嵌入式软件开发第三部分,各类常用的数据结构及扩展,良好的数据结构选择是保证程序稳定运行的关键,(1)部分包括数组,链表,栈,队列。(2)部分包括树,堆。(3)部分包括散列表,图。
五 树
树是由结点或顶点和边组成的(可能是非线性的)且不存在着任何环的一种数据结构。
特点:
- 每个结点有零个或多个子结点
- 没有父结点的结点为根节点;
- 每个非根结点有且只有一个父结点
- 除了根结点外,每个子结点可以分为多个不相交的子树
树是一种非常重要的数据结构,广泛应用于各个领域。以下是树的一些应用场景:
文件系统:计算机中的文件系统通常是树形结构,其中根节点代表文件系统的根目录,每个节点代表一个目录或一个文件,子节点表示该节点的子目录或者文件。
数据库索引:数据库索引通常是以树的形式组织,不同的索引类型对应了不同的树结构,例如B-tree索引、B+tree索引等。
编译器:编译器通常使用语法树来表示代码的语法结构,并将其转换为可执行代码。
网络路由:网络路由通常使用树型结构来表达网络拓扑关系,例如Internet中的AS路由。
人工智能:决策树和搜索树是人工智能中的重要算法,用于问题求解和决策制定。
种类
1 无序树: 树中任意节点的子结点之间没有顺序关系,这种树称为无序树,也称为自由树;
2 有序树: 树中任意节点的子结点之间有顺序关系,这种树称为有序树;
3 二叉树: 每个节点最多含有两个子树的树称为二叉树;
4 完全二叉树: 完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树
5 满二叉树:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且结点总数是(2^k) -1 ,则它就是满二叉树。
6 霍夫曼树: 带权路径最短的二叉树称为哈夫曼树或最优二叉树;
树

树的相关概念
节点的度:一个节点含有的子树的个数称为该节点的度; 如上图:A的为3
叶节点或终端节点:度为0的节点称为叶节点; 如上图:E、F、G、H、I节点为叶节点
非终端节点或分支节点:度不为0的节点; 如上图:B、C、D节点为分支节点
双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 如上图:B是A的孩子节点
兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图:B、C是兄弟节点
树的度:一棵树中,最大的节点的度称为树的度; 如上图:树的度为3
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
树的高度或深度:树中节点的最大层次; 如上图:树的高度为3
堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:E、G互为兄弟节点
节点的祖先:从根到该节点所经分支上的所有节点;如上图:A是所有节点的祖先
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙
森林:由m(m>0)棵互不相交的树的集合称为森林;
树的表示方法
双亲表示法,孩子表示法,孩子双亲表示法,孩子兄弟表示法(最常用)
//左孩子右兄弟表示法
typedef int TreeDataType;//数据类型
struct TreeNode
{
TreeDataType data;// 指向数据域
struct TreeNode* child;// 指向第一个孩子结点
struct TreeNode* brother;// 指向其下一个兄弟结点
}

二叉树的性质

二叉树的存储形式
1. 顺序存储
顺序结构存储就是使用数组来存储,一般使用数组只适合表示完全二叉树,因为不是完全二叉树会有空间的浪费。而现实中使用中只有堆才会使用数组来存储。二叉树顺序存储在物理上是一个数组,在逻辑上是一颗二叉树


2. 链式存储
二叉树的链式存储结构是指,用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。 通常的方法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址
typedef int BTDataType;
// 二叉链
struct BinaryTreeNode
{
struct BinTreeNode* _pLeft; // 指向当前节点左孩子
struct BinTreeNode* _pRight; // 指向当前节点右孩子
BTDataType _data; // 当前节点值域
}
满二叉树:除在二叉树最下层的节点外,每层的节点都有两个子节点。

利用栈实现满二叉树
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 50
// 定义二叉树节点结构体
typedef struct node {
int data;
struct node *left;
struct node *right;
} Node;
// 定义栈结构体
typedef struct stack {
int top;
Node *data[MAX_SIZE];
} Stack;
// 初始化栈
void init_stack(Stack *s) {
s->top = -1;
}
// 判断栈是否为空
int is_empty(Stack *s) {
return s->top == -1;
}
// 判断栈是否已满
int is_full(Stack *s) {
return s->top == MAX_SIZE - 1;
}
// 入栈操作
void push(Stack *s, Node *node) {
