基于C#和OpenVINO部署PaddleOCR模型
- 1.OpenVINO
- 2.PaddleOCR
- PP-OCRv2
- PP-OCRv3
- 3.模型下载与转换
- 3.1 Detection model
- 3.2 Direction classifier
- 3.3 Recognition model
- 4.OpenVinoSharp安装
- 4.1 获取OpenVinoSharp源码
- 4.2 配置OpenVINO依赖项
- 5. PaddleOCR
- 5. 1模型推理C#实现
- (1) 模型推理基类
- (2)文本区域识别类
- (3) 文字方向判断类
- (4)文字内容识别
- 5.2 文字识别结果类
- 5.3 PaddleOCR类
- 5.3 其他类
- 6. 文本识别过程与结果
基于OpenVINO模型推理库,在C#语言下,调用封装的OpenVINO动态链接库,部署推理PaddleOCR中的文字识别模型;实现了在C#平台使用PaddleOCR文字识别模型识别文字。
OpenVinoSharp源码在GitHub和Gitee上已开源,可以直接通过Git获取所有源码
在Github上克隆下载:
git clone https://github.com/guojin-yan/OpenVinoSharp_deploy_PaddleOCR.git
在Gitee上克隆下载:
git clone https://gitee.com/guojin-yan/OpenVinoSharp_deploy_PaddleOCR.git
飞桨AI Studio 项目链接
基于C#和OpenVINO部署PaddleOCR模型 - 飞桨AI Studio
1.OpenVINO
OpenVINO™是英特尔基于自身现有的硬件平台开发的一种可以加快高性能计算机视觉和深度学习视觉应用开发速度工具套件,用于快速开发应用程序和解决方案,以解决各种任务(包括人类视觉模拟、自动语音识别、自然语言处理和推荐系统等)。
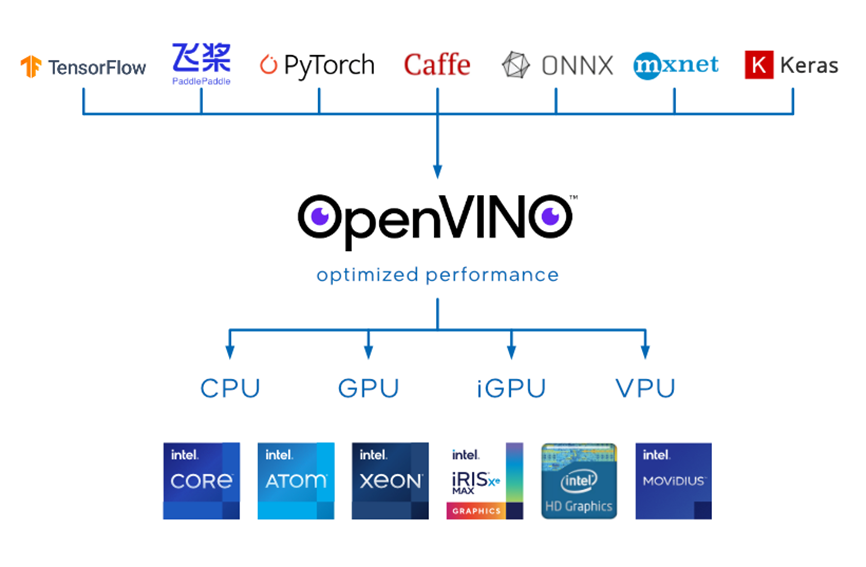
该工具套件基于最新一代的人工神经网络,包括卷积神经网络 (CNN)、递归网络和基于注意力的网络,可扩展跨英特尔® 硬件的计算机视觉和非视觉工作负载,从而最大限度地提高性能。它通过从边缘到云部署的高性能、人工智能和深度学习推理来为应用程序加速,并且允许直接异构执行。极大的提高计算机视觉、自动语音识别、自然语言处理和其他常见任务中的深度学习性能;使用使用流行的框架(如TensorFlow,PyTorch等)训练的模型;减少资源需求,并在从边缘到云的一系列英特尔®平台上高效部署;支持在Windows与Linux系统,且官方支持编程语言为Python与C++语言。
官方发行的OpenVINO™未提供C#编程语言接口,因此在使用时无法实现在C#中利用OpenVINO™进行模型部署。在之前所做工作中,利用动态链接库功能,调用官方依赖库,实现在C#中部署深度学习模型,推出了OpenVinoSharp。在本文项目中,使用了OpenVinoSharp作为模型推理工具,加速PaddleOCR模型推理。

2.PaddleOCR
PP-OCR是PaddleOCR自研的实用的超轻量OCR系统。在实现前沿算法的基础上,考虑精度与速度的平衡,进行模型瘦身和深度优化,使其尽可能满足产业落地需求。PP-OCR是一个两阶段的OCR系统,其中文本检测算法选用DB,文本识别算法选用[RNN,并在检测和识别模块之间添加文本方向分类器,以应对不同方向的文本识别。
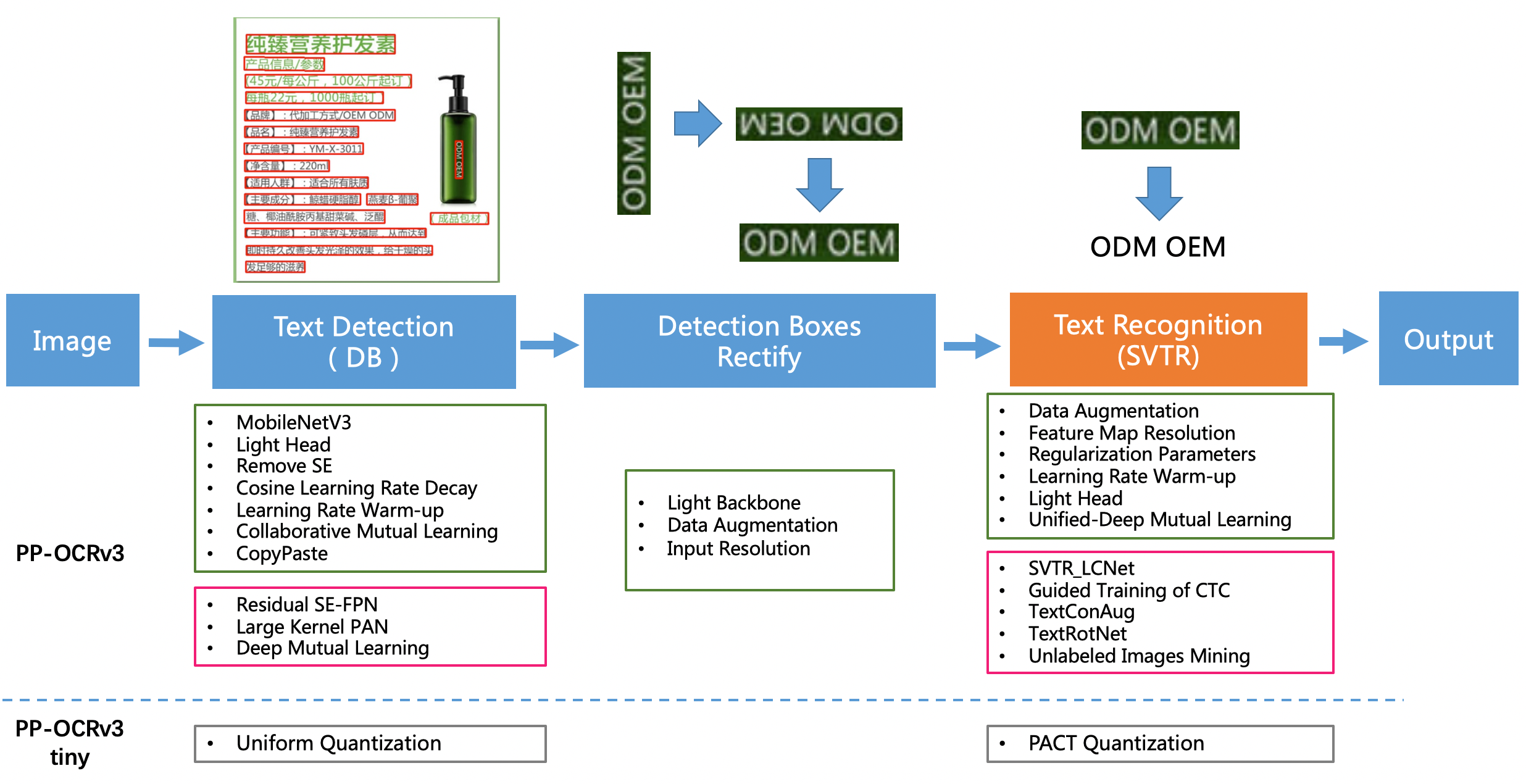
PP-OCR系统在持续迭代优化,目前已发布PP-OCR、PP-OCRv2和PP-OCRv3三个版本。PP-OCR从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化8个方面,采用19个有效策略,对各个模块的模型进行效果调优和瘦身(如绿框所示),最终得到整体大小为3.5M的超轻量中英文OCR和2.8M的英文数字OCR。
PP-OCRv2
PP-OCRv2在PP-OCR的基础上,进一步在5个方面重点优化,检测模型采用CML协同互学习知识蒸馏策略和CopyPaste数据增广策略;识别模型采用LCNet轻量级骨干网络、UDML 改进知识蒸馏策略和Enhanced CTC loss损失函数改进(如上图红框所示),进一步在推理速度和预测效果上取得明显提升。
PP-OCRv3
PP-OCRv3在PP-OCRv2的基础上,针对检测模型和识别模型,进行了共计9个方面的升级:
- PP-OCRv3检测模型对PP-OCRv2中的CML协同互学习文本检测蒸馏策略进行了升级,分别针对教师模型和学生模型进行进一步效果优化。其中,在对教师模型优化时,提出了大感受野的PAN结构LK-PAN和引入了DML蒸馏策略;在对学生模型优化时,提出了残差注意力机制的FPN结构RSE-FPN。
- PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。PP-OCRv3通过轻量级文本识别网络SVTR_LCNet、Attention损失指导CTC损失训练策略、挖掘文字上下文信息的数据增广策略TextConAug、TextRotNet自监督预训练模型、UDML联合互学习策略、UIM无标注数据挖掘方案,6个方面进行模型加速和效果提升。
3.模型下载与转换
本文中用到的所有模型均在PaddleOCR中下载,本文中给出了详细获取流程,丙夜在代码厂库中提供了本文中所用到的所有模型。
3.1 Detection model
(1)PaddlePaddle模型下载方式:
命令行直接输入以下代码,或者浏览器输入后面的网址即可。
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar
下载好后将其解压到文件夹中,便可以获得Paddle格式的推理模型。
(2)转换为ONNX格式:
该方式需要安装paddle2onnx和onnxruntime模块。在命令行中输入以下指令进行转换:
paddle2onnx --model_dir ./ch_PP-OCRv3_det_infer --model_filename inference.pdmodel --params_filename inference.pdiparams --save_file ./inference/det_onnx/model.onnx --opset_version 10 --input_shape_dict="{'x':[-1,3,640,640]}" --enable_onnx_checker True
其中在指定模型输入大小时,-1代表不指定,可以模型推理部署时在进行指定。运行上述指令后在./inference/det_onnx/路径下可以找到该模型
(3)转换为IR格式
利用OpenVINOTM模型优化器,可以实现将ONNX模型转为IR格式。
在OpenVINOTM环境下,切换到模型优化器文件夹,直接使用下面指令便可以进行转换。
mo –input_model det_onnx/model.onnx
经过上述指令模型转换后,可以在当前文件夹下找到转换后的三个文件。
3.2 Direction classifier
(1)PaddlePaddle模型下载方式:
命令行直接输入以下代码,或者浏览器输入后面的网址即可。
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
下载好后将其解压到文件夹中,便可以获得Paddle格式的推理模型。
(2)转换为ONNX格式:
该方式需要安装paddle2onnx和onnxruntime模块。在命令行中输入以下指令进行转换:
paddle2onnx --model_dir ./ch_ppocr_mobile_v2.0_cls_infer --model_filename inference.pdmodel --params_filename inference.pdiparams --save_file ./inference/cls_onnx/model.onnx --opset_version 10 --input_shape_dict="{'x':[-1,3,640,640]}" --enable_onnx_checker True
其中在指定模型输入大小时,-1代表不指定,可以模型推理部署时在进行指定。运行上述指令后在./inference/cls_onnx/路径下可以找到该模型
(3)转换为IR格式
利用OpenVINOTM模型优化器,可以实现将ONNX模型转为IR格式。
在OpenVINOTM环境下,切换到模型优化器文件夹,直接使用下面指令便可以进行转换。
mo –input_model det_onnx/model.onnx
经过上述指令模型转换后,可以在当前文件夹下找到转换后的三个文件。
3.3 Recognition model
(1)PaddlePaddle模型下载方式:
命令行直接输入以下代码,或者浏览器输入后面的网址即可。
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar
下载好后将其解压到文件夹中,便可以获得Paddle格式的推理模型。
(2)转换为ONNX格式:
该方式需要安装paddle2onnx和onnxruntime模块。在命令行中输入以下指令进行转换:
paddle2onnx --model_dir ./ch_PP-OCRv3_rec_infer --model_filename inference.pdmodel --params_filename inference.pdiparams --save_file ./inference/rec_onnx/model.onnx --opset_version 10 --input_shape_dict="{'x':[-1,3,40,6625]}" --enable_onnx_checker True
其中在指定模型输入大小时,-1代表不指定,可以模型推理部署时在进行指定。运行上述指令后在./inference/rec_onnx/路径下可以找到该模型
(3)转换为IR格式
利用OpenVINOTM模型优化器,可以实现将ONNX模型转为IR格式。
在OpenVINOTM环境下,切换到模型优化器文件夹,直接使用下面指令便可以进行转换。
mo –input_model det_onnx/model.onnx
经过上述指令模型转换后,可以在当前文件夹下找到转换后的三个文件。
4.OpenVinoSharp安装
4.1 获取OpenVinoSharp源码
OpenVinoSharp源码在GitHub和Gitee上已开源,可以直接通过Git获取所有源码
在Github上克隆下载:
git clone https://github.com/guojin-yan/OpenVinoSharp.git
在Gitee上克隆下载:
git clone https://gitee.com/guojin-yan/OpenVinoSharp.git
4.2 配置OpenVINO依赖项
OpenVinoSharp项目主要依赖OpenVINO和OpenCV两个依赖项,使用者可以根据自己安装情况配置,下文是笔者安装配置:
包含目录
OpenCV
E:\OpenCV Source\opencv-4.5.5\build\include
E:\OpenCV Source\opencv-4.5.5\build\include\opencv2
OpenVINO
C:\Program Files (x86)\Intel\openvino_2022.1.0.643\runtime\include
C:\Program Files (x86)\Intel\openvino_2022.1.0.643\runtime\include\ie
库目录
OpenCV
E:\OpenCV Source\opencv-4.5.5\build\x64\vc15\lib
OpenVINO
C:\Program Files (x86)\Intel\openvino_2022.1.0.643\runtime\lib\intel64\Release
附加依赖项
OpenCV
opencv_world455.lib
OpenVINO
openvino.lib
5. PaddleOCR
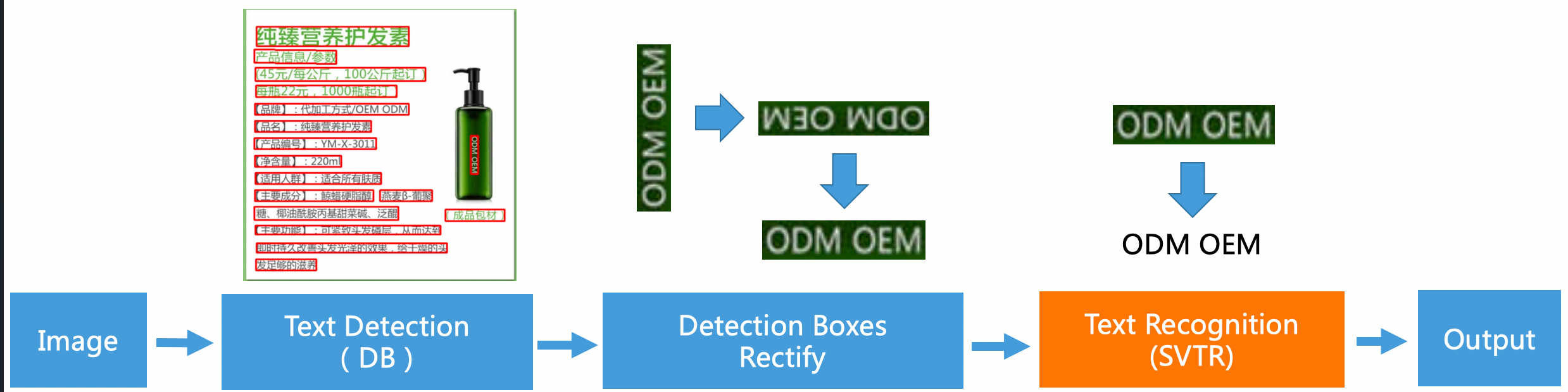
PaddleOCR文字识别分为三个阶段:文本区域识别->文字方向判断与转换->文本内容识别。
5. 1模型推理C#实现
PaddleOCR官方提供了C++与Python接口,未提供C#接口,在本文中,主要实现在C#使用OpenVINO™部署工具部署PaddleOCR全系列模型,因此需要C#中复现所有的PaddleOCR模型推理方法,对此,在本项目中构建了PaddleOCR 文字识别所需的文本推理类。
PaddleOCR基本的文本识别包括文本区域识别、文本方向判断以及文字内容识别。对与代码中的详细内容此处不做详细介绍。
(1) 模型推理基类
public class Predictor
{
protected Core m_core;
protected EnumDataType m_type = 0;
protected string m_input_name;
protected string m_output_name;
protected float[] m_mean = new float[3];
protected float[] m_scale = new float[3];
protected float[] infer(Mat img, int result_length)
{
byte[] image_data_det = img.ImEncode(".bmp");
