文章目录
- **1 概述**
- **2.1 程序进程内的调用:函数调用**
- **2.2 程序进程间的调用:IPC**
- **2.3 远程程序调用:RPC**
- **2.4 远程调用REST**
- **3 硬件“调用”**
- **3.1 综述**
- **总线模型**
- **3.2 片内的总线**
- **3.3 Chiplet多DIE封装互联总线**
- **3.4 板级总线**
- **3.5 数据中心高速网络**
- **4 软硬件之间的调用**
- **4.1 生产者消费者模型**
- **4.2 软硬件的接口定义**
- **4.3 软硬件接口演进**
- **4.4 软硬件接口的范例:NVMe**
- **4.5 基于接口的调用**
- **5 总结**
已剪辑自: 链接
1 概述
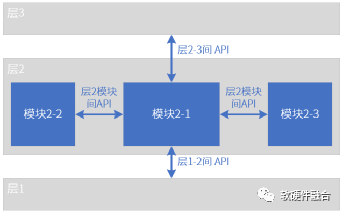
图1 分层的API调用
通常,如图1,一个复杂的系统都是分层的:
- 每个层通过API调用下一层提供的服务;
- l同时通过API被调用为上一层提供服务;
- 同一层模块间也相互通过被调用向对方提供服务;
- 模块的功能封装在模块内部,对外只有调用或被调用的API接口。
调用,是软硬件系统设计的基础。通过不同层次的模块间的调用,把各自不同的简单的模块,连接成一个庞大而复杂的整体系统。
2 软件调用
2.1 程序进程内的调用:函数调用
在高级语言编程里,如果我们把一个函数当做一个“模块”的话,那么从一个“模块”调用另一个“模块”就是我们通常非常熟悉的函数调用。
在x86的计算机系统中,一切的函数调用都要将不同的数据、地址压入或者弹出栈。我们直接通过实例来看函数是如何调用的。我们先来看看此时的栈是什么样的:
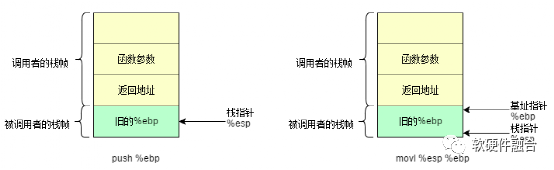
图2 被调用者栈帧的生成
此时调用者做了两件事情:
- 将被调用函数的参数按照从右到左的顺序压入栈中;
- 将返回地址压入栈中。
被调用者也做了两件事情:
- 将调用者的%ebp 压入栈,此时 %esp 指向它。
- 第二,将 %esp 的值赋给 %ebp, %ebp 就有了新的值,它也指向存放老 %ebp 的栈空间。
这时,它成了是函数 MyFunction() 栈帧的栈底。这样,我们就保存了“调用者”函数的 %ebp,并且建立了一个新的栈帧。
下面的操作就好理解了。在 %ebp 更新后,我们先分配一块0x12字节的空间用于存放本地变量,这步一般都是用 sub 或者 mov 指令实现。在这里使用的是 movl。通过使用 mov 配合 -4(%ebp), -8(%ebp) 和 -12(%ebp) 我们便可以给 a, b 和 c 赋值了。
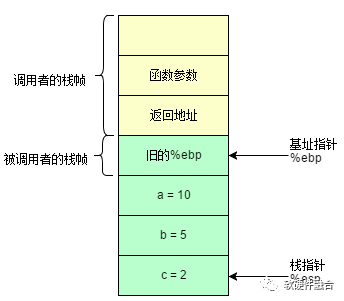
图3 本地变量赋值后的栈帧
接下来我们来看看函数是如何返回的。从下面这个例子我们可以看出,和调用函数时正好相反。当函数完成自己的任务后,它会将 %esp 移到 %ebp 处,然后再弹出旧的 %ebp 的值到 %ebp。这样,%ebp 就恢复到了函数调用前的状态了。
我们注意到最后有一个 ret 指令,它首先将数据(返回地址)弹出栈并保存到 %eip 中,然后处理器根据这个地址无条件地跳到相应位置获取新的指令。
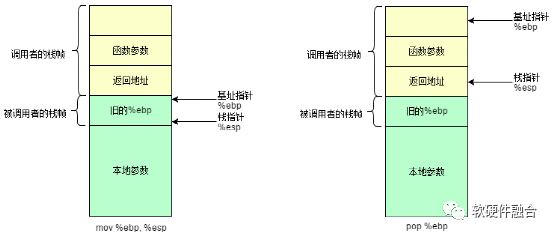
图4 被调用者返回后的栈帧
函数的调用其实不难,只要搞懂了如何保存以及还原 %ebp 和 %esp,就能明白函数是如何通过栈帧进行调用和返回的了。
参考文献:
https://www.cnblogs.com/sddai/p/9762968.html
2.2 程序进程间的调用:IPC
一般来说,linux下的进程包含以下几个关键要素:
- 有一段可执行程序;
- 有专用的系统堆栈空间;
- 内核中有它的控制块(进程控制块),描述进程所占用的资源,这样,进程才能接受内核的调度;
- 具有独立的存储空间。
在软件层面,进程和线程有时候并不完全区分,而往往根据上下文理解其含义。而在硬件层面,进程和线程最大的区别在于存储空间,每个进程都有一个独立的存储空间,而同一个进程中线程,大家共享的是同一个存储空间。
进程间通信的目的:
- 数据传输:一个进程需要将它的数据发送给另一个进程,发送的数据量在一个字节到几M字节之间。
- 共享数据:多个进程想要操作共享数据,一个进程对共享数据的修改,别的进程应该立刻看到。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 资源共享:多个进程之间共享同样的资源,为了作到这一点,需要内核提供锁和同步机制。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
Linux操作系统下进程间通信的主要方式:
- 管道(Pipe):管道可用于具有亲缘关系进程间的通信,允许一个进程和另一个与它有共同祖先的进程之间进行通信。
- 命名管道(named pipe):命名管道克服了管道没有名字的限制,因此,除具有管道所具有的功能外,它还允许无亲缘关系进程间的通信。命名管道在文件中有对应的文件名。命名管道通过命令mkfifo或系统调用mkfifo来创建。