if (is_full(s)) {
printf("Stack overflow\n");
exit(1);
}
s->data[++(s->top)] = node;
}
// 出栈操作
Node *pop(Stack *s) {
if (is_empty(s)) {
printf("Stack underflow\n");
exit(1);
}
return s->data[(s->top)--];
}
// 创建满二叉树
Node* create_full_binary_tree(int level, int value) {
Stack s;
init_stack(&s);
Node *root = (Node*)malloc(sizeof(Node));
root->data = value;
root->left = NULL;
root->right = NULL;
push(&s, root);
for (int i = 2; i <= level; i++) {
while (!is_empty(&s)) {
Node *node = pop(&s);
node->left = (Node*)malloc(sizeof(Node));
node->left->data = value;
node->left->left = NULL;
node->left->right = NULL;
push(&s, node->left);
node->right = (Node*)malloc(sizeof(Node));
node->right->data = value;
node->right->left = NULL;
node->right->right = NULL;
push(&s, node->right);
}
}
return root;
}
// 先序遍历满二叉树
void preorder_traversal(Node *root) {
if (root != NULL) {
printf("%d ", root->data);
preorder_traversal(root->left);
preorder_traversal(root->right);
}
}
int main() {
Node *root = create_full_binary_tree(3, -1);
printf("Preorder traversal: ");
preorder_traversal(root);
printf("\n");
return 0;
}
利用队列实现满二叉树
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 50
// 定义二叉树节点结构体
typedef struct node {
int data;
struct node *left;
struct node *right;
} Node;
// 定义队列结构体
typedef struct queue {
int front;
int rear;
Node *data[MAX_SIZE];
} Queue;
// 初始化队列
void init_queue(Queue *q) {
q->front = 0;
q->rear = -1;
}
// 判断队列是否为空
int is_empty(Queue *q) {
return q->front > q->rear;
}
// 判断队列是否已满
int is_full(Queue *q) {
return q->rear == MAX_SIZE - 1;
}
// 入队操作
void enqueue(Queue *q, Node *node) {
if (is_full(q)) {
printf("Queue overflow\n");
exit(1);
}
q->data[++(q->rear)] = node;
}
// 出队操作
Node *dequeue(Queue *q) {
if (is_empty(q)) {
printf("Queue underflow\n");
exit(1);
}
return q->data[(q->front)++];
}
// 创建满二叉树
Node* create_full_binary_tree(int level, int value) {
Queue q;
init_queue(&q);
Node *root = (Node*)malloc(sizeof(Node));
root->data = value;
root->left = NULL;
root->right = NULL;
enqueue(&q, root);
for (int i = 2; i <= level; i++) {
int count = q.rear - q.front + 1;
for (int j = 1; j <= count; j++) {
Node *node = dequeue(&q);
node->left = (Node*)malloc(sizeof(Node));
node->left->data = value;
node->left->left = NULL;
node->left->right = NULL;
enqueue(&q, node->left);
node->right = (Node*)malloc(sizeof(Node));
node->right->data = value;
node->right->left = NULL;
node->right->right = NULL;
enqueue(&q, node->right);
}
}
return root;
}
// 先序遍历满二叉树
