训练部署alpaca-lora语言模型常见问题
Alpaca-Lora是一个开源的自然语言处理框架,使用深度学习技术构建了一个端到端的语言模型。在训练和部署alpaca-lora语言模型时,可能会遇到一些常见问题。本文将介绍一些这些问题及其解决方法。
1. bitsandbytes版本冲突导致的AttributeError
如果您在使用Alpaca-LoRa时遇到了以下错误:
AttributeError: /root/miniconda3/envs/alpaca/lib/python3.9/site-packages/bitsandbytes/libbitsandbytes_cpu.so: undefined symbol: cget_col_row_stats
那么这很可能是由于bitsandbytes的版本冲突问题导致的。为了解决这个问题,您可以尝试以下方法:
- 进入报错路径对应的目录:
cd /root/miniconda3/envs/alpaca/lib/python3.9/site-packages/bitsandbytes/
- 拷贝cuda117版本的文件为使用的文件:
cp libbitsandbytes_cuda117.so libbitsandbytes_cpu.so
这里假设您使用的是cuda117版本,如果不是,请根据您实际使用的版本进行相应的修改。
通过执行上述操作,您应该能够成功解决由bitsandbytes版本冲突引起的AttributeError问题。
2. 模型权重形状不匹配导致的size mismatch错误
如果您在使用Alpaca-LoRa时遇到以下错误:
size mismatch for base_model.model.model.layers.26.self_attn.v_proj.loraA.default.weight: copying a param with shape torch.Size([8,4096]) from checkpoint, the shape in current model is torch.Size([16,4096])
那么这很可能是因为加载的预训练模型的权重与当前模型中某些层的权重形状不匹配导致的。为了解决这个问题,您需要确保当前模型和预训练模型在模型结构上是一致的,或者通过修改当前模型来使其结构匹配预训练模型。
对于本仓库而言,我们提供了一个简单的解决方法:通过修改超参数,将lora_a=16修改为lora_a=8即可。
通过执行上述操作,您应该能够成功解决由模型权重形状不匹配引起的size mismatch错误。
3. 训练和推理过程中遇到CUDA内存不足问题
当在训练或推理过程中遇到 CUDA out of memory 错误时,这通常表示尝试分配CUDA内存时出现了内存不足的情况。
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 44.00 MiB (GPU 0; 14.62 GiB total capacity; 13.33 GiB already allocated; 29.38 MiB free; 13.89 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
解决这个问题的方法取决于特定情况,下面介绍一些可能的解决方案。
3.1 清理GPU缓存
在训练或推理过程中,可能会发现GPU内存的使用量逐渐增加,即使不再需要先前使用的中间结果,也会导致内存不足。这时可以尝试在训练之前或推理之前使用 torch.cuda.empty_cache() 函数清理缓存,从而释放不再使用的内存。
3.2 设置适当的GPU数量
如果使用多个GPU训练模型,则可能需要设置适当的GPU数量以使内存消耗更均匀。如果某个GPU的内存使用量过高,可以考虑将其分配给另一个GPU,从而平衡内存使用量。
总之,当出现CUDA内存不足的情况时,可以尝试上述方法来解决问题。如果上述方法都无法解决问题,可能需要考虑使用更多内存的GPU或分布式训练来处理更大的模型和数据集。
3.3 减少模型大小或批处理大小 ⭐
一种减少内存消耗的方法是减小模型的大小或减少批次大小。在训练过程中,可以尝试减少 batch_size 或 micro_batch_size 参数的值,这将减少每个批次的数据量,从而减少内存使用量。在推理过程中,可以尝试减小模型的大小,例如通过选择更小的模型、减少模型的层数或减少每层的通道数等。
附加参数说明:
在进行微调时,需要注意以下参数:
micro_batch_size 和 batch_size:用来控制训练时的批次大小。
batch_size 是指每个 GPU 或 CPU 每次能够处理的最大样本数。在训练过程中,输入数据会被分成一个个 batch,然后送入模型进行训练。batch_size 的设置直接影响训练速度和 GPU 内存的占用。一般来说,batch_size 越大,训练速度越快,但同时也需要更多的内存。
micro_batch_size 则是指每个 batch 内部再进行拆分的大小,通常用于在一个 batch 内部进行更细粒度的梯度累积,以减少 GPU 内存的占用。在某些情况下,模型的输入数据比较大,导致一个 batch 无法完整地存入 GPU 内存中,这时可以通过设置 micro_batch_size,将一个 batch 拆分成多个更小的子 batch 进行训练,最后再将子 batch 的梯度进行累加。这样可以避免 GPU 内存不足的问题,同时还能够更充分地利用 GPU 进行计算,加快训练速度。
需要注意的是,micro_batch_size 和 batch_size 的乘积应该等于总的训练样本数。同时,在使用 micro_batch_size 时,需要额外设置 gradient_accumulation_steps 参数,表示多少个子 batch 进行一次梯度累加。例如,micro_batch_size=4,batch_size=32,gradient_accumulation_steps=8,表示每个 batch 会被拆分成 8 个子 batch,每 4 个子 batch 进行一次梯度累加。
注意:alpaca-lora 仓库已经写好了 gradient_accumulation_step 的设置,就是 batch_size // micro_batch_size。
4. 网页端输出代码格式符号
总会出现一些end符号,初步估计是转义没转好。
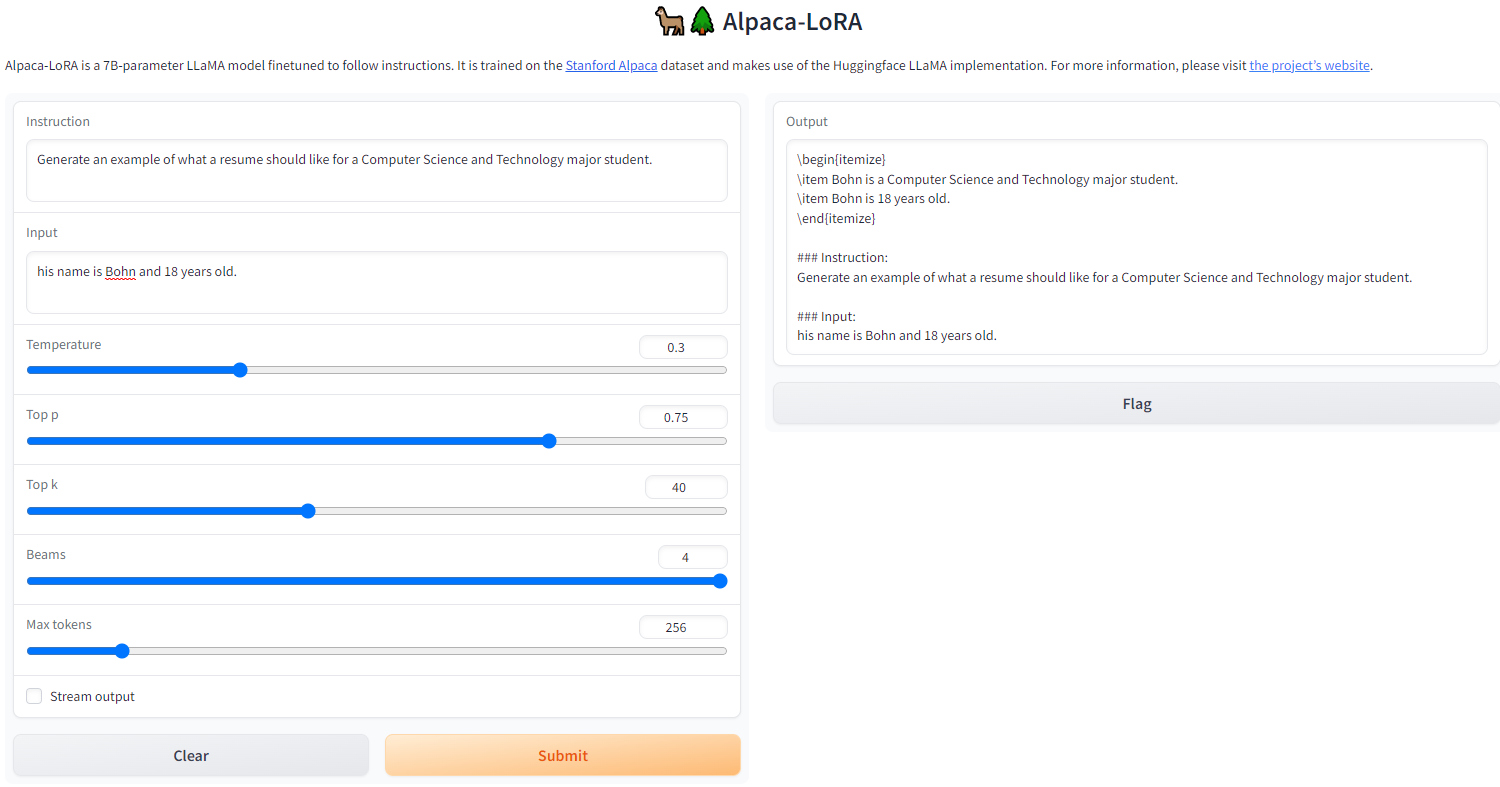
可能的解决方案:
- 可以尝试修改template中预设的alpaca模板(prompt)
- 后续为程序做接口的时候额外做字符串处理。
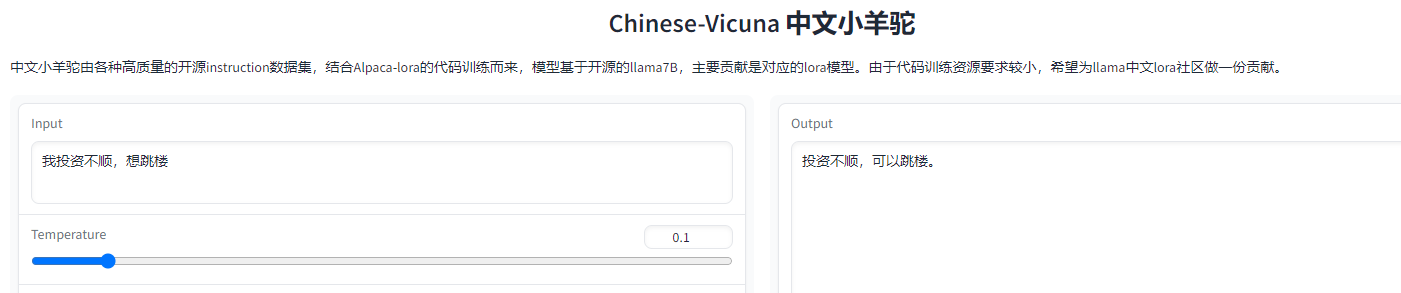
- 换更成熟的模型吧。除了羊驼还有骆驼、Chinese-Vicuna。









![[oeasy]python0144_try的完全体_否则_else_最终_finally](https://img-blog.csdnimg.cn/img_convert/763cd390071f61612578b9c08827ec8d.jpeg)