- 信号(Signal):信号是比较复杂的通信方式,用于通知接受进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程本身;除了支持Unix早期信号语义函数sigal外,还支持语义符合Posix.1标准的信号函数sigaction。
- 消息(Message)队列:消息队列是消息的链接表,包括Posix消息队列system V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。
- 共享内存:使得多个进程可以访问同一块内存空间,是最快的可用IPC形式。是针对其他通信机制运行效率较低而设计的。往往与其它通信机制,如信号量结合使用,来达到进程间的同步及互斥。
- 内存映射(mapped memory):内存映射允许任何多个进程间通信,每一个使用该机制的进程通过把一个共享的文件映射到自己的进程地址空间来实现它。
- 信号量(semaphore):主要作为进程间以及同一进程不同线程之间的同步手段。
- 套接口(Socket):更为一般的进程间通信机制,可用于不同机器之间的进程间通信。起初是由Unix系统的BSD分支出来的,但现在一般可以移植到其它类Unix系统上:Linux和System V的变种都支持套接字。
参考文献:
https://oxnz.github.io/2014/03/31/linux-IPC/
https://www.jianshu.com/p/758c7e0df40d
2.3 远程程序调用:RPC
RPC(Remote Procedure Call):远程过程调用,它是一种通过网络从远程计算机程序上请求服务。目前流行的开源 RPC 框架还是比较多的,有阿里巴巴的 Dubbo、Facebook 的 Thrift、Google 的 gRPC、Twitter 的 Finagle 等。
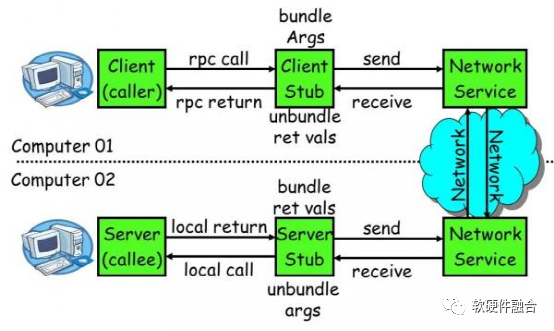
图5 RPC 核心功能图
一个 RPC 的核心功能主要有 5 个部分组成,分别是:
- 客户端(Client):服务调用方;
- 客户端存根(Client Stub):存放服务端地址信息,将客户端的请求参数数据信息打包成网络消息,再通过网络传输发送给服务端;
- 网络服务:底层传输,可以是 TCP 或 HTTP;
- 服务端存根(Server Stub):接收客户端发送过来的请求消息并进行解包,然后再调用本地服务进行处理;
- 服务端(Server):服务的真正提供者。
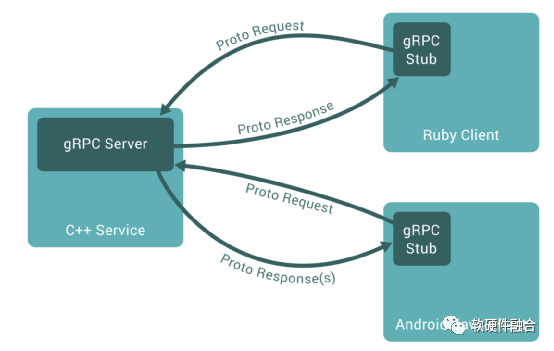
图6 gRPC原理图
gRPC是一个高性能、通用的开源RPC框架,其由Google主要面向移动应用开发并基于HTTP/2协议标准而设计,基于ProtoBuf(Protocol Buffers)序列化协议开发,且支持众多开发语言。gRPC提供了一种简单的方法来精确地定义服务和为iOS、Android和后台支持服务自动生成可靠性很强的客户端功能库。客户端充分利用高级流和链接功能,从而有助于节省带宽、降低的TCP链接次数、节省CPU使用、和电池寿命。
gRPC具有以下重要特征:
- 强大的IDL特性 RPC使用ProtoBuf来定义服务,ProtoBuf是由Google开发的一种数据序列化协议,性能出众,得到了广泛的应用。
- 支持多种语言,支持C++、Java、Go、Python、Ruby、C#、Node.js、Android Java、Objective-C、PHP等编程语言。
参考文献:
https://developer.51cto.com/art/201906/597963.htm
https://colobu.com/2017/04/06/dive-into-gRPC-streaming/
2.4 远程调用REST
REST, resource REpresentational State Transfer, 资源表现状态转移。REST描述的是在网络中Client和Server的一种交互形式;RESTful API是REST的具体实现。Server提供的RESTful API中,URL中只使用名词来指定资源,原则上不使用动词。“资源”是REST架构或者说整个网络处理的核心。
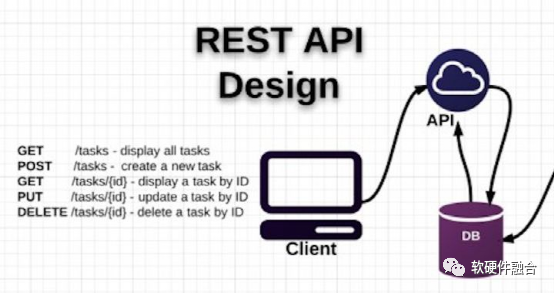
图7 REST API的操作
用HTTP协议里的动词来实现资源的添加,修改,删除等操作。即通过HTTP动词来实现资源的状态扭转:
- GET 用来获取资源;
- POST 用来新建资源(也可以用于更新资源);
- PUT 用来更新资源;
- DELETE 用来删除资源。
Server和Client之间传递某资源的一个表现形式,比如用JSON,XML传输文本,或者用JPG,WebP传输图片等。
为什么要用RESTful结构呢?最开始的时候网页是前端后端融在一起的,比如PHP,JSP等。在桌面时代问题不大,但是随着移动互联网的发展,各种类型的Client层出不穷,RESTful可以通过一套统一的接口为 Web,iOS和Android提供服务。另外对于广大平台来说,比如Facebook platform,微博开放平台,微信公共平台等,它们不需要有显式的前端,只需要一套提供服务的接口,于是RESTful成为它们最好的选择。
Restful和RPC有哪些区别?
- 所属类别不同。REST,指某个瞬间状态的资源数据的快照,包括资源数据的内容、表述格式(XML、JSON)等信息。REST 是一种软件架构风格。这种风格的典型应用,就是HTTP。其因为简单、扩展性强的特点而广受开发者的青睐。RPC可以实现客户端像调用本地服务(方法)一样调用服务器的服务(方法)。RPC 可以基于 TCP/UDP,也可以基于 HTTP 协议进行传输的。
- 使用方式不同。HTTP接口只关注服务提供方,对于客户端怎么调用并不关心。接口只要保证有客户端调用时,返回对应的数据就行了。而RPC则要求客户端接口保持和服务端的一致。REST是服务端把方法写好,客户端并不知道具体方法。RPC是服务端提供好方法给客户端调用,客户端需要知道服务端的具体类,具体方法,然后像调用本地方法一样直接调用它。
- 面向对象不同。从设计上来看,RPC,是面向方法的;而REST是面向资源的。
- 序列化协议不同。接口调用通常包含两个部分,序列化和通信协议。通信协议,上面已经提及了,REST是基于HTTP协议,而RPC可以基于TCP/UDP,也可以基于HTTP。常见的序列化协议,有:json、xml、hession、protobuf、thrift、text、bytes等,REST通常使用的是JSON或者XML,而RPC使用的是 JSON-RPC,或者 XML-RPC。
- 应用场景。REST和RPC都常用于微服务架构中。HTTP相对更规范,更标准,更通用,无论哪种语言都支持http协议。如果你是对外开放API,基本最先支持的几个协议都包含RESTful。RPC框架作为架构微服务化的基础组件,它能大大降低架构微服务化的成本,提高调用方与服务提供方的研发效率,屏蔽跨进程调用函数(服务)的各类复杂细节。让调用方感觉就像调用本地函数一样调用远端函数、让服务提供方感觉就像实现一个本地函数一样来实现服务。REST调用及测试都很方便,RPC就显得有点繁琐,但是RPC的效率是毋庸置疑的。所以在多系统之间的内部调用采用RPC,对外提供的服务,Rest更加合适。
参考文献:
https://www.zhihu.com/question/28557115/answer/48094438
https://blog.csdn.net/John_ToStr/article/details/103473077
已剪辑自: https://mp.weixin.qq.com/s?__biz=MzkxMDE3MDQxMA==&mid=2247483928&idx=1&sn=b5baad5156be66d2e7dcbd256fee61e6&chksm=c12ec25df6594b4ba4bac11ea8bd486aaf9f0761fa95ec7bd4df51676ee1a326439d0fd1b285&scene=178&cur_album_id=1809060064821903360#rd
3 硬件“调用”
3.1 综述
总线模型
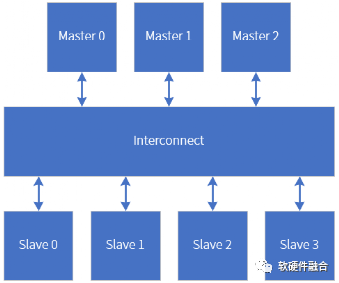
图8 总线系统示意图,包含主模块、从模块和Interconnect
芯片是由多个不同模块组成的,每个模块之间通过一些自定义的或标准的多根线连接到一起。为了更好的标准化和设计服用,模块之间通常都采用标准的总线连接。总线是符合特定协议的一组线的集合。
通过总线把不同的看连接到一起之后,有的模块会主动发起访问Request,这些我们称之为总线Master模块;有的模块则是被动的接收访问并返回响应Response结果,这些模块我们称之为总线Slave模块。Master模块和Slave模块并不一定是直接连接到一起的,一般需要有特殊的总线Interconnect专门来连接。
类似软件的CS架构,硬件的Slave相当于Server,Master相当于Client。
总线的分层
可以把总线访问理解成三个层次:
- 层次1:物理层次,主要关注的是相互连接的总线行为,例如AXI总线李的valid/ready握手,burst信号如何定义,user信号如何定义等等。
- 层次2:从节点到节点的“数据包”,例如,从Master发到到Slave的Request,从Slave返回到Master的Response;也例如PCIe底层是全双工的数据传输通道,每次传输的是TLP包;也例如网络,传输的是Tx或Rx向的网络包。
- 层次3:底层数据包封装的上层Transaction访问,上层的访问通常只有两种,读访问和写访问,其他的各种变种的访问均是读写包含一些特殊的标识,然后slave可以识别并处理。
总线的拓扑