void preorder_traversal(Node *root) {
if (root != NULL) {
printf("%d ", root->data);
preorder_traversal(root->left);
preorder_traversal(root->right);
}
}
int main() {
Node *root = create_full_binary_tree(3, -1);
printf("Preorder traversal: ");
preorder_traversal(root);
printf("\n");
return 0;
}
完全二叉树:除最后一层外,其他各层的节点数都达到最大个数,且最后一层节点是从左到右的连续存在。

链式存储构建完全二叉树(队列)
#include<stdio.h>
typedef int ElementType;//输入的数据的类型
#define NoInfo 0//如果输入是0,则输入结束
typedef struct TreeNode* BinTree;
struct TreeNode//二叉树节点
{
ElementType Data;
BinTree Left;
BinTree Right;
};
/
typedef struct QueueNode*PtrToNode;//队列中的节点
struct QueueNode
{
BinTree Data;//指着那块内存
PtrToNode Next;
};
typedef PtrToNode Position;
typedef struct QNode* PtrToQNode;//队列的头尾数据和队列的长度
struct QNode
{
Position Front, Rear;
int Size;
};
typedef PtrToQNode Queue;
///
BinTree CreateBinTree();
Queue CreateQueue();
void AddQ(Queue Q, BinTree BT);
BinTree DeleteQ(Queue Q);
void SequenceTraversal(BinTree BT);
///
int main()
{
BinTree T = CreateBinTree();//输入一个元素就回一次车,他就会层序给你排好,建立一个完全二叉树
SequenceTraversal(T);
return 0;
}
/********************************************************************************************************
创建思路:用户每输入一个非0(NoInfo)数据,我们都malloc一个QueueNode类型的节点来储存数据,并把存入队列中,
用QueueNode类型的节点来保存数据,并更改Q里面的数据,然后就是把这个数据插入到二叉树里面。再从队列中取出来一
个数据,将接下来输入的两个数据分别同样malloc一个QueueNode类型的节点来存放数据,并把它存入队列中,然后把这
两个数据插入取出的这个节点的左右孩子里面
*********************************************************************************************************/
BinTree CreateBinTree()//创建一个完全二叉树,是全过程的精髓
{
ElementType Data;
BinTree BT, T;
Queue Q = CreateQueue();//创建一个空队列
scanf_s("%d", &Data);//临时存放数据
if (Data != NoInfo)//等于0表示输入终结
{
BT = (BinTree)malloc(sizeof(struct TreeNode));//为二叉树节点申请一个内存,先插入二叉树
BT->Data = Data;
BT->Left = BT->Right = NULL;
AddQ(Q, BT);//入队
}
else//等于0表示输入终结
return NULL;
while (Q->Size != 0)//如果队列不为空
{
T = DeleteQ(Q);//出队,已经筛选好了指针,可以直接用
scanf_s("%d", &Data);
if (Data == NoInfo)
{
T->Left = NULL;
T->Right = NULL;
return BT;
}
else//为新数据申请内存节点,把节点插入二叉树
{
T->Left = (BinTree)malloc(sizeof(struct TreeNode));
T->Left->Data = Data;
T->Left->Left = T->Left->Right = NULL;
AddQ(Q, T->Left);
}
scanf_s("%d", &Data);
if (Data == NoInfo)
{
T->Right = NULL;
return BT;
}
else//为新数据申请内存节点,把节点插入二叉树
{
T->Right = (BinTree)malloc(sizeof(struct TreeNode));
T->Right->Data = Data;
T->Right->Left = T->Right->Right = NULL;
AddQ(Q, T->Right);
}
}
return BT;
}
Queue CreateQueue()//创建一个空队列,里面没有除了头节点外的其他任何节点
{
Queue Q = (Queue)malloc(sizeof(struct QNode));
