1.列表
序列是Python中最基本的数据结构。序列中的每个元素都分配一个数字 去锁定它的位置,或索引,第一个索引是0,第二个索引是1,依此类推。Python有6个序列的内置类型,但最常见的是列表和元组。序列都可以进行的操作包括索引,切片,加,乘,检查成员。此外,Python已经内置确定序列的长度以及确定最大和最小的元素的方法。列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。列表的数据项不需要具有相同的类型
1.1创建列表
1.方式一直接声明,如下实例
>>> [1, 2, 3, 4, 5]
[1, 2, 3, 4, 5] //声明一个整型数字列表
>>> [1, 2, 3, 4, 5, "上山打老虎"]
[1, 2, 3, 4, 5, '上山打老虎'] //声明一个列表
>>> rhyme = [1, 2, 3, 4, 5, "上山打老虎"] //声明一个列表并将它作为一个对象赋值给thyme
>>> rhyme //相当于print(rhyme)
[1, 2, 3, 4, 5, '上山打老虎']
>>>
2.使用乘法操作,如下实例
>>> A = [0] * 3 //用元素[0] * 3 表示重复元素0三次,快速的创建一个每个元素相同的列表
>>> A
[0, 0, 0]
1.2访问列表
访问整个列表,如下实例
>>> for item in rhyme: //利用上一节的for循环内容,遍历序列中的每一个元素
print(item, end=" ") //输出序列的每一个数据项,并将每个数据后默认的换行转化为空格输出
1 2 3 4 5 上山打老虎
>>>
访问列表中的某一个元素,如下实例
>>> rhyme[0] //访问列表中的第一个元素,列表默认第一个元素的下标为0
1
>>> rhyme[len(rhyme)-1] //访问列表中的组后一个元素,最后一个元素的下标为列表长度-1
'上山打老虎' //使用len()模块的作用就是你可以不用事先知道列表的长度
>>>> rhyme[-1] //最后一个元素的下标索引值可以为-1,以此类推倒数第二个元素的下标索引值为-2,倒数第三个元素的下标索引值为-3......
'上山打老虎'
>>>
注: 在列表中最后一个元素的下标索引值可以为len(列表名)-1,也可以是-1,以此类推,倒数第二个元素的下标索引值为-2,倒数第三个元素的下标索引值为-3…
切片访问(高级索引): 在Python中,切片(slice)是对序列型对象(如list, string, tuple)的一种高级索引方法。 普通索引只取出序列中 一个下标 对应的元素,而切片取出序列中 一个范围 对应的元素,这里的范围不是狭义上的连续片段。通俗一点就是在一定范围里面.用刀切出一部分,达到自己需要的一部分.
格式一: str[start: stop] start和stop是需要获取元素的起始索引和结束索引,如下实例
>>>rhyme[0: 3] //获取列表前三个元素 [1, 2, 3] >>>rhyme[3: 6] //获取列表后三个元素 [4, 5, '上山打老虎']格式二: str[: stop] 访问序列str从第一个元素开始到stop下标的元素
str[start: ] 访问从start下标的元素开始到序列结束的所有元素内容,如下实例>>> rhyme[: 3] //访问从第一个元素到第3个元素之前的所有元素内容 [1, 2, 3] >>> rhyme[3: ] //访问从第3个元素开始到结束的所有元素内容 [4, 5, '上山打老虎'] >>> rhyme[5: ] //访问从第5个元素开始到结束的所有元素内容 ['上山打老虎'] >>> rhyme[: 5] //访问从第1个元素开始到结束元素的所有元素内容 [1, 2, 3, 4, 5]格式三: str[:] 表示访问整个序列内容,如下实例
>>> rhyme[:] //访问整个列表内容 [1, 2, 3, 4, 5, '上山打老虎']格式四: str[start: stop: step] 访问从start下标开始的元素到stop下标结束的元素之间以step为步长逐个访问,如下实例
>>> rhyme[0: 6: 2] //访问从下标0开始的元素到下标6之前的元素结束之间的并以步长为2访问 [1, 3, 5] >>> rhyme[: : 2] //冒号前后省略默认为列表开端和结束的端点下标 [1, 3, 5] >>> rhyme[6: 0: -2] //访问从末尾元素到开端元素且步长为2,就是倒序以步长为2访问 ['上山打老虎', 4, 2] >>> rhyme[::-2] //省略默认代表开始和结束元素 ['上山打老虎', 4, 2] >>> rhyme[::-1] //相当于对序列进行了倒置操作 ['上山打老虎', 5, 4, 3, 2, 1]注意: 起始数和截止数索引是左闭区间,右开区间
1.3向列表添加数据
1. obj.append() 每次添加一个数据对象,如下实例
>>> heros = ["钢铁侠", "绿巨人"] //初始化一个列表
>>> heros
['钢铁侠', '绿巨人']
>>> heros.append("黑寡妇") //向列表追加一个数据项
>>> heros
['钢铁侠', '绿巨人', '黑寡妇']
2.利用切片的方法追加数据项,如下实例
注意: python使用切片方法时,当切片的范围超过下标范围时,不会报错,会返回空列表,所以利用这个特性可以在列表末尾追加数据项
>>> s = [1, 2, 3, 4, 5] //初始化一个列表对象
>>> s[len(s): ] = [6] //在末尾追加数据6
>>> s[len(s):] //len(s)已经超出下标范围了,但是返回不会报错,返回一个空列表
[]
>>> s[len(s): ] = [7, 8, 9] //利用切片进行追加多个数据项
>>> s
[1, 2, 3, 4, 5, 6, 7, 8, 9]
>>>
3. obj.extend() 每次添加多个元素 注:此方法的参数必须是一个 可迭代对象 ,新内容追加到原列表的最后一个元素后面,如下实例
>>> heros.extend(["鹰眼", "雷神", "幻视"]) //追加数据项,参数是一个列表,可迭代对象
>>> heros
['钢铁侠', '绿巨人', '黑寡妇', '鹰眼', '雷神', '幻视']
>>>
4.obj.insert(index, value) 每次在列表的任意位置插入数据项,如下实例,其中index为下标,从0开始
>>> s = [1, 3, 4, 5]
>>> s
[1, 3, 4, 5]
>>> s.insert(1,2) //在下标为1的位置上插入元素2
>>> s
[1, 2, 3, 4, 5]
1.4从列表删除数据
1. obj.remove(value) 删除值为value的数据项,如下实例
>>> heros
['钢铁侠', '绿巨人', '黑寡妇', '鹰眼', '雷神', '幻视']
>>> heros.remove("鹰眼") //删除列表中的鹰眼
>>> heros
['钢铁侠', '绿巨人', '黑寡妇', '雷神', '幻视']
>>> heros.remove("武松") //删除列表中不存在的内容,报错
Traceback (most recent call last):
File "<pyshell#61>", line 1, in <module>
heros.remove("武松")
ValueError: list.remove(x): x not in list
注意: 1.如果列表中存在多个匹配的元素,那么它只会删除第一个
2.如果指定的元素不存在,那么程序就会报错。
2. obj.pop(index) 删除指定下标index的数据项,如下实例
>>> heros
['钢铁侠', '绿巨人', '黑寡妇', '雷神', '幻视']
>>> heros.pop(2) //删除下标索引为2的元素,即删除黑寡妇
'黑寡妇'
>>> heros
['钢铁侠', '绿巨人', '雷神', '幻视']
3. obj.clear() 删除整个列表的全部内容,如下实例
>>> heros
['钢铁侠', '绿巨人', '雷神', '幻视']
>>> heros.clear() //obj.clear()删除列表所有内容
>>> heros
[]
1.5修改列表的数据内容
因为列表是可变的,而字符串是不可变的,所以我们能对列表进行修改操作。
- 修改某一索引对应的值,直接将新的值赋给对应下标的元素即可,如下实例
>>> heros
['钢铁侠', '绿巨人', '黑寡妇', '鹰眼', '雷神', '幻视']
>>> heros[len(heros)-1] = "蜘蛛侠" //将列表最后一个元素,幻视替换为蜘蛛侠
>>> heros
['钢铁侠', '绿巨人', '黑寡妇', '鹰眼', '雷神', '蜘蛛侠']
>>>
- 利用切片技术,同时修改多个数据项的内容,如下实例
>>> heros
['钢铁侠', '绿巨人', '黑寡妇', '鹰眼', '雷神', '蜘蛛侠']
>>> heros[4:] = ["武松", "林冲"] //实现将第四个元素后面的内容进行替换
>>> heros
['钢铁侠', '绿巨人', '黑寡妇', '鹰眼', '武松', '林冲']
3.str.[str.index(被替代的内容)] = ‘替代的内容’ ,如下实例
>>> heros[heros.index('武松')] = '冬兵' //将武松替换为冬兵
>>> heros //替换后的结果输出
['林冲', '冬兵', '雷神', '蜘蛛侠', '鹰眼', '黑寡妇', '绿巨人', '蚁人', '钢铁侠', '黄蜂女']
>>>
实际的底层是分为两步骤执行的
step one:将赋值号 = 左边指定的内容删除
step two:将包含在赋值号 = 右边的可迭代对象中的片段插入左边被删除的位置
1.6 对列表内容进行排序,逆置
1. obj.sort() 方法 对列表内容进行从小到大排序,如下实例
>>> nums = [3, 1, 9, 6, 8, 3, 5, 3] //乱序的初始列表
>>> nums
[3, 1, 9, 6, 8, 3, 5, 3]
>>> nums.sort() //使用obj.sort()方法进行排序
>>> nums
[1, 3, 3, 3, 5, 6, 8, 9] //排序内容输出
2. obj.reverse() 方法 对列表的内容进行逆置操作,如下实例
>>> nums
[1, 3, 3, 3, 5, 6, 8, 9]
>>> nums.reverse() //对列表进行逆置操作
>>> nums
[9, 8, 6, 5, 3, 3, 3, 1]
>>> heros
['钢铁侠', '绿巨人', '黑寡妇', '鹰眼', '武松', '林冲']
>>> heros.reverse() //对列表内容进行逆置操作
>>> heros
['林冲', '武松', '鹰眼', '黑寡妇', '绿巨人', '钢铁侠']
>>>
3.obj.sort(reverse = True) 对列表内容进行逆序排序操作,如下实例
>>> nums = [3, 1, 9, 6, 8, 3, 5, 3]
>>> nums
[3, 1, 9, 6, 8, 3, 5, 3]
>>> nums.sort(reverse = True) //对列表内容进行逆序
>>> nums
[9, 8, 6, 5, 3, 3, 3, 1]
>>>
4.obj.count(value) 对列表中value的个数进行统计,如下实例
>>> nums = [3, 1, 9, 6, 8, 3, 5, 3] //初始化一个列表
>>> nums
[3, 1, 9, 6, 8, 3, 5, 3]
>>> nums.count(3) //统计列表中3的个数
3
5.obj.index(value) 查找列表中值为value的元素的下标索引,如下实例
obj.index(value, start_index, end_index) 从指定的下标索引范围内查找值为value的第一个元素的下标索引
>>> nums
[3, 1, 9, 6, 8, 3, 5, 3]
>>> nums.index(3) //统计3在列表中第一次出现的位置
0
>>> nums.index(6) //统计6在列表中第一次出现的位置
3
>>> heros
['林冲', '武松', '雷神', '蜘蛛侠', '鹰眼', '黑寡妇', '绿巨人', '蚁人', '钢铁侠', '黄蜂女']
>>> heros.index('武松') //统计武松在列表中 **第一次** 出现的位置
1
>>> heros.index('蜘蛛侠') //统计蜘蛛侠在列表中第一次出现的位置
3
>>> nums
[3, 1, 9, 6, 8, 3, 5, 3]
>>> nums.index(3, 4, 7) //在下标为4-7的范围内查找元素值为3的第一个位置下标
5
>>>
6. str.copy() 对str列表进行复制操作,如下实例
str_copy = str[:] 使用切片语法对str列表进行复制操作,如下实例
>>> nums
[3, 1, 9, 6, 8, 3, 5, 3]
>>> nums1_copy = nums.copy() //复制列表nums并赋值给nums1_copy
>>> nums1_copy //打印输出复制后的列表
[3, 1, 9, 6, 8, 3, 5, 3]
>>> nums2_copy = nums[:] //利用切片语法实现对列表的复制然后赋值给另一个数据对象
>>> nums2_copy
[3, 1, 9, 6, 8, 3, 5, 3]
>>>
1.7对列表进行加法和乘法
1.对列表的加法,相当于是两个列表的拼接,如下实例
>>> s = [1, 2, 3] //声明列表s
>>> t = [4, 5, 6] //声明列表t
>>> s + t //对两个列表执行加法操作,相当于将两个列表拼接在一起
[1, 2, 3, 4, 5, 6]
>>>
2.队列的乘法,相当于是对重复列表的内容,如下实例
>>> s //初始化列表s
[1, 2, 3]
>>> s * 3 //对列表s进行乘法操作,重复3次s列表的内容
[1, 2, 3, 1, 2, 3, 1, 2, 3]
>>> s
1.8列表嵌套 顾名思义就是在列表中嵌套列表 二维列表
1.8.1 嵌套列表的创建
1.嵌套列表即二维列表的创建,如下实例
>>> matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] //初始化一个二维列表
>>> matrix
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> matrix = [[1, 2, 3], //这样写二维列表的结构更为直观,方便人们理解
[4, 5, 6],
[7, 8, 9]]
>>> matrix
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
2.使用乘法快速创建一个元素相同的嵌套列表,即二位列表,存储方式及实例如下

实例
>>> A
[0, 0, 0]
>>> for i in range(3): //使用循环对A的每个元素进行乘法扩展其内容
A[i] = [0] * 3
>>> A
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
>>>
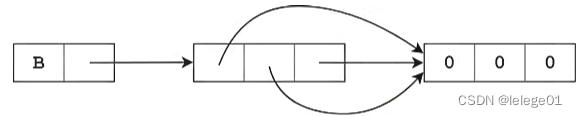
3.使用两次乘法,对嵌套列表进行拷贝,即二维列表,存储方式及实例如下
实例
>>> B = [[0] * 3] * 3 //先创建一个一维列表[0, 0, 0]在使用乘法生成二维列表
>>> B
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
>>>
注:
上述方法2、3使用乘法生成嵌套列表的方法存在一定的差异,继续往下看
现在我们修改A[1][1]和B[1][1]的值>>> A //A的初始情况 [[0, 0, 0], [0, 0, 0], [0, 0, 0]] >>> B //B的初始情况 [[0, 0, 0], [0, 0, 0], [0, 0, 0]] >>> A[1][1] = 1 //修改A[1][1] = 1 >>> B[1][1] = 1 //修改B[1][1] = 1 >>> A [[0, 0, 0], [0, 1, 0], [0, 0, 0]] >>> B [[0, 1, 0], [0, 1, 0], [0, 1, 0]]为什么使用方法2、3生成的列表,我们更改一个元素的值,结果却不一样呢?
为搞清楚这个问题,我们引入运算符 is【同一性运算符】:用于检验两个变量是否指向同一个对象的运算符,如下实例,is运算符的用法>>> x = "LoveYou" >>> y = "LoveYou" >>> x is y //两个命名不一样内容相同的字符串是指向同一个数据对象的 True >>> x = [1, 2, 3] >>> y = [1, 2, 3] >>> x is y //两个命名不一样内容相同的列表是指向不同的数据对象的 False造成上述结果的原因是,在python中不同性质的变量的存放方式是不一样的,对于字符串是一个常量,不变量 即内容一致都会存储在同一个位置,即使是赋值操作也是指向同一个位置的,而对于序列、列表这一类的内容可变的数据来说,他们的数据是随时要发生变化的,所以会将内容相同的变量不一致的数据进行单独存储,所以二者指向的数据对象也是不一样的。所以接下来我们对A和B的内容进行同一性判断,如下
>>> A [[0, 0, 0], [0, 1, 0], [0, 0, 0]] >>> B [[0, 1, 0], [0, 1, 0], [0, 1, 0]] >>> A[0] is A[1] False >>> A[1] is A[2] //用方法2生成的列表,每一个元素的存储位置都不一样,都是不同的数据对象 False >>> B[0] is B[1] True >>> B[1] is B[2] //使用方法3生成的列表,每一个元素的存储位置都一致,指向相同的数据对象,即就是使用乘号和一维列表生成一个嵌套列表即二维列表,其实拷贝的是一个引用。 True
1.8.2 嵌套列表的访问
1.访问嵌套列表 二维列表,如下实例
>>> for i in matrix: //一维列表用一层循环,二维列表使用二层循环
for item in i:
print(item, end=' ') //去除每个输出元素后面的换行更为空格
print()
1 2 3
4 5 6
7 8 9
>>>
2.访问嵌套列表中的一维列表,如下实例
>>> matrix
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> matrix[0] //访问嵌套列表的第一个元素,第一个元素也是一个列表,所以返回嵌套列表中的第一个元素列表
[1, 2, 3]
>>> matrix[1] //访问嵌套列表的第二个元素
[4, 5, 6]
>>> matrix[2] //访问嵌套列表的第三个元素
[7, 8, 9]
3.访问嵌套列表的某一个具体的元素值,如下实例
>>> matrix[0][2] //访问第一行第3个元素
3
>>> matrix[2][0] //访问第三行第一个元素
7