文章目录
- DSL操作
- 索引操作
- 新建索引
- 查询索引
- 查看所有索引
- 删除索引
- 映射操作
- 创建映射
- 查看映射
- 索引映射关联(同创建映射类似)
- 文档操作
- 创建文档
- 查询指定ID文档
- 查询所有文档
- 全局修改文档
- 局部修改文档
- 删除文档
- 条件删除
- 数据搜索
- 数据准备
- 条件查询(match)
- 多字段条件查询(multi_match)
- 关键字精确查询(term)
- 多关键字精确查询(terms)
- 过滤字段(_source)
- 组合查询(bool 与或非)
- 范围查询(range)
- 模糊查询(fuzzy)
- 字段排序(sort)
- 高亮查询(highlight)
- 分页查询(其实序号from,单页大小size)
- 聚合查询(aggs)
- State 聚合
- 索引模板
- 创建模版
- 查看模板
- 验证模板是否存在
- 创建索引
- 删除模版
DSL操作
索引操作
ES的索引与SQL的表很类似
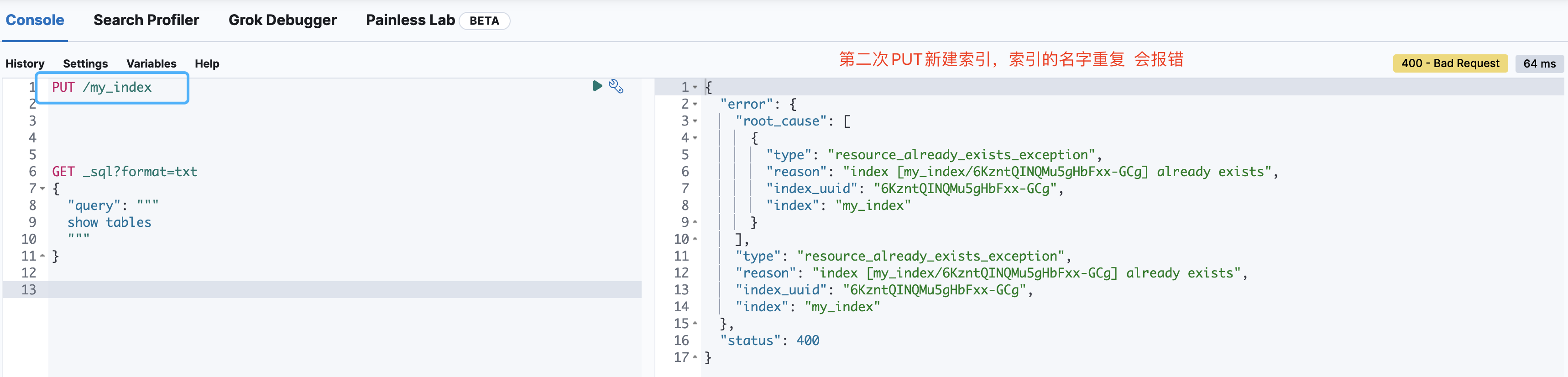
新建索引
PUT /my_index
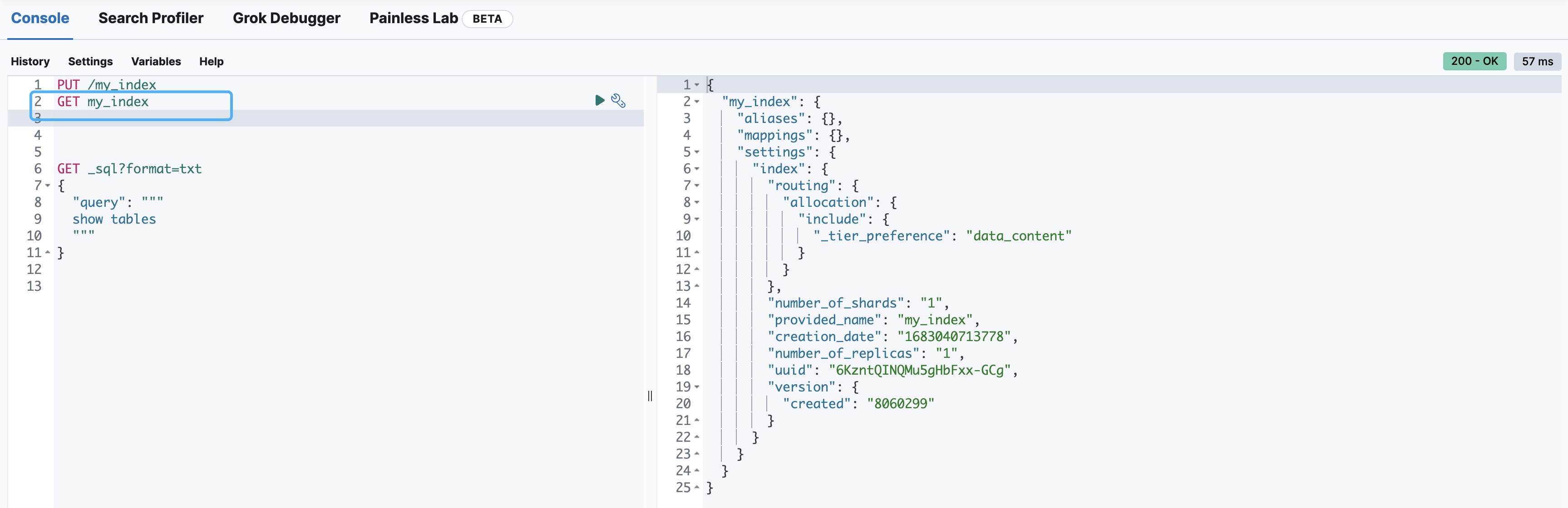
查询索引
# 如果查询的索引未存在,会返回错误信息
GET my_index
查看所有索引
GET _cat/indices
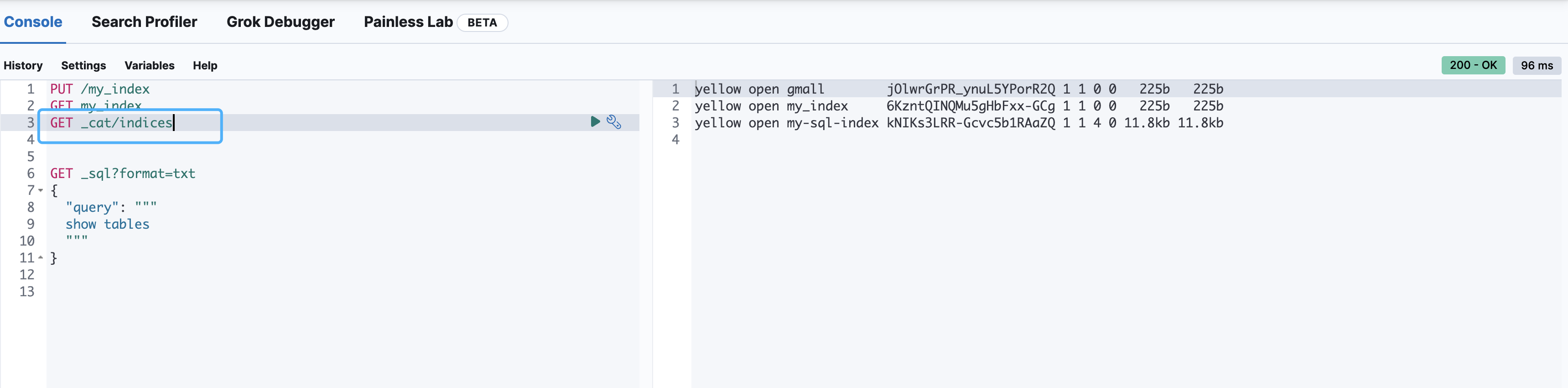
这里的查询结果表示索引的状态信息,按顺序数据表示结果如下:
| 内容 | 含义 | 具体描述 |
|---|---|---|
| yellow | 单点正常 | 当前服务器健康状态: green(集群完整) yellow(单点正常、集群不完整) red(单点不正常) |
| open | status | 索引打开、关闭状态 |
| my_index | index | 索引名 |
| 6KzntQINQMu5gHbFxx-GCg | uuid | 索引统一编号 |
| 1 | pri | 主分片数量 |
| 1 | rep | 副本数量 |
| 0 | docs.count | 可用文档数量 |
| 0 | docs.deleted | 文档删除状态(逻辑删除) |
| 225b | store.size | 主分片和副分片整体占空间大小 |
| 225b | pri.store.size | 主分片占空间大小 |
