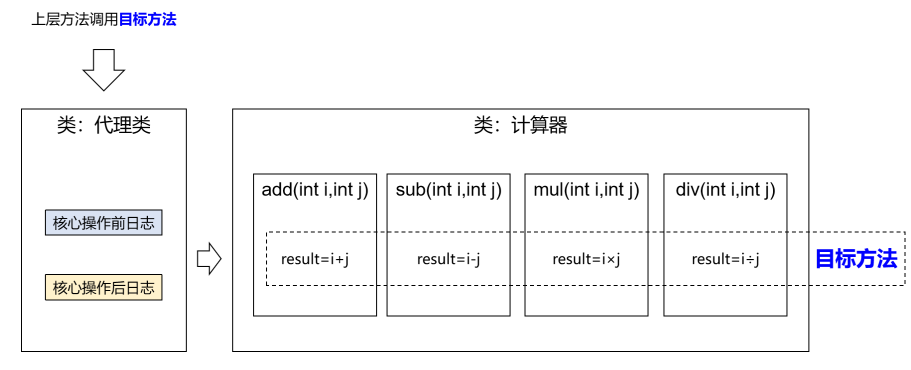
文章目录
- 云计算
- 云计算的定义
- 第1关:云计算定义
- 第2关:云计算的基本原理
- 云计算出现的背景
- 第1关:云计算出现的背景
- 第2关:云计算的特征
- 第3关:云计算的优势与劣势
- 虚拟化的类型
- 第1关:虚拟化的定义
- 第2关:虚拟化的类型
- 虚拟机的实现技术
- 第1关:计算虚拟化
- 第2关:存储虚拟化
- 第3关:网络虚拟化
- 仓库
- 第1关:Docker 仓库
- 第2关:Docker 公共仓库
- 第3关:Docker 私有仓库
- 数据科学导论——数据科学认知
- 第1关:数据初体验
- 第2关:一切都可数据化
- 第3关:拥抱数据红利
- 第4关:揭秘“数据范式”
- 第5关:何为“数据科学”
- 第6关:数据科学方法论
- 数据科学导论——数据采集基本概念
- 第1关:巧妇难为无米之炊
- 第2关:数据采集概念1、
- 软件即服务( `SaaS` )
- 第1关:`SaaS`的定义
- 第2关:`SaaS` 的优劣势
- 基础设施即服务( `IaaS` )
- 第1关:`IaaS` 的定义
- 第2关:`IaaS` 的主要功能
- 平台即服务( `PaaS` )
- 第2关:`PaaS` 的优劣势
- 私有云
- 第1关:私有云的概念和优势
- 第2关:私有云的平台
- 公有云
- 第1关:公有云简介
- 第2关:公有云的现状与未来
- **混合云**
- 第1关:混合云简介
- 第2关:混合云的应用场景和发展趋势
- 分布式文件系统
- 第1关:初识分布式文件系统
- 第2关:常见的分布式文件系统介绍
- 机器学习基本含义
- 机器学习概述
- 第1关:监督学习与无监督学习
- 第2关:训练、验证、测试与评估
- 镜像
- 第1关:Hello Docker !
- 第2关:拉取镜像
- 容器镜像的导入导出
- 第1关:导入导出容器
- 任务描述
- 相关知识
- 将 "容器的文件系统"保存到 tar 包
- 从tar包导入一个镜像
- 实例
- docker export 和 docker save的区别
- 任务要求
- 测评说明
- `openstack`环境体验
- Docker安装与描述
- 第2关:创建和应用docker命令操作容器
- `Hadoop`环境搭建与使用
- 第3关:安装Java
- 第4关:安装 `Hadoop`-单机配置
- 第5关:安装`Hadoop`-伪分布式配置
- Storm搭建与使用
- 第1关:Storm在Linux环境配置
- 第2关:Spark Shell的应用
- Spark环境搭建与使用
- 第1关:安装Spark
- 第2关: Shell的应用
- 第3关:通过 `Spark API` 编写一个独立应用程序
- 第4关:使用Maven对Java独立应用程序进行编译打包
- 第5关:使用Maven对Scala独立应用程序进行编译打包
- 认识 `OpenStack`
- 第1关:`OpenStack` 的应用前景
- `OpenStack` 的组件
- 环境准备
- 第1关:环境准备
- Docker基础实战教程一:入门
- 第1关:Hello Docker !
- 第2关:拉取镜像
- 第3关:启动一个容器
- 第4关:停止一个容器
- 第5关:进入一个容器
- 第6关:删除容器
- Docker基础实战教程二:镜像管理
- 第1关:基于Commit定制镜像
- 第2关:基于save保存镜像与基于load加载镜像
- 第3关:导入导出容器
- 第4关:删除镜像
- 第5关:构建私有Registry
- Docker基础实战教程三:`Dockerfile`
- 第1关:初识 `Dockerfile`
- 第2关:docker build、COPY和ADD
- 第3关:`CMD` 和 `ENTRYPOINT` 指令
- 第4关:`ENV、EXPOSE、WORKDIR、ARG` 指令
- 第5关:`ONBUILD` 和 `VOLUME` 指令
- 第6关:镜像构建时的缓存机制
- Docker基础实战教程四:数据卷操作
- 第1关:创建一个数据卷
- 第2关:挂载和共享数据卷
- 第3关:查看数据卷的信息
- 第4关:删除数据卷
- 第5关:备份、恢复数据卷
- MPI编程
- 第1关:`MPI`安装及配置
- 第2关:使用 `MPI` 运行"Hello World"
- 第3关:使用 `MPI` 运行"Hello World"
- 第4关:乒乓程序
- 第5关:环程序
- 第6关:求π值
- `Numpy`科学计算
- 第1关:数组创建
- 第2关:切片索引
- 第3关:基本运算
- 第4关:ufunc
- 第5关:文件读写
- 第6关:数组切片与索引
- 第7关:数组堆叠
- 数据结构课程设计Python版--植物百科数据的管理与分析
- 科比投篮选择——数据采集
- 第1关:数据采集
- 科比投篮预测——可视化与探索性数据分析(一)
- 第2关:射击距离
- 第3关:射击区范围
- 第4关:射击区
- 第5关:具体投篮区域
- 第6关:投篮准确度
- 科比投篮预测——数据处理与分析
- 第1关:数据清洗
- 第2关:数据预处理
- 第3关:构造模型并调参
- 第4关:参数验证
- 第5关:预测结果
- Pandas基本操作
- 第1关:数据结构
- 第2关:切片索引
- 第3关:增删改查
- 第4关:文件读写
- 第5关:算术运算
- 第6关:描述性统计
- 第7关:时间序列处理
- 第8关:Series
- 第9关:DataFrame
- 第10关:读取数据
- 第11关:排序
- 第12关:去重
- 正则表达式入门
- 第1关:查找第一个匹配的字符串
- 第2关:基础正则表达式--字符组
- 第3关:基础正则表达式--区间与区间取反
- 第4关:基础正则表达式--快捷方式
- 第5关:字符串的开始与结束
- 第6关:任意字符
- 第7关:可选字符
- 第8关:重复区间
- 第9关:开闭区间与速写
- Python正则表达式进阶
- 第1关:分组
- 第2关:先行断言
- 第3关:后发断言
- 第4关:标记
- 第5关:编译
- python正则表达式综合练习
- 第1关:提取日志内容
- 第2关:组合密码匹配
- 第3关:网页内容解析
- 爬虫实战——国防科技大学本科招生信息网爬取
- 第1关:利用URL获取超文本文件并保存至本
- 泰坦尼克生还预测——可视化与探索性数据分析
- 第1关:存活率与性别和船舱等级之间的关
- 第2关:各个口岸的生还率
- 第3关:统计各登船口岸的登船人数以及生还
- 泰坦尼克号生还预测
- 第1关:数据探索
- 第2关:填充缺失值
- 第3关:特征工程与生还预测
云计算
云计算的定义
第1关:云计算定义
- 云计算首次正式出现在商业领域是在哪一年?
- D. 2006
- 下面哪些属于云计算的特征?
-
A. 广泛的网路接入
-
B. 可测量的服务
-
C. 弹性服务
-
D. 资源池化
第2关:云计算的基本原理
- 分布式计算是将一个任务细分为多个任务,每个任务由一台或多台计算机来完成
- 正确
- 下列关于分布式计算说法正确的有()
-
提升系统的容错能力
-
为每一站点的硬件投入小于中间站点的投入
-
一个站点不能运行时可以转移到其他站点
- 分布式计算的优点有哪些
-
A. 高可用性
-
B. 计算速度快
-
C. 提升系统的容错能力
- 云计算的基本原理是,通过使计算分布在大量的分布式计算机上,而非本地计算机或远程服务器中,企业数据中心的运行将更与互联网相似。
- A. 正确
云计算出现的背景
第1关:云计算出现的背景
- 互联网就是一个超大云。(判断正)
- 正确
- 在云计算诞生之前,( )是一个摆在科学家面前的命题。
- 高效快速解决无限增长的信息的存储和计算问题
- 云计算对企业而言的意义包含有以下哪些方面?(多选)
-
A. 降低了维护成本
-
B. 可以获得更好的存储能力
-
C. 能更加高效地解决信息存储和计算问题
-
D. 能够提高系统的性能
- 简单的来说,云计算等于资源的闲置而产生的。(判断正误)
- A. 正确
第2关:云计算的特征
- 下列哪个特性不是云计算的主要特征( )
- 实现的技术简单
- 云计算可以把普通的服务器或者 PC 连接起来以获得超级计算机的计算与存储等功能,但成本更低(判断正误)。
- A. 正确
- 下列关于云计算的说法错误的是?
- D. 个体自治
- 与网络计算相比,不属于云计算特征的是( )
- B. 适合紧耦合科学计算
- 某用户从云服务提供商租用虚拟机进行日常使用,外出旅游时把虚拟机归还给云服务提供商,这体现了云计算的哪个关键特征?
- 按使用付费
第3关:云计算的优势与劣势
- 不属于云计算缺点的选项是( )
- 不能提供可靠、安全的数据存储
- 云计算的优势体现在以下哪几个方面。(多选)
- 设备数量
- 设备成本
- 管理成本
- 运维成本
虚拟化的类型
第1关:虚拟化的定义
- 虚拟化技术主要是对什么东西进行虚拟化?
- B. 硬件
- 虚拟化就是网络化,网络化就是虚拟化。
- B. 错
- 虚拟化技术能够实现以下哪些设备的虚拟化?
- A. CPU
- B. 内存
- C. 存储
- D. 网络
第2关:虚拟化的类型
- 按照实现方法分类,分为:
- A. 仿真
- B. 完全虚拟化
- C. 类虚拟化
- 完全虚拟化分为哪两种?
- A. 软件实现虚拟化
- C. 硬件辅助完全虚拟化
- 在半虚拟化中的客户机操作系统知道自己是处于虚拟化环境中,并且还会主动适应虚拟化环境。
- 对
- 在半虚拟化中的客户机操作系统知道自己是处于虚拟化环境中,并且还会主动适应虚拟化环境。
- A. 对
虚拟机的实现技术
第1关:计算虚拟化
- 计算虚拟化是将物理机的硬件资源进行虚拟化形成的资源池。
- B. 错
- 不属于计算虚拟化的技术有()
- C. 存储虚拟化
- 不属于计算虚拟化的技术有()
- C. 存储虚拟化
第2关:存储虚拟化
- 存储虚拟化虚拟的对象是()
- B. 存储系统
- C. 磁盘
- 下列不属于存储虚拟化的是
- C. 操作系统虚拟化
- 使用存储虚拟化可以解决下列哪些问题?