Q->Front = Q->Rear = (Position)malloc(sizeof(struct QueueNode));//刚开始指针都指着头节点,为这个头节点申请了一块内存
Q->Size = 0;
Q->Front->Next = Q->Front->Data = NULL;
return Q;
}
void AddQ(Queue Q, BinTree BT)
{
Q->Size++;
Position Temp = Q->Rear;//先保存好尾节点指针
Q->Rear = (Position)malloc(sizeof(struct QueueNode));//尾节点指着这块内存
Q->Rear->Data = BT;//这块内存里面的数据指针指着这个二叉树节点的内存
Q->Rear->Next = NULL;
Temp->Next = Q->Rear;//把上一个节点和这一个节点连接起来
}
BinTree DeleteQ(Queue Q)
{
BinTree BT;
if (Q->Front->Next == NULL)//如果是空的
return NULL;//报错
Q->Size--;//先把长度减一
Position Temp = Q->Front->Next;//先保存好头节点的Next指针,Q->Front指着头节点
if (Temp == Q->Rear)
Q->Rear = Q->Front;//返回头节点
Q->Front->Next = Temp->Next;//头节点的Next指针往下移,多出来一个节点就是要删除的节点
BT = Temp->Data;
free(Temp);//释放队列节点内存
return BT;
}
void SequenceTraversal(BinTree BT)
{
BinTree T = BT;
Queue Q = CreateQueue();//先创建一个队列
AddQ(Q, BT);//入队
while (1)
{
T = DeleteQ(Q);//出队
if (T == NULL)
return;
else
{
if (T->Left != NULL)
{
AddQ(Q, T->Left);
if (T->Right != NULL)
AddQ(Q, T->Right);
}
printf("%d ", T->Data);
}
}
}
链式存储构建完全二叉树(栈)
//完全二叉树
//队列的链式存储
#include <stdio.h>
#include <malloc.h>
#include <string.h>
#define max 51
#define initSize 10
typedef struct
{
int number[initSize];
int top; //线性栈当前位置
}Stack;
struct People
{
char name[max];
char ID[max];
};
typedef struct treeNode
{
People people1;
struct treeNode* lNext;
struct treeNode* rNext;
}treeNode , *BiTree;
void initStack(Stack& stack);//初始化栈
bool stackEmpty(Stack stack);//判断是否为空栈
bool stackFull(Stack stack);//判断是否为满栈
bool push(Stack& stack, int number);//入栈
bool pop(Stack& stack, int& number);//出栈
void initTree(BiTree &tree , People peo);//初始化二叉树
void preOrder(BiTree tree , int &i);//先序遍历
void inOrder(BiTree tree , int &i);//中序遍历
void postOrder(BiTree tree, int& i);//后序遍历
void visit(BiTree tree ,int &i );//访问节点
void getStack(Stack& stack, int i);//访问获取指定节点的路径
bool addNode(BiTree &tree , People peo);//添加节点
bool delBiTree(BiTree &tree);//销毁树
void printPeo(People peo);//输出people
int main()
{
People peo = { "李参政" , "0418" };
People peo1[6] = { {"李" , "0418"} , {"参" , "0418"} ,{"正" ,"0418"} ,{ "li" , "0418"} ,{"can" ,"0418" } ,{"zheng" ,"0418"} };
BiTree tree;
initTree(tree , peo);
for (int j = 0; j < 6; j++)
{
addNode(tree, peo1[j]);
}
int i = 0;
printf("i = %d\n", i);
printf("先序遍历\n");
preOrder(tree, i);
printf("********************************************\n");
//printf("i = %d\n", i);
i = 0;
printf("i = %d\n", i);
printf("中序遍历\n");
inOrder(tree, i);
printf("********************************************\n");
