目录
一、Ansible Playbook剧本初识
1.1 Ansible Playbook 基本概述
1.1.1 什么是playbook
1.1.2 Ansible playbook 与AD-Hoc的关系
1.2 Ansible Playbook 书写格式
1.2.1安装NFS 服务
1.3 Playbook变量详解
1.3.1 使用 vars定义变量
1.3.2 使用 vars_flies定义变量
1.3.3使用Inventory定义变量
1.3.4使用 group_vars定义变量
1.3.5 使用 host_vars定义变量
1.3.6 变量层级定义方式
1.3.7 Register 变量注册
1.4 Facts变量
1.4.1 获取被控制端的主机和IP地址
2.4.2Facts自定义zabbix-Agent配置文件
2.4.3Facts自定义Memcached
1.5 Ansible-playbook控制语句
2.5.1playbook条件语句
2.5.2循环
2.5.3Handlers触发器
2.5.4Tags标签
2.5.5Include文件复用
2.5.6Ignore忽略错误
2.5.7playbook错误处理
一、Ansible Playbook剧本初识
1.1 Ansible Playbook 基本概述
1.1.1 什么是playbook
ansible 入门
playbook翻译过来就是“剧本”,playbook组成如下
- Playbook: 由一个或多个 play 组成,一个 play 可以包含多个 task 任务
- Play: 定义主机角色
- task: 定义的是具体执行的任务
总结:playboook是由一个或多个play组成,一个play可以包含多个task任务。可以理解为:使用不多的模块来共同完成意见事情。

1.1.2 Ansible playbook 与AD-Hoc的关系
- playbook是对AD-Hoc的一种编排方式
- Playbook是可以持久运行,而Ad-Hoc只能临时运行
- Playbook适合复杂的任务,而Ad-Hoc适合快速简单的任务
- Playbook能控制执行任务的先后顺序,以及互相依赖的关系
1.1.3 理解
- Playbooks 是 Ansible的配置、部署、编排语言,他们可以被描述为一个需要希望远程主机执行命令的方案,或者一组IT程序运行的命令集合
- Playbooks 与 ad-hoc相比,是一种完全不同的运用ansible的方式,是非常之强大的。
- playbooks是一种简单的配置管理系统与多机器部署系统的基础,与现有的其他系统有不同之处,且非常适合于复杂应用的部署。
- playbook是ansible用于配置,部署,和管理被控节点的剧本。
- 通过playbook的详细描述,执行其中的一系列tasks,可以让远端主机达到预期的状态。playbook就像Ansible控制器给被控节点列出的的一系列to-do-list,而被控节点必须要完成。
也可以这么理解,playbook 字面意思,即剧本,现实中由演员按照剧本表演,在Ansible中,这次由计算机进行表演,由计算机安装,部署应用,提供对外服务,以及组织计算机处理各种各样的事情
1.1.4 Ansible playbook 使用场景
- 执行一些简单的任务,使用ad-hoc命令可以方便的解决问题,但是有时一个设施过于复杂,需要大量的操作时候,执行的ad-hoc命令是不适合的,这时最好使用playbook。
- 执行批处理任务,不过playbook有自己的语法格式。
- 使用playbook你可以方便的重用这些代码,可以移植到不同的机器上面,像函数一样,最大化的利用代码。在你使用Ansible的过程中,你也会发现,你所处理的大部分操作都是编写playbook。可以把常见的应用都编写成playbook,之后管理服务器会变得十分简单。(2)
1.2 Ansible Playbook 书写格式

[root@offline-client project01]# cat p1.yml
---
- hosts: hdp
tasks:
- name: Installed Httpd Server
yum:
name: httpd
state: present
- name: Start Httpd Server
service:
name: httpd
state: started
enabled: yes
ansible-playbook --syntax-check p1.ymlansible-playbook 会检查语法错误,不会检查逻辑错误

