前言
本文已收录在MySQL性能优化+原理+实战专栏,点击此处浏览更多优质内容。

目录
- 一、MySQL InnoDB是否支持哈希索引?
- 1.1 InnoDB不支持Hash Index
- 1.2 InnoDB支持Hash Index
- 二、Adaptive Hash Index的概念
- 三、涉及Adaptive Hash Index的参数
- 3.1 innodb_adaptive_hash_index
- 3.2 innodb_adaptive_flushing
- 3.3 innodb_adaptive_flushing_lwm
- 3.4 innodb_adaptive_hash_index_parts
- 小提示
- 四、准备工作
- 五、通过聚簇索引和普通索引访问记录的过
- 5.1 聚簇索引访问记录过程
- 5.2 普通索引访问记录过程
- 六、通过Adaptive Hash Index访问记录的过程
- 七 、Adaptive Hash Index状态监控
- 八、Adaptive Hash Index 注意事项
- 8.1 使用场景
- 8.2 注意事项
- 8.3 Adaptive Hash Index 限制
首先放一个MySQL官档中提供的InnoDB体系架构图:
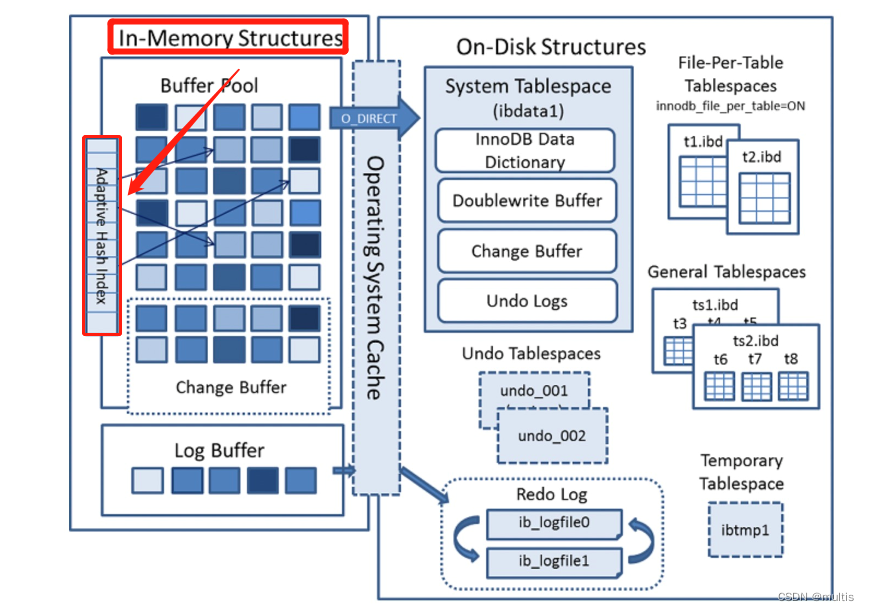
如图所示,在InnoDB体系架构图的内存结构中,还有一块区域(已经用红框标出)名为:Adaptive Hash Index,翻译成中文:自适应哈希索引,缩写:AHI。它是一个纯内存结构,今天我们就来深入的了解它。
一、MySQL InnoDB是否支持哈希索引?
