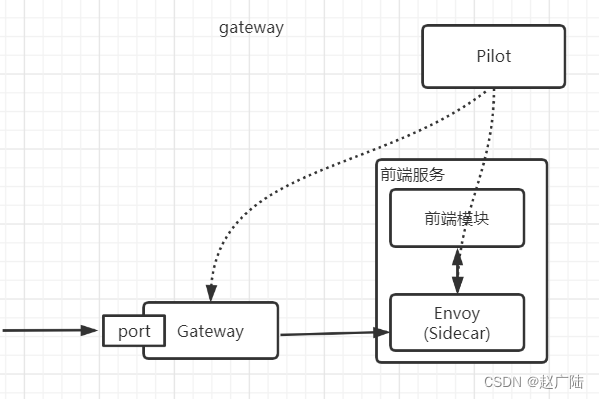
DataFrame是二维数据结构,数据以行和列的形式排列
构建DataFrame最基本的定义格式如下
df = pd.DataFrame(data=None, index=None, columns=None)参数说明
data: 具体数据
index: 行索引,如果没有指定,会自动生成RangeIndex(0,1,2,...,n)
columns: 列索引(表头),如果没有指定,会自动生成RangeIndex(0,1,2,...,n)
我们可以直接使用pd.DataFrame()创建一个空的DataFrame数据框
import pandas as pd
df = pd.DataFrame()
'''
Empty DataFrame
Columns: []
Index: []
'''
print(df)以下给出常用的构建DataFrame数据框的方法
方法1: 使用字典dict构建DataFrame数据框
字典中的键为列名,值一般为一个列表、元组或ndarray数组对象,是具体的数据
import pandas as pd
import numpy as np
data = {'a':[1, 2, 3, 4], # 列表
'b':(4, 5, 6, 7), # 元组
'c':np.array([8, 9, 10, 11]) # ndarry数组
}
# 创建Dataframe
df1 = pd.DataFrame(data) df1
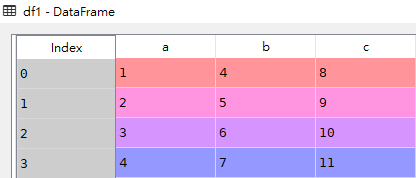
可以看到,一个新的DataFrame数据框已经创建成功了,系统默认为我们生成了行索引,而列索引就是字典dict里的key,我们也可以在创建Dataframe时手动指定行索引,只需修改参数index即可
import pandas as pd
import numpy as np
data = {'a':[1, 2, 3, 4], # 列表
'b':(4, 5, 6, 7), # 元组
'c':np.array([8, 9, 10, 11]) # ndarry数组
}
# 创建Dataframe
df1 = pd.DataFrame(data,index=['one','two','three','four']) df1
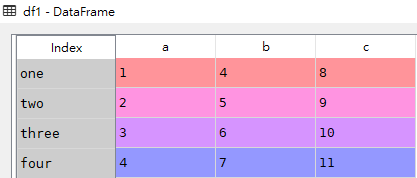
我们也可以使用Series组成的字典构建DataFrame数据框
字典里的一个键值对为一列数据,键为列名,值是一个Series
import pandas as pd
data = {"x": pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']),
"y": pd.Series([5, 6, 7, 8], index=['a', 'b', 'c', 'd'])}
# 创建DataFrame
df2 = pd.DataFrame(data)df2

方法2: 使用列表构建Dataframe数据框
我们可以使用字典组成的列表构建DataFrame,每个字典是一行数据
import pandas as pd
# 定义一个字典列表
data = [{'x':1, 'y':2, 'z':3},
{'x':4, 'y':5, 'z':6}]
# 创建DataFrame
df3 = pd.DataFrame(data, index=['a','b'])df3

我们也可以使用二维列表创建DataFrame数据框
import pandas as pd
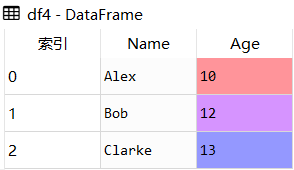
data = [['Alex',10],['Bob',12],['Clarke',13]]
df4 = pd.DataFrame(data,columns=['Name','Age'])df4
提示Tips
在实际业务中一般不需要我们来生成数据,而是有已经采集好的数据集,直接加载到DataFrame即可
![[Pandas] 查看DataFrame的常用属性](https://img-blog.csdnimg.cn/32e7d7a3aaf647e4bfae63090d316be1.png)







![[架构之路-185]-《软考-系统分析师》-3-操作系统基本原理 - 文件索引表](https://img-blog.csdnimg.cn/679b63ffaad542a5bbe1b59f58eafc57.png)