ansible-playbook -C p1.yml 模拟执行
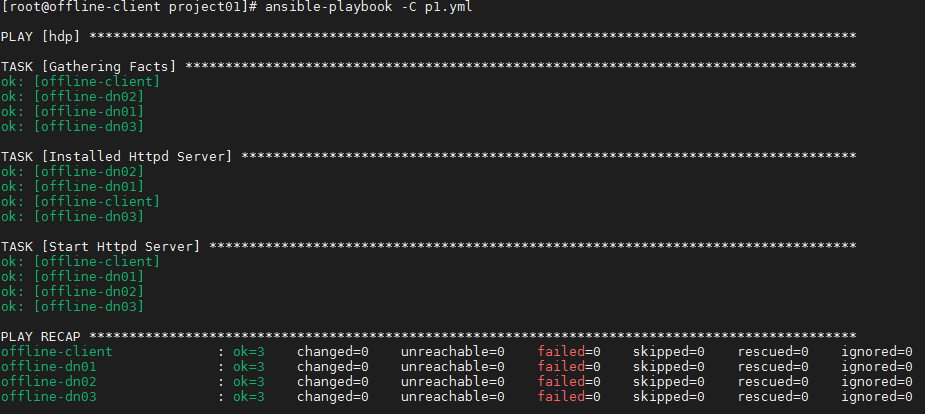
[root@offline-client project01]# cat pro1.yml
---
- hosts: hdp
tasks:
- name: Install Httpd Server
yum: name=httpd state=present
- name: Configurate Httpd Server
copy: content="I'am kangll" dest=/var/www/html/index.html
- name: Start Httpd Server
service: name=httpd state=started enabled=yes安装Apache httpd 服务并启动。访问结果如下:

[root@hdp101 ansible]# cat test-03.yml
---
# 相同的地方共同执行
- hosts: hdp
tasks:
- name: Install httpd Server
yum: name=httpd state=present
- name: Start httpd server
service: name=httpd state=started enabled=yes
- name: Start firewalld server
service: name=httpd state=started enabled=yes
# 定制化的操作单独执行
- hosts: web01
tasks:
- name: Configuration web01 website
copy: content='this is web01' dest=/var/www/html/index.html
- hosts: web02
tasks:
- name: Configuraion web02 website
copy: content='this is web03' dest=/var/www/html/index.html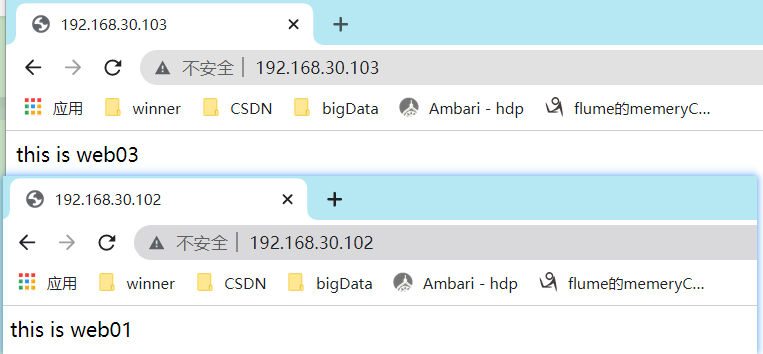
1.2.1安装NFS 服务
步骤:安装、配置、用户, 共享目录创建 /data 、启动
[root@hdp101 ansible]# cat project01.yml
---
- hosts: hdp
tasks:
- name: Install NFS-utils Server
yum: name=nfs-utils state=present
- name: Configuration NFS-utils Server
copy: src=./export.j2 dest=/etc/exports owner=root group=root mode=0644
notify: Restart NFS Server
- name: Create NFS group
group: name=www gid=666
- name: Create NFS user
user: name=www uid=666 group=www create_home=no shell=/sbin/nologin
- name: Create data directory
file: path=/data state=directory owner=www group=www mode=0755 recurse=yes
- name: Start NFS server
service: name=nfs state=started enabled=yes
handlers:
- name: Restart NFS Server
service: name=nfs state=restarted
- hosts: web01
tasks:
- name: Mount NFS Server
mount: path=/data src=hdp101:/data fstype=nfs opts=defaults state=mounted配置发生变化调用 handler restarted,如下export.j2配置NFS服务器共享。
[root@hdp101 ansible]# cat export.j2
/data 192.168.30.102(rw,sync,all_squash,anonuid=666,anongid=666) 192.168.30.103(rw,sync,all_squash,anonuid=666,anongid=666)
[root@hdp101 ansible]#运行:

数据共享目录挂载成功

1.3 Playbook变量详解
变量提供了便捷的方式来管理ansible项目中的动态值,比如 zbbix-3.4.15 ,可能后期会修改这个版本的值,那个如果将此值设置为变量,后续使用和修改将变得非常的方便,这样可以简化项目的创建和维护成本。
定义变量分为如下三种方式
- 通过命令行进行变量的定义
- 在play中进行变量变量
- 通过inventory在主机组或单个主机中设置变量
如果定义的变量出现重复,且造成冲突,有优先级如下
命令行定义的变量 > play文件定义的变量 > inventory 文件定义的变量
1.3.1 使用 vars定义变量
[root@hdp101 ansible]# cat vars01.yml
- hosts: web01
vars:
- web_package: httpd
- ftp_package: vsftpd
tasks:
- name: Installed Packages
yum:
name:
- "{{ web_package }}"
- "{{ ftp_package }}"
state: present此变量只可以在一个 play 中使用
1.3.2 使用 vars_flies定义变量
一个project 一般包含:
- ansible 配置文件
- 主机清单文件
- 变量定义文件 (play 中定义为相对路径)
[root@hdp101 project01]# cat pro01.yml
- hosts: web01
vars_files: ./vars.yml
tasks:
- name: Install Packages
yum:
name:
- "{{ web_package }}"
- "{{ ftp_package }}"
state: present
[root@hdp101 project01]# cat vars.yml
web_package: httpd
ftp_package: vsftpd
[root@hdp101 project01]#
1.3.3使用Inventory定义变量
[root@hdp101 project01]# mkdir host_vars
[root@hdp101 project01]# mkdir group_vars1.3.4使用 group_vars定义变量
ansible 的项目目录中创建额外的两个变量目录,分别是host_vars和group_vars。
group_vars 目录下必须存放和 inventory 清单文件中定义的组名一致。
注意:系统提供了特殊的组 -all,也就是说在 group_vars 目录下创建一个 all 文件,定义变零对所有的主机都生效。
[root@hdp101 project01]# cat group_vars/web01
web_package: httpd
ftp_package: vsftpd
[root@hdp101 project01]# cat pro01.yml
- hosts: web01
tasks:
- name: Install Packages
yum:
name:
- "{{ web_package }}"
- "{{ ftp_package }}"
state: present1.3.5 使用 host_vars定义变量
通用的定义在 group_vars中,定制化的变量 可以定义在host_vars中,只对特定的主机生效,host_vars定义的变量优先级高于group_vars。
[root@hdp101 project01]# cat /etc/ansible/hosts
[hdp]
hdp101 ansible_ssh_host=192.168.30.101
hdp102 ansible_ssh_host=192.168.30.102
hdp103 ansible_ssh_host=192.168.30.103
[webservers]
192.168.30.101
[web01]
192.168.30.101
[web02]
192.168.30.102
[web03]
192.168.30.103
[root@hdp101 project01]# cat group_vars/hdp
web_package: httpd
ftp_package: vsftpd
[root@hdp101 project01]# cat host_vars/hdp101
web_package: zmap
ftp_package: zlib_static
[root@hdp101 project01]#
[root@hdp101 project01]# cat pro01.yml
- hosts: hdp
tasks:
- name: Install Packages
yum:
name:
- "{{ web_package }}"
- "{{ ftp_package }}"
state: present
变量优先级:
命令行变量 ---> play中的vars_files ---> play中的vars变量 --> host_vars中定义的变量---> group_vars/组 ---> group_vars/all
通过命令行覆盖变量,inventory 的变量会被playbook文件中覆盖,这两种方式的变量会被命令行直接指定变量所覆盖。使用 --extra-vars 或 -e 设定变量。

