数据库管理 2023-05-03
- 第七十一期 五一,休息?
- 1 备份
- 2 两个DDL
- 3 问题处理
- 4 问题排查
- 总结
第七十一期 五一,休息?
好不容易,熬过万恶的6天班来到了五一假期,想着好好休息,顺便把绝地幸存者给通关(优化稀烂,更新后好了一点)
结果X8那套库连着两条出问题(虽然覆盖这台维护的新合同还没签下来,但是影响生产了就要处理吧),搞得假期充满了烦躁。
1 备份
先说后面发生的那个问题,是NBU存储满了,定期的归档日志备份没有执行,也就没有删除已备份的归档日志,造成了FRA满了,归档卡住引起数据库不可用。好的一点是8点不到发生而且是五一当天,影响不是太大,连到服务器执行:
rman target /
RMAN> delete archivelog all completed before 'sysdate-0.5';
归档日志删除过程中数据库就恢复正常了,这个就没啥好分析的了。
2 两个DDL
这是五一假期第一天出现的问题(游戏打的正嗨时!),当时是数据库出现性能问题了,大概发生时间是14:00-14:30,通知到我这登陆到服务器已经14:50之后了,正在查看问题发现故障时段出现了大量的library cache lock、cursor: pin S wait on X和row cache lock:

同时通过问题时段AWR报表中Top Blocking Sessions段落进行排查:
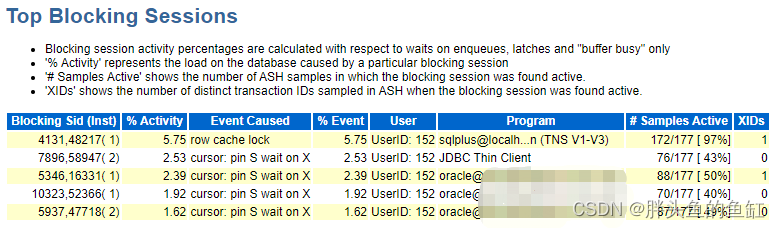
发现顶级锁会话是一条create table as select的DDL语句。
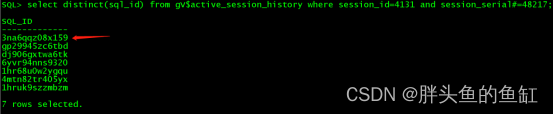

这条语句在EM的SQL记录中也在问题时段同时执行了两条,只不过另一条是从2点开始的,接近2点半就失败了。
根据前一张图,排查到3点的时候数据库再次出现性能问题,和2点到2点半的情况一致,是两条相同的create table as select DDL语句在同时执行引起的,随即在3点08分的样子干掉实例1运行的,session_id为4131,session_serial#为48217的会话,数据库随即恢复正常。
后续排查发现出现问题的语句执行了4小时以上,3点新发起的语句后面也执行了超过1小时没有完成,而根据业务方反馈,这条语句已执行1年以上,第一次出现问题。
3 问题处理
- 业务场景
业务需求每一个小时会对全量的基站数据进行刷新,出现问题的语句为其中一步,前面还CTAS了几张临时表用于数据刷新。由于该任务是通过SQL脚本与crontab实现,所以没有异常处置,当任务异常时,后面的任务仍然会继续执行,从而导致两条相同CTAS DDL语句冲突引起大面积数据库等待,出现性能问题。
只不过这里发现第一个异常任务执行开始后,后面前2小时几乎没啥影响,分析应该为后续语句快速失败了,第三个小时和第四个小时就出现了问题。业务方在出现问题后就暂停了这个任务,由非即时数据支撑生产。 - 语句排查
首先先看看这条语句的情况:
-- sql_id: 3na6qqz08x159
create table temp_ponptp_sp as
select
e.city_id,e.county_name,
b.g1000_flag,
e.zh_label cell_name,
d.zh_label cover_area,
c.related_olt olt_name,
c.olt_neport_pon_m olt_port,
d.all_port_num,d.zyfg_sbkydks
from
rms_trans_neport a,
temp_ponptp_cardtype b, --临时表
rms_splitter c,
rms_area_cell d,
rms_wcell e
where
a.related_ne=b.olt_id
and a.related_card=b.card_int
and a.card_type=b.card_type
and a.stateflag=0
and b.olt_name=c.related_olt
and a.old_name=c.olt_neport_pon_m
and c.city_id=b.city_id
and c.stateflag=0
and c.cover_area=d.zh_label
and c.city_id=d.city_id
and d.stateflag=0
