笔者实现的这个超级迷你版编译器(词法分析、语法分析、生成中间代码(cpp))仅支持四则运算,功能真的是非常非常简单,不过其中的流程(词法分析 -> 语法分析 -> 中间代码生成)还是有一定的学习价值的,可以把这些阶段都给串起来,看看不同的处理阶段是如何衔接的,而不是仅仅停留在教科书中各个分裂的模块里。
myCompiler.cpp
该文件涵盖了词法分析,语法分析,中间代码生成这三个部分,可以更清楚地观察源语言是怎么一步步通过词法分析器转换为token序列,再由token序列根据递归下降算法构建抽象语法树,最后根据抽象语法树生成中间代码的。(注:笔者将此编译器的中间代码选为cpp,并不是传统意义上的汇编代码哈,主要是汇编代码不大熟悉)
#include <iostream>
#include <iterator>
#include <fstream>
#include <stdexcept>
#include <string>
#include <vector>
using namespace std;
enum class TokenType
{
Keyword,
Identifier,
Number,
Operator,
Separator,
Comment
};
struct Token
{
TokenType type;
string value;
};
vector<Token> lex(const string &input)
{
vector<Token> tokens;
size_t i = 0;
while (i < input.length())
{
char c = input[i];
if (isspace(c))
{
i++;
}
else if (isalpha(c) || c == '_')
{
string identifier;
while (i < input.length() && (isalnum(input[i]) || input[i] == '_'))
{
identifier.push_back(input[i]);
i++;
}
if (identifier == "int")
{
tokens.push_back({TokenType::Keyword, identifier});
}
else
{
tokens.push_back({TokenType::Identifier, identifier});
}
}
else if (isdigit(c))
{
string number;
while (i < input.length() && isdigit(input[i]))
{
number.push_back(input[i]);
i++;
}
tokens.push_back({TokenType::Number, number});
}
else if (c == '+' || c == '-' || c == '*' || c == '/' || c == '=')
{
tokens.push_back({TokenType::Operator, string(1, c)});
i++;
}
else if (c == ';' || c == ',')
{
tokens.push_back({TokenType::Separator, string(1, c)});
i++;
}
else if (c == '/')
{
if (i + 1 < input.length() && input[i + 1] == '/')
{
i += 2;
string comment;
while (i < input.length() && input[i] != '\n')
{
comment.push_back(input[i]);
i++;
}
tokens.push_back({TokenType::Comment, comment});
}
else if (i + 1 < input.length() && input[i + 1] == '*')
{
i += 2;
string comment;
while (i + 1 < input.length() && !(input[i] == '*' && input[i + 1] == '/'))
{
comment.push_back(input[i]);
i++;
}
if (i + 1 < input.length())
{
i += 2;
// comment.push_back(input[i]);
// i++;
// comment.push_back(input[i]);
// i++;
}
tokens.push_back({TokenType::Comment, comment});
}
else
{
tokens.push_back({TokenType::Operator, string(1, c)});
i++;
}
}
else
{
throw runtime_error(" Invalid character: " + string(1, c));
}
}
return tokens;
}
enum class ASTNodeType
{
Program,
Declaration,
Assignment,
BinaryExpression,
Identifier,
IntegerLiteral
};
struct ASTNode
{
ASTNodeType type;
string value;
vector<ASTNode> children;
};
class Parser
{
public:
Parser(const vector<Token> &tokens) : tokens(tokens), index(0) {}
ASTNode parse()
{
ASTNode program{ASTNodeType::Program, "", {}};
while (index < tokens.size())
{
program.children.push_back(parseStatement());
}
return program;
}
private:
const vector<Token> &tokens;
size_t index;
ASTNode parseStatement()
{
ASTNode statement;
if (tokens[index].type == TokenType::Keyword && tokens[index].value == "int")
{
statement = parseDeclaration();
}
else
{
statement = parseAssignment();
}
// 跳过语句后面的分号
if (tokens[index].type == TokenType::Separator && tokens[index].value == ";")
{
index++;
}
else
{
throw runtime_error(" Expected ';' at the end of the statement");
}
return statement;
}
ASTNode parseDeclaration()
{
ASTNode declaration{ASTNodeType::Declaration, "", {}};
// 跳过关键字int
index++;
if (tokens[index].type == TokenType::Identifier)
{
// 将声明节点的值设置为标识符的名字
declaration.value = tokens[index].value;
index++;
}
else
{
throw runtime_error(" Expected an identifier in declaration");
}
return declaration;
}
ASTNode parseAssignment()
{
ASTNode assignment{ASTNodeType::Assignment, "", {}};
if (tokens[index].type == TokenType::Identifier)
{
// 添加标识符作为子节点
assignment.children.push_back({ASTNodeType::Identifier, tokens[index].value, {}});
index++;
}
else
{
throw runtime_error(" Expected an identifier in assignment");
}
if (tokens[index].type == TokenType::Operator && tokens[index].value == "=")
{
// 跳过赋值操作的"="
index++;
}
else
{
throw runtime_error(" Expected '=' in assignment");
}
assignment.children.push_back(parseExpression());
return assignment;
}
ASTNode parseExpression()
{
ASTNode expression{ASTNodeType::BinaryExpression, "", {}};
// 处理第一个操作数(数字或标识符)
if (tokens[index].type == TokenType::Number)
{
// 添加整数字面量作为子节点
expression.children.push_back({ASTNodeType::IntegerLiteral, tokens[index].value, {}});
}
else if (tokens[index].type == TokenType::Identifier)
{
// 添加标识符作为子节点
expression.children.push_back({ASTNodeType::Identifier, tokens[index].value, {}});
}
else
{
throw runtime_error(" Expected a number or an identifier in expression");
}
index++;
if (tokens[index].type == TokenType::Operator &&
(tokens[index].value == "+" || tokens[index].value == "-" ||
tokens[index].value == "*" || tokens[index].value == "/"))
{
// 将二元表达式节点的值设置为运算符
expression.value = tokens[index].value;
index++;
}
else
{
throw runtime_error(" Expected an operator in expression");
}
// 处理第二个操作数(数字或标识符)
if (tokens[index].type == TokenType::Number)
{
// 添加整数字面量作为子节点
expression.children.push_back({ASTNodeType::IntegerLiteral, tokens[index].value, {}});
}
else if (tokens[index].type == TokenType::Identifier)
{
// 添加标识符作为子节点
expression.children.push_back({ASTNodeType::Identifier, tokens[index].value, {}});
}
else
{
throw runtime_error(" Expected a number or an identifier in expression");
}
index++;
return expression;
}
};
void printTokens(const vector<Token> &tokens)
{
cout << "Tokens:" << endl;
for (const auto &token : tokens)
{
cout << token.value << " ";
}
cout << endl;
}
/*
enum class ASTNodeType
{
Program,
Declaration,
Assignment,
BinaryExpression,
Identifier,
IntegerLiteral
};
*/
void printAST(const ASTNode &node, int indent = 0)
{
string indent_str(indent, ' ');
cout << indent_str << "Node: type=";
// << static_cast<int>(node.type) << ", value=" << node.value << endl;
switch (node.type)
{
case ASTNodeType::Program:
cout << "Program";
break;
case ASTNodeType::Declaration:
cout << "Declaration";
break;
case ASTNodeType::Assignment:
cout << "Assignment";
break;
case ASTNodeType::BinaryExpression:
cout << "BinaryExpression";
break;
case ASTNodeType::Identifier:
cout << "Identifier";
break;
case ASTNodeType::IntegerLiteral:
cout << "IntegerLiteral";
break;
}
cout << ", value=" << node.value << endl;
for (const auto &child : node.children)
{
printAST(child, indent + 2);
}
}
// string generateCode(const ASTNode &node)
// {
// string code;
// switch (node.type)
// {
// case ASTNodeType::Declaration:
// code += "int " + node.value + ";\n";
// break;
// case ASTNodeType::Assignment:
// code += node.children[0].value + " = " + generateCode(node.children[1]) + ";\n";
// break;
// case ASTNodeType::BinaryExpression:
// code += generateCode(node.children[0]) + " " + node.value + " " + generateCode(node.children[1]);
// break;
// case ASTNodeType::IntegerLiteral:
// code += node.value;
// break;
// case ASTNodeType::Identifier:
// code += node.value;
// break;
// default:
// throw runtime_error("Unknown AST node type in code generation");
// }
// return code;
// }
string generateCode(const ASTNode &node)
{
string code;
switch (node.type)
{
case ASTNodeType::Program:
for (const auto &child : node.children)
{
code += generateCode(child);
}
break;
case ASTNodeType::Declaration:
code += "int " + node.value + ";\n";
break;
case ASTNodeType::Assignment:
code += generateCode(node.children[0]) + " = " + generateCode(node.children[1]) + ";\n";
break;
case ASTNodeType::BinaryExpression:
code += "(" + generateCode(node.children[0]) + " " + node.value + " " + generateCode(node.children[1]) + ")";
break;
case ASTNodeType::IntegerLiteral:
code += node.value;
break;
case ASTNodeType::Identifier:
code += node.value;
break;
default:
throw runtime_error(" Unknown AST node type in code generation");
}
// cout << "here :" << endl;
// for (size_t i = 2; i < node.children.size(); ++i)
// {
// cout << static_cast<int>(node.children[i].type) << ", value=" << node.children[i].value << endl;
// code += generateCode(node.children[i]);
// }
return code;
}
int main(int argc, char** argv)
{
if (argc <= 1)
{
cout << "mjn reminds you:\nplease input filename like './myCompiler filename'" << endl;
return 0;
}
string filename = argv[1];
ifstream infile(filename);
if (!infile)
{
cerr << "mjn reminds you:\nError opening input file" << endl;
return 1;
}
string input((istreambuf_iterator<char>(infile)), istreambuf_iterator<char>());
vector<Token> tokens;
try
{
tokens = lex(input);
}
catch (const runtime_error &e)
{
cerr << "mjn reminds you~\nLexer error: " << e.what() << endl;
return 1;
}
printTokens(tokens);
Parser parser(tokens);
ASTNode ast;
string generatedCode;
try
{
ast = parser.parse();
generatedCode = generateCode(ast);
}
catch (const runtime_error &e)
{
cerr << "mjn reminds you~\nParser error: " << e.what() << endl;
return 1;
}
cout << "Abstract Syntax Tree:" << endl;
printAST(ast);
ofstream outputFile("output.cpp");
outputFile << generatedCode;
outputFile.close();
cout << "mjn reminds you:\nCode generation complete. Output written to 'output.cpp'." << endl;
return 0;
}
input.txt
此编译器的输入文件(注意,仅支持声明单个变量,不能同时声明多个哈,比如,int a, b; 就不可以哈,还有只能是二元表达式,仅支持 a = b op c; 的形式哈,所以说,这个编译器真的是非常非常简单hh~)
int a;
int b;
a = 3 + 5;
b = a * 2;
还有一点需要注意的是,在执行生成的myCompiler时,后面需要跟上待编译文件的名称,不然会弹出如下提示hh~

如果输入的文件名不存在,则会提示找不到该文件

正确输入文件名后,打印出token序列,构建好的抽象语法树,并提示输出中间代码到新文件output.cpp中
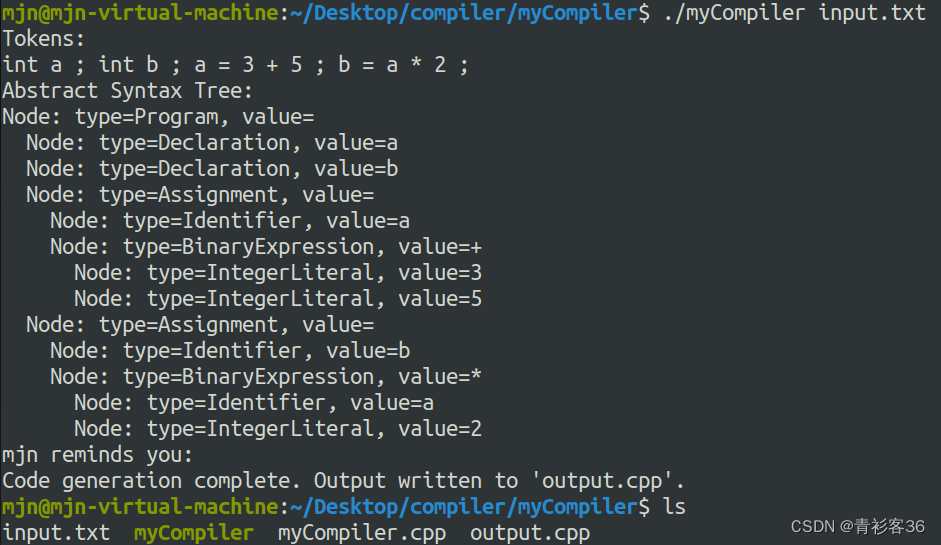
output.cpp中的内容如下:

如果输入文件中的语法不正确,比如,同时声明了多个变量(如下所示)
int a;
int b, c, d;
a = 3 + 5;
b = a * 2;
就会报语法解析错误,没有按照规定(即只能声明单个变量)来做,int b后面必须跟上";"

总结:通过自己构建这样一个功能超级简单的编译器,加深了对龙书上面的知识点的理解,最重要的是,对于编译器的各个处理模块之间的数据流向及其转换形式有了一个深刻、直观的认识。
再次说明一下,笔者写的这个编译器(我甚至都不愿称之为编译器,因为功能实在是太简单了,呜呜呜)功能极其简单,感兴趣的读者可以在此基础上肆意发挥哈,尽情地扩充其他功能。