//printf("i = %d\n", i);
i = 0;
printf("i = %d\n", i);
printf("后序遍历\n");
postOrder(tree, i);
printf("********************************************\n");
//printf("i = %d\n", i);
delBiTree(tree);
return 0;
}
void initTree(BiTree& tree , People peo)//初始化二叉树
{
tree = (treeNode*)malloc(sizeof(treeNode));//创建根节点
tree->people1 = peo;//修改根节点数据域
tree->lNext = NULL;//根节点左孩子置空
tree->rNext = NULL;//根节点有孩子置空
}
void preOrder(BiTree tree, int& i)//先序遍历
{
if (tree != NULL)
{
visit(tree, i);//访问节点父节点
preOrder(tree->lNext, i);//访问左边子节点
preOrder(tree->rNext , i);//访问右边子节点
}
}
void inOrder(BiTree tree, int& i)//中序遍历
{
if (tree != NULL)
{
preOrder(tree->lNext, i);//访问左边子节点
visit(tree, i);//访问节点父节点
preOrder(tree->rNext, i);//访问右边子节点
}
}
void postOrder(BiTree tree, int& i)//后序遍历
{
if (tree != NULL)
{
preOrder(tree->lNext, i);//访问左边子节点
preOrder(tree->rNext, i);//访问右边子节点
visit(tree, i);//访问节点父节点
}
}
void visit(BiTree tree, int& i)//访问节点
{
if (tree != NULL)//如果节点非空,节点数加1
{
i++;
printPeo(tree->people1);
//printf("vist_i = %d\t" ,i);
}
else//节点为空,不执行操作
;
}
bool addNode(BiTree& tree, People peo )//添加节点
{
int num = 0;
preOrder(tree ,num);//先序遍历树,获取节点数量
//printf("num1 = %d\t" ,num);
treeNode* node = NULL;
node = tree;//创建参数节点,并将根节点地址赋给参数节点;
num++;
//printf("num_change = %d\t" , num);
int last_number = num - ((int)(num / 2))*2;//last_number = 0则插入节点是根节点的左孩子,last_number = 1则插入节点是其父节点的有孩子
//printf("lastNum = %d\n", last_number);
Stack stack;//创建访问父节点路径栈
initStack(stack);
int stack_number = num / 2;
getStack(stack, stack_number);//获取访问插入节点父节点的路径栈
while (!stackEmpty(stack)) //访问父节点
{
int number = 0;
pop(stack, number);
//printf("number = %d\n" ,number);
if (node != NULL && number == 0 && node->lNext != NULL)
node = node->lNext;
if (node != NULL && number == 1 && node->rNext != NULL)
node = node->rNext;
//printf("node = %x\n" ,node);
}
treeNode* newnode = (treeNode*)malloc(sizeof(treeNode));
newnode->people1 = peo;
newnode->lNext = NULL;
newnode->rNext = NULL;
//printf("newNode = %x\t" , newnode);
if (last_number == 0)
{
node->lNext = newnode;
}
if (last_number == 1)
{
node->rNext = newnode;
}
//printf("l = %x\t" , node->lNext);
//printf("r = %x\n" , node->rNext);
//printf("**********************************************************************\n");
return true;
}
bool delBiTree(BiTree& tree)//销毁树
{
//空树
if (tree == NULL)
return false;
//只有根节点的树,直接释放根节点空间销毁树
if (tree->lNext == NULL && tree->rNext == NULL)
{
free(tree);
return true;
}
int num = 0;