and e.zh_label=d.zyfg_ssxq
and e.city_id=d.city_id
and e.stateflag=0
结合SQL Monitor:
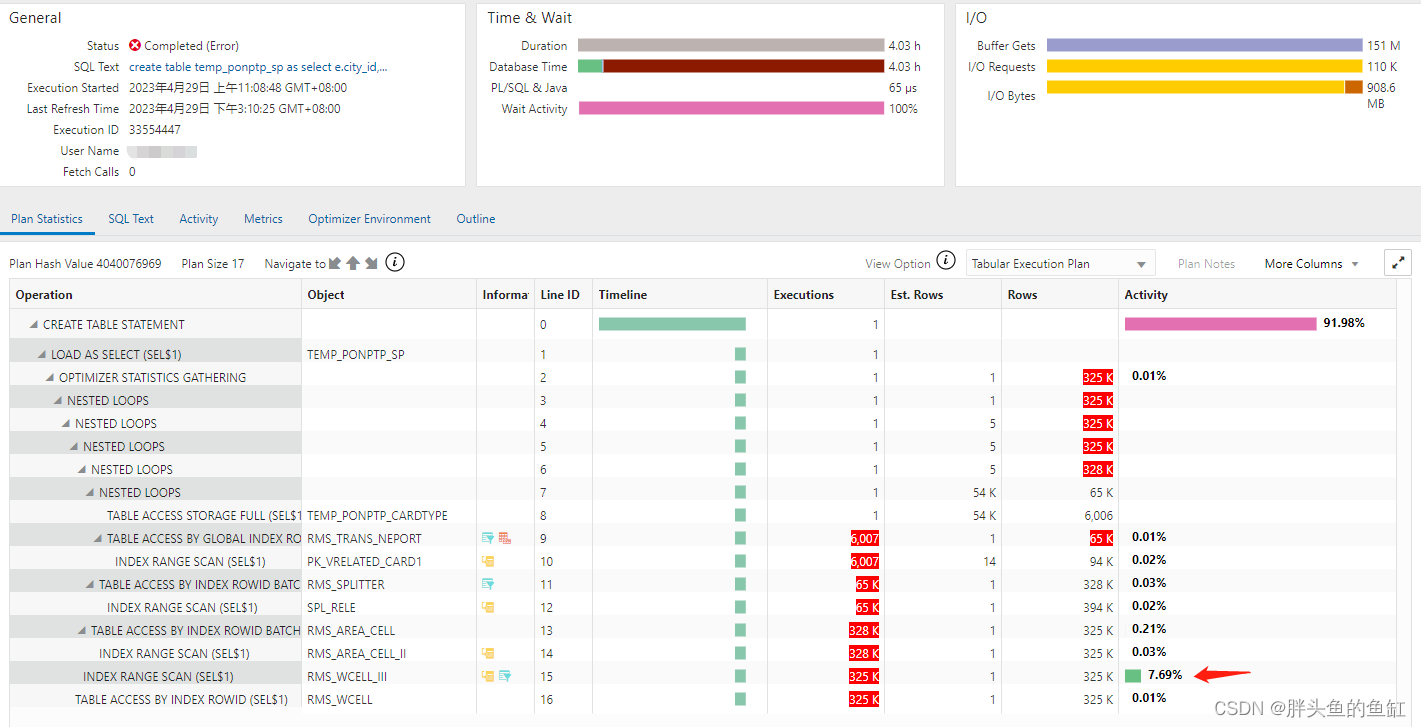
排查出该语句在RMS_WCELL表的索引RMS_WCELL_III索引上花费最多。随即排查该索引:

回头看看语句,涉及RMS_WCELL列的筛选顺序为zh_label、city_id、stateflag,而复合索引第一列为CITY_ID,初步排查为zh_label列并未走索引。随即反馈业务方,开发直接在zh_label列建立了索引,再次执行,2分半即完成,对应的SQL Monitor如下:
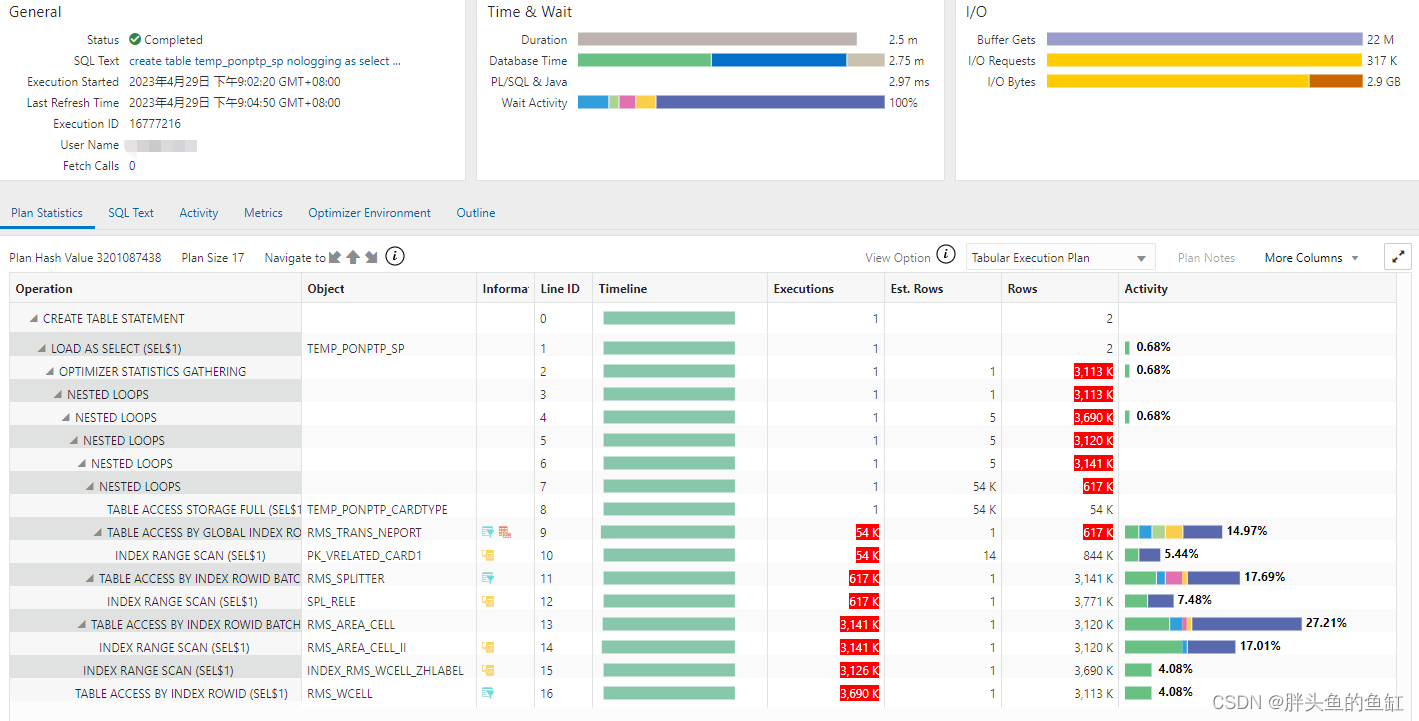
从执行计划各项细节来看,各表的活动花费比例正常,同时IO执行也正常。
完成SQL优化后,业务方也对任务进行了调整,添加了异常检测与告警,避免任务同时执行。
4 问题排查
其实library cache lock、cursor: pin S wait on X和row cache lock等待的分析相对比较简单,数据库在某些操作过程中会产生一系列锁,即是用于确保SQL执行顺序,也是数据一致性的保证。两条相同的CTAS,保持了相同的建表对象,同时执行过程中会维护一系列redo和undo信息(同时也会冲突),一系列复合的原因造成了性能问题。
而语句本身的性能问题,才是我客户最关心的问题,其实在我看来,相较于一年前上线时,数据库的数据量和压力都提升了不少。也许在原来的数据量情况下,原有的索引是可以跑出结果的,量变引发质变,现有的数据量却无法用原有索引高效执行。
回到三十二期说过的,数据库管理是一个持续的过程,其实这系列语句还有很多地方需要优化,还有不少全表扫,同时也希望能不走nest loop。
插播一下:阿三的英语啊,真是不得行,听不懂,而且处理问题的态度主要也是“卡BUG”(就是看个大概,然后去匹配BUG,懒得去就事论事),SR中的反馈分析基本都是我的分析过程,明天上班了,转回国内。
总结
最终绝地幸存者主线也打完了,后面等优化好点了再玩。
老规矩,知道写了些啥。