领域驱动设计: DDD
事件驱动框架: Event Driven Architecture
命令查询责任分离: CQRS(Command Query Responsibility Segregation)
测试驱动开发: TDD
先睹为快:架构图
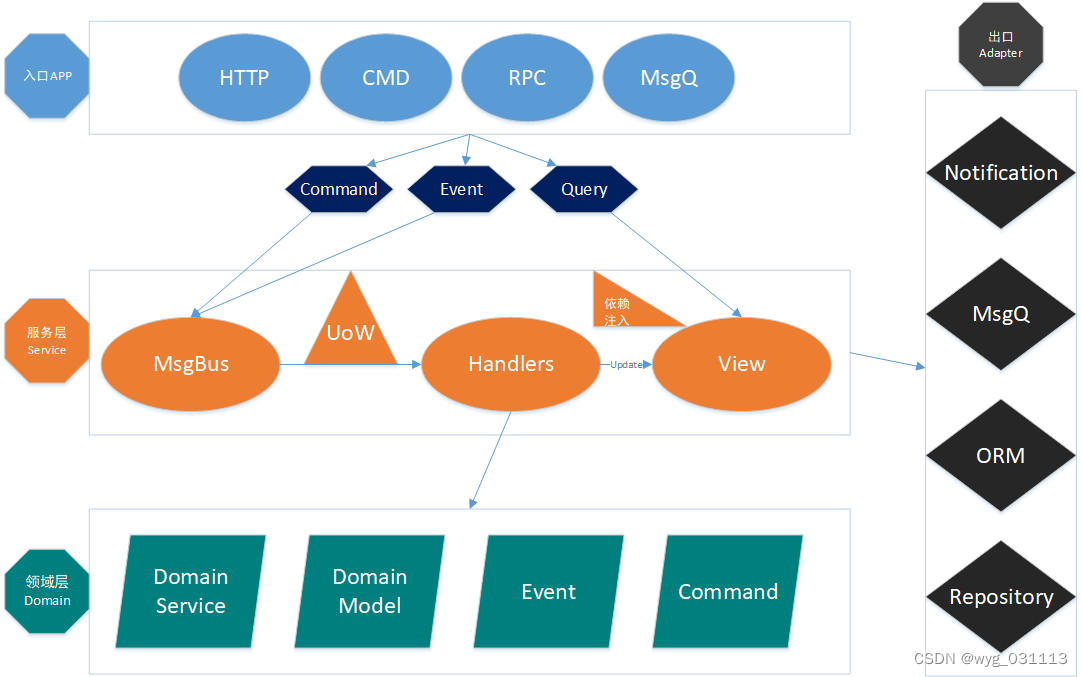
入口:entrypoint
入口是系统外部客户访问系统内部的端口。常见的入口如http, rpc, 命令行,外部消息(消费kafka,rocketmq或者zk, etcd的通知消息)。
入口的职责:解析外部输入,并将输入封装成命令,事件。然后调用服务层的MsgBus去处理。
命令与事件不同:命令需要其handler返回是否成功。而且一个命令唯一对应一个handler。事件则不需要返回成功,或者说失败后handler内部自己处理,一个事件可以有多个handler。事件是记录已经发的事,所以一般用过去式:如OrderCreated, OutOfResource;另一个概念消息,消息只是一个信息,可能转化成事件,也可能转化成命令。所以说Kafka, RocketMQ这些叫消息队列,而不叫事件队列或者命令队列。建议命令处理只返回简单的成功/失败,具体前端要展示处理后的结果,可以另发一个Query请求过来。
CQRS
一种区别对待写请求(命令)和读请求的设计模式。这样区分是因为写和读对系统的要求可能很不相同。
- 读写本质不同
写请求一般会修改系统状态,而且其修改一般要穿过缓存,直接提交到数据库。一个系统的写请求一般远少于读请求。
读请求不修改系统状态,请求量也会非常大,这时候可以使用大量cache来提高性能。因此,读写分离一般能提高系统性能。
- 优化读性能
甚至可以构建物化视图,即复制一份数据,按照查询的需求的数据结构来组织数据,并放到NoSQL数据库或者缓存中,提供快速查询。避免了在查询时还要进行复杂的表连接等耗费性能的重量级操作。
- 更新视图,保证一致
在写请求完成后或者抛出事件,在专门的视图更新handler中更新视图(View)。
事件驱动的优势
无论是HTTP还是RPC还是外部消息,上层应用可能各不相同,但是统一抽象成事件或者命令后再交给MsgBus处理。这个解耦了入口应用层与服务层handler。同时在系统内部也可以抛出事件,这就把系统内外的处理入口集中并统一起来了。能实现这些因为中间引入了MsgBus和Event+Command。这样应用层和handler都可以自由变化,并灵活组合,而又互不阻碍。事件甚至是一种实体,他有唯一ID。可以持久化。防止事件丢失。
MsgBus
消息总线,维护了事件/命令和handler之前的关系。并分发事件到对应的handler。
UoW(Unit of Work)模式
一个Command或者Event在处理时,可能需要修改系统状态,而且在复杂又很深的调用链中,各种函数方法可能都要对同一个状态进程累进修改。UoW相当于一个请求的上下文状态,在处理请求前,构建UoW,一般是准备Repository, 然后把UoW带到handler以及各种需要修改状态的函数中去。当handler执行完成后,所有需要变更在状态都积累在UoW中了。此时可以在一个事务中提交修改。或者中途出现异常,则rollback,忽略修改。因此UoW是完成了一次事务。至于在处理过程中抛出的事件,则在提交事务后交由各事件handler处理。事件的处理并不在这次事务中。但是,UoW可以收集过程中的事件,如果事务回滚,则这些事件可以忽略。UoW可以在msg_bus,或者handler中或者由依赖注入模块来创建。他在handler结束后销毁。像python中UoW可以实现为ContextManager。
领域层
领域层包含领域服务,聚合,实体,值对象。这是DDD的核心概念。
- 实体:有唯一ID和永久生命周期,修改其内部属性,实体依然是这个实体,而且会永久保存到Repository中。
- 值对象:无ID,内部属性值标识了自己,生命周期短暂,一般不会修改其属性值,而是创建一个新的值对象。例如人是一个实体,有唯一ID(身份证),而人的姓名则是值对象,修复姓名,人还是那个人。只是重新创建了姓名这个值对象。
- 聚合:聚集了多个领域对象,对于一些业务,涉及到修改多个领域对象,或者修改一批同一种领域对象,此时把这一批领域对象聚集起来,形成新的实体:聚合,此时就不能再单独操作聚合中的实体了。要通过聚合提供的方法来操作其中的实体。聚合越小越好。标准是更新一个聚合,系统仍然是一致的。也是聚合是一个事务,一种边界。
- 领域服务:一些操作不适合放在聚合或者实体中,比如要修改一个聚合,但是会引用另一个聚合的数据,只是引用。
handler中会从仓储(repository)中获取必要的实体/聚合,并调用领域层的领域服务来完成业务操作。之后又把变更了的实体/聚合持久化到仓储中。因此,领域层一般不需要依赖仓储。
依赖倒置
handler也不依赖具体的仓储(repository). hander和具体仓储的实现(如MySQL仓储)都依赖抽象的仓储接口。这样可以灵活的更换各种仓储。其他三方库,如redis, kafka, etcd,通知服务(邮件,SMS)等也是一样的用依赖倒置原则。
领域事件
领域模型中可以抛出一些事件,如订单已经创建,资源已经分配,资源不足等。或者系统有异常抛出,也可以封装成事件。注意的是事件丢失或者后续处理失败并不会造成当前事务状态不一致。这也是判断哪些操作可以延后到事件处理中去的标准。这些事件并不需要立即调用MsgBus去处理。而是收集起来,可以暂时放到UoW中,或者暂时放在聚合/实体中,或者直接作为参数返回也行。这样,领域层也不会反向依赖MsgBus。
基础服务层
定义好接口,使用依赖倒置原则解耦。接口的具体实现称为适配器。
仓储(repository):一个仓储一个聚合,一次事务,一个UoW
微服务划分与服务间通信
这涉及到DDD中的界限上下文。理论上一个聚合,或者说一个事务就能拆成一个微服务。当然,这样有可能让微服务太多,可以用现在流行的云函数来支持这么小级别的微服务。拆的小也有小的好处,比如资源分配上可以灵活,系统之间极大的解耦和。也有坏处,让系统运维起来复杂,理解起来困难。最好还是按业务界限划分。一种评判标准是:两个模块之间能异步通信,比如订单模块和仓库模块,订单下好后,发一个事件到消息队列,仓库模块异步处理即可。
