1.三种路由和各自的比较
2.配置文件所有的字母必须大写
3.if __name__的作用
4.核心对象循环引用的几种解决方式–难
5.Flask的经典错误
6.上下文管理器
7.flask的多线程和线程隔离
三种路由
方法1:装饰器 python C#, java 都可以用这种方式
from flask import Flask
app = Flask(__name__)
@app.route('/hello')
def hello():
return 'Hello world!'
app.run(debug=True)
方法2: 注册路由 php python
from flask import Flask
app = Flask(__name__)
//@app.route('/hello')
def hello():
return 'Hello world!'
app.add_url_rule('/hello', view_func=hello)
app.run(debug=True)
方法3:python 特有的规则
from flask.views import View, MethodView
from flask import Flask, render_template, request
app = Flask(__name__)
class MyView(MethodView):
def get(self):
return render_template('index.html')
def post(self):
username = request.form.get('username')
password = request.form.get('password')
if username == "gp" and password == "mypassword":
return '密码正确'
else:
return '密码错误'
app.add_url_rule('/', endpoint='login', view_func=MyView.as_view('login'))
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000)
它的过程是通过View的as_view -> MethodView中的dispatch_request -> 具体的get、post等方法。
看一看flask 是如何实现的
class View:
methods: t.Optional[t.List[str]] = None
provide_automatic_options: t.Optional[bool] = None
decorators: t.List[t.Callable] = []
def dispatch_request(self) -> ResponseReturnValue:
raise NotImplementedError()
@classmethod
def as_view(
cls, name: str, *class_args: t.Any, **class_kwargs: t.Any
) -> t.Callable:
def view(*args: t.Any, **kwargs: t.Any) -> ResponseReturnValue:
self = view.view_class(*class_args, **class_kwargs) # type: ignore
return current_app.ensure_sync(self.dispatch_request)(*args, **kwargs)
if cls.decorators:
view.__name__ = name
view.__module__ = cls.__module__
for decorator in cls.decorators:
view = decorator(view)
view.view_class = cls # type: ignore
view.__name__ = name
view.__doc__ = cls.__doc__
view.__module__ = cls.__module__
view.methods = cls.methods # type: ignore
view.provide_automatic_options = cls.provide_automatic_options # type: ignore
return view
实际上flask通过as_view方法,返回一个函数,这个函数就是我们需要绑定的视图函数,实现由类到函数的变化过程。
通过把cls绑定到view函数的view_class属性上面,实现view.view_class(*class_args, **class_kwargs)
来达到传递参数的目的,这正是python魅力之所在。就是用的闭包,或者装饰器了。和第一种方法类型,不过一个显示,一个隐式而已。
配置文件所有的字母必须大写
开发环境和测试环境以及生成环境的参数不同,那么如何区分这三个环境呢,if else 获取不一样的环境? 不是的,应该让三个环境相近,而使用配置文件将他们分开, 然后 设置 git ignore, 各自走各自的配置文件
在项目根路径下设置config.py
DEBUG=True
在面的启动文件
app = Flask(__name__)
# 加载配置项
app.config.from_object("config")
# 读取
app.config["DEBUG"]
注意flask 规定,只能用全大写,否则key error
if __name__的作用
是入口文件,增加了这个判断,能够确保入口文件里面的代码只在入口文件执行。
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000)
手动启动很好理解,因为他做了入口。
但是生产环境下是nginx+uwsgi,它是被uwsgi所加载的模块。入口文件变成了uwsgi,此时如果没有 if __name__的判断,会使web服务器启动两遍。一个是uwsgi的,一个是 开发中的python入口文件的,flask的内置服务器。
视图函数的return和普通函数的return有什么区别么?
有,不是一个简单的普通函数的return,是返回了一个response的响应对象。
视图函数,不会只返回类似 helloworld的字符串,
而是返回包含 status code 200,404, 301, content-type http headers,默认text/html
以及return的文本。
它等于
@app.route('/hello')
def hello():
return 'helloworld'
@app.route('/hello')
def hello():
return '<html></html>'
@app.route('/hello')
def hello():
headers = {
'content-type':'text/plain'
}
response = make_response('<html></html>',200)
response.headers=headers
return response
最后一个会解析出html 因为他当成 text/plain 普通文本,而不是html文本了。
@app.route('/hello')
def hello():
return '<html></html>', 301,headers
它等价于这个,flask 还是给返回了response对象。
解决核心对象重复引用
在flask中,将app的核心对象和注册路由写在同一个文件中是非常不好的体验
from flask import Flask
app = Flask(__name__)
@app.route('/hello')
def hello():
return 'Hello world!'
app.run(debug=True)
只有1,2个路由是没问题的,可是,当有上百个路由的时候,而且开发者10个人同时在开发,大家都修改这一个入口文件,会造成很差的体验。
所以我们需要可以拆分路由,那么如何才能拆分呢?