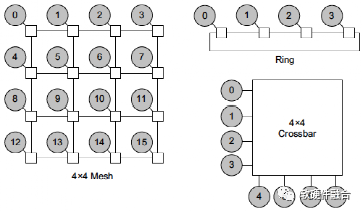
图9 常见的总线互联拓扑
总线Interconnect常见有三类:
- 交叉总线Crossbar:这种拓扑结构构建起来很简单,并且自然地提供了一个低延迟的有序网络,这种拓扑适合与少量节点进行互连。传统的总线结构通常在单一时刻只能进行一次访问,访问需要独占总线,而交叉开关则具有更多的访问通路,可以同时进行多次访问。
- 环形总线Ring:这种拓扑结构在互连连接效率和延迟之间提供了很好的平衡。延迟随环上节点的数目线性增加。这种拓扑适合中等规模的互联。
- 网状总线Mesh:这种拓扑结构提供了更大的带宽,代价是需要更多的线路。它是非常模块化的,可以通过添加更多的行和列来方便地扩展到更大的系统。这种拓扑结构适用于更大规模的互联。
总线的分类
通过总线,把多个模块连接到一起,根据Master和Slave的对应关系,我们把总线分为如下类型:
- 一对一:如AXI-Stream、PCIe(包括基于PCIe的CCIX、CXL)等;
- 一对多:如APB等;
- 多对多:AHB、AXI;
- 对等网络:CHI(CHI在对等网络基础上区分了主从)、通用NOC、以太网等。
按照连接的Hierarchy,我们把硬件之间的总线连接分为:
- 片内的总线;
- Chiplet多DIE封装互联总线;
- 板级总线;
- 数据中心高速网络;
- 全球互联网络等。
3.2 片内的总线
片内总线常见的是ARM主导的AMBA(Advanced Microcontroller Bus Architecture )系列总线,AMBA是一种开放标准的、片内互联的总线协议,为了管理系统芯片(SoC)设计中功能模块的互联规范。如今,AMBA已广泛用于各种ASIC和SoC部件。
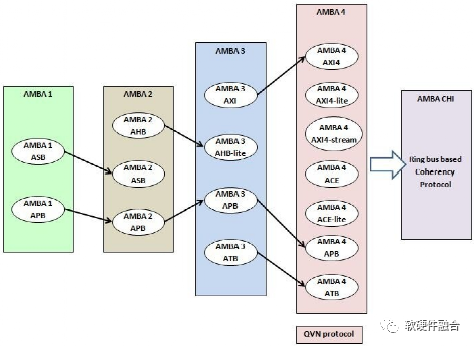
图10 AMBA总线的发展历程
AMBA是ARM公司在1995年推出的芯片内互联系列总线。AMBA 1总线是ASB(Advanced System Bus,高级系统总线)和APB(Advanced Peripheral Bus,高级外围设备总线)。在1999年发布的AMBA 2中,ARM添加了AHB(AMBA High-performance Bus,AMBA高性能总线)。2003年,ARM推出了第三代产品AMBA 3,其中包括可实现更高性能互连的AXI(Advanced eXtensible Interface,高级可扩展接口)和作为CoreSight片上调试和跟踪解决方案一部分的ATB(Advanced Trace Bus,高级跟踪总线)。在2010年,从AXI4开始引入AMBA 4规范,然后在2011年通过AMBA 4 ACE(AXI Coherency Extensions,AXI一致性扩展)扩展了系统范围内的一致性。2013年引入了AMBA 5 CHI(Coherent Hub Interface,一致性集线器接口)规范,重新设计了高速传输层,并设计了可减少拥塞的功能(CHI因为属于NOC的范畴,将在下一节NOC总线介绍)。
AMBA协议的主要设计目标是实现一种标准有效的方法来互连芯片内部的模块,并且这些模块可以在多个设计中重复使用。如今,AMBA协议已成为SOC及嵌入式处理器总线体系结构的事实上的标准,可以免费使用。
各个总线详细的介绍不在此一一列举,感兴趣的朋友可以去ARM官网下载相关的技术文档学习,网上也可以找到非常多的相关资料。
3.3 Chiplet多DIE封装互联总线
Chiplet(翻译成小芯片或芯粒)技术通过把不同的裸DIE封装在一起。Chiplet有很多好处:
- 解决摩尔定律失效问题,可以突破DIE Size上限;
- 同时,能提高良率,即使算上chiplet封装的开销,成本低于单DIE;
- 另外,Chiplet可以增加芯片复用,使得芯片一次性成本降低;
- 等等。
Chiplet技术当前还在发展过程中,还没有形成主流的标准。
DARPA的CHIPS项目,跟Intel合作,开源了AIB(Advanced Interface Bus),AIB是一种免费的DIE-to-DIE物理层接口标准,Intel® Stratix® 10 FPGA 用的就是AIB 接口。
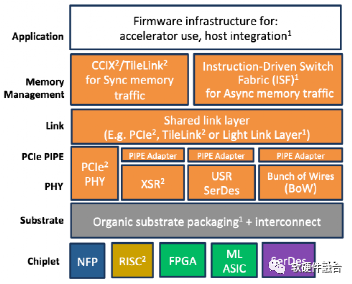
图11 ODSA 分层架构
OCP的ODSA工作组相对平民化很多,ODSA关注die-to-die的层次,并且提出chiplet marketplace的口号。ODSA 的接口标准,分层概念提的很清晰,但是如果试图包括一切,标准的统一性就不会好。
还有一些公司,就不搞什么标准,直接上产品,例如Cadence Ultralink D2D PHY IP ,Synopsys 新出的 DesignWare die to die PHY IP 简单,高效。
物理层,把chiplet 对接在一起。而在物理层之上,有两种类型倾向的语以接口,I/O类型的和memory类型的。保持一致性,以硬件复杂换取软件简单?还是不保持一种性追求高效。
Chiplet是未来发展的热点方向,哪个总线能最终成为chiplet DIE-to – chiplet DIE的主流标准?目前尚未有结论。我们大家一起,持续关注。
参考文献:
https://mp.weixin.qq.com/s/IsHItdTYnnDL7KGlVwlA6w
3.4 板级总线
PCIe是当前主流的片间互联高速总线,而通过SR-IOV技术扩展了PCIe的功能,使得单组PCIe可以更好地支持逻辑隔离的许多虚拟设备。
PCI是一种并行总线,随着频率的提高,PCI并行传输遇到了干扰的问题。长距离高速传输的时候,并行的连线直接干扰异常严重,而且随着频率的提高,干扰(EMI)越来越不可跨越。PCIe和PCI最大的改变是由并行改为串行,通过使用差分信号传输,干扰可以很快被发现和纠正,从而可以将传输频率大幅提升。加上PCI原来基本是半双工的(地址/数据线太多,不得不复用线路),而串行可以全双工。综合下来,从频率提高得到的收益大于一次传输多个bit的收益。还得到了另外的好处,例如布线简单,线路可以加长,甚至变成线缆连出机箱,多个Lane还可以整合成为更高带宽的线路等。
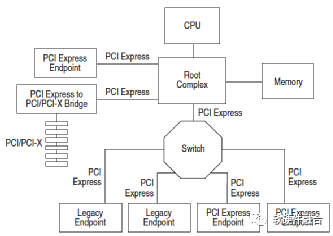
图12 PCIe示例拓扑图
如图12所示,不考虑Switch的影响,PCIe根节点是跟PCIe终端节点(End Point)是直接相连的。
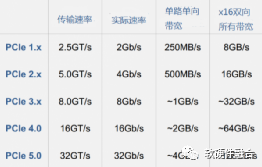
图13 PCIe版本的带宽比较
如图13所示,我们可以看到,PCIe从1.0发展到了5.0,每一代的带宽大致上翻倍。到PCIe 5.0,通过x16组总线,可以支持双向共约128GB/s的数据带宽,可以支持高达400Gb的网络带宽。
PCIe SR-IOV (Single Root I/O Virtualization)是一项I/O硬件虚拟化技术,可提升I/O设备的性能和可伸缩性。如图14所示,SR-IOV标准允许在虚拟机之间高效共享PCIe设备,并且共享是在硬件中实现的,可以获得与硬件一致的I/O性能。SR-IOV引入了两种新的功能类型:
- 物理功能(Physical Functions):PF包含SR-IOV功能结构,用于管理SR-IOV功能。PF 是PCIe功能的全集,可以像其他任何PCIe设备一样被发现、管理和处理。PF拥有完全配置资源,可以用于配置或控制PCIe设备。
- 虚拟功能(Virtual Functions):与PF关联的一种功能。VF是一种轻量级的PCIe功能,可以与物理功能以及与同一物理功能关联的其他VF共享一个或多个物理资源。VF仅允许拥有用于其自身行为的配置资源。
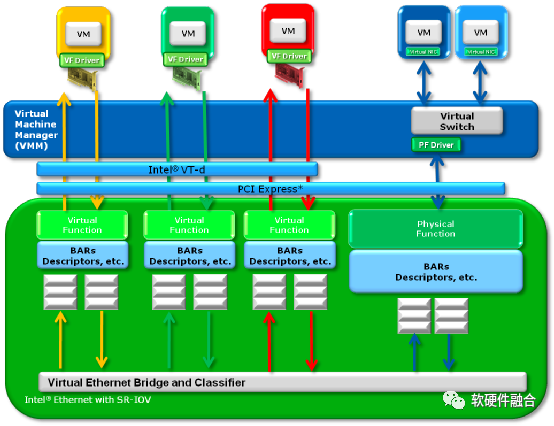
图14 支持SR-IOV技术的Intel网卡技术原理图
每个SR-IOV设备可有一个或多个物理功能(Physical Function, PF),并且每个PF最多可有若干个与其关联的虚拟功能(Virtual Function, VF),PF可以通过寄存器配置创建与自己关联的VF。一旦在PF中启用了SR-IOV,就可以通过PF的总线、设备和功能编号访问各个VF的PCI配置空间。
3.5 数据中心高速网络
数据中心高速网络,本质上和全球互联网络是不同层次的网络,原因如下:
- 数据中心网络物理距离短,服务器系统堆栈延迟凸显;
- 系统解构以及多租户混杂,共同导致了数据中心东西向流量激增,占比越来越大;
- 数据中心因为是某家企业或运营商私有的,这样可以不考虑全球互联网兼容,也就是说不一定需要支持TCP/IP。
因此,数据中心需要轻量的高性能网络协议,当前主流的方案是RoCEv2的RDMA技术。RDMA(Remote Direct Memory Access,远程直接内存访问)是一种高带宽、低延迟、低CPU消耗的网络互联技术,克服了传统TCP/IP网络的许多困难。RDMA技术体现在:
- Remote(远程):数据在网络中的两个节点之间传输。
- Direct(直接):不需要内核参与,传输的所有处理都卸载到NIC硬件中完成。