ulong image_size_det = Convert.ToUInt64(image_data_det.Length);
// 将图片数据加载到模型
m_core.load_input_data(m_input_name, image_data_det, image_size_det, (int)m_type, m_mean, m_scale);
// 模型推理
m_core.infer();
float[] result = m_core.read_infer_result<float>(m_output_name, result_length);
return result;
}
}
(2)文本区域识别类
public class OcrDet : Predictor
{
private float m_det_db_thresh = 0.3f;
private float m_det_db_box_thresh = 0.5f;
private string m_det_db_score_mode = "slow";
private float m_det_db_unclip_ratio = 2.0f;
string m_limit_type = "max";
int m_limit_side_len = 960;
private PostProcessor m_post_processor = new PostProcessor();
private PreProcess m_preprocess = new PreProcess();
public OcrDet(string det_model, string device, string input_name, string output_name,
ulong[] input_size_det, EnumDataType type, double det_db_thresh = 0.3, double det_db_box_thresh = 0.5)
{
m_core = new Core(det_model, device);
m_type = type;
m_input_name = input_name;
m_output_name = output_name;
m_det_db_thresh = (float)det_db_thresh;
m_det_db_box_thresh = (float)det_db_box_thresh;
// 设置模型节点形状
m_core.set_input_sharp(m_input_name, input_size_det);
}
public List<List<List<int>>> predict(Mat image)
{
float ratio_h;
float ratio_w;
Mat resize_img = m_preprocess.ResizeImgType0(image, m_limit_type, m_limit_side_len, out ratio_h, out ratio_w);
ratio_h = (float)(640.0 / image.Cols);
ratio_w = (float)(640.0 / image.Rows);
int result_det_length = 640 * 640;
float[] result_det = infer(resize_img, result_det_length);
// 将模型输出转为byte格式
byte[] result_det_byte = new byte[result_det_length];
for (int i = 0; i < result_det_length; i++)
{
result_det_byte[i] = (byte)(result_det[i] * 255);
}
// 重构结果图像
Mat cbuf_map = new Mat(640, 640, MatType.CV_8UC1, result_det_byte);
Mat pred_map = new Mat(640, 640, MatType.CV_32F, result_det);
double threshold = m_det_db_thresh * 255;
double maxvalue = 255;
// 图像阈值处理
Mat bit_map = new Mat();
Cv2.Threshold(cbuf_map, bit_map, threshold, maxvalue, ThresholdTypes.Binary);
//Cv2.ImShow("bit_map", bit_map);
List<List<List<int>>> boxes = m_post_processor.BoxesFromBitmap(pred_map, bit_map, m_det_db_box_thresh, m_det_db_unclip_ratio,
m_det_db_score_mode);
boxes = m_post_processor.FilterTagDetRes(boxes, ratio_h, ratio_w, image);
return boxes;
}
}
(3) 文字方向判断类
public class OcrCls : Predictor
{
public float m_cls_thresh = 0.9f;
private PreProcess m_preprocess = new PreProcess();
public OcrCls(string cls_model, string device, string input_name, string output_name,
ulong[] input_size_det, EnumDataType type, double cls_thresh = 0.9)
{
m_core = new Core(cls_model, device);
m_type = type;
m_input_name = input_name;
m_output_name = output_name;
m_cls_thresh = (float)cls_thresh;
// 设置模型节点形状
m_core.set_input_sharp(m_input_name, input_size_det);
m_mean = new float[3] { 0.5f * 255, 0.5f * 255, 0.5f * 255 };
m_scale = new float[3] { 0.5f * 255, 0.5f * 255, 0.5f * 255 };
}
public void predict(List<Mat> img_list, List<int> lables, List<float> scores)
{
int img_num = img_list.Count;
List<int> cls_image_shape = new List<int> { 3, 48, 192 };
for (int n = 0; n < img_num; n++)
{
Mat resize_img = m_preprocess.ClsResizeImg(img_list[n], cls_image_shape);
if (resize_img.Cols < cls_image_shape[2])
{
Cv2.CopyMakeBorder(resize_img, resize_img, 0, 0, 0, cls_image_shape[2] - resize_img.Cols,
BorderTypes.Constant, new Scalar(0, 0, 0));
}
int result_cls_length = 2;
float[] result_cls = infer(resize_img, result_cls_length);
int lable = result_cls[0] > result_cls[1] ? 0 : 1;
lables.Add(lable);
scores.Add(result_cls[lable]);
//Console.WriteLine("({0}, {1})", result_cls[0], result_cls[1]);
}
}
}
(4)文字内容识别
public class OcrRec : Predictor
{
private int[] m_rec_image_shape;
List<string> m_label_list;
private PostProcessor m_post_processor = new PostProcessor();
private PreProcess m_preprocess = new PreProcess();
public OcrRec(string det_model, string device, string input_name, string output_name,
ulong[] input_size_rec, EnumDataType type, string label_path)
{
m_core = new Core(det_model, device);
m_type = type;
m_input_name = input_name;
m_output_name = output_name;
m_label_list = Utility.ReadDict(label_path);
m_label_list.Insert(0, "#");
m_label_list.Add(" ");
m_rec_image_shape = new int[] { (int)input_size_rec[1], (int)input_size_rec[2], (int)input_size_rec[3] };
// 设置模型节点形状
m_core.set_input_sharp(m_input_name, input_size_rec);
m_mean = new float[3] { 0.5f * 255, 0.5f * 255, 0.5f * 255 };
m_scale = new float[3] { 0.5f * 255, 0.5f * 255, 0.5f * 255 };
}
public void predict(List<Mat> img_list, List<string> rec_texts, List<float> rec_text_scores)
{
int img_num = img_list.Count;
List<float> width_list = new List<float>();
for (int i = 0; i < img_num; i++)
{
width_list.Add((float)(img_list[i].Cols) / img_list[i].Rows);
}
List<int> indices = Utility.argsort(width_list);
for (int n = 0; n < img_num; n++)
{
int imgH = m_rec_image_shape[1];
int imgW = m_rec_image_shape[2];
float max_wh_ratio = imgW * 1.0f / imgH;
int h = img_list[n].Rows;
int w = img_list[n].Cols;
float wh_ratio = w * 1.0f / h;
max_wh_ratio = Math.Max(max_wh_ratio, wh_ratio);
Mat resize_img = m_preprocess.CrnnResizeImg(img_list[n].Clone(), max_wh_ratio, m_rec_image_shape);
int result_cls_length = 40 * 6625;
float[] result_cls = infer(resize_img, result_cls_length);
string str_res = "";
int argmax_idx;
int last_index = 0;
float score = 0.0f;
int count = 0;
float max_value = 0.0f;
for (int r = 0; r < 40; r++)
{
float[] temp = new float[6625];
for (int j = 0; j < 6625; j++)
{
temp[j] = result_cls[r * 6625 + j];
}
argmax_idx = Utility.argmax(temp, out max_value);
if (argmax_idx > 0 && (!(n > 0 && argmax_idx == last_index)))
{
score += max_value;
count += 1;
str_res += m_label_list[argmax_idx];
}
last_index = argmax_idx;
}
score /= count;
rec_texts.Add(str_res);
rec_text_scores.Add(score);
}
}
}
5.2 文字识别结果类
为了更好的存放文字识别结果,构建了结果类:
public class OCRPredictResult
{
public List<List<int>> box = new List<List<int>>();
public string text = "";
public float score = -1.0f;
