环境:centos7.6,腾讯云服务器
Linux文章都放在了专栏:【Linux】欢迎支持订阅相关文章推荐:
【Linux】冯.诺依曼体系结构与操作系统
【C/进阶】如何对文件进行读写(含二进制)操作?
【Linux】基础IO_文件操作
前言
在前文中学习了open函数,我们知道open函数的返回值就是文件描述符,本章将对文件描述符进行详细讲解。
文件描述符
文件描述符是什么?
在前文一开始我们已经提到了,我们是通过创建进程,然后让进程底层通过系统调用,从而让OS打开文件。而一个进程是可以打开多个文件。内存中一定是存在多个被打开的文件的,那么如何知道哪些文件是哪个进程打开的呢?这里就谈到了文件描述符。如下:

简单来说:文件描述符就是一个进程与该进程所打开文件建立索引关系的数组(文件描述符表)下标。通过文件描述符,也就是该进程对应的的文件描述符表所对应的下标。就可以找到该进程所打开的各个文件。
我们再来看如下现象:

为什么文件描述符是从3开始的呢?
- Linux系统下进程会默认打开三个文件,即标准输入、标准输出、标准错误,分别对应文件描述符0 1 2。这也是为什么我们打开文件时,返回的文件描述符是从3开始,因为前面的0 1 2已经被占用了
- 一个文件可以在同一个进程中被打开对此,也就意味着不同的文件描述符,可能会指向同一个文件。
文件描述符分配规则
- 文件描述符的分配规则为从0开始,扫描文件描述符表中,没有被使用的数值最小的下标,作为新打开文件的文件描述符。
我们也可以通过代码来验证一下:
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#define LOG "log.txt"
int main()
{
int fd1=open(LOG,O_CREAT| O_WRONLY|O_TRUNC,0666);
int fd2=open(LOG,O_CREAT| O_WRONLY|O_TRUNC,0666);
printf("fd1:%d\n",fd1);
printf("fd2:%d\n",fd2);
close(2);
int fd3=open(LOG,O_CREAT| O_WRONLY|O_TRUNC,0666);
printf("fd3:%d\n",fd3);
return 0;
} 
文件操作实现的底层原理
在此之前,我们要知道,ANSIC 标准采用“缓冲文件系统”来处理数据文件,所谓缓冲文件系统,其实就是OS会为每一个正在使用的文件开辟一个文件缓冲区。文件缓冲区的存在会提升IO的效率。(就好比你一个一个的拿快递(无缓冲区),和你从快递点一次性拿很多快递(有缓冲区))
write原理(ssize_t write(int fd, const void *buf, size_t count);)
对于write函数来说,会通过文件描述符fd,在该进程中找到文件描述符表的下标,从而找到被打开文件的struct file,再从而找到OS给该文件开辟的文件缓冲区,然后通过参数buf,结合count,将buf的数据拷贝count大小的数据到文件缓冲区,最后OS根据自己的刷新策略,将文件缓冲区内的数据刷新到磁盘。

read原理(ssize_t read(int fd, void *buf, size_t count);)
对于read函数来说也是如此,OS通过文件描述符先将磁盘的数据拷贝到该文件对应的缓冲区,然后通过read函数的参数中的buf,将文件缓冲区的数据拷贝到buf缓冲区,再根据count来决定读取buf缓冲区的数据的大小。

因此,我们也可以将这些所谓的read与write函数看成是一种拷贝函数。
语言级别的文件操作原理
对于我们C语言中,提到的这些读写函数(fputs、fgets等),它们的底层一定是调用了系统级别的函数,从而实现对文件内容的读写,而调用read、write这种系统级别的函数,文件描述符是必不可少的存在,本质上来说,访问文件都是通过文件描述符来进行访问。
因此,我们也可以推测:在C语言级别提供的文件结构体FILE中,一定存在文件描述符!我们可以来通过简单的代码进行验证我们的猜测:

重定向的原理
重定向定义
了解文件描述符的特点后,我们知道一个进程会默认打开三个文件,那么假如我们在打开新文件之前,将1号文件描述符对应的文件(即标准输出)关闭,会发生什么现象呢?我们通过如下代码来试验一下:
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<stdlib.h>
int main()
{
//关闭1号文件描述符对应的文件,即标准输出
close(1);
pid_t fd=open("log.txt",O_WRONLY | O_CREAT |O_TRUNC);
if(fd == -1)
{
printf("open fail\n");
return -1;
}
//直接printf,看看会出现什么现象
printf("can you see me???\n");
printf("can you see me???\n");
printf("can you see me???\n");
printf("can you see me???\n");
fflush(stdout);//刷新缓冲区
//关闭
close(fd);
return 0;
}按理来说,这是一段平平无奇的代码,应该会在显示器上打印出四串文字,但是我们关闭1号文件描述符对应的文件后,会发生什么呢?运行结果如下:
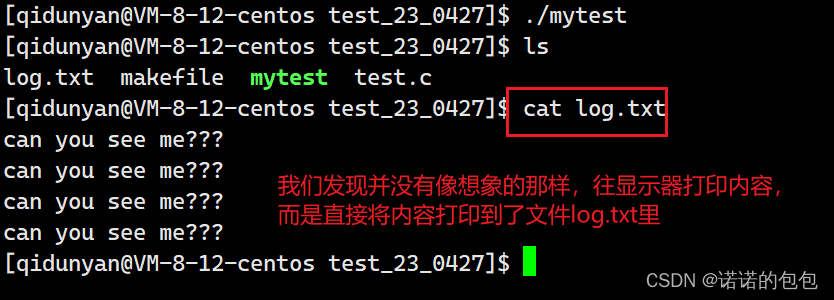
这是为什么呢?
原因在于我们关闭1号文件,也就是进程默认打开的标准输出文件,而当我们再次打开log.txt文件时,由于文件描述符分配规则,1是没有被使用的最小的下标,此时1号文件描述符对应的文件就变为了log.txt文件,而printf函数,是默认向1号文件里输出内容,所以我们在显示器看不到printf打印的信息,而在log.txt文件可以看到。

这就是重定向的原理,即:在上层无法感知的情况下,修改底层进程的文件描述符表中,特定下标的指向。
dup2函数实现重定向
上面我们这种close一个文件,再打开一个文件,以此来更改文件描述符对应的文件指向,这种方法多多少少有一些不方便,而且也挺挫的。因此有一种更好的方法,即系统提供了一个函数——dup2函数。
#include<unistd.h>
int dup2(int oldfd, int newfd);对于该函数:我们要注意的是,这里很容易被名字混淆,实际上这里最终文件描述符对应的文件都会被修改为oldfd。也就是将newfd重定向为oldfd。如果重定向失败,则返回-1。
所以假如我们要将1号文件描述符的指向的文件修改为fd对应的文件,应该这样来写:dup2(fd,1),这就是输出重定向,当然输入重定向就是:dup2(fd,0)。
dup2原理: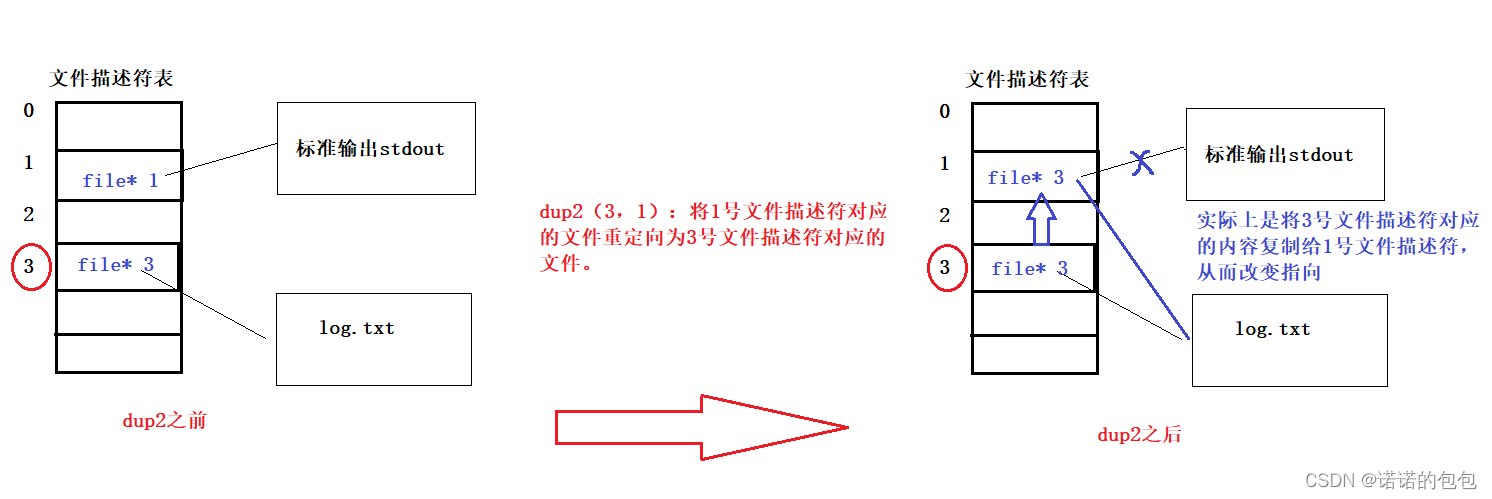
dup2函数的原理实际上就是通过拷贝的方式,修改原来文件描述符表中特定下标所指向的文件,这里需要注意一点的是,dup2函数在实现重定向时,会先将原有的文件描述符指向的对应的文件关闭,这样避免内存泄漏问题的出现。
缓冲区的理解
缓冲区是什么?
缓冲区实际上就是对数据做临时存储的一个“容器”(可以理解为临时存储快递的驿站),最主要的目的就是为了提高IO效率(一个一个拿快递,与从驿站一次性拿很多快递的区别)。
现象:
像我们的一些比如printf、fprintf函数,它们内部就存在一个缓冲区,也就是说,我们在进行printf打印时,并不是直接将数据打印出来,而是先将数据存放到缓冲区,再结合一定的刷新策略,刷新到外设。当然,我们也可以验证一下:
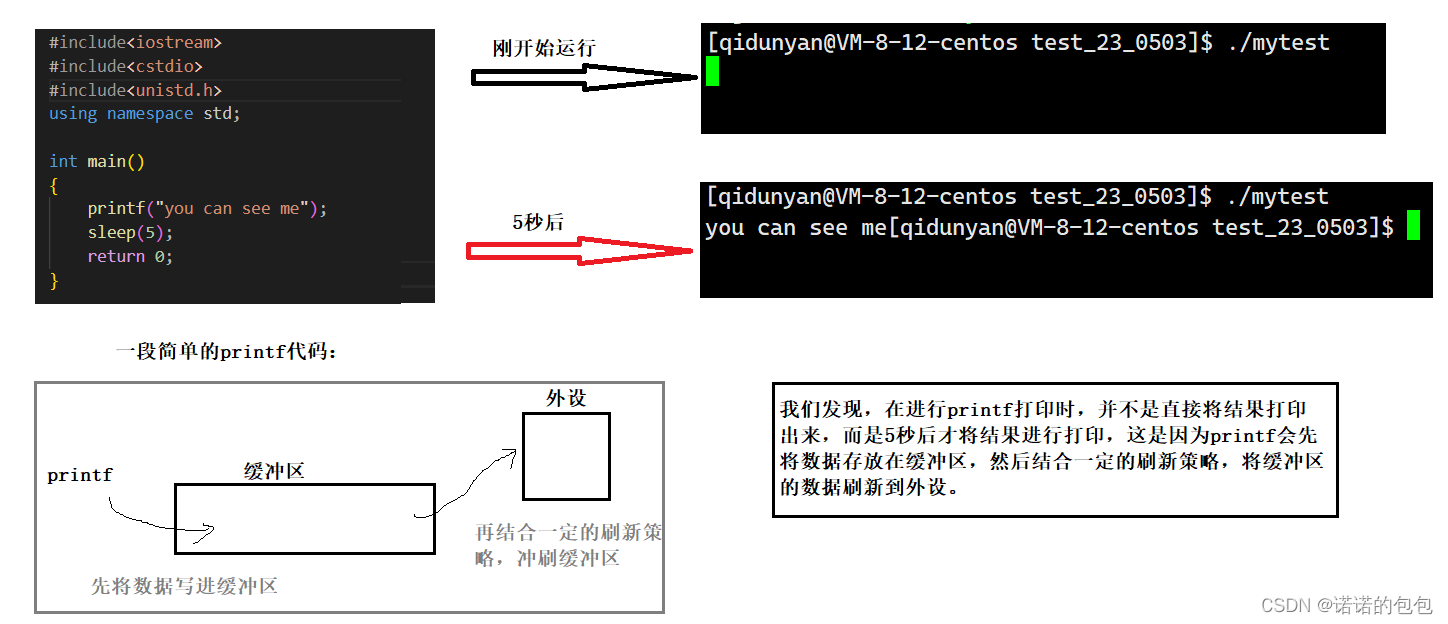
缓冲区的刷新策略
在上面提到了缓冲区的刷新策略一词,这里主要分为以下几种:
- 无缓冲 :不存在缓冲区
- 行缓冲:遇到换行符‘\n’,才将数据从缓冲区刷新(诸如printf、fprintf等)
- 全缓冲:缓冲区满时,才将数据从缓冲区刷新(诸如普通文件)
因此,对于上面printf,假如我们后面加上一个\n,就会立刻看到运行结果,而不是5秒后才看到。
用户/内核 级缓冲区
我们上面所说的缓冲区都是属于用户级缓冲区,实际上OS为了提升整体性能,也会存在内核级缓冲区(这里不过多讨论),而我们用户级的缓冲区在哪里呢?实际上是由C语言标准库提供,在我们进行fopen打开文件时,缓冲区在FILE结构体内。

其它
了解缓冲区后,我们来看这么一段有意思的代码:
#include<iostream>
#include<cstdio>
#include<unistd.h>
#include<cstring>
using namespace std;
int main()
{
fprintf(stdout,"%s","hello fprintf\n");
const char* str="hello write\n";
write(1,str,strlen(str));
fork();
return 0;
}直接运行:

重定向到普通文件:

我们发现,为什么重定向后,会显示三个打印结果。重定向之前只有两个?
这是因为:
- 首先在重定向之前,我们是向显示器(stdout对应的外设)打印内容,而显示器的刷新策略为行刷新,所以fprintf缓冲区内的内容会被立刻冲刷到显示器,而write这种系统调用函数不存在缓冲区的概念。所以write函数也直接打印在显示器。
- 而在fork之后,创建子进程,但是此时fprintf对应的缓冲区的内容已经被冲刷掉了,所以重定向之前只有两个打印结果
- 而在重定向后,是向普通文件打印内容,而普通文件的刷新策略为全缓冲,只有缓冲区满了,才会冲刷数据。所以在fork之前,fprintf缓冲区的内容不会被冲刷掉,而fork创建子进程后,该缓冲区的数据依然还在(也就是说,父子进程各自的fprintf缓冲区都存在数据),所以此时return时,程序运行结束,冲刷缓冲区就会出现两个hello fprintf,和一个hello write!

当然,假如我们将fprintf的\n去除后,由于显示器的刷新策略,所以不会冲刷缓冲区,被子进程继承后,程序运行结束对缓冲区进行刷新,也会看到三条打印信息:
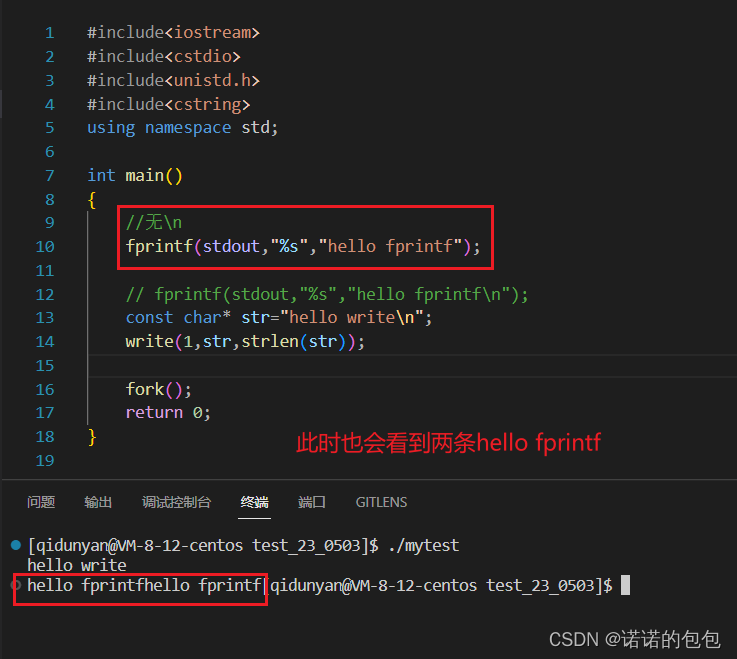
end.
生活原本沉闷,但跑起来就会有风!🌹






![[stable-diffusion-art] 指北-2 如何为sd提出好的prompt](https://img-blog.csdnimg.cn/4e58f54a484b4e0d891c711cf8ef76c9.png)