示降其他包的版本。以typing-extensions为例,指定版本下载输入以下命令(pip或conda均可):
pip install typing-extensions==3.7.4
其中“==”后面就是要下载的版本号。如果不知道有哪些版本能够下载,可以先查找,以gast为例,用conda search gast查看可下载的包版本。
但是我在后面运行时还是遇到了很多报错,可能是因为tensorflow版本太低了,索性直接升tensorflow版本,使用命令pip install -U tensorflow。这样就不用给其他包降级了。
③TensorRT
接下来继续测试tensorflow,torch返回1.10.0+cu113 True,tensorflow返回2.11.1 True(其他输出略),说明成功。
注意,除了成功输出的东西外,额外打印了一些提示:
2023-04-30 23:12:10.817914: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory
2023-04-30 23:12:10.817996: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory
2023-04-30 23:12:10.818001: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
这几条是需要运行TensorRT才需要安装的东西。也就是说单独使用Tensorflow不需要。
这里我们可以忽略。
其他库同理,全部安装完一定要检查好自己的环境,再进行后续代码的配置(否则会很麻烦,有可能直接白整)。
step3:Installation
1. Update your -arch
找到Faster-RCNN-endernewton/lib目录,打开setup.py。找到参数extra_compile_args,其中有个-arch是需要根据自己CUDA的版本填写的。
由于GPU算力和CUDA算力的关系很复杂,我查了一下我的GPU算力,对应-arch=sm_75,RTX版本对应关系如下图:

修改完成后,进入lib目录进行配置。
root@a:~# cd /Faster-RCNN-endernewton/lib
root@a:/Faster-RCNN-endernewton/lib# make clean
root@a:/Faster-RCNN-endernewton/lib# make
2. Install the Python COCO API
接下来下载COCO和VOC数据库。这步先下载COCO数据库。我选择下载到数据盘,然后建立软连接的方式。
软连接的使用可参考下文1.4节内容,此处不再赘述:
【深度学习】计算机视觉(11)——Faster RCNN(工具篇)
先进入数据盘,使用命令:
root@a:~/autodl-tmp# git clone https://github.com/pdollar/coco.git
出现报错GnuTLS recv error (-110): The TLS connection was non-properly terminated.,运行下面代码之后再执行一次,正常。
export GIT_TRACE_PACKET=1
export GIT_TRACE=1
export GIT_CURL_VERBOSE=1
然后回到系统盘,进入项目文件的data目录下,建立COCO的软连接,命令行操作记录及显示记录如下。
root@a:~/autodl-tmp# cd /
root@a:/# cd /Faster-RCNN-endernewton/data
root@a:/Faster-RCNN-endernewton/data# ln -sv /root/autodl-tmp/coco coco
'coco' -> '/root/autodl-tmp/coco'
然后还是在data目录下,进入coco/PythonAPI,执行make。
cd coco/PythonAPI
make
3. setup VOC
接下来下载VOCdevkit,就是我们用的VOC数据集。进入数据盘,分别输入以下命令下载压缩包:
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
然后解压缩:
tar xvf VOCtrainval_06-Nov-2007.tar
tar xvf VOCtest_06-Nov-2007.tar
tar xvf VOCdevkit_08-Jun-2007.tar
然后再回到系统盘,建立VOCdevkit2007的软连接在data目录下。
root@a:~/autodl-tmp/VOCdevkit# cd /Faster-RCNN-endernewton/data
root@a:/Faster-RCNN-endernewton/data# ln -sv /root/autodl-tmp/VOCdevkit VOCdevkit2007
'VOCdevkit2007' -> '/root/autodl-tmp/VOCdevkit'
4. Download pre-trained model
接下来下载训练好的模型。根据readme文件的提示在一级目录下使用命令./data/scripts/fetch_faster_rcnn_models.sh,我出现错误提示:fetch_faster_rcnn_models.sh: Permission denied,无执行权限。
进入.sh文件所在目录,使用命令:
root@a:/Faster-RCNN-endernewton/data/scripts# chmod +x fetch_faster_rcnn_models.sh
原理可查询下文 “2 Permission denied” 部分,因为后面还会遇到无权限的问题,可以了解一下:
【深度学习】计算机视觉(11)——Faster RCNN(工具篇)
然后再次执行fetch_faster_rcnn_models.sh,如下:
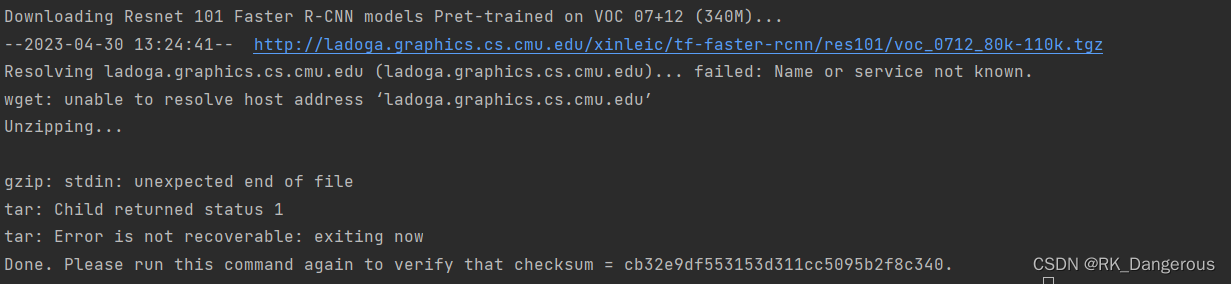
root@a:/Faster-RCNN-endernewton/data/scripts# ./fetch_faster_rcnn_models.sh
根据下面的提示可以看到我们下载的模型是在VOC 07+12数据集上训练的Resnet 101模型。但我还是报错,提示wget: unable to resolve host address ‘ladoga.graphics.cs.cmu.edu’
根据网上的提示修改相关配置还是没用,因此我直接使用参考作者提供的百度网盘链接。参考文章地址:
https://blog.csdn.net/zzyincsdn/article/details/83989606
本地下载好后,先解压缩.tgz文件中的voc_2007_trainval+voc_2012_trainval,然后上传到我的服务器里,我按照要求放在了Faster-RCNN-endernewton/data下。
接下来需要将模型放入指定位置(使用软连接)。在一级文件夹下新建目录:output/res101/voc_2007_trainval+voc_2012_trainval,并使用cd进入到该目录里建立软连接default。操作及显示如下:
root@a:/Faster-RCNN-endernewton/output/res101/voc_2007_trainval+voc_2012_trainval# ln -sv ../../../data/voc_2007_trainval+voc_2012_trainval ./default
'./default' -> '../../../data/voc_2007_trainval+voc_2012_trainval'
step4:Demo and Test
1. Demo for testing
回到一级文件夹。
测试运行demo,这里是使用下载好的权重测试几张样例图片。因为tensorflow版本的问题,在运行的时候可能会遇到报错,解决方式参考下文3.1、3.2、3.3节内容:
【深度学习】计算机视觉(11)——Faster RCNN(工具篇)
我修改的内容包括(可能没记录全):
| 目录 | 文件 |
|---|---|
| lib/layer_utils | proposal_layer、proposal_top_layer、snippets |
| lib/model | bbox_transform、train_val |
| lib/nets | mobilenet_v1、network、resnet_v1、vgg16 |
| tools | demo、test_net、convert_from_depre |
① pycharm直接运行(CPU)
为了测试命令行指定GPU和直接运行有什么不同,我先在pycharm里直接运行demo.py。Plots结果会直接显示,下面截几张结果图片。
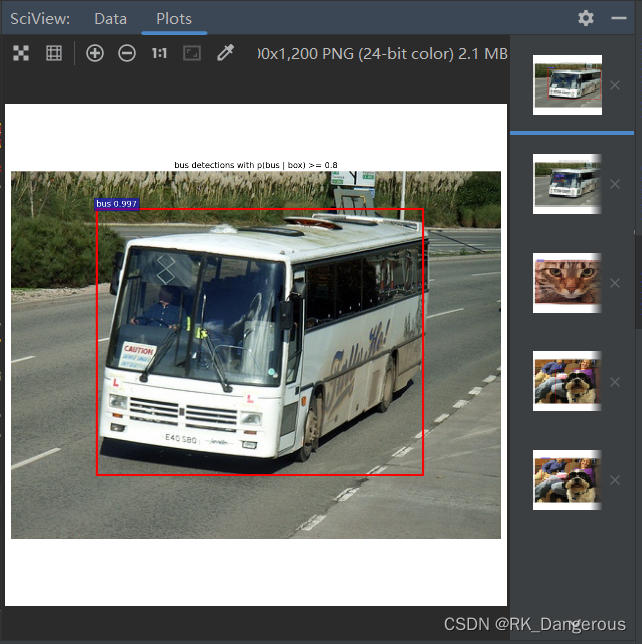
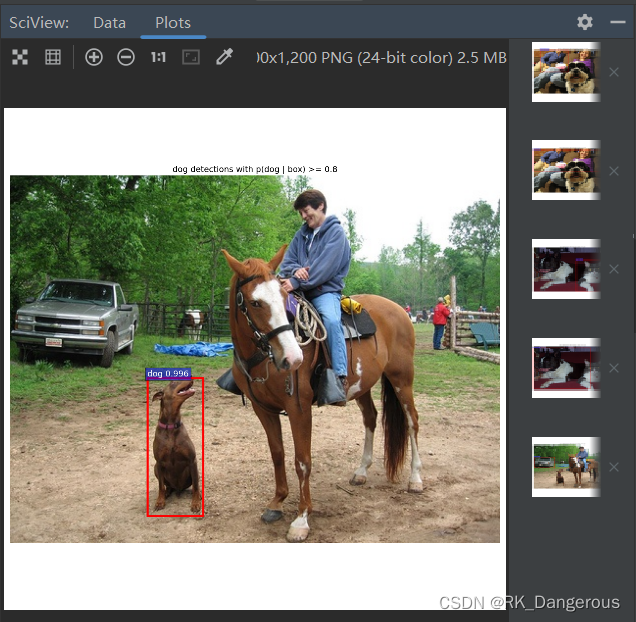
成功! 而且正确率似乎还挺高!
② 命令行运行(GPU)
接下来按照readme提示运行项目demo.py,进入一级文件输入命令:
GPU_ID=0
CUDA_VISIBLE_DEVICES=${GPU_ID} ./tools/demo.py
控制台显示相关输出,但是命令行运行无法显示Plots结果。
两次运行的GPU使用情况对比如下(上下两个图片分别表示GPU的使用率和显存使用大小,第一个峰值表示第一次运行,第二个峰值表示第二次运行):
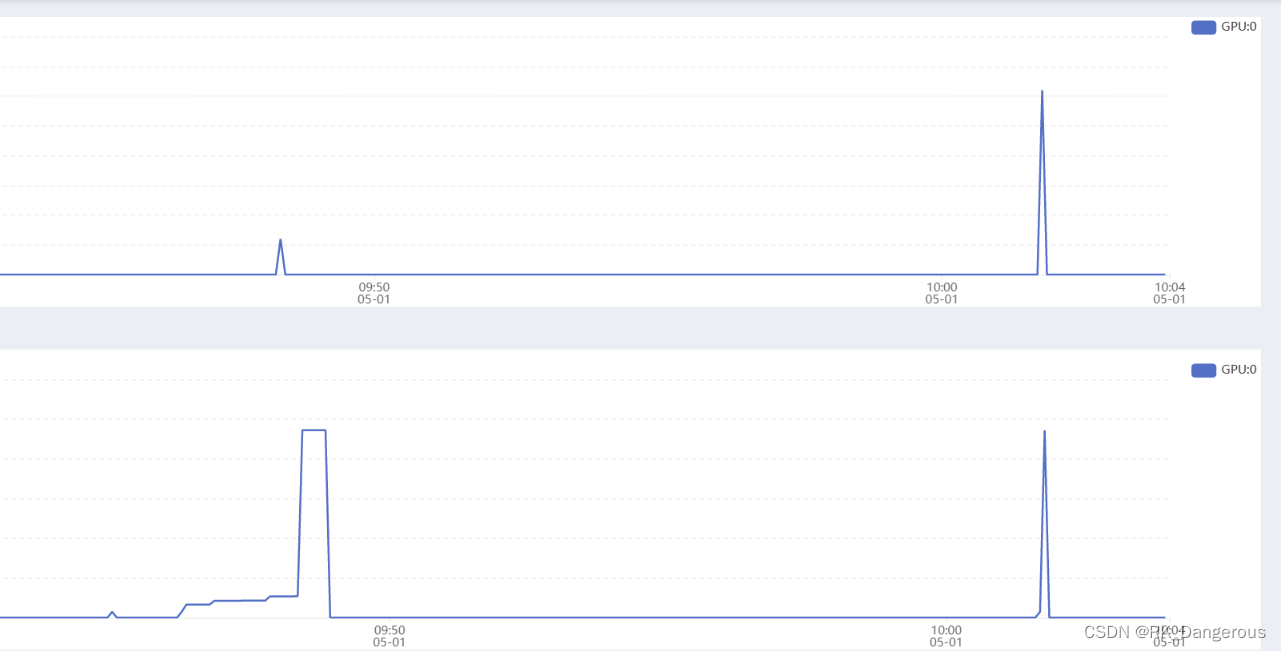
可见第一次运行用的并不是GPU,虽然速度也非常快(可能因为图片数量少)
③ pycharm直接运行(GPU)
只需要在程序中添加以下代码即可:
import os
gpu_ids = '0'
os.environ['CUDA_VISIBLE_DEVICES'] = gpu_ids
④ 命令行运行(CPU)
命令行使用CPU运行不指定GPU即可默认使用CPU。下图是四次运行测试的比较情况:
- 从上到下分别是:GPU的使用率、显存使用情况、CPU使用率、内存使用情况。
- 四个峰值表示四次运行:GPU代码版、GPU终端版、CPU代码版、CPU终端版。
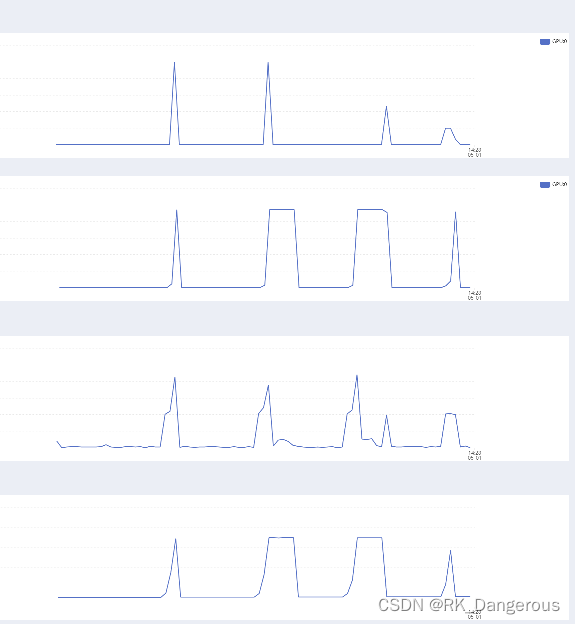
2. Test with pre-trained Resnet101 models
demo的几张图片能够测试成功,接下来利用下载好的VOC数据集测试大批量的数据,还是使用提前训练好的模型。
首先需要修改几处代码(readme文件中没有提到,是从别的作者那里看的)。