public float cls_score = -1.0f;
public int cls_label = -1;
}
5.3 PaddleOCR类
根据PaddleOCR文字识别的三个阶段,此处根据是实现的模型推理C#实现的方法,完整的实现文本识别,此处构建了PaddleOCR推理类:
public class PaddleOCR
{
OcrDet ocrDet;
OcrCls ocrCls;
OcrRec ocrRec;
public PaddleOCR(Dictionary<string, string> model_path){}
public List<OCRPredictResult> predict_det(Mat image){}
public void predict_cls(List<Mat> img_list, List<OCRPredictResult> ocr_results){}
public void predict_rec(List<Mat> img_list, List<OCRPredictResult> ocr_results){}
public List<OCRPredictResult> predict(Mat image){}
}
predict_det:文本区域识别
通过调用OcrDet模型推理类,识别待预测图片中包含文字的区域,并通过文字区域提取算法,提取完整的文本区域。
public List<OCRPredictResult> predict_det(Mat image)
{
List<OCRPredictResult> ocr_results = new List<OCRPredictResult>();
// 文字区域识别
List<List<List<int>>> boxes = ocrDet.predict(image);
for (int i = 0; i < boxes.Count; i++)
{
OCRPredictResult res = new OCRPredictResult();
res.box = boxes[i];
ocr_results.Add(res);
}
ocr_results = ocr_results.OrderBy(t => t.box[0][1]).ThenBy(t => t.box[0][0]).ToList();
return ocr_results;
}
predict_cls:文本方向判断
通过调用OcrCls模型推理类,识别裁剪后的文字区域方向,主要是实现将反向的文字识别出来并作转换。
public void predict_cls(List<Mat> img_list, List<OCRPredictResult> ocr_results)
{
List<int> lables = new List<int>();
List<float> scores = new List<float>();
ocrCls.predict(img_list, lables, scores);
// output cls results
for (int i = 0; i < lables.Count; i++)
{
ocr_results[i].cls_label = lables[i];
ocr_results[i].cls_score = scores[i];
}
}
predict_rec:文字内容识别
通过调用OcrRec模型推理类,识别裁剪后的文字区域中的文字,并根据文字结果字典,获取识别后的文字内容。
public void predict_rec(List<Mat> img_list, List<OCRPredictResult> ocr_results)
{
List<string> rec_texts = new List<string>();
List<float> rec_text_scores = new List<float>();
ocrRec.predict(img_list, rec_texts, rec_text_scores);
for (int i = 0; i < rec_texts.Count; i++)
{
ocr_results[i].text = rec_texts[i];
ocr_results[i].score = rec_text_scores[i];
}
}
predict:文字识别
分别调用前面封装的predict_rec()、predict_cls()、**predict_det()**方法,实现文字识别的整体流程。
