1.语句
1.1.if…elif…else
类似于java的if…else if…else语句
1.1.1.判断条件
比较运算符: ==、>、<、<=、>=、!=、is、is not、in、not in
1.1.2.==和is的区别
list_1 = ['aaa', 'bbb']
list_2 = ['aaa', 'bbb']
print(list_1 == list_2)
#结果:True
print(list_1 is list_2)
#结果:False
== 判断值是否是相同
is 判断两个对象是不是同一个对象
1.2.循环
1.2.1.while
a = 1
while a <= 10:
print(a)
a += 1
1.2.2.for
b = [1, 2, 3, 4, 5, 6, 7, 8, 9]
for i in b:
print(i)
#或者
for c in range(1, 10):
print(c)
能使用for就尽量不要使用while
1.2.3.获取索引
d = ['a', 'b', 'c', 'd', 'e', 'f']
for index,j in enumerate(d):
print(index, j)
1.2.4.while True…break
x = 1
while True:
if x < 10:
print(x)
else:
break
x += 1
1.3.排序
print(sorted([4,3,5,7,1]))
#结果: [1, 3, 4, 5, 7]
按字母表排序, 区分大小写
print(sorted('AbDcPa'))
#结果:['A', 'D', 'P', 'a', 'b', 'c']
按字母表顺序, 且不区分大小写, 相同字母默认先大写后小写
print(sorted('AbDcPa', key=str.lower))
#结果:['A', 'a', 'b', 'c', 'D', 'P']
倒序函数
print(list(reversed('AbDcPa')))
#结果:['a', 'P', 'c', 'D', 'b', 'A']
1.4.eval
将字符串转为表达式, 并返回结果
print(eval('1 + 2 * 4 - 3'))
#结果:6
1.5.exec
将字符串转为代码, 并执行
exec("for i in range(10):\
print(i)")
结果:
0
~
9
2.读写文件
2.1.csv
2.1.1.读取
import csv
with open('test_reader.csv', 'r') as csvfile:
spamreader = csv.reader(csvfile)
for row in spamreader:
print(','.join(row))
2.1.2.写入
with open('test_writer.csv', 'w') as csvfile:
spamwriter = csv.writer(csvfile)
for row in range(10):
spamwriter.writerow(['key-' + str(row),'value-' + str(row),'comment-' + str(row)])
2.2.config
读取类似.config、.properties文件
2.2.1.读取
文件名称:test_conf.config, 文件内容:
[user]
name=fracong
[server]
ip=127.0.0.1
代码:
from configparser import ConfigParser
parser = ConfigParser()
parser.read('test_conf.config')
print(parser.get('user', 'name'))
print(parser.get('server', 'ip'))
#结果:
fracong
127.0.0.1
2.2.2.写入
from configparser import ConfigParser
config = ConfigParser()
config['user'] = {
'name': 'fracong',
'age': 33
}
with open('test_conf2.config', 'w') as configfile:
config.write(configfile)
输出内容:
[user]
name = fracong
age = 33
2.3.xml
2.3.1.ElementTree
2.3.1.1.读取
文件名称:read_xml.xm, 文件内容
<root version="1.1">
<name>fracong</name>
</root>
读取代码
import xml.etree.ElementTree as ET
tree = ET.parse('read_xml.xml')
root = tree.getroot()
print(root.tag)
print(root.attrib['version'])
for elem in list(root):
print(elem.tag)
#结果:
root
1.1
name
2.3.1.2.写入
import xml.etree.ElementTree as ET
root_write = ET.Element("root")
root_write.set("version", "1.2")
name_elem = ET.SubElement(root_write, "name", test="true")
name_elem.text='fracong'
tree_write = ET.ElementTree(root_write)
tree_write.write('write_xml.xml')
结果
<root version="1.2"><name test="true">fracong</name></root>
2.3.2.minidom
2.3.2.1.读取
文件名称:read_xml.xm, 文件内容
<root version="1.1">
<name>fracong</name>
</root>
读写代码
from xml.dom import minidom
read_file_1 = minidom.parse('read_xml.xml')
read_root_1 = read_file_1.getElementsByTagName('root')[0]