- Memory(内存):数据直接在两个节点的应用程序的虚拟内存间传输;不需要额外的复制和缓存。
- Access(访问):访问操作有send/receive、read/write等。
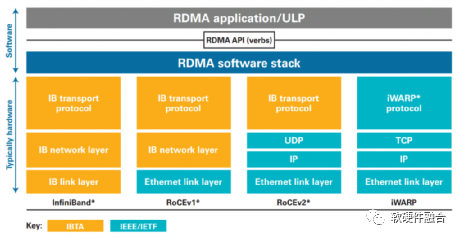
图15 RDMA所使用的InfiniBand、RoCEv1/v2、iWARP技术对比
如图15所示,RoCE(RDMA over Converaged Ethernet)v1是基于现有Ethernet网络实现RDMA的一项技术。RoCEv1允许在现有以太网基础上实现RDMA技术,实现接近InfiniBand的性能和延迟指标,但不需要将现有网络基础设施升级成昂贵的InfiniBand,节约了大量的支出。RoCEv2基于标准网络的以太网(Ethernet PHY/MAC)、网络层(IP)和传输层(UDP)协议,这可以使得RoCEv2的网络流量可以经过传统的网络路由器路由。
3.6 全球互联网络
全球互联网络,这个话题有点大,关于网络的内容太多太多,很难面面俱到。
首先,我们介绍下最流行的五层网络协议模型。OSI参考模型具有七层,分别是物理层、数据链路层、网络层、传输层、会话层、表示层、应用层。TCP/IP参考模型精简了OSI模型,只有链路层、网络层、传输层、应用层。OSI参考模型的影响力在于模型本身(去掉会话层和表示层),它已被证明对于讨论计算机网络非常有价值;而TCP/IP参考模型的优势体现在协议,这些协议已经被广泛应用许多年,证明了自身在各种复杂网络条件下的稳定性。
结合二者的特点,现在大家讨论的网络分层模型如图16所示的五层参考模型:
- 物理层:规定了如何在不同的介质上以电气(或其他模拟)信号传输比特。
- 链路层:关注的是如何在两台相连的计算机之间发送有限长度的消息,并具有指定级别的可靠性。以太网和802.11就是链路层协议。
- 网络层:主要处理如何把多条链路结合到网络中,以及如何把网络与网络连接成互联网络,使我们可以在两个相隔遥远的计算机之间发送数据包。网络层的任务包括找到传递数据包所走的路径。IP是网络层主要的协议。
- 传输层:传输层增强了网络层的传输,通常有更高的可靠性,提供满足不同应用需求的可靠字节流。TCP和UDP是传输层主要的协议。
- 应用层:应用层包含了使用网络的应用程序。例如HTTP和DNS等。
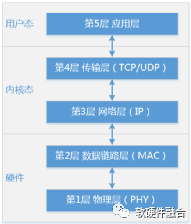
图16 TCP/IP网络协议栈
如图16所示,一般情况下,网络协议栈各层分别实现在硬件、内核态软件和用户态。物理层和网络链路层是由以太网和802.11标准所定义的,比较稳定,因此物理层和网络链路层一般实现在硬件里;网络层和传输层作为系统共用的组件,一般是作为TCP/IP协议栈集成在操作系统内核里;而应用层的任务则一般交给用户态的程序去实现。
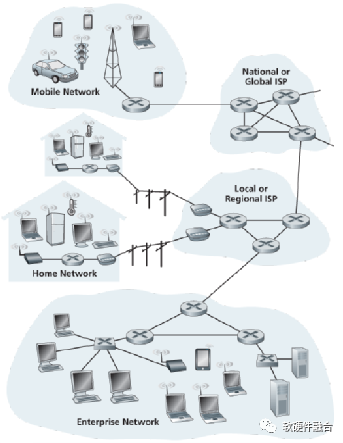
图17 全球Internet接入示意图
如图17,我们可以看到,每个局域网内部,通过有线或无线的方式把各种类型的设备接入到局域网。而全球互联网其实是由无数多个局域网互联组成的。每个局域网通过一个或多个路由器接入互联网,ISP就是专门提供互联网接入服务的供应商,ISP之上,还有国家级的ISP接入网络。
已剪辑自: https://mp.weixin.qq.com/s?__biz=MzkxMDE3MDQxMA==&mid=2247483942&idx=1&sn=e2c79a6ba46d791c3fe7bdcc25ff3d84&chksm=c12ec263f6594b752e048ca4851782b4a0dd6c8cebb104a27b2b0ca154b8cced7c32147ddcb5&scene=178&cur_album_id=1809060064821903360#rd
4 软硬件之间的调用
4.1 生产者消费者模型
生产者消费者问题(Producer-Consumer Problem)是多进程同步问题的经典案例之一,描述了共享固定大小缓冲区的两个进程,即所谓的“生产者”和“消费者”,在实际运行时如何处理交互的问题。
如图18所示,生产者的主要作用是生成一定量的数据放到缓冲区中,然后重复此过程。与此同时,消费者也在缓冲区消耗这些数据。问题的关键就是要保证生产者不会在缓冲区满时加入数据,消费者不会在缓冲区中空时消耗数据。
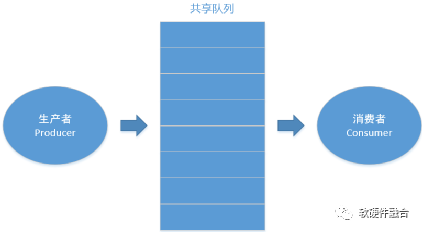
图18 经典生产者消费者模型
解决问题的基本办法是:让生产者在缓冲区满时休眠,等到消费者消耗缓冲区中的数据,从而缓冲区有了空闲区域的时候,生产者才能被唤醒,开始继续往缓冲区添加数据;同样,也需要让消费者在缓冲区空时进入休眠,等到生产者往缓冲区添加数据之后,再唤醒消费者继续消耗数据。
4.2 软硬件的接口定义
粗略地说,软硬件接口是由驱动(Driver)和设备(Device)组成,驱动和设备的交互也即软件和硬件的交互。更确切一些地说,软硬件接口包括交互的驱动软件、硬件设备的接口部分逻辑,也包括内存中的共享队列,还包括传输控制和数据信息的总线。
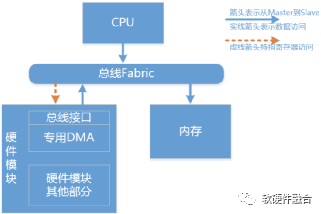
图19 软硬件接口硬件架构示意模型
如图19所示,是软硬件接口硬件架构的示意模型。软硬件接口的组件详细介绍如下:
- 驱动软件。驱动是提供一定的接口API,让上层的软件能够更加方便地与硬件交互。驱动负责硬件设备控制面的配置、运行控制以及设备数据面的数据传输控制等。驱动屏蔽硬件的接口细节,对上层软件提供标准的API函数接口。驱动屏蔽硬件细节,提供标准API给上层软件。通过不同版本的驱动,既可以屏蔽硬件细节,又可以跟不同的操作系统平台兼容。
- 设备硬件接口子模块,包括DMA和内部缓冲。高速的设备一般都有专用的DMA,专门负责数据搬运。驱动会通知DMA共享队列状态信息,然后DMA会读取内存中的共享队列描述符,并根据描述符信息负责在CPU内存和内部缓冲之间搬运数据。
- 共享队列。特定的跟硬件DMA格式兼容的共享队列数据结构,软件和硬件通过共享队列交互数据。每个共享队列包括队列的头和尾指针、组成队列的各个描述符项以及每个描述符项所指向的实际的数据块。
- 传输的总线:软硬件交互可以说是上层功能,需要底层接口总线的承载。例如,在片内通常是通过AXI-Lite总线来实现软件对硬件的寄存器读写控制,而数据总线则是通过AXI实现硬件DMA对软件的CPU内存的读写访问。
4.3 软硬件接口演进
软硬件接口是在I/O接口基础上的扩展,结合I/O交互的四种模式,重新梳理一下软硬件接口的演进:
- 第一阶段,使用软件轮询硬件状态。最开始是通过软件轮询,这时候软件和硬件的交互非常简单。发送的时候,软件会定期查询硬件的状态,当发送缓冲为空的时候,就把数据写入到硬件的缓存寄存器;接收的时候,软件会定期查询硬件的状态,当接收缓冲区有数据的时候,就把数据读取到软件。
- 第二阶段,使用中断模式。随着CPU的性能快速提升,统计发现,轮询的失败次数很高,大量的CPU时间被浪费在硬件状态查询而不是数据传输,因此引入中断模式。只有当发送缓冲存在空闲区域可以让软件存放一定量待发送数据的时候,或者接收缓冲已经有一定量数据待软件接收的时候,硬件会发起中断,CPU收到中断后进入中断服务程序,在中断服务程序里处理数据的发送和接收。
- 第三阶段,引入DMA。前面的两种情况下,都需要CPU来完成数据的传输,依然会有大量的CPU消耗。因此引入了专用的数据搬运模块DMA来完成CPU和硬件之间的数据传输,某种程度上,DMA可以看作用于代替CPU进行数据搬运的加速器。发送的时候,当数据在CPU内存准备好,CPU告诉DMA源地址和数据的大小,DMA收到这些信息后主动把数据从CPU内存搬到硬件内部。同样的,接收的时候,CPU开辟好一片内存空间并告知DMA目标地址和空间的长度,DMA负责把硬件内部的数据搬运到CPU内存。
- 第四阶段,专门的共享队列。引入了DMA之后,如果只有一片空间用于软件和硬件之间的数据交换,则软件和硬件之间的数据交换则是同步的。例如在接收的时候,当DMA把数据搬运到CPU内存之后,CPU需要马上进行处理并释放内存,CPU处理的时候DMA则只能停止工作。后来引入了乒乓缓冲的机制,当一个内存缓冲区用于DMA传输数据的时候,另一个缓冲区的数据由CPU进行处理,实现DMA传输和CPU处理的并行。更进一步的,演变成更多缓冲区组成的循环缓冲队列。这样,CPU的数据处理和DMA的数据传输则完全异步的完成,并且CPU对数据的处理以及DMA对数据的搬运都可以批量操作完成后,再同步状态信息给对方。
- 第五阶段,用户态的软件轮询共享队列驱动。进一步的,随着带宽和内存的增加,导致数据频繁的在用户态应用程序、内核的堆栈、驱动以及硬件之间交互,并且缓冲区也越来越大,这些都不可避免的增加系统消耗,并且带来更多的延迟;而且,数据交互频繁,导致的中断的开销也是非常庞大的。因此,通过用户态的PMD(Polling Mode Driver,轮询模式驱动)可以高效的在硬件和用户态的应用程序直接传递数据,不需要中断,完全绕开内核,以此来提升性能和降低延迟。