public List<OCRPredictResult> predict(Mat image)
{
DateTime start = DateTime.Now;
// 文本区域识别
List<OCRPredictResult> ocr_results = predict_det(image);
// crop image
List<Mat> img_list = new List<Mat>();
for (int j = 0; j < ocr_results.Count; j++)
{
Mat crop_img = Utility.GetRotateCropImage(image, ocr_results[j].box);
img_list.Add(crop_img);
//Cv2.ImShow("resize_img", crop_img);
//Cv2.WaitKey(0);
}
// 文字方向判断
predict_cls(img_list, ocr_results);
for (int i = 0; i < img_list.Count; i++)
{
if (ocr_results[i].cls_label % 2 == 1 &&
ocr_results[i].cls_score > ocrCls.m_cls_thresh) { }
else
{
Cv2.Rotate(img_list[i], img_list[i], RotateFlags.Rotate180);
}
}
predict_rec(img_list, ocr_results);
DateTime end = DateTime.Now;
TimeSpan timeSpan = end - start;
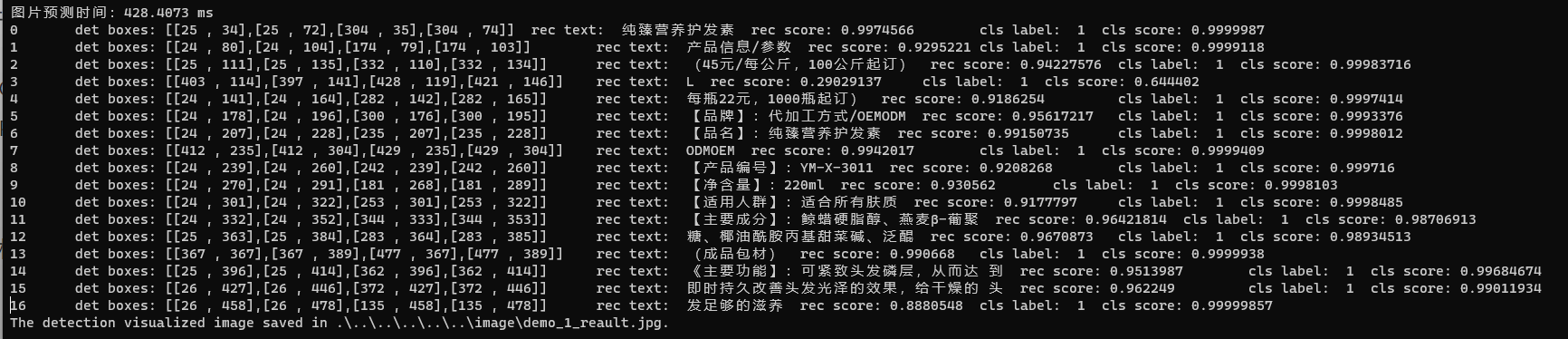
Console.WriteLine("图片预测时间:{0} ms", timeSpan.TotalMilliseconds);
return ocr_results;
}
5.3 其他类
该项目还包含其他文本以及图片处理类,由于内容较多,此处不做赘述,可以通过查看项目源码获取。
6. 文本识别过程与结果
在前面我们已经对文本识别方法进行了封装,最后在使用时,我们只需要指定预测模型与测试图片,调用PaddleOCR类即可实现。
public void test()
{
string det_path = @".\..\..\..\..\..\model\ppocr_model_v3\det_onnx\model.onnx";
string cls_path = @".\..\..\..\..\..\model\\ppocr_model_v3\cls_onnx\model.onnx";
string rec_path = @".\..\..\..\..\..\model\\ppocr_model_v3\rec_onnx\model.onnx";
// 模型路径
Dictionary<string, string> model_path = new Dictionary<string, string>();
model_path.Add("det_model", det_path);
model_path.Add("cls_model", cls_path);
model_path.Add("rec_model", rec_path);
PaddleOCR paddleOCR = new PaddleOCR(model_path);
string image_path = @".\..\..\..\..\..\image\demo_1.jpg";
Mat image = Cv2.ImRead(image_path);
List<OCRPredictResult> ocr_results = paddleOCR.predict(image);
Utility.print_result(ocr_results);
string save_path = Path.GetDirectoryName(image_path) + "\\" + Path.GetFileNameWithoutExtension(image_path) + "_reault.jpg";
Utility.VisualizeBboxes(image.Clone(), ocr_results, save_path);
}
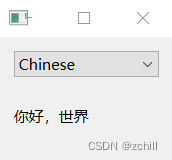
下图是文本区域识别与处理后的文本区域,可以看出经过模型识别与轮廓处理,已经可以实现文本区域完全获取。

根据识别结果,识别文本方向并最后识别文字内容。