Background
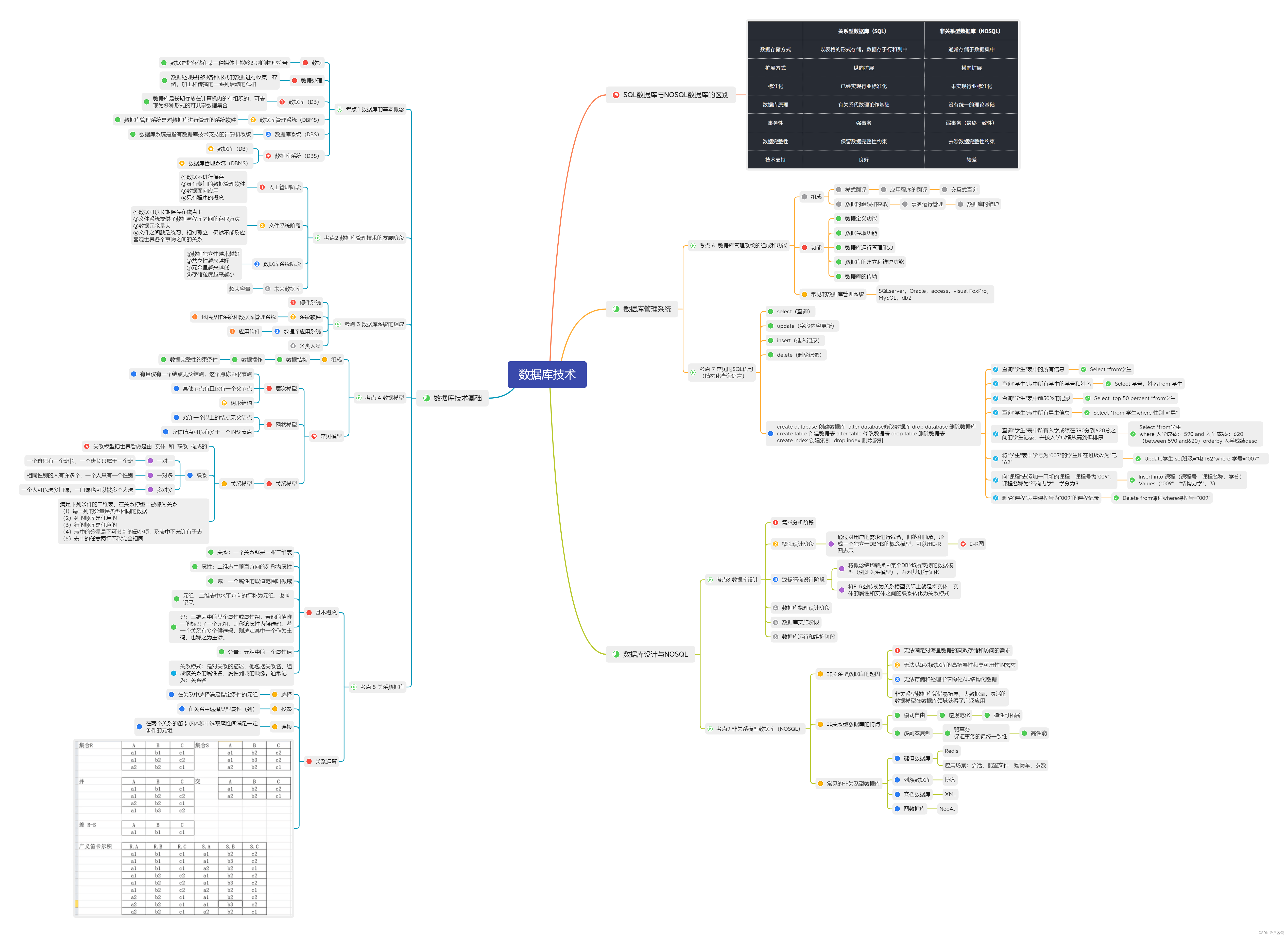
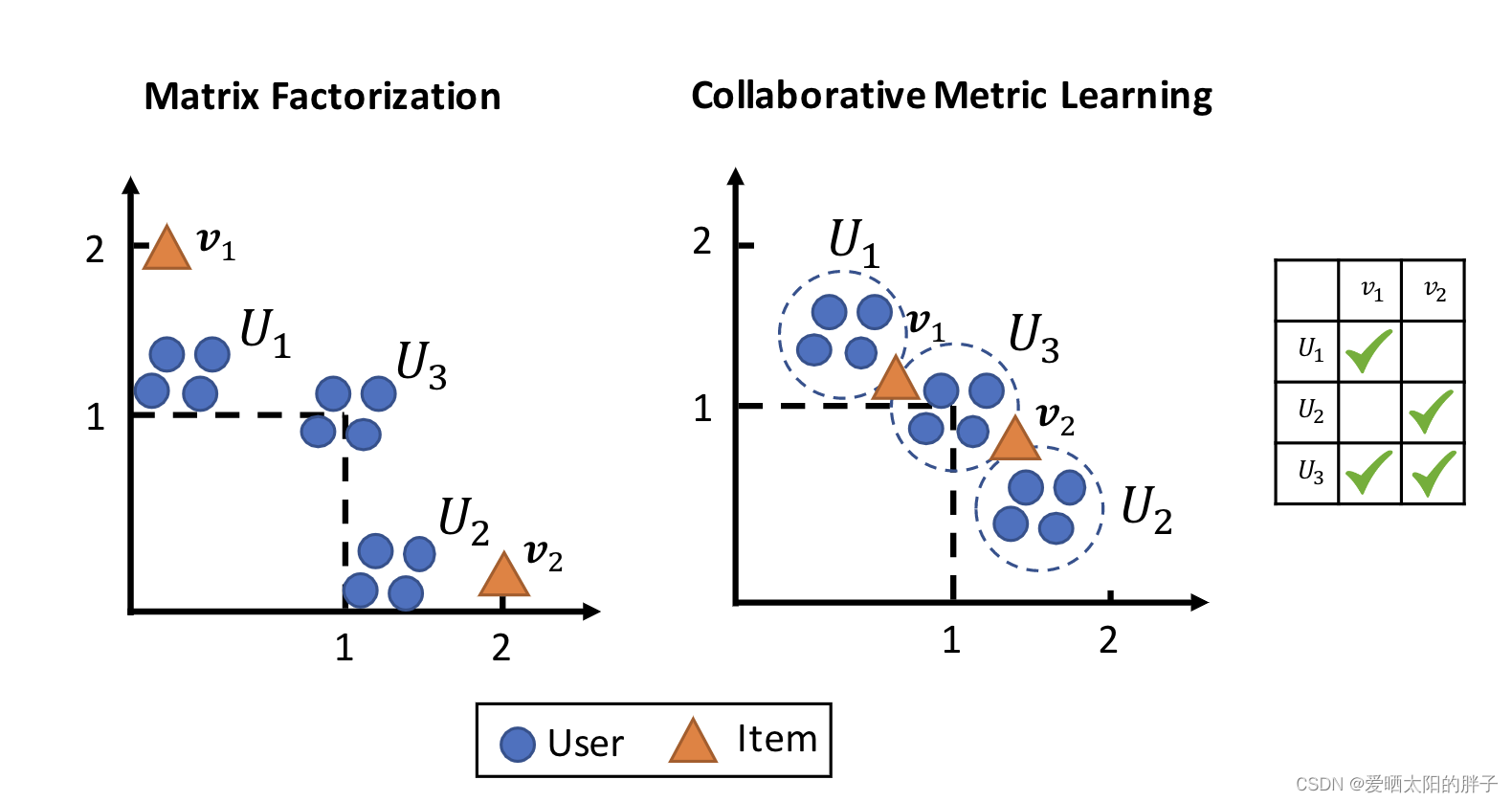
传统基于MF的模型,将特征向量的点积作为预测结果,这存在一个很大的问题,即dot product 不满足三角不等式),这会导致学到的特征向量次优(难以捕捉用户细粒度的偏好)。本文提出了一种Collaborative+Metric Learning模型,不仅能捕捉用户细粒度偏好,还可以捕捉用户-用户/物品-物品相似性。
注:
度量学习目的:通过一个投影函数 f 将物品投影到一个潜在特征空间中,在此空间中相似物品距离近,不相似物品距离远。
三角不等式:x为用户,y,z用户交互过的两物品,根据三角不等式公式d(y,z)≤d(x,y) +d(x,z),可知在缩短(x,y),(x,z)之间距离的同时,(y,z)两物品之间的距离也会因为约束的存在而被缩短,可将此现象看做相似度传递。
Pre-model
在隐式反馈中无法直接获得用户评分作为label,这就使得rating变得不准确,所以本文在隐式反馈场景下,将问题转变为对不同物品排序问题。
Large margin nearest neighbor(LMNE)
拉近
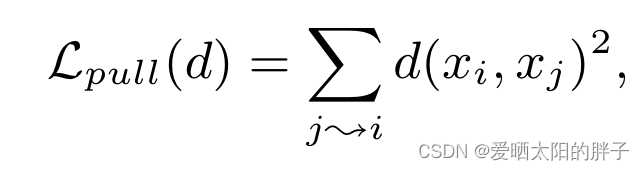
推远

Bayesian Personalized Ranking
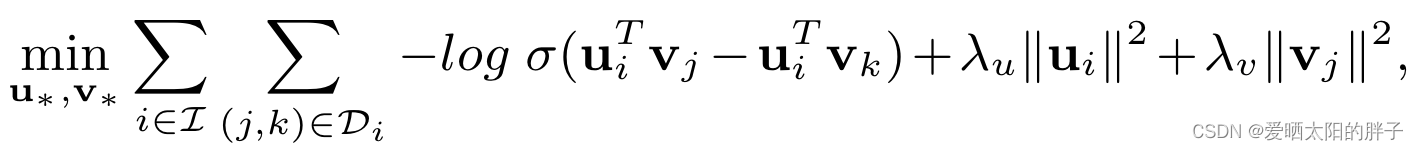
训练样本为三元组(i,j,k),j为用户i交互过的物品,k为用户未交互过的物品。:sigmoid
缺点:
从公式中可以看出,在损失函数中,任意一组三元组地位相同。换言之,该模型只能区分出正负样本,而每类样中的区分度是非常小的,即在topk推荐中保证正样本出现在推荐序列中,但并不考虑排列顺序对结果的影响(排序顺序是存在bias的)。
CML
Method
本文模型:
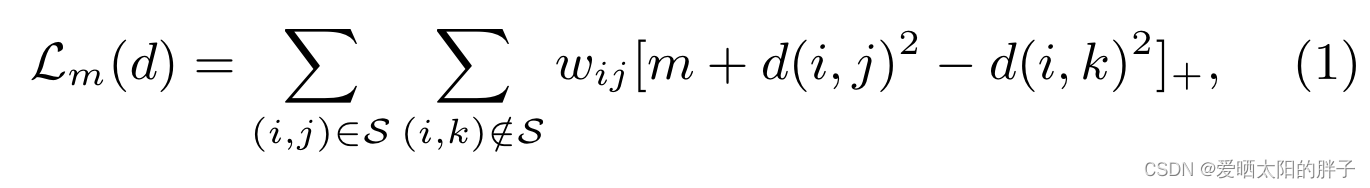
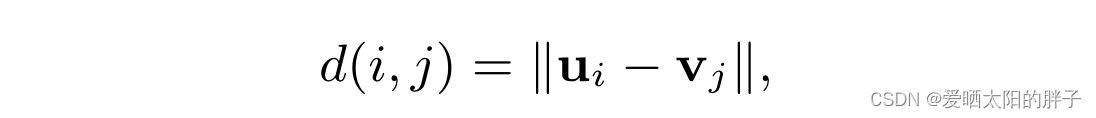

:度量d下,物品j在给用户i推荐列表的位置。0<=
<=列表长度
约束
1、特征约束
将物品j的特征向量,限制在周围。
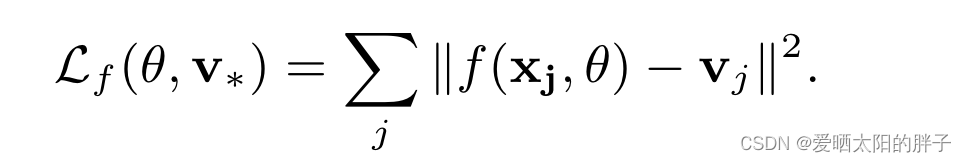
:物品原始特征
:两层MLP(256维)+0.5 Dropout
:物品j的特征向量
2、独立性约束
通过协方差,解偶特征向量各维度间的线性相关性。
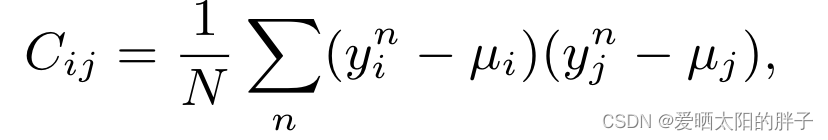

:用户/物品的特征向量
损失函数