preOrder(tree, num);//遍历树,获取节点数量
while (num != 0)//从最后节点依次释放节点空间
{
treeNode* node = NULL;
node = tree;
int last_nuber = num - (int)(num / 2) * 2;//判断最后一个节点是其父节点的左孩子还是右孩子
Stack stack;
initStack(stack);
getStack(stack,num/2 );//获取父节点访问栈
while (!stackEmpty(stack))//访问其父节点
{
int number = 0;
pop(stack, number);
if (node != NULL && number == 0 && node->lNext != NULL)
node = node->lNext;
else if (node != NULL && number == 1 && node->rNext != NULL)
node = node->rNext;
}
//删除最后一个节点
if (last_nuber == 0)
{
free(node->lNext);
node->lNext = NULL;
}
else if (last_nuber == 1)
{
free(node->rNext);
node->rNext = NULL;
}
num--;//节点数减一
}
return true;
}
//获取第i个节点的访问路径,
void getStack(Stack &stack ,int i)
{
int num = i;
int quo = 0;
while (num/2 != 0)
{
quo = num / 2;
int ele = num - quo * 2;
push(stack, ele);
num = num / 2;
}
}
void printPeo(People peo)//输出people
{
printf("name = %s\n", peo.name);
printf("ID = %s\n", peo.ID);
printf("-------------------------------\n");
}
void initStack(Stack& stack)//初始化栈
{
stack.top = 0;//指向栈的第一个空间,此时栈为空栈
}
bool stackEmpty(Stack stack)//判断是否为空栈
{
if (stack.top == 0)
return true;
else
return false;
}
bool stackFull(Stack stack)//判断是否为满栈
{
if (stack.top >= initSize)
return true;
else
return false;
}
bool push(Stack& stack, int number)//入栈
{
//栈满
if (stackFull(stack))
return false;
int top = stack.top;
stack.number[top] = number;//元素入栈
++stack.top;//栈顶向上移
return true;
}
bool pop(Stack& stack, int& number)//出栈
{
if (stackEmpty(stack))
return false;
else
{
--stack.top;//栈顶向下移
int top = stack.top;
number = stack.number[top];//元素出栈
}
return true;
}
int getPop(Stack& stack)//读取栈顶元素
{
if (!stackEmpty(stack))
{
int i = stack.top - 1;
return stack.number[i];
}
}
六 堆
堆 与 栈 与队列的区别
堆:堆是一种完全二叉树结构。堆可以分为最大堆和最小堆两种形式。最大堆是一种满足任何父节点的值都大于等于其子节点的堆,而最小堆是一种满足任何父节点的值都小于等于其子节点的堆。堆常用于实现优先队列,以及堆排序等算法。
栈:栈是一种后进先出(LIFO)的数据结构,栈中的元素只能通过栈顶进行插入和删除。在程序中,栈常用于存储程序执行过程中的上下文信息,如函数调用、异常处理等场景。
队列:队列是一种先进先出(FIFO)的数据结构,队列的元素从队尾入列,从队头出列。队列在程序中常被用于实现广度优先搜索(BFS)、层序遍历二叉树等场景。
堆(Heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵完全二叉树的数组对象。
特点:
堆中某个节点的值总是不大于或不小于其父节点的值;
堆总是一棵完全二叉树。
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。
堆排序:堆排序是一种常见的排序算法,它利用堆数据结构来实现排序。时间复杂度为 �(�log�)O(nlogn),其中 �n 表示待排序序列的长度。
求TopK元素:在一个非常大的数据集合中,需求出其中最大(或最小)的 �k 个元素。一种解决方法就是使用堆结构,在往堆中插入元素时,如果堆的大小超过 �k 就删除堆中最小的元素,这样就能保证在遍历完所有元素后,堆中剩下的就是最大(或最小)的 �k 个元素。
实现图的 Dijkstra 算法:Dijkstra 算法是用于求图中单源最短路径的经典算法之一。在实现过程中,需要使用最小优先队列(通常使用堆来实现),来不断更新当前节点到源点的最短距离。
实现图的 Prim 和 Kruskal 算法:Prim 和 Kruskal 是两个用于求无向权重图的最小生成树的算法。在实现过程中,同样需要使用最小优先队列(通常使用堆来实现),来不断更新当前节点到最小生成树的最短距离。
作为内存管理中的“垃圾”数据收集器:在一些高级编程语言中,如Java、Python等,都有自动垃圾回收机制。这些语言中的垃圾回收机制通常使用堆来管理内存,并使用堆上的空间管理垃圾数据的收集。在这些垃圾收集器中,可以使用二叉堆或斐波那契堆等高效的数据结构来实现。
小根堆:
1.是个完全二叉树。
2.树中所有的父亲都是小于等于孩子。
大根堆:
1.是个完全二叉树。
2.树中所有的父亲都是大于等于孩子。

构建一个堆(最小堆)
1)插入数据
因为使用的顺序表,其真实的存储是直接插入到尾部就可以了,但是怎么让其逻辑上成为一个堆呢?插入的节点跟父节点进行比较如果,父节点比较大,就把自己跟父节点进行交换。然后继续跟新的父节点进行比较,直到遇到比自己小的父节点。
PS:调整节点比较大小时,只需要跟相同祖先的节点进行比较,兄弟节点之间的大小不影响堆的建立。
//向上调整
void AdjustUp(int* arr,int pos)
{
int child = pos;
int parent = (child - 1) / 2; //父节点公式。
while ( child > 0 ) {
parent = (child - 1) / 2;
if (arr[child] < arr[parent]) {
Swap(&arr[child],&arr[parent]);
}
else {
break;
}
child = parent;
}
}PS:这里创建的是小堆,如果要创建大堆,把父子节点的比较换成大于符号就可以了。
2)删除数据
删除堆的根节点,不能直接删除,不然其逻辑结构失效,堆会被打乱。首先要把根节点跟最后一个叶子节点进行交换,然后删除。再把新的根节点进行向下调整。
向下调整思路:选择较小的子节点,如果其也比自己小,那么进行交换。如果其比自己大那么结束交换。(生成大堆的时候选择较大的数,如果比自己大进行交换) 并不是每个节点都有右节点,如果只有一个左节点直接交换就行了。如果自己孩子节点的下标超过了堆的大小,说明自己已经是叶子节点了,就要退出循环。
PS:向下调整算法有一个前提:左右子树必须是一个堆,才能调整。
void AdjustDown(int *arr ,int size,int parent)
{
int child = parent * 2 + 1;
while ( child < size ) {
//防止越界,因为有左孩子节点,不一定有右孩子节点。
if ( child + 1 < size && arr[child + 1] <arr[child]) {
child++;
}
if (arr[child] < arr[parent]) {
Swap(&arr[child], &arr[parent]);
parent = child;
child = parent * 2 + 1;
}
else {
break;
}
}
}3)堆代码实现
typedef int HPDataType;
typedef struct Heap
{
HPDataType* _a;
int _size;
int _capacity;
}Heap;
//交换
void Swap(HPDataType* a, HPDataType* b)
{
HPDataType temp = *a;
*a = *b;
*b = temp;
}
//向上调整
void AdjustUp(int* arr,int pos)
{
//建立小堆,如果新加入的数据比父节点小,就交换,比父节点大就退出。
int child = pos;
int parent = (child - 1) / 2;
while ( child > 0 ) {
parent = (child - 1) / 2;
if (arr[child] < arr[parent]) {
Swap(&arr[child],&arr[parent]);
}
else {
break;
}
child = parent;
}
}
//向下调整
void AdjustDown(int *arr ,int size,int parent)
{
//取较小的子节点交换数据。
int child = parent * 2 + 1;
while ( child < size ) {
//防止越界,因为有左孩子节点,不一定有右孩子节点。
if ( child + 1 < size && arr[child + 1] <arr[child]) {
child++;
}
if (arr[child] < arr[parent]) {
Swap(&arr[child], &arr[parent]);
parent = child;
child = parent * 2 + 1;
}
else {
break;
}
}
}
//初始化
void HeapInit(Heap* hp)
{
assert(hp);
hp->_a = NULL;
hp->_capacity = 0;
hp->_size = 0;
}
//创建堆
void HeapCreate(Heap* hp, HPDataType* a, int n)
{
assert(hp);
assert(a);
for (int i = 0; i < n;i++) {
HeapPush(hp, a[i]);
}
}
//销毁
void HeapDestory(Heap* hp)
{
assert(hp);
free(hp->_a);
hp->_a = NULL;
hp->_capacity = 0;
hp->_size = 0;
}
//插入数据
void HeapPush(Heap* hp, HPDataType x)
{
assert(hp);
int newCpacity = 0;
if (hp->_capacity==hp->_size) {
newCpacity = hp->_capacity == 0 ? 4 : hp->_capacity * 2;
HPDataType* temp=(HPDataType*)realloc(hp->_a, sizeof(HPDataType) * newCpacity);
if (temp==NULL) {
perror("temp为NULL");
exit(-1);
}
hp->_a = temp;
hp->_capacity = newCpacity;
}
hp->_a[hp->_size] = x;
hp->_size++;
//向上调整,构建堆
AdjustUp(hp->_a,hp->_size-1);
}
//删除数据
void HeapPop(Heap* hp)
{
assert(hp);
assert(!HeapEmpty(hp));
//交换首尾元素,size--,然后把根节点的元素向下调整。
Swap(&hp->_a[0],&hp->_a[hp->_size-1]);
hp->_size--;
AdjustDown(hp->_a,hp->_size,0);
}
//取根数据
HPDataType HeapTop(Heap* hp)
{
assert(hp);
assert(!HeapEmpty(hp));
return hp->_a[0];
}
//堆的大小
int HeapSize(Heap* hp)
{
assert(hp);
return hp->_size;
}
//堆是否为空
bool HeapEmpty(Heap* hp)
{
assert(hp);
return hp->_size==0;
}
//测试
void PrintHeap(Heap* hp){
for(int i = 0; i < hp->_size; i++){
printf("%-02d",hp->_a[i]);
}
printf("\n");
}
void test1()
{
Heap hp;
HeapInit(&hp);
int a[] = {67,24,35,56,18,25,26,7}
HeapCreate(&hp,a,sizeof(a)/sizeof(a[0]));
printfHeap(&hp);
HeapPop(&hp);
printfHeap(&hp);
}
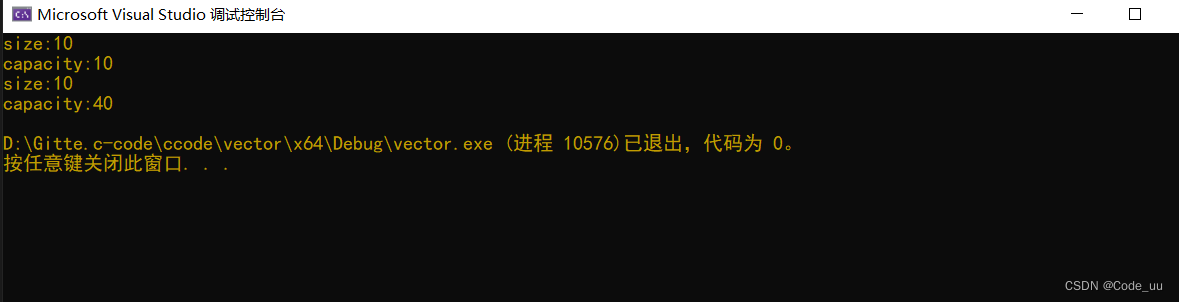
//输出为
// 7 18 25 24 56 34 26 67
// 18 24 25 67 56 34 26具体应用——堆排序(快速选数)
直接利用上面已经写好的堆。
void HeapSort(int* a, int n)
{
Heap hp;
HeapInit(&hp);
for (int i = 0; i < n;i++) {
HeapPush(&hp,a[i]);
}
int i = 0;
while (!HeapEmpty(&hp)) {
a[i++] = HeapTop(&hp);
HeapPop(&hp);
}
}
//测试
void test2()
{
int a[] = {12,25,10,56,5,78,4,89};
HeapSort(a,sizeof(a)/sizeof(a[0]));
for(int i = 0;i < sizeof(a)/sizeof(a[0]); i++){
printf("%-02d",a[i]);
}
printf("\n")
}
//输出
// 89 78 56 25 12 10 5 4或利用向上调整法、向下调整法对数组进行调整
直接把给进来的数组的数据向上调整,调整出来的是数组就是堆的结构,构成堆就可进行排序了。
PS:这里构建堆,要从第二个元素开始向上调整,一直到最后。
//方式1:
//直接从数组第二个元素开始向上调整构建堆 ,此时的时间复杂度为O(nlogn);
for (int i = 1; i < n;i++) {
AdjustUp(a, i);
}
向下调整,需要节点左右有堆,这里第一个有堆的节点,是最后一个叶子节点的父节点。然后依次往上调整,调整到最后堆的结构就建立起来了。
PS:最后一个节点的下标就是数组的长度-1,然后它的父节点就是第一个开始调整的节点。
//方式2:
//直接从最后的叶子节点的父节点,往下调整构建堆,时间复杂度为O(N)
for (int i = (n - 1 - 1) / 2; i >= 0; i--) {
AdjustDown(a, n, i);
}
从上面的思路就可以知道,假设建立的是小堆,其根节点是堆中最小的数,把他放到数组后面,然后继续建堆,找到次小的数,再放到后面。最后会发现,放置的数据在数组中是从大到小排列,构成了一个降序的数组。(根据其逻辑可以知道,建立降序数组用小堆,建立升序数组,用大堆)
void HeapSort(int* a, int n)
{
//i是最后一个叶子节点的父节点
for (int i = (n - 1 - 1) / 2; i >= 0; i--) {
AdjustDown(a, n, i);
}
//注意升序建立小堆,降序建立大堆。
//把首尾数据交换,然后把根数据向下调整
int size = n-1;
while (size > 0) {
Swap(&a[0], &a[size]);
AdjustDown(a,size,0);
size--;
}
}




![[大二下]手把手1小时下载Pandoc](https://img-blog.csdnimg.cn/f16cfd7012184aa995443bcb3558d6ba.png)