- A. 用户数据管理麻烦
- B. 数据迁移难
第3关:网络虚拟化
- 堆叠交换机属于网络虚拟化
- A. 对
- 某些情况下堆叠交换机可以消除设备间的环路
- A. 对
- 网络虚拟化之后不同租户之间再也不能相互访问。
- B. 错
- 网络虚拟化可以做到哪些事
- A. 将多个网路交换机虚拟化成一个逻辑交换机
- B. 将一个物理交换机虚拟多个逻辑交换机
- C. 使整个网络只存在一台逻辑交换机
仓库
第1关:Docker 仓库
- 下列选项中符合 docker 仓库概念的是()
- B. Docker 仓库中如果未给出镜像的标签的话,仓库会默认为镜像打上latest的标签。
- 用户准备在 Docker 仓库中存放
centos 6.5版本的镜像,现需要为centos 6.5镜像打上标签,下列选项正确的是()
- D.
centos:6.5
- 我们可以通过 <仓库名>:<标签> 的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签。
- A. 正确
第2关:Docker 公共仓库
- 关于 Docker 公共仓库的使用正确的是()
- B. 可以使用 docker search 命令在 Docker Hub 中查找镜像。
- C. 可以使用 docker push 命令上传镜像至 Docker Hub 上。
- D、可以使用 Docker pull 命令将需要的 Docker Hub 官方镜像下载至本地。
- 下列关于公共仓库的叙述错误的是()
- C. 国内没有类似于 Docker Hub 的公开服务。
- 下列哪些属于国内云服务商研发的镜像加速器()
- A. 阿里云加速器
- B.
DaoCloud加速器
第3关:Docker 私有仓库
- 下列关于私有仓库叙述正确的是()
- B.搭建私有仓库后将镜像提交至仓库,我们既能使用 Docker 来运行我们的项目镜像,也避免了商业项目暴露出去的风险。
- 下列关于私有仓库的搭建和使用正确的是()
- B.搭建完成私有仓库后可通过 docker image ls 命令查看本地镜像。
- D.我们可以通过 docker push 命令将本地镜像上传到私有仓库
数据科学导论——数据科学认知
第1关:数据初体验
- 以下行为中,哪些制造了数据
- A. 使用手机点了份外卖
- C. 注册了一个
EduCoder账号
- 在计算机内,多媒体数据最终是以什么形式存在的?
- D. 二进制代码
- 用一个字节能编出多少个不同的码?
- A. 256个
第2关:一切都可数据化
- 下列描述中,哪些是合理的:
- A、我们使用的地图
app软件数据属于方位数据化 - B、数据化不仅能将态度和情绪转变为一种可分析的形式,还可转化分析人类的关系和行为
- C、借助社交网络量化分析技术,可以对社会关系的结构和位置、角色和地位等进行建模,进而可以分析清楚人的行为、相互影响等,从而掌握社交网络结构、互动和传播规律等
- D、把一些从不被认为是数据、甚至不被认为和数据沾边的事物转化成可以用数值来量化的数据模式,就可以衍生出一系列的创新性应用,激发数据活力,创造信息独特的价值
- 下列属于数据化带来的消极影响的是:
- B.人们的私人信息被大量收集
第3关:拥抱数据红利
- 下列关于数据重组的说法中,错误的是:
- A、数据重组是数据的重新生产和重新采集
- 数据重组后力量也远大于单个价值的总和,数据重组需要把握哪些要点?
- A、广交五湖四海的朋友,营造一个多方共赢互利的数据应用生态体系
- B、要发挥数据的外部性,实现数据的跨域关联、跨界应用
- D、要克服封闭、保守的思想,首先树立数据开放、共享、共赢的意识
第4关:揭秘“数据范式”
- 在我们日常使用的谷歌翻译中,也是一种非常典型的人工智能,它翻译出来的结果大部分能满足你的需求,那么它的工作原理是什么?
- C、主要采用匹配法,同时结合机器学习,依赖于海量的数据及其相关相关统计信息,不管语法和规则,将原文与互联网上的翻译数据对比,找到最相近、引用最频繁的翻译结果做为输出
- 下列数据建模方式中,正确的有哪些?
- A. 概念模型
- B. 物理模型
- C. 逻辑模型
第5关:何为“数据科学”
- 数据科学是一个跨学科的课题,在工业界和学术界的诸多应用中扮演着越来越重要的角色,你认为作为一个数据科学家,哪些能力是我们需要具备的?
- A. 统计学家能力
- B. 计算机科学家能力
- C. 领域专家能力
- 学习数据科学我们需要学习哪些核心知识?
- A. 数学基础:统计学,线性代数等
- B. 算法实现
- C. 数据建模及评估
- D. 数据采集以及处理
- E. 数据科学道德规范
第6关:数据科学方法论
- 从左侧的知识点可以看出,数据收集之后需要进行数据理解操作,那么它到底需要进行哪些操作呢?
- A. 理解每个字段的意义,对我们所分析的内容是否有帮助
- C. 对数据进行可视化,让我们更好的理解数据
- D. 查看数据是否有遗漏以及需要补充什么类型的数据
- 下列对于数据科学的基本原则描述正确的是
-
A. 模型的泛化能力
-
B.描述性分析与预测性分析
-
C.相关性不同于因果性
-
D.数据分析可以划分成一系列明确的阶段
-
E.分析结果的评估与特定应用场景有关
数据科学导论——数据采集基本概念
第1关:巧妇难为无米之炊
- 数据采集在数据分析中的地位不言而喻,那么我们应该通过哪些方式来获取数据集呢?
-
A通过编写爬虫获取我们想要的数据集
-
B. 通过网络下载公开的数据集
- 数据采集需要遵循哪些原则?
-
A.实效性
-
B. 准确性
-
C. 全面性
-
D. 直观性
-
E. 精确性
第2关:数据采集概念1、
假设我们现在要调查肥胖的因素有哪些,你任务采集以下哪些数据是合理的?
-
A.父母,爷爷奶奶是否肥胖
-
B. 肥胖者从事什么样的工作
-
D.肥胖者的身体健康状况,是否患有什么疾病?
-
E.肥胖者的睡眠时间
- 以下哪些数据是非结构化数据?
-
A. 图片
-
D. 视频
-
E.网页
软件即服务( SaaS )
第1关:SaaS的定义
SaaS层服务是()
- C.以应用软件向客户提供服务
- 下列关于
SaaS说法错误的是()
- C.用户可以在上面安装其他的应用软件
SaaS模式可以多用户租赁
- A.正确
第2关:SaaS 的优劣势
SaaS模式的优点()
- A.不要承担软件项目制定、实施的费用
- B. 不用支付软件许可费用
- C. 不需支付购买数据库等平台软件费用
- D.不需要支付服务器、网络等硬件设备费用
SaaS的优势有哪些()
- A.更灵活的使用软件
- C.更好的软件交付和产品优化
- D.减少所需的 IT 资源
SaaS适合用于商业应用程序和高度定制化的应用程序。
- B. 错误
基础设施即服务( IaaS )
第1关:IaaS 的定义
- 下面属于
IaaS服务类型的为()
- B.将服务器、存储、网络等基础硬件资源通过网络交付给用户、由用户部署操作系统、应用软件。
IaaS主要提供哪些资源()
- A.网络资源
- B. 存储资源
- C. 计算资源
- D. 操作系统
IaaS有哪些优势()
-
A. 快速供应基础设施
-
B. 提高资源的使用率
-
C. 按需付费
-
D.高可扩展性
第2关:IaaS 的主要功能
IaaS的基本功能有()
- A. 数据管理
- B. 资源监控
- C. 资源抽象
- D. 资源部署
- 资源抽象包括()
- A. 服务器资源
- B. 存储资源
- D.网络资源
- 下列关于资源监控的说法正确的是()
- A.对数据中心的多种设备监控,包括路由器、交换机和防火墙等硬件设备。
- B. 存储通常对监控块的读写速率。
- C. 监控服务器CPU的使用量,内存的使用量,磁盘的使用率。
平台即服务( PaaS )
### 第1关:`PaaS` 的定义
PaaS是把服务平台作为一种提供商的模式。
- A. 正确
PaaS未来将会逐渐成为主流平台交付模式。
- A. 正确
- 下列关于
PaaS的说法正确的有()
-
B.
PaaS提供的是基础平台 -
C.
PaaS对平台提供技术支持 -
D.
PaaS对平台提供应用系统开发、优化等服务
第2关:PaaS 的优劣势
- 下列不属于
PaaS服务的是()
- C. 网络安全系统
- 下列属于
PaaS优势的有哪些()
-
B. 更快地应用开发和部署
-
C. 更好的应对突发流量
-
D.降低开发和测试的复杂程度
PaaS提供商为用户提供了操作系统和基础设施环境。
- A. 正确
私有云
第1关:私有云的概念和优势
- 私有云的优势有哪些()
- A. 数据安全
- B. 服务质量
- C. 从分利用现有硬件资源和软件资源
- D. 不影响现有IT管理的流程
- 下列那个属于私有云()
- D.
FusionCloud
- 为客户专门使用的云服务是私有云()
- A. 正确
第2关:私有云的平台
OATOS具有下面哪些功能()
-
A. 文件管理
-
B. 多平台支持
-
C. 权限管理
-
D. 数据备份
- 私有云的建设需要注意的问题哪有哪些()
-
A. 老旧服务器能否利用
-
B. 是否具备弹性空间
-
C. 是否具备高度的虚拟化、高度资源共享
-
D. 是否具有可扩展性
- 与公有云相比私有云更加安全()
- A. 正确
公有云
第1关:公有云简介
- 下列关于公有云的说法中,错误的是( )。
- D. 公有云是银行等大数据企业最佳的选择;
- 下列属于公有云优势的有哪些?(多选)
-
A. 成本低廉
-
B. 易扩展
第2关:公有云的现状与未来
- 下列关于公有云的说法中,错误的有哪些?(多选)
-
A. 在未来,公有云会随着技术的发展彻底取代私有云;
-
C.
AWS云是目前中国国内公有云市场公认的行业巨头之一;
- 下列不属于公有云服务提供商的有哪些?(多选)
-
B. 学校云
-
D. 企业云
- 下列属于我国的公有云服务商的有哪些?(多选)
-
A. 阿里云
-
C. 腾讯云
混合云
第1关:混合云简介
- 下面选项中,哪些属于混合云的优势?(多选)
-
B. 混合云本质上要比传统计算安全
-
C. 可以调整和配置混合云
-
D. 可以扩展存储
- 下列关于混合云说法正确的有哪些?(多选)
-
A. 将安全性要求高的应用部署在自建的私有云上
-
B. 将公开访问的应用部署在公有云上
- 混合云可以利用私有云的安全性,将重要数据保存在本地数据中心;同时可以利用公有云的可扩展性,获取更高的计算资源。(判断正误)
- A. 正确
- 混合云的灾难恢复一般采用什么架构?
- D. 主从架构
第2关:混合云的应用场景和发展趋势
- ( )是指企业建立自己的私有云,同时使用公有云。
C. 混合云
- 下列关于混合云的说法中,错误的是( )。
- C. 混合云的灾难恢复一般采用主从架构,将备用数据放在私有云上;
- 与公有云相比,混合云具备以下哪些优势?(多选)
-
A.数据备份更加灵活;
-
B.能有效降低企业成本;
-
D. 提升系统的服务能力和用户体验;
分布式文件系统
第1关:初识分布式文件系统
- 请在下列选项中选择不是描述分布式文件系统的一项()
- C. 分布式文件系统只能通过本地节点管理存储资源
- 以下哪些属于分布式文件系统的特点()
- A.可以组建集群存储系统。
- B. 可扩展性强,增加存储节点和追踪器都比较容易。
- D. 在对个文件副本之间就进行负载均衡,可以通过横向扩展来确保性能的提升。
- 下列是分布式文件存储服务的为()
-
C.
Ceph -
D.
HDFS
第2关:常见的分布式文件系统介绍
- 以下关于
GFS的描述正确的是()
- C. Google 公司公布了
GFS的技术细节,但并没有作为开源软件发布。
- 关于下列叙述错误的是()
- B、
Ceph是一个优秀的、可靠的、可扩展的、成熟的分布式文件系统。 - D、
Mogilefs支持多节点冗余,不能实现自动的文件复制。
- 下列叙述正确的是()
-
A.
GridFS是MongoDB的一个内置功能,它提供一组文件操作的API以利用MongoDB存储文件。 -
B.
Lustre适合存储小文件、图片的分布式系统研究。 -
C.
TFS是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据。
机器学习基本含义
- 机器学习数据集可划分为训练集和测试集
- A. 对
- 下列属于监督学习的有
-
A.分类
-
B. 回归
- 机器学习致力于研究如何通过计算的手段,利用经验来改善系统自身的性能。
- A. 对
机器学习概述
第1关:监督学习与无监督学习
1. 在____学习中,每个实例都是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成。
- A. 监督
- 有监督算法常见的有哪些?
-
A.
KNN -
B.线性回归算法
-
C. 决策树
- 聚类是监督学习的代表,这样的表述正确吗?
- B. 不正确
- 无监督学习的方法分为以下哪些类?
-
A. 基于概率密度函数估计的直接方法
-
B. 基于样本间相似性度量的简洁聚类方法
- 监督学习和无监督学习有以下哪些区别?
-
A. 训练样本不同
-
B. 核心
-
C. 可解释性不同
-
D. 规律性不通
第2关:训练、验证、测试与评估
- 通过作业可以知道不同学生学习情况、进步的速度快慢这一过程属于以下哪种?
- B. 验证
- 常用的评估方法有哪些?
-
A. k折交叉验证
-
B. 自助法
-
C. 留出法
- 在数据集较小难以有效划分训练集和测试集时很有用。
- B. 自助法
- 评价指标有以下哪几种?
-
A. 召回率(Recall)
-
B. 准确率(Accuracy)
-
C.
F1_score -
D. 精确率(Precision)
5、
学习器在训练集上的误差称为____,在新样本上的误差称为____。
- B. “训练误差”(training error),“泛化误差”(
generalizationerror)
- k折交叉验证是留一法的特例,这种表达正确吗?
- B. 不正确
镜像
第1关:Hello Docker !
#注意如果想在右侧使用命令行模拟操作,请先输入
#service docker start
#否则将不能执行docker命令
#拉取busybox官方镜像,启动容器并执行输出"Hello Docker"
#拉取busybox官方最新镜像
docker pull busybox
#********** Begin *********#
ocker pull busybox:latest
docker run --name first_docker_container busybox:latest echo "Hello Docker"
#********** End **********#
第2关:拉取镜像
#注意如果想在右侧使用命令行模拟操作,请先输入
#service docker start
#否则将不能执行docker命令
#拉取busybox:1.27镜像
#********** Begin *********#
docker pull busybox:1.27
#********** End **********#
容器镜像的导入导出
第1关:导入导出容器
任务描述
本关任务是学习导入导出容器,要求学习者参照示例完成将busyboxContainer容器的文件系统保存为一个tar包,通过该tar包导入一个busybox:v1.0镜像。
相关知识
将 "容器的文件系统"保存到 tar 包
docker export是将“容器的文件系统”导出为一个tar包。注意是操作的对象是容器!它的具体语法如下:
docker export [OPTIONS] CONTAINER
其中:
docker export:Docker将容器导出到tar包的命令关键词;OPTIIONS: 命令选项,-o指定写到一个文件中,而不是标准输出流中;Container: 需要导出到tar包的容器。
例如,将容器container1的“文件系统”保存到tar包,对应的语句如下:
docker export container1 > container1.tar
或者
docker export container1 -o container1.tar
从tar包导入一个镜像
docker import使用docker export导出的tar包加载为一个镜像。它的具体语法如下:
docker import [OPTIONS] 文件|URL|- [镜像名]
其中:
docker import:Docker从tar包加载镜像的命令关键词;OPTIIONS: 命令选项;文件|URL|: 指定docker import的对象,可以是文件或者某个URL;[镜像名]: 以<仓库名>:<标签>的方式来指定。
例如,从container1.tar中加载镜像,镜像名为test:v1.0,对应的语句如下:
docker cat container1.tar | docker import - test:v1.0
实例
在本机以ubuntu镜像为基础创建了一个容器,并在容器的/dir1目录下创建了1.txt和2.txt两个文件,然后将改容器导出为tar文件。
[root@localhost step2]# docker run -it ubuntu /bin/bash
root@a2864c3ed14f:/# touch /dir1/1.txt
root@a2864c3ed14f:/# touch /dir1/2.txt
[root@localhost tempdir]# docker export a286 > ubuntu-test.tar
[root@localhost tempdir]# ls
ubuntu-test.tar
执行cat ubuntu-test.tar | docker import - ubuntu:test命令,将导出的tar包(ubuntu-test.tar)导入成一个镜像,镜像名为ubuntu:test。然后使用ubuntu:test创建一个容器,查看容器中/dir1的内容,发现1.txt和2.txt都存在。
[root@localhost tempdir]# cat ubuntu-test.tar | docker import - ubuntu:test
sha256:34be0173049d9f177d84117a786bc02de18c9c84137ea9c61288810c0917c671
docker export 和 docker save的区别
首先,两者的操作对象不同。docker save是将一个镜像保存为一个tar包,而docker export是将一个容器快照保存为一个tar包。
然后,docker export导出的容器快照文件将丢弃所有的历史记录和元数据信息,即仅保存容器当时的快照状态;而docker save保存的镜像存储文件将保存完整记录,体积也要大。下图就能够很好的说明,ubuntu:test仅仅占97.8MB而ubuntu:latest却占了120MB。
[root@localhost step2]# docker images ubuntu
REPOSITORY TAG IMAGE ID CREATED SIZE
ubuntu test 34be0173049d 5 seconds ago 97.8 MB
ubuntu latest 14f60031763d 2 weeks ago 120 MB
[root@localhost tempdir]# docker run ubuntu:test ls /dir1
1.txt
2.txt
任务要求
本关的编程任务是补全step3/imexport.sh文件中的内容,要求实现导入导出容器。具体要求如下,
- 将
busyboxContainer容器的文件系统保存为一个tar包; - 通过该
tar包导入一个busybox:v1.0镜像。
本关涉及的代码文件step3/imexport.sh的代码框架如下:
#!/bin/bash
#以busybox为镜像创建一个容器,容器名为busyboxContainer
docker run --name busyboxContainer busybox echo "hello"
#1.然后将busyboxContainer导出为容器快照:busybox.tar
#********** Begin *********#
#********** End **********#
#2.最后使用该容器快照导入镜像,镜像名为busybox:v1.0。
#********** Begin *********#
#********** End **********#
测评说明
下面是对平台如何评测你所实现功能的说明及样例测试。本关的测试文件是step3/imexporttest.sh。
具体测试过程如下:
- 平台运行
step3/imexport.sh; - 平台运行
step3/imexporttest.sh,并以标准输入方式提供测试输入; - 平台获取
step3/imexporttest.sh的输出,然后将其与预期输出比较,如果一致则测试通过;否则测试失败。
以下是平台对step3/imexport.sh的样例测试集: 测试输入: 无 测试输出: success
参考答案:
#以busybox为镜像创建一个容器,容器名为busyboxContainer
#拉取busybox 最新镜像,实际生产中,docker pull 这一步可以省略,docker run的时候会自己去拉取。
docker pull busybox
docker run --name busyboxContainer busybox echo "hello"
#1.然后将busyboxContainer导出为容器快照:busybox.tar
#********** Begin *********#
docker export busyboxContainer > busybox.tar.gz
#********** End **********#
#2.最后使用该容器快照导入镜像,镜像名为busybox:v1.0
#********** Begin *********#
cat busybox.tar.gz | docker import - busybox:v1.0
#********** End **********#
openstack环境体验
直接测评
Docker安装与描述
apt-get remove docker docker-engine docker.io containerd runc
apt-get update
apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg \
lsb-release
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 7EA0A9C3F273FCD8
add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
apt-get update
apt-get install docker-ce docker-ce-cli containerd.io
service docker start
apt-get install docker-ce=5:19.03.5~3-0~ubuntu-bionic docker-ce-cli=5:19.03.5~3-0~ubuntu-bionic containerd.io
docker --v
systemctl status docker
第2关:创建和应用docker命令操作容器
Hadoop环境搭建与使用
useradd -m hadoop -s /bin/bash #这里我们登录的是root账号,不需要sudo
#sudo useradd -m hadoop -s /bin/bash # 如果当前用户不是root用户需要使用sudo
passwd hadoop
adduser hadoop sudo
su hadoop
sudo apt-get install openssh-server
passwd root
sudo service ssh start
cd ~/.ssh/
ssh-keygen -t rsa
cat ./id_rsa.pub >> ./authorized_keys
ssh localhost
第3关:安装Java
cd /usr/lib
sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
sudo tar -zxvf /data/bigfiles/jdk-19_linux-x64_bin.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下
cd /usr/lib/jvm #进入jvm文件夹中
ls #查看文件
vim /etc/profile #配置环境
export JAVA_HOME=/usr/local/java/jdk1.8.0_144
export JRE_HOME=/usr/local/java/jdk1.8.0_144/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
source /etc/profile
第4关:安装 Hadoop-单机配置
tar -zvxf /data/bigfiles/hadoop-3.3.4.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/ #进入hadoop解压后的文件夹
mv ./hadoop-3.3.4/ ./hadoop # 将文件夹名改为hadoop
cd /usr/local/hadoop
./bin/hadoop version
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* # 查看运行结果
第5关:安装Hadoop-伪分布式配置
Storm搭建与使用
第1关:Storm在Linux环境配置
第2关:Spark Shell的应用
Spark环境搭建与使用
第1关:安装Spark
第2关: Shell的应用
第3关:通过 Spark API 编写一个独立应用程序
第4关:使用Maven对Java独立应用程序进行编译打包
第5关:使用Maven对Scala独立应用程序进行编译打包
认识 OpenStack
第1关:OpenStack 的应用前景
OpenStack属于一下哪一类服务?
- C.
IaaS
OpenStack的优点包括
-
A.免费开源
-
B. 方便二次开发
-
C. 组件配置灵活
-
D.模块松耦合
OpenStack相当于以下哪个概念
- B. 操作系统
OpenStack 的组件
OpenStack中提供认证管理服务的组件是
- C. Keystone
OpenStack中提供镜像注册服务的组件是
- B. Glance
OpenStack中提供计算服务的组件是
- B. Nova
OpenStack中提供网络服务的组件是
D. Neutron
- 云平台中虚拟机的创建、开机、关机、挂起、暂停、调整、迁移、重启、销毁等操作由哪个 OpenStack 服务负责?
- C. Nova
OpenStack框架中负责管理身份验证、服务规则和服务令牌功能的模块是
- D. Keystone
环境准备
第1关:环境准备
Docker基础实战教程一:入门
第1关:Hello Docker !
#注意如果想在右侧使用命令行模拟操作,请先输入
#service docker start
#否则将不能执行docker命令
#拉取busybox官方镜像,启动容器并执行输出"Hello Docker"
#拉取busybox 最新镜像,实际生产中,docker pull 这一步可以省略,docker run的时候会自己去拉取。
docker pull busybox
#********** Begin *********#
docker run --name my_container busybox:latest echo "Hello Docker"
#********** End **********#
第2关:拉取镜像
#注意如果想在右侧使用命令行模拟操作,请先输入
#service docker start
#否则将不能执行docker命令
#拉取busybox:1.27镜像
#********** Begin *********#
docker pull busybox:1.27
#********** End **********#
第3关:启动一个容器
#注意如果想在右侧使用命令行模拟操作,请先输入
#service docker start
#否则将不能执行docker命令
#创建并启动一个容器,容器名为firstContainer,具备busybox的运行环境。并输出hello world
#拉取最新镜像
docker pull busybox
#********** Begin *********#
docker run --name 'firstContainer' busybox echo "hello world"
#********** End **********#
第4关:停止一个容器
#!/bin/bash
#注意如果想在右侧使用命令行模拟操作,请先输入
#service docker start
#否则将不能执行docker命令
#以ubuntu镜像为基础,创建并在后台启动了一个名为firstContainer的容器(-d看不懂没关系,下一关会介绍的)
#拉取ubutun 最新镜像,实际生产中,docker pull ubutun可以省略,docker run的时候会自己去拉取。
docker pull ubuntu
docker run -itd --name firstContainer ubuntu /bin/bash
#将firstContainer容器停止!
#********** Begin *********#
docker stop firstContainer
#********** End **********#
第5关:进入一个容器
#注意如果想在右侧使用命令行模拟操作,请先输入
#service docker start
#否则将不能执行docker命令
#基于ubuntu镜像创建并在后台启动一个名为container2的容器
#拉取ubutun 最新镜像,实际生产中,docker pull ubutun可以省略,docker run的时候会自己去拉取。
docker pull ubuntu
docker run -itd --name container2 ubuntu /bin/bash
#由于测试环境不允许从终端输入,所以请使用docker exec完成任务
#********** Begin *********#
docker exec container2 mkdir 1.txt
#********** End **********#
第6关:删除容器
#!/bin/bash
#注意如果想在右侧使用命令行模拟操作,请先输入
#service docker start
#否则将不能执行docker命令
#拉取ubutun ,busybox最新镜像,实际生产中,docker pull 这一步可以省略,docker run的时候会自己去拉取。
docker pull ubuntu
docker pull busybox
#创建两个容器
docker run -itd ubuntu /bin/bash
docker run busybox echo "hello world"
#删除所有容器
#********** Begin *********#
docker rm -f $(docker ps -aq)
#********** End **********#
Docker基础实战教程二:镜像管理
第1关:基于Commit定制镜像
#以busybox镜像创建一个容器,在容器中创建一个hello.txt的文件。
#拉取busybox 最新镜像,实际生产中,docker pull 这一步可以省略,docker run的时候会自己去拉取。
docker pull busybox
docker run --name container1 busybox touch hello.txt
#将对容器container1做出的修改提交为一个新镜像,镜像名为busybox:v1
#********** Begin *********#
docker commit container1 busybox:v1
#********** End **********#
第2关:基于save保存镜像与基于load加载镜像
#!/bin/bash
#首先拉取一个busybox镜像
docker pull busybox:latest
#1.将busybox:latest镜像保存到tar包
#********** Begin *********#
docker save busybox:latest > busybox.tar
#********** End **********#
#删除busybox:latest镜像
docker rmi busybox:latest
#2.从tar包加载busybox:latest镜像
#********** Begin *********#
docker load < busybox.tar
#********** End **********#
第3关:导入导出容器
#以busybox为镜像创建一个容器,容器名为busyboxContainer
#拉取busybox 最新镜像,实际生产中,docker pull 这一步可以省略,docker run的时候会自己去拉取。
docker pull busybox
docker run --name busyboxContainer busybox echo "hello"
#1.然后将busyboxContainer导出为容器快照:busybox.tar
#********** Begin *********#
docker export busyboxContainer > busybox.tar.gz
#********** End **********#
#2.最后使用该容器快照导入镜像,镜像名为busybox:v1.0
#********** Begin *********#
cat busybox.tar.gz | docker import - busybox:v1.0
#********** End **********#
第4关:删除镜像
#!/bin/bash
#以busybox为基础镜像创建一个容器,容器名为container3
#拉取busybox 最新镜像,实际生产中,docker pull 这一步可以省略,docker run的时候会自己去拉取。
docker pull busybox
docker run --name container3 busybox:latest echo "hello"
#然后将busybox:latest镜像删除
#********** Begin *********#
docker rm container3 #删除容器
docker rmi busybox #删除镜像
#********** End **********#
第5关:构建私有Registry
#!/bin/bash
#构建一个私人仓库
docker pull registry:2
docker run -d -p 5000:5000 --restart=always --name myregistry registry:2
#拉取busybox镜像
docker pull busybox
#1.使用docker tag给busybox加上一个标签localhost:5000/my-busybox:latest
#********** Begin *********#
docker tag busybox:latest localhost:5000/my-busybox:latest
#********** End **********#
#2.将localhost:5000/my-busybox:latest镜像推送到私人仓库
#********** Begin *********#
docker push localhost:5000/my-busybox:latest
#********** End **********#
#删除本地镜像
docker rmi localhost:5000/my-busybox:latest
#3.从私人仓库拉取localhost:5000/my-busybox:latest镜像
#********** Begin *********#
docker pull localhost:5000/my-busybox:latest
#********** End **********#
#删除私人仓库并将私人仓库中的镜像也删除掉
docker rm -vf myregistry
Docker基础实战教程三:Dockerfile
第1关:初识 Dockerfile
#创建一个空文件夹,并进入其中
mkdir newdir1
cd newdir1
#创建一个Dockerfile文件
touch Dockerfile
#假设我的Dockerfile文件为
#FROM ubuntu
#RUN mkdir dir1
#可以这么写:
# echo 'FROM ubuntu' > Dockerfile
# echo 'RUN mkdir dir1'>> Dockerfile
#输入Dockerfile文件内容
#********** Begin *********#
#以busybox为基础镜像
#在基础镜像的基础上,创建一个hello.txt文件
echo 'FROM busybox' > Dockerfile
echo 'RUN touch hello.txt' >> Dockerfile
#********** End **********#
#使用Dockerfile创建一个新镜像,镜像名为busybox:v1
docker build -t busybox:v1 .
第2关:docker build、COPY和ADD
#创建一个空文件夹,并进入其中
mkdir newdir2
cd newdir2
#创建一个文件夹dir1,将其压缩,然后删除dir1
mkdir dir1 && tar -cvf dir1.tar dir1 && rmdir dir1
#创建一个Dockerfile文件
touch Dockerfile
#假设我的Dockerfile文件为
#FROM ubuntu
#RUN mkdir dir1
#可以这么写:
# echo 'FROM ubuntu' > Dockerfile
# echo 'RUN mkdir dir1'>> Dockerfile
#输入Dockerfile文件内容
#********** Begin *********#
echo 'FROM busybox' > Dockerfile
#并将上下文目录下的dir1.tar“解压提取后”,拷贝到busybox:v3的/
echo 'ADD dir1.tar /' >> Dockerfile
#********** End **********#
#文件内容完毕,在当前文件夹中执行
#********** Begin *********#
#以该Dockerfile构建一个名为busybox:v3的镜像
docker build -t busybox:v3 .
#********** End **********#
第3关:CMD 和 ENTRYPOINT 指令
#创建一个空文件夹,并进入其中
mkdir newdir3
cd newdir3
#创建一个Dockerfile文件
touch Dockerfile
#假设我的Dockerfile文件为
#FROM ubuntu
#RUN mkdir dir1
#可以这么写:
# echo 'FROM ubuntu' > Dockerfile
# echo 'RUN mkdir dir1'>> Dockerfile
#输入Dockerfile文件内容
#********** Begin *********#
#以busybox为基础镜像
echo 'FROM busybox' > Dockerfile
echo 'ENTRYPOINT ["df"]'>> Dockerfile
echo 'CMD ["-Th"]'>> Dockerfile
#********** End **********#
#文件内容完毕,在当前文件夹中执行
#********** Begin *********#
#以该Dockerfile构建一个名为mydisk:latest的镜像
docker build -t mydisk:latest .
#********** End **********#
第4关:ENV、EXPOSE、WORKDIR、ARG 指令
#创建一个空文件夹,并进入其中
mkdir newdir4
cd newdir4
#创建一个Dockerfile文件
touch Dockerfile
#假设我的Dockerfile文件为
#FROM ubuntu
#RUN mkdir dir1
#可以这么写:
# echo 'FROM ubuntu' > Dockerfile
# echo 'RUN mkdir dir1'>> Dockerfile
#输入Dockerfile文件内容
#********** Begin *********#
#以busybox为基础镜像
echo 'FROM busybox' > Dockerfile
#声明暴露3000端口
echo 'EXPOSE 3000' >>Dockerfile
#将变量var1=test设置为环境变量
echo 'ENV var1=test '>>Dockerfile
#设置工作目录为/tmp
echo 'WORKDIR /tmp'>>Dockerfile
#在工作目录下创建一个1.txt文件
echo "RUN touch 1.txt" >> Dockerfile
#********** End **********#
#文件内容完毕,在当前文件夹中执行
#********** Begin *********#
#以该Dockerfile构建一个名为testimage:v1的镜像
docker build -t testimage:v1 .
#********** End **********#
第5关:ONBUILD 和 VOLUME 指令
直接评测
第6关:镜像构建时的缓存机制
直接测评
Docker基础实战教程四:数据卷操作
第1关:创建一个数据卷
#!/bin/bash
#创建一个名为vo1的数据卷,并将该数据卷挂载到container1容器的/dir1目录。
#拉取ubutun 最新镜像,实际生产中,docker pull 这一步可以省略,docker run的时候会自己去拉取。
docker pull ubuntu
#********** Begin *********#
docker run -v vo1:/dir1 --name container1 ubuntu
#********** End **********#
第2关:挂载和共享数据卷
#1.创建一个名为container1的容器,并将本地主机的/dir1目录挂载到容器中的/codir1中。
#拉取ubutun 最新镜像,实际生产中,docker pull 这一步可以省略,docker run的时候会自己去拉取。
docker pull ubuntu
#********** Begin *********#
docker run -v /dir1:/codir1 --name container1 ubuntu
#********** End **********#
#2.创建一个名为container2的容器,与container1共享数据卷。
#********** Begin *********#
docker run --volumes-from container1 --name container2 ubuntu
#********** End **********#
第3关:查看数据卷的信息
#创建一个容器,并创建一个随机名字的数据卷挂载到容器的/data目录
#拉取ubutun 最新镜像,实际生产中,docker pull 这一步可以省略,docker run的时候会自己去拉取。
docker pull ubuntu &> /dev/null
docker rm container1 -f &>/dev/null
docker run -v /data --name container1 ubuntu
#输出容器container1创建的数据卷的名字
#********** Begin *********#
docker inspect --type container --format='{{range .Mounts}}{{.Name}}{{end}}' container1
#********** End **********#
第4关:删除数据卷
#!/bin/bash
#创建一个名为container1的容器,创建一个数据卷挂载到容器的/data目录
#拉取ubutun 最新镜像,实际生产中,docker pull 这一步可以省略,docker run的时候会自己去拉取。
docker pull ubuntu
docker run -v vo4:/data --name container1 ubuntu
#删除container1对应的数据卷
#********** Begin *********#
docker rm -v container1
docker volume rm vo4
#********** End **********#
第5关:备份、恢复数据卷
#!/bin/bash
#拉取ubutun 最新镜像,实际生产中,docker pull 这一步可以省略,docker run的时候会自己去拉取。
docker pull ubuntu
# 创建一个vo1的数据卷,并在数据卷中添加1.txt文件
docker run --name vocontainer1 -v vo1:/dir1 ubuntu touch /dir1/1.txt
#1.将vo1数据卷的数据备份到宿主机的/newback中,将容器的/backup路径挂载上去,并将容器内/dir1文件夹打包至/backup/backup.tar
#********** Begin *********#
docker run --volumes-from vocontainer1 -v /newback:/backup ubuntu tar -cvf /backup/backup.tar /dir1
#********** End **********#
#删除所有的容器以及它使用的数据卷
docker rm -vf $(docker ps -aq)
docker volume rm vo1
#在次创建一个vo1的数据卷
docker run -itd --name vocontainer2 -v vo1:/dir1 ubuntu /bin/bash
#2.将保存在宿主机中备份文件的数据恢复到vocontainer2的/中
#********** Begin *********#
docker run --volumes-from vocontainer2 -v /newback:/backup ubuntu tar -xvf /backup/backup.tar -C /
#********** End **********#
MPI编程
第1关:MPI安装及配置
第2关:使用 MPI 运行"Hello World"
第3关:使用 MPI 运行"Hello World"
第4关:乒乓程序
第5关:环程序
第6关:求π值
Numpy科学计算
第1关:数组创建
# 引入numpy库
import numpy as np
# 定义cnmda函数
def cnmda(m,n):
'''
创建numpy数组
参数:
m:第一维的长度
n: 第二维的长度
返回值:
ret: 一个numpy数组
'''
ret = 0
# 请在此添加创建多维数组的代码并赋值给ret
#********** Begin *********#
x = [y for y in range(n)]
ret =np.array([x]*m)
#********** End **********#
return ret
第2关:切片索引
import numpy as np
def get_roi(data, x, y, w, h):
'''
提取data中左上角顶点坐标为(x, y)宽为w高为h的ROI
:param data: 二维数组,类型为ndarray
:param x: ROI左上角顶点的行索引,类型为int
:param y: ROI左上角顶点的列索引,类型为int
:param w: ROI的宽,类型为int
:param h: ROI的高,类型为int
:return: ROI,类型为ndarray
'''
#********* Begin *********#
return data[x:x+h+1, y:y+w+1]
#********* End *********#
第3关:基本运算
# 引入numpy库
import numpy as np
# 定义opeadd函数
def opeadd(m,b,n):
'''
参数:
m:是一个数组
b:是一个列表
n:是列表中的索引
你需要做的是 m+b[n]
返回值:
ret: 一个numpy数组
'''
ret = 0
#********** Begin *********#
ret = m+b[n]
#********** End **********#
return ret
# 定义opemul函数
def opemul(m,b,n):
'''
参数:
m:是一个数组
b:是一个列表
n:是列表中的索引
你需要做的是 m*b[n]
返回值:
ret: 一个numpy数组
'''
ret = 0
#********** Begin *********#
ret=m*b[n]
#********** End **********#
return ret
第4关:ufunc
import numpy as np
ndarray = np.ndarray
def task1(A: ndarray) -> ndarray:
'''
:param A n*m维的numpy数组
任务要求:计算矩阵A的平方根并与标量2相加;
'''
########## Begin ##########
B = np.sqrt(A) + 2
########## End ##########
return B
def task2(A: ndarray) -> ndarray:
'''
:param A n*m维的numpy数组
任务要求:将矩阵A开根号后的小数部分与原矩阵A相加;
'''
########## Begin ##########
B = A + np.modf(np.sqrt(A))[0]
########## End ##########
return B
def task3(A: ndarray) -> ndarray:
'''
:param A n*m维的numpy数组
任务要求:使用通用函数numpy.dot()计算矩阵A与矩阵A转置的矢量积;
提示:使用.T属性获得转置矩阵,例如A的转置矩阵为A.T
'''
########## Begin ##########
B = np.dot(A, A.T)
########## End ##########
return B
第5关:文件读写
import numpy as np
ndarray = np.ndarray
def task():
'''
任务要求:从指定路径的二进制文件中("step5/FileHandling/files/A.npy")读取NumPy矢量数组A,从从指定路径的txt文件中读取矢量数组B("step5/FileHandling/files/B.txt"),然后使用通用函数numpy.add()对数组A和B进行求和,将结果保存到指定的二进制文件中("step5/FileHandling/files/out.npy")
提示1:使用np.load('path')加载二进制文件'step5/FileHandling/files/A.npy'
提示2:使用np.loadtxt('path', delimiter=',')加载文本文件'step5/FileHandling/files/B.txt'
提示3:使用使用np.save('path', C)将结果储存到二进制文件'step5/FileHandling/files/out.npy'中
提示3:A.npy和B.txt中矩阵维度一致
'''
########## Begin ##########
A = np.load('step5/FileHandling/files/A.npy')
B = np.loadtxt('step5/FileHandling/files/B.txt', delimiter=',')
C = A + B
np.save("step5/FileHandling/files/out.npy", C)
########## End ##########
第6关:数组切片与索引
# 引入numpy库
import numpy as np
# 定义cnmda函数
def ce(a,m,n):
'''
参数:
a:是一个Numpy数组
m:是第m维数组的索引
n:第m维数组的前n个元素的索引
返回值:
ret: 一个numpy数组
'''
ret = 0
# 请在此添加切片的代码,实现找出多维数组a中第m个数组的前n个元素 并赋值给ret
#********** Begin *********#
ret = a[m][:n]
#********** End **********#
return ret
第7关:数组堆叠
# 引入numpy库
import numpy as np
# 定义varray函数
def varray(m,n):
'''
参数:
m:是第一个数组
n:是第二个数组
返回值:
ret: 一个numpy数组
'''
ret = 0
# 请在此添加代码实现数组的垂直叠加并赋值给ret
#********** Begin *********#
ret = np.vstack((m,n))
#********** End **********#
return ret
# 定义darray函数
def darray(m,n):
'''
参数:
m:是第一个数组
n:是第二个数组
返回值:
ret: 一个numpy数组
'''
ret = 0
# 请在此添加代码实现数组的深度叠加并赋值给ret
#********** Begin *********#
ret = np.dstack((m,n))
#********** End **********#
return ret
# 定义harray函数
def harray(m,n):
'''
参数:
m:是第一个数组
n:是第二个数组
返回值:
ret: 一个numpy数组
'''
ret = 0
# 请在此添加代码实现数组的水平叠加并赋值给ret
#********** Begin *********#
ret = np.hstack((m,n))
#********** End **********#
return ret
数据结构课程设计Python版–植物百科数据的管理与分析
科比投篮选择——数据采集
第1关:数据采集
import requests
import pandas as pd
def student():
# ********* Begin *********#
req=requests.session()
req.headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
data=pd.DataFrame()
for pg in range(1,5):
a=req.get("http://121.40.96.250:10000/articleList?page="+str(pg)+"&articleTitle=&tagId=")
for i in a.json()["data"][:2]:
season=i["title"].split(":")[1]
pg1=1
while True:
b=req.get("http://121.40.96.250:10000/getSeasonData?page="+str(pg1)+"&limit=90&season="+season)
if b.json()["data"]==[]:
break
for b1 in b.json()["data"]:
d=pd.DataFrame([b1["action_type"],b1["combined_shot_type"],b1["game_event_id"],b1["game_id"],b1["lat"],b1["loc_x"],b1["loc_y"],b1["lon"],b1["minutes_remaining"],b1["period"],b1["playoffs"],b1["season"]
,b1["seconds_remaining"],b1["shot_distance"],b1["shot_made_flag"],b1["shot_type"],b1["shot_zone_area"],b1["shot_zone_basic"],b1["shot_zone_range"],b1["team_id"],b1["team_name"]
,b1["game_date"],b1["matchup"],b1["opponent"],b1["shot_id"].replace("\r","")]).T
data=pd.concat([data,d])
pg1+=1
print(data.head())
data.to_csv("data.csv",index=None)
# ********* End *********#
科比投篮预测——可视化与探索性数据分析(一)
import matplotlib.pyplot as plt
import pandas as pd
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
def student():
# ********* Begin *********#
nona=pd.read_csv("Task1/data.csv").dropna()
alpha = 0.02
plt.figure(figsize=(10,10))
# loc_x and loc_y
plt.subplot(121)
plt.scatter(nona.loc_x, nona.loc_y, color='blue', alpha=alpha)
plt.title('loc_x and loc_y')
# lat and lon
plt.subplot(122)
plt.scatter(nona.lon, nona.lat, color='green', alpha=alpha)
plt.title('lat and lon')
plt.savefig("Task1/img/T1.png")
plt.show()
# ********* End *********#
第2关:射击距离
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
def student():
# ********* Begin *********#
raw = pd.read_csv("Task2/data.csv")
raw['dist'] = np.sqrt(raw['loc_x']**2 + raw['loc_y']**2)
plt.figure(figsize=(5,5))
plt.scatter(raw.dist, raw.shot_distance)
plt.title('dist and shot_distance')
plt.savefig("Task2/img/T1.png")
plt.show()
# ********* End *********#
第3关:射击区范围
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import matplotlib.cm as cm
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
def student():
# ********* Begin *********#
data=pd.read_csv("./data.csv")
cmap = plt.cm.rainbow
norm = matplotlib.colors.Normalize()
plt.figure(figsize=(10,10))
plt.subplot(2,1,1)
data1=data
x=data1["shot_made_flag"].groupby(data1["shot_zone_range"]).mean()
x=pd.DataFrame([x.index,x.values]).T
data1=pd.merge(data1,x,left_on="shot_zone_range",right_on=0)
plt.scatter(x=data1["lon"],y=data1["lat"],c=cmap(norm(list(data1[1].values))))
plt.ylim(33.7,34.0883)
plt.subplot(2,1,2)
d=data["shot_zone_range"].groupby(data["shot_zone_range"]).count()
d=pd.DataFrame([d.index,d.values]).T
d.sort_values(by=[1],ascending=False,inplace=True)
c=[]
for i in d[0]:
c.append(data1[data1["shot_zone_range"]==i][1].head(1).values[0])
plt.bar(d[0],d[1],color=cmap(norm(c)))
plt.savefig("Task4/img/T1.png")
plt.show()
# ********* End *********#
第4关:射击区
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import matplotlib.cm as cm
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
def student():
c={"Center(C)":"goldenrod","Right Side Center(RC)":"cornflowerblue","Right Side(R)":"fuchsia","Left Side Center(LC)":"limegreen","Left Side(L)":"turquoise","Back Court(BC)":"red"}
# ********* Begin *********#
plt.figure(figsize=(10,10))
data=pd.read_csv("./data.csv")
plt.subplot(2,1,1)
data1=data
x=data1["shot_made_flag"].groupby(data1["shot_zone_area"]).mean()
x=pd.DataFrame([x.index,x.values]).T
data1=pd.merge(data1,x,left_on="shot_zone_area",right_on=0)
data2=pd.DataFrame([c.keys(),c.values()]).T
data1=pd.merge(data1,data2,left_on="shot_zone_area",right_on=0)
plt.scatter(x=data1["lon"],y=data1["lat"],color=data1["1_y"])
plt.ylim(33.7,34.0883)
plt.subplot(2,1,2)
d=data["shot_zone_area"].groupby(data["shot_zone_area"]).count()
d=pd.DataFrame([d.index,d.values]).T
d.sort_values(by=[1],ascending=False,inplace=True)
plt.bar(d[0],d[1],color=c.values())
plt.xticks(rotation=45)
plt.savefig("Task5/img/T1.png")
plt.show()
# ********* End *********#
第5关:具体投篮区域
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import matplotlib.cm as cm
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
def student():
c={"Mid-Range":"cornflowerblue","Restricted Area":"fuchsia","Above the Break 3":"tomato","In The Paint (Non-RA)":"limegreen","Right Corner 3":"green","Back Court(BC)":"fuchsia","Left Corner 3":"lime","Backcourt":"tan"}
# ********* Begin *********#
plt.figure(figsize=(10,10))
data=pd.read_csv("./data.csv")
plt.subplot(2,1,1)
data1=data
x=data1["shot_made_flag"].groupby(data1["shot_zone_basic"]).mean()
x=pd.DataFrame([x.index,x.values]).T
data1=pd.merge(data1,x,left_on="shot_zone_basic",right_on=0)
data2=pd.DataFrame([c.keys(),c.values()]).T
data1=pd.merge(data1,data2,left_on="shot_zone_basic",right_on=0)
plt.scatter(x=data1["lon"],y=data1["lat"],color=data1["1_y"])
plt.ylim(33.7,34.0883)
plt.subplot(2,1,2)
d=data["shot_zone_area"].groupby(data["shot_zone_basic"]).count()
d=pd.DataFrame([d.index,d.values]).T
d.sort_values(by=[1],ascending=False,inplace=True)
plt.bar(d[0],d[1],color=c.values())
plt.xticks(rotation=45)
plt.savefig("Task6/img/T1.png")
plt.show()
# ********* End *********#
第6关:投篮准确度
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import matplotlib.cm as cm
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
def student():
# ********* Begin *********#
data=pd.read_csv("./data.csv").dropna()
plt.subplot(212)
data1=data[["lat","lon","shot_zone_range","shot_made_flag"]]
x=data1["shot_made_flag"].groupby(data1["shot_zone_range"]).mean()
x=pd.DataFrame([x.index,x.values]).T
data1=pd.merge(data1,x,left_on="shot_zone_range",right_on=0)
d=plt.scatter(x=data1["lon"],y=data1["lat"],c=data1[1])
plt.colorbar(d,)
plt.ylim((33.7, 34.0883))
plt.subplot(222)
data2=data[["lat","lon","shot_zone_area","shot_made_flag"]]
da=data2["shot_made_flag"].groupby(data2["shot_zone_area"]).mean()
d=pd.DataFrame([da.index,da.values]).T
data2=pd.merge(data2,d,left_on="shot_zone_area",right_on=0)
plt.scatter(x=data2["lon"],y=data2["lat"],c=data2[1])
plt.ylim((33.7, 34.0883))
plt.subplot(221)
data3=data[["lat","lon","shot_zone_basic","shot_made_flag"]]
da=data3["shot_made_flag"].groupby(data3["shot_zone_basic"]).mean()
da=pd.DataFrame([da.index,da.values]).T
data3=pd.merge(data3,da,left_on="shot_zone_basic",right_on=0)
plt.scatter(x=data3["lon"],y=data3["lat"],c=data3[1])
plt.ylim((33.7, 34.0883))
plt.savefig("Task7/img/T1.png")
plt.show()
# ********* End *********#
科比投篮预测——数据处理与分析
第1关:数据清洗
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
def student():
result=""
# ********* Begin *********#
raw = pd.read_csv("task1/data.csv")
raw['dist'] = np.sqrt(raw['loc_x']**2 + raw['loc_y']**2)
loc_x_zero = raw['loc_x'] == 0
raw['angle'] = 0
raw['angle'][~loc_x_zero] = np.arctan(raw['loc_y'][~loc_x_zero] / raw['loc_x'][~loc_x_zero])
raw['angle'][loc_x_zero] = np.pi / 2
raw['remaining_time'] = raw['minutes_remaining'] * 60 + raw['seconds_remaining']
result=raw[["dist","angle","remaining_time"]].head()
# ********* End *********#
return result
第2关:数据预处理
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
raw = pd.read_csv("task2/data.csv",index_col=0)
def student(raw):
# ********** Begin ********** #
drops = ['shot_id', 'team_id', 'team_name', 'shot_zone_area', 'shot_zone_range',
'shot_zone_basic','matchup','lon','lat','seconds_remaining', 'minutes_remaining',
'shot_distance', 'loc_x', 'loc_y', 'game_event_id', 'game_id', 'game_date']
for drop in drops:
raw = raw.drop(drop, 1)
categorical_vars = ['action_type', 'combined_shot_type', 'shot_type','opponent',
'period', 'season']
for var in categorical_vars:
raw = pd.concat([raw, pd.get_dummies(raw[var], prefix=var)], 1)
raw = raw.drop(var, 1)
return raw.columns
# ********** End ********** #
if __name__ == "__main__":
stu = student(raw)
print(stu)
第3关:构造模型并调参
import numpy as np
import pandas as pd
import scipy as sp
import warnings
warnings.filterwarnings("ignore")
with warnings.catch_warnings():
warnings.filterwarnings("ignore",category=DeprecationWarning)
from numpy.core.umath_tests import inner1d
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import confusion_matrix
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import KFold
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
def logloss(act, pred):
epsilon = 1e-15
pred = sp.maximum(epsilon, pred)
pred = sp.minimum(1-epsilon, pred)
ll = sum(act*sp.log(pred) + sp.subtract(1,act)*sp.log(sp.subtract(1,pred)))
ll = ll * -1.0/len(act)
return ll
def student():
# ********* Begin *********#
df=pd.read_csv("task3/data.csv")
train = df.drop('shot_made_flag', 1)
train_y = df['shot_made_flag']
min_score = 100000
best_n = 0
scores_n = []
range_n = [1,10,100]
for n in range_n:
rfc_score = 0.
rfc = RandomForestClassifier(n_estimators=n)
kf=KFold(n_splits=3,shuffle=True)
for train_k, test_k in kf.split(train,train_y):
rfc.fit(train.iloc[train_k], train_y.iloc[train_k])
pred = rfc.predict(train.iloc[test_k])
rfc_score += logloss(train_y.iloc[test_k], pred) / 3
scores_n.append(rfc_score)
if rfc_score < min_score:
min_score = rfc_score
best_n = n
print("n_estimators:"+str(best_n))
min_score = 100000
best_m = 0
scores_m = []
range_m = [1,10,100]
for m in range_m:
rfc_score = 0.
rfc = RandomForestClassifier(max_depth=m, n_estimators=best_n)
kf=KFold(shuffle=True,n_splits=3)
for train_k, test_k in kf.split(train,train_y):
rfc.fit(train.iloc[train_k], train_y.iloc[train_k])
pred = rfc.predict(train.iloc[test_k])
rfc_score += logloss(train_y.iloc[test_k], pred) / 3
scores_m.append(rfc_score)
if rfc_score < min_score:
min_score = rfc_score
best_m = m
print("max_depth:"+str(best_m))
# ********* End *********#
第4关:参数验证
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
def visual(range_n,scores_n,range_m,scores_m):
# ********* Begin *********#
plt.figure(figsize=(10,5))
plt.subplot(121)
plt.plot(range_n, scores_n)
plt.ylabel('score')
plt.xlabel('number of trees')
plt.subplot(122)
plt.plot(range_m, scores_m)
plt.ylabel('score')
plt.xlabel('max depth')
plt.savefig("task4/result/pict1.jpg")
# ********* End *********#
第5关:预测结果
import numpy as np
import pandas as pd
import scipy as sp
import warnings
warnings.filterwarnings("ignore") # 忽略警告
with warnings.catch_warnings():
warnings.filterwarnings("ignore",category=DeprecationWarning)
from numpy.core.umath_tests import inner1d
from sklearn.ensemble import RandomForestClassifier
def student(n_estimators,max_depth):
# ********* Begin *********#
raw = pd.read_csv("task5/data.csv",index_col=0)
df = raw[pd.notnull(raw['shot_made_flag'])]
submission = raw[pd.isnull(raw['shot_made_flag'])]
submission = submission.drop('shot_made_flag', 1)
train = df.drop('shot_made_flag', 1)
train_y = df['shot_made_flag']
model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth)
model.fit(train, train_y)
pred = model.predict_proba(submission)
# ********* End *********#
return pred
Pandas基本操作
第1关:数据结构
import pandas as pd
########## Begin ##########
data = {'A':{'a':90,'b':89,'c':78},
'B':{'a':82,'b':95,'c':92},
'C':{'a':78,'b':67},
'D':{'a':78,'b':67}}
df1 = pd.DataFrame(data)
########## End ##########
print(df1)
第2关:切片索引
import pandas as pd
from sklearn import datasets
def demo():
data = datasets.load_linnerud().data
#********** Begin **********#
index = pd.MultiIndex.from_product([["A","B","C","D"],["1",'2','3','4','5']])
column = pd.MultiIndex.from_product([["stage"],["a","b","c"]])
df = pd.DataFrame(data,index=index,columns=column)
df1 = df.T.stack()
idx = pd.IndexSlice
print(df1.loc[idx["stage",:,"2"],:])
#*********** End ***********#
第3关:增删改查
import pandas as pd
# pandas版本原因显示,设置列名仅显示4列
pd.set_option('display.max_columns', 4)
DataFrame = pd.DataFrame
def task1(Books: DataFrame) -> DataFrame:
'''
参数:图书列表
任务:添加新图书【书名: 算法图解, 作者: [美] Aditya Bhargava, 出版社: 人民邮电出版社, 出版年: 2017-3, 页数: 196, 定价: 49.00元, 豆瓣评分: 8.4】;
'''
########## Begin ##########
new_book = {'书名': '算法图解', '作者': '[美] Aditya Bhargava', '出版社': '人民邮电出版社', '出版年': '2017-3', '页数': 196, '定价': '49.00元', '豆瓣评分': 8.4}
Books = Books.append(new_book, ignore_index=True)
########## End ##########
return Books
def task2(Books: DataFrame) -> DataFrame:
'''
参数:图书列表
任务:删除页数列的数据;
'''
########## Begin ##########
Books = Books.drop('页数', axis=1)
########## End ##########
return Books
def task3(Books: DataFrame) -> DataFrame:
'''
参数:图书列表
任务:修改《算法导论(原书第3版)》的价格为666元;
'''
########## Begin ##########
Books.loc[5, '定价'] = '666元'
########## End ##########
return Books
def task4(Books: DataFrame) -> DataFrame:
'''
参数:图书列表
任务:查询所有图书的豆瓣评分;
'''
########## Begin ##########
Out = Books.loc[:, ['书名', '豆瓣评分']]
########## End ##########
return Out
第4关:文件读写
import pandas as pd
# pandas版本原因显示,设置列名仅显示4列
pd.set_option('display.max_columns', 4)
def task():
'''
任务要求:实现使用Pandas读取gbk编码的文件("FileHandling/Books.csv"),然后将数据写入到utf-8编码的文件中("FileHandling/Out.csv")并使用'*'号分隔数据。
提示1:使用参数encoding指定编码格式('gbk' 和 'utf-8')
提示2:使用参数sep指定数据分隔方式
'''
########## Begin ##########
df = pd.read_csv('FileHandling/Books.csv', encoding='gbk')
df.to_csv('FileHandling/Out.csv', encoding='utf-8', sep='*')
########## End ##########
第5关:算术运算
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import numpy as np
import pandas as pd
def add_way():
df1 = DataFrame(np.arange(12.).reshape((3, 4)), columns=list('abcd'))
df2 = DataFrame(np.arange(20.).reshape((4, 5)), columns=list('abcde'))
###请在此添加代码
#********** Begin *********#
df3=df1.add(df2,fill_value=4)
#********** End **********#
return df3
第6关:描述性统计
import pandas as pd
def task1():
'''
任务:使用describe()方法对给定数据进行统计描述汇总;
'''
# 创建学生成绩数据
score = [
["张三", 92, 95, 100, 96],
["李四", 85, 80, 80, 90],
["王二", 95, 90, 89, 95],
["小刚", 88, 92, 96, 93]
]
score = pd.DataFrame(score, columns=['姓名', '语文', '数学', '计算机', '英语'])
########## Begin ##########
result = score.describe(include=['number'])
########## Begin ##########
return result
def task2():
'''
任务:使用统计描述描述函数求各科目成绩的中位数;
'''
# 创建学生成绩数据
score = [
["张三", 92, 95, 100, 96],
["李四", 85, 80, 80, 90],
["王二", 95, 90, 89, 95],
["小刚", 88, 92, 96, 93]
]
score = pd.DataFrame(score, columns=['姓名', '语文', '数学', '计算机', '英语'])
########## Begin ##########
result = score.median(axis=0)
########## Begin ##########
return result
第7关:时间序列处理
import pandas as pd
from datetime import datetime
def task1():
'''
任务:创建以 2021 年1 月1 日为开始的 12 条时间索引,相邻索引间隔时间长度为一个月。
'''
########## Begin ##########
result = pd.date_range('2021-1-1', periods=12, freq='M')
########## End ##########
return result
def task2():
'''
任务:在 2021 年 1 月 1 日到 2021 年 3 月 1 日间,每隔一周创建一条索引。
'''
########## Begin ##########
start = datetime(2021, 1, 1)
end = datetime(2021, 3, 1)
result = pd.date_range(start, end, freq='W')
########## End ##########
return result
def task3():
'''
任务:给定以时间为索引的 Series 对象,查找索引时间在 2021 年 1 月内的所有记录。
'''
start = datetime(2021, 1, 1)
end = datetime(2021, 3, 1)
rng = pd.date_range(start, end, freq='W')
ts = pd.Series(range(len(rng)), index=rng)
########## Begin ##########
result = ts["2021-1"]
########## End ##########
return result
第8关:Series
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import pandas as pd
def create_series():
###请在此添加代码
#********** Begin *********#
series_a=Series([1,2,5,7],index=['nu','li','xue','xi'])
dict_a={"ting":1,"shuo":2,"du":32,"xie":44}
series_b=Series(dict_a)
#********** End **********#
return series_a,dict_a,series_b
create_series()
第9关:DataFrame
第10关:读取数据
第11关:排序
第12关:去重
正则表达式入门
第1关:查找第一个匹配的字符串
# coding=utf-8
# 在此导入python正则库
########## Begin ##########
import re
########## End ##########
check_name = input()
# 在此使用正则匹配'张明'的信息,结果存储到is_zhangming中
########## Begin ##########
is_zhangming = re.search(r'张明', check_name)
########## End ##########
if is_zhangming is not None:
print(is_zhangming.span())
else:
print(is_zhangming)
第2关:基础正则表达式–字符组
# coding=utf-8
import re
input_str = input()
# 编写获取python和Python的正则,并存储到match_python变量中
########## Begin ##########
match_python = re.findall(r'[Pp]ython',input_str)
########## End ##########
print(match_python)
第3关:基础正则表达式–区间与区间取反
# coding=utf-8
import re
input_str = input()
# 1、编写获取到数字的正则,并输出匹配到的信息
########## Begin ##########
b=re.findall(r'[0-9]',input_str)
print(b)
########## End ##########
# 2、编写获取到不是数字的正则,并输出匹配到的信息
########## Begin ##########
c = re.findall(r'[^0-9]',input_str)
print(c)
########## End ##########
第4关:基础正则表达式–快捷方式
# coding=utf-8
import re
input_str = input()
# 1、编写获取到单词的正则,并输出匹配到的信息
########## Begin ##########
b=re.findall(r'[a-zA-Z0-9]',input_str)
print(b)
########## End ##########
# 2、编写获取到不是单词的正则,并输出匹配到的信息
########## Begin ##########
c=re.findall(r'[\W]',input_str)
print(c)
########## End ##########
第5关:字符串的开始与结束
import re
input_str = input()
# 1、编写获取到以educoder开头的正则,并存储到变量a
########## Begin ##########
a = re.search(r'^educoder', input_str)
########## End ##########
if a is not None:
print(a.span())
else:
print(a)
# 2、编写获取到以educoder结束的正则,并存储到变量b
########## Begin ##########
b = re.search(r'educoder$', input_str)
########## End ##########
if b is not None:
print(b.span())
else:
print(b)
第6关:任意字符
# coding=utf-8
import re
input_str = input()
# 编写获取(任意字符)+ython的字符串,并存储到变量a中
########## Begin ##########
a = re.findall(r'.ython',input_str)
########## End ##########
print(a)
第7关:可选字符
# coding=utf-8
import re
input_str = input()
# 编写获取she或者he的字符串,并存储到变量a中
########## Begin ##########
a = re.findall(r's?he',input_str)
########## End ##########
print(a)
第8关:重复区间
import re
input_str = input()
# 1、基于贪心模式匹配字符串中重复出现2个数字的子字符串,并存储到变量a。
########## Begin ##########
a = re.findall(r'[\d]{2}',input_str)
########## End ##########
print(a)
# 2、基于贪心模式匹配字符串中重复出现4-7个数字的子字符串,并存储到变量b。
########## Begin ##########
b = re.findall(r'[\d]{4,7}',input_str)
########## End ##########
print(b)
第9关:开闭区间与速写
# coding=utf-8
import re
input_str = input()
# 1、基于贪心模式匹配字符串中连续出现5个数字以上的子字符串,并存储到变量a。
########## Begin ##########
a = re.findall(r'[\d]{5,}',input_str)
########## End ##########
print(a)
# 2、匹配字符串中都为数字的子字符串,并存储到变量b。
########## Begin ##########
b = re.findall(r'[\d]+',input_str)
########## End ##########
print(b)
Python正则表达式进阶
第1关:分组
import re
def re_group(input_data):
result=[]
#*********** Begin **********#
result = re.findall(r'\(?\+?8?6?\)?[ .-]?([\d]{11})',input_data)
#*********** End **********#
return result
第2关:先行断言
import re
a = input()
#*********** Begin **********#
result=re.findall(r'[\w]+(?=ing)',a)
#*********** End **********#
print(result)
第3关:后发断言
import re
a = input()
#*********** Begin **********#
result=re.findall(r'(?<=go)[\w]+',a)
#*********** End **********#
print(result)
第4关:标记
import re
def re_mark(input_data):
result=[]
#*********** Begin **********#
result = re.findall(r'^study[\w]*@[\w]+\.com',input_data,re.I|re.M)
#*********** End **********#
return result
第5关:编译
import re
def re_telephone(str):
#*********** Begin **********#
re_input = '^(\d{3})-(\d{3,8})$'
re_telephone = re.compile(re_input)
re_group = re_telephone.match(str).groups()
#*********** End **********#
return re_group
python正则表达式综合练习
第1关:提取日志内容
import re
def re_Regex():
#*********** Begin **********#
# 读取数据文件
# 根据日志数据编写正则表达式提取数据内容
# 提取cs_item_sk的数值以1结尾的并且布尔值为true的所需的日志内容
string = r'cs_item_sk[\s=]*(\d*?1+)\s+.+?true\s*(\d+)$'
pattern = re.compile(string)
with open('./test_one/src.txt', 'r') as f:
for line in f.readlines():
line = line.strip()
m = pattern.search(line)
if m is not None:
print(m.groups())
#*********** End **********#
第2关:组合密码匹配
import re
def re_test2(input_data):
result=[]
#*********** Begin **********#
result = re.findall(r'^(?![a-zA-z]+$)(?!\d+$)(?![!@#$%^&*.?]+$)[a-zA-Z\d!@#$%.?^&*]+$',input_data,re.M)
#*********** End **********#
return result
第3关:网页内容解析
import re
def parse_one_page(html):
#*********** Begin **********#
pattern = re.compile('<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)"'
+'.*?name.*?a.*?>(.*?)</a>.*?star.*?>[^\u4e00-\u9fff]+(.*?)[^\u4e00-\u9fff]+</p>'
+'.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>'
+'.*?fraction.*?>(.*?)</i>.*?</dd>',
re.S)
res = re.findall(pattern, html)
print(res)
# 将输出结果打印即可
#*********** End **********#
爬虫实战——国防科技大学本科招生信息网爬取
第1关:利用URL获取超文本文件并保存至本
# -*- coding: utf-8 -*-
import requests
import os
import hashlib
# 国防科技大学本科招生信息网中录取分数网页URL:
url = 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/index.html' # 录取分数网页URL
def step1():
# 请按下面的注释提示添加代码,完成相应功能
#********** Begin **********#
# 1.将网页内容保存到data
response=requests.get(url)
data=response.text
# 2.将data以二进制写模式写入以学号命名的 “nudt.txt” 文件:
with open("nudt.txt","w") as f:
f.write(data)
#********** End **********#
泰坦尼克生还预测——可视化与探索性数据分析
第1关:存活率与性别和船舱等级之间的关
import pandas as pd
import numpy as np
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
sns.set()
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
def student():
# ********* Begin *********#
a=pd.read_csv('Task1/train.csv')
fig,axes=plt.subplots(1,2)
sns.violinplot(x="Pclass",y="Age",data=a,split=True,ax=axes[0],hue='Survived') #上图
sns.violinplot(x="Sex",y="Age",split=True,data=a,hue='Survived',ax=axes[1]) #下图
plt.savefig('Task1/img/T1.png')
plt.show()
# ********* End *********#
第2关:各个口岸的生还率
import pandas as pd
import numpy as np
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
sns.set()
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
def student():
# ********* Begin *********#
a=pd.read_csv('Task2/train.csv')
sns.factorplot(data=a, x="Embarked", y="Survived")
plt.savefig('Task2/img/T1.png')
plt.show()
# ********* End *********#
第3关:统计各登船口岸的登船人数以及生还
import pandas as pd
import numpy as np
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
sns.set()
import matplotlib.pyplot as plt
def student():
# ********* Begin *********#
a=pd.read_csv('Task3/train.csv')
fig,ax = plt.subplots(2,2,figsize=(10,10))
sns.countplot("Embarked",data=a,ax=ax[0,0])
ax[0,0].set_title("No.Of Passengers Boarded")
sns.countplot("Embarked",hue="Sex",data=a,ax=ax[0,1])
ax[0,1].set_title("Male-Female Split for Embarked")
sns.countplot("Embarked",hue="Survived",data=a,ax=ax[1,0])
ax[1,0].set_title("Embarked vs Survived")
sns.countplot("Embarked",hue="Pclass",data=a,ax=ax[1,1])
ax[1,1].set_title("Embarked vs Pclass")
plt.savefig("Task3/img/T1.jpg")
plt.show()
# ********* End *********#
泰坦尼克号生还预测
第1关:数据探索
- 以下两幅图说明了什么?
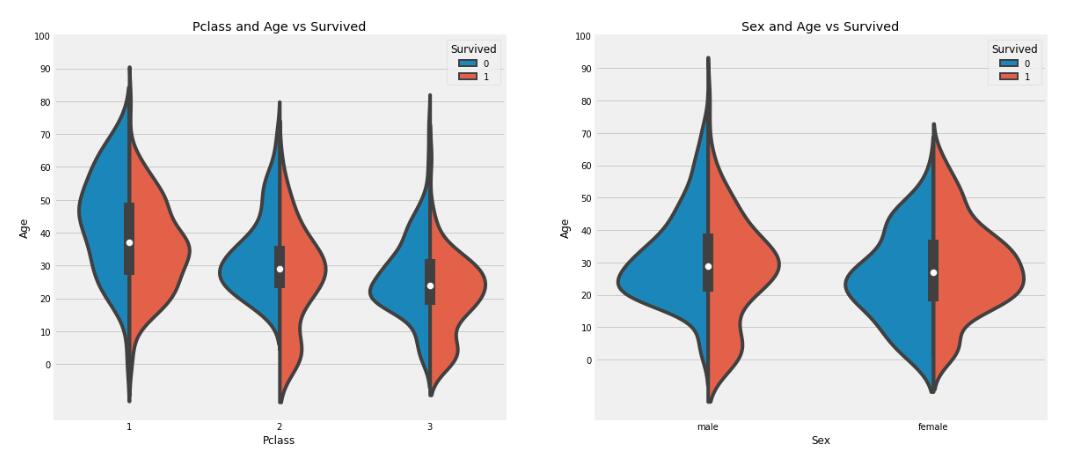
-
B、一等舱的20-50岁的人群的存活率较高
-
C、对于男性来说,越老,存活率越低
-
D、女性的生还率较高
- 这副图说明了什么?
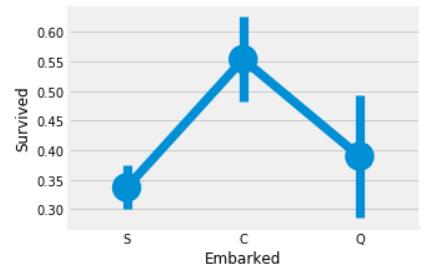
-
A、在C号口岸上船的船客的生还率高于55%
-
B、在S号口岸上船的船客的存活率最低
D、上船人数最少的是S号口岸
- 以下四幅图说明了什么?
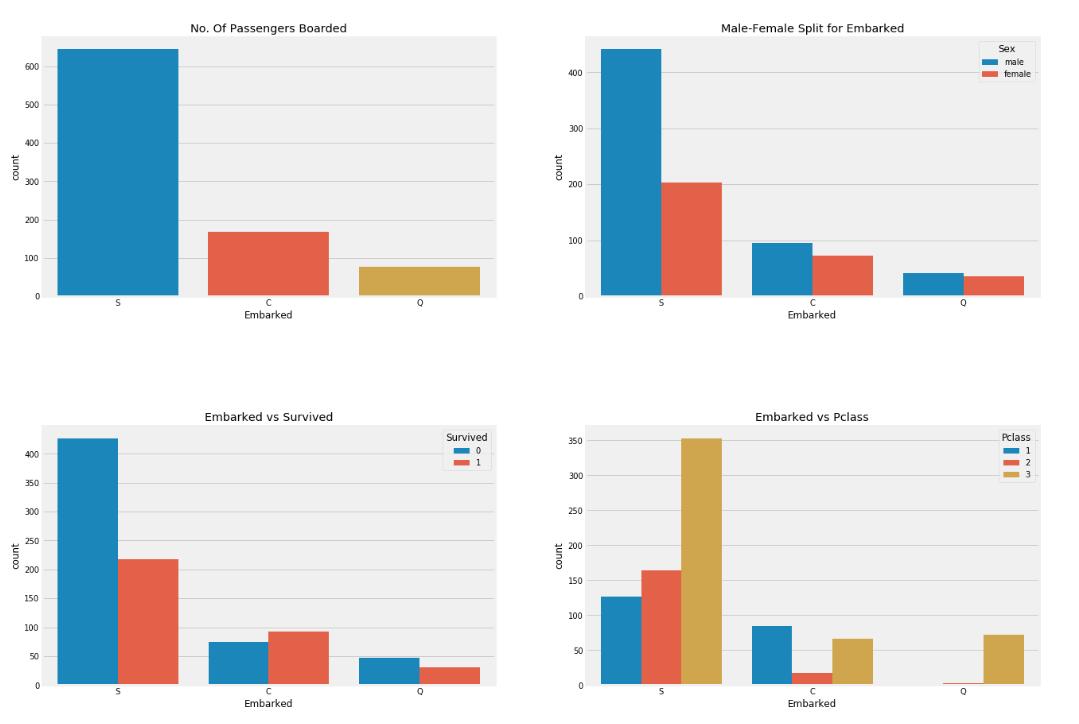
-
A、虽然有很多一等舱的土豪们基本都是在S号口岸上船的,但是S号口岸的生还率最低,可能是因为S口岸上船的人中有很多都是三等舱的船客
-
C、Q号口岸上船的人中有90%多都是三等舱的船客
-
D、在C号口岸上船的生还率最高
- 以下两幅图说明了什么
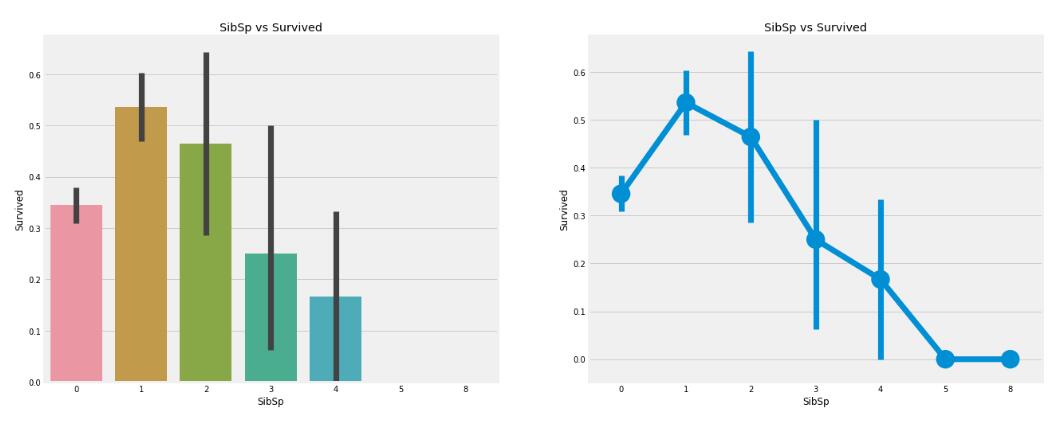
-
A、一个人在船上旅游的人的存活率约为34%
-
B、有一个兄弟姐妹或者爱人也在船上的话,生还率最高
-
C、兄弟姐妹或者爱人的数量比较多的时候,生还率呈下降趋势
第2关:填充缺失值
import pandas as pd
import numpy as np
def process_nan_value(data):
'''
处理data中缺失值,有缺失值的特征为`Age`,`Cabin`,`Embarked`。
:param data: 训练集的特征,类型为DataFrame
:return:处理好缺失值后的训练集特征,类型为DataFrame
'''
#********* Begin *********#
data['Age'].replace(np.nan,np.nanmedian(data['Age']),
inplace=True)
#data['Age'].replace(np.nan,np.nanmedian(data['Age']),inplace=True)
data.drop(labels='Cabin',axis=1,inplace=True)
data['Embarked'].replace(np.nan,'S',inplace=True)
return data
#********* End *********#
第3关:特征工程与生还预测
import pandas as pd
import numpy as np
import sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import RandomForestRegressor
#********* Begin *********#
titanic = pd.read_csv('./train.csv')
def set_missing_ages(df):
# 把已有的数值型特征取出来丢进Random Forest Regressor中
age_df = df[['Age', 'Fare', 'Parch', 'SibSp', 'Pclass']]
# 乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].values
unknown_age = age_df[age_df.Age.isnull()].values
# y即目标年龄
y = known_age[:, 0]
# X即特征属性值
X = known_age[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1::])
# 用得到的预测结果填补原缺失数据
df.loc[(df.Age.isnull()), 'Age'] = predictedAges
return df
titanic = set_missing_ages(titanic)
dummies_Embarked = pd.get_dummies(titanic['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(titanic['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(titanic['Pclass'], prefix= 'Pclass')
df = pd.concat([titanic, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
# print(df)
train_label = df['Survived']
train_titanic = df.drop('Survived', 1)
titanic_test = pd.read_csv('./test.csv')
titanic_test = set_missing_ages(titanic_test)
dummies_Embarked = pd.get_dummies(titanic_test['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(titanic_test['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(titanic_test['Pclass'], prefix= 'Pclass')
df_test = pd.concat([titanic_test,dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df_test.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
#model = RandomForestClassifier(random_state=1, n_estimators=10, min_samples_split=2, min_samples_leaf=1)
model = RandomForestClassifier(n_estimators=10)
model.fit(train_titanic, train_label)
predictions = model.predict(df_test)
result = pd.DataFrame({'Survived':predictions.astype(np.int32)})
result.to_csv("./predict.csv", index=False)
#********* End *********#