可以add_url 的方式手动注册,但这种并不优雅。
我认为有两种比较好的
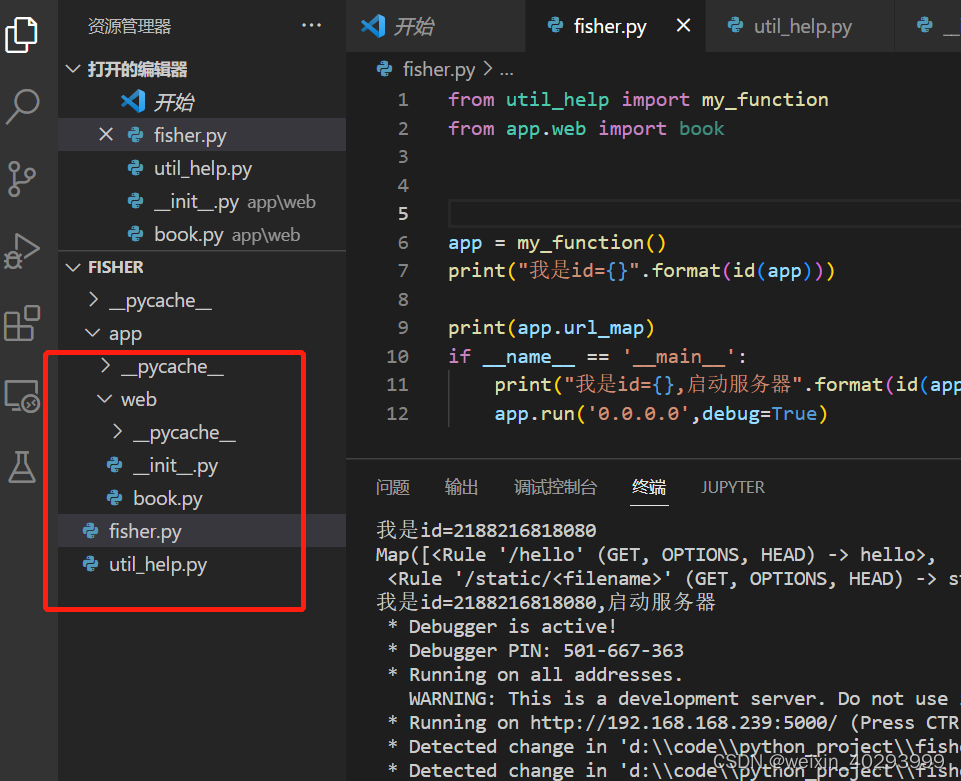
方式1: 保持核心对象app 只有一个,在util_help.py中定义一个函数,
from flask import Flask
def my_function():
# 定义静态变量
if not hasattr(my_function, "my_static_variable"):
my_function.my_static_variable = Flask(__name__)
return my_function.my_static_variable
谁用到app对象都去这里满拿,因为是定义了静态变量,所以,是独一份的,不会随着包引用构建多次. 注册路由是没问题的.
方式2: 通常情况会出现循环引用,因为入口文件会引入 app.web.book 文件, 而book文件又会去入口文件引入app, 造成两个app, 在book文件中的app对象,注册了路由函数,但不是入口文件的app对象.这个时候,蓝图就起作用了.
Flask的经典错误
working outside application context
AppContext, RequestContext, Flask与Request直接的关系.
应用上下文 对象 Flask
请求上下文 对象 Request
Flask AppContext
Request RequestContext
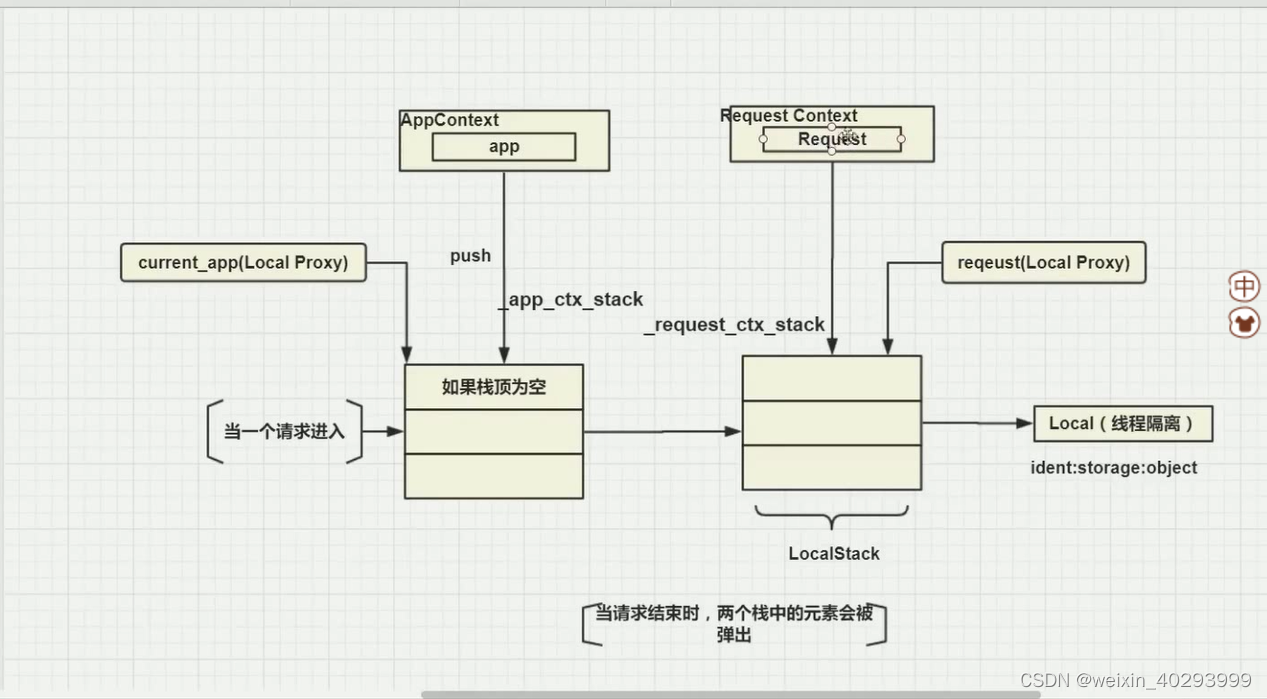
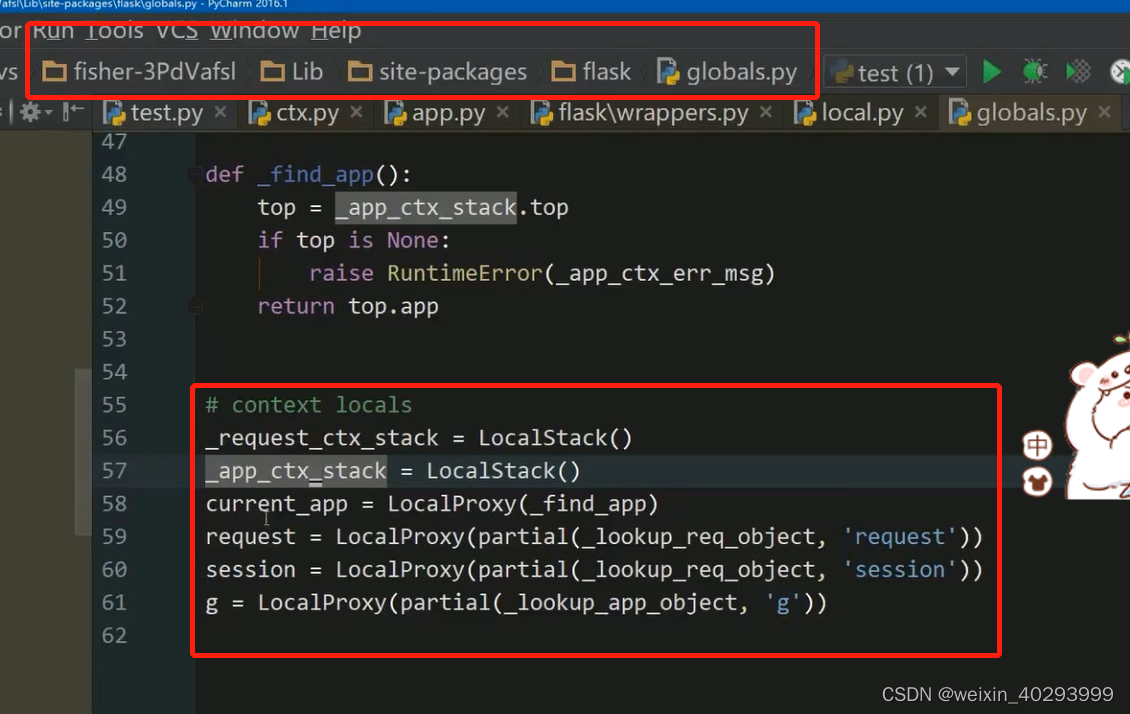
做上下文管理的源码!
用这两句把current_app 推进占
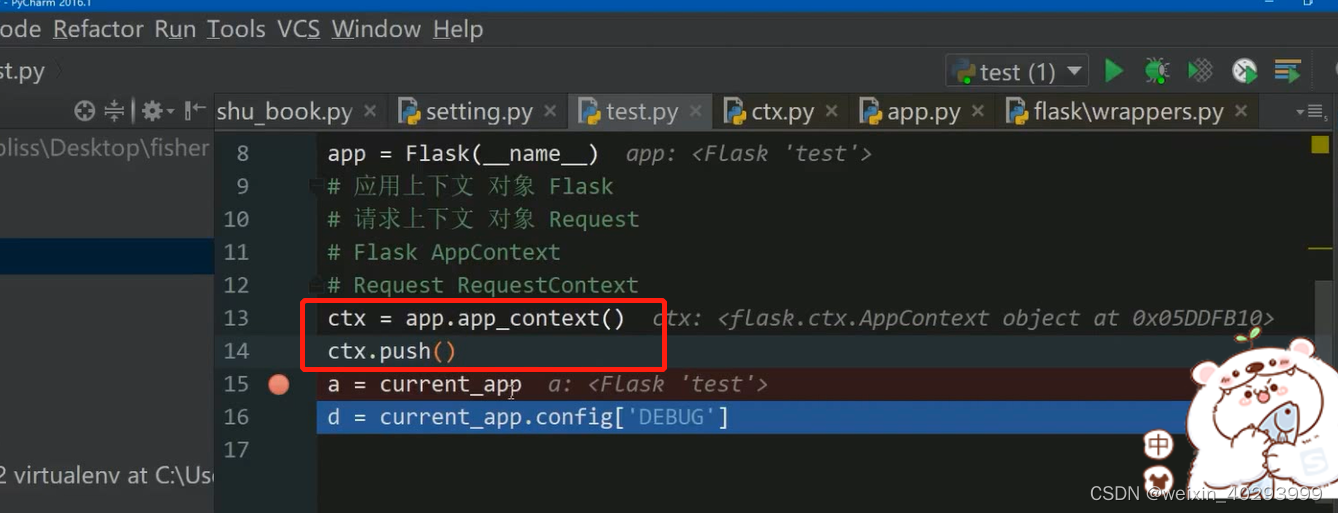
上下文管理的逻辑使用场景:
数据库:
1.连接数据库
2.执行sql
3.释放资源
解决方法1:
try
…
except
…
finall
…
解决方法2:
with 语句, 可以对比 whith open() as f:
…
文件读写:
try:
f = open(r"D:/t.txt")
print(f.read())
finally:
f.close()
with open(r"D:/t.txt") as f:
print(f.read())
只要实现了__enter__ 和 __exit__方法就是上下文管理器.
class A:
def __enter__(self):
a = 1
def __exit__(self,exc_type, exc_value, tb):
if tb:
print("process exception")
else:
print('no exception')
b = 2
return True
# 或者返回 False, 代表异常还需要接着抛出去,
# True 异常里面出来,外面不抛出异常
# 什么都不返回 和False 的逻辑一致
with A() as obj_A:
pass
现在的 obj_A 是 None
as 返回的不是上下文管理器,而是 enter方法返回的值.
with 语句包裹的变量值是有值的, 运行exit之后,就没值了.因为分别执行了 push 和pop,
push 就是把变量放进去, pop 就弹出来了.
flask的多线程和线程隔离
资源是稀缺的,计算机资源 竞争计算机资源
进程 至少由1个进程, 进程是竞争计算机的基本单位
单核cpu, 永远只能执行一个应用程序?
再不同的应用程序之间切换
进程调度 切换到另外一个进程 操作系统原理
进程/线程 开销是非常大 上下文
线程是进程的一部分 1个线程 多个线程
cpu 颗粒度太大了 更小的单元 cpu的资源
线程
进程 分配资源 内存资源
线程 利用cpu执行代码
代码 指令 cpu来执行 原料
线程不能够拥有资源,但 线程属于进程,可以访问进程资源
主线程
def worker():
print("i am thread")
t = threading.current_thread()
print(t.get.getName())
import threading
print("i am 7 月")
t = threading.current_thread()
print(t.getName())
new_t = threading.Thread(target=work)
线程名字可以改变。
多线程是为了更加充分的利用cpu的性能优势。
异步变成
单核cpu
4核心 A核 B核 并行的执行顺序
python不能充分利用多核cpu的优势,这句话是对的。因为python有GIL 全局解释器锁 global interpreter lock
python的多线程是鸡肋? 不是的。IO密集的是有用的。
锁 是为了负责线程安全
细小粒度的锁, 解释器 GIL 多核cpu 1个线程执行,一定程度上保证线程安全
a+=1
bytecode
python 多线程到底是不是鸡肋
python 有GIL, 是在字节码bytecode基础上的单线程。
node,js 是单进程单线程的。
CPU密集型的程序,多线程就是垃圾,鸡肋
IO密集型的程序,查询数据库,请求网络资源,读写文件。那么python的多线程是有意义的。
flask web框架 和客户端请求的关系
框架代码/webserver/自己写的代码 要区分开
Java PHP nginx Apache Tomcat IIS
app.run 是启动了一个flask 内置的webserver
真实环境下,不用flask自带的,因为默认情况下它是单进程单线程的形式提供服务的。在开发阶段是可以的,方便调试,真正部署的时候不用它。实际上,flask 自带的服务器也可以开启自带的多线程模型, 可以开启单线程多进程, 也可以开启多进程,多线程模型。
app.run(host='0.0.0.0', debug=True, port=81,threaded=True,)
process默认是1,也可以开启多进程,也是一个参数。
对于一个接口,实际请求不同,如何保证返回的结果是隔离的。
比如用户a, 是访问 作者是金庸 page=1的书目列表。。用户b是另外一个。
那么,实例化的request请求信息是如何隔离的?
在单线程下是排队的,没问题。但是多线程下如何做到的呢?
答案: 线程隔离技术
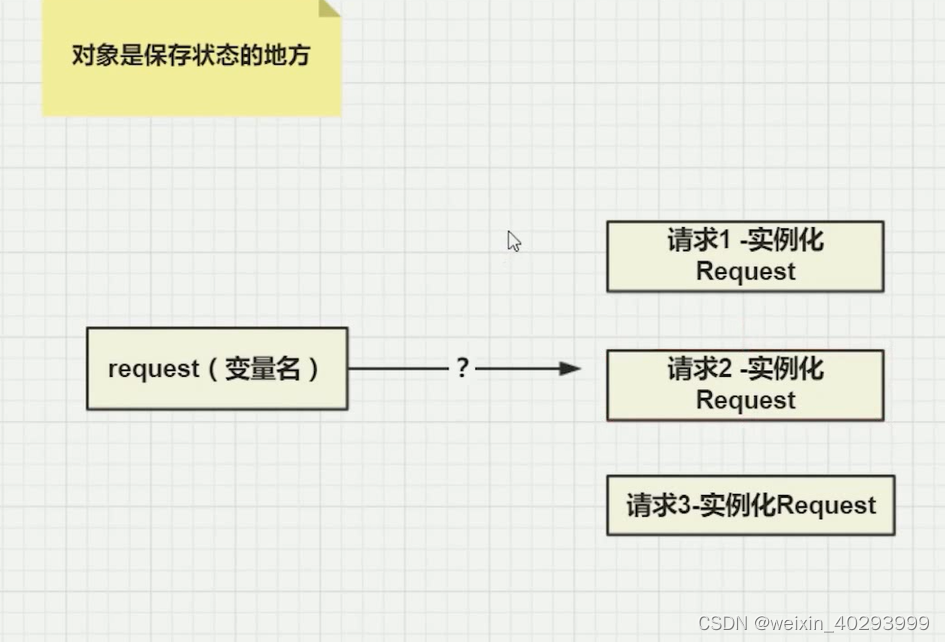
一个变量名,指向了多个实例化的Request,这个问题如何解决。
import threading
request = None
request1 = Request()
request2 = Request()
request3 = Request()
## python 字典 php 数组
request = {
key1:v1
k2:v2
k3:v3
}
所以用线程的标识 作为key,文件就解决了。
request = {
thread_key1:v1
thread_key2:v2
thread_key3:v3
}
用字典这种基本的数据结构,来完成线程隔离。
flask是借助werkzeug 下面的local模块的Local对象来完成的。
local对象的本质就是用字典的方式来解决的。
追一下源码:
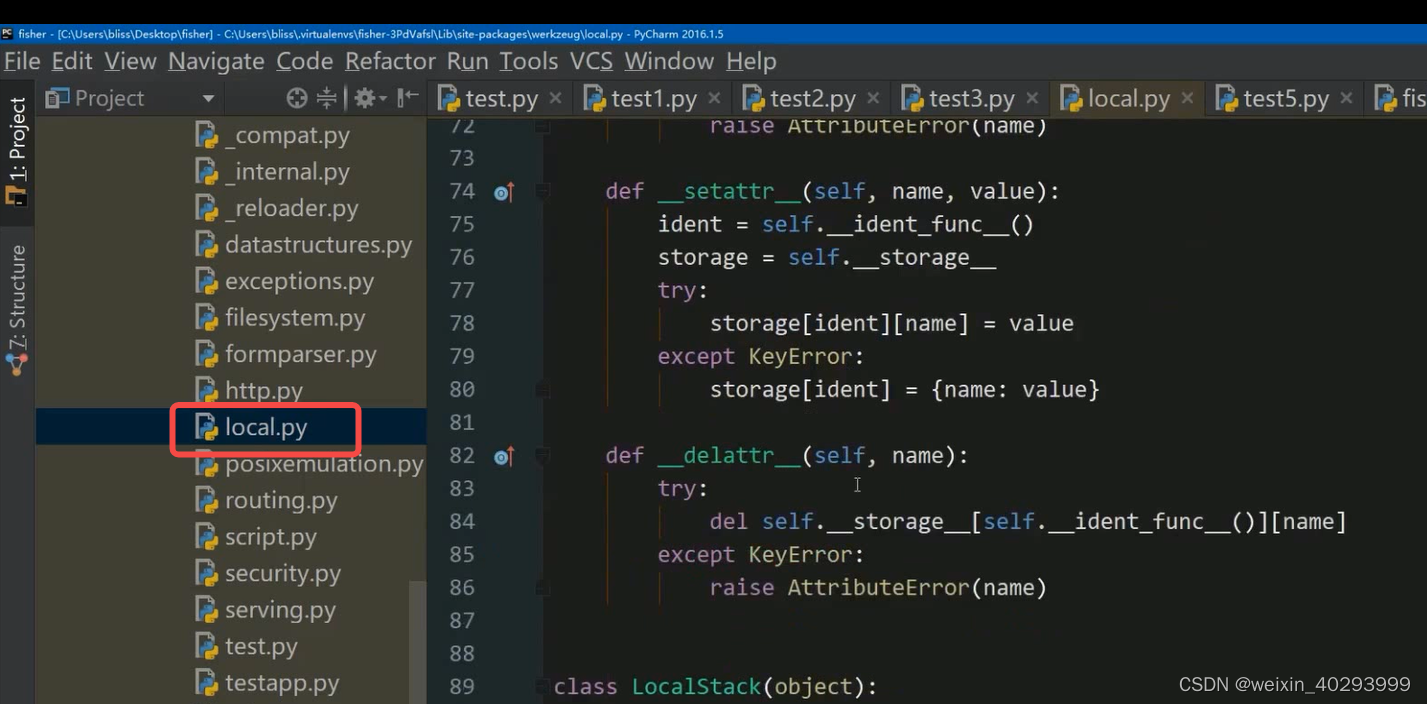
取当前线程的id号
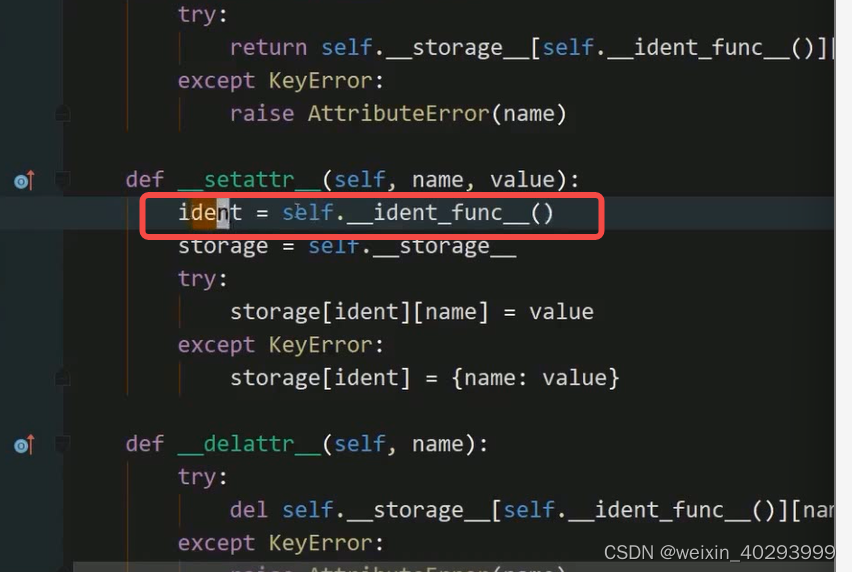
Local对象
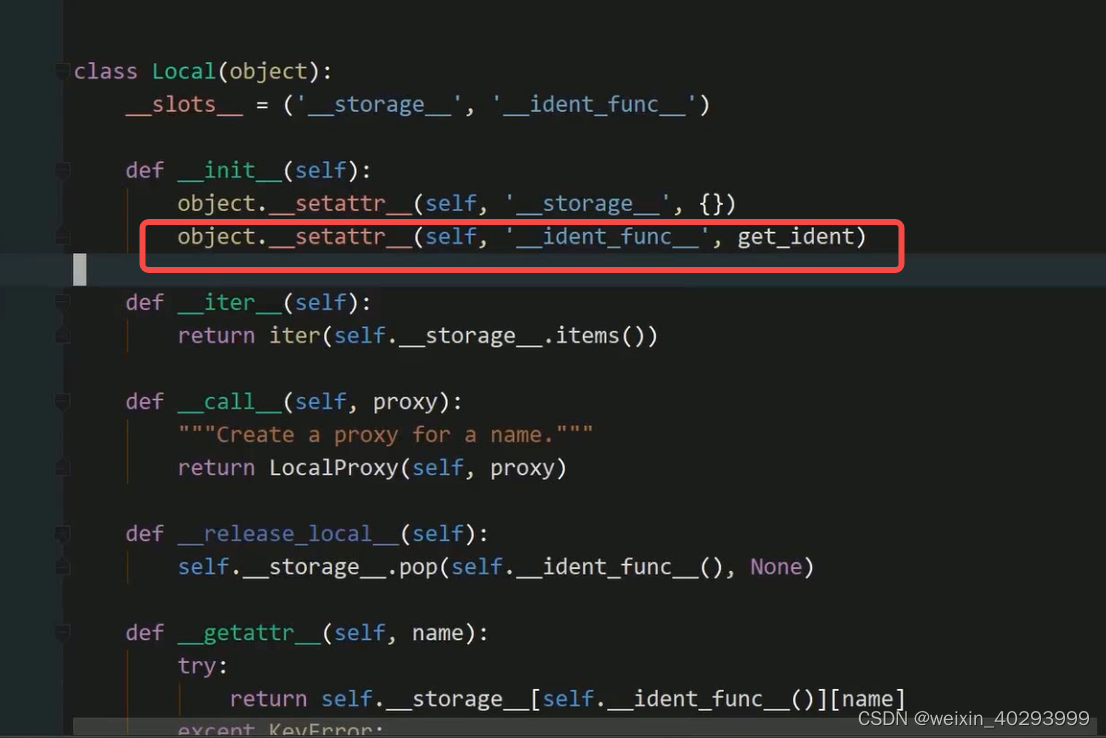
如何在当前线程,通过线程id号,拿到线程的值?
L 线程隔离的对象
t1 L.a 和 t2 L.a 是完全隔离的,互不干扰
这个Local对象不一定非要在flask下使用,还可以自己使用.
class A:
b = 1
my_obj = Local()
def worker():
#新线程
my_obj.b = 2
new_t = threading.Thread(target=work)
new_t.start()
time.sleep(1)
from werkzeug.local import Local
my_obj = Local()
my_obj.b = 1
def worker():
#新线程
my_obj.b = 2
print("in new thread b is :"+ str(my_obj.b))
new_t = threading.Thread(target=work)
new_t.start()
time.sleep(1)
print("in main thread b is :"+ str(my_obj.b))
Local, LocalStack 和字典的关系
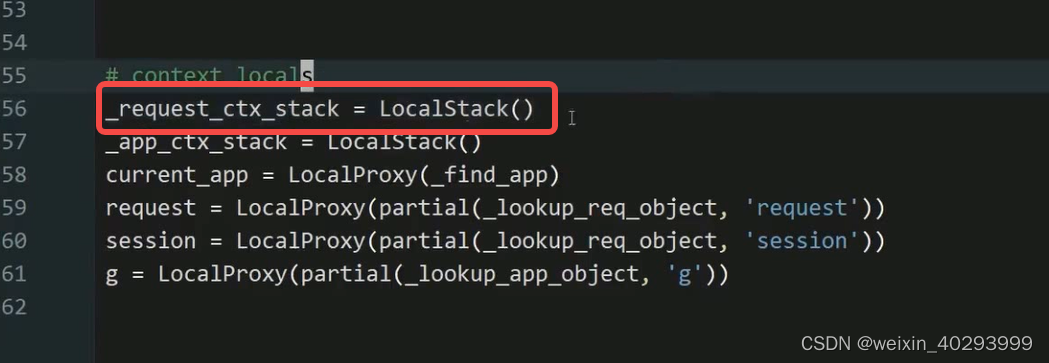
LocalStack的核心方法 push/pop和top,继承自 localStack的核心属性local就是Local()的对象.
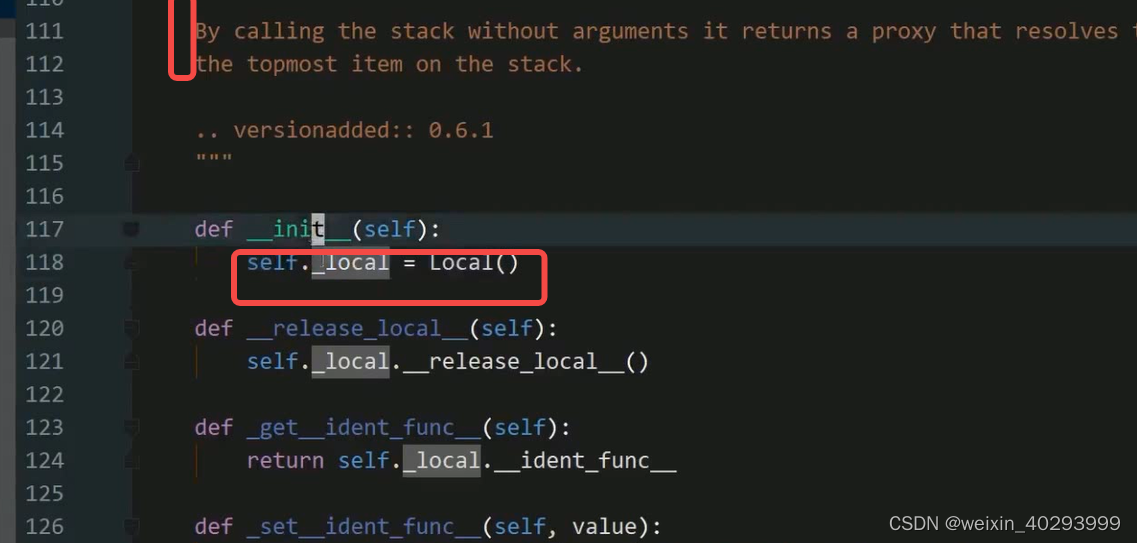
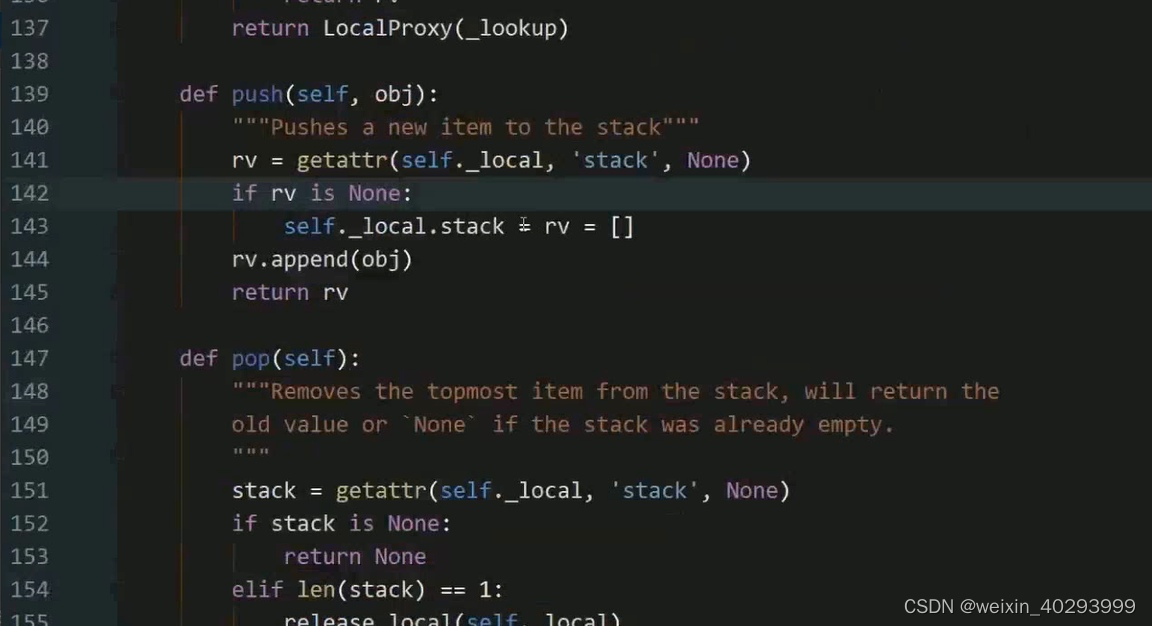
Local使用字典的方式实现现场隔离,localstack是线程隔离的栈结构.
LocalStack的基础用法
以下讲解体现了LocalStack 作为stack的特性的用法.
from werkzeug.local import LocalStack
# 重点是要实现push, pop和top
s = LocalStack()
s.push(1)
s.top # 读取栈顶元素,但不会删除, 需要注意点是,以属性的形式读取的,不需要加括号
s.pop() # 获取并且弹出栈顶
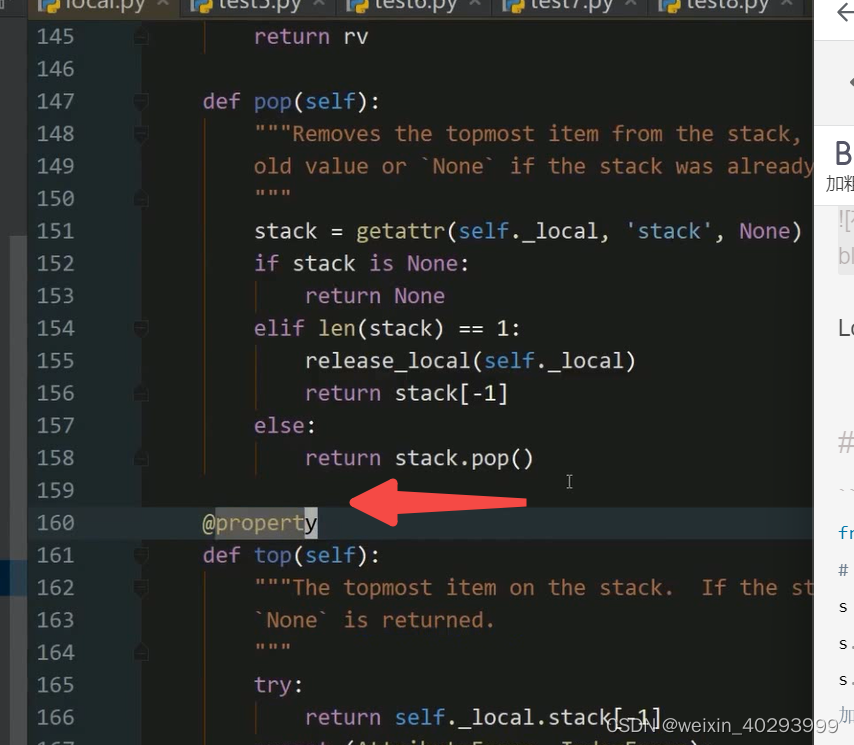
而且栈是后进先出.
以下讲解体现了LocalStack 作为Local的特性的用法.
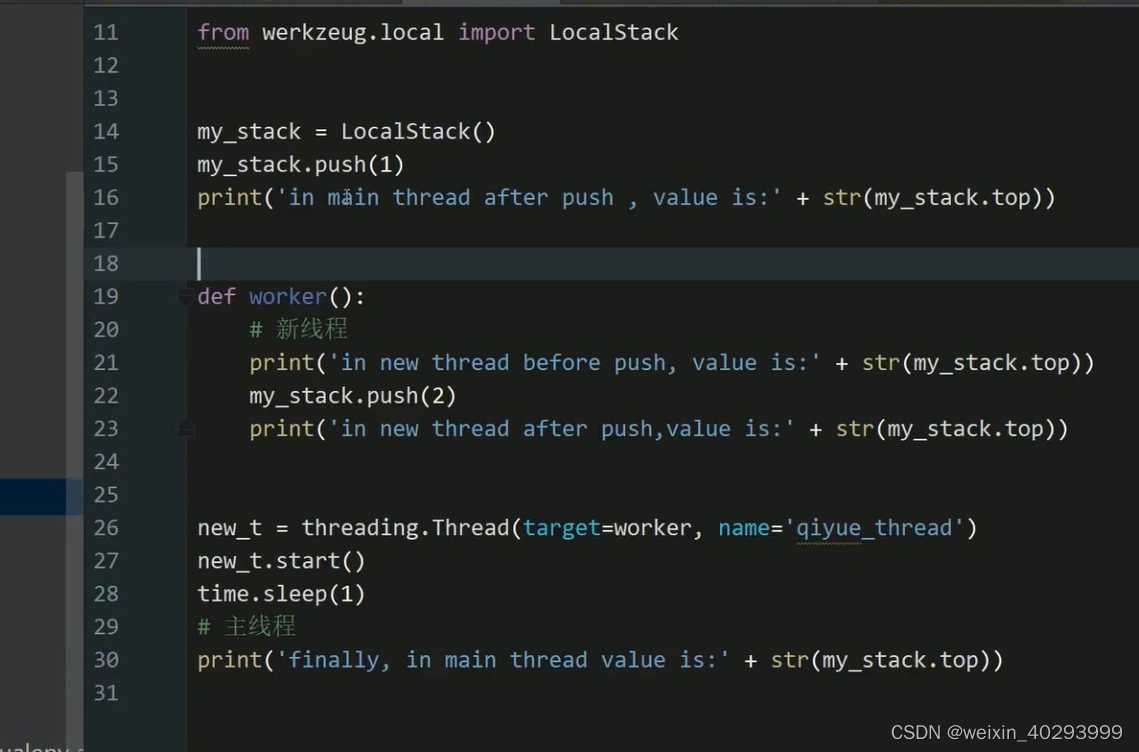
from werkzeug.local import LocalStack
my_stack = LocalStack()
my_Stack.push(1)
print("in main thread after push, value is:"+ str(my_stack.pop))
def worker():
# 新线程
print("in main thread after push, value is:"+ str(my_stack.pop))
my_Stack.push(2)
print("in main thread after push, value is:"+ str(my_stack.pop))
new_t = threading.Thread(target=work)
new_t.start()
time.sleep(1)
print("in main thread b is :"+ str(my_Stack.top))
打印结果:

之前知道localstack的这个特性就好了,当时手写多进程那么辛苦~~~~解决 显卡不足的问题.