for it in read_root_1.attributes.values():
print(it.name, it.value)
2.3.2.2.写入
from xml.dom import minidom
doc = minidom.Document()
root = doc.createElement('root')
root.setAttribute("version", "1.2")
doc.appendChild(root)
name = doc.createElement('name')
name.setAttribute("test", "true")
fracong_text = doc.createTextNode("fracong")
name.appendChild(fracong_text)
root.appendChild(name)
xml_str = doc.toprettyxml(indent ="\t") # 格式化
#或者使用doc.toxml() 非格式化
#xml_str = doc.toxml()
with open('write_xml2.xml', 'w') as xmlfile:
xmlfile.write(xml_str)
结果:
<?xml version="1.0" ?>
<root version="1.2">
<name test="true">fracong</name>
</root>
2.4.parquet
说明: parquet文件一般用于大数据
前提: 安装pandas
pip3 install pandas
2.4.1.写入
import pandas as pd
field_list = ["Name","Age","Content"]
data_1 = ["fracong","33","xxx.xxx"]
data_2 = ["fracong2","32","xxx.xxx1"]
data_list = []
data_list.append(data_1)
data_list.append(data_2)
df = pd.DataFrame(data_list, columns = field_list)
path = 'test.parquet'
df.to_parquet(path)
DataFrame的第一个是数据, 第二个参数是字段名
2.4.2.读取
import pandas as pd
path = 'test.parquet'
df = pd.read_parquet(path)
print(df)
结果:
Name Age Content
0 fracong 33 xxx.xxx
1 fracong2 32 xxx.xxx1
2.5.excel
安装pandas和openpyxl
pip3 install pandas
pip install openpyxl
2.5.1.使用pandas
2.5.1.1.写入
import pandas as pd
field_list = ["Name","Age","Content"]
data_1 = ["fracong","33","xxx.xxx"]
data_2 = ["fracong2","32","xxx.xxx1"]
data_list = []
data_list.append(data_1)
data_list.append(data_2)
df = pd.DataFrame(data_list, columns = field_list)
df.to_excel('test.xlsx')
结果:
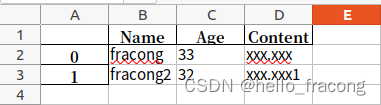
2.5.1.2.读取
import pandas as pd
workbook = pd.read_excel('test.xlsx', sheet_name=0)
print(workbook)
print('--------##--------------')
print(workbook['Name'].iloc[0])
结果:
Unnamed: 0 Name Age Content
0 0 fracong 33 xxx.xxx
1 1 fracong2 32 xxx.xxx1
--------##--------------
fracong
2.5.2.使用openpyxl
2.5.2.1.写入
import openpyxl
workbook = openpyxl.Workbook()
sheet1 = workbook.create_sheet("Test1", index=0)
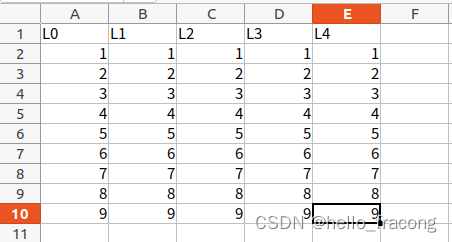
row0 = ['L0', 'L1', 'L2', 'L3', 'L4']
for i in range(1, 10):
for j in range(1, len(row0)):
if i == 1:
sheet1.cell(row=i, column=j).value = row0[j]
else:
sheet1.cell(row=i, column=j).value = i
path2 = "test2.xlsx"
workbook.save(path2)
行和列都是从1开始的
结果:
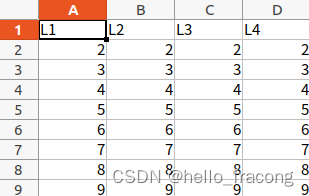
2.5.2.2.读取
path2 = "test2.xlsx"
wb_obj = openpyxl.load_workbook(path2)
sheet_obj = wb_obj.active
cell_obj = sheet_obj.cell(row = 1, column = 1)
print(cell_obj.value)
结果:
L1
2.5.3.使用XlsxWriter写入
安装
pip install XlsxWriter
写入
import xlsxwriter
workbook2 = xlsxwriter.Workbook('test3.xlsx')
worksheet2 = workbook2.add_worksheet()
row0 = ['L0', 'L1', 'L2', 'L3', 'L4']
for i in range(10):
for j in range(len(row0)):
if i == 0:
worksheet2.write(i, j, row0[j])
else:
worksheet2.write(i, j, i)
workbook2.close()
结果: