windows :\r\n
linux:\n
1.shell介绍
1.1、shell是操作系统的终端命令行
(1)shell可以理解为软件系统提供给用户操作的命令行界面,可以说它是人机交互的一种方式。
(2)我们可以使用shell和操作系统、uboot等软件系统进行交互。具体来说就是我们通过shell给软件系统输入命令然后回车执行,执行完成后又会回到shell命令行可以再次输入命令执行。
(3)上述的操作方式一般情况下工作很好,但是有缺陷。譬如我们要在linux下创建一个文件a.c,可以touch a.c 但是如果我现在是用在linux下创建100个文件,分别为a1.c a2.c.....a100.c 如果这时候还是手工去命令行下执行命令创建也可以,但是很累。最好的做法就是把创建过程写成一个shell脚本程序,然后去执行这个shell脚本程序,执行这个程序的效果和手工在命令行输入那些命令效果一样的。(回忆在arm裸机中安装交叉编译工具链时,创建arm-linux-xxx的符号链接时)
1.2、shell是一类编程语言
(1)编写shell脚本时使用的语言就是shell语言,又叫脚本语言。
(2)shell脚本其实是一类语言而不是一个语言。
1.3、常用shell语言:sh、bash、csh、ksh、perl、python等
(1)在linux下常用的脚本语言其实就是bash、sh;
(2)perl、python这样的高级shell脚本语言,常用在网络管理配置等领域,系统运维人员一般要学习这些。
(3)脚本语言一般在嵌入式中应用,主要是用来做配置。(一个复杂的嵌入式程序都是可配置的,配置过程就是用脚本语言来实现的)自然不会使用过于复杂的脚本语言特性,因此只需要针对性的学习即可。
(4)linux下最常用的脚本就是bash,我们学习也是以bash为主。
1.4、shell脚本的运行机制:解释运行
(1)C语言(C++)这种编写过程是:编写出源代码(源代码是不能直接运行的)然后编译链接形成可执行二进制程序,然后才能运行;而脚本程序不同,脚本程序编写好后源代码即可直接运行(没有编译链接过程)
(2)shell程序是解释运行的,所谓解释运行就是说当我们执行一个shell程序时,shell解析器会逐行的解释shell程序代码,然后一行一行的去运行。(顺序结构)
(3)CPU实际只认识二进制代码,根本不认识源代码。脚本程序源代码其实也不是二进制代码,CPU也不认识,也不能直接执行。只不过脚本程序的编译链接过程不是以脚本程序源代码为单位进行的,而是在脚本运行过程中逐行的解释执行时才去完成脚本程序源代码转成二进制的过程(不一定是编译链接,因为这行脚本程序可能早就编译连接好了,这里我们只是调用它)的。
2.动手写第一个shell
2.1、编辑器、编译器、运行方法(脚本的3种执行方法)
(1)shell程序是文本格式的,只要是文本编辑器都可以。但是因为我们的shell是要在linux系统下运行的,所以换行符必须是'\n',而windows下的换行符是"\r\n",因此windows中的编辑器写的shell不能在linux下运行。所以我们整个课程都是在linux下使用vi编辑器(实际上是vim)进行编写调试的。
(2)编译器 不涉及,因为shell是解释性语言,直接编辑完就可以运行。
(3)shell程序运行的运行有多种方法,这里介绍三种方法:
第一种:./xx.sh,和运行二进制可执行程序方法一样。这样运行shell要求shell程序必须具有可执行权限。chmod a+x xx.sh来添加可执行权限。
第二种:source xx.sh,source是linux的一个命令,这个命令就是用来执行脚本程序的。这样运行不需要脚本具有可执行权限。
第三种:bash xx.sh,bash是一个脚本程序解释器,本质上是一个可执行程序。这样执行相当于我们执行了bash程序,然后把xx.sh作为argv[1]传给他运行。
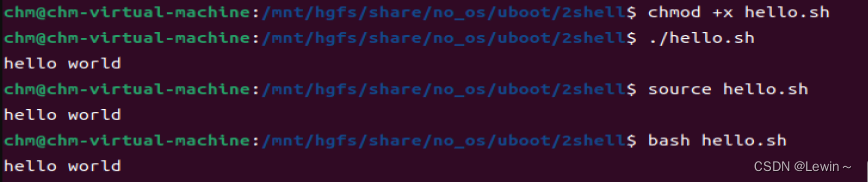
2.2、hello world程序和解释
(1)shell程序的第一行一般都是: #!/bin/sh 这行话以#!开始,后面加上一个pathname,这行话的意思就是指定shell程序执行时被哪个解释器解释执行。所以我们这里写上/bin/sh意思就是这个shell将来被当前机器中/bin目录下的sh可执行程序执行。
可以将第一行写为:#!/bin/bash来指定使用bash执行该脚本。
注意:在ubuntu上面默认使用的解释器sh其实不是bash,而是dash。dash是ubuntu中默认使用的脚本解释器。

(2)脚本中的注释使用#,#开头的行是注释行。如果有多行需要注释,每行前面都要加#。(#就相当于是C语言中的//)
(3)shell程序的正文,由很多行shell语句构成。
2.3、shell并不神秘
(1)shell就是把以前命令行中键入执行的命令写成了程序。shell其实就是为了避免反复的在命令行下手工输入而发明的一种把手工输入步骤记录下来,然后通过执行shell脚本程序就能再次复述原来记录的手工输入过程的一种技术。
(2)shell编辑完可以直接运行(不需编译)
3.shell编程学习1
3.1、shell中使用linux命令
(1)练习1:当前目录下创建文件a.txt
(2)练习2:当前目录下创建文件夹dir,dir下创建文件b.txt
总结:以上2个练习的目的是让大家基本学会写脚本,明白脚本编程其实就是把以前在命令行下输入的命令挪到脚本程序中去然后一次执行。
3.2、shell中的变量定义和引用
(1)变量定义和初始化。shell是弱类型语言(语言中的变量如果有明确的类型则属于强类型语言;变量没有明确类型就是弱类型语言),和C语言不同。在shell编程中定义变量不需要制定类型,也没有类型这个概念。
(2)变量定义时可以初始化,使用=进行初始化赋值。在shell中赋值的=两边是不能有空格的。
注意:shell对语法非常在意,非常严格。很多地方空格都是必须没有或者必须有,而且不能随意有没有空格。
(3)变量赋值,变量定义后可以再次赋值,新的赋值会覆盖老的赋值。shell中并不刻意区分变量的定义和赋值,反正每个变量就是一个符号,这个符号的值就是最后一个给他赋值时的值。
(4)变量引用。shell中引用一个变量必须使用$符号,$符号就是变量解引用符号。
注意:$符号后面跟一个字符串,这个字符串就会被当作变量去解析。如果这个字符串本身没有定义,执行时并不会报错,而是把这个变量解析为空。也就是说在shell中没有被定义的变量其实就相当于是一个定义并赋值为空的变量。
注意:变量引用的时候可以$var,也可以${var}。这两种的区别是在某些情况下只能用${var}而不能简单的$var
#!/bin/sh
# commnt
var="hello"
echo "$varworld"
#echo "$(var)world"输出结果:

#!/bin/sh
# commnt
var="hello"
#echo "$varworld"
echo "$(var)world"输出结果:

#!/bin/sh
# commnt
#touch a.c
#mkdir dir
#cd dir
#touch b.c
#cd ..
string="helloworld"
string="new"
echo $string
echo string
echo $str输出结果:

3.3、shell中无引号、单引号和双引号的区别
(1)shell中使用字符串可以不加双引号,直接使用。而且有空格时也可以。不加双引号和加双引号是一样的,但是两者都不能识别输出",要想输出",必须将"当作一个转义字符对待,即在"前面加上\。
(2)shell中也可以使用单引号来表示字符串,也是直接使用的,不能识别输出转义字符。
(3)单引号中:完全字面替换(不可包含单引号本身)
(4)双引号中:
$加变量名可以取变量的值
反引号仍表示命令替换
$表示$的字面值 输出$符号
`表示`的字面值
"表示"的字面值
\表示\的字面值
除以上情况之外,在其它字符前面的\无特殊含义,只表示字面值。
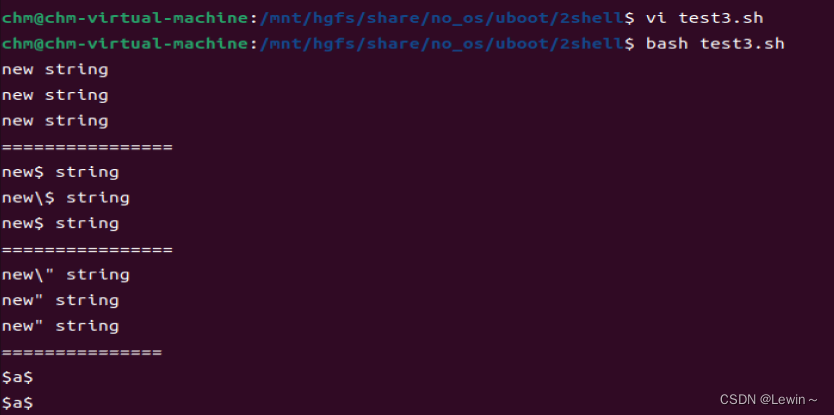
#!/bin/sh
# commnt
echo "new string"
echo 'new string'
echo new string
echo "================"
echo "new\$ string"
echo 'new\$ string'
echo new\$ string
echo "================"
#echo 'new" string'
#echo new" string
#echo "new" string"
echo 'new\" string'
echo new\" string
echo "new\" string"
echo "==============="
var=\$a\$
echo $var
var="\$a\$"
echo $var
输出结果:
4.shell编程学习2
4.1、shell中调用linux命令
(1)直接执行
(2)反引号括起来执行。有时候我们在shell中调用linux命令是为了得到这个命令的返回值(结果值),这时候就适合用一对反引号(键盘上ESC按键下面的那个按键,和~在一个按键上)来调用执行命令。
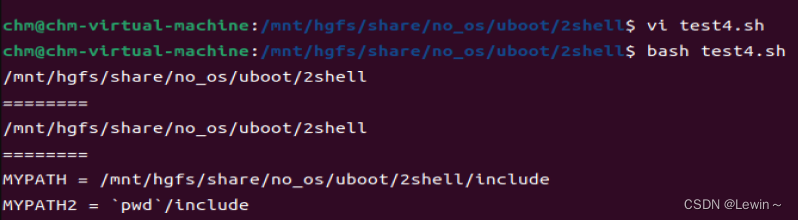
#!/bin/sh
# commnt
pwd
echo "========"
PWD=`pwd`
echo $PWD
echo "========"
MYPATH="`pwd`/include"
MYPATH2='`pwd`/include'
echo "MYPATH = $MYPATH"
echo "MYPATH2 = $MYPATH2"输出结果:
4.2、shell中的选择分支结构
(1)shell的if语言用法很多,在此只介绍常用的,其他感兴趣可以自己去学
(2)典型if语言格式
if [表达式]; then
xxx
yyy
zzz
else
xxx
ddd
uuu
fi
(3)if的典型应用
判断文件是否存在。(-f),注意[]里面前后都有空格,不能省略。
#!/bin/sh
# commnt
if [ -f a.txt ]; then
echo "yes"
else
echo "no"
touch a.txt
fi输出结果:

判断目录是否存在 (-d)
判断字符串是否相等("str1" = "str2"),注意用一个等号而不是两个
#!/bin/sh
# commnt
if [ "abc" = "abc" ]; then
echo "euqal"
else
echo "no euqal"
fi
输出结果:

判断数字是否相等(-eq)、大于(-gt)、小于(-lt)、大于等于(-ge)、小于等于(-le) 回忆一下在ARM裸机中讲述ARM汇编条件执行时,曾经用过这些条件判断的缩写。(eq就是equal,gt就是greater than,lt就是less than,ge就是greater or equal,le就是less or equal)
#!/bin/sh
# commnt
if [ 12 -eq 0 ]; then
echo "euqal"
else
echo "no euqal"
fi
输出结果:

判断字符串是否为空(-z)
#!/bin/sh
# commnt
if [ -z $str ]; then
echo "euqal"
else
echo "no euqal"
fi输出结果:

(4)if判断式中使用“-o”表示逻辑或
相当于C语言中在if后面的条件式中用逻辑与、逻辑或来连接2个式子,最终的if中是否成立取决于2个式子的逻辑运算结果。
#!/bin/sh
# commnt
if [ "abc" = "cba" -o 12 -eq 12 ]; then
echo "euqal"
else
echo "no euqal"
fi输出结果:

(5)逻辑与&&和逻辑或||与简写的if表达式相结合
#!/bin/sh
# commnt
str="ddd"
[ -z $str ] || echo "fei kong"
[ -z $str ] && echo "kong"输出结果:

5.shell中的循环结构
5.1、for循环
(1)要求:能看懂、能改即可。不要求能够完全不参考写出来。因为毕竟嵌入式并不需要完全重新手写shell,系统管理员(服务器运维人员,应用层系统级管理开发的才需要完全掌握shell)
#!/bin/sh
# commnt
for i in 1 2 3 4 5
do
echo $i
done
for i in `ls`
do
echo $i
done
输出:

5.2、while循环
(1)和C语言的循环在逻辑上无差别
(2)要注意很多格式要求,譬如:while后面的[]两边都有空格,[]后面有分号分号(如果do放在一行的话),i++的写法中有两层括号。
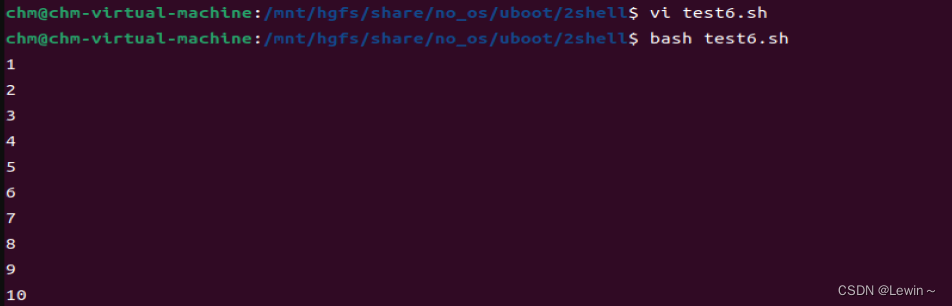
#!/bin/sh
# commnt
i=1
j=11
while [ $i -lt $j ]
do
echo $i
i=$(($i+1))
done输出结果:
5.3、echo的创建和追加输入文件
(1)在shell中可以直接使用echo指令新建一个文件,并且将一些内容传入这个文件中。创建文件并输入内容的关键就是>。
(2)还可以使用echo指令配合追加符号>> 向一个已经存在的文件末尾追加输入内容。
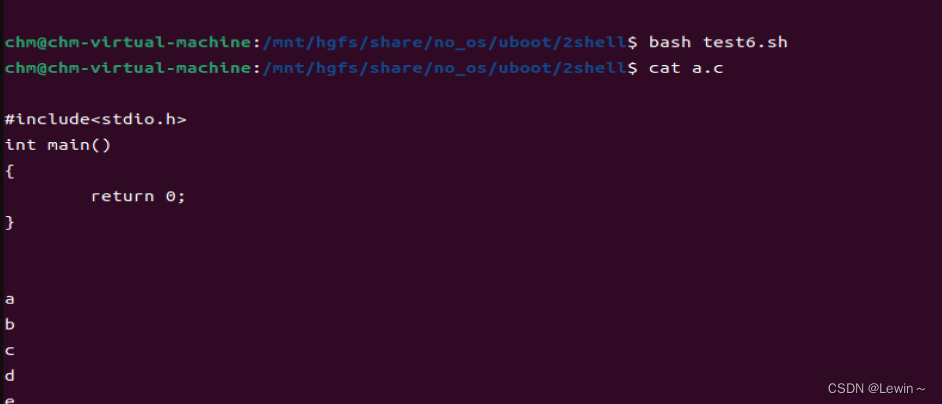
#!/bin/sh
# commnt
echo "
#include<stdio.h>
int main()
{
return 0;
}
" > a.c输出结果:

#!/bin/sh
# commnt
echo "
#include<stdio.h>
int main()
{
return 0;
}
" > a.c
echo "
a
b
c
d
e
" >> a.c
输出结果:
6.shell中其他值得关注的知识点
6.1、case语句
(1)shell中的case语句和C语言中的switch case语句作用一样,格式有差异
(2)shell中的case语句天生没有break,也不需要break,和C语言中的switch case不同。shell中的case默认就是匹配上哪个执行哪个,不会说执行完了还去执行后面的其他case(就好像shell中的case语言默认都带了break)。
#!/bin/sh
# commnt
var=2
case $var in
1) echo "1" ;;
2) echo "2" ;;
esac
输出结果:

6.2、调用shell程序的传参
(1)C语言中可以通过main函数的argc和argv给程序传参(详情参考《4.8.3.argc、argv与main函数的传参》)
(2)shell程序本身也可以在调用时传参给他。在shell程序内部使用传参也是使用的一些特定符号来表示的,包括:
$#表示调用该shell时传参的个数。($#计数时只考虑真正的参数个数)
$0、$1、$2·····则依次表示传参的各个参数。
C语言:./a.out aa bb cc argc = 4, argv[0] = ./a.out, argv[1]是第一个有效参数····
shell:source a.sh aa bb cc $# = 3, $0是执行这个shell程序的解析程序的名字,$1是第一个有效参数的值,$2是第2个有效参数的值·····
#!/bin/sh
# commnt
echo $# $0 $1 $2 $3输出结果:

注意:shell中的很多语法特性和C语言中是相同的,也有很多是不同的。所以大家学的越多越容易混淆(本质原因还是用的不熟悉,用的少),解决方案是:做笔记、作总结、多写代码经常用
6.3、while循环和case语言和传参结合
(1)shell中的break关键字和C语言中意义相同(都是跳出)但是用法不同。因为shell中case语句默认不用break的,因此在shell中break只用于循环跳出。所以当while中内嵌case语句时,case中的break是跳出外层的while循环的,不是用来跳出case语句的。
(2)shell中的$# $1等内置变量的值不是不可变的,而是可以被改变,被shift指令改变。shift指令有点像左移运算符,把我们给shell程序的传参左移了一个移出去了,原来的$2变成了新的$1,原来的$#少了1个。
#!/bin/sh
# commnt
echo $# $1
shift;
echo $# $1输出结果:

7.Makefile基础回顾
7.1、Makefile的作用和意义
(1)工程项目中c文件太多管理不方便,因此用Makefile来做项目管理,方便编译链接过程。
(2)uboot和linux kernel本质上都是C语言的项目,都由很多个文件组成,因此都需要通过Makefile来管理。所以要分析uboot必须对Makefile有所了解。
7.2、目标、依赖、命令
(1)目标就是我们要去make xxx的那个xxx,就是我们最终要生成的东西。
(2)依赖是用来生成目录的原材料
(3)命令就是加工方法,所以make xxx的过程其实就是使用命令将依赖加工成目标的过程。
7.3、通配符%和Makefile自动推导(规则)
(1)%是Makefile中的通配符,代表一个或几个字母。也就是说%.o就代表所有以.o为结尾的文件。
(2)所谓自动推导其实就是Makefile的规则。当Makefile需要某一个目标时,他会把这个目标去套规则说明,一旦套上了某个规则说明,则Makefile会试图寻找这个规则中的依赖,如果能找到则会执行这个规则用依赖生成目标。
7.4、Makefile中定义和使用变量
(1)Makefile中定义和使用变量,和shell脚本中非常相似。相似是说:都没有变量类型,直接定义使用,引用变量时用$var
7.5、伪目标(.PHONY)
(1)伪目标意思是这个目标本身不代表一个文件,执行这个目标不是为了得到某个文件或东西,而是单纯为了执行这个目标下面的命令。
(2)伪目标一般都没有依赖,因为执行伪目标就是为了执行目标下面的命令。既然一定要执行命令了那就不必加依赖,因为不加依赖意思就是无条件执行。
(3)伪目标可以直接写,不影响使用;但是有时候为了明确声明这个目标是伪目标会在伪目标的前面用.PHONY来明确声明它是伪目标。
7.6、Makefile的文件名
(1)Makefile的文件名合法的一般有2个:Makefile或者makefile
7.7、Makfile中引用其他Makefile(include指令)
(1)有时候Makefile总体比较复杂,因此分成好几个Makefile来写。然后在主Makefile中引用其他的,用include指令来引用。引用的效果也是原地展开,和C语言中的头文件包含非常相似。
8.Mafile补充学习1
8.1、Makefile中的注释用#
(1)Makefile中注释使用#,和shell一样。
8.2、命令前面的@用来静默执行
(1)在makefile的命令行中前面的@表示静默执行。
(2)Makefile中默认情况下在执行一行命令前会先把这行命令给打印出来,然后再执行这行命令。
all:
echo "helloworld"
(3)如果你不想看到命令本身,只想看到命令执行就静默执行即可。
all:
@echo "helloworld"
8.3、Makefile中几种变量赋值运算符
(1)= 最简单的赋值
(2):= 一般也是赋值
以上这两个大部分情况下效果是一样的,但是有时候不一样。
用=赋值的变量,在被解析时他的值取决于最后一次赋值时的值,所以你看变量引用的值时不能只往前面看,还要往后面看。
A="abc"
B=$(A)def
A=gh
all:
echo $(B)
用:=来赋值的,则是就地直接解析,只用往前看即可。
A="abc"
B:=$(A)def
A=gh
all:
echo $(B)
(3)?= 如果变量前面并没有赋值过则执行这条赋值,如果前面已经赋值过了则本行被忽略。(实验可以看出:所谓的没有赋值过其实就是这个变量没有被定义过)
var=
var ?= "efgh"
all:
echo $(var)
(4)+= 用来给一个已经赋值的变量接续赋值,意思就是把这次的值加到原来的值的后面,有点类似于strcat。(在shell makefile等文件中,可以认为所有变量都是字符串,+=就相当于给字符串stcat接续内容)(注意一个细节,+=续接的内容和原来的内容之间会自动加一个空格隔开)
注意:Makefile中并不要求赋值运算符两边一定要有空格或者无空格,这一点比shell的格式要求要松一些。
8.4、Makefile的环境变量
(1)makefile中用export导出的就是环境变量。一般情况下要求环境变量名用大写,普通变量名用小写。
(2)环境变量和普通变量不同,可以这样理解:环境变量类似于整个工程中所有Makefile之间可以共享的全局变量,而普通变量只是当前本Makefile中使用的局部变量。所以要注意:定义了一个环境变量会影响到工程中别的Makefile文件,因此要小心。
(3)Makefile中可能有一些环境变量可能是makefile本身自己定义的内部的环境变量或者是当前的执行环境提供的环境变量(譬如我们在make执行时给makefile传参。make CC=arm-linux-gcc,其实就是给当前Makefile传了一个环境变量CC,值是arm-linux-gcc。我们在make时给makefile传的环境变量值优先级最高的,可以覆盖makefile中的赋值)。这就好像C语言中编译器预定义的宏__LINE__ __FUNCTION__等一样。
CC=gcc
all:
echo $(CC)
9.Makefile补充学习2
9.1、Makefile中使用通配符
(1)* 若干个任意字符
(2)? 1个任意字符
(3)[] 将[]中的字符依次去和外面的结合匹配
还有个%,也是通配符,表示任意多个字符,和*很相似,但是%一般只用于规则描述中,又叫做规则通配符。
关于通配符,Makefile还有一些wildcard等比较复杂的通配符用法,具体参考《跟我一起学Makefile》即可。
all:1.c 2.c 12.c test.c 1.h
echo %.c
echo *.c
echo ?.c
echo [12].c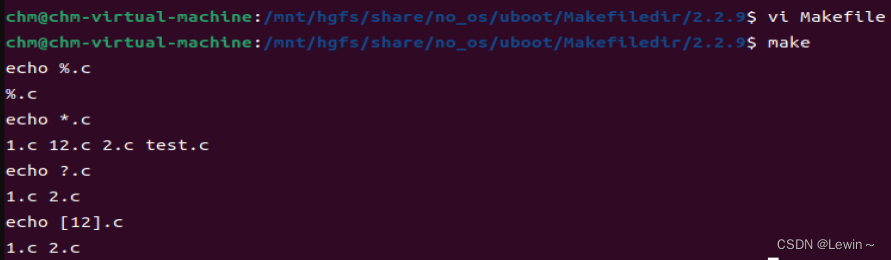
9.2、Makefile的自动变量
(1)为什么使用自动变量。在有些情况下文件集合中文件非常多,描述的时候很麻烦,所以我们Makefile就用一些特殊的符号来替代符合某种条件的文件集,这就形成了自动变量。
(2)自动变量的含义:预定义的特殊意义的符号。就类似于C语言编译器中预制的那些宏__FILE__一样。
(3)常见自动变量:
$@ 规则的目标文件名
$< 规则的依赖文件名
$^ 依赖的文件集合
all:1.c 2.c 12.c test.c 1.h
echo $@
echo $<
echo $^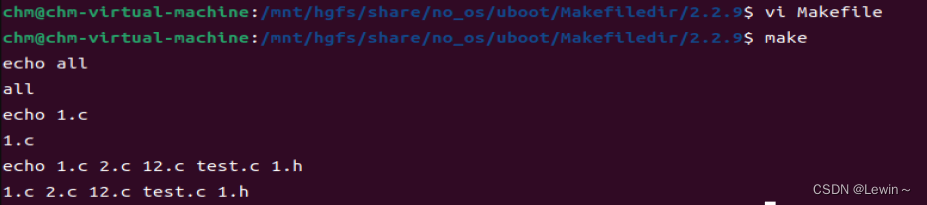
![[Cursor Tool] 面向编程的ChatGPT工具的入门使用指南](https://img-blog.csdnimg.cn/2db80f23be2f4256ade73a53ebcf421a.png)






![[MAY DAY]五一综合训练 之——最值问题](https://img-blog.csdnimg.cn/59101246caee4c89a725f13533dee73d.png#pic_center)