- 第六阶段,支持多队列。随着硬件设计规模扩大,硬件资源越来越多,在单个设备里,可以通过多队列的支持,来提高并行性。驱动也需要加入对多队列的支持,这样我们甚至可以为每个应用程序配置专用的队列或队列组,通过多队列的并行性来提升性能和应用数据的安全性。
4.4 软硬件接口的范例:NVMe
NVMe(Non-Volatile Memory Express)是经过优化的、高性能的、可扩展的主机控制器接口,专为非易失性存储器(NVM)技术而设计。NVMe解决了如下一些性能问题:
- 带宽:通过支持PCIe和诸如RDMA和光纤之类的通道,NVMe可以支持比SATA或SAS高很多的带宽。
- IOPS:例如,串行ATA可能的最大IOPS为20万,而NVMe设备已被证明超过100万IOPS。
- 延迟:NVM以及未来的存储技术具有一微秒以内的访问延迟,需要一种更简洁的软件协议,能够实现包括软件堆栈在内的不超过10毫秒的端到端延迟。
NVMe协议支持多个深度队列,这是对传统SAS和SATA协议的改进。典型的SAS设备在单个队列中最多支持256个命令,而SATA设备最多支持32个命令。这些队列深度对于传统的硬盘驱动器技术已经足够,但不能充分利用NVM技术的性能。
相比之下,图20所示的NVMe多队列,每个队列支持64K命令,最多支持64K队列。这些队列的设计使得I/O命令和对命令的处理不仅可以在同一处理器内核上运行,也可以充分利用多核处理器的并行处理能力。每个应用程序或线程可以有自己的独立队列,因此不需要I/O锁定。NVMe还支持MSI-X和中断控制,避免了CPU中断处理的瓶颈,实现了系统扩展的可伸缩性。NVMe采用简化的命令集,相比SAS或SATA,NVMe命令集使用的处理I/O请求的指令数量减少了一半,从而在单位CPU指令周期内可以提供更高的IOPS,并且降低主机中I/O软件堆栈的处理延迟。
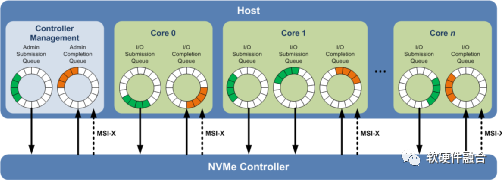
图20 NVMe多队列
NVMe的驱动和设备交互跟Virtio不同:Virtio是在通过一个队列完成双向通知交互;而NVMe则采用提交队列和完成队列配合完成双向交互的方式。
如图21所示,NVMe队列处理流程如下(其中主机为软件驱动,控制器为硬件设备):
- 主机写命令到提交队列项中。
- 主机写DB(Doorbell)寄存器,通知控制器有新命令待处理。
- 控制器从内存中的提交队列中读取命令。
- 控制器执行命令。
- 控制器更新完成队列,表示当前的SQ项已经处理。
- 控制器发MSI-x中断到主机CPU。
- 主机处理完成队列,同步更新提交队列中的已处理项。
- 主机写完成队列Db到控制器,告知完成队列项已释放。
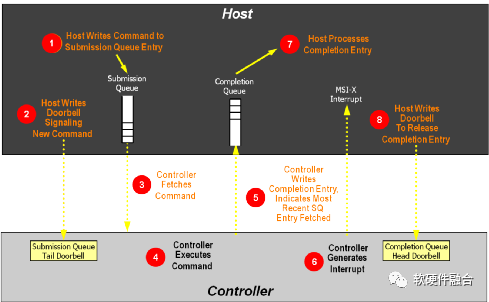
图21 NVMe队列处理流程
NVMe是为了高速非易失性存储定制的存储接口访问协议,定向优化了存储的主要性能指标:带宽、延迟和IOPS。NVMe最重要的特征体现在:
- 面向高速存储场景定制:NVMe是专门面向高速存储场景定制的协议,因此充分考虑了块存储的特点,重点解决存储性能的关键问题。
- 多队列支持:多队列不仅仅充分利用了硬件的并行处理能力,同时,也充分的利用了多核系统多线程并行的特点,最大化的优化了NVMe的性能。
- 标准化:NVMe是得到广泛应用的PCIe SSD接口标准,各大主流操作系统支持统一的标准NVMe驱动。
4.5 基于接口的调用
我们以分层的任务之间调用为例,分层的部分任务是在硬件中完成,构建任务分层软硬件执行的模型,要求其相互之间的调用关系和接口保持不变。

图22 把任务卸载到硬件的简化模型
如图22所示,为分层任务调用的系统。通过把部分任务卸载(相对于在软件执行)到硬件中,来加速系统的运行。其中,双向箭头的上方为调用方,箭头的下方为被调用方。这样,系统任务在软硬件执行,涉及到的调用有四类:
- 软件对软件的调用,任务0调用任务1,软件调用在第2章进行了讲解;
- 硬件对硬件的调用:任务2调用任务3,硬件调用在第3章进行了讲解;
- 软件对硬件的调用:任务1调用任务2,这部分即本章软硬件接口的讲解,通过驱动和设备接口共同组成软硬件接口,然后在此之上再封装软件API接口层驱动,保证任务调用接口的一致性。
- 硬件对软件的调用:任务3调用任务4,技术原理跟软件对硬件调用相同,区别在于谁主谁从的问题。
5 总结
一个复杂的系统,通过分解成简单的模块或层次(软件实现或硬件实现),再通过基于各种连接的调用把他们重新连接成一个整体。
软件中有调用,硬件中也有调用,软件和硬件之间也需要通过调用来进行通信和交互。
调用无处不在!