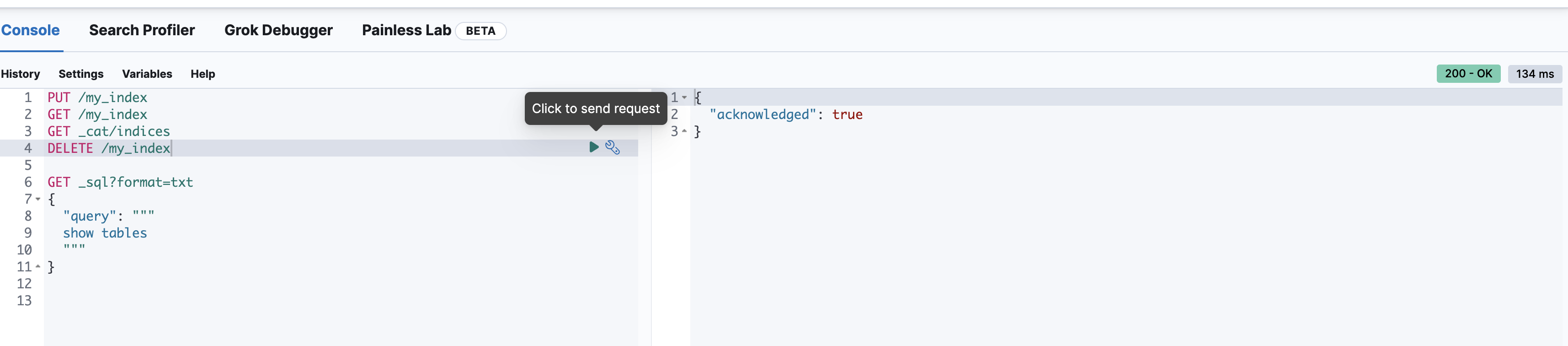
删除索引
# 如果删除一个不存在的索引,那么会返回错误信息
DELETE /my_index
映射操作
创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。
创建映射
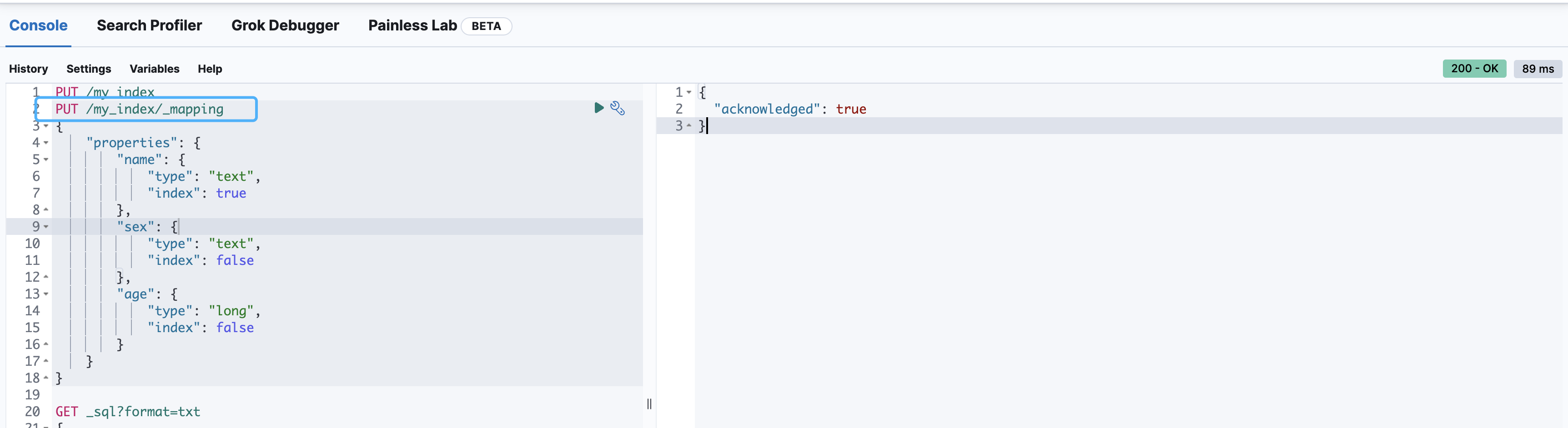
PUT /my_index/_mapping
{
"properties": {
"name": {
"type": "text",
"index": true
},
"sex": {
"type": "text",
"index": false
},
"age": {
"type": "long",
"index": false
}
}
}
-
字段名:任意填写,例如name、sex、age
-
数据类型(type)
- String 类型,分两种
- text:可分词
- keyword:不可分词,数据会作为完整字段进行匹配,精准匹配的
- Numerical:数值类型,分两类
- 基本数据类型:long、integer、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
- Date:日期类型
- Array:数组类型
- Object:对象
- String 类型,分两种
-
是否索引(index)
默认true,即字段会被索引
- true:字段会被索引,则可以用来进行搜索
- false:字段不会被索引,不能用来搜索
-
是否独立存储(store)
默认为false
原始的文本会存储在_source 里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置"store": true 即可,获取独立存储的字段要比从_source 中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置。
-
分词器(analyzer)
这里的 ik_max_word 即使用 ik 分词器,后面会有专门的章节学习
查看映射
GET /my_index/_mapping
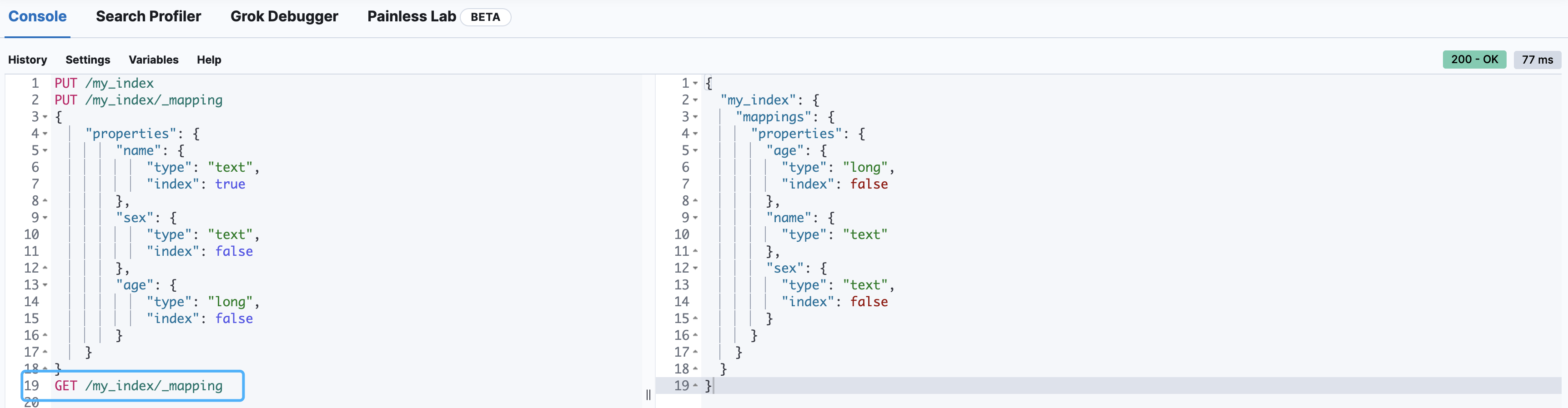
索引映射关联(同创建映射类似)
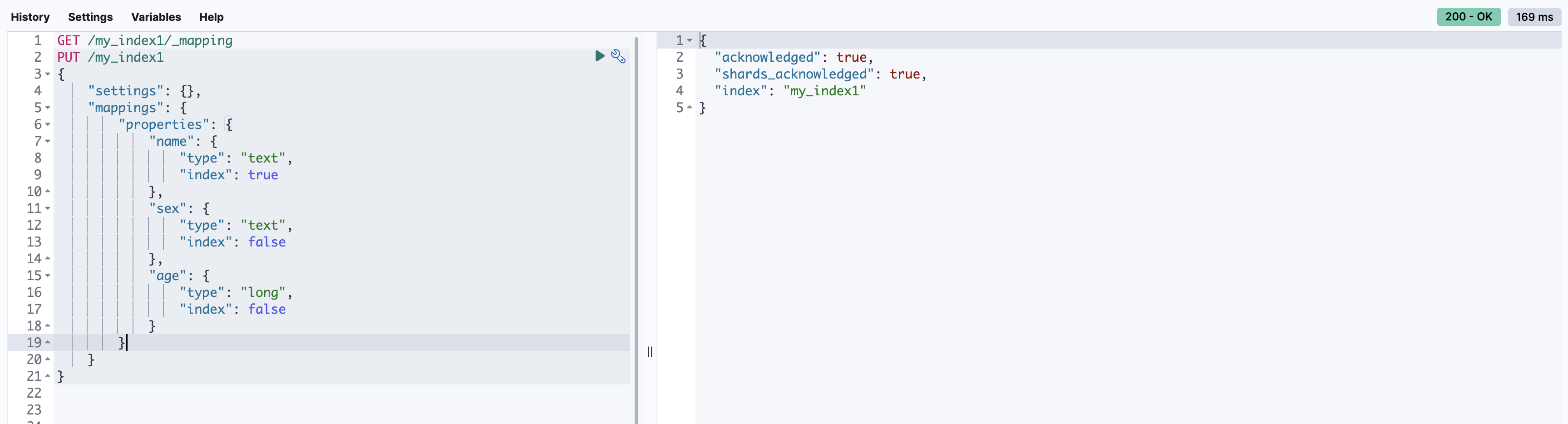
PUT /my_index1
{
"settings": {},
"mappings": {
"properties": {
"name": {
"type": "text",
"index": true
},
"sex": {
"type": "text",
"index": false
},
"age": {
"type": "long",
"index": false
}
}
}
}
文档操作
文档是 ES 软件搜索数据的最小单位, 不依赖预先定义的模式,所以可以将文档类比为表的一行JSON类型的数据。
创建文档
POST my_index/_doc
{
"id": 1001,
"name": "alan",
"age": 18,
"city": "shanghai"
}
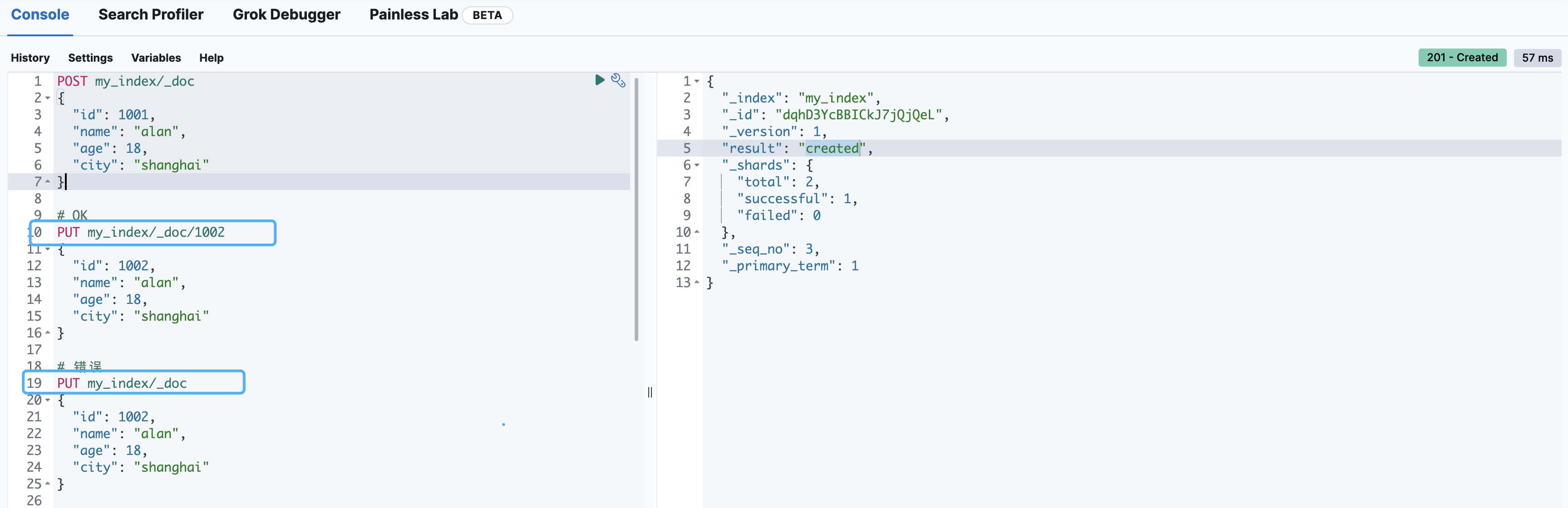
-
my_index:上面创建好的索引 -
多次请求,会生成不同的ID,即不是幂等性的操作,不能使用put请求。
-
POST/PUT /my_index/_doc/1:最后那个1,指定唯一性标识(ID),默认情况下,ES服务器会自动生成一个,在响应体里有体现。 -
如果明确了数据主键,也即是指定了ID,请求方式也可以是PUT请求
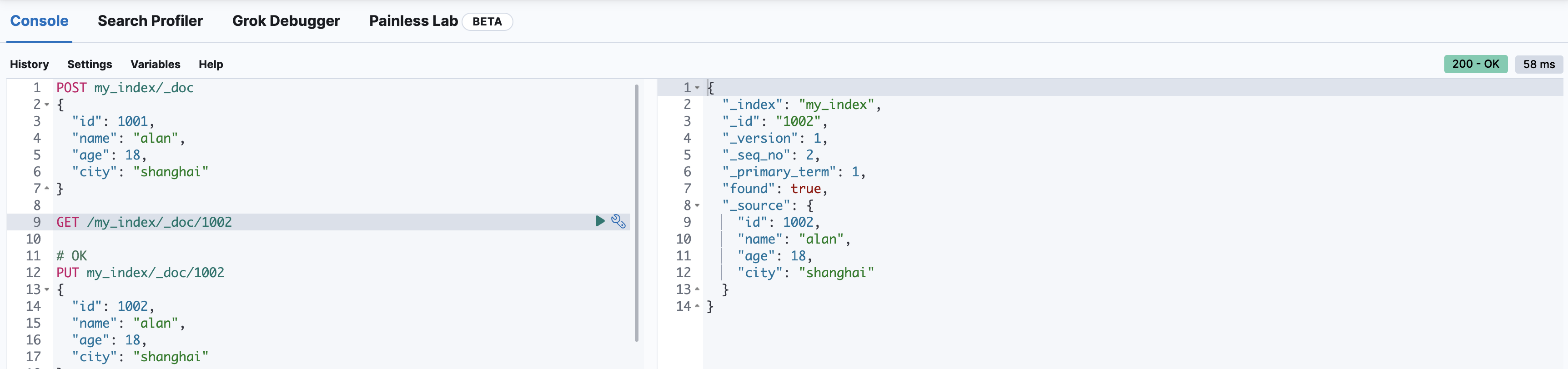
查询指定ID文档
GET /my_index/_doc/1002
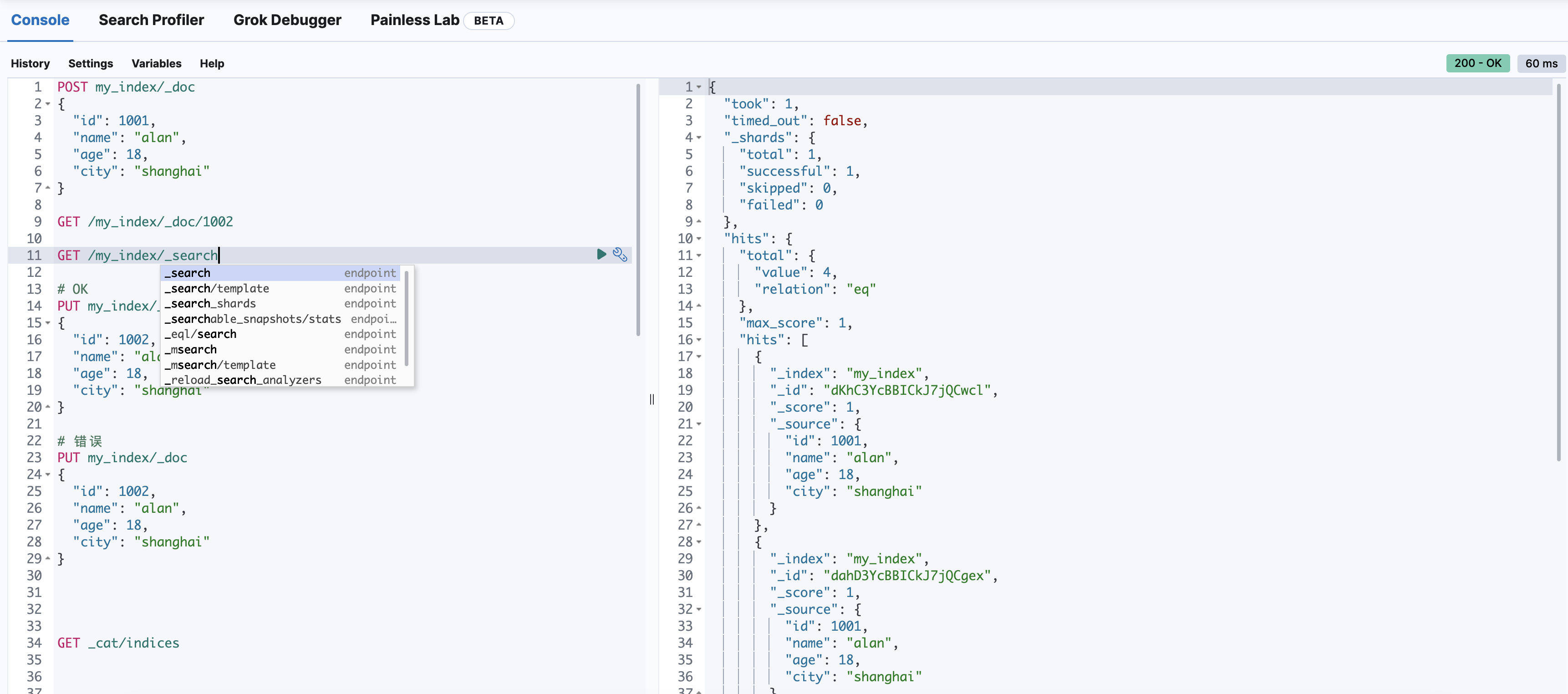
查询所有文档
GET /my_index/_search
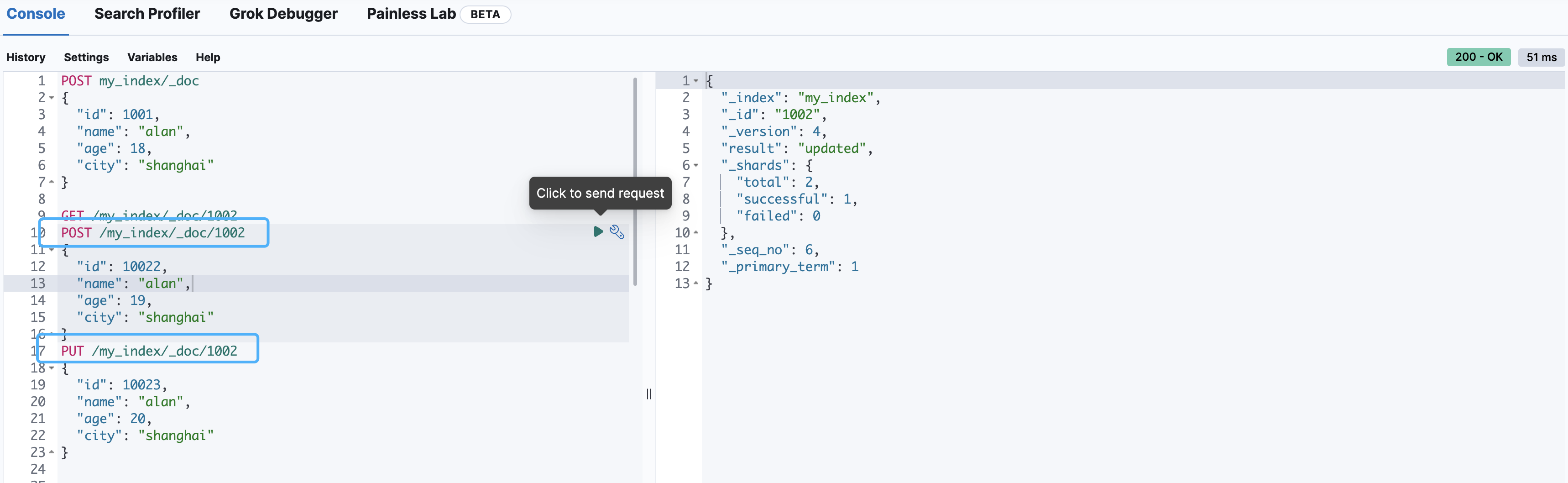
全局修改文档
修改文档本质上和新增文档是一样的,如果存在就修改,如果不存在就新增
POST/PUT /my_index/_doc/1002
{
"id": 10022,
"name": "alan",
"age": 19,
"city": "shanghai"
}
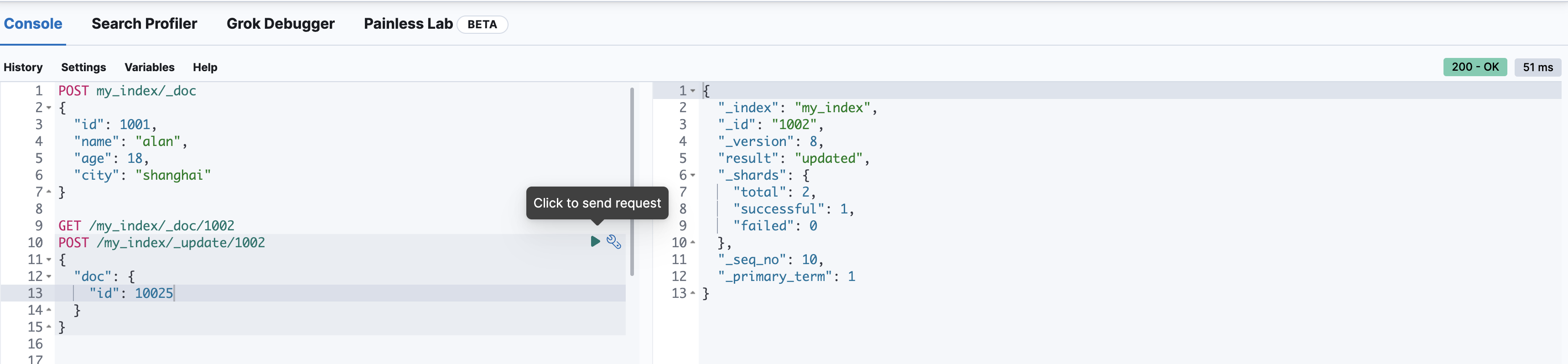
局部修改文档
POST /my_index/_update/1002
{
"doc": {
"id": 10025
}
}
删除文档
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。
DELETE /my_index/_doc/1002
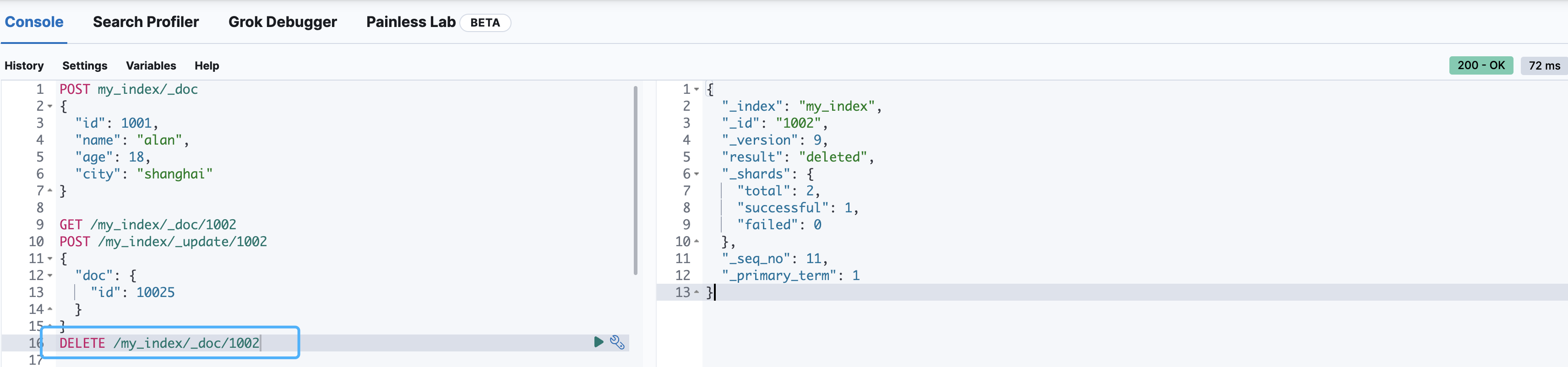
条件删除
POST /my_index/_delete_by_query
{
"query":{
"match":{
"age":18
}
}
}
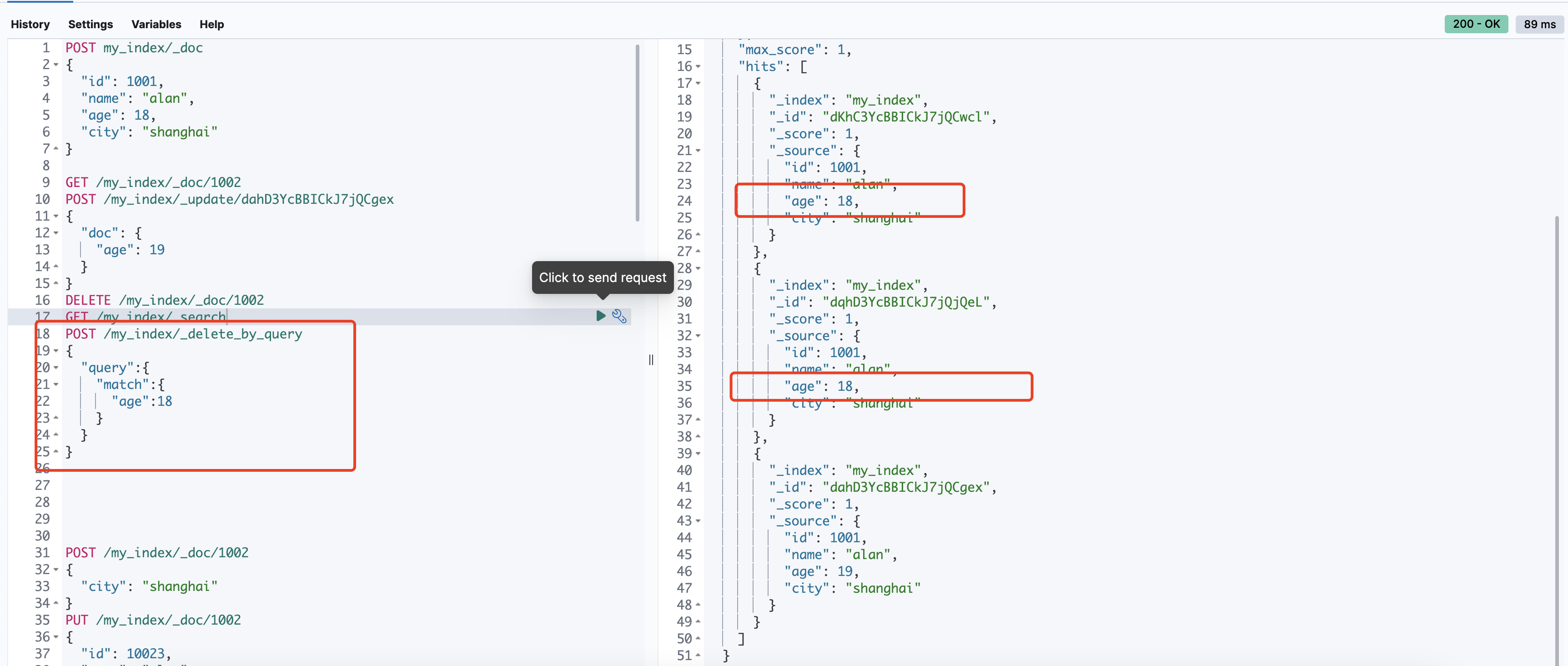
数据搜索
数据准备
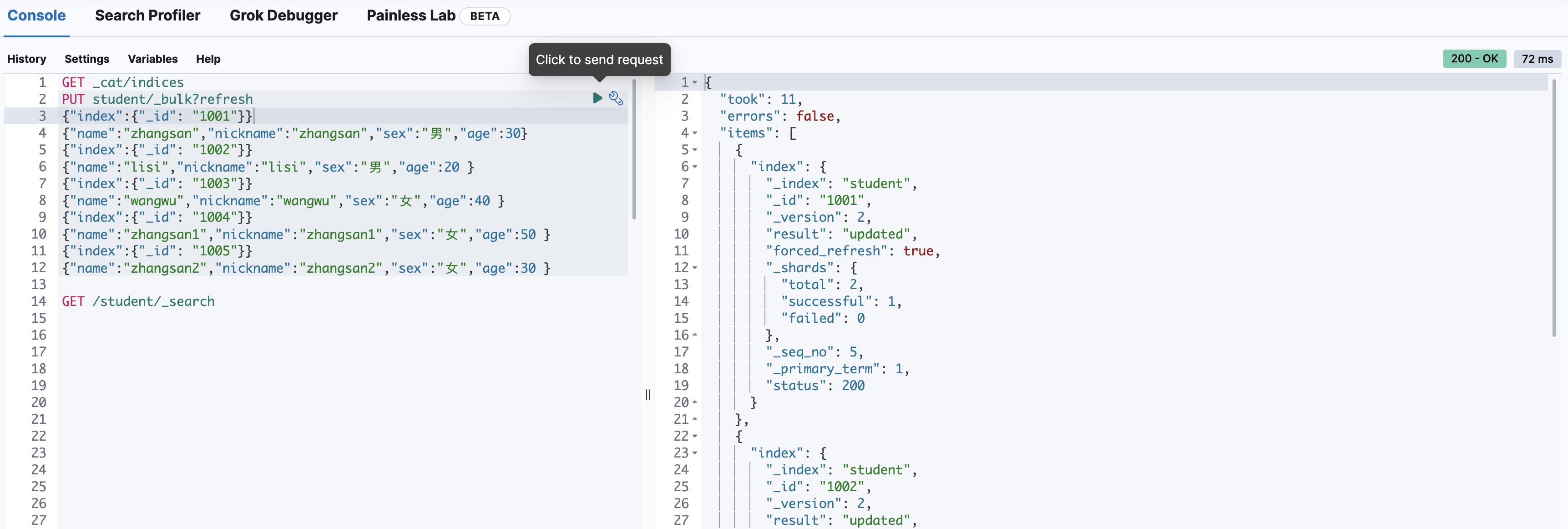
PUT student/_bulk?refresh
{"index":{"_id": "1001"}}
{"name":"zhangsan","nickname":"zhangsan","sex":"男","age":30}
{"index":{"_id": "1002"}}
{"name":"lisi","nickname":"lisi","sex":"男","age":20 }
{"index":{"_id": "1003"}}
{"name":"wangwu","nickname":"wangwu","sex":"女","age":40 }
{"index":{"_id": "1004"}}
{"name":"zhangsan1","nickname":"zhangsan1","sex":"女","age":50 }
{"index":{"_id": "1005"}}
{"name":"zhangsan2","nickname":"zhangsan2","sex":"女","age":30 }
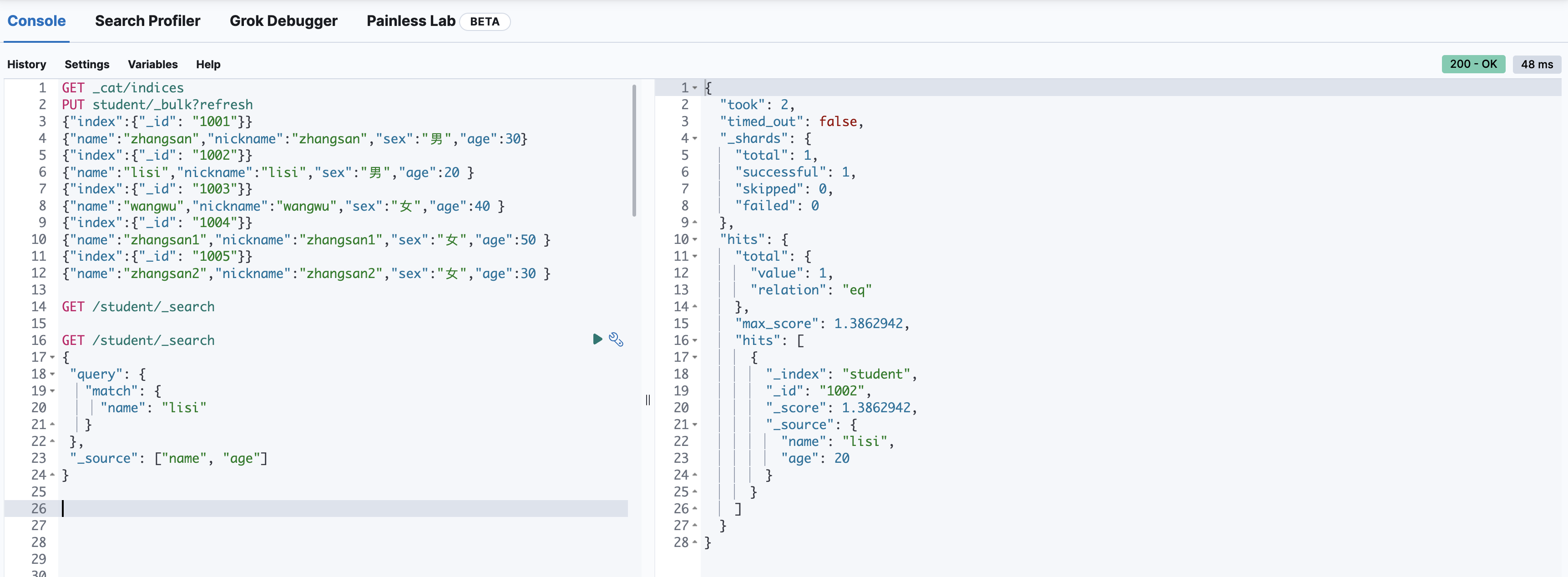
条件查询(match)
match 匹配类型查询,会把查询条件进行分词,然后进行查询,多个词条之间是 or 的关系
# 查所有
GET /student/_search
{
"query": {
"match_all": {}
}
}
# 按条件查询
GET /student/_search
{
"query": {
"match": {
"name": "lisi"
}
},
"_source": ["name", "age"] # 指定查询字段,类似于SQL中的select,默认是*(查所有)
}
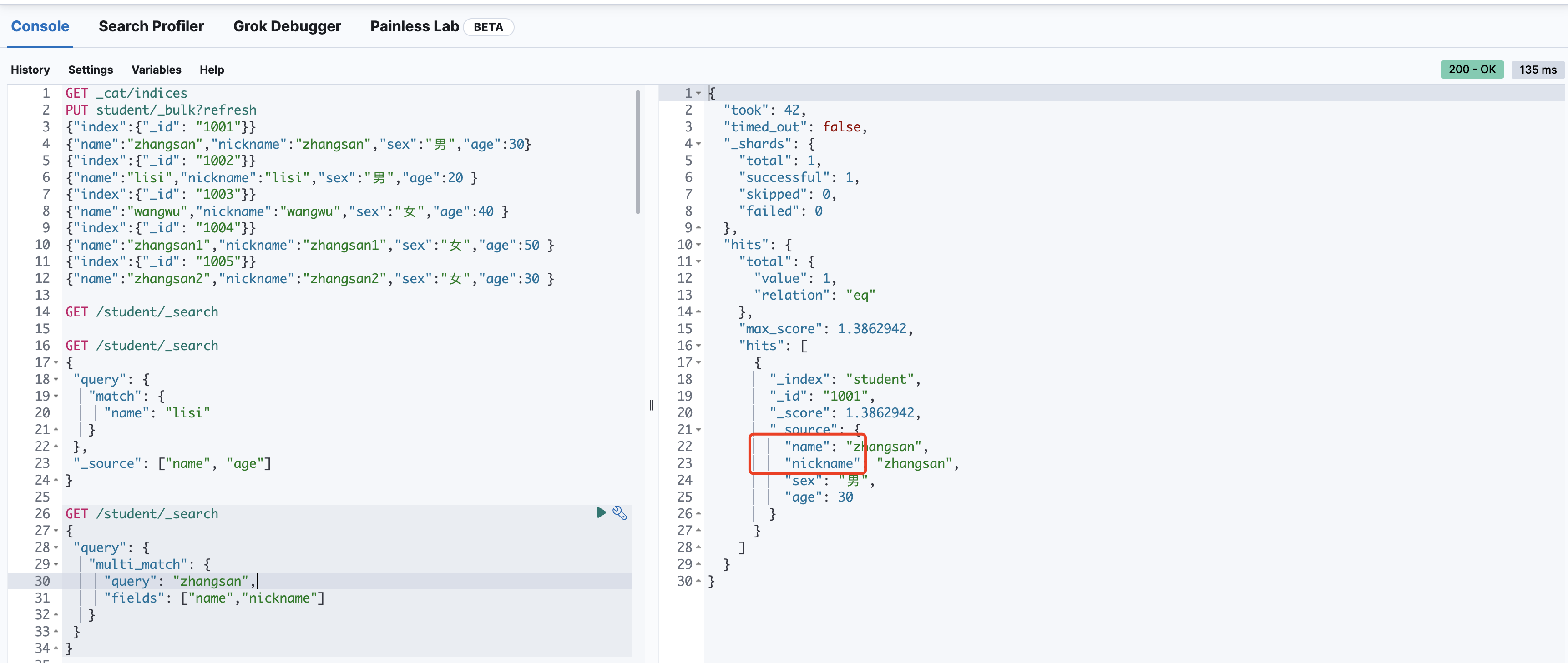
多字段条件查询(multi_match)
GET /student/_search
{
"query": {
"multi_match": {
"query": "zhangsan",
"fields": ["name","nickname"]
}
}
}
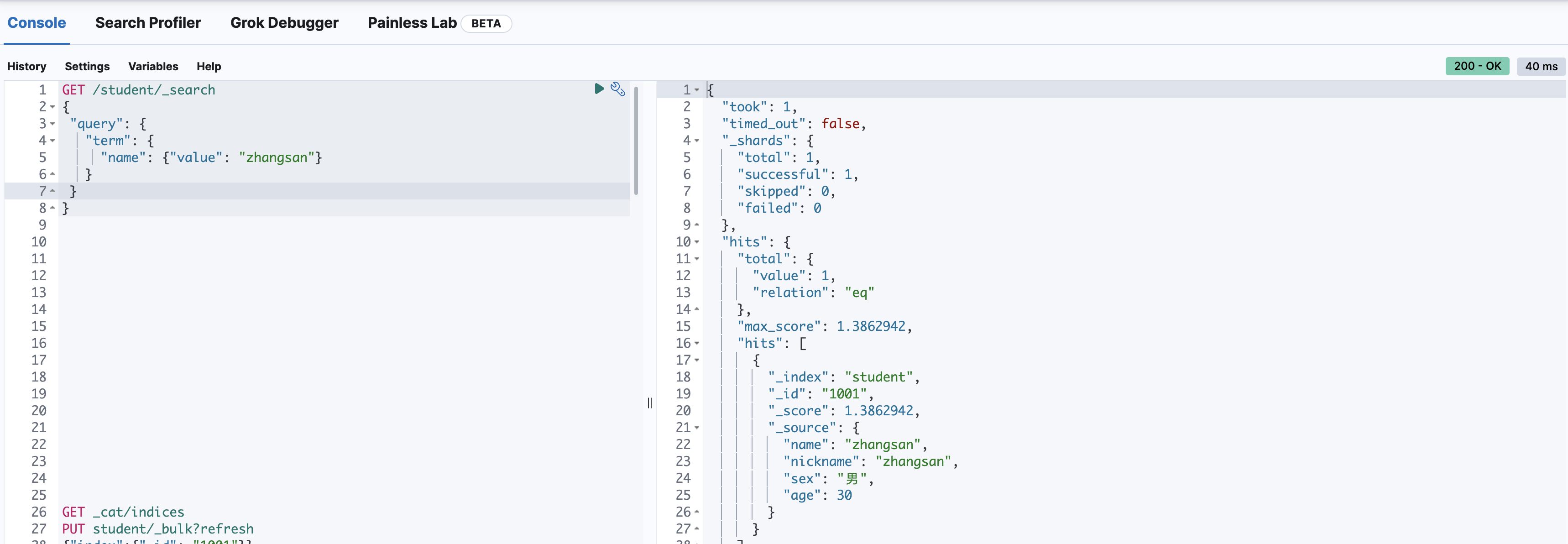
关键字精确查询(term)
GET /student/_search
{
"query": {
"term": {
"name": {"value": "zhangsan"}
}
}
}
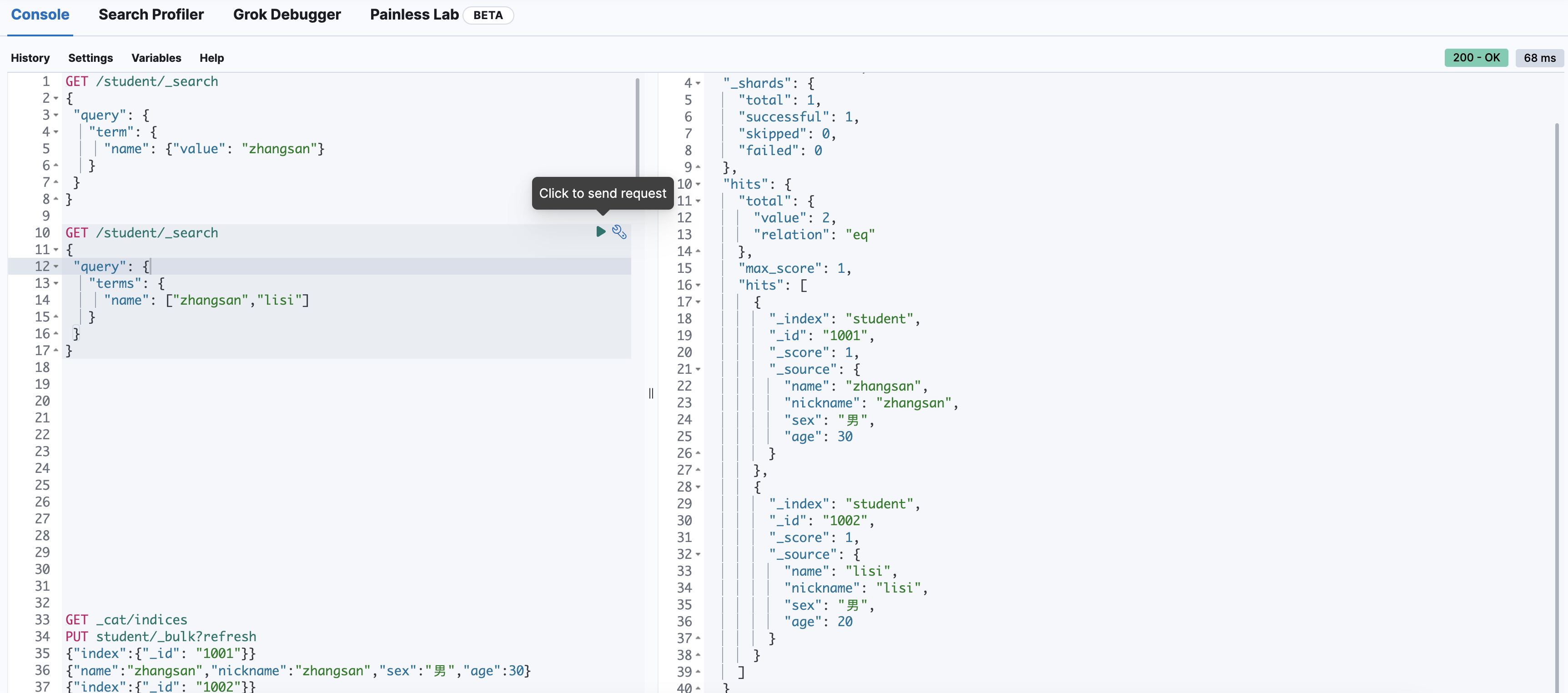
多关键字精确查询(terms)
GET /student/_search
{
"query": {
"terms": {
"name": ["zhangsan","lisi"]
}
}
}
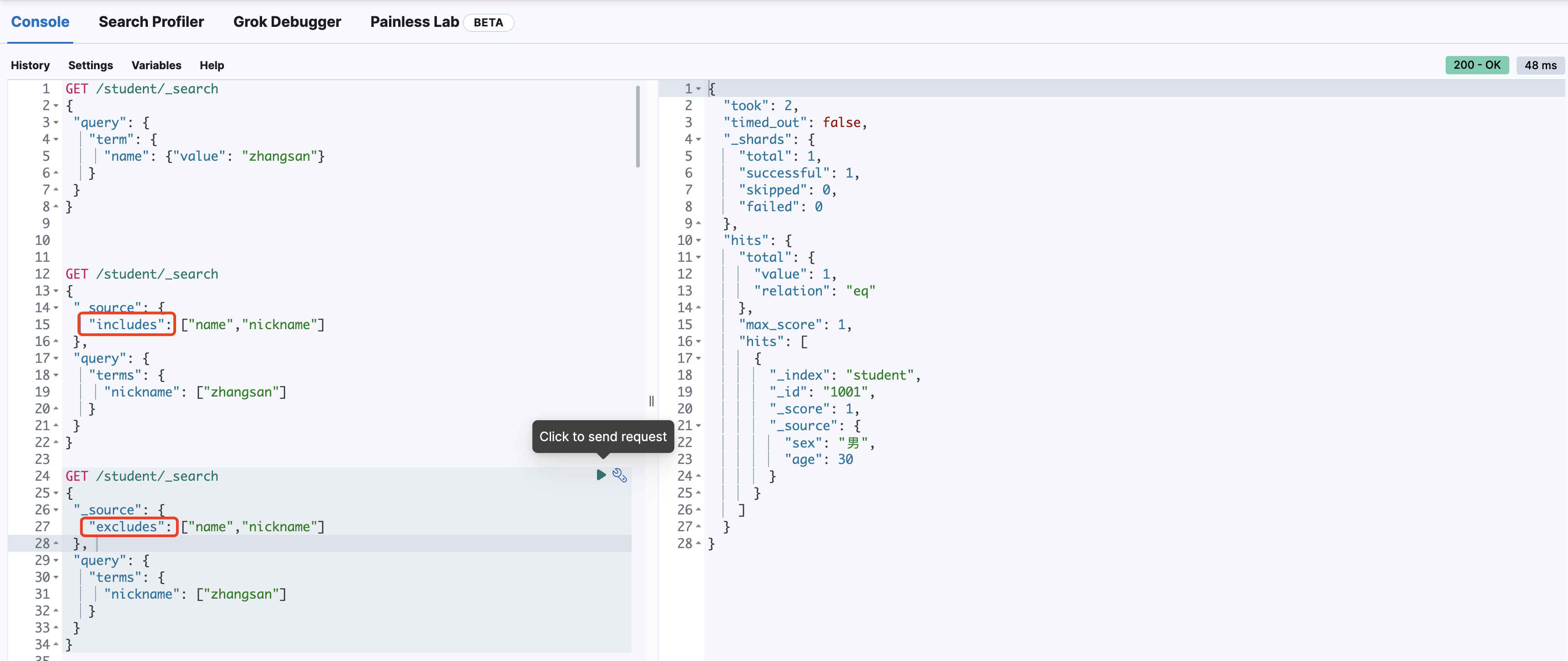
过滤字段(_source)
GET /student/_search
{
"_source": {
"includes": ["name","nickname"]
},
"query": {
"terms": {
"nickname": ["zhangsan"]
}
}
}
GET /student/_search
{
"_source": {
"excludes": ["name","nickname"]
},
"query": {
"terms": {
"nickname": ["zhangsan"]
}
}
}
组合查询(bool 与或非)
GET /student/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "zhangsan"
}
}
],
"must_not": [
{
"match": {
"age": "40"
}
}
],
"should": [
{
"match": {
"sex": "男"
}
}
]
}
}
}
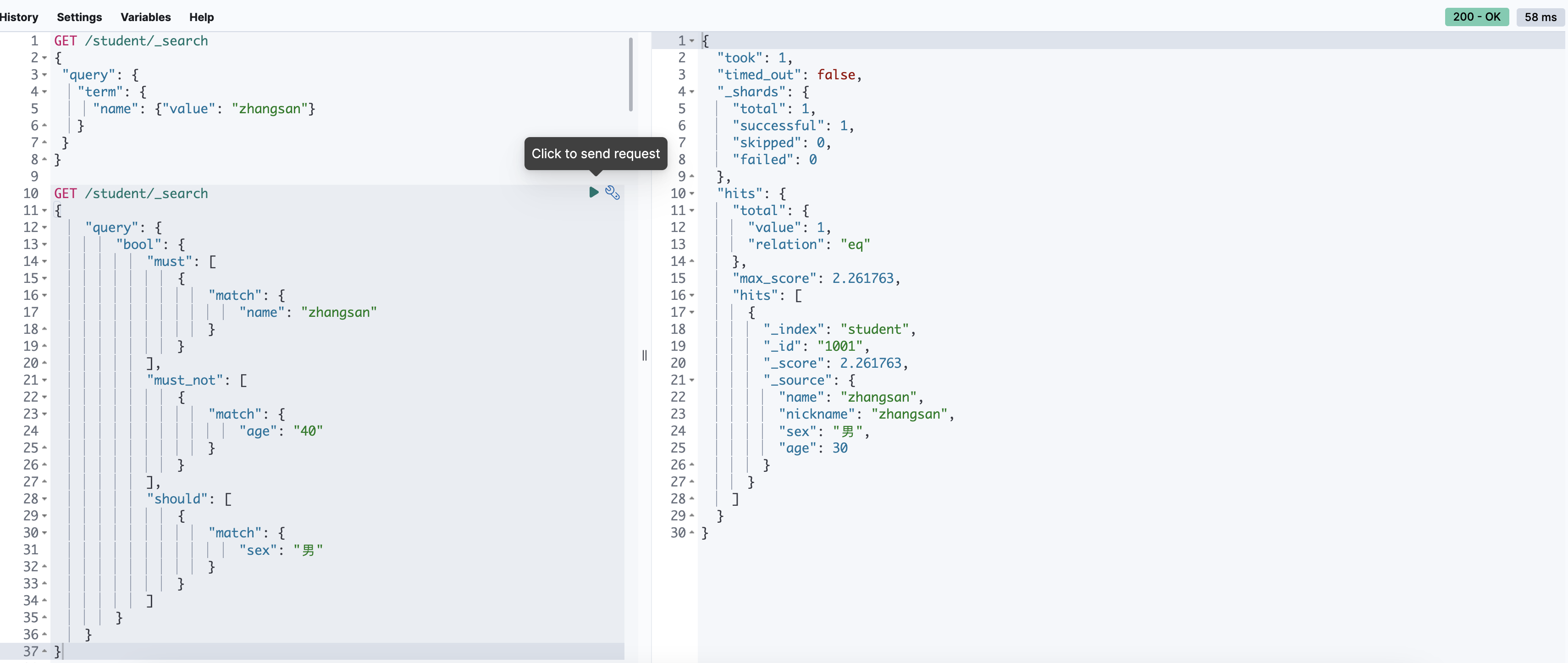
范围查询(range)

GET /student/_search
{
"query": {
"range": {
"age": {
"gte": 30,
"lte": 35
}
}
}
}
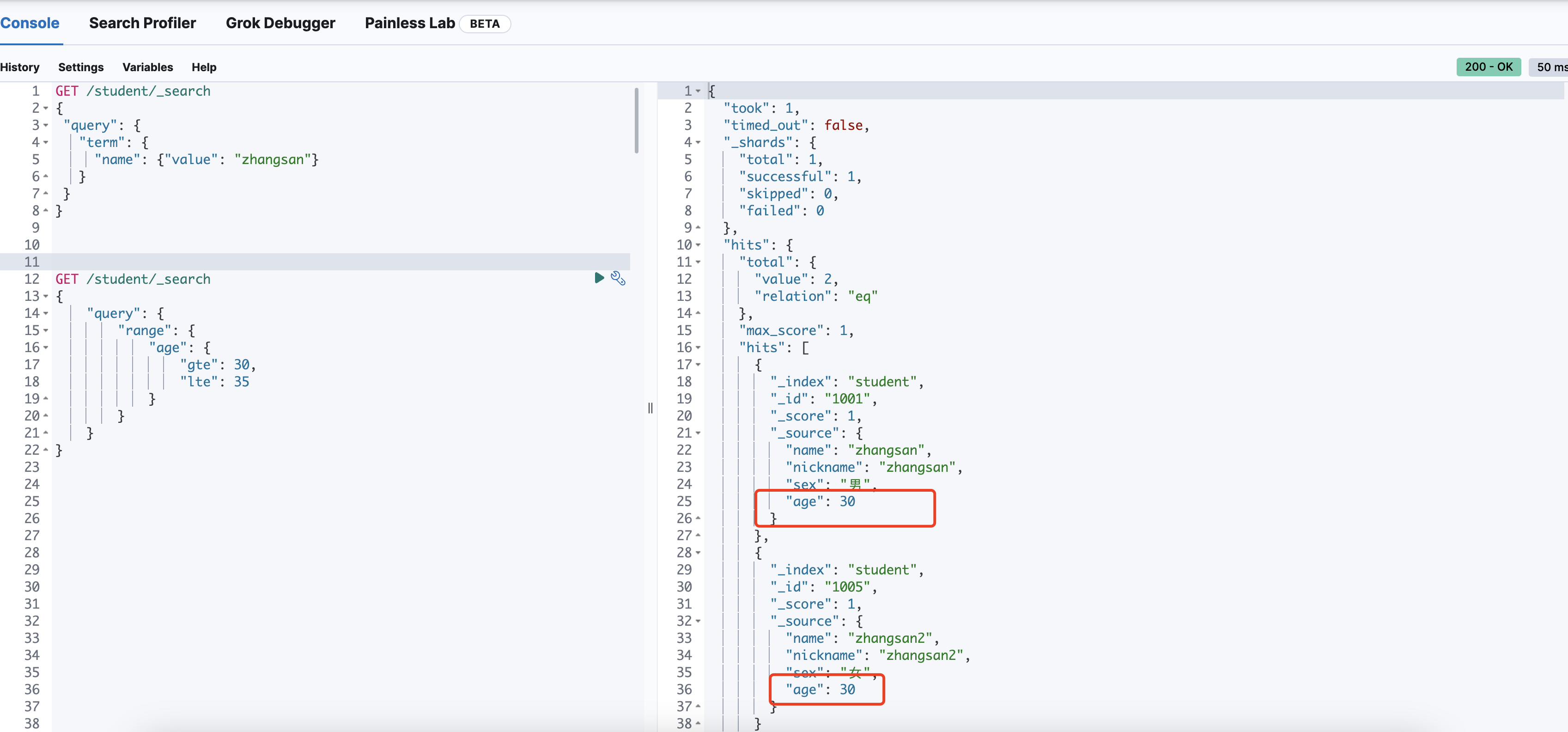
模糊查询(fuzzy)
编辑距离(fuzziness)范围:[0, 1, 2]
编辑距离越高,允许更多的字符更改,这意味着更多的相似词将被包含在匹配中。例如,使用模糊度为1的查询词“apple”将匹配“ale”、“aple”、“aplee”等词。
当被查的字符长度大于2时,并且还没有指定fuzziness,用默认值1.
编辑距离是将一个术语转换为另一个术语所需的一个字符更改的次数。这些更改可以包括:
- 更改字符(box → fox)
- 删除字符(black → lack)
- 插入字符(sic → sick)
- 转置两个相邻字符(act → cat)
GET /student/_search
{
"query": {
"fuzzy": {
"name": {
"value": "zhangsan"
}
}
}
}
GET /student/_search
{
"query": {
"fuzzy": {
"name": {
"value": "zhangsan",
"fuzziness": 0
}
}
}
}
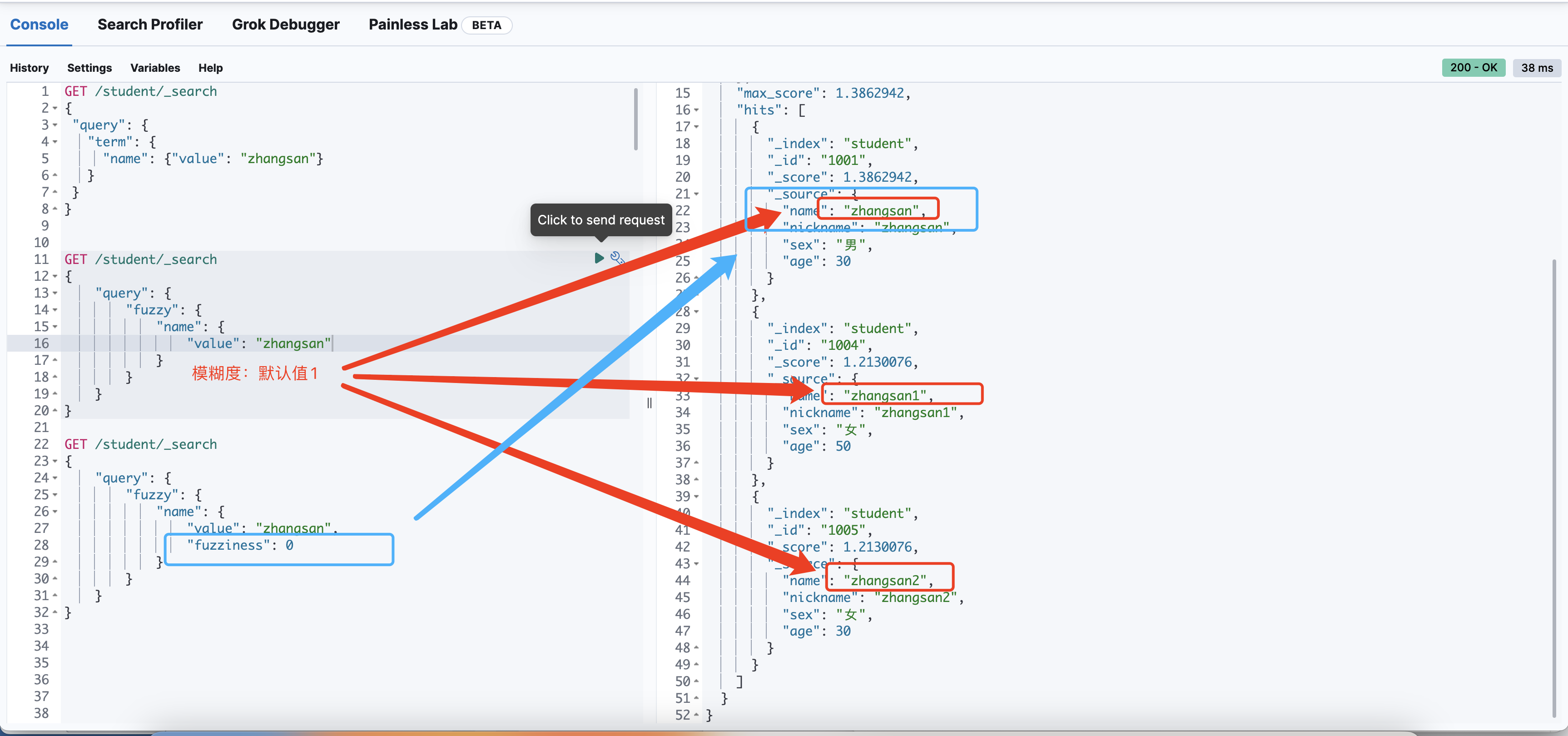
字段排序(sort)
倒序:desc,正序asc
GET /student/_search
{
"query": {
"fuzzy": {
"name": "zhangsan"
}
},
"sort": [
{
"age": {
"order": "desc"
}
},
{
"_score": {
"order": "asc"
}
}
]
}
高亮查询(highlight)
GET /student/_search
{
"query": {
"match": {
"name": "zhangsan"
}
},
"highlight": {
"pre_tags": "<font color='red'>",
"post_tags": "</font>",
"fields": {
"name": {}
}
}
}
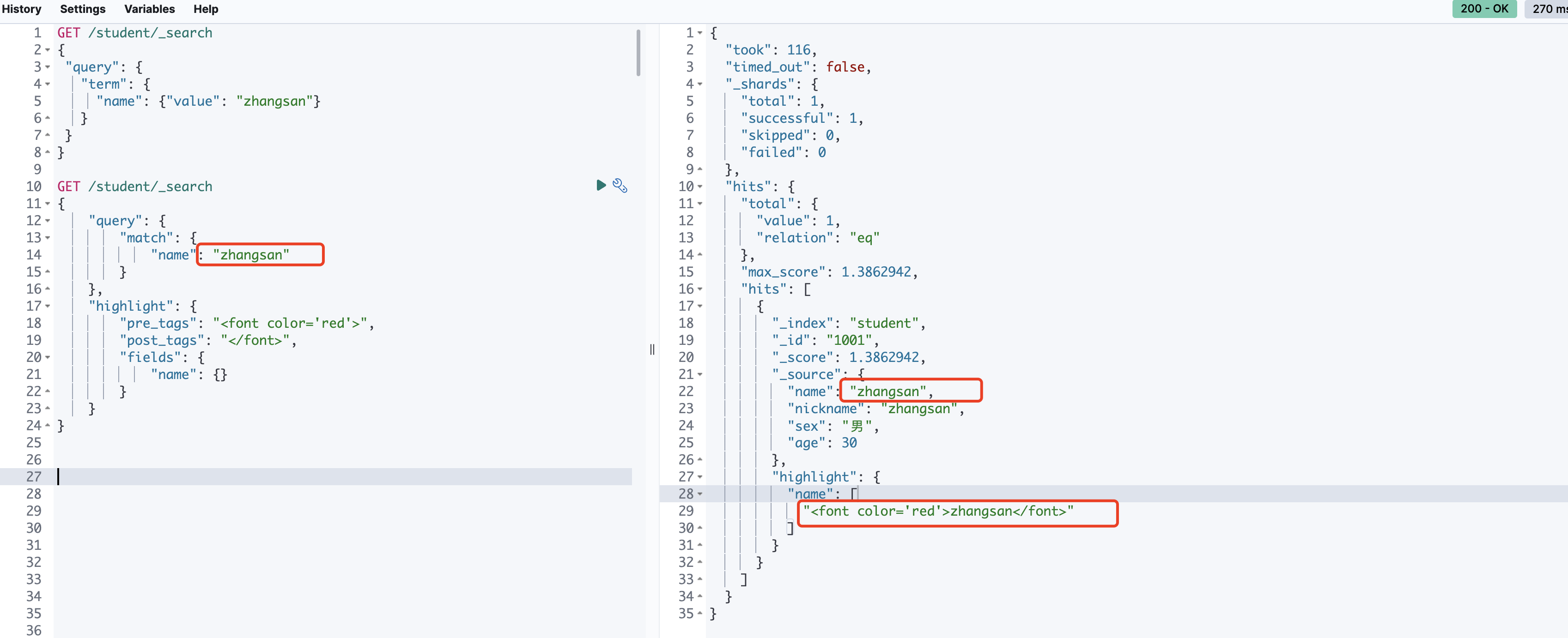
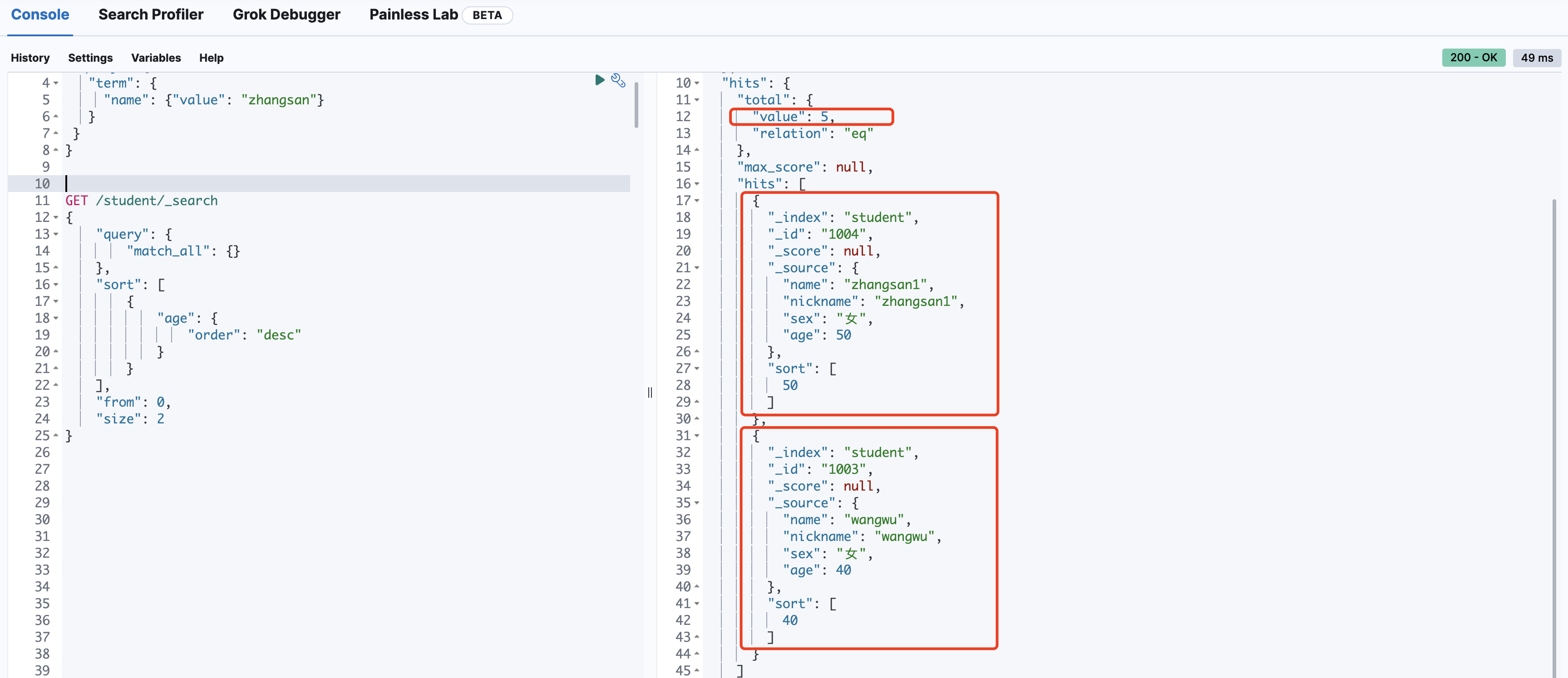
分页查询(其实序号from,单页大小size)
GET /student/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 2
}
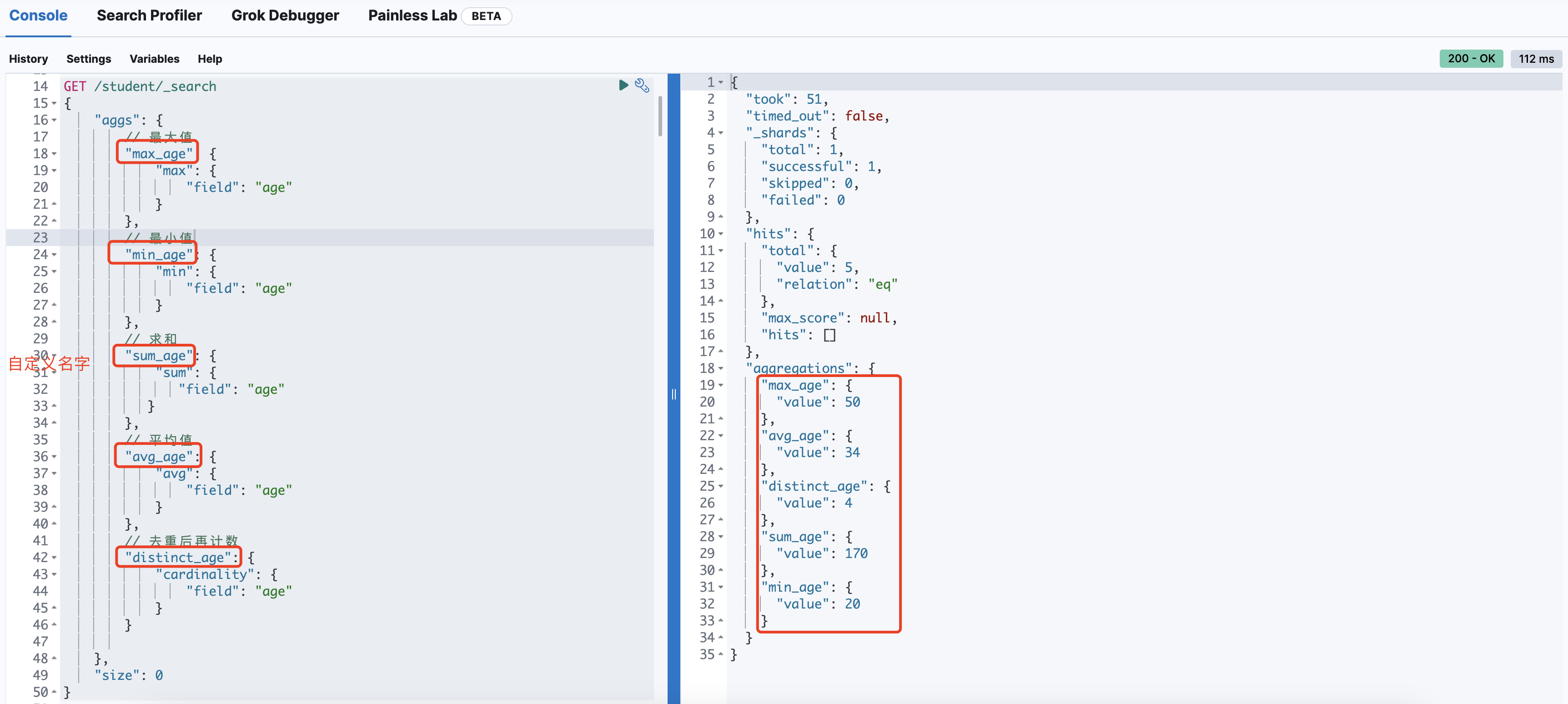
聚合查询(aggs)
# 下面列举了几个常见的聚合函数,更多的自己摸索
GET /student/_search
{
"aggs": {
// 最大值
"max_age": {
"max": {
"field": "age"
}
},
// 最小值
"min_age": {
"min": {
"field": "age"
}
},
// 求和
"sum_age": {
"sum": {
"field": "age"
}
},
// 平均值
"avg_age": {
"avg": {
"field": "age"
}
},
// 去重后再计数
"distinct_age": {
"cardinality": {
"field": "age"
}
}
// topN
"top_age_hits": {
"top_hits": {
"sort": [{
"age":{
"order": "desc"
}
}],
"_source": {
"includes": ["name", "age"]
},
"size": 2 //这个size是控制top_hits显示的条数
}
}
},
"size": 0
}
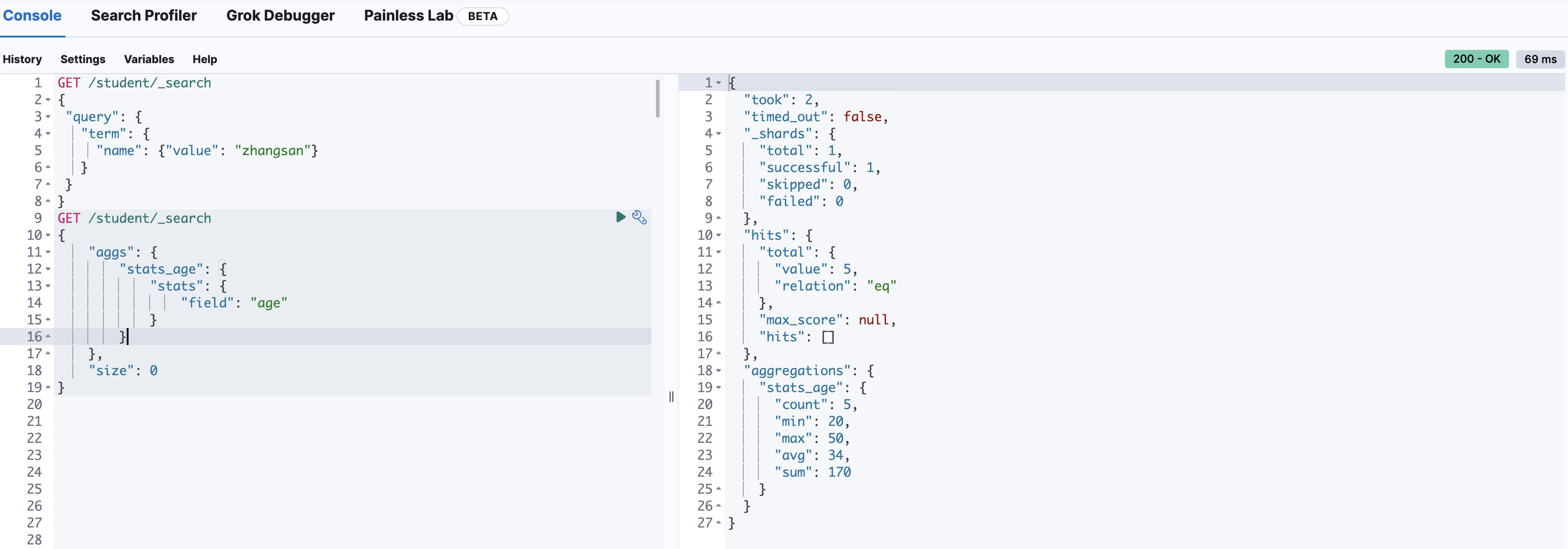
State 聚合
stats关键字对某个字段一次性返回 count,max,min,avg 和 sum 五个指标
GET /student/_search
{
"aggs": {
"stats_age": {
"stats": {
"field": "age"
}
}
},
"size": 0
}
索引模板
在实际开发中,我们可能需要创建不止一个索引,但是每个索引或多或少都有一些共性。
elasticsearch 在创建索引的时候,就引入了模板的概念,你可以先设置一些通用的模板,在创建索引的时候,elasticsearch 会先根据你创建的模板对索引进行设置。
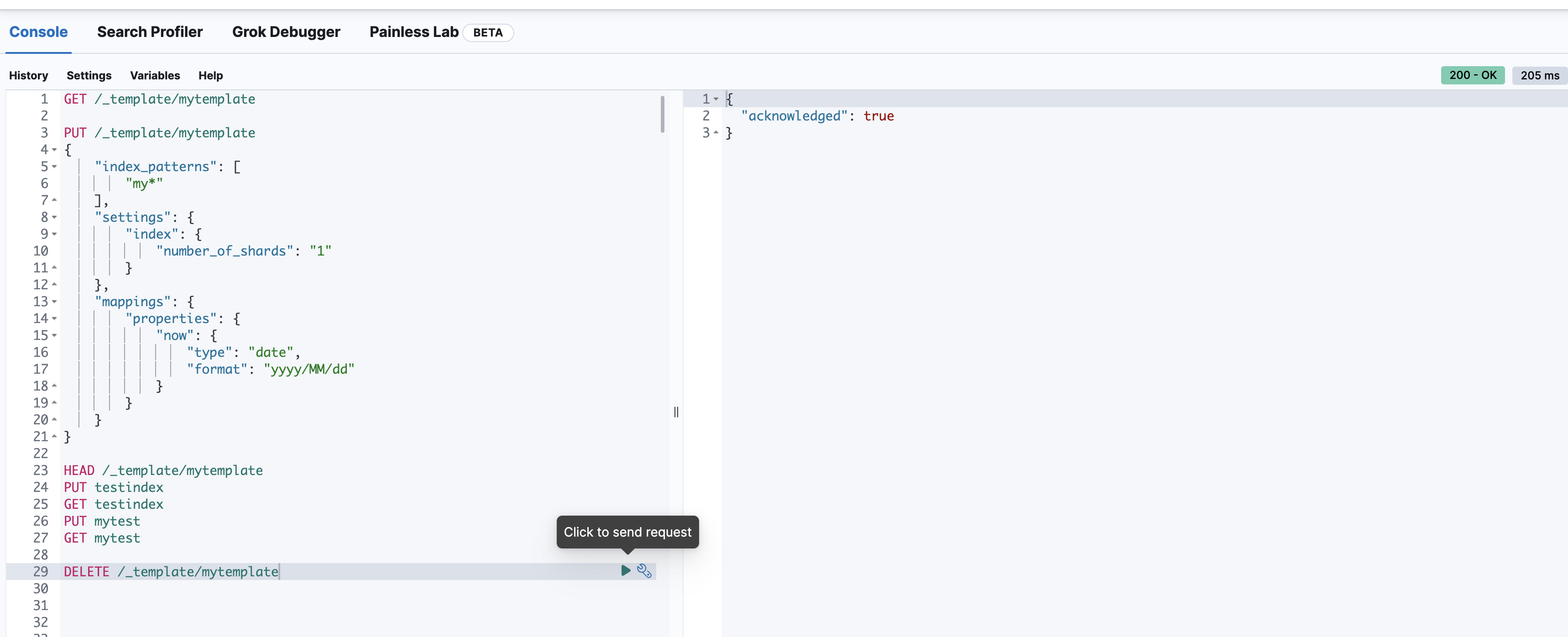
创建模版
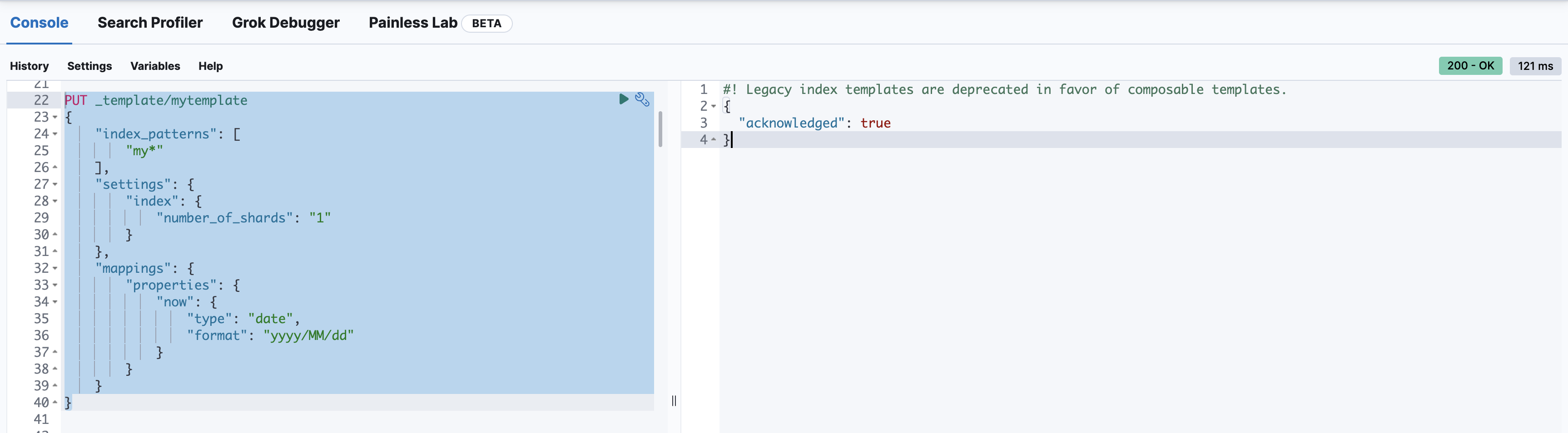
PUT _template/mytemplate
{
"index_patterns": [
"my*"
],
"settings": {
"index": {
"number_of_shards": "1"
}
},
"mappings": {
"properties": {
"now": {
"type": "date",
"format": "yyyy/MM/dd"
}
}
}
}
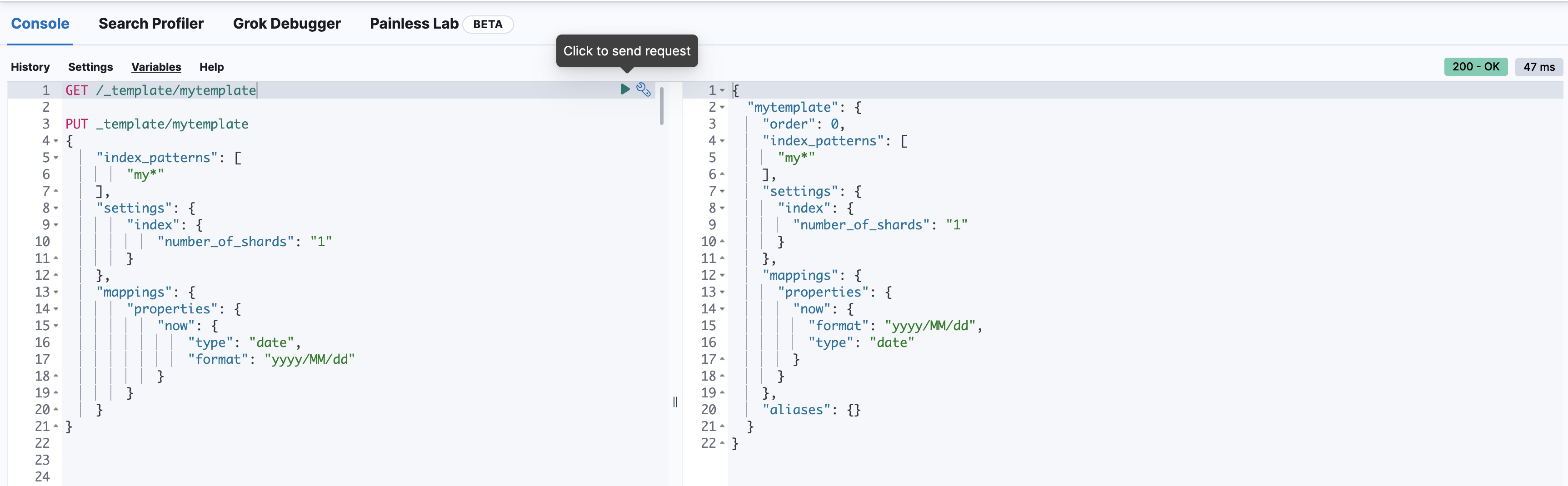
查看模板
GET /_template/mytemplate
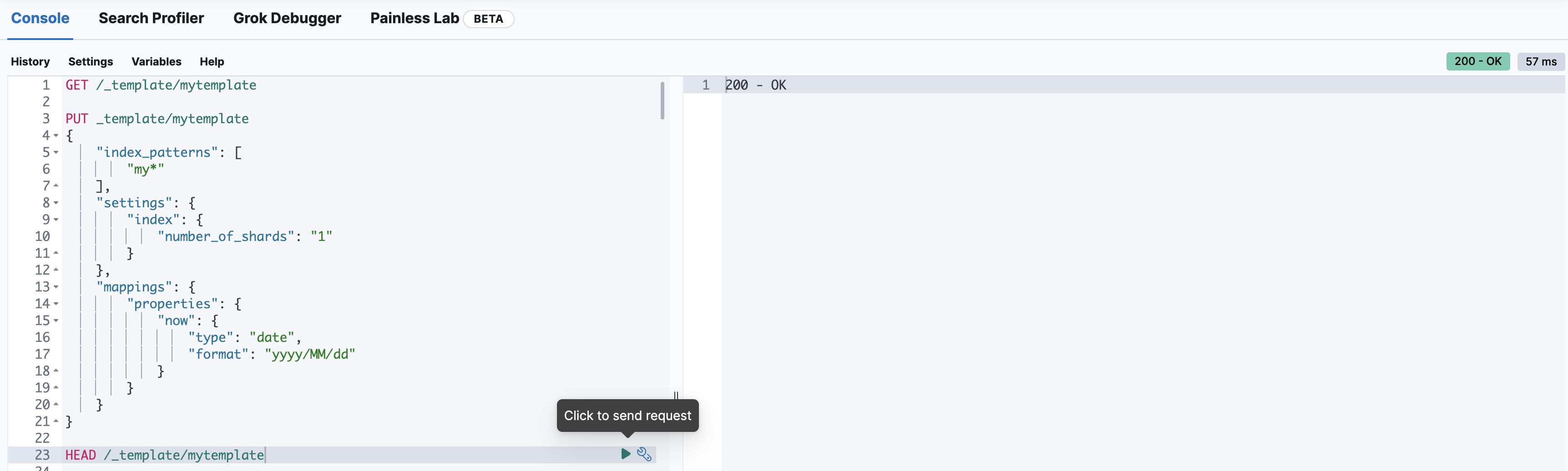
验证模板是否存在
HEAD /_template/mytemplate
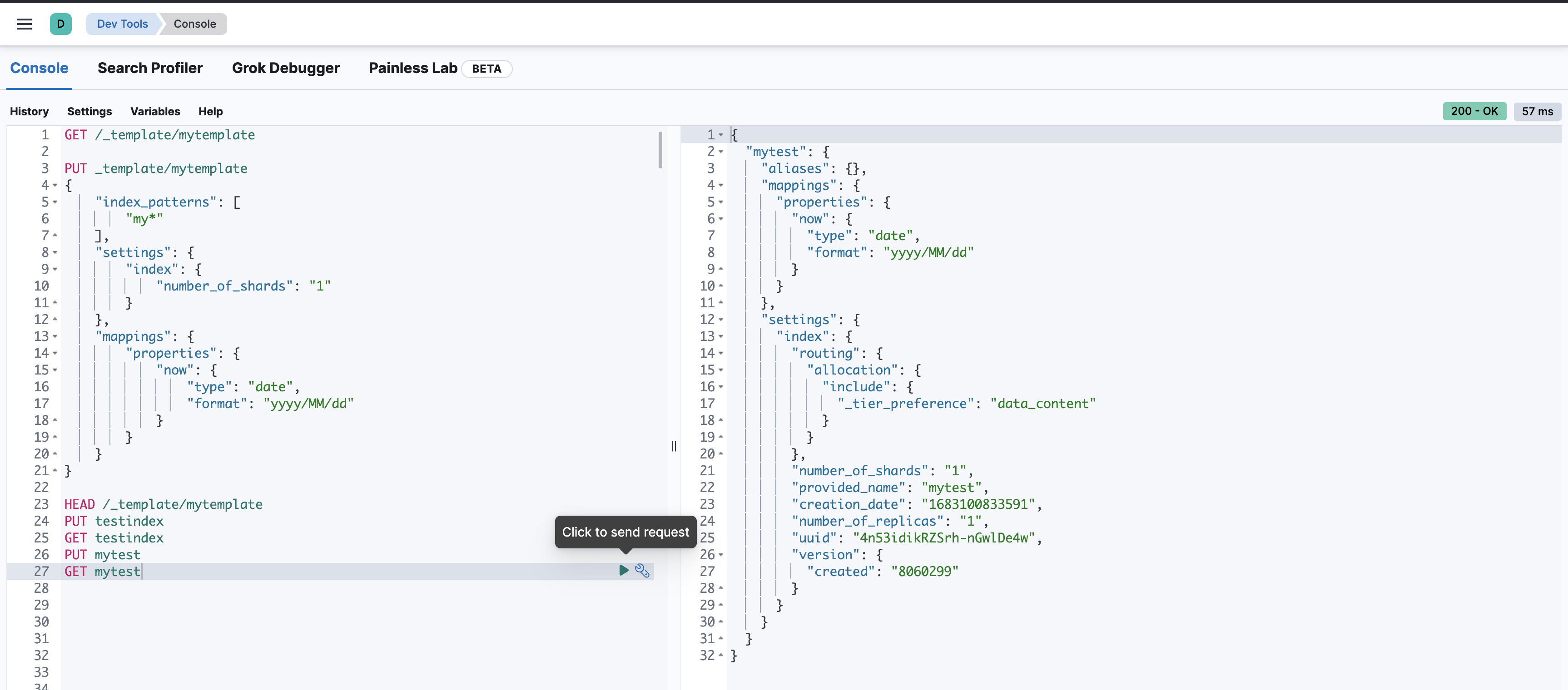
创建索引
PUT testindex -> 不符合index_patterns的规则,不生效
PUT mytest -> 符合规则,生效
删除模版
DELETE /_template/mytemplate