官方参数文档
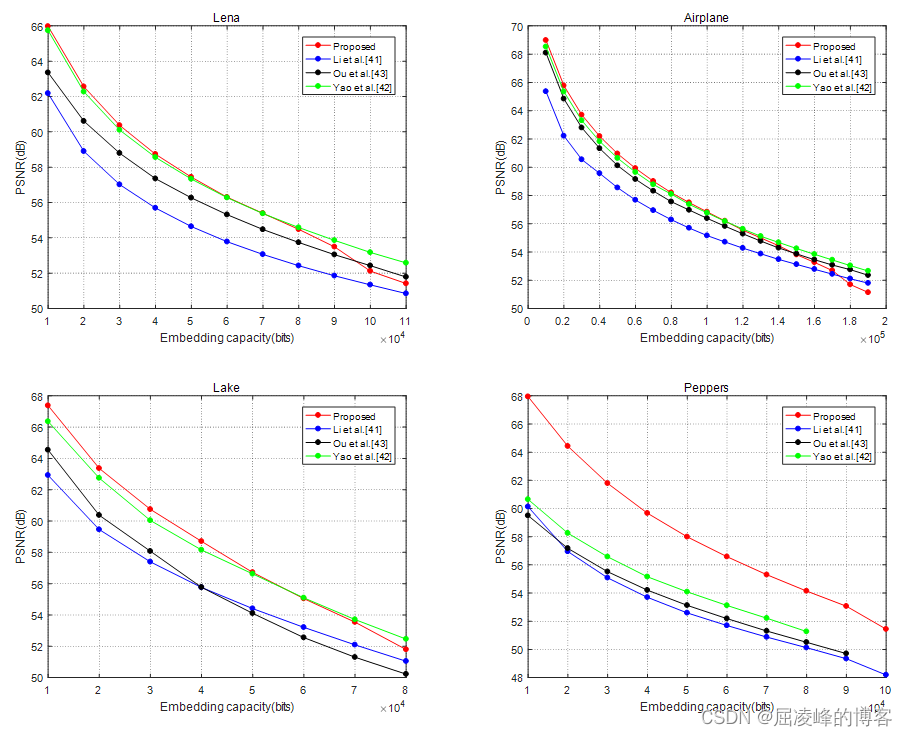
Apache Hadoop 3.3.5 – HDFS Users Guide
Hadoop是一个分布式存储和计算框架,由以下几个组件组成:
1. Hadoop Distributed File System (HDFS):Hadoop分布式文件系统,用于存储大量数据,并提供高可靠性和高可用性。
2. MapReduce:一种编程模型,用于处理大规模数据集。它将数据分成小块,并在分布式计算集群上并行处理。
3. YARN (Yet Another Resource Negotiator):Hadoop的资源管理器,用于管理集群中的计算资源,并分配任务给不同的节点。
4. Hadoop Common:包含Hadoop所需的共享库和工具。
5. Hadoop Ozone:Hadoop的对象存储层,用于存储和管理大规模的非结构化数据。
6. Hadoop Archives:Hadoop的存档工具,用于将文件和目录压缩成一个单独的归档文件。
7. Hadoop KMS (Key Management Server):Hadoop的密钥管理器,用于管理和保护数据加密密钥。
8. Hadoop HttpFS:Hadoop的HTTP文件系统,提供了一个REST接口,可以通过HTTP访问Hadoop文件系统。
以下是一些关于Hadoop组件的链接:
1. HDFS:Apache Hadoop 3.3.5 – HDFS Users Guide
2. MapReduce:Apache Hadoop 3.3.5 – MapReduce Tutorial
3. YARN:Apache Hadoop 3.3.5 – Apache Hadoop YARN
4. Hadoop Common:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/CommonJars.html
5. Hadoop Ozone:https://hadoop.apache.org/docs/stable/hadoop-ozone/index.html
6. Hadoop Archives:https://hadoop.apache.org/docs/stable/hadoop-archive-logs/HadoopArchives.html
7. Hadoop KMS:Hadoop KMS – Hadoop Key Management Server (KMS) - Documentation Sets
8. Hadoop HttpFS:HttpFS – Hadoop HDFS over HTTP - Documentation Sets
代码相关的问题,请提供具体问题和代码。
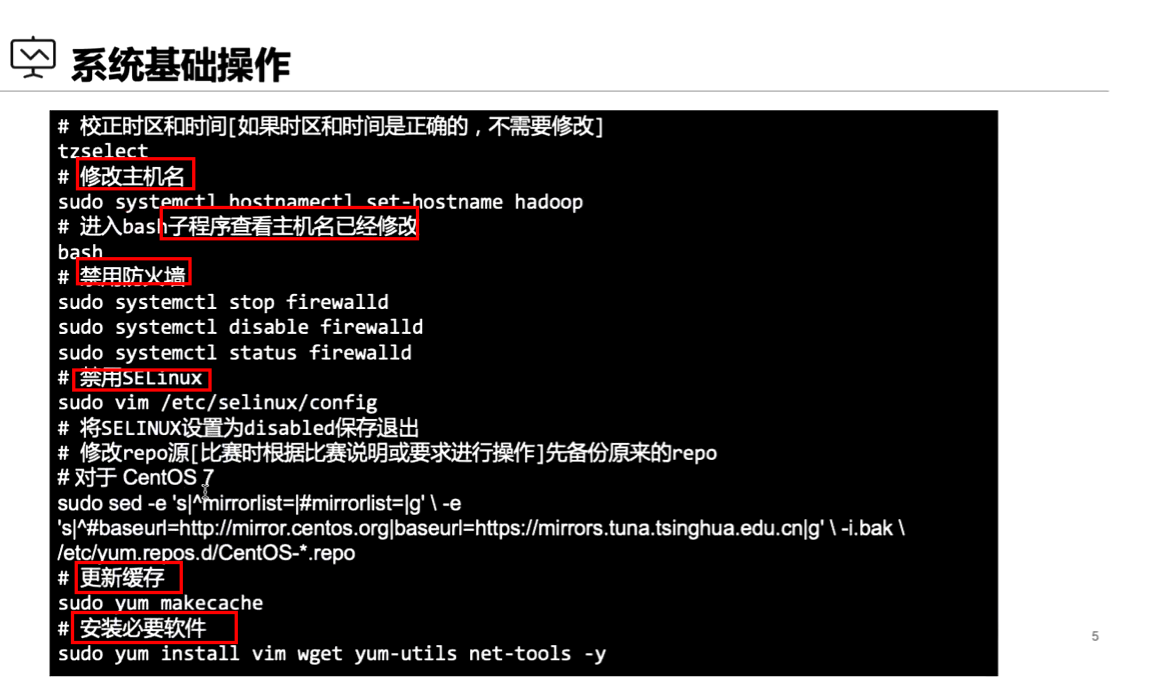
基础环境准备
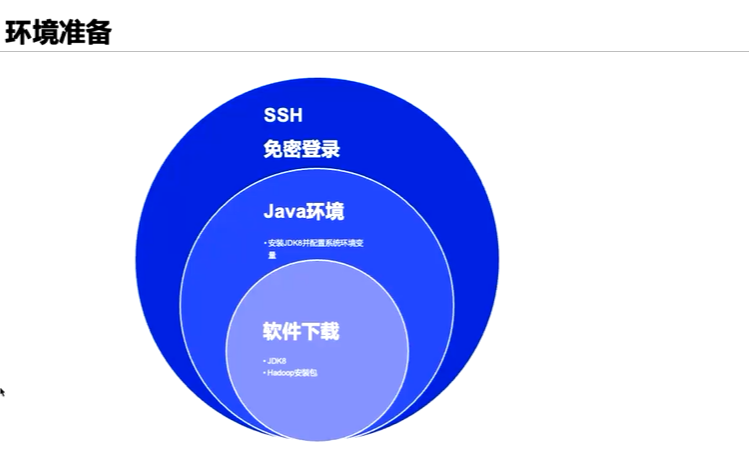
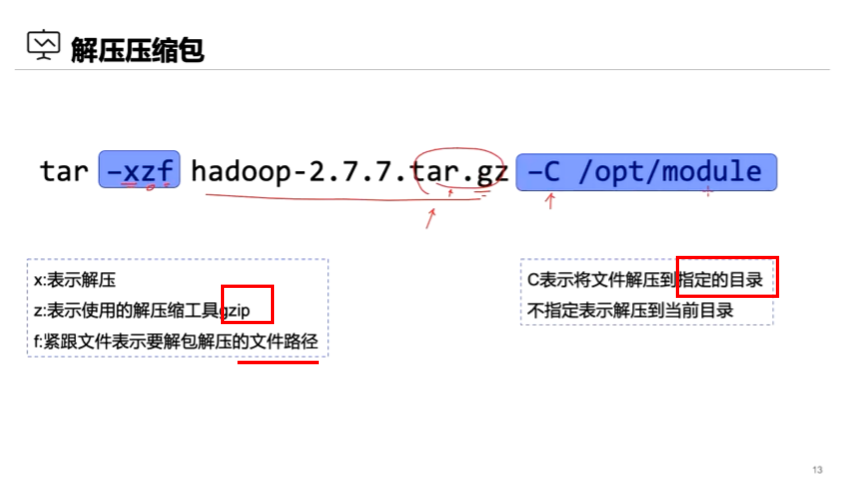
jdk包上传并且解压

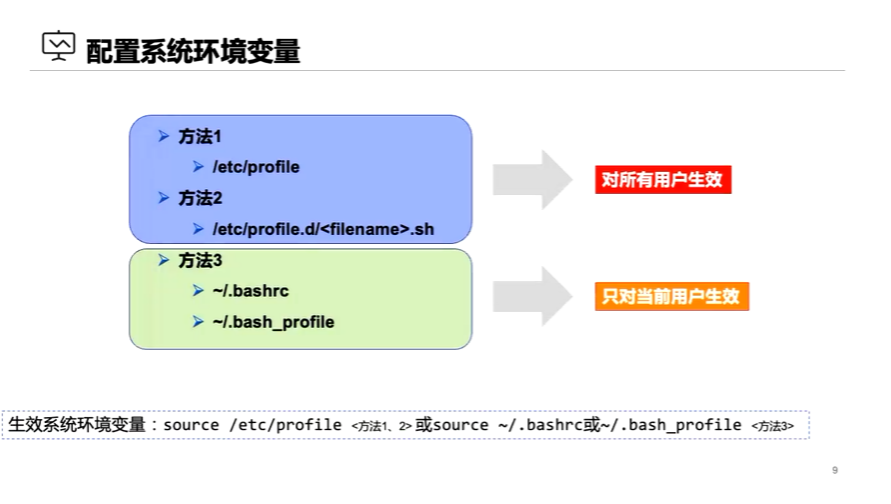
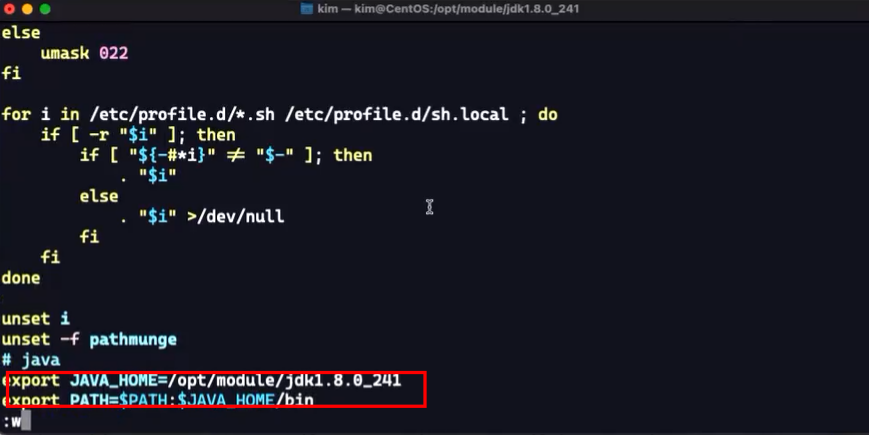
添加jdk环境变量
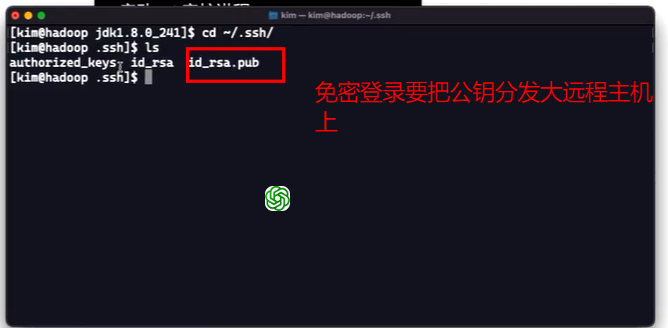
配置免密登录

ssh-keygen -t加密算法 -b密钥长度(用于生成ssh密钥),将公钥分发到远程主机上
Hadoop伪分布式集群搭建

hadoop的搭建(压缩包的解压)
添加环境变量
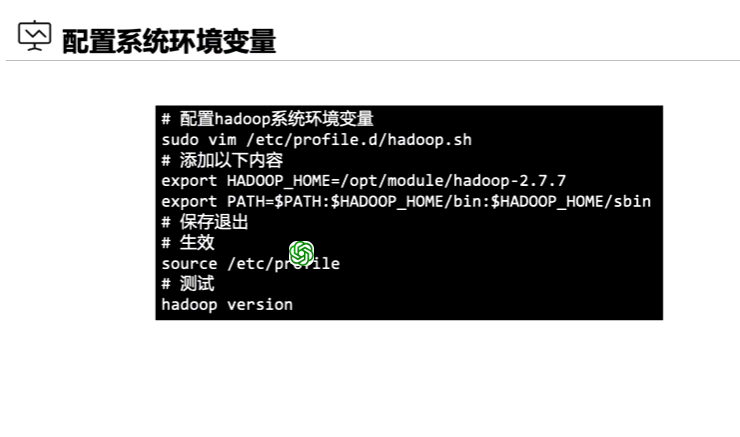
sudo vim /etc/profile.d/hadoop.sh
export HADOOP HOME=/opt/module/hadoop-2.7.7
export PATH=$PATH:$HADOOP HOME/bin:$HADOOP HOME/sbin
source /etc/prorifle #配置生效
hadoop version
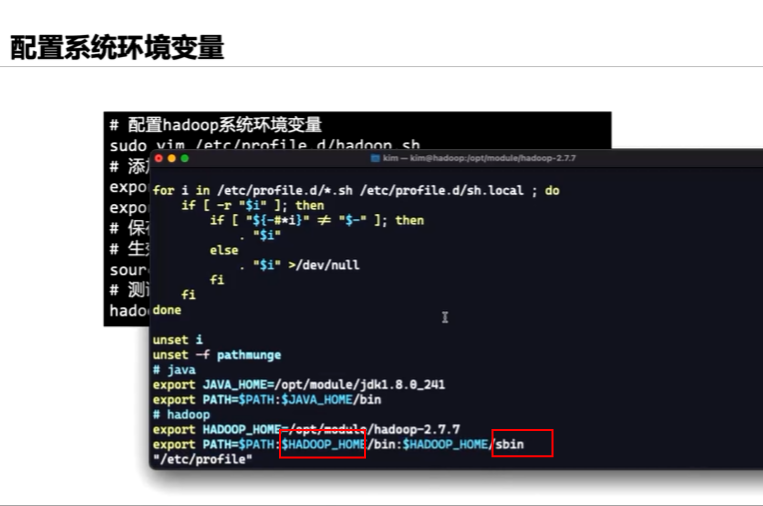
bin目录
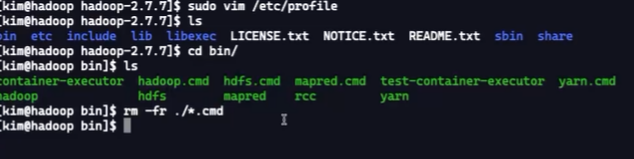
sbin目录(管理hadoop的脚本)

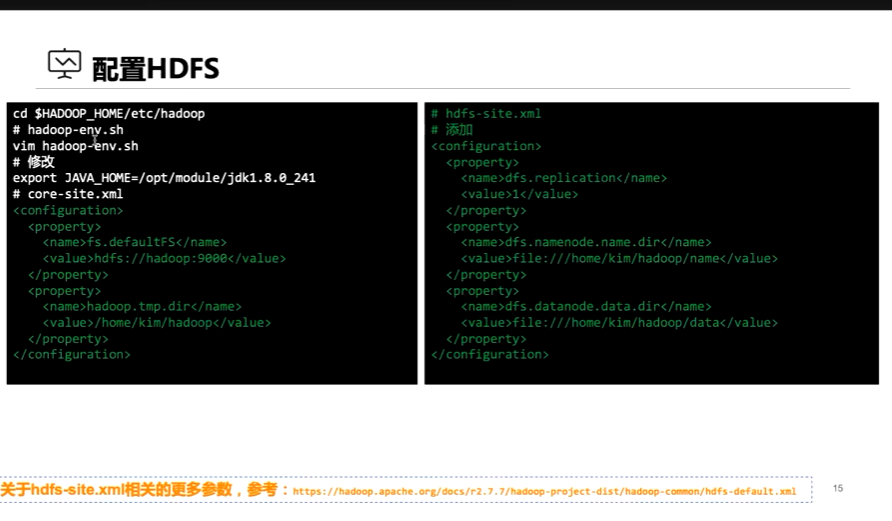
配置hdfs

1、官方网址查询
- http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/core-default.xml
- http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
- http://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
- http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
通过这些网址,可以了解最新的全部的hadoop 配置信息,而且包括一些过时的定义标识,从而更好地维护您的集群。
(2条消息) hadoop搭建四个配置文件(core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml )的简单介绍_蜗牛!Destiny的博客-CSDN博客
(都是在解药的hadoop文件里编辑)
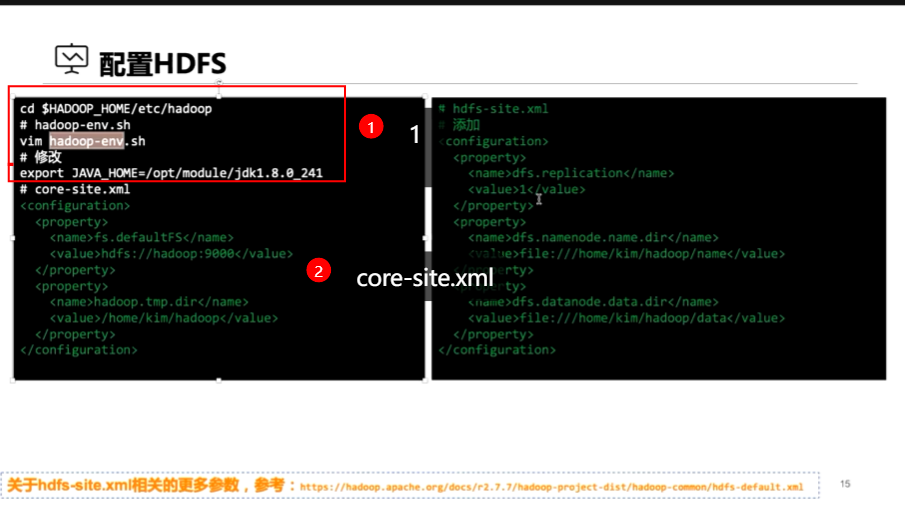
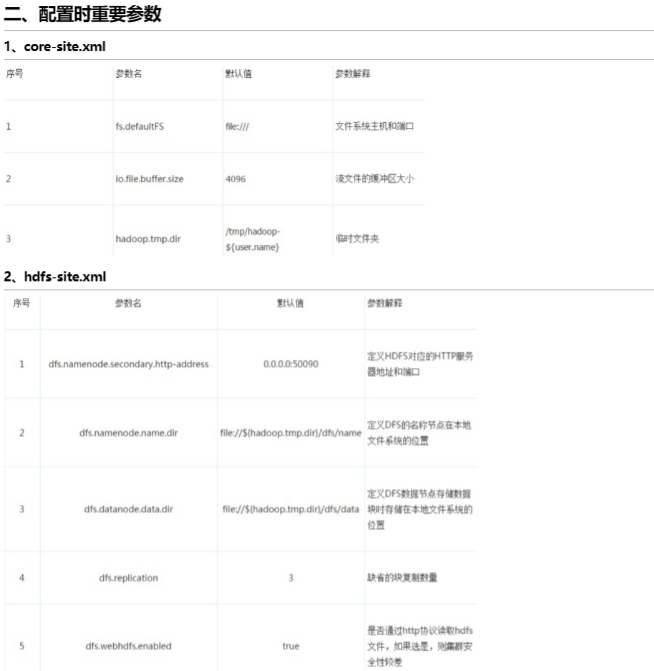
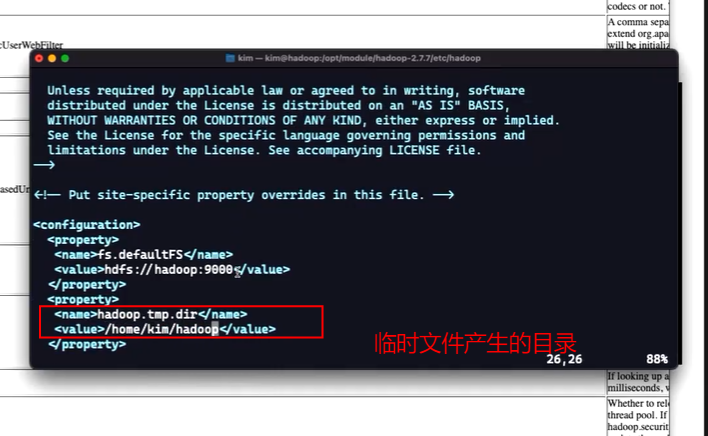
1、配置core-site.xml
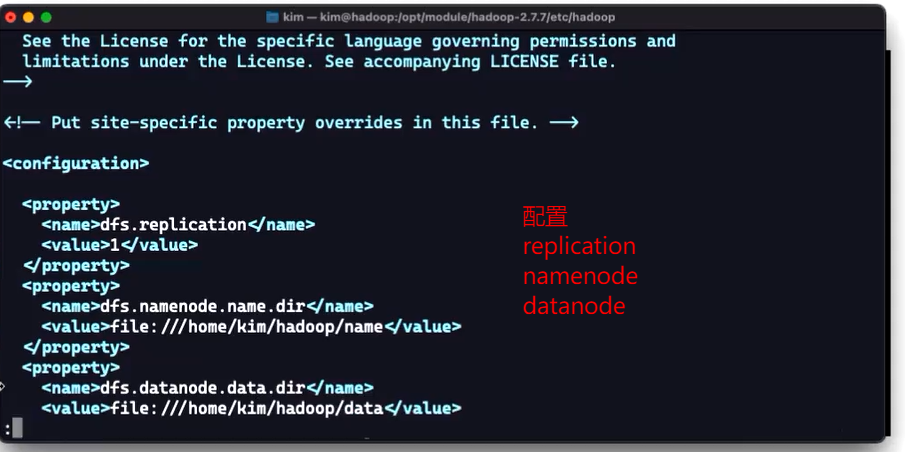
2、配置hdfs-site.xml
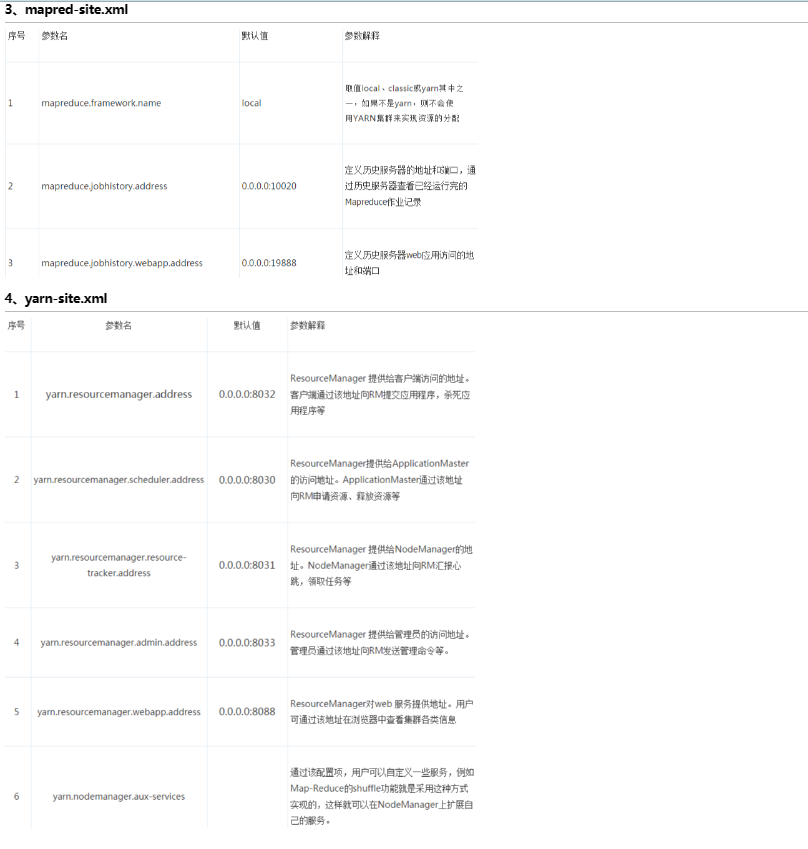
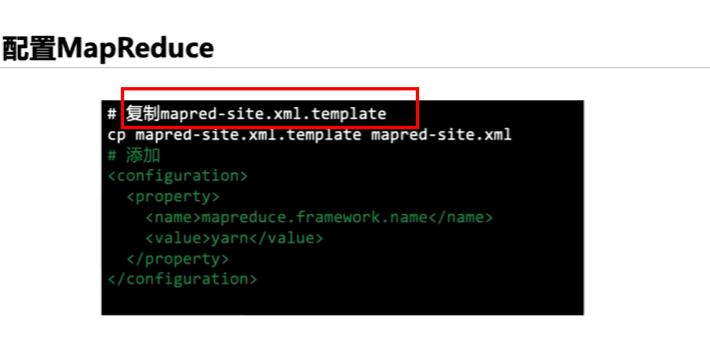
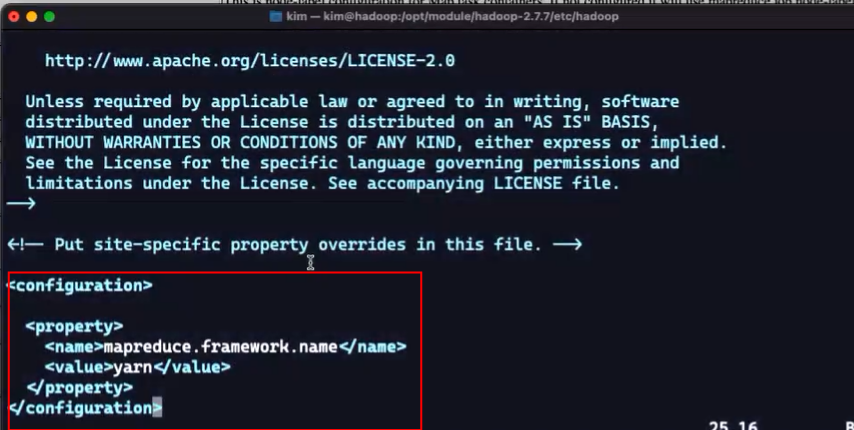
3、配置mapred-site.xml

4、配置yarn-site.xml
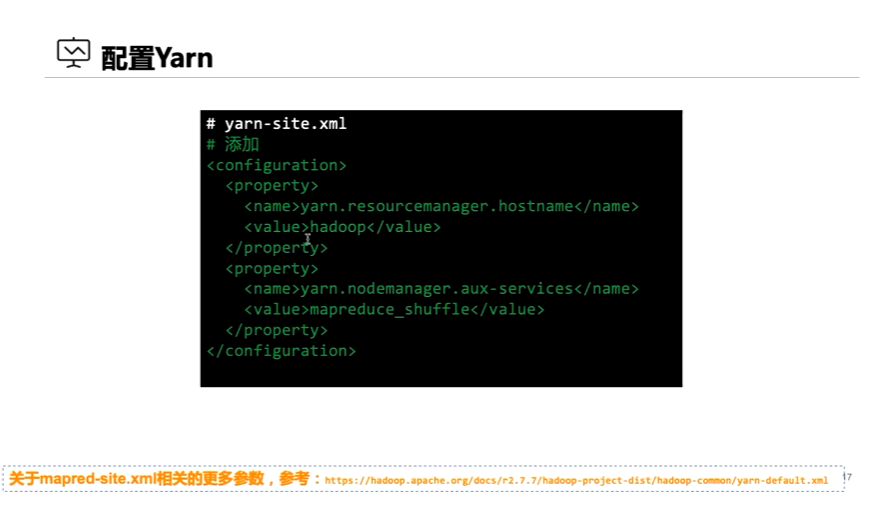
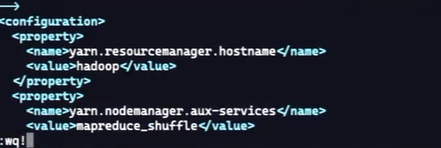
<configuration>
<property>
<name>yarn.resourcemanager.hostname</nam
<value>hadoop</value> #主机名字
</property>
<property>
<name>yarn.nodemanager.aux-services</nam
<value>mapreduce_shuffle</value>
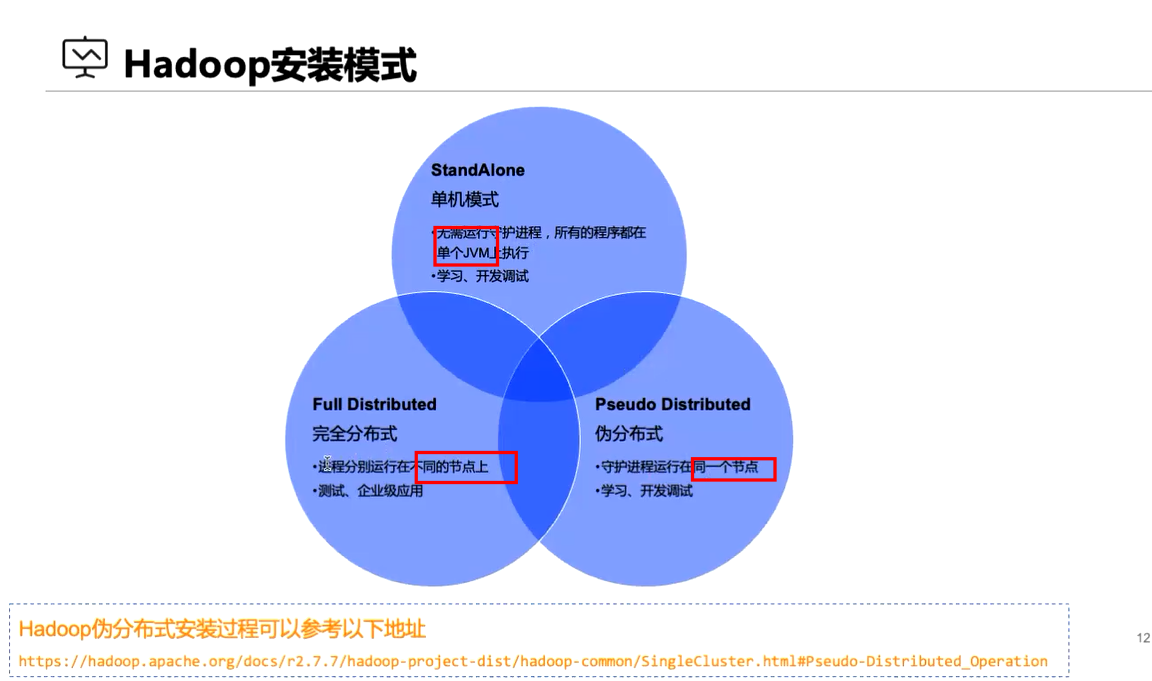
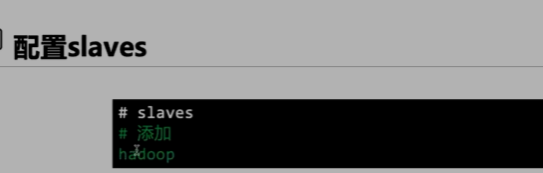
伪分布式配置slaves(简单版本)
伪分布式配置slaves是一种在单台计算机上模拟分布式计算的方法。在这种配置中,我们将单台计算机视为一个集群,然后在该计算机上启动多个slave节点来模拟多台计算机的情况。
为了配置伪分布式,我们需要安装和配置Hadoop和其他必要的软件。然后,我们需要在单台计算机上启动多个slave节点。这可以通过在不同的端口上启动多个Hadoop进程来实现。
在伪分布式配置中,所有的slave节点都运行在同一台计算机上,因此它们共享相同的资源,如内存和硬盘空间。这种配置适合于开发和测试Hadoop应用程序,但不适合生产环境。
需要注意的是,伪分布式配置不同于真正的分布式配置,因为它只是在单台计算机上模拟了分布式环境。在真正的分布式环境中,我们需要多台计算机来构建一个集群,并且每台计算机都运行着一个或多个slave节点。
直接在hadoop文件目录下配置
cd hadoop
vim slaves
添加主机的名字
格式化NameNode
格式化NameNode是指将Hadoop分布式文件系统(HDFS)上的NameNode节点的元数据清空,以便重新开始使用。这通常是在重新启动集群之前执行的操作。
hdfs namenode -format

启动hadoop
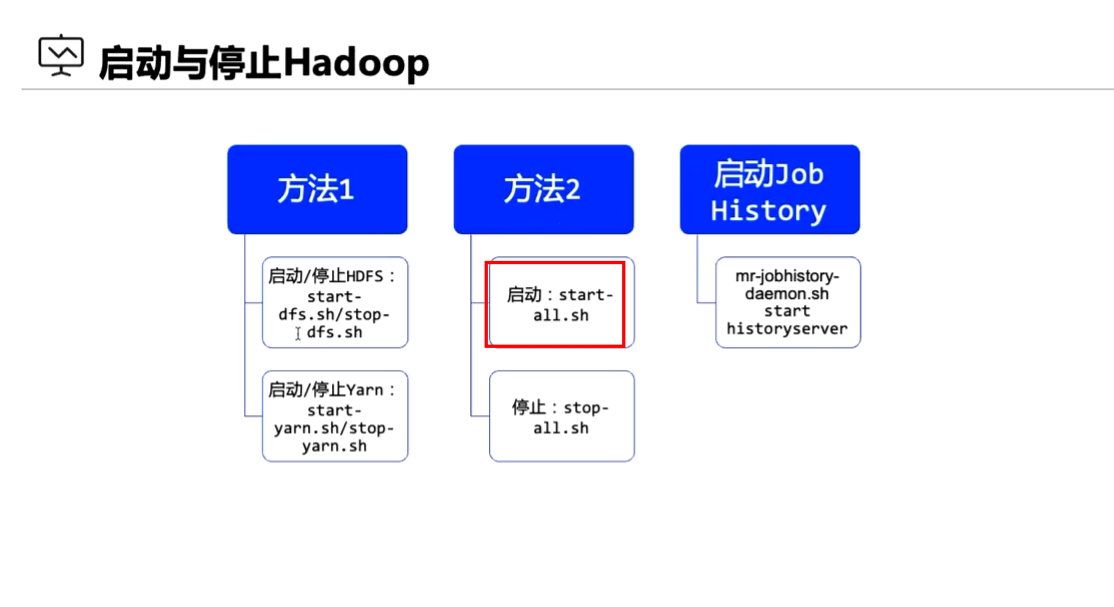
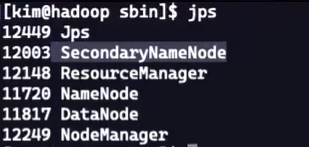
jps查看进程、
jps是Java Virtual Machine Process Status Tool的缩写,它是用于查看Java进程的命令行工具。jps命令可以显示当前系统中所有正在运行的Java进程的进程ID和进程名。
$ jps
12345 Jps
67890 MyJavaApp
ui界面
hdfs上传文件
hadoop fs -put /path/to/local/file /path/in/hdfs