1.3.6 变量层级定义方式
[root@hdp101 project01]# cat vars02.yml
rainbow:
web:
web_package: httpd
ftp_package: vsftpd
code:
web:
filename: code_web_filename
[root@hdp101 project01]# cat pro02.yml
- hosts: web01
vars_files: ./vars02.yml
tasks:
- name: Install Package
yum: name= {{ rainbow.web.web_package }}
- name: Create FileName
file:
path: /tmp/{{ code.web.filename }}
state: touch运行:
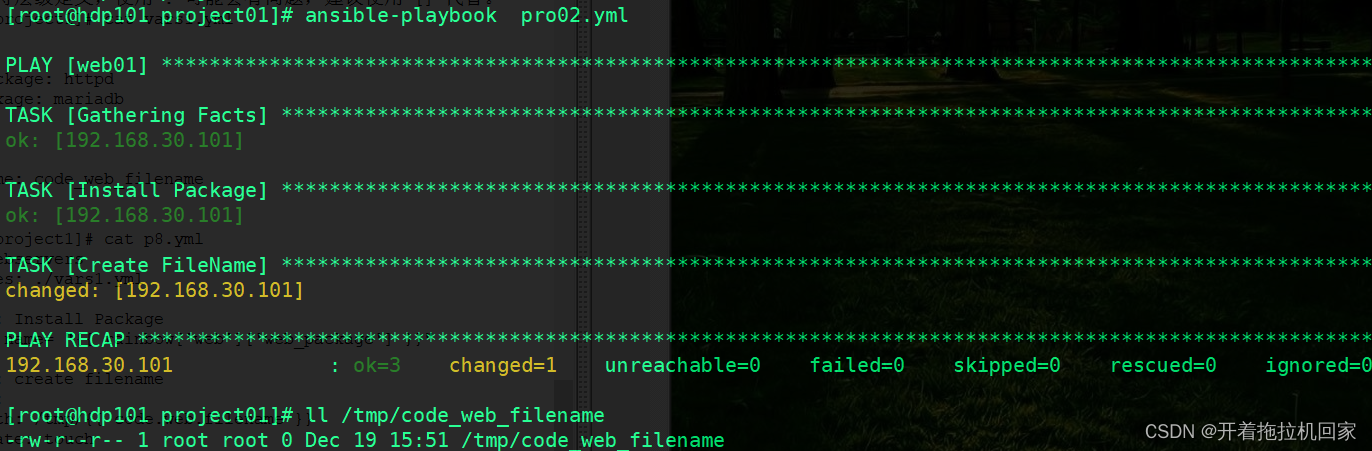
1.3.7 Register 变量注册
[root@hdp101 project01]# cat pro03.yml
- hosts: web01
tasks:
- name: Get network port status
shell: netstat -nltp
register: net_port
- name: Print network port status
debug:
msg: "{{ net_port.stdout_lines }}"1.4 Facts变量
Ansible facts 是在被管理主机上通过 ansible自动采集发现的变量。facts包含每台特定的主机信息。比如:被控制端主机的主机名、IP地址、系统版本、CPU数量、内存状态、磁盘状态等等。
fact 使用场景:
- 通过facts检查CPU、来生成对应的Nginx配置文件
- 通过facts检查主机信息,来生成不同的 zabbix等配置文件
- 通过facts检索的内存情况来自定义MySQL的配置文件
1.4.1 获取被控制端的主机和IP地址
ansible 使用 setup模块获取被控端主机信息拉取到控制端。

2.4.2Facts自定义zabbix-Agent配置文件
/hadoop/ansible/project01
[root@hdp101 project01]# cat facts.yml
---
- hosts: hdp
vars:
- zabbix_server: hdp101
tasks:
- name: Copy Zabbix Agent Configuration
template: src=./zabbix_agentd.conf dest=/root/zabbix_agent.conf
[root@hdp101 project01]#我们来到hdp102验证zabbix_agent.conf文件是否已经修改

2.4.3Facts自定义Memcached
[root@hdp101 project01]# yum install memcached -y
[root@hdp101 project01]# rpm -qc memcached
/etc/sysconfig/memcached
1.5 Ansible-playbook控制语句
2.5.1playbook条件语句
判断在Ansible 任务中使用频率非常高。比如 yum模块可以检测软件包是否已经安装,而在这个过程中我们不用做太多的人工干预。但是也有部分任务需要进行判断,比如:web服务器角色都需要安装nginx仓库,但其他的服务器角色并不需要,此时就会用到 when 判断。
比如:CentOS 与Ubuntu系统都需要安装httpd服务,那么就需要使用 when判断主机系统,然后调用不同的模块执行。
实践案例一、根据不同操作系统,安装相同的软件包
[root@hdp101 control]# cat when01.yml
---
- hosts: hdp
tasks:
- name: Install httpd Server
yum: name=httpd state=present
when: ansible_distribution == "CentOS"
- name: Install httpd Server
apt: name=htt2 state=present
when: ansible_distribution == "Ubuntu"运行结果:

实践案例二、所有为 web主机名的添加 nginx仓库,其余的都跳过添加
若要将字符串与子字符串或正则表达式匹配,请使用「match」、「search」或「regex」过滤。
- match:必须有开头匹配
- search:子串匹配
- regex:正则匹配
[root@hdp101 control]# cat when02.yml
---
- hosts: hdp
tasks:
- name: Add Nginx repo
yum_repository:
name: nginx_tet
description: Nginx yum repo
baseurl: http://nginx.org/packages/centos/7/$basearch/
gpgcheck: no
when: (ansible_hostname is regex("hdp*")) or (ansible_hostname is regex("hdp*"))匹配主机名是以hdp开头的

repo文件在路径:/etc/yum.repos.d/ 添加成功

2.5.2循环
有时候我们写playbook 的时候发现了很多task都要重复引用某个模块,比如一次性启动10个服务,或者一次拷贝10个文件,如果按照传统的写法我们需要多次启动,这样会显得 playbook很臃肿。如果使用循环的方式来编写playbook ,这样可以减少重复使用某个模块。
实践案例一、使用循环启动多个服务
1.在没有使用循环的场景下,启动多个服务需要写多条tasksr任务。
[root@hdp101 circu]# cat item01.yml
---
- hosts: web01
tasks:
- name: Start httpd service
service: name={{ item }} state=started
with_items:
- httpd
- vsftpd实践案例二、定义变量方式循环安装软件包
[root@hdp101 circu]# cat item02.yml
---
- hosts: web01
tasks:
- name: define a list of package installed
yum: name= {{ packages }} state=present
vars:
packages:
- httpd
- vsftpd
[root@hdp101 circu]#实践案例三、使用字典循环方式创建用户和批量拷贝文件
[root@hdp101 circu]# cat loop-user.yml
---
- hosts: web01
tasks:
- name: Add user
user: name={{ item.name }} groups={{ item.groups }} state=present
with_items:
- { name: 'kangll', groups: 'hadoop' }
- { name: 'winner',groups: 'zookeeper' }
- name: Copy Rsync configuration and passwd
copy: src={{ item.src }} dest={{ item.dest }} mode={{ item.mode }}
with_items:
- { src: './rsync.conf', dest: '/root/rsync.conf', mode: '0644' }
- { src: './rsync.passwd', dest: '/root/rsync.paswd', mode: '0644'}运行:

2.5.3Handlers触发器
[root@hdp101 ansible]# cat handler01.yml
---
- hosts: web01
tasks:
- name: Install Http Server
yum: name=httpd state=present
# 修改80端口,触发handler
- name: configuration httpd server
template: src=./httpd.conf dest=/etc/httpd/conf/httpd.conf
notify:
- Restart Httpd Server
- name: start httpd server
service: name=httpd state=started enabled=yes
handlers:
- name: Restart Httpd Server
service: name=httpd state=restartedhandler注意事项
1.无论多少个task通知了相同的handlers,handlers仅会在所有tasks结束后运行一次。
2.只有task 发生改变了才会通知handlers,没有改变则不会触发handlers
3.不能使用 handlers替代 tasks
2.5.4Tags标签
默认情况下,Ansible在执行一个 playbook时,会执行 playbook中定义的所有任务。Ansible的标签(Tags) 功能可以给单独任务甚至整个 playbook 打上标签,然后利用利用这些标签指定要运行的playbook中的某些任务,或不执行某个任务其余的都执行。
1.打标签的方式有几种,比如:
对一个 task打一个标签、对一个task打多个标签、对多个task打一个标签
2.对task 打完标签应该如何使用
-t: 执行指定的 tag 标签任务
--skip-tags: 执行 --skip-tags之外的标签任务
案例一、使用 -t 指定tags执行
用于调试 或运行指定的模块

2.5.5Include文件复用


2.5.6Ignore忽略错误
默认 playbook 会检查tasks执行的返回状态,如果遇到错误则会立即终止 Playbook 的后续tasks执行。然而有些时候 我们希望 playbook即使执行报错也要让它继续执行
加入参数:ignore_errors: yes 忽略参数
编写playbook ,当有 task执行失败则会立即执行后续task 运行
---
- hosts: web01
tasks:
- name: Ignore False
command: /bin/false
ignore_errors: yes # 忽略错误 继续执行
- name: touch new file
file: path=/tmp/bgx_ignore state=touch运行:

2.5.7playbook错误处理
通过情况下,当 task 失败后,play将会终止,任何在前面已经被tasks notify 的handlers都不会被执行。如果在play 中设置了 force_handlers:yes 参数,被通知的handlers就会被强制执行。
案例一、task执行失败强制调用 handlers
---
- hosts: web
vars:
- http_port: 8088
force_handlers: yes # 强制触发handler
tasks:
- name: configure httpd server
template: src=./httpd.conf.j2 dest=/etc/httpd/conf/httpd.conf
notify: Restart Httpd Server
- name: Install httpd server
yum: name=kangll state=present ## 报错
- name: Start httpd server
service: name=httpd state=started enabled=yes
handlers:
- name: Restart Httpd Server
systemd: name=httpd state=restarted运行:
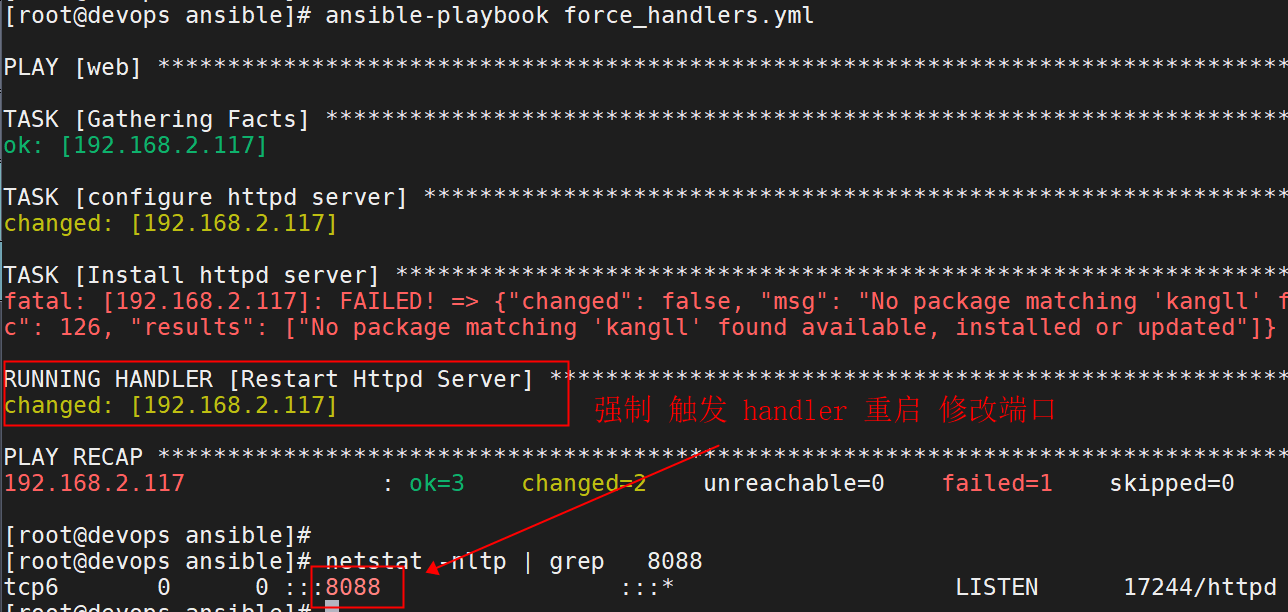
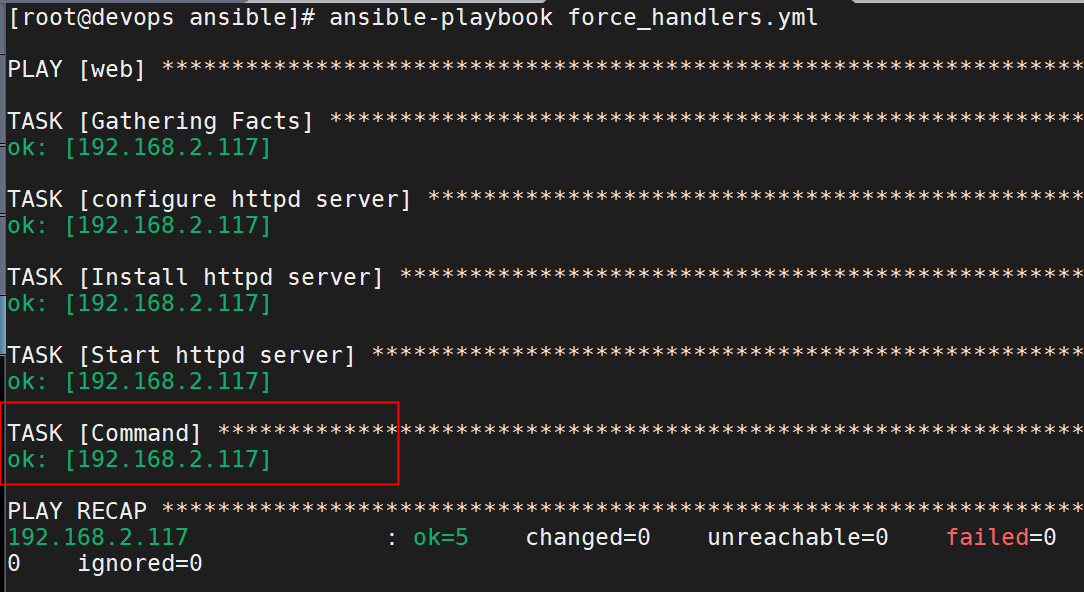
案例二、控制task报告的状态,不一定必须是“changed”
shell任务不应该每次都报告 changed状态,因为它没有在被管理主机执行后发生变化。添加一行
changed_when: false 来抑制这个改变。
---
- hosts: web
vars:
- http_port: 8088
force_handlers: yes # 强制触发handler
tasks:
- name: configure httpd server
template: src=./httpd.conf.j2 dest=/etc/httpd/conf/httpd.conf
notify: Restart Httpd Server
- name: Install httpd server
yum: name=httpd state=present
- name: Start httpd server
service: name=httpd state=started enabled=yes
- name: Command
shell: netstat -nltp | grep httpd
register: check_httpd
changed_when: false # 被管理主机没有发生变化,可以使用参数将change状态改为ok
handlers:
- name: Restart Httpd Server
systemd: name=httpd state=restarted
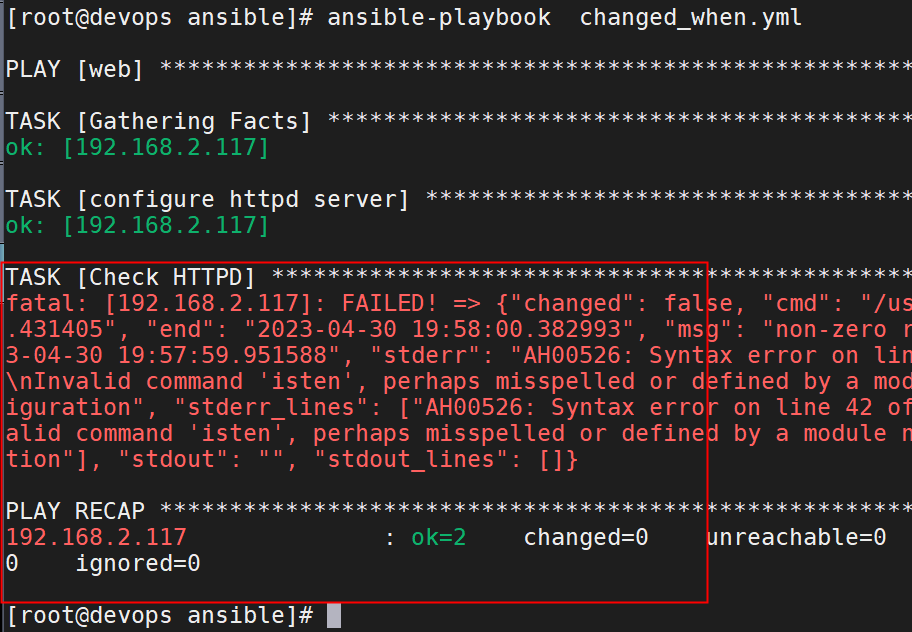
运行:
changed_when.yml
- hosts: web
vars:
- http_port: 8083
tasks:
- name: configure httpd server
template: src=./httpd.conf.j2 dest=/etc/httpd/conf/httpd.conf
notify: Restart Httpd Server
- name: Check HTTPD
shell: /usr/sbin/httpd -t
register: httpd_check
changed_when:
- httpd_check.stdout.find('OK')
- false
- name: start httpd server
service: name=httpd state=started enabled=yes
handlers:
- name: Restart Httpd Server
systemd: name=httpd state=restarted正常重启

配置错误检查,配置文件检查出错后handler不执行: