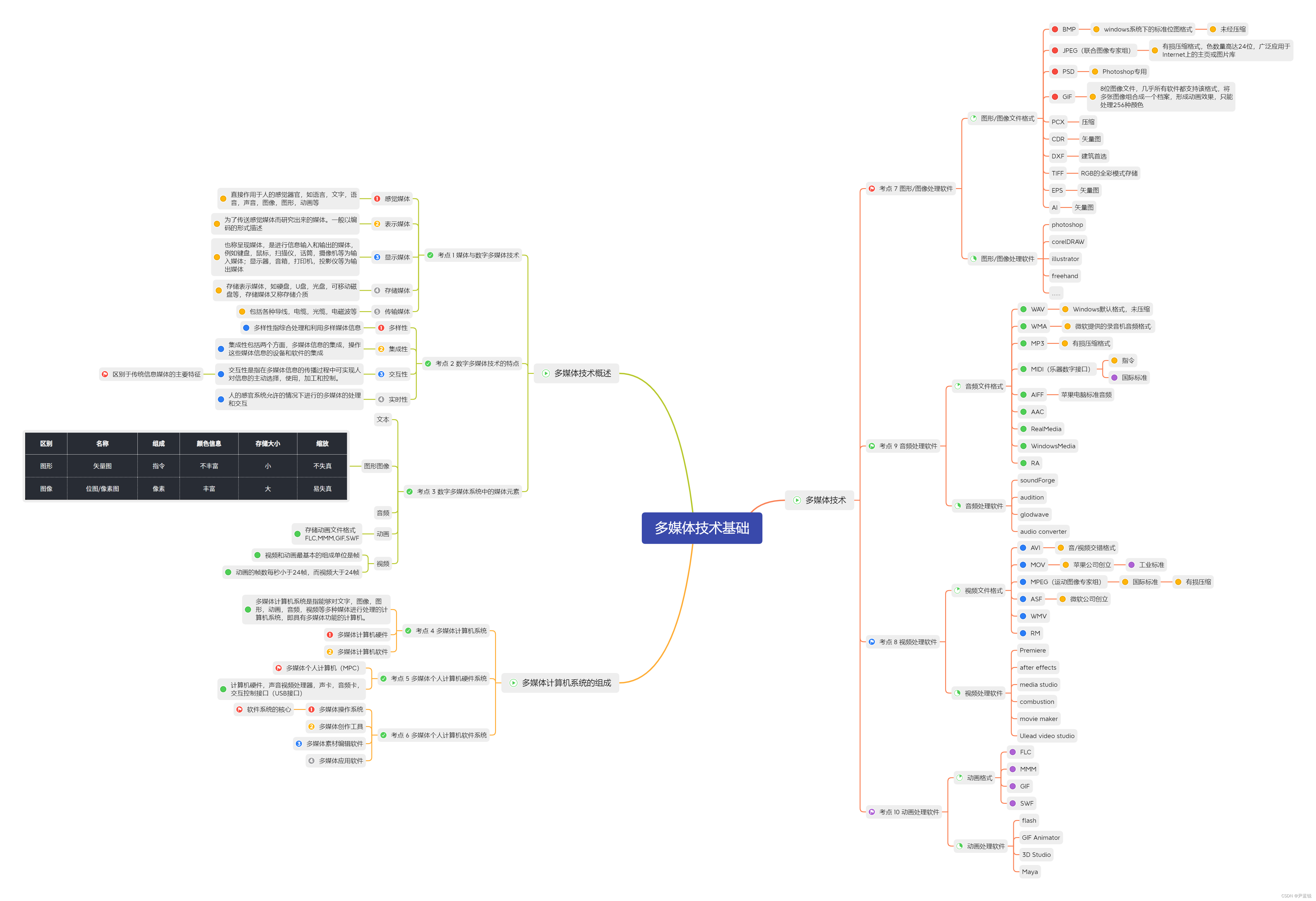
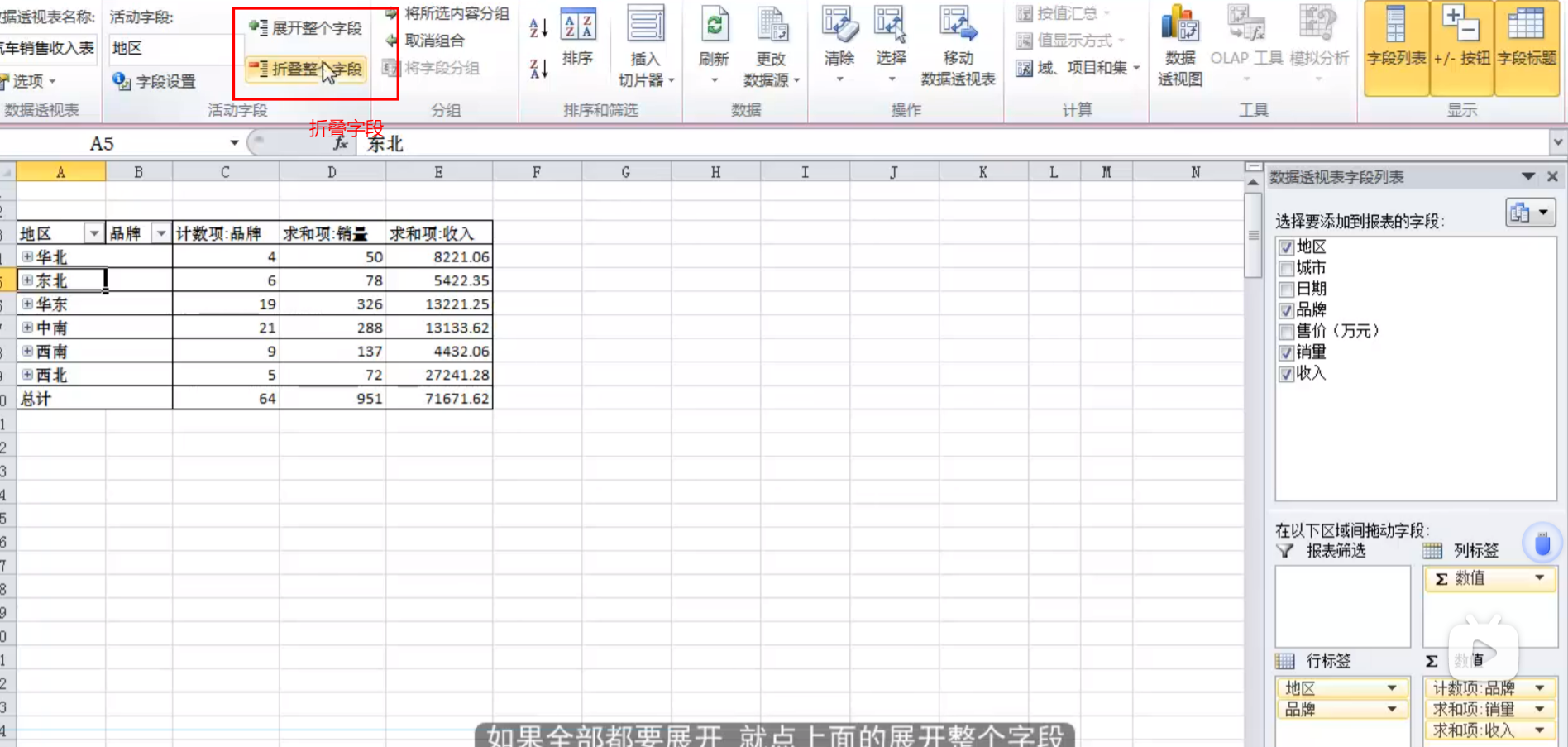
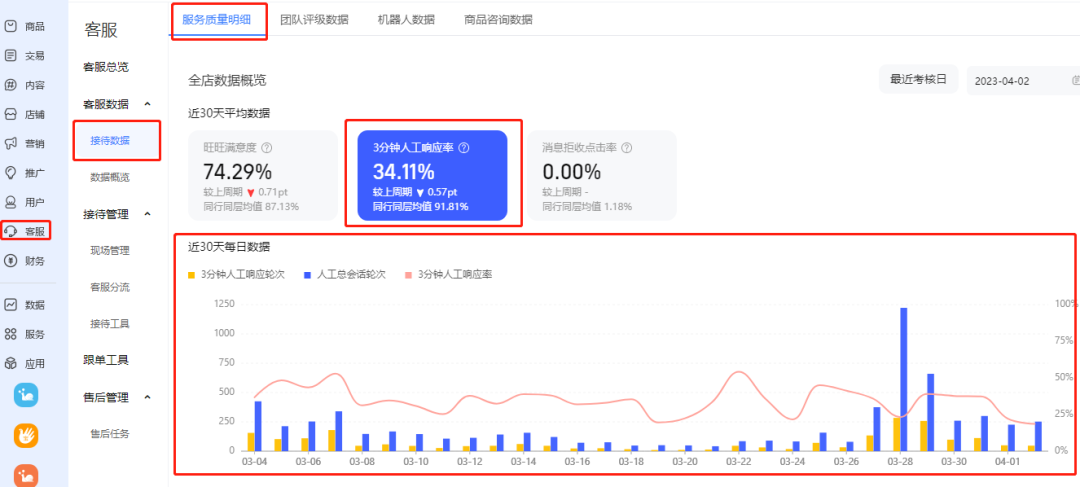
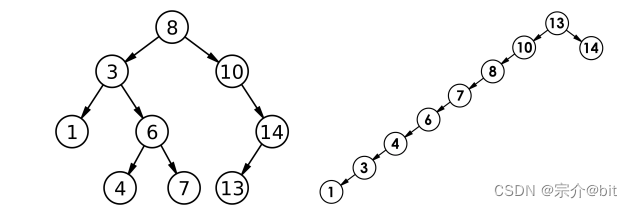
行为识别
行为检测是一个广泛的研究领域,其应用包括安防监控、健康医疗、娱乐等。
课程大纲
导论
图卷积在行为识别中的应用:论文研读,代码解读,实验
Topdown关键点检测中的hrnet:论文研读,代码解读,实验
行为识别的其它算法
深度学习中的重要组件:优化器,学习率策略
导论
主要算法简述
任务简述:
识别人体行为 action recognition
行为分类(classification),行为定位(localization),行为检测(detection)
识别人体行为(action recognition)是指从视频数据中自动识别出人体的行为活动。行为识别可以分为三个层次:行为分类(classification)、行为定位(localization)和行为检测(detection)。
-
行为分类(classification)
行为分类是指将整个视频序列划分为不同的行为类别,例如走路、跑步、开车等。这是行为识别中最基本的任务,也是最常见的任务。在行为分类中,通常会使用深度学习模型(如卷积神经网络、循环神经网络等)对视频序列进行建模,并使用softmax分类器对各个行为类别进行分类。行为分类的难点在于解决类内差异和类间相似性的问题,以及在不同场景和光照条件下的数据变化问题。 -
行为定位(localization)
行为定位是指在视频序列中定位出某个行为的发生时间段,例如在一个长时间的视频中,定位出某个人走路的具体时间段。行为定位比行为分类更具挑战性,因为它需要确定行为的开始和结束时间,而且同一个行为在不同的时间段里可能会有不同的表现。在行为定位中,通常会使用时间窗口的方法对视频序列进行分割,然后对每个时间窗口进行行为分类,最后通过时间对齐的方法确定行为的发生时间段。 -
行为检测(detection)
行为检测是指在视频序列中检测出某个特定行为的出现,例如检测出某个人是否在走路。行为检测通常需要使用目标检测等技术来定位出人体的位置,并使用行为分类技术对每个人体位置处的行为进行分类。行为检测的难点在于解决多人行为的检测问题,以及在复杂背景下的行为检测问题。
需要注意的是,行为识别面临许多挑战,例如数据量不足、数据噪声、类内差异和类间相似性等问题。为了提高行为识别的准确性,通常需要使用多种技术和模型进行结合,例如使用多种传感器数据、多种特征提取方法和多种深度学习模型进行融合。
数据模态:
外观appearance
深度depth
光流optical-flow
骨骼graph
时间维度t
遍历维度h,w,t
数据模态(data modality)指的是用于行为识别的数据类型,常用的数据模态包括外观、深度、光流和骨骼等。时间维度(time dimension)指的是视频数据中的时间轴,遍历维度(spatial dimensions)指的是视频数据中的图像尺寸,通常为高(height)和宽(width)。
-
外观(appearance)
外观模态是指从视频中提取的图像数据,通常使用深度卷积神经网络(Convolutional Neural Networks,CNN)对图像进行特征提取,并使用分类器对行为进行分类。外观模态可以通过使用不同的图像预处理方法来增加数据的多样性和鲁棒性,例如使用数据增强和迁移学习等方法。 -
深度(depth)
深度模态是指从深度相机或其他深度传感器中获取的数据,可以获得人体的三维姿态信息。深度模态可以使用深度卷积神经网络或其他深度学习模型进行处理,并与其他数据模态进行融合以提高行为识别的准确性。 -
光流(optical-flow)
光流模态是指从视频序列中提取的光流数据,光流是描述像素点在时间上的运动变化的一种方法。光流模态可以用于描述人体运动的速度和方向,通常使用光流特征和深度学习模型进行行为识别。 -
骨骼(skeleton)
骨骼模态是指从动作捕捉设备中获取的人体骨骼关节信息,可以获得人体的动态姿态信息。骨骼模态可以使用骨骼关节坐标和骨骼运动特征等方法进行处理,并与其他数据模态进行融合以提高行为识别的准确性。
在时间维度上,行为识别通常会对视频序列进行切割,形成不同的视频段。在遍历维度上,行为识别通常会使用卷积神经网络对视频帧进行特征提取,并使用循环神经网络(Recurrent Neural Networks,RNN)或卷积神经网络进行视频段级别的建模。为了提高行为识别的准确性,通常需要使用多种数据模态和处理方法进行融合。
算子扩展
Conv3d
GraphConv
- Conv3d
Conv3d是一种三维卷积操作,用于处理视频数据等三维数据。它类似于卷积神经网络中的二维卷积操作,但是Conv3d对于三维数据的特征提取更为有效。Conv3d操作通常由多个3D卷积核组成,每个卷积核在三个维度上分别进行卷积,从而提取出三维数据中的特征。
Conv3d的输入是一个四维张量,其维度分别为[batch_size, channels, depth, height, width],其中batch_size表示批量大小,channels表示通道数,depth表示深度,height表示高度,width表示宽度。Conv3d的输出也是一个四维张量,其维度与输入张量相同。
- GraphConv
GraphConv是一种用于图神经网络的卷积操作,用于处理图结构数据。与传统的卷积操作不同,GraphConv并不是在图像上进行滑动窗口的操作,而是在图的顶点上进行卷积操作。GraphConv利用图的邻接矩阵来描述顶点之间的关系,并将邻接矩阵作为卷积核来提取顶点的特征。
GraphConv的输入是一个二维张量,其维度为[batch_size, num_nodes, num_features],其中batch_size表示批量大小,num_nodes表示图的顶点数,num_features表示每个顶点的特征维度。GraphConv的输出也是一个二维张量,其维度与输入张量相同。
GraphConv可以应用于各种类型的图结构数据,例如社交网络、推荐系统、化学分子等。它可以有效地捕获顶点之间的关系,从而提高图神经网络的性能。

https://blog.csdn.net/weixin_44402973/article/details/103498856
光流方程
光流方程是描述光流的数学模型,它描述了图像中同一物体在不同帧之间的像素级运动状态。在光流法中,光流方程是基于光强不变假设推导出来的。
假设在第t帧中一个像素点的位置为(x,y),在第t+1帧中位置为(x+u,y+v),其中(u,v)表示像素点在x和y方向上的位移,光强不变假设认为这两个位置的像素点的灰度值是相等的。因此,可以得到光流方程:
I(x,y,t) = I(x+u,y+v,t+1)
其中,I(x,y,t)表示在第t帧中像素点(x,y)的灰度值,I(x+u,y+v,t+1)表示在第t+1帧中像素点(x+u,y+v)的灰度值。
使用泰勒展开对光强进行近似,可以得到:
I(x+u,y+v,t+1) ≈ I(x,y,t) + uIx + vIy + It
其中,Ix、Iy和It分别表示在像素点(x,y)处沿x、y和时间t方向的灰度梯度。
将上式代入光流方程中,可得到:
Ixu + Iyv = -It
这就是光流方程,它描述了像素在相邻帧中的运动状态,其中(u,v)表示像素点在x和y方向上的位移,Ix和Iy表示在像素点(x,y)处沿x、y方向的灰度梯度,It表示在相邻帧中像素点灰度的变化。
光流
光流(optical flow)是指在图像序列中,相邻两帧之间,同一物体在像素级别上的运动状态。光流法是一种基于像素级别的物体运动分析方法,它可以用于运动目标的跟踪、三维重建、视觉里程计等应用。
在光流法中,核心的假设是光强不变假设,即同一点在相邻帧中的光强不变。由此可以推导出光流方程,它描述了像素在相邻帧中的运动状态。光流方程的推导基于三个假设:光强不变假设、运动可微假设和区域一致性假设。
根据光强不变假设,同一点在相邻帧中的光强不变,可以使用一阶泰勒展开对光强进行近似。由此可以获得光流方程,它描述了像素在相邻帧中的运动状态。但是,光流方程只有一个方程,还无法求解。为了解决这个问题,可以构造点的邻域多个点的方程组,基于区域一致性假设,认为一点的邻域运动一致。这样,就可以得到多个方程,使用最小二乘法求解超定方程组,获得像素点的运动状态。
Lucas-Kanade光流法是一种稀疏光流方法,它使用像素点的邻域点来构造方程组,提高了求解光流的效率。对于每个像素点,只选择其邻域中的一些点来构造方程组,从而减少了求解的复杂度。
总之,光流法是一种基于像素级别的物体运动分析方法,它可以用于运动目标的跟踪、三维重建、视觉里程计等应用。
光流optical-flow
相邻帧物体运动趋势,
核心假设:
光强不变假设,同一点在相邻帧光强差分为0。环境光一致,引起光强变化的只有物体运动
运动可微,时间变化不引起位置突变
区域一致性,一点的邻域运动一致,相邻帧同一点的邻域近似( Lucas-Kanade光流法,稀疏光流)
一阶泰勒展开
指高阶无穷小
基于,获得光流方程
除以dt,dt可认为是1,获得
关注 ,是像素点p(x,y)在t时刻沿着x,y方向的运动速度
此时只有一个方程,还无法求解
类同上述方法,构造点P(x,y)邻域多个点的一组方程,
基于假设3邻域运动一致性,有一致, 为相邻帧灰度变化
可对一点的邻域多个点,联立获得方程组
和是单帧灰度图在x,y方向的偏导,可使用sobel算子计算
是相邻帧灰度图差分
例如1个中心点,8个邻域点,共9个方程,即3*3窗口内运动一致
此时有两个待求解参数,这是一个超定方程组,可使用最小二乘法等求解
参考资料:
光流法(optical flow methods) - 知乎 (zhihu.com)
https://zhuanlan.zhihu.com/p/384651830
图源:
光流估计——从传统方法到深度学习 - 知乎 (zhihu.com)
A Comprehensive Study of Deep Video Action Recognition
https://zhuanlan.zhihu.com/p/74460341

骨骼skeleton
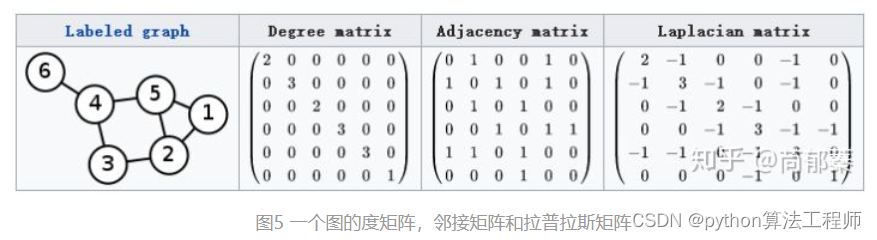
在人体骨骼关键点的场景中,可以使用无向图G来表示骨骼的拓扑结构,其中点V表示人体的关键点,边E表示骨骼之间的连接关系。邻接矩阵A可以用来表示图中点之间的连接情况,其中A(i,j)表示点i和点j之间是否有连接,如果有连接则为1,否则为0。
对于人体关键点,每个关键点可以表示为一个二元组[k,p],其中k表示关键点的标识,p表示关键点的位置信息。位置信息可以使用二维坐标 (x,y) 或三维坐标 (x,y,z) 来表示,其中 x、y 和 z 分别表示关键点在空间中的 x、y 和 z 坐标,c 表示关键点的置信度或可见度。
连接的边长可以表示骨骼之间的距离,可以使用欧几里得距离或其他距离度量来计算。在邻接矩阵中,可以将边长作为权重来表示,即 A(i,j) 表示点i和点j之间的边权重,如果没有连接则为0。这样可以更准确地表示关键点之间的连接情况和距离关系。
无向图G
点V
边E
邻接矩阵A,
邻接为1,不考虑权重
人体关键点: [k,p], p=[x,y,c]或[x,y,z]
邻接矩阵:
所有点两两连接(外积)
连接的边长
右图有什么问题?
0代表断开还是距离为0,v和v自身连接如何表示?
在右图中,邻接矩阵中的0表示两个点之间没有边连接,1表示有边连接。因此,如果一个点与自身相连,则对应的邻接矩阵元素应该为1。在人体关键点的情况下,如果一个关键点与自身相连,则表示该关键点存在自连接,可以使用1来表示。如果一个关键点与另一个关键点没有连接,那么这两个关键点之间的邻接矩阵元素应该为0,而不是表示距离为0。
对于连接的边长,可以将其作为权重进行表示,可以考虑使用带权邻接矩阵来表示图,其中矩阵元素表示对应边的权重。如果两个关键点之间没有连接,则对应的邻接矩阵元素为0,表示它们之间没有边连接,也没有权重。
图源:
https://zhuanlan.zhihu.com/p/89503068
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
算子扩展

 https://zhuanlan.zhihu.com/p/63974249
https://zhuanlan.zhihu.com/p/63974249
im2col 方法是一种将卷积运算转化为矩阵乘法的方法,在卷积神经网络中被广泛使用。其实现步骤如下:
- 对输入图像进行补零操作,使得卷积后输出的大小与输入大小相同。补零的大小由卷积核大小和步幅决定。
- 对补零后的输入图像进行滑动窗口操作,将每个窗口中的像素按照列优先的方式排列成一个列向量,形成一个二维矩阵。这个矩阵的每一列对应于一个滑动窗口中的像素。
- 将所有滑动窗口中的列向量拼接成一个大矩阵,每一列对应于一个滑动窗口中的像素。
- 将卷积核中的元素按照行优先的方式排列成一个行向量,形成一个二维矩阵。这个矩阵的每一行对应于卷积核中的一个元素。
- 对于每个卷积核大小的窗口,在步骤3生成的大矩阵中,选取对应的列向量,将其按行排列成一个行向量。这样得到的矩阵的每一行对应于一个卷积核大小的窗口。
- 对于每个卷积核大小的窗口,将其对应的行向量与卷积核矩阵相乘,得到一个标量。这样得到的标量构成了输出矩阵中的一个元素。
- 将输出矩阵进行重塑,得到输出图像。
这样,通过将卷积运算转化为矩阵乘法,可以利用矩阵乘法的高效性和并行性,加速卷积神经网络的计算过程。
-
im2col的反向计算是col2im。在反向传播时,需要将误差传递回输入数据中,col2im就是将误差转换回输入数据的过程。具体步骤如下:
1)将误差张量重排为二维矩阵,每一列对应于im2col中的一列。
2)将卷积核重排为二维矩阵,每一行对应于im2col中的一行。
3)将二维误差矩阵和二维卷积核矩阵相乘,得到二维输出矩阵。
4)将输出矩阵重排为输入数据的形状,即使用与im2col中相同的窗口大小和步幅,按照列优先的方式将输出矩阵转换为输入数据张量的形状。 -
进行图像仿射增强(旋转)的目的是为了增加数据的多样性和增强模型的泛化能力。通过旋转图像,可以得到更多的训练数据,从而使模型更好地学习图像特征。对于卷积神经网络中的卷积核,如果图像被旋转了,卷积核也应该随之旋转,这样才能更好地识别图像中的特征。因此,在进行图像旋转时,卷积神经网络中的卷积核参数也需要进行旋转,并重新训练模型,以获得更好的性能。
反映在filter参数上的特征是,经过旋转后的卷积核参数不再具有原来的对称性和平移不变性,因此需要更多的参数来表示卷积核,以适应旋转后的图像特征。在旋转图像时,需要重新训练卷积神经网络中的卷积核参数,以适应旋转后的图像特征。
图卷积神经网络
图卷积神经网络(Graph Convolutional Networks,简称GCN)是一种能够处理图数据的神经网络模型。与传统的卷积神经网络不同,GCN能够处理非欧几里得结构的数据,如社交网络、蛋白质分子结构等,具有广泛的应用前景。
GCN的核心思想是在图上进行卷积操作,将节点的特征表示传递给其邻居节点,并进行加权求和。具体来说,GCN中的每个节点都有一个特征表示,这个特征表示可以是节点自身的特征向量,也可以是由节点的邻居节点的特征向量组成的聚合特征向量。GCN通过对每个节点的特征向量进行线性变换和非线性变换,得到每个节点的新特征向量。这个过程可以看作是将节点的特征表示映射到一个更高维度的空间中,并在这个空间中进行卷积操作。
具体来说,GCN的卷积操作可以表示为:
H ( l + 1 ) = σ ( D ^ − 1 2 A ^ D ^ − 1 2 H ( l ) W ( l ) ) H^{(l+1)} = \sigma(\hat{D}^{-\frac{1}{2}}\hat{A}\hat{D}^{-\frac{1}{2}}H^{(l)}W^{(l)}) H(l+1)=σ(D^−21A^D^−21H(l)W(l))
其中, H ( l ) H^{(l)} H(l)表示第 l l l层GCN中所有节点的特征矩阵, A ^ \hat{A} A^是一个带自环的邻接矩阵, D ^ \hat{D} D^是 A ^ \hat{A} A^的对角线矩阵, σ \sigma σ是非线性激活函数, W ( l ) W^{(l)} W(l)是第 l l l层GCN的权重矩阵。这个公式表示将节点的特征矩阵 H ( l ) H^{(l)} H(l)通过一个线性变换 W ( l ) W^{(l)} W(l)映射到一个新的特征空间中,然后通过邻接矩阵 A ^ \hat{A} A^计算节点之间的邻接关系,将节点的特征向量传递给邻居节点,并进行加权求和。最后,通过非线性激活函数 σ \sigma σ将这个加权和映射回原始特征空间,得到每个节点的新特征向量 H ( l + 1 ) H^{(l+1)} H(l+1)。
GCN的训练过程通常使用反向传播算法进行优化,目标是最小化损失函数,以提高模型的泛化能力。
图卷积神经网络(GCN)的出现是为了解决图数据处理的问题。传统的神经网络模型(如全连接神经网络、卷积神经网络等)只能处理欧几里得结构的数据,即数据在空间上具有规则的网格结构。而对于图数据,其节点之间的连接关系是任意的、不规则的,因此无法直接应用传统的神经网络模型进行处理。
GCN的出现恰好填补了这一空白。GCN可以通过图卷积操作在节点之间传递和聚合信息,并在此基础上提取图的特征表示,从而可以用于图数据的分类、聚类、链接预测等任务。
除了传统神经网络无法处理图数据这一问题,还有一些其他的原因促成了图卷积神经网络的出现:
-
图数据的稀疏性:在图数据中,节点之间的连接关系是任意的,这就导致图数据通常是稀疏的。而传统的神经网络模型需要密集的连接参数,这就导致了传统神经网络难以处理稀疏的图数据。GCN使用的邻接矩阵可以有效地处理稀疏性问题。
-
图数据的不变性:在图数据中,节点的标号是任意的,这就导致了节点的相对位置可能发生变化,从而导致传统的神经网络模型很难应对。GCN使用的卷积操作是基于邻接矩阵的,可以保证在不同图中相同的节点具有相同的特征表示,从而具有一定的不变性。
-
图数据的非平凡性:与传统的欧几里得结构的数据不同,图数据中的每个节点都是独立的,且每个节点的特征向量可能具有不同的维度。这就导致了传统的神经网络模型很难处理图数据中的非平凡性。GCN使用的卷积操作可以在不同的节点之间共享权重,从而有效地处理图数据中的非平凡性问题。
因此,图卷积神经网络的出现是为了解决图数据的处理问题,GCN具有对图数据进行有效的特征表示和学习的能力,能够在图数据的分类、聚类、链接预测等任务中取得较好的性能。
Conv3d : cincout(dhw)
3d数据:d-depth
时序数据:d-time
Kernel : cin*(d,k,k)
Filter : cout*(cin,d,k,k)
GraphConv,一般只考虑距离为1的邻接点
Image描述为graph:
可获得:
点集{V}={RGB(x,y)}
边集{E}:{P(x,y)邻接p(x1,y),p(x,y±1)},角点各有2个邻接点,边点各有3个邻接点,其它点各有4个邻接点
Conv2d描述为GraphConv:
假设一个conv2d的kernel,角点=0,其它点=1/5,则卷积过程等价于将一个像素与上下左右四个邻接点做平均
等价于用GraphConv对点P和邻接点{p(x1,y),p(x,y±1)}做图卷积

图源:从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (二) - 知乎 (zhihu.com)
算子扩展:
GraphConv
节点的特征向量H
邻接矩阵A,邻接=1,不考虑权重
度矩阵D,邻接点数
拉普拉斯矩阵L,D-A
激活函数σ
特征聚合计算方法
-
H’ = σ(A@H),存在什么问题?
维度变换:(k,p) = (k,k) @ (k,p)
L = D-A -
H’ = σ(L@H@W),存在什么问题?
-
L’ = ,可简单理解为度矩阵的逆与邻接矩阵的矩阵乘积
-
H’ = σ(A@H)存在什么问题?
在这种情况下,特征聚合的计算方法是直接将邻接矩阵A与特征矩阵H做矩阵乘法,得到新的特征矩阵H’。这种方法存在一个问题,就是它没有考虑到节点的度数信息,节点的度数对特征的聚合和传递有着重要的影响。在这种情况下,节点的度数越大,邻居节点对该节点的特征聚合的影响就越大,但是直接使用邻接矩阵进行特征聚合无法反映这种影响。 -
H’ = σ(L@H@W)存在什么问题?
在这种情况下,特征聚合的计算方法是将拉普拉斯矩阵L与特征矩阵H做矩阵乘法,并乘以权重矩阵W,得到新的特征矩阵H’。这种方法考虑了节点的度数信息,因为拉普拉斯矩阵中的度矩阵D反映了节点的度数信息。但是,这种方法存在一个问题,就是它没有考虑到节点的自身特征信息,因为特征矩阵H直接乘以拉普拉斯矩阵L,没有对特征矩阵进行变换。这可能会导致模型对节点自身特征的处理不足,影响模型的性能。 -
L’ = D^-1/2 * A * D^-1/2可简单理解为度矩阵的逆与邻接矩阵的矩阵乘积
在这种情况下,特征聚合的计算方法是先将邻接矩阵A通过度矩阵D的逆矩阵进行归一化处理,得到新的邻接矩阵L’,然后将L’与特征矩阵H做矩阵乘法,并乘以权重矩阵W,得到新的特征矩阵H’。这种方法综合考虑了节点的度数信息和节点自身特征信息,因为它同时考虑了邻接矩阵和度矩阵。这种方法的性能要优于上述两种方法,因为它能够更好地反映节点的特征聚合和传递过程。
主流算法
基于双流网络
双流网络是一种常用于视频行为识别的深度学习模型,它使用两个并行的卷积神经网络来处理视频的两个输入流:图像流和光流流。
图像流是由视频的一系列帧组成的,它提供了视频中静态的外观信息。光流流是通过计算相邻帧之间的像素运动而得到的,它提供了视频中动态的运动信息。
在双流网络中,每个输入流都有自己的卷积神经网络,这些网络通常具有不同的结构和参数。例如,图像流可以使用常规的卷积神经网络,例如VGG、ResNet等,而光流流通常使用光流估计算法提取光流特征,并使用3D卷积神经网络来处理光流张量。然后,两个流的特征可以合并并输入到全连接层中进行分类。
双流网络的优点是它可以利用视频中的静态和动态信息,并且在行为识别任务中表现出了优异的性能。它已经在许多视频行为识别任务中得到了广泛的应用,例如人类行为识别、交通行为识别和手势识别等。
基于双流网络的深度学习方法可以用于行为识别,它是一种利用RGB图像和光流图像的双流模型。光流是指一个像素在相邻两帧图像中的运动轨迹,它可以提供物体的运动信息。在双流网络中,RGB图像和光流图像分别输入到两个卷积神经网络中进行处理,然后将它们的特征合并起来进行分类,以实现对行为的识别。
以下是一些基于双流网络的行为识别的深度学习应用的例子:
-
人体行为识别:基于双流网络的深度学习方法可以用于人体行为识别,例如识别跑步、跳跃、打拳等行为。这种方法通常使用卷积神经网络和循环神经网络进行处理。
-
交通行为识别:基于双流网络的深度学习方法可以用于交通行为识别,例如识别汽车、行人、自行车等交通工具的行为。这种方法通常使用卷积神经网络和循环神经网络进行处理。
-
动作识别:基于双流网络的深度学习方法可以用于动作识别,例如识别手势、面部表情等动作。这种方法通常使用卷积神经网络和循环神经网络进行处理。
需要注意的是,基于双流网络的深度学习方法需要大量的训练数据和计算资源,同时需要特别注意数据预处理、数据增强和模型的选择等问题。此外,基于双流网络的深度学习方法在实际应用中还存在一些挑战,例如如何处理光流图像和如何选择合适的网络结构等问题。
基于3d模型
3D卷积神经网络(3D CNN)是一种深度学习模型,用于处理3D数据,例如视频、医学图像和3D物体等。它们是2D CNN的拓展,可以在视频或3D图像的三个维度上执行卷积运算。
3D CNN的基本结构与2D CNN类似,包括卷积层、池化层和全连接层。在卷积层中,3D CNN使用3D卷积核来卷积3D张量。在池化层中,我们使用3D池化核来对3D张量进行池化操作。在全连接层中,我们将3D张量转换为一维向量,并将其输入到全连接层中进行分类或回归。
当我们处理3D数据时,可以使用基于3D卷积神经网络(3D CNN)的深度学习模型。与2D CNN类似,3D CNN也使用卷积层和池化层来提取3D数据中的特征,并使用全连接层来分类或回归。
3D CNN的输入是一个三维张量,通常是由多个3D图像组成的。类似于2D CNN,3D CNN也可以通过堆叠多个卷积层和池化层来增加网络的深度。在卷积层中,我们使用3D卷积核来卷积3D张量。在池化层中,我们使用3D池化核来对3D张量进行池化操作。
在训练3D CNN时,我们可以使用与2D CNN类似的方法,例如随机梯度下降(SGD)和反向传播算法。同时,我们还可以使用其他进阶的优化算法,例如Adam和Adagrad等。
3D CNN常常被用于处理3D数据,例如视频、3D物体和医学图像等。它们在行为识别、物体识别和医学图像分割等领域都有广泛的应用。
基于3D模型的深度学习方法可以用于行为识别,它是一种利用视频序列中的3D信息进行行为识别的方法。与基于2D模型的方法不同,基于3D模型的方法可以直接利用视频中的空间信息,从而能够更好地捕捉物体的运动和行为。
以下是一些基于3D模型的行为识别的深度学习应用的例子:
-
人体行为识别:基于3D模型的深度学习方法可以用于人体行为识别,例如识别跑步、跳跃、打拳等行为。这种方法通常使用3D卷积神经网络进行处理。
-
交通行为识别:基于3D模型的深度学习方法可以用于交通行为识别,例如识别汽车、行人、自行车等交通工具的行为。这种方法通常使用3D卷积神经网络进行处理。
-
动作识别:基于3D模型的深度学习方法可以用于动作识别,例如识别手势、面部表情等动作。这种方法通常使用3D卷积神经网络进行处理。
需要注意的是,基于3D模型的深度学习方法也需要大量的训练数据和计算资源,同时需要特别注意数据预处理、数据增强和模型的选择等问题。此外,基于3D模型的深度学习方法还存在一些挑战,例如如何处理不同尺度的3D模型、如何处理运动模糊等问题。
基于2d模型+时序模型
基于2D模型+时序模型的行为识别算法通常是指将2D图像和时间序列信息结合起来进行行为识别的方法。该算法包括两个主要步骤:首先,使用2D卷积神经网络(CNN)从每个视频帧中提取特征。其次,使用时序模型(例如循环神经网络,LSTM等)将提取的特征序列建模为行为序列,并对其进行分类或回归。
具体来说,基于2D模型+时序模型的行为识别算法可以分为以下步骤:
-
数据预处理:对视频进行预处理,例如裁剪、缩放和标准化等操作,以便于后续处理。
-
特征提取:使用2D CNN从视频帧中提取特征。可以使用预先训练好的2D CNN模型(例如VGG,ResNet等),也可以自己训练一个特定于任务的2D CNN模型。
-
特征序列建模:使用时序模型将2D CNN提取的特征序列建模为行为序列。可以使用LSTM、GRU等循环神经网络模型,也可以使用卷积LSTM等结合卷积和LSTM的模型。
-
行为分类或回归:使用全连接层将时序模型的输出映射到类别标签或回归值上。
基于2D模型+时序模型的行为识别算法通常需要大量的训练数据和计算资源。此外,需要特别注意数据预处理、数据增强和模型的选择等问题,以及如何处理不同尺度和运动模糊等问题。
基于骨架的图模型
基于骨架的图模型的行为识别算法是一种利用人体骨架信息进行行为识别的方法。该算法首先从视频中检测出人体骨架信息,然后将骨架信息转换为图模型,最后使用图神经网络对图模型进行建模和分类。
具体来说,基于骨架的图模型的行为识别算法可以分为以下步骤:
-
数据预处理:对视频进行预处理,例如裁剪、缩放和标准化等操作,以便于后续处理。
-
骨架检测:使用人体骨架检测算法(例如OpenPose)从视频中提取人体骨架信息。
-
图模型构建:将每个骨架节点转换为图模型中的节点,并连接相邻的节点,构建骨架图模型。可以根据不同需求选择不同的图模型,例如基于邻接矩阵的图模型或基于边列表的图模型等。
-
图神经网络建模:使用图神经网络对骨架图模型进行建模。可以使用基于GCN(图卷积网络)或GAT(图自注意力网络)的图神经网络模型。
-
行为分类:使用全连接层将图神经网络的输出映射到类别标签上。
基于骨架的图模型的行为识别算法可以利用人体骨架信息,不受视频中的光照、背景等因素的影响,因此具有较好的鲁棒性。此外,图神经网络可以对不同的节点和边进行建模,因此可以更好地捕捉骨架中的关节运动和姿态信息,提高行为识别的准确率。
需要注意的是,基于骨架的图模型的行为识别算法需要大量的训练数据和计算资源,同时需要特别注意数据预处理、数据增强和模型的选择等问题,以及如何处理不同动作速度和姿态变化等问题。
slowfast
SlowFast是一种用于视频行为识别的深度学习模型,由Facebook AI Research提出。它结合了慢速和快速两个流程,以提高对视频中快速动作和细节的捕捉能力。SlowFast模型由两个部分组成:慢速骨干网络和快速骨干网络。
慢速骨干网络处理低频信息,例如物体的整体移动和姿态变化,以较低的帧率处理视频。它通常采用较深的2D CNN模型(例如ResNet)来提取特征。快速骨干网络处理高频信息,例如物体的细节和文物,以较高的帧率处理视频。它通常采用较浅的2D CNN模型(例如VGG)来提取特征。
SlowFast模型的主要优点包括:
-
高效的特征提取:通过分层处理视频,SlowFast模型可以高效地提取视频中的关键特征,从而提高行为识别的准确率。
-
对快速动作和细节的敏感度:采用慢速和快速两个流程可以有效地捕捉视频中的快速动作和细节,从而提高行为识别的准确率。
-
可扩展性:SlowFast模型可以轻松地应用于不同的视频行为识别任务,例如动作分类、动作检测和行为定位等。
需要注意的是,使用SlowFast模型进行行为识别需要大量的训练数据和计算资源,同时需要特别注意数据预处理、数据增强和模型的选择等问题,以及如何处理不同尺度和运动模糊等问题。
st-gcn
ST-GCN是一种基于时空图卷积神经网络(Spatial-Temporal Graph Convolutional Network)的视频行为识别模型,它可以对人体骨骼运动进行建模并进行行为分类。ST-GCN模型可以捕捉人体骨骼运动中的时空关系,从而更好地表征人体运动特征。
ST-GCN主要包括三个部分:时空图的构建、时空图卷积神经网络和分类器。
-
时空图的构建:首先,将人体骨骼运动序列转化为时空图结构,每个节点代表一个骨骼关键点,每条边代表不同关键点之间的相连关系。然后,根据关键点之间的距离和时间上的关系,构建时空图。
-
时空图卷积神经网络:将构建好的时空图输入到ST-GCN的卷积神经网络中,其中每个节点表示一个骨骼关键点,每个时空图卷积层都包含时空卷积和相应的非线性激活函数。通过多层时空图卷积网络的堆叠,可以有效地提取时空特征。
-
分类器:最后,使用全局池化操作将时空图卷积网络的输出转换为固定长度的特征向量,然后使用全连接层将其映射到行为类别上进行分类。
ST-GCN模型具有以下优点:
-
能够有效地捕捉人体骨骼运动的时空关系,提高行为分类的准确性。
-
可以处理不同数量的关键点和不同长度的骨骼运动序列。
-
模型参数相对较少,具有较高的计算效率。
需要注意的是,使用ST-GCN模型进行行为识别需要大量的训练数据和计算资源,同时需要特别注意数据预处理、数据增强和模型的选择等问题,以及如何处理不同尺度和姿态变化等问题。
Topdown-heatmap关键点检测下的Hrnet
数据模态
数据模态:
Rgb图像=>人体检测框对中图像
保存框中心坐标center,以及宽高wh(缩放scale),用于将结果映射回原图(decode)
算子扩展
算子扩展:
Conv2d(stride=2,…),缩小2倍图像尺寸
Conv2d(ksize=1,…),保持原图尺寸,只做通道变换
Conv2d(dilation=2,…),膨胀卷积/空洞卷积,在卷积核行/列插入dilation-1行/列0值
Conv2d(group=k,…),分组卷积,输入通道分k组,输出通道分k组
(深度可分离卷积:Conv2d(group=n,…)+Conv2d(kernelsize=1,…))
Conv2dtranspose(inchannel,outchannel,stride,pad,…),转置卷积(反卷积deconvolution)
在输入图行/列插入stride-1行/列0值
减去pad边
Pool2d/unpool2d
参考资料:
conv_arithmetic/README.md at master · vdumoulin/conv_arithmetic (github.com)
常规卷积
Conv2d(stride=2,…),缩小2倍图像尺寸
Pool2d(stride=2,…),缩小尺寸,增大感受野,不会改变通道数
Backward
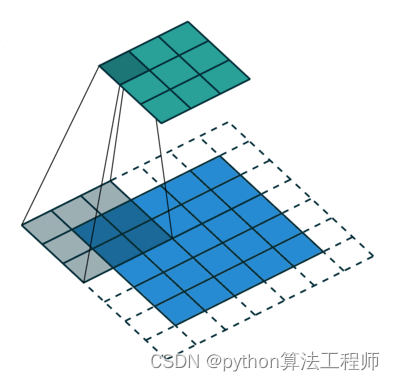
图像尺寸:
感受野计算(第T层在第i层的感受野大小,i从0开始,即原始图像):
Conv1 = conv2d(3,3,1), conv2=conv2d(3,3,1)
Feature0=7, feature1=3, feature2=1
第2层在第1层的感受野:3 = (1-1)*1+3
第2层在第0层的感受野:5 = (3-1)*1+3
常规卷积
Conv2d(ksize=1,pad=0,…),保持原图尺寸
可用于通道转换(对齐,…)
可用于输出头,代替linear做像素粒度的输出
全连接层限制输入尺寸
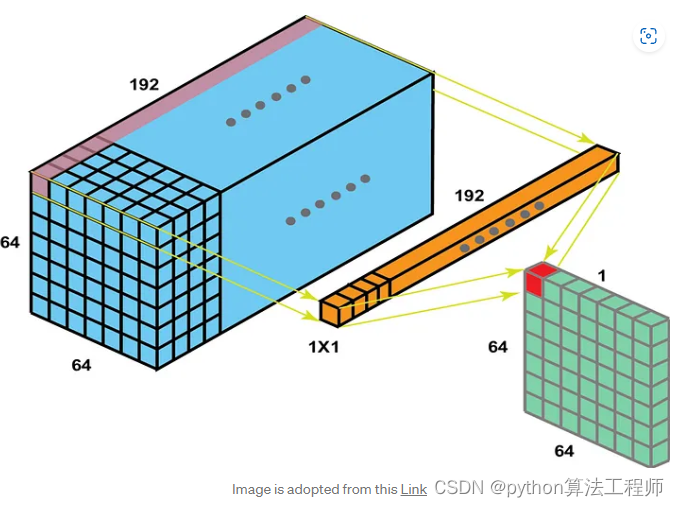
图源:
1X1 Convolution, CNN, CV, Neural Networks | Analytics Vidhya (medium.com)
膨胀卷积/空洞卷积
Conv2d(dilation=2,…),在卷积核行/列插入dilation-1行/列0值
Im2col计算方法类同conv2d
增大感受野(reception field)
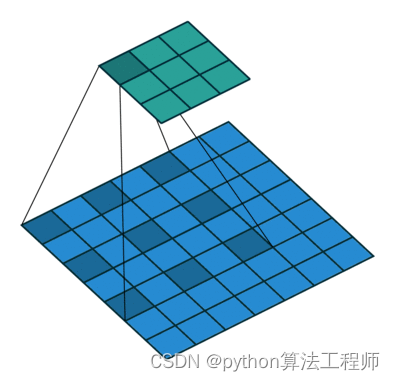
分组卷积
Conv2d(group=k,…),分组卷积,输入通道分k组,输出通道分k组
(深度可分离卷积:Conv2d(group=n,…)+Conv2d(kernelsize=1,…))
Conv2d参数量:
分组卷积参数量:
=>
深度可分离卷积:depthwise-conv + pointwise-conv
当 时,分组卷积成为depthwise-conv,设
当ksize=1时,常规卷积成为pointwise-conv,参数量
这种通道维度和空间维度分别扫描的思路,也适用于其它轻量化算子
转置卷积
不是严格意义上的反卷积(deconvolution):只还原尺寸,不还原参数
Conv2dtranspose(stride,pad,…)
- Kernel与之前的对应的卷积层一致
- Stride不指卷积核滑动步长,而是指插入0值行列数量:
- 在输入图行/列插入stride-1行/列0值
- 卷积核滑动步长恒定为1
- Pad是减去边,而不是加上边
- Kernel将在超出图像边界处扫描,最远保持1行/列扫描到
使用双线性插值初始化卷积核
Img —conv2d(ksize=3,stride=2,pad=1)—>mid_img—conv2dtranspose(ksize=3,stride=2,pad=1)—>img_rec
Imgsize(i):
池化
Pool2d(stride=2),下采样,增大感受野。avg/max?
输出池化值和局部坐标
反池化(Max)
Unpool2d
接受池化值和局部坐标
仅还原最大值在原图的坐标,其它值舍去
池化和反池化都将导致尺寸还原过程中的信息损失

图源:
MaxUnpool2d — PyTorch 2.0 documentation
融合方式
融合方式(fuse)
拉平拼接
相加
通道拼接
后融合:
logits/prob融合,直接相加
特征融合:
单流/多流
单跳/稠密
Block内/block间
对齐方式
通道对齐(conv2d(ksize=1))
尺寸对齐(interpolate, conv2d/conv2dtranspose, pool/unpool)
Topdown-heatmap
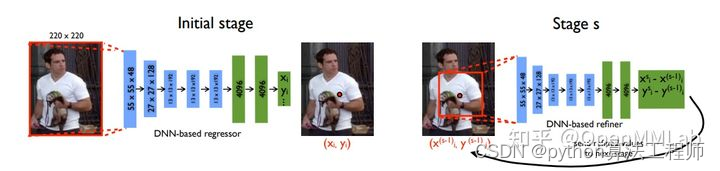
https://zhuanlan.zhihu.com/p/394060630
原图目标检测模型
人体框图(保留框中心坐标和框长宽)
符合关键点模型输入尺寸的人体对中图关键点模型
下采样热力图,每个通道对应一个关键点的热力图,最大值处即为关键点估计坐标
基于下采样倍率和关键点估计坐标的邻域值,还原人体对中图中的关键点坐标
基于框中心坐标和框长宽,还原原图中的关键点坐标
Top-down heatmap是一种基于人体姿态估计的方法,通过生成人体关键点热度图(heatmap)的方式来预测人体姿态。
具体来说,该方法首先将图像输入到卷积神经网络中进行特征提取,然后在最后一层卷积层的输出上生成多个人体关键点的热度图,其中每个热度图对应一个关键点。每个热度图中的值表示该关键点在图像中的可能位置,值越大表示该位置越可能是该关键点的位置。然后,根据这些热度图,可以使用一些特定的算法或者模型提取出每个关键点的位置,从而得到人体姿态的估计结果。
Top-down heatmap方法的优点是能够很好地处理遮挡、姿态变化等情况,同时具有较好的准确性和鲁棒性。但是,该方法对于多人姿态估计和关键点匹配问题还存在一定的挑战。因此,近年来,一些新的方法如Bottom-up heatmap等也逐渐受到关注。
Hrnet论文流程解析
HRNet(High-Resolution Network)是一种用于图像分类和目标检测的深度神经网络模型,由北京大学计算机视觉实验室提出。相比于传统的深度神经网络,HRNet在保持高分辨率特征图的同时,通过多个分支网络进行特征融合,从而提高了模型的准确性。
以下是HRNet论文的主要流程解析:
-
高分辨率特征提取:HRNet采用了高分辨率输入和高分辨率特征提取的策略,即将输入图像的分辨率保持在较高水平,同时使用多个分支网络提取不同尺度的特征。
-
多尺度特征融合:HRNet通过多个分支网络提取不同尺度的特征,并采用一种高效的特征融合方法将这些特征融合为一个高质量的特征表示。具体来说,HRNet将分支网络中的特征进行级联或相加操作,从而进行特征融合。
-
高分辨率特征重建:HRNet通过使用转置卷积或上采样等方法,将低分辨率的特征图进行上采样,从而恢复高分辨率特征图。这一步操作能够使得模型在保持高分辨率特征的同时,具有较小的计算开销。
-
分类或检测:HRNet将重建的高分辨率特征图输入全连接层,进行分类或检测等任务。
HRNet在多个图像分类和目标检测的任务中都取得了较好的性能表现,尤其是在需要提取高分辨率特征的任务中具有明显的优势。
Hrnet实际代码流程解析
下面是HRNet的具体代码实现流程:
- 数据预处理:使用OpenCV等图像处理库将原始图像进行缩放和裁剪,得到指定大小的输入图像,然后将其转换为Tensor格式。这一步可以使用PyTorch或TensorFlow的数据加载器和转换工具实现。
import cv2
import numpy as np
import torch
def preprocess(img, input_size):
img = cv2.resize(img, (input_size[1], input_size[0]))
img = np.array(img, dtype=np.float32)
img = img / 255.0
img = (img - [0.485, 0.456, 0.406]) / [0.229, 0.224, 0.225]
img = np.transpose(img, (2, 0, 1))
img = np.expand_dims(img, axis=0)
return torch.from_numpy(img)
- 构建网络:HRNet的网络结构可以使用PyTorch实现。在实现过程中,需要首先定义高分辨率特征提取模块、多尺度特征融合模块和高分辨率特征重建模块,然后将这些模块组合起来构建HRNet网络。
import torch.nn as nn
import torch.nn.functional as F
class HighResolutionModule(nn.Module):
def __init__(self, num_branches, blocks, num_blocks, num_channels, fuse_method):
super(HighResolutionModule, self).__init__()
self.num_branches = num_branches
self.fuse_method = fuse_method
self.branches = self._make_branches(num_branches, blocks, num_blocks, num_channels)
self.fuse_layers = self._make_fuse_layers()
self.relu = nn.ReLU(inplace=True)
def _make_one_branch(self, branch_index, block, num_blocks, num_channels):
layers = []
layers.append(block(64, num_channels[branch_index], stride=2))
for i in range(1, num_blocks):
layers.append(block(num_channels[branch_index], num_channels[branch_index], stride=1))
return nn.Sequential(*layers)
def _make_branches(self, num_branches, block, num_blocks, num_channels):
branches = []
for i in range(num_branches):
branches.append(self._make_one_branch(i, block, num_blocks, num_channels))
return nn.ModuleList(branches)
def _make_fuse_layers(self):
if self.num_branches == 1:
return None
num_branches = self.num_branches
num_fuse_layers = num_branches - 1
fuse_layers = []
for i in range(num_fuse_layers):
fuse_layer = []
for j in range(num_branches):
if j > i:
fuse_layer.append(nn.Conv2d(num_channels[j], num_channels[i], kernel_size=1, stride=1, padding=0))
elif j == i:
fuse_layer.append(None)
else:
conv3x3s = []
for k in range(i-j):
in_channels = num_channels[j + k]
out_channels = num_channels[i]
conv3x3s.append(nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)))
fuse_layer.append(nn.Sequential(*conv3x3s))
fuse_layers.append(nn.ModuleList(fuse_layer))
return nn.ModuleList(fuse_layers)
def _fuse(self, x):
if self.num_branches == 1:
return x
out = []
for i in range(len(self.fuse_layers)):
y = x[0] if i == 0 else self.fuse_layers[i][0](x[0])
for j in range(1, self.num_branches):
if i == j:
y = y + x[j]
elif j > i:
width_output = x[i].shape[-1]
height_output = x[i].shape[-2]
y = y + F.interpolate(self.fuse_layers[i][j](x[j]), size=[height_output, width_output],
mode='bilinear', align_corners=True)
else:
y = y + self.fuse_layers[i][j](x[j])
out.append(self.relu(y))
return out
def forward(self, x):
if self.num_branches == 1:
return [self.branches[0](x[0])]
x = self.branches[0](x[0])
x = [x]
for i in range(1, self.num_branches):
y = self.branches[i](x[i-1])
if i == self.num_branches - 1 and self.num_branches > 1:
y = self.fuse_layers[-1][i-1](y)
x.append(y)
x = self._fuse(x)
return x
- 定义损失函数:在HRNet中,通常使用均方误差(MSE)作为损失函数,用于计算预测关键点位置与真实位置之间的差异。
import torch.nn as nn
class HeatmapLoss(nn.Module):
def __init__(self):
super(HeatmapLoss, self).__init__()
def forward(self, pred, gt):
loss = ((pred - gt) ** 2).mean()
return loss
- 训练模型:通过定义训练循环,可以使用PyTorch的优化器和损失函数来训练HRNet模型。训练过程中,需要将输入图像和目标热图传入网络,计算损失并进行反向传播,最终更新网络参数。
import torch.optim as optim
# define HRNet model and optimizer
model = HRNet()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=0.0001)
# define loss function
criterion = HeatmapLoss()
# define training loop
for epoch in range(num_epochs):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, targets = data
inputs = inputs.to(device)
targets = targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
running_loss += loss.item()
print('Epoch %d loss: %.3f' % (epoch + 1, running_loss / len(train_loader)))
- 测试模型:使用测试集数据对训练好的HRNet模型进行评估,计算预测关键点位置与真实位置之间的差异,并输出平均误差。
# define testing loop
test_loss = 0.0
with torch.no_grad():
for data in test_loader:
inputs, targets = data
inputs = inputs.to(device)
targets = targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
test_loss += loss.item()
print('Test loss: %.3f' % (test_loss / len(test_loader)))
- 使用模型进行预测:使用训练好的模型对新的图像进行关键点检测。首先,需要将图像进行预处理,然后将其输入到HRNet模型中,得到预测的热图。最后,可以使用后处理技术(如非极大值抑制)来提取关键点位置。
import numpy as np
import cv2
# load image
img = cv2.imread('test.jpg')
# preprocess image
input_size = (256, 192)
img_tensor = preprocess(img, input_size)
# predict heatmaps
with torch.no_grad():
output = model(img_tensor.to(device))
heatmaps = output[-1].cpu().numpy()
# postprocess heatmaps
keypoints = []
for heatmap in heatmaps:
heatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0]))
heatmap = cv2.GaussianBlur(heatmap, (3, 3), 0)
heatmap = heatmap / np.max(heatmap)
heatmap[heatmap < 0.3] = 0
heatmap = heatmap.astype(np.uint8)
contours, _ = cv2.findContours(heatmap, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
keypoint = cv2.minMaxLoc(heatmap, mask=contour[::-1])[3]
keypoints.append(keypoint)
# visualize keypoints
for keypoint in keypoints:
cv2.circle(img, keypoint, 3, (0, 255, 0), -1)
cv2.imshow('keypoints', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
这段代码将输入一个测试图像,并得到预测的关键点坐标,最后可视化结果。
以上是一个简单的人体姿态估计的流程,其中可以调整的参数有很多,比如网络结构、预处理方式、后处理方式等,需要根据具体的应用场景进行调整。
Hrnet主要模块
HRNet是一种新型的高分辨率网络,相对于传统的深度学习网络,其最大的优点是能够在多个分辨率上提取特征,从而兼顾了高分辨率和低分辨率下的特征。HRNet模型主要由四个模块组成,分别是:
-
高分辨率特征提取模块(High-Resolution Feature Extraction Module):这个模块负责从输入图像中提取高分辨率的特征,并将其送入下一层网络。这个模块由两个分支组成,一个分支对输入图像进行下采样,得到低分辨率的特征,另一个分支则保持输入图像的分辨率,得到高分辨率的特征。
-
多分辨率融合模块(Multi-Resolution Fusion Module):这个模块将来自不同分辨率的特征进行融合,以兼顾不同分辨率下的特征信息。具体来说,这个模块将低分辨率的特征通过上采样恢复到高分辨率,并与高分辨率的特征进行融合。
-
高分辨率特征重建模块(High-Resolution Feature Reconstruction Module):这个模块负责将融合后的特征重建回原始的高分辨率特征。具体来说,这个模块通过一个反卷积操作将融合后的特征上采样到原始分辨率。
-
最终预测模块(Final Prediction Module):这个模块使用重建后的高分辨率特征进行最终的预测。在人体姿态估计任务中,这个模块通常会输出关键点的热图,以指示关键点在图像中的位置。
以上四个模块构成了HRNet模型的基本结构。在实践中,可以根据具体任务对这些模块进行调整和修改,以达到更好的性能。
topdown关键点检测的hrnet全流程代码解析
下面是Top-Down方法的HRNet关键点检测的完整代码,其中包含了数据预处理、模型训练、模型预测等步骤的详细解析。
- 数据预处理
首先,我们需要对数据进行预处理,以便在HRNet模型中进行训练。数据预处理一般包括以下几个步骤:
- 将图像进行缩放,使其长边的长度为输入尺寸(如256或384),短边按比例缩放;
- 将关键点坐标进行缩放,使其与缩放后的图像对应;
- 对图像进行数据增强,如随机旋转、随机裁剪、随机翻转等。
import cv2
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
class KeyPointDataset(Dataset):
def __init__(self, img_path, label_path, input_size=(256, 192)):
self.input_size = input_size
self.img_path = img_path
self.label_path = label_path
self.img_list = []
self.label_list = []
with open(img_path, 'r') as f:
for line in f.readlines():
self.img_list.append(line.strip())
with open(label_path, 'r') as f:
for line in f.readlines():
label = np.array(line.strip().split(' ')).astype(np.float32).reshape(-1, 3)
self.label_list.append(label)
self.transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
def __len__(self):
return len(self.img_list)
def __getitem__(self, index):
# load image and label
img = cv2.imread(self.img_list[index])
label = self.label_list[index]
# resize image and label
h, w, _ = img.shape
scale_h = self.input_size[0] / h
scale_w = self.input_size[1] / w
img = cv2.resize(img, self.input_size)
label[:, 0] *= scale_w
label[:, 1] *= scale_h
# data augmentation
if self.training:
angle = np.random.randint(-30, 30)
scale = np.random.uniform(0.8, 1.2)
trans_x = np.random.randint(-30, 30)
trans_y = np.random.randint(-30, 30)
center = np.array([w / 2, h / 2])
M = cv2.getRotationMatrix2D(tuple(center), angle, scale)
M[:, 2] += np.array([trans_x, trans_y])
img = cv2.warpAffine(img, M, (w, h))
label[:, :2] = self._affine_transform(label[:, :2], M)
# normalize image
img = self.transform(img)
return img, label
def _affine_transform(self, pts, M):
n = pts.shape[0]
pts_pad = np.concatenate([pts, np.ones((n, 1))], axis=1)
pts_trans = np.dot(pts_pad, M.T)
return pts_trans[:, :2]
# create dataset and dataloader
train_dataset = KeyPointDataset('train_img.txt', 'train_label.txt')
val_dataset = KeyPointDataset('val_img.txt', 'val_label.txt')
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4)
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=4)
以上代码中,我们定义了一个KeyPointDataset类,用于加载数据集,并进行预处理。在__init__函数中,我们读取图像和标签的路径,并将它们分别存储在img_list和label_list中。在__getitem__函数中,我们首先读取对应索引的图像和标签,然后将它们进行缩放和数据增强。最后,我们将图像转化为Tensor类型,并进行归一化处理。
- 模型训练
接下来,我们使用PyTorch框架来训练HRNet模型。在训练之前,我们需要定义损失函数和优化器。
import torch.nn as nn
import torch.optim as optim
# define loss function and optimizer
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
然后,我们可以开始训练模型。在每个epoch中,我们使用训练集进行训练,并使用验证集进行评估。在每个batch中,我们计算模型的输出以及与标签的差异(损失函数),并使用优化器更新模型参数。
def train(model, dataloader, criterion, optimizer, device):
model.train()
train_loss = 0.0
for i, (inputs, labels) in enumerate(dataloader):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * inputs.size(0)
train_loss /= len(dataloader.dataset)
return train_loss
def evaluate(model, dataloader, criterion, device):
model.eval()
val_loss = 0.0
with torch.no_grad():
for inputs, labels in dataloader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item() * inputs.size(0)
val_loss /= len(dataloader.dataset)
return val_loss
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = HRNet().to(device)
num_epochs = 50
for epoch in range(num_epochs):
train_loss = train(model, train_dataloader, criterion, optimizer, device)
val_loss = evaluate(model, val_dataloader, criterion, device)
print(f'Epoch {epoch+1:02}/{num_epochs}, Train Loss: {train_loss:.4f}, Val Loss: {val_loss:.4f}')
- 模型预测
在训练完成后,我们可以使用训练好的模型进行预测。下面是一个使用训练好的HRNet模型进行单张图像预测的示例代码。
def predict(model, img_path):
model.eval()
img = cv2.imread(img_path)
h, w, _ = img.shape
scale_h = 256 / h
scale_w = 192 / w
img = cv2.resize(img, (192, 256))
img = img.astype(np.float32) / 255.0
img = (img - np.array([0.485, 0.456, 0.406])) / np.array([0.229, 0.224, 0.225])
img = np.transpose(img, (2, 0, 1))
img = np.expand_dims(img, axis=0)
img = torch.from_numpy(img).to(device)
with torch.no_grad():
output = model(img)
output = output.cpu().numpy()[0]
output[:, 0] /= scale_w
output[:, 1] /= scale_h
return output
model_path = 'hrnet.pth'
model = HRNet().to(device)
model.load_state_dict(torch.load(model_path))
output = predict(model, 'test.jpg')
在预测中,我们首先读取测试图像,并将其缩放到网络输入尺寸。然后,我们将图像转化为Tensor类型,并进行归一化处理。接着,我们使用训练好的模型进行预测,并将输出结果进行反缩放,得到最终的关键点坐标。