在网络上,流传着两种关于MySQL InnoDB哈希索引的传言。有一部分人说,InnoDB不支持哈希索引;有一部分人说,InnoDB支持哈希索引。那么到底谁说的对呢,其实两种说法都对
1.1 InnoDB不支持Hash Index
首先我们创建一张student表,代码如下:
mysql> create database testdb;
Query OK, 1 row affected (0.00 sec)
mysql> use testdb;
Database changed
mysql> create table student (
student_id int not null auto_increment comment '学号',
student_name varchar(20) not null comment '姓名',
address varchar(100) default '江苏省苏州市常熟市' comment '家庭住址',
primary key (student_id)
) comment='学生表';
Query OK, 0 rows affected (0.03 sec)
然后,我们为address字段添加一个Hash Index
mysql> alter table student add index idx_address(address) using hash;
Query OK, 0 rows affected, 1 warning (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 1
我们查看MySQL的warning
show warnings;
+-------+------+---------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+---------------------------------------------------------------------------------------------------------+
| Note | 3502 | This storage engine does not support the HASH index algorithm, storage engine default was used instead. |
+-------+------+---------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
系统提示我们Innodb存储引擎不支持HASH索引算法,使用存储引擎默认值代替,接着查询创建完哈希索引后的表结构
mysql> show index from student \G;
*************************** 1. row ***************************
Table: student
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: student_id
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
*************************** 2. row ***************************
Table: student
Non_unique: 1
Key_name: idx_address
Seq_in_index: 1
Column_name: address
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
2 rows in set (0.01 sec)
ERROR:
No query specified
从上面的显示结果看,你会惊人的发现,刚创建的Hash Index,终归还是B+树Index
1.2 InnoDB支持Hash Index
InnoDB会进行自调优,如果判定建立Adaptive Hash Index,能够提升查询效率,InnoDB自己会在内存中建立相关哈希索引(所以这就是Adaptive——“自适应”的由来),不需要人工手动干预,InnoDB会根据所需自己创建自适应哈希索引。所以,从这个角度来说,InnoDB是支持哈希索引的
二、Adaptive Hash Index的概念
自适应哈希索引是Innodb引擎的一个特殊功能,当它注意到某些索引值使用的非常频繁,发现建立哈希索引(又称散列索引)可以带来速度的提升,Innodb就会在自己的内存缓冲区(Buffer Pool)里,开辟一块区域,建立自适应哈希索引(Adaptive Hash Index,AHI),以便加速查询。
官档地址:https://dev.mysql.com/doc/refman/8.0/en/innodb-adaptive-hash.html
点击此处跳转
三、涉及Adaptive Hash Index的参数
show variables like '%adaptive%'
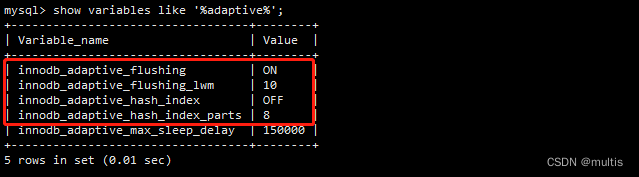
3.1 innodb_adaptive_hash_index
该参数影响自适应哈希索引是否启用。默认情况下启用此变量。当我们禁用自适应哈希索引会立即清空哈希表。当哈希表被清空时,正常操作可以继续,并且执行使用哈希表的查询直接访问索引 B 树。当重新启用自适应散列索引时,在正常操作期间会再次填充散列表。
set persist innodb_adaptive_hash_index = on;
3.2 innodb_adaptive_flushing
该参数影响每秒刷新脏页的操作,默认情况下是启用此变量,刷新脏页会通过判断产生重做日志的速度来判断最合适的刷新脏页的数量,如果关闭该参数会导致你的MySQL的服务器的tps有明显的波动。每当重做日志写满了,MySQL就会停下手头的任务,先把脏页刷到磁盘里,才能继续干活
set persist innodb_adaptive_flushing = on;
3.3 innodb_adaptive_flushing_lwm
该参数可以设置redo log flush低水位线,当需要flush的redo log超过这个低水位时,innodb会立即启用adaptive flushing,默认值10,最小值0,最大值70
set persist innodb_adaptive_flushing_lwm= 10;
3.4 innodb_adaptive_hash_index_parts
该参数是5.7后InnoDB将自适应哈希索引进行了分区处理,每个区对应一个锁,如果大量地访问,那么可能会对性能产生影响(抢锁),InnoDB将这个值默认设为8,最小值1,最大值512
set persist_only innodb_adaptive_hash_index_parts= 10;
小提示
相关参数解释了这么多,其实生产环境我们均采取默认值即可。
四、准备工作
为了后面内容的顺利进行,我们对student学生表做了一些改造
- 删除了并没有实际用处的“Hash”索引idx_address
mysql> alter table student drop index idx_address;
- 为student_name学生姓名字段添加了一个普通二级索引。
mysql> alter table student add index idx_student_name(student_name);
- 为student_name插入数据
insert into student(student_name,address) values('张一','工业园区');
insert into student(student_name,address) values('张二','姑苏区');
insert into student(student_name,address) values('张三','吴中区');
insert into student(student_name,address) values('张四','高新区');
insert into student(student_name,address) values('张五','吴江区');
insert into student(student_name,address) values('张六','相城区');
insert into student(student_name,address) values('张七','常熟市');
insert into student(student_name,address) values('张八','昆山市');
insert into student(student_name,address) values('张九','太仓市');
insert into student(student_name,address) values('张十','张家港市');
- 最后,我们看一下表结构和表中的数据
mysql> show create table student \G;
*************************** 1. row ***************************
Table: student
Create Table: CREATE TABLE `student` (
`student_id` int NOT NULL AUTO_INCREMENT COMMENT '学号',
`student_name` varchar(20) NOT NULL COMMENT '姓名',
`address` varchar(100) DEFAULT '江苏省苏州市常熟市' COMMENT '家庭住址',
PRIMARY KEY (`student_id`),
KEY `idx_student_name` (`student_name`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='学生表'
1 row in set (0.00 sec)
ERROR:
No query specified
mysql> select * from student;
+------------+--------------+--------------+
| student_id | student_name | address |
+------------+--------------+--------------+
| 1 | 张一 | 工业园区 |
| 2 | 张二 | 姑苏区 |
| 3 | 张三 | 吴中区 |