事件驱动不是要禁止一切直接RPC:比如登录模块中要验证用户名密码,可能用到用户管理模块。现在很多做法是把登录抽象成SSO统一登录服务。这样业务服务中,只要RPC访问登录服务来校验token或者获取用户信息即可。可以看出,事件驱动的好处是解耦,缺点是异步,延时,因此,在线请求这种对延时要求极高的服务,还是得用RPC.不过可以看出,这些服务大多提供查询,校验,计算等服务。一盘不修改这些服务的状态。
系统内部并发与一致性
并发冲突
接入层HTTP, RPC在现实服务中都是并发的。当然可以单线程做事件循环。但是现代服务器都是多核心的。因此为提高性能,不可避免的使用多线程,多进程。甚至使用负载均衡器+集群的方式。这时,对同个实体的并发/并行修改不可避免。因此并发冲突可能导致状态被破坏,出现一张票卖个连个人等等问题。解决方法一般有两种:
- 悲观事务枷锁: 像MySQL中种数据库支持ACID,事务加锁,在从repository中获取数据时使用select for update之类的语句,加锁后,其他并发将被阻塞。直到当前事务完成。显然性能低。
- 乐观事务MVCC:像mongodb, etcd这类NoSQL数据库一般通过版本号控制并发,每个实体维护一个版本号,每次更新+1,真正提交事务的时候比较版本号是不是+1就能知道是不是冲突了。冲突了只能回滚了。这种做法乐观的认为冲突一般不会发生,并发度高,性能好。但是一但冲突,这次操作就白做了。
事件丢失&失败
异常情况发生时,如服务器崩溃,或者日志发布时重启服务器,可能会导致事务提交后,一些事件还没来得及处理就丢失了。最后导致了系统状态不一致。此时首先要考虑的是,是不是聚合没选对,导致其不是一个完整的事务。否则可以有以下处理方式:
事件也作为事务的一部分持久化到DB。重启后有专门线程扫描DB,恢复事件。注意事件处理的幂等性。这对于跨系统发送的事件通常是比较好的处理方式。
事后人工恢复:对于上述情况,人工介入,通常需要打足够多的日志,metrics等,后续人工分析介入。
事件失败:打日志,不妨碍其他事件继续处理
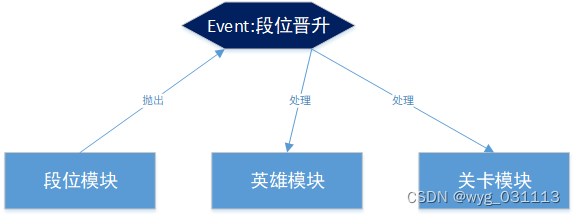
看这样一个例子,在游戏中,段位则模块判断玩家段位晋升了,并抛出了段位晋升事件。其他模块监听此事件,英雄模块可能要奖励玩家一个英雄,关卡模块要开放新的关卡。后续可能有其他模块奖励玩家物品或者金币。
实现方法:
直接在段位晋升后,依次调用英雄模块,关卡模块的函数。不抛出事件。显然,以后新模块加入又得改这里的代码。不符合开放封闭(OCP)原则。
引入新的领域服务来处理晋升:依次调用段位模块,英雄模块,关卡模块,最后提交。各模块是干净了,但是,领域服务这块儿代码不符合开放封闭(OCP)原则。
抛出事件:但是在段位保存前就处理完事件,把修改收集到UoW中。此时考虑的是不是聚合,或者领域服务抽象的不合理?
持久化事件:段位晋升后,把抛出的事件也作为段位模块的数据持久化到repository中。后台线程定时扫描并重放未处理的事件。如果这三个模块是独立的为服务,可能比较适合。因为事件投递到另消息队列和持久化到repository一般不在同一个DB中,没法进行事务操作。 或者得使用复杂的分布式事务,两阶段提交等复杂操作。
抽象出更高层的聚合:如玩家。玩家是一个聚合,自身带了段位,英雄,关卡等信息。理当作为一个聚合,同时持久化时,要以玩家为单位进行。需要注意,此时的事件处理确实需要在事务提交前进行。这里的MsgBus不再是上文提到的MsgBus。这是玩家这个聚合自己的MsgBus。这样系统中有两个MsgBus。或者进一步扩展,当聚合过于复杂时,为解耦各模块,有时也使用事件。
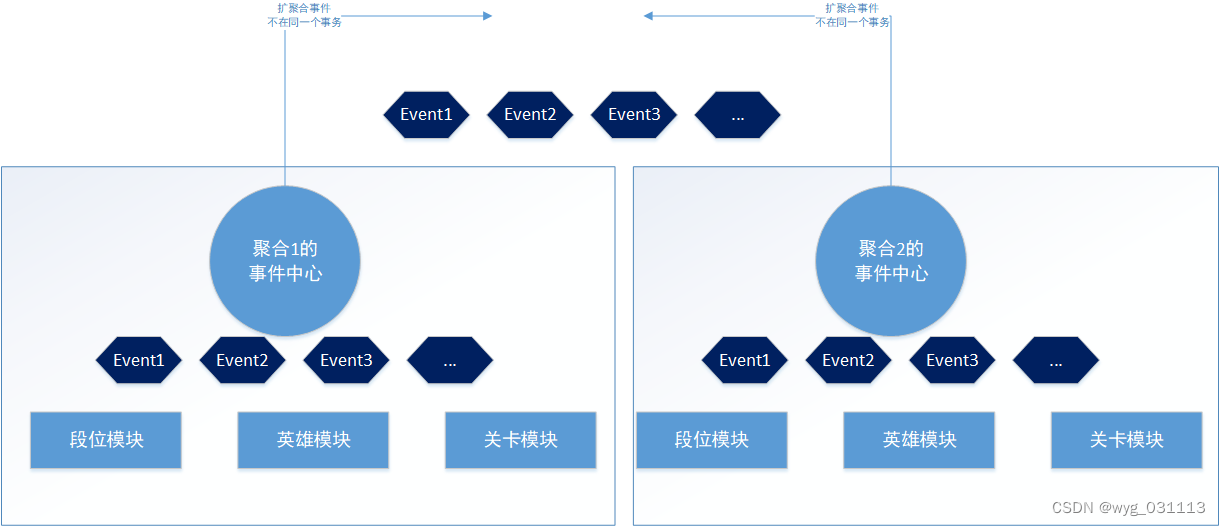
全局事件中心与局部事件中心
这里虽然叫事件中心,实质与MsgBus实现一样。但是聚合内模块之间如果是命令的话,就直接调用函数。因此,只有这种一对多的情况用事件来解耦合。更复杂的可以组成事件树。这在游戏中组件模式下经常使用。
全局事件中心用于处理聚合外的事件,也就是聚合之间的事件。他在UoW事务提交后才执行。失败打日志,不影响聚合内一致性。
局部事件中心:处理聚合内事件,事件触发即执行。是聚合内的事件处理。在事务提交前,就执行完所有事件了。如果有失败,可以打日志。也可以抛出异常,中止整个操作。一般有失败,是代码BUG导致。需要修改代码。这里的事件中心已经不是为了事务间解耦合而使用事件了,而是为了聚合内部模块之间的解耦和。
如果需要投递事件,那应该是投递到哪个事件中心去呢?
- 人工选择:提交事件时指定事件中心
- 自动将局部事件全部也提交到全局事件。
- 事件冒泡,即局部处理成功了就不往上层提交了。
- 写个局部事件handler来决定哪些事件要提交到全局。
跨微服务事件:即全局中有些事件是发往外部系统的。可以统一发到消息队列中去,再由外部服务订阅。也可以直接调用外部服务接口(这样要求外部服务也可服务。否则要处理失败的情况,要求不高就打错误日志,人工恢复)
如下内容还在持续完善中.....
分布式系统,跨微服务的一致性:分布式事务
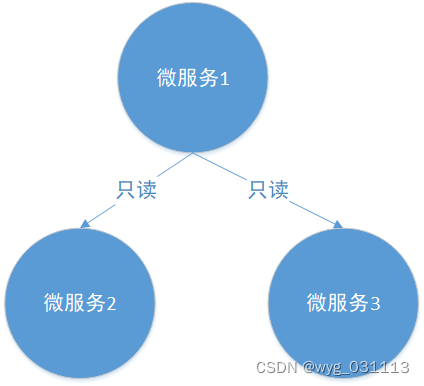
只读
微服务1只读不修改微服务2,3的状态,最后微服务1只修改自己的状态。这种就直接使用RPC吧,可以保证一致。
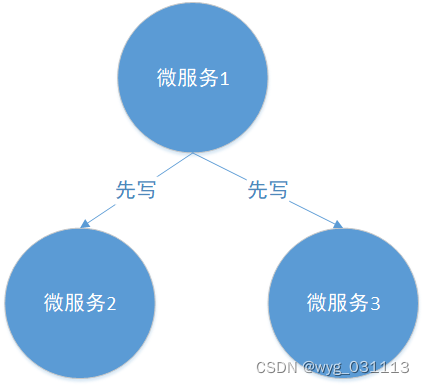
先写
微服务1先修改微服务2,3的状态,成功后才能提交自己的修改:首先考虑是不是合并这三个微服务。不能的话考虑使用分布式事务,但也只能降低失败率,还会影响性能。
后写
微服务1先修改自己的状态,然后才微服务2,3的状态:首先考虑是不是合并这三个微服务。然后考虑是使用消息队列解耦合。还不能的话考虑使用分布式事务,但也只能降低失败率,还会影响性能。
分布式事务7种解决方案:
分布式事务最经典的七种解决方案_分布式事务解决方案_Java烟雨的博客-CSDN博客
分布式事务解决方案:7种常见解决方案汇总_51CTO博客_分布式事务解决方案
七种分布式事务的解决方案 - 简书
TDD
测试驱动开发:在实现业务逻辑前。先写出测试用例。可能会觉得何必呢?增加了工作量。其实,在针对领域模型写测试用例时,其实时在梳理业务需求和功能。相当于用测试用例而不是文档来描述清楚需求。让后来者可以通过读测试用例就能知道系统的需求和功能。测试用例可以分为慢用例,如使用真实的数据库,和快用例,如使用Fake数据库。依赖道指使测试变得容易。可以由最初的对领域模型的测试,到最后的高层次的端到端测试逐步构建测试用例。