/lib/datasets/voc_eval.py中的第121行:
with open(cachefile,'w') as f
# 改成:
with open(cachefile,'wb') as f
同时第105行:
cachefile = os.path.join(cachedir, '%s_annots.pkl' % imagesetfile)
# 改成:
cachefile = os.path.join(cachedir, '%s_annots.pkl' % imagesetfile.split("/")[-1].split(".")[0])
改完之后即可进行测试。在一级文件夹下进入终端使用命令:
GPU_ID=0
./experiments/scripts/test_faster_rcnn.sh $GPU_ID pascal_voc_0712 res101
(这里出现报错以及解决办法放在本小节的最后)
测试成功,控制台打印结果如下,检测率正常:
Saving cached annotations to /Faster-RCNN-endernewton/data/VOCdevkit2007/annotations_cache/test_annots.pkl
AP for aeroplane = 0.8303
AP for bicycle = 0.8693
AP for bird = 0.8140
AP for boat = 0.7417
AP for bottle = 0.6847
AP for bus = 0.8772
AP for car = 0.8805
AP for cat = 0.8844
AP for chair = 0.6239
AP for cow = 0.8687
AP for diningtable = 0.7062
AP for dog = 0.8858
AP for horse = 0.8727
AP for motorbike = 0.8285
AP for person = 0.8272
AP for pottedplant = 0.5321
AP for sheep = 0.8069
AP for sofa = 0.7753
AP for train = 0.8442
AP for tvmonitor = 0.7919
Mean AP = 0.7973
测试完代码,就可以开始准备训练自己的数据集了。
① time: command not found
出现如下报错:
+ time python ./tools/test_net.py --imdb voc_2007_test --model output/res101/voc_2007_trainval+voc_2012_trainval/default/res101_faster_rcnn_iter_110000.ckpt --cfg experiments/cfgs/res101.yml --net res101 --set ANCHOR_SCALES '[8,16,32]' ANCHOR_RATIOS '[0.5,1,2]'
./experiments/scripts/test_faster_rcnn.sh: line 67: time: command not found
因为系统里没有time模块,需要使用apt-get install time命令安装,(如果安装失败可先更新apt-get工具,使用命令apt-get update)。安装time的过程显示如下:
Preparing to unpack .../time_1.7-25.1build1_amd64.deb ...
Unpacking time (1.7-25.1build1) ...
Setting up time (1.7-25.1build1) ...
② load(×××, Loader=)
出现如下报错:
TypeError: load() missing 1 required positional argument: 'Loader'
这是因为新版load添加了参数,要求指定具体的 Loader,禁止执行任意函数。有三种解决办法:
d1 = yaml.load(file, Loader=yaml.FullLoader)
d1 = yaml.safe_load(file)
d1 = yaml.load(file, Loader=yaml.CLoader)
我这里选择第一种,对应将错误代码改为:
yaml_cfg = edict(yaml.load(f, Loader=yaml.FullLoader))
step5:Train your own model
1. 下载权重
因为我们在已经训练好的model的基础上去训练RPN,也就是说Faster RCNN的卷积网络是直接采用VGG-16的,而初始权重也是VGG-16中保存的对任何数据集都表现比较好的一组。可以选择下载各种模型的权重,我这里选择vgg16。
先删除之前output文件夹训练好的模型的软连接和整个output目录,因为每次训练都会先加载之前保存的模型。
首先在data下新建imagenet_weights文件夹。进入数据盘,使用命令下载权重文件、解压、修改文件名:
wget -v http://download.tensorflow.org/models/vgg_16_2016_08_28.tar.gz
tar -xzvf vgg_16_2016_08_28.tar.gz
mv vgg_16.ckpt vgg16.ckpt
然后回到系统盘,进入imagenet_weights建立vgg16.ckpt的软连接,并回到一级目录下。
2. 设计自己的数据集
接下来设计自己的数据集,数据集要求按照VOC格式。关于VOC格式的介绍以及VOC格式数据集的制作方式详见下文 “4. 数据集制作” 部分:
【深度学习】计算机视觉(11)——Faster RCNN(工具篇)
特别注意数据集采用六位数字编码,如000001.jpg、000002.jpg。
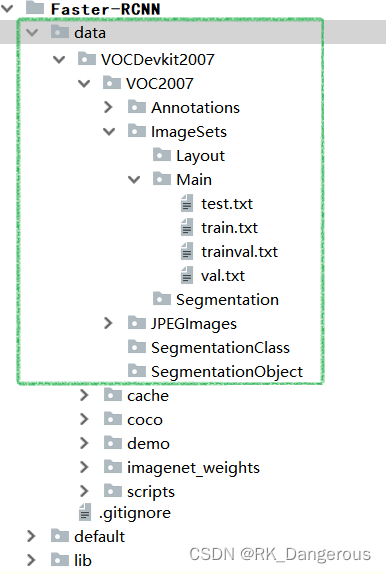
将数据集放在数据盘,系统盘建立软连接,目录结构为Faster-RCNN-endernewton/data/VOCdevkit2007/VOC2007,如图:
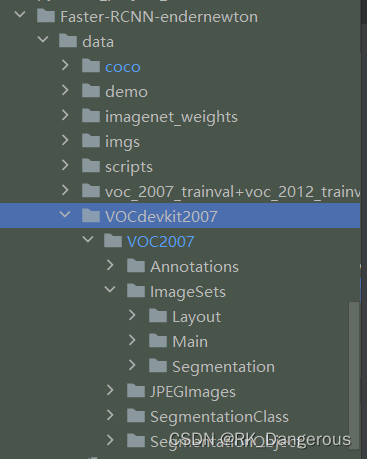
3. 修改代码
① classes
修改Faster-RCNN-endernewton/lib/datasets/pascal_voc.py文件中的类别集合,background不变,将之后改为自己数据集的类别。
# self._classes = ('__background__', # always index 0
# 'aeroplane', 'bicycle', 'bird', 'boat',
# 'bottle', 'bus', 'car', 'cat', 'chair',
# 'cow', 'diningtable', 'dog', 'horse',
# 'motorbike', 'person', 'pottedplant',
# 'sheep', 'sofa', 'train', 'tvmonitor')
self._classes = ('__background__', # always index 0
'cat')
然后修改Faster-RCNN-endernewton/lib/datasets/imdb.py文件中的类总数,为背景和前景类别的总和。
# self._num_classes = 0
self._num_classes = 2
② bbox
问题一:
然后根据个人情况,解决bbox坐标的问题。如果数据集标注的时候起点是(0, 0),那么/lib/datasets/pascal_voc.py就要修改获得真实框坐标时不再减1;如果数据集标注的时候起点是(1, 1),那么就不改。只要保证faster-rcnn的数据集起点是(0, 0)即可。
def _load_pascal_annotation(self, index):
# ...
# Load object bounding boxes into a data frame.
for ix, obj in enumerate(objs):
bbox = obj.find('bndbox')
# Make pixel indexes 0-based
x1 = float(bbox.find('xmin').text) - 1
y1 = float(bbox.find('ymin').text) - 1
x2 = float(bbox.find('xmax').text) - 1
y2 = float(bbox.find('ymax').text) - 1
# x1 = float(bbox.find('xmin').text)
# y1 = float(bbox.find('ymin').text)
# x2 = float(bbox.find('xmax').text)
# y2 = float(bbox.find('ymax').text)
问题二:
bbox翻转报错,参考下文3.4节:
【深度学习】计算机视觉(11)——Faster RCNN(工具篇)
问题三:
同样也需要检查Faster-RCNN-endernewton/lib/datasets/voc_eval.py中的函数def parse_rec(filename):,要符合自己的xml结构,因为我的xml文件都是按照标注转化的所以这里不需要修改。
3. config
至此,配置环节基本结束。然后需要调整模型参数。这里只是为了验证代码有没有问题,所以参数都调的小一些。
类似之前使用预训练的模型测试VOC数据集,我们还是使用命令行运行train_faster_rcnn.sh文件。在train_faster_rcnn.sh的末尾会执行test_faster_rcnn.sh,所以两个文件都需要修改。
我使用的是pascal_cov数据集,所以分别修改Faster-RCNN-endernewton/experiments/scripts/train_faster_rcnn.sh文件和Faster-RCNN-endernewton/experiments/scripts/test_faster_rcnn.sh文件中的迭代次数(修改70000为20)。其中STEPSIZE因为我不打算认真训练,所以没有改,保持它比ITERS大。两个文件的修改样例(部分)如下:
case ${DATASET} in
pascal_voc)
TRAIN_IMDB="voc_2007_trainval"
TEST_IMDB="voc_2007_test"
STEPSIZE="[50000]"
ITERS=20
ANCHORS="[8,16,32]"
RATIOS="[0.5,1,2]"
;;
case ${DATASET} in
pascal_voc)
TRAIN_IMDB="voc_2007_trainval"
TEST_IMDB="voc_2007_test"
ITERS=20
ANCHORS="[8,16,32]"
RATIOS="[0.5,1,2]"
;;
4. 训练和测试
在一级目录下使用命令:
./experiments/scripts/train_faster_rcnn.sh 0 pascal_voc vgg16
出现报错,显示FileNotFoundError,某一文件打开失败。python在使用open对文件进行’wt’操作时,如果找不到文件目录是不会自动创建的。所以需要在调用open前先确认是否存在路径,如果没有需要先新建。修改报错代码:
path = os.path.join(
self._devkit_path,
'results',
'VOC' + self._year,
'Main',
filename)
if not os.path.isdir(path):
os.makedirs(path)
注意os.mkdir()是新建子文件夹,如果需要创建多级目录要使用os.makedirs()。
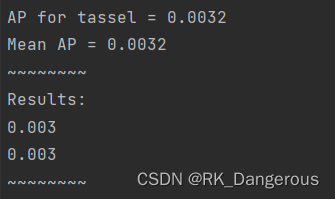
测试结果如下:
ps:因为我担心使用命令行运行比较麻烦,我还是希望能找到直接运行的方法。看了代码之后我了解到,实际上运行的就是Faster-RCNN-endernewton/tools/trainval_net.py文件和test_net.py文件。但是这两个文件都对命令行输入的参数设置了限制,而且通过阅读代码我了解到命令行运行并不像我以为的会影响程序的功能和可视化,所以还是不另辟蹊径了。