| 4 | 张四 | 高新区 |
| 5 | 张五 | 吴江区 |
| 6 | 张六 | 相城区 |
| 7 | 张七 | 常熟市 |
| 8 | 张八 | 昆山市 |
| 9 | 张九 | 太仓市 |
| 10 | 张十 | 张家港市 |
+------------+--------------+--------------+
10 rows in set (0.00 sec)
五、通过聚簇索引和普通索引访问记录的过
InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,聚簇索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的就是整张表的行记录数据,也将聚集索引的叶子节点称为数据页。这个特性决定了索引组织表中数据也是索引的一部分;
5.1 聚簇索引访问记录过程
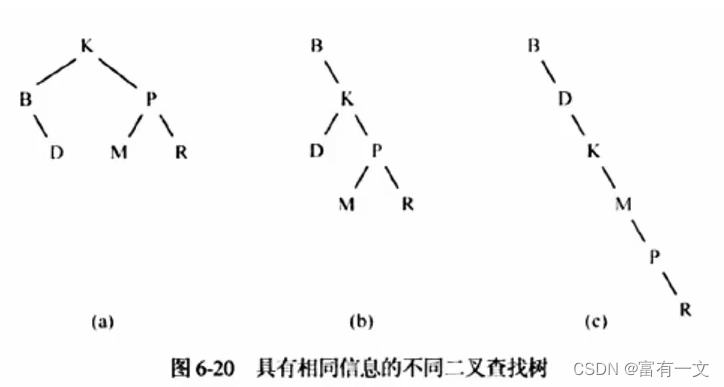
student学生表中的数据我们可以简易画一个B+树的结构图(真实的B+树结构要复杂的多,后期会开辟单独的文章详细讲解),如下所示:

InnoDB会在主键student_id上建立聚集索引(Clustered Index),叶子节点存储记录本身,在student_name上会建立普通索引(Secondary Index),叶子节点存储主键值(聚集索引就是数据的完整记录,普通索引也是单独的物理结构,两者均存放在.ibd文件中)。发起主键student_id查询时,能够通过聚集索引,直接定位到行记录。
select * from student where student_id = 6;
此时的过程如下图所示:

5.2 普通索引访问记录过程
select * from student where student_name = '张九';

通过普通索引查询记录时,和通过聚簇索引查询记录有所不同,分为两步:
- 步骤1:查询会先访问普通索引,定位到主键值9;
- 步骤2:再通过步骤1得到的主键值,回表到聚集索引上经过二次遍历定位到具体的完整记录。
六、通过Adaptive Hash Index访问记录的过程
从上面的流程图可以看出,不管是聚集索引还是普通索引,记录定位的寻路路径(Search Path)都很长。回到Adaptive Hash Index的概念上:在MySQL运行的过程中,如果InnoDB发现:
- 有很多寻路很长(比如B+树层数太多、回表次数多等情况)的SQL;
- 有很多SQL会命中相同的页(Page)。
Innodb就会在自己的内存缓冲区(Buffer Pool)里,开辟一块区域,建立自适应哈希索引(Adaptive Hash Index,AHI),以便加速查询。
Adaptive Hash Index访问记录原理

通过上面的流程图,我们可以得出以下结论:
- MySQL InnoDB的Adaptive Hash Index,更像“索引的索引”,以此来缩短寻路路径(Search Path)。
- 我们都知道,Hash数据结构都是包含键(Key)、值(Value)的,在Adaptive Hash Index,Key就是经常访问到的索引键值,Value就是该索引键值匹配的完整记录所在页面(Page)的位置。
- 因为是MySQL InnoDB自己维护创建的,所以称之为“自适应”哈希索引,但系统也有误判的时候,也不能起到加速查询的效果。
七 、Adaptive Hash Index状态监控
show engine innodb status \G;
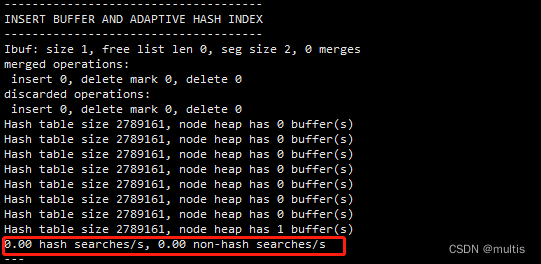
注意: 这是一段时间的结果。通过hash searches、non-hash searches计算AHI带来的收益以及成本,确定是否开启AHI
八、Adaptive Hash Index 注意事项
8.1 使用场景
- 很多单行记录查询,比如用户登录系统时密码的校验。
- 索引范围查询,此时AHI可以快速定位首行记录。
- 所有记录内存能放得下,这时AHI往往是有效的。
- 当业务有大量LIKE或者JOIN,AHI的维护反而可能成为负担,降低系统效率,此时可以手动关闭AHI功能。
8.2 注意事项
- AHI目的:缓存索引中的热点数据,提高检索效率,时间复杂度O(1) VS O(N)的差异;
- 基于主键的搜索,几乎都是hash searches;
- 基于普通索引的搜索,大部分是non-hash searches,小部分是hash searches;
- 无序,没有树高,对热点Buffer Pool建立AHI,非持久化;
- 初始化为innodb_buffer_pool_size的1/64,会随着InnoDB Buffer Pool动态调整;
- 只支持等值查询(基于主键的等值查询AHI效果更好)
- AHI很可能是部分长度索引,并非所有的查询都能有效果
8.3 Adaptive Hash Index 限制
- 只能用于等值比较,例如=、<=>、IN、AND等
- 无法用于排序
- 有冲突可能
- MySQL自动(“自适应”)管理,人为无法干预
今天主要讲解了MySQL InnoDB Adaptive Hash Index的工作原理,通过一些例子来说明整个过程,偏理论的知识,内容比较少也很好理解,大家理解记忆即